如何把数据存储到MySql中
写在前面
- 这篇博客主要记录了在学习了老师得课程之后如何把爬取下来的文件存储到MySql中去
- 数据库的安装和配置在这里略去不讲
- 目标如下:
- 数据库存储爬取的数据
- 爬取新闻页面之前先查询数据库,是否该url已经爬取过了
- 设置爬虫定时工作
用npm引入mysql模块
1 | npm install mysql --save |
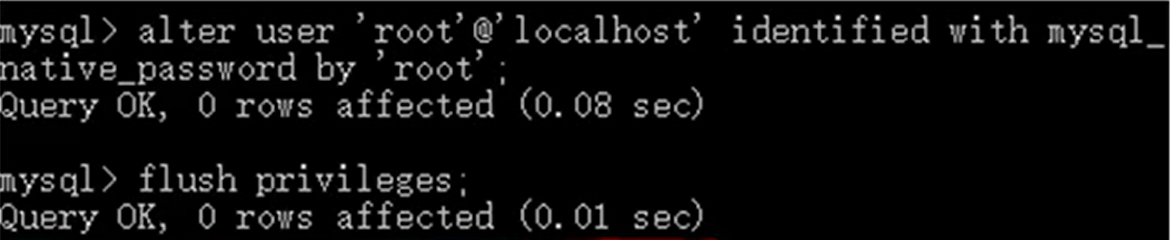
给root用户授权从客户端访问
在mysql中敲入
1 | alter user'root'@'localhost'identified with mysql_native_password by 'root'; |
- 目的是让其他客户端,也能访问我的mysql
使用mysql创造一个数据库和一张用来存放数据的表
- 建库代码
1 | create database crawl;(crawl就是新的数据库名字) |
- 建表代码,老师的最为详细,我一一来解释,同时也会附上我的建表码
1 | CREATE TABLE `fetches` ( |
- 我爬取的数据分类比较少,除了改动一行代码的名字之外,删了几行不需要的代码
1 | CREATE TABLE `fetches` ( |
用node调用mysql
- 我们通过引用分文件的方式。也就是说新建一个mysql.js文件,在里面写上具体操作,然后在主爬虫程序中引入即可,我们还是通过讲解代码的方式来介绍。
1 | //在这个文件里真正引入了mysql模块 |
改写主函数脚本—主要两方面
在文件开始
需要用var mysql = require(‘./mysql.js’),前提是两个文件放在同一个文件夹下。关于js中调用同文件夹的语法,这里略去不讲
在newsGet函数的最后修改
1 | //因为老师的代码更为详细,所以那他的举例子,具体到我自己写的每个爬虫,只需要在原基础上删改即可 |
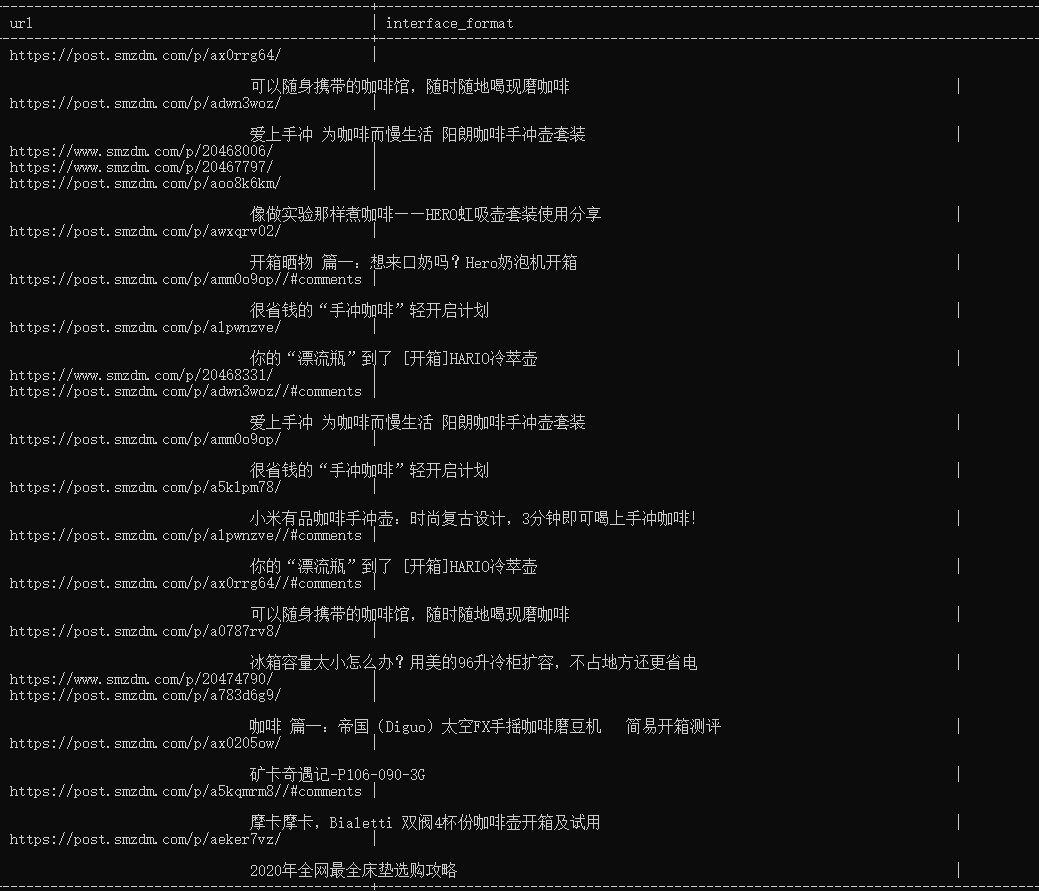
成果展示
经过了上面的操作,我们来分别看看老师的爬虫和我的爬虫分别爬取到的信息吧!
- 老师的爬虫

- 我的爬虫
写在最后
- 其实我真的只是想看看大佬们都买了那些咖啡玩具,QAQ