用nodejs来制作一个简单的爬虫来爬取网页信息
写在前面——知其然也要知其所以然
像我这样连冲个咖啡豆要记笔记的人,怎么能写自己都看不懂的博客呢?所以我的目标是你读完了我的博客,也可以写出爬虫来。
这一篇是目录性质的博客,冰冻三尺非一日之寒,爬虫项目只写一篇博客是完全不够的,所以我打算用分而治之的框架来完成这篇博客的内容。我想把它分成几个部分,逐个击破,已达到融会贯通的地步(显然这是基本不可能的)
最近学校的web编程课要求我们做一个爬虫来爬取网页信息,老师给出了一个新闻网站的爬取,但是因为缺少对JavaScript语言的认识和运用,用nodejs来写显得举步维艰。(水平过于低下)
- 前三个问题,注重于基础知识,是为正式的爬虫项目打基础、做准备的,罗马不是一天建成的,有了前面的基础知识,对爬虫有了初步了解,才能够有能力看得懂(我说只是有能力看懂)每一步的操作
对JavaScript语法的陌生
对爬虫原理的陌生
对正则表达式的陌生
爬虫项目中引用的包及其用法
如何选定一个网站,并模仿老师的代码开始我的爬虫项目?
用JSON格式存储时的重名问题
对爬取特定信息的格式问题
将数据存储到MySql时遇到的问题
如何用mysql查询已经爬取的数据
用网页发送请求到后端查询
用express构建网站访问mysql
用表格显示查询结果
爬虫定时工作
尝试其他的扩展(留给读者,或者无限期暂停更新)
- 所以,这篇文章列举了我在写爬虫项目时候的种种问题和解答,如果篇幅不长,我会直接在博文里介绍,如果篇幅过长,我会另写一篇博客,并在这里附上链接,以供读者方便切换阅读
1.对JavaScript语法的陌生
起因
在大一下之前,我对JavaScript一脸茫然,甚至认为JavaScript和Java是一种语言,这显然是过于荒唐的一件事。认真学习JavaScript也是在网课进行了一个半月之后。
如何解决?
对于老师的每章节网课,我都有在博客上记笔记,可以看看我的JavaScript语法系列博客
在没有学习过Javascript语法的时候,就上手爬虫项目,无异于以卵击石,自不量力。对于每一句话,每一个函数,都在脑子中缓缓打出一个?
2.对爬虫原理的陌生
起因
这方面对于没有学过爬虫原理的我来说要理解起来确实有点困难,但是幸好老师提供了几期视频来阐述,于是懵懵懂懂有个概念。
如何解决?
看了几遍老师的代码和讲解后,可以简单得将爬虫的思想列举一下
- 首先我们搜索主页面,获取我们想要的子网页的URL
- 通过request请求,cheerio解析,each遍历
- 搜索出我们子网页页面中我们需要的信息:标题,正文等
- 通过request请求,cheerio解析
- 将这些我们需要的信息保存下来,通过各种形式访问到这种信息
- 建立fetch(文件对象),输入文件信息,fs /mysql模块写入
读到这里,你只需要了解我们要一步步完成的目标就行,具体的工具我会在接下来的文章中一一讲述。
3.对正则表达式的陌生
原因
没有接触过正则表达式,一开始看到的时候感叹——这像天书般的\/{}$.+-[]根本无从下手
有一说一,我就是因为看不懂这么几行正则表达式,才迟迟不开始爬虫作业(特别不好学)
1 | var url_reg = /\/(\d{4})\/(\d{2})-(\d{2})\/(\d{7}).shtml/; |
如何解决?
显然,ddl是第一生产力。只剩下两周的时间了,我找了几期正则表达式的教学视频来补习了一下,也是勉强有了大概,并且用了这个页面上的正则表达式检测器练习了几遍。
- 菜鸟工具
- 咦,他叫自己菜鸟工具,正好,非常适合我。
- 这里补充一下练习模式,就是在某一个网站上找源代码,然后找全部都是一种模式的网址或者图片。对着他写下你的正则表达式,然后把源代码复制到这个菜鸟工具中,检测一下是否把你想要的哪些网站都搜索出来了。
- 笨方法才是好方法,要写自己看的懂的,不要用很巧妙的正则表达式,当然大佬自动忽略。
- 程度,现在勉强可以看着网址写出他的正则表达式了
- 关于我如何学习正则表达式和正则表达式的具体概念,参见我的另一篇博客 —初识正则表达式
- 初识正则表达式
4.爬虫项目中引用的包及其用法
起因
- 我们不能简单的把几个模块引用过来但不知道其具体作用
如何解决?
因此,我另写了篇博客来谈谈爬虫中需要引入的模块和它们的作用
5.如何选定一个网站,并模仿老师的代码开始我的爬虫项目?
起因
读懂了老师的代码,才是开始自己爬虫的第一步。那么,是应该选择什么网站来开始我的爬虫项目呢?娱乐网站?新闻网站?购物网站? 最后,作为练习时长大半年的个人练习生 吧台手和资深键盘咖啡师的我来说,还是选择了什么值得买网站作为我的第一个爬虫项目(想看看大家的开箱报告)
如何解决
因为这里的空间不是很够,所以我会新建一篇博客详细讨论一下我是如何解决的
6.用JSON格式存储时的重名问题
我写完代码之后,已经成功地转码了
- 但是却没有.json文件保存下来
- 存储下来了,但不是JSON文件
如何解决
问题1
问了助教和老师之后,在大家一起努力下,找到了问题并成功解决了。
1 | var filename = source_name + "_" + (new Date()).toFormat("YYYY-MM-DD") + |
一开始,我和老师命名文件的时候用的是同一行代码,但是很显然,这个存储方法不是放诸四海皆准的,我们需要结合网站的url和具体作用来具体分析,然后再选择一个不会让文件重名的命名方法.
说白了,就是你怎样通过字符串拼接来给这么多文件取互不相同的名字??
首先看看中国新闻网的(子网页)URL
http://www.chinanews.com/gn/2020/04-23/9166028.shtml
再来看看什么值得买 (子网页)的URL
https://post.smzdm.com/p/531543/
结合老师的命名方法,我们一步一步分析,
source_name 是我们规定的,在老师的代码里,是”中国新闻网”,在我的代码里是”什么值得买“,到现在,所有文件的命名都是一样的
(new Date()).toFormat(“YYYY-MM-DD”) 是用一个新的Date()对象,然后转码成YYYY-MM-DD的形式,如果在这里我仍然和老师的代码一样,那么到这里,所有的文件命名也还是一样的
最关键的一点,老师的这部分 myURL.substr(myURL.lastIndexOf(‘/‘) + 1),也就是说,他截取了URL的一部分,那么,是从什么时候开始截取 的呢?
lastIndexOf()这个api在我的Javascript数组这篇博客中有些到,就是从尾部开始遍历数组或者字符串,返回’/‘出现的第一个索引,然后把他加1
substr是字符串截取函数,这里是从myURL.lastIndexOf(‘/‘) + 1处开始截取,一直到末尾结束
我们可以看到,根据上面那个例子最后一个’/‘+1之后的字符串为9166028.shtml,而这一部分对中国新闻网的每一个页面都是不同的
但是我的URL呢?我们如果用myURL.substr(myURL.lastIndexOf(‘/‘) + 1)这个方法呢?
- 从什么值得买子网页可以看出,最后一个‘/’就是字符串中的最后一位,所以再加一,再截取,那么我们根本截取不到任何东西!!!
所以这就出现了问题,老师在这一步已经完成了不同文件的命名,但我这时候所有的文件命名任然是一样的
最后只是加上后缀名’.json’,大家都一样
那么这就是问题的痛点了。我因为所有的文件名字都一样,所以电脑上更本无法保存,如何修改呢??
通过老师的点拨,我对代码做了这样的修改
1 | var filename = source_name + "_" +(new Date()).valueOf()+"_"+".json"; |
- 我把新的Date()对象,使用了valueOf()的方法(返回的是毫秒数)
- 因为爬取每个页面的时间精确到毫秒级别,所以单单提取秒数是远远不够的,所以我没有用getSeconds()方法,而用了valueOf()方法
经过再操作,这个问题解决了!
问题2
现在,我已经实现了保存文件,但是,却都是这样的
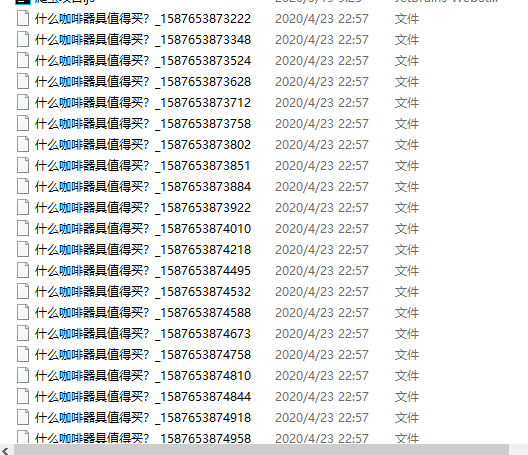
他没有任何的文件类型,这是啥情况呢
返回代码本身,看看 .json 之前出了什么问题
果然,我们发现了一个多余的下划线,本来是在老师的代码里面连接9166028.shtml用的,我没有把他删掉,这样, 下划线和.json的. 相连接,不符合命名规范。所以无法存储
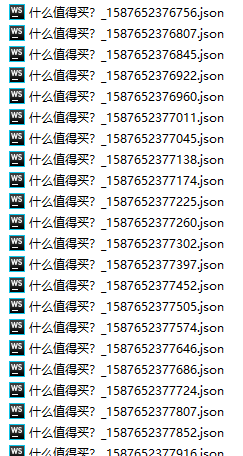
1 | var filename = source_name + "_" +(new Date()).valueOf() +".json"; |
改成这样后,再运行,就完美了
7.对爬取特定信息的格式问题
起因
我准备爬取一个title和文章的内容,但是一开始只有文章内容被保留了下来,title并没有被爬取到
如何解决?
助教一阵见血的指出了我的错误
- 原来,本来我的代码是这样的:
1 | var interface_format = "$('.edit_interface').text()" |
- 然而,网站里的源代码竟然是这样的
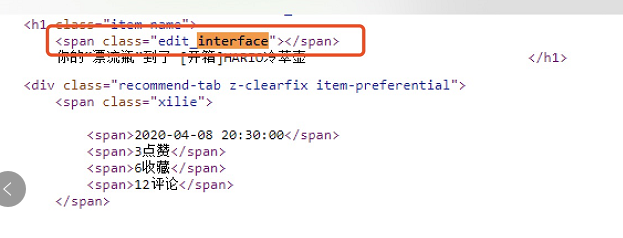
我们看见\ \ 这一行代码没有任何东西!
所以,我们爬取下来的文件,变成了这样:

当我们改成下面代码的时候,一切都好起来了
1 | var interface_format = "$('h1.item-name').text()" |

8.如何把数据存储到MySql中?
起因
如果说只能把内容存储到json文件中,那管理起来很麻烦。我们可以通过修改一下代码,让内容存储到数据库当中
如何解决
看了老师的视频之后,在问过助教之后,最终解决了
具体怎么解决,请看我的子博文:如何把数据存储到MySql中
9.如何用mysql查询已经爬取的数据
起因
- 已经爬取到了那么多数据,并且存放到了Mysql中了,那么怎么才能访问、查询他们呢?
如何解决
- 大量搜寻:
- select title,url from fetches //title,url可以换成任意种类,但这样所有的数据都会呈现
- select title,url from fetches limit 20 //这样,呈现的信息就被限制在了20条
- 因为这样搜索的结果已经在如何把数据存储到MySql中?这篇博文中有所展示,因此不予赘述
- 关键词搜寻
- select title,author,publish_date from fetches where title like ‘%新冠%’;
- 结果如下

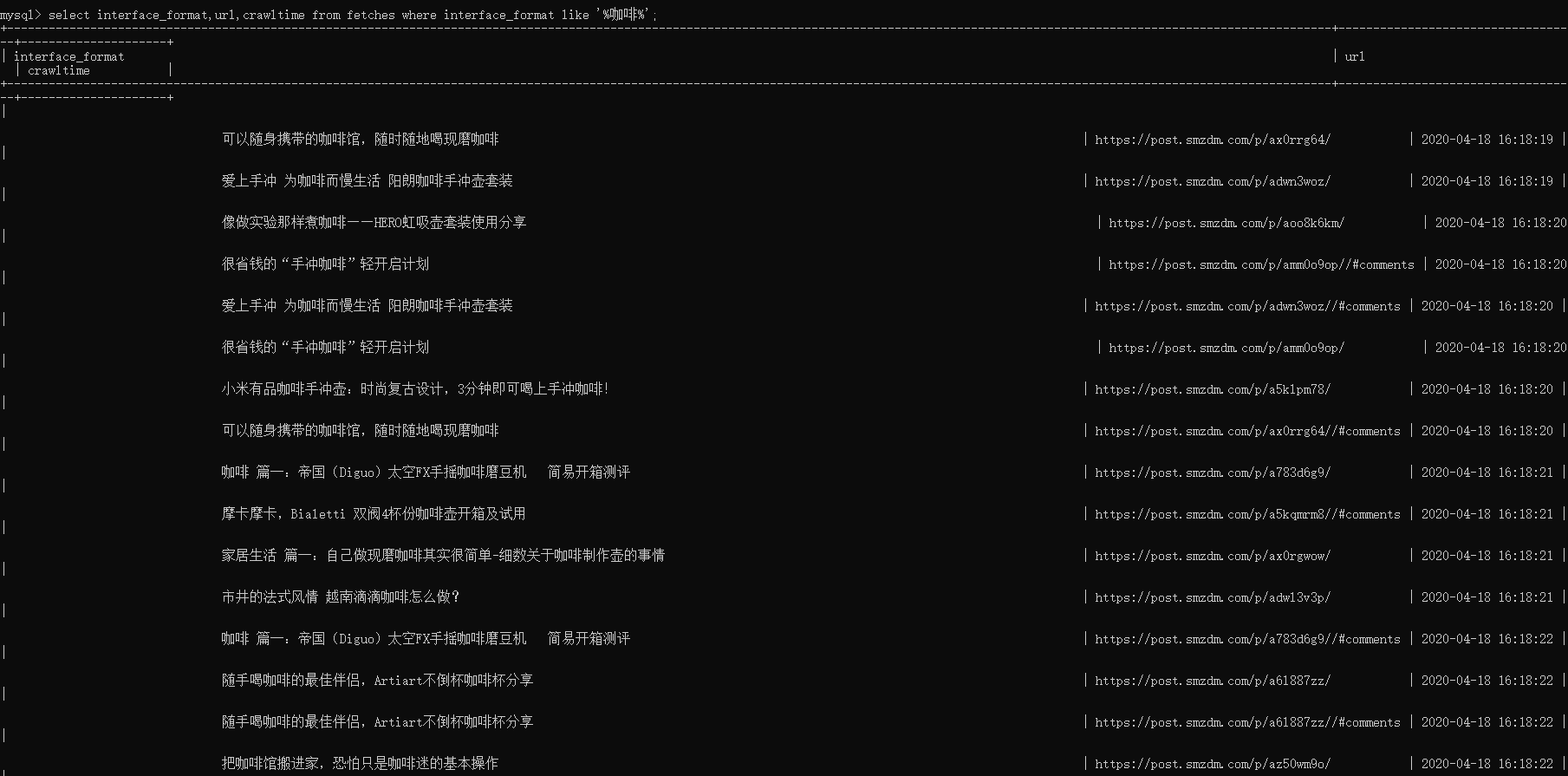
- select interface_format,url,crawltime from fetches where interface_format like ‘%咖啡%’;
- 结果如下
- 利用js文件搜寻
1 | var mysql = require('./mysql_coffee.js'); |
- 来看看结果
- 老师的结果
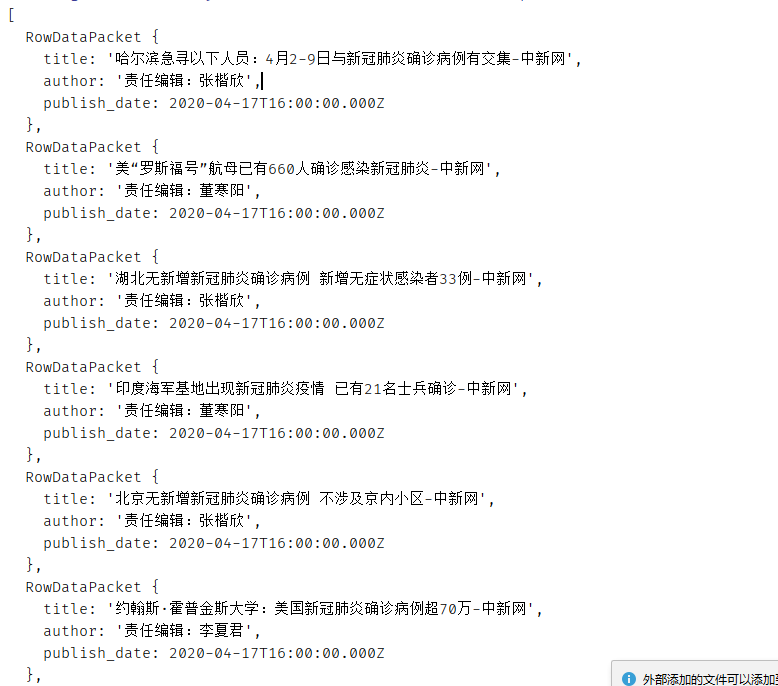
- 我的结果

10.如何用网页发送请求到后端查询
起因:
- 怎么样在网页上查询关键词,并在我的后端返回结果呢?
解决方法:
- 首先,我们创建一个html前端
1 |
|
- 具体样式如下

- 随后,我们建立一个后端,这里用了http模块,而没有用其他框架
1 | var http = require('http'); |
- 我们可以看到,老师的代码运行后,在搜索框中写入 新冠 后是这样一个结果

- 而我们对这个代码稍加修改,马上可以爬取到自己想要的文件
- 比如,我想在什么值得买 表格中搜寻 :咖啡

- 又比如,我想在新浪网 表格上搜寻: 切尔西

- 再比如,我想在东方财富 表格上搜寻: 股市

可以看出,这个问题就算是解决了。
11.如何用express构建网站访问mysql
起因
- 在后端显示其实意义不大,我们要在前端显示,才能体现搜寻效果,那么怎么才能前端现实呢?
如何解决
- 我们用express框架来构建
1 |
|
- 然后我们用express来写后端,虽然功能更丰富,但是代码更为简洁
1 | var express = require('express'); |
- 通过简单的修改,我们可以查询到自己想要的文件
- 比如我想再什么值得买中搜寻咖啡
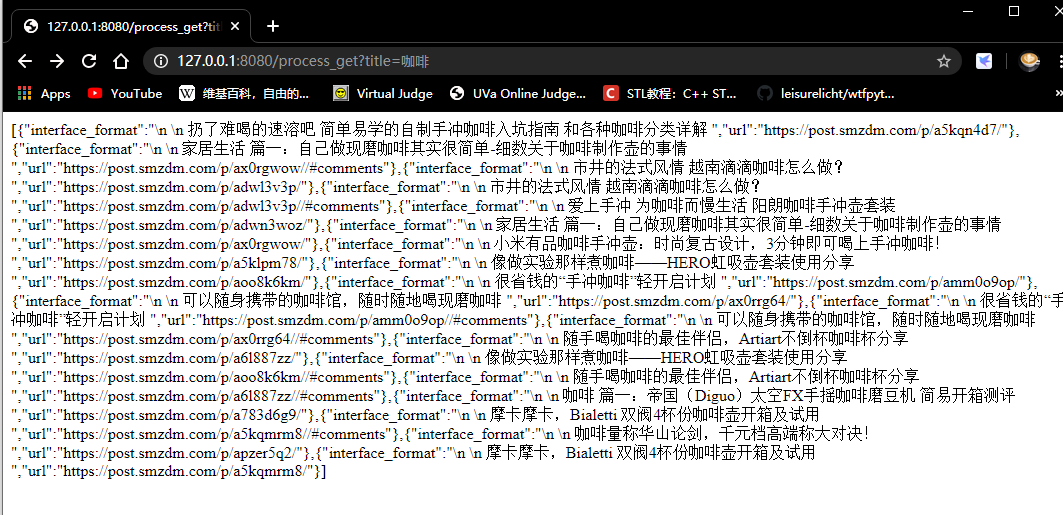
- 比如我想在虎扑上搜寻球

- 到这里,这个问题也解决了
12.如何用表格显示查询结果
起因
向上面的那种显示方法,还是缺少美观性,那么我们试试用表格显示查询结果
如何解决?
这里的空间不是很够,请移步我的子博文: 如何用表格显示查询结果
13.爬虫定时工作
起因:
每次手动爬取太麻烦,怎么样才能定时操控爬虫呢?
解决方法:
- 引入第三方包 node-schedule;
1 | npm install node-schedule; |
- 爬虫代码中引入
1 | var schedule = require('node-schedule'); |
13.尝试其他的扩展(留给读者,或者无限期暂停更新)
- 对查询结果进行分页显示
- 对查询结果按每个字段进行排序
- 对多个查询条件进行复合查询
- 其他功能和性能的提升
总结
山再高,也得往上攀。浪波涛,也得去划船。我们在学习过程中需要有程序员精神。就是不断地发现问题,解决问题,虽然水平不高,但是大佬的水平也是在一次次的解决问题中提高的。 曾经自己认为高难度的作业也会一点一点被自己征服。
完成一个比较大的项目,一定要把它拆分成很多小问题,这也是一种很实用的编程思维。分而治之,逐个击破。
1 | while(项目未完成) |
鸣谢
- 我初次尝试爬虫项目的时候,是助教高瑞卿学姐热心帮我解答了很多疑难问题,还帮我检查了代码中的错误。所以在博客的最后,特此感谢学姐的无私帮助。
在了解了我们的学习进度之后,王晔老师放宽了ddl,并且在视频中加入了很多在写爬虫时候的细节。并且也解答了我一部分问题,特此感谢。
前人栽树后人乘凉。感谢我的好朋友们,是你们在一些问题上的经验帮我规避了很多难题;感谢一些同学们写的博客,是看了你们的博客之后我才有了这篇博客的思路于灵感。