正则表达式的探索与发现-爬虫项目系列博客
因为要实现爬虫的功能,正则表达式是必须要掌握和简单应用的。那么这对于从来没看到过正则表达式的小白来说,它无疑是头痛的,因为它的长这个样子
1 | var url_reg = /\/(\d{4})\/(\d{2})-(\d{2})\/(\d{7}).shtml/; |
1 | /* |
翻阅了一下犀牛书,有看了几个网上的教学视频,总算有了点概念,接下来我先把书本的内容贴上来







先来看看第一个正则表达式
我们要知道,正则表达式不是我们凭空捏造出来的,而是在我们找到目标网页后,根据源代码中子内容的编写规律对应着写下来的,老师的代码爬取的式中国新闻网的内容,所以我们先打开中国新闻网的源代码页面。
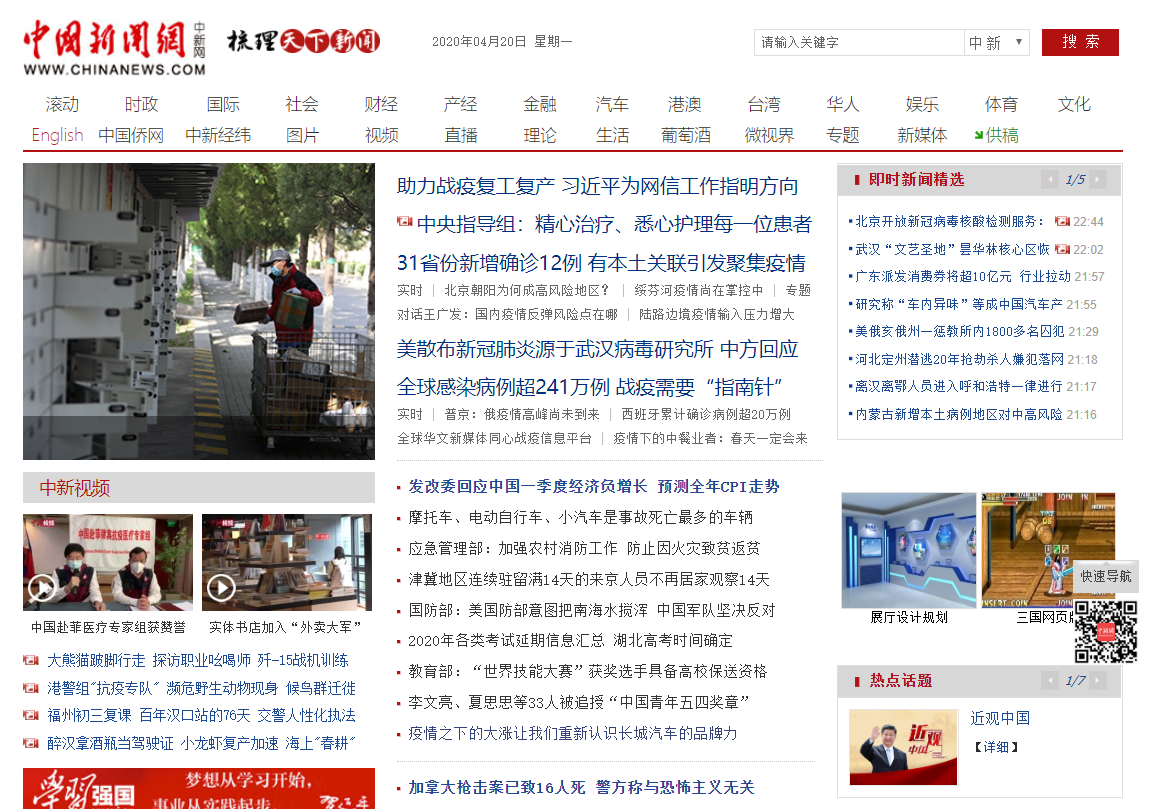
我们看到了这一行行的新闻标题,心想:这不就是我想要的嘛!!!怎么才能获得呢!??
不慌,按F12进入坦克进入DevTools
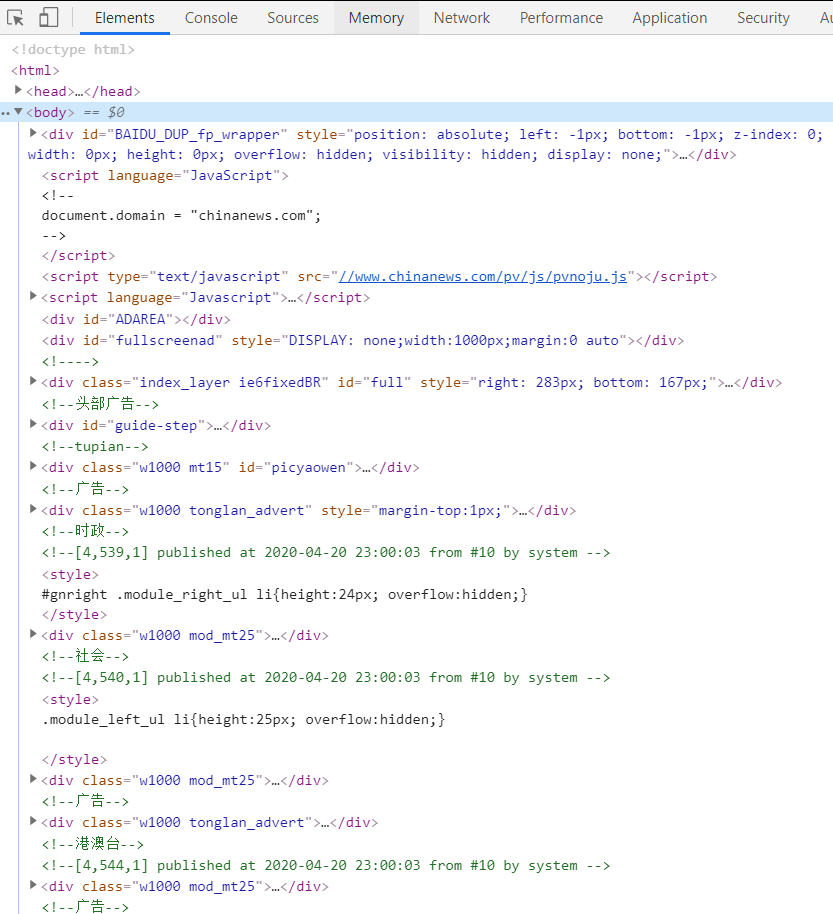
那么如何才能定位呢?我们点击左上方的那个小按钮,对,就是那个有鼠标一样的小按钮
新世界开启
我们只要把我们的鼠标移动到任何一处,图片,链接,窗口等等,devtools中就会自动显示对应的链接,太可了!

这样看了几个新闻链接后,我们不难发现
http://www.chinanews.com/gn/2020/04-20/9162393.shtml
http://www.chinanews.com/gj/2020/04-20/9162621.shtml
http://www.chinanews.com/cj/2020/04-20/9162059.shtml
好吧事不过三,我们发现这三个基本上具有相同的格式,只是中间的gn/gj/cn不同,日期可能不同和后边的编码不同,好,那么我们需要用正则表达式去匹配前面的www.chinanews.com嘛?其实并不需要,我们只需要找到这类链接的不同之处即可,否则就是浪费时间。那么再来分析一下我们的正则表达式
1 | var url_reg = /\/(\d{4})\/(\d{2})-(\d{2})\/(\d{7}).shtml/; |
分析完毕,我们来测试一下他的具体性能吧
https://c.runoob.com/front-end/854 这是一个在线测试正则表达式的网站,在写爬虫的时候先跑一下看看到底能不能过滤出有效的信息来
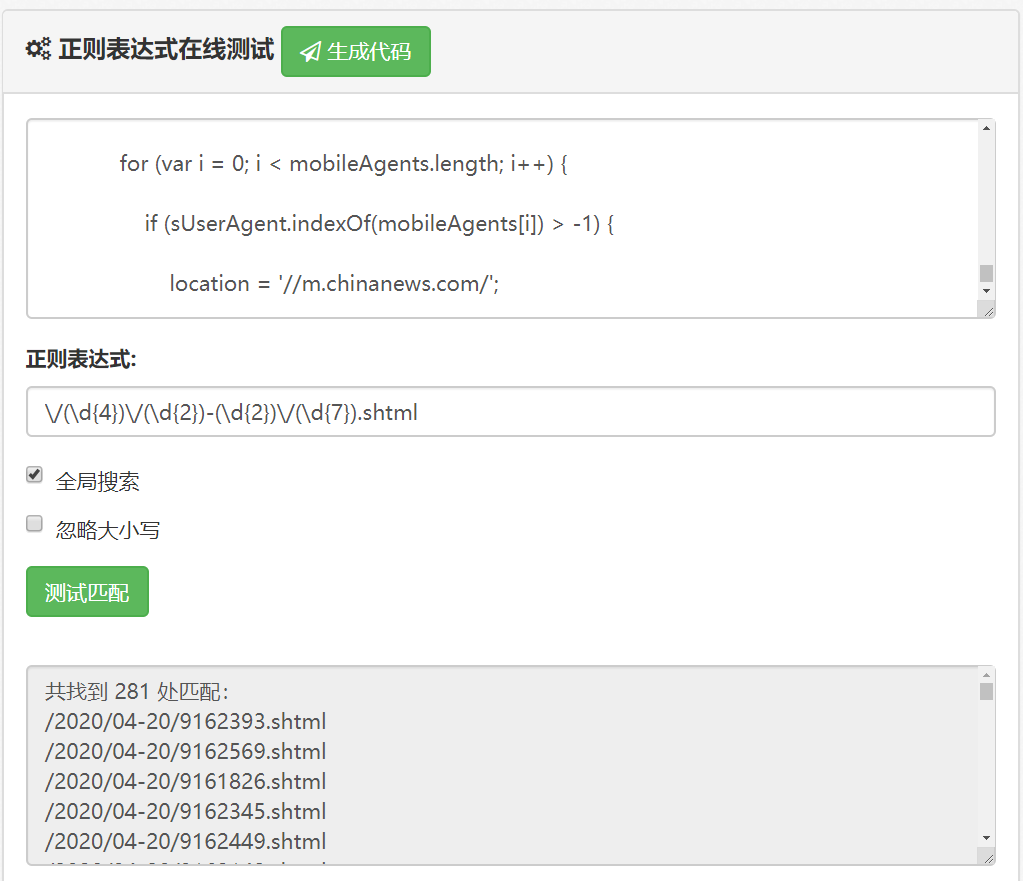
可以看到这个正则表达式还是蛮厉害的,匹配到了200多条网页链接
再来看看第二个正则表达式
- 我们来看看第二个正则表达式索要匹配的目标
1 | var regExp = /((\d{4}|\d{2})(\-|\/|\.)\d{1,2}\3\d{1,2})|(\d{4}年\d{1,2}月\d{1,2}日)/ |
1 | 1.<span id="pubtime_baidu">2020-04-21 08:53:46</span> |
- 其实我们要匹配的是这个出版时间,因为新闻嘛,总要讲究出版时间,所以我们要把他们都找出来
- 因为出版时间有多种形式,有可能是19-08-19类的,有可能是2020/03/20,也有可能是2020年04月21日
- \d{4} 出现四个数字,也就是匹配年份
- \d{2} 出现两个数字,也是年份,只不过可能是19-xx-xx也有可能是 2019-xx-xx 所以在中间加个|表示或
- ( \-|\/|\.)其实是最难的,因为信息量很大,其实她想说的就是中间连字符的种类,可能是 -,可能是/,可能是 . 中间两个| 就是表示或者的意思
- \d{1,2}是匹配月份的,有可能是 1,也有可能是01
- \3比较难理解,这个\3其实就是匹配左边开始数第三个左括号的,也就是( \-|\/|\.),其实也是月和日之间的连接符
- \d{1,2}匹配的是日期
- 前面完全是数字字符来表达年月日,不过也存在2020年4月21日这种情况,那么我们如何解决?| 就完事了
- | 后面匹配的就是2020年4月21日这类的日期表达
下图就是\3 这类\后面加上数字的作用

最后来看看我的爬虫中的正则表达式
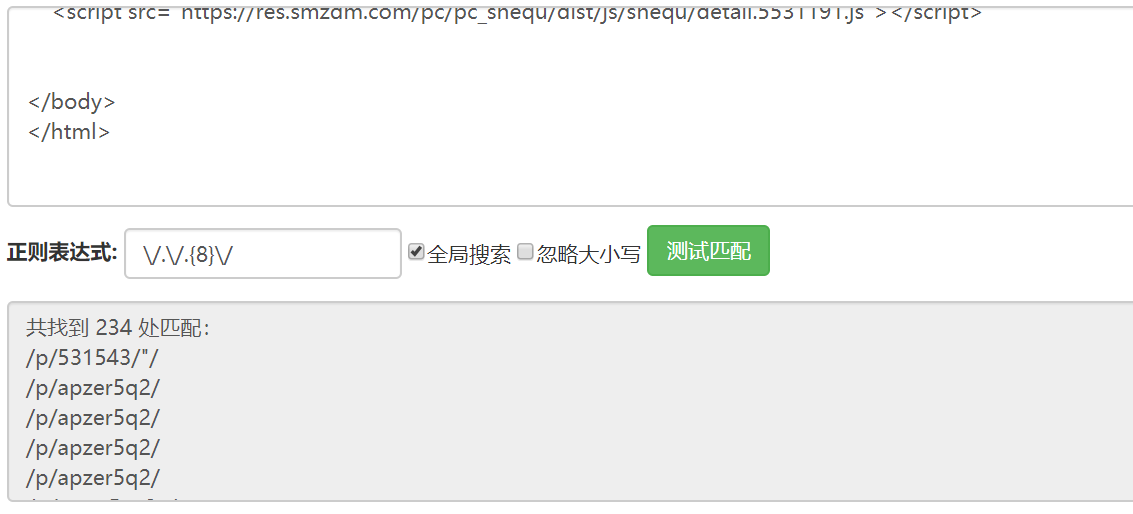
1 | var regExp =/\/.\/.{8}\// |
我要爬取的网站是 https://www.smzdm.com/ 什么值得买网站(为了找我喜欢的咖啡具)
然后我们来看看子网页
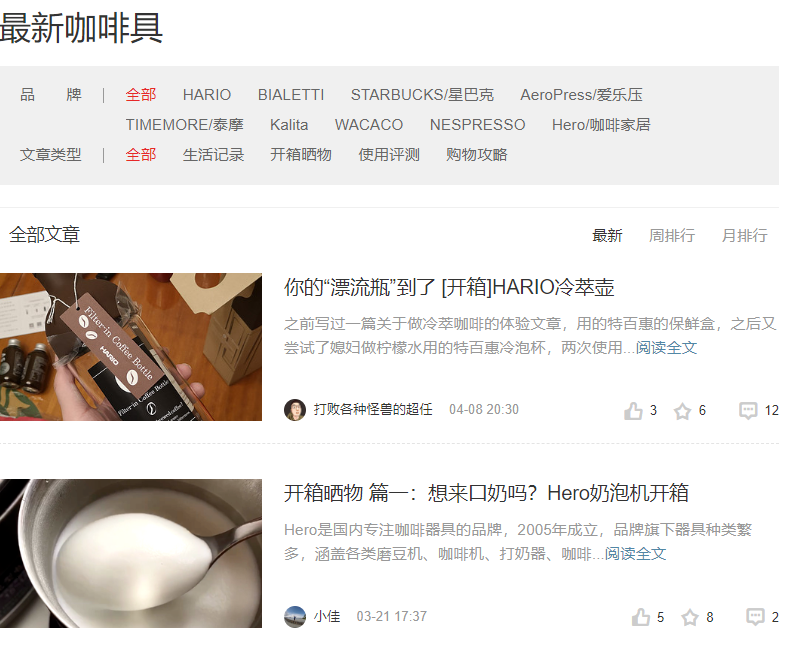
按照上面的方法,我们来找找看子网页的url
https://post.smzdm.com/p/alpwnzve/
https://post.smzdm.com/p/awxqrv02/
规律是很明显的,我们需要匹配的就是 /p/alpwnzve/
- \/匹配的就是/
- .匹配的是任何字符(除了\n),当然也可以用[a-zA-Z]代替
- \/又匹配的是/
- .{8} 匹配的就是 连续八个字符,这里匹配的就是alpwnzve之类的
- \/匹配的还是/
来看看我们的匹配结果
总结
写到这里,我们对正则表达式都有了一个基本的概念了,学会了正则表达式,在爬虫的项目中就解决了一个很大的难题。