python 基本语法
if
1 | # if语句 |
if-elif-else 语句
1 | # if-elif-else 语句 |
for 和while
1 | # for 遍历 |
break和continue
1 | # break |
数字
分为 int 和 float两种
运算符
数学运算符
1 | 10**3 #幂运算 10^3 |
逻辑运算符
1 | and #和 |
比较运算符
1 | > |
math function
1 | round() #四舍五入 |
math 模块
1 | math.ceil(x) # 取大于x的最小整数 |
字符串
1 | # 字符串 |
replace()实现字符串替换
replace(‘’,’’,)前面是待替换的字符串,后面是替换的内容。最后一个可选可不选。是在替换的内容选择前几位替换进去。
替换结果时找到字符串中所有的目标进行替换
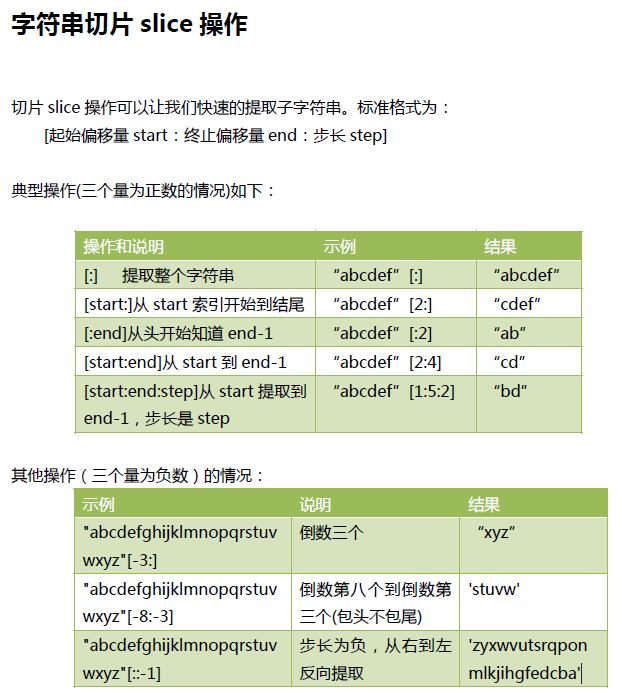
slice()字符串切片
split()分割和join()合并
split()可以基于指定分隔符将字符串分隔成多个子字符串(存储到列表中)。如果不指定分隔符,则默认使用空白字符(换行符/空格/制表符)。示例代码如下:
1 | a = "to be or not to be" |
[‘to’, ‘be’, ‘or’, ‘not’, ‘to’, ‘be’]
join()的作用和split()作用刚好相反,用于将一系列子字符串连接起来。示例代码如下:
1 | a = ['sxt','sxt100','sxt200'] |
sxt-sxt100-sxt200
拼接字符串要点:
使用字符串拼接符+,会生成新的字符串对象,因此不推荐使用+来拼接字符串。推荐使用join 函数,因为join 函数在拼接字符串之前会计算所有字符串的长度,然后逐一拷贝,仅新建一次对象。
字符串汇总
常用查找方法
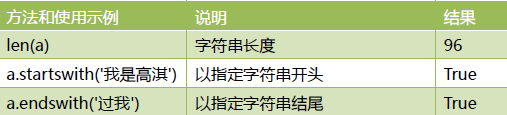

a.isalnum,a.isalpha,可以是对a这个整个字符串,也可以是a[1],a[1:4]等等字符串切片
去除首尾信息
我们可以通过strip()去除字符串首尾指定信息。通过lstrip()去除字符串左边指定信息,rstrip()去除字符串右边指定信息。
1 | "*s*x*t*".strip("*") |
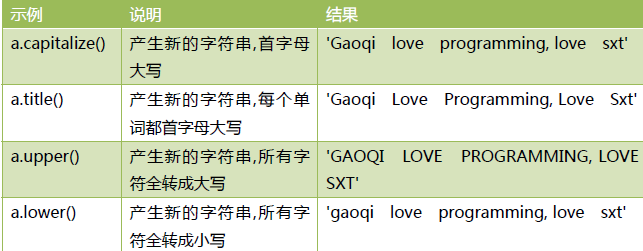
大小写转换
编程中关于字符串大小写转换的情况,经常遇到。我们将相关方法汇总到这里。为了方便学习,先设定一个测试变量:a = “gaoqi love programming, love SXT”

其他方法
- isalnum() 是否为字母或数字
- isalpha() 检测字符串是否只由字母组成(含汉字)。
- isdigit() 检测字符串是否只由数字组成。
- isspace() 检测是否为空白符
- isupper() 是否为大写字母
- islower() 是否为小写字母
- in 判断字符串中是否有我们的目标
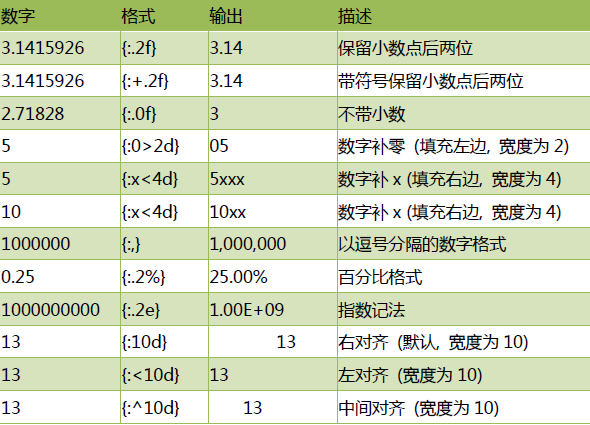
数字格式化
字符串格式化
%s
%10s——右对齐,占位符10位
%-10s——左对齐,占位符10位
%.2s——截取2位字符串
%10.2s——10位占位符,截取两位字符串
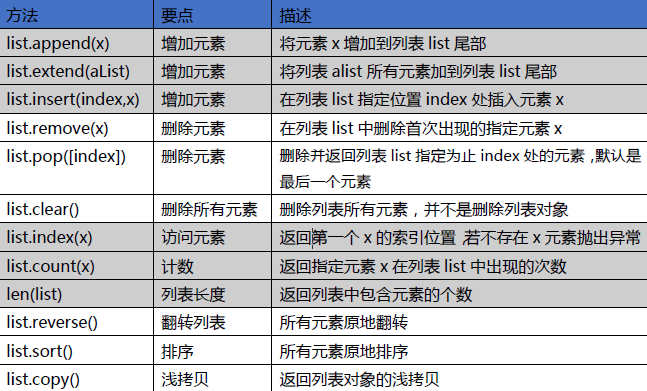
列表
1 | # 列表 |
列表:用于存储任意数目、任意类型的数据集合。
列表是内置可变序列,是包含多个元素的有序连续的内存空间。列表定义的标准语法格式:
a = [10,20,30,40]
其中,10,20,30,40 这些称为:列表a 的元素。
列表中的元素可以各不相同,可以是任意类型。比如:
a = [10,20,’abc’,True]
遍历列表
直接遍历,输出数值
1 | numbers = [2,2,4,6,3,4,6,1] |
通过枚举输出,返回元组
1 | numbers = [2,2,4,6,3,4,6,1] |
还可以输出去掉括号的枚举内容
1 | letters = ["a","b","c"] |
找到列表中的最大值
1 | number = [12,3,289,33,2903,948,1029] |
二维列表(矩阵)
1 | matrix = [ |
列表去重
1 | numbers = [2,2,4,6,3,4,6,1] |
列表解释
1 | items =[ |
元组 Tuple
只有 count和index两个方法
1 | # 元组,(不可变的列表)用小括号 |
字典
1 | # 字典{} |
输出电话号码
1 | number = { |
emoji
1 | message = input(">") |
get的用法
dic.get(k,d) 的意思是说哈,再字典中找,找到了呢就返回dic[k],找不到呢就返回d
函数
def是关键词
1 | def sum(n,m): |
函数返回值,不写默认返回None
推荐要有返回值,在外面输出,后期代码维护方便
1 | def square(number): |
key arguments
1 | def increment(number,by) |
缺省参数
默认参数应该放在参数列表中的最后一位
形如def increment(number,by =1 ,anothor)的写法是不能接受的
1 | def increment(number,by=1) |
*args
运用*args,可以传入很多的参数
1 | def multiply(*numbers): |
**args
传入多个参数,其中是可以指定每个参数的类型的
1 | def save_user(**user): |
全局变量和局部变量
1 | message = "a" |
可以通过关键字global 把函数中的局部变量转换成全局变量
1 | message = "a" |
Lambda Function
Lambda函数又叫做匿名函数
lambda 并不会带来程序运行效率的提高,只会使代码更简洁。
如果使用lambda,lambda内不要包含循环,如果有,我宁愿定义函数来完成,使代码获得可重用性和更好的可读性。
总结:lambda 是为了减少单行函数的定义而存在的。
1 | g = lambda x:x+1 |
又如
1 | def sort_item(item): |
所以Lambda函数的写法就是
1 | lambda paramerters:expression |
Map function
map()是 python 内置的高阶函数,它接收一个函数 f 和一个 list,并通过把函数 f 依次作用在 list 的每个元素上,得到一个新的列表并返回。
map()的使用方法形如map(f(x),Itera),它有两个参数,第一个参数为某个函数,第二个为可迭代对象。
1 | items =[ |
Filter Function
和map函数一样的格式,第一个参数传入一个函数,第二个参数传入一个可迭代的对象
filter函数用来筛选
1 | items =[ |
Zip Function
1 | list1 = [1,2,3] |
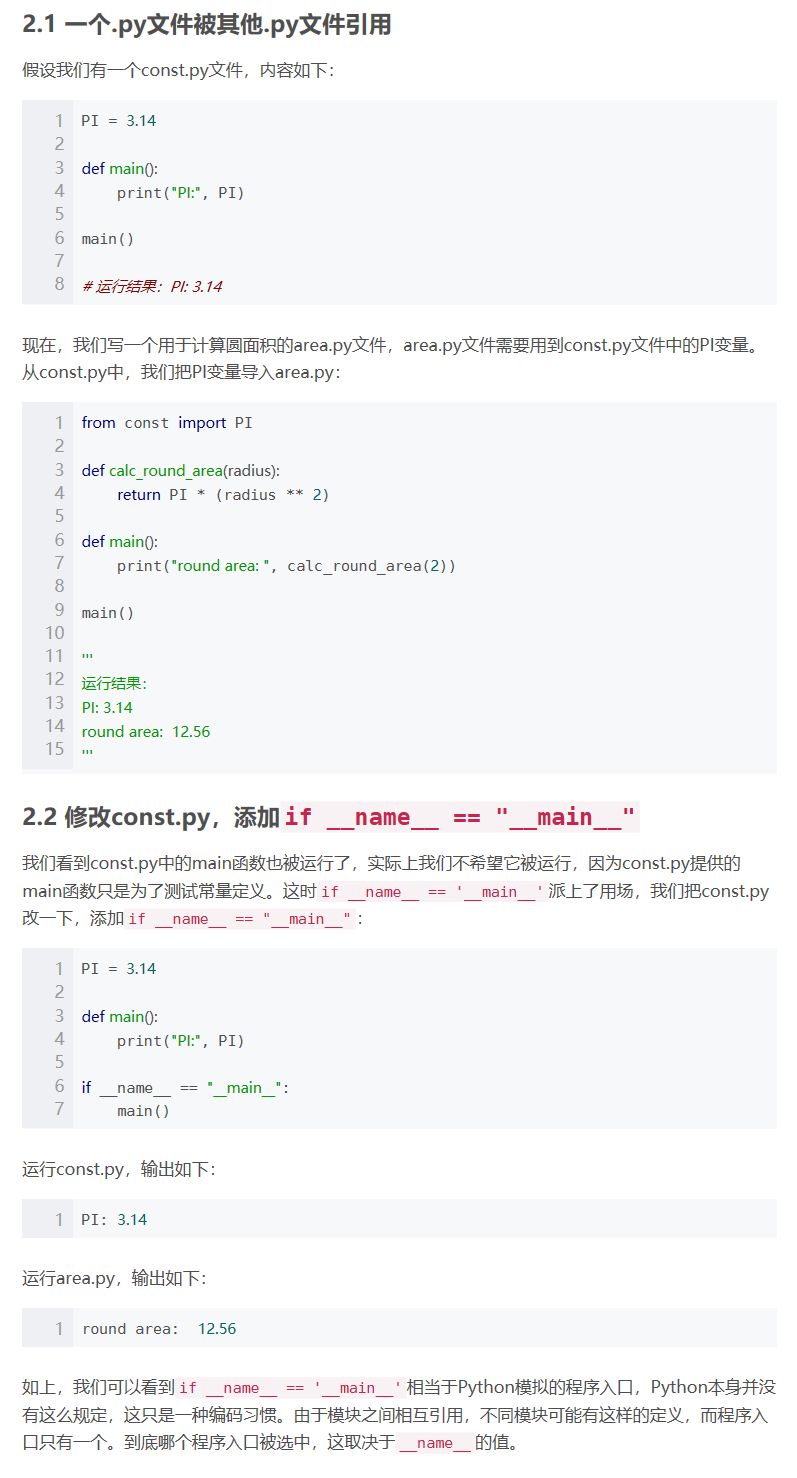
if __name__ \=\= \’__main__\’
https://blog.csdn.net/yjk13703623757/article/details/77918633/
通俗的理解__name__ == '__main__':假如你叫小明.py,在朋友眼中,你是小明(__name__ == '小明');在你自己眼中,你是你自己(__name__ == '__main__')。
if __name__ == '__main__'的意思是:当.py文件被直接运行时,if __name__ == '__main__'之下的代码块将被运行;当.py文件以模块形式被导入时,if __name__ == '__main__'之下的代码块不被运行。
Exception :异常
异常会发现你的错误并报告,而不是说让你的程序down掉
1 | try: |
finally后面的代码是操作成功后执行的代码
Raise exception
相当于C++中的 throw,抛出一个异常来
当程序出现错误,python会自动引发异常,也可以通过raise显示地引发异常。一旦执行了raise语句,raise后面的语句将不能执行。也就是自定义的异常情况
1 | try: |
又如
1 | def calculate_xfactor(age): |
Cost of Raising Exceptions
使用raise是要多出很多时间的
with 语句
凡是对象带
1 | __enter__ 和 __exit__ |
这两个magic function的,都可以用with语句,它会自动打开关闭这个文件。
所以不再需要Finally这个关键字了
而且with可以同时打开很多文件
1 | try: |
类和对象
类的每一个单词首字母都要大写
1 | class Point: |
声明了一个实例后,还可以通过. 运算符添加这个实例的属性
构造函数
1 | def __init__(self): |
例一
1 | class Person: |
例二
1 | # 类和对象:面向对象 编程 |
classmethod,staticmethod修饰符和类方法的总结
classmethod
1 | class A(object): |
又如:
1 | class Point: |
staticmethod
总结
实例方法只能被实例对象调用,静态方法(由@staticmethod装饰的方法)、类方法(由@classmethod装饰的方法),可以被类或类的实例对象调用。
实例方法,第一个参数必须要默认传实例对象,一般习惯用self。
静态方法,参数没有要求。
类方法,第一个参数必须要默认传类,一般习惯用cls
Privite Members 私有成员,外界无法访问
设为私有的方法,就是在属性前加两条下划线
1 | class TagCloud: |
但是我们还是有方法获取到类内的属性
1 | class TagCloud: |
magic function
1 | class Point: |
魔术方法中的比较函数
1 | class Point: |
魔术方法中的运算函数
1 | class Point: |
1 | class TagCloud: |
property
property() 函数的作用是在新式类中返回属性值。
在绑定属性时,如果我们直接把属性暴露出去,虽然写起来很简单,但是,没办法检查参数,导致可以把成绩随便改。这显然不合逻辑,为了限制score的范围,可以通过一个set_score()方法来设置成绩,再通过一个get_score()来获取成绩,这样,在set_score()方法里,就可以检查参数:
class property( fget , fset , fdel , doc )
参数:
- fget — 获取属性值的函数
- fset — 设置属性值的函数
- fdel — 删除属性值函数
- doc — 属性描述信息
1 | class Product: |
但这样,类外还是能访问到我们的get_price,set_price方法,那么如果我们要在类外无法访问这两个方法,就要用到@property
@property修饰符
有没有既检查参数,又可以用类似属性这样简单的方式来访问类的变量呢,当然有
还记得装饰器可以给函数动态加上功能吗,对于类的方法,装饰器一样起作用,python内置的property装饰器就是负责把一个方法变成属性调用的
将 property 函数用作装饰器可以很方便的创建只读属性:
1 | class Product: |
@property的实现比较复杂,我们先考察如何使用,把一个getter方法变成属性,只需要加上@property就可以了,此时,@property本身又创建了另一个装饰器@price.setter,负责把一个setter方法变成属性赋值,于是,我们就拥有一个可控的属性操作
注意到这个神奇的@property,我们在对实例属性操作的时候,就知道该属性很可能不是直接暴露的,而是通过getter和setter方法来实现的
还可以定义只读属性,只定义getter方法,不定义setter方法就是一个只读属性,这时候再尝试修改,就会报错了
继承
在字类的括号中写父类即可
1 | class Mammal: |
和其他语言的类一样,可以自己添加功能,类的属性
Object对象
所有的类都继承于Object对象。而且继承了Object对象中的magic function
1 | class Animal(object):# 这里写不写(Object)都是可以的 |
和js中差不多,Object是总类,Animal继承 Object ,Mammal继承Animal
super().__int__()
当需要继承父类构造函数中的内容,且子类需要在父类的基础上补充时,使用super().__init__()方法
1 | class Animal(object): # 这里写不写(Object)都是可以的 |
Multi-level inheritance
多级继承会增加复杂度,还会继承意想不到的方法
1 | class Animal: |
Multiple inheritance
一个子类继承多个父类
1 | class Employee: |
A Good Example of inheritance
1 | class InvalidOperationError(Exception): |
多态
Abstract Base Classes
由于python 没有抽象类、接口的概念,所以要实现这种功能得abc.py 这个类库
@abstractmethod:抽象方法,含abstractmethod方法的类不能实例化,继承了含abstractmethod方法的子类必须复写所有abstractmethod装饰的方法,未被装饰的可以不重写
实例化抽象类,会报错
1 | from abc import ABC,abstractmethod |
实现多态
就是自类对父类函数的重写,从而让一个函数是现在不同类中的不同功能
1 | from abc import ABC,abstractmethod |
python中的鸭式辩型
- 像鸭子一样走路,有用并且嘎嘎叫的鸟就是鸭子
- 哪怕并不是从鸭子类的原型对象继承而来,但认为这个对象是鸭子
所以向上面的draw(controls)函数,他并不要求输入的对象是从哪个类实例化出来的。也并不要求这个类是从哪个基类继承的这个draw()方法,他只要求这个类中有一个draw()函数即可,这就是鸭式辩型。所以说,我们完全可以不写UIcontrol这个虚基类,因为python和JavaScript一样支持鸭式辩型
Data classes:collections模块的namedtuple子类
当我们构建一个Point类实例化出来两个对象的时候,不能直接判断他们是否相等.在C++中,我们需要进行==重载,但是在python中,我们需要用__eq__ 这个magic function或者 Data classes来实现这个功能
1 | class Point: |
当然,data class 的方法更加简单
collections模块的namedtuple子类不仅可以使用item的index访问item,还可以通过item的name进行访问。可以将namedtuple理解为c中的struct结构,其首先将各个item命名,然后对每个item赋予数据。
collections.namedtuple(typename, field_names, \, verbose=False, rename=False, module=None)*
typename:实际上就是你通过namedtuple创建的一个元组的子类的类名,通过这样的方式我们可以初始化各种各样的实例化元组对象。
field_names:类似于字典的key,在这里定义的元组可以通过这样的key去获取里面对应索引位置的元素值,这样的key可以是列表,也可以是用空格、/和逗号这样的分隔符隔开的字符串。
1 | from collections import namedtuple |
学生系统
1 | data = [ |