从-1开始的python爬虫
写在前面
- 这篇长博客主要记录了我跟着一个公开课的内容从-1开始的爬虫经验,为什么是从-1呢,就是说我对python刚刚上手没几天,就开始学爬虫了QAQ
- 假设我们都已经安装了pycharm并配置好了所有库
- 我们要用的库是:pip3 install requests selenium beautifulsoup4 pyquery pymysql pymongo redis flask django jupyter
- 除了pyquery这类的包需要网上下载,其他都用pip3 install 包名解决,但是有时候很慢,有时候失败 ,多试几次8
- 谁能想到,仅仅安装这个包我就装了一个下午???
爬虫原理的讲解
概述
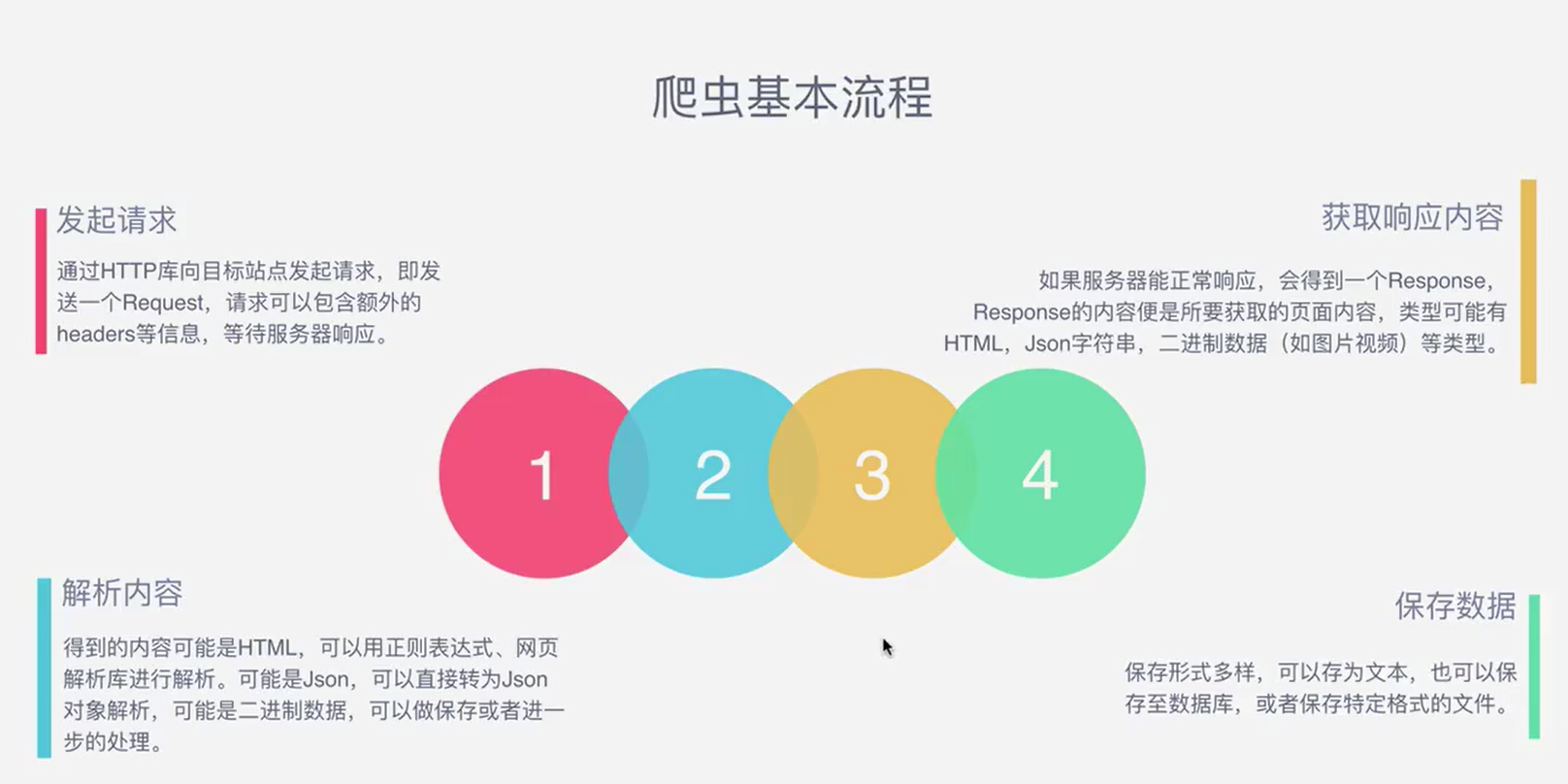
什么是Request和Response?
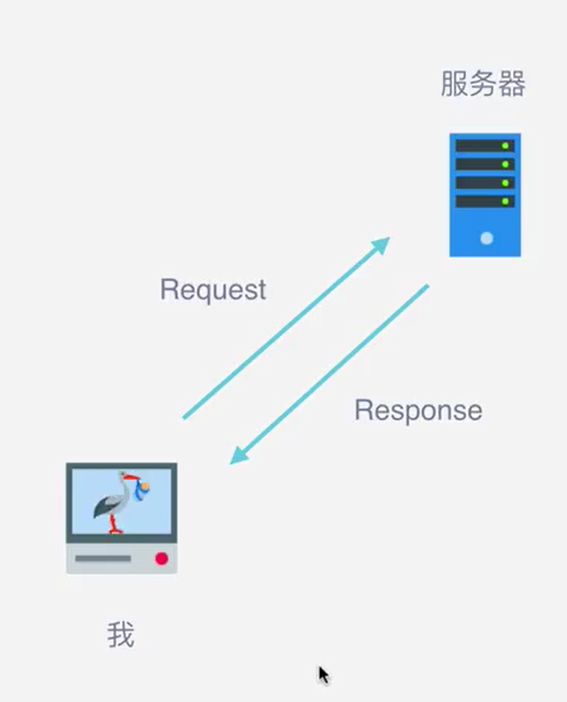
- 浏览器就发送消息给该网址所在的服务器,这个过程叫做HTTP Request
- 服务器收到浏览器发送的消息后,能够根据浏览器发送的内容做相应处理,然后把消息回传给浏览器。这个过程叫做HTTP Response
Request包含哪些方法?
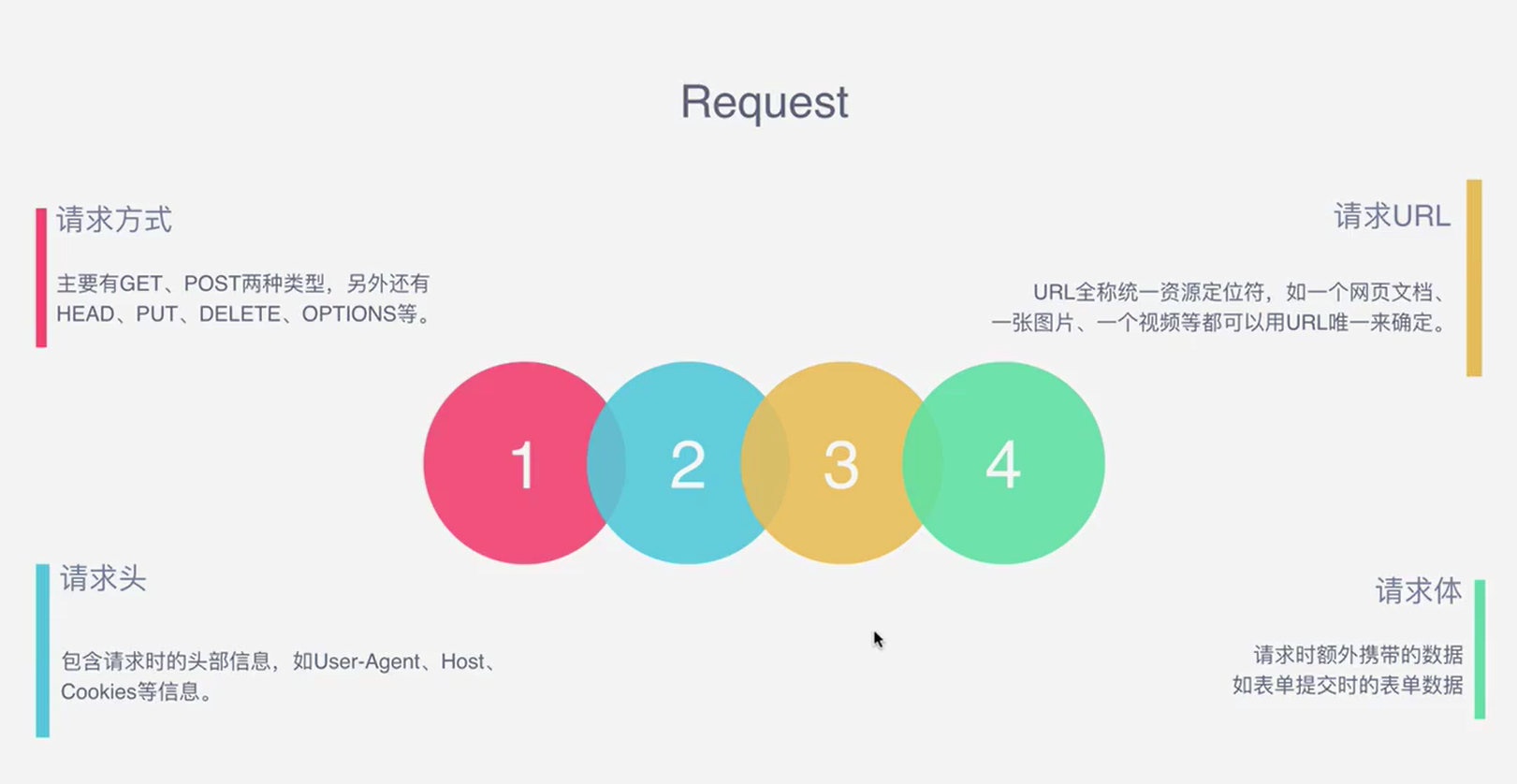
Response

1 | import requests |
- 这三行代码就是我向百度发送了一个请求,然后把response返回给我们命名的response
然后打印出网页源代码
注意,这样的请求不能请求知乎这样的网站
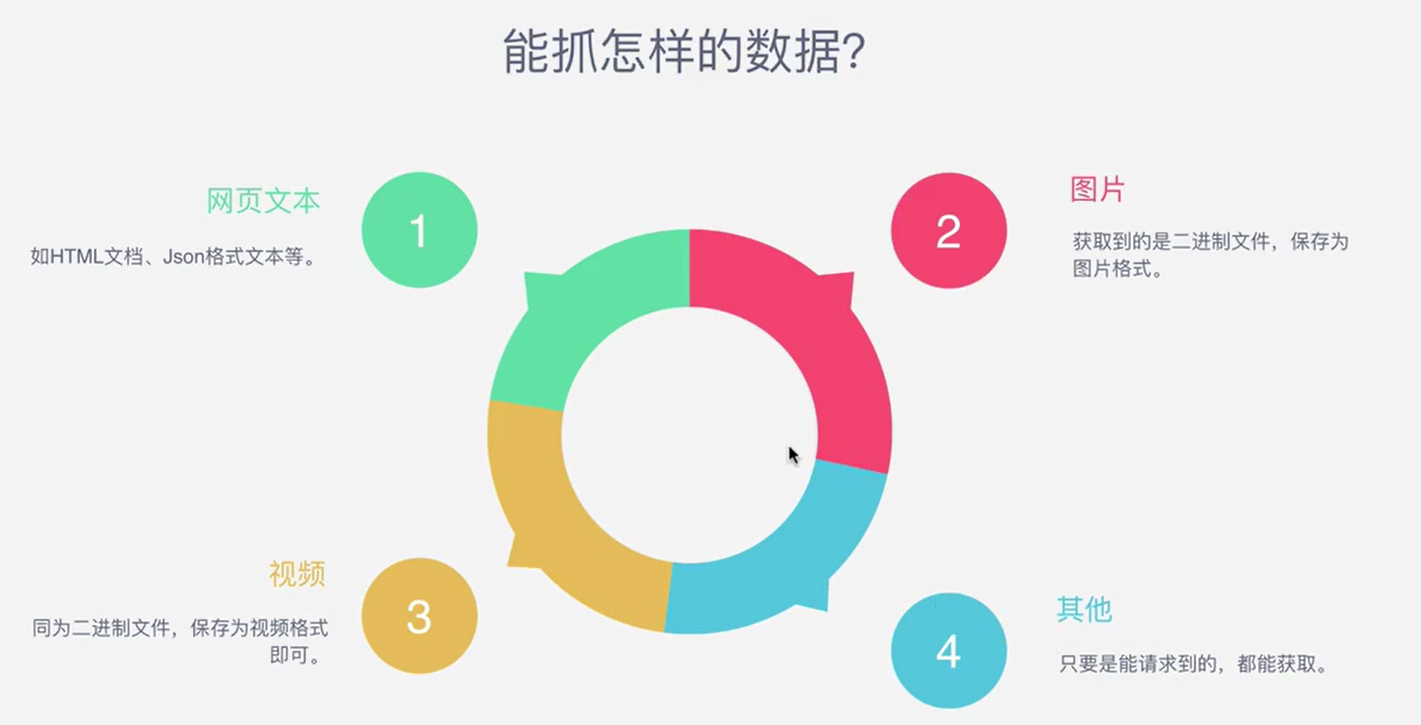
能抓取怎样的数据
解析方式

- request请求只会请求第一个html网页,而不会加载后面的Js文件,但是我们在dev-tool的Elements中看到的源代码是已经经过js渲染过后的,体量很大,行数很多,和一开始拿到的源代码完全不一样
那么,如何解决JavaScript渲染的问题

- 我们在python中引入了selenium库
1 | import selenium |
效果如下
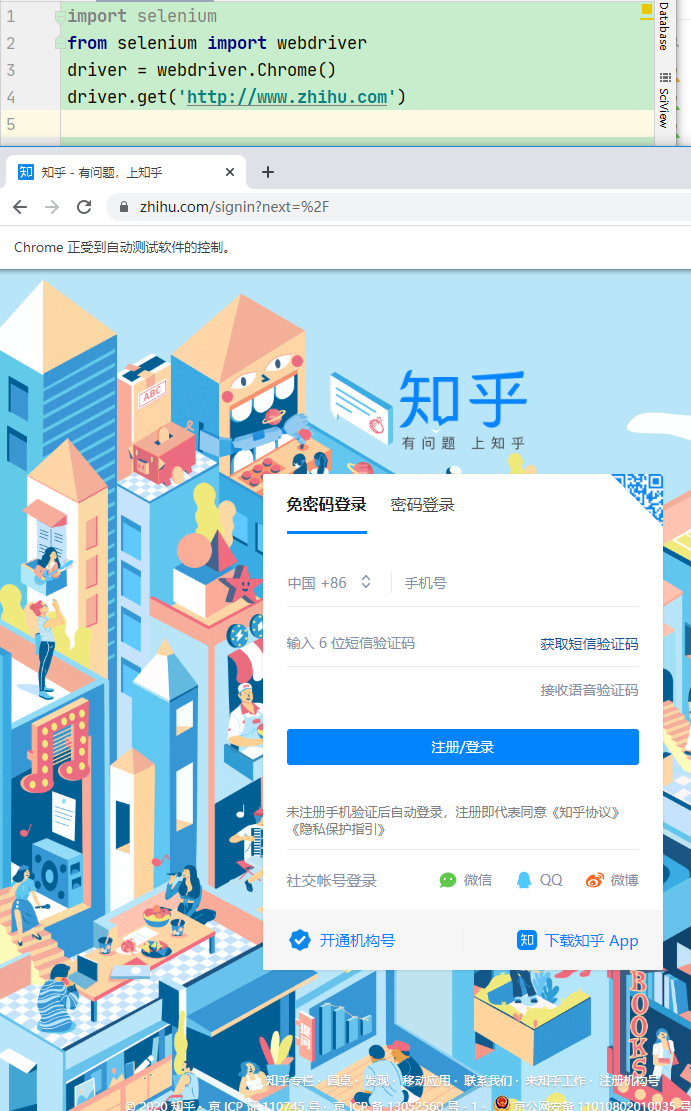
用库不能获得js渲染后的源代码,但是driver.page_source 可以
如何存储文件

Urllib 库的基本使用
使用方法
https://www.cnblogs.com/Caiyundo/p/12448948.html
urlopen
get 类型请求
返回源代码的所有内容,完成了爬虫的第一步,就是把网页给请求下来了
1 | import urllib.request |
post类型请求,加了data就是以post方式
1 | import urllib.request |

timeout 参数:超时就报错,否则就返回
1 | import urllib.request |

调用urllib.error判断原因
1 | import urllib.request |
Response
响应类型
1 | import urllib.request |
状态码,响应头
1 | import urllib.request |
read方法,返回响应的内容
- 就是网页的源代码(js渲染之后)

1 | import urllib.request |
Request
发送request对象 获得response的内容
1 | import urllib.request |
加入headers的参数
1 | from urllib import request,parse |
下面是返回的内容
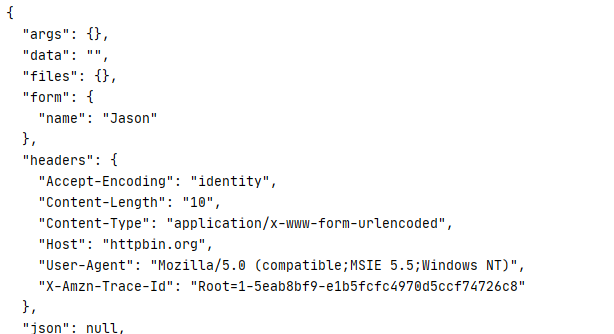
通过add_headers传入参数
1 | from urllib import request,parse |
内容和上图一样
Handler
handler就是辅助的工具,用来做更高级的操作
代理
1 | import urllib.request |
- 传回来一堆东西,就是百度的源代码

- 如果换成httpbin.org,会返回一个ip地址
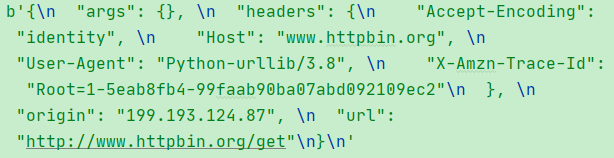
稍做查询,我们可以知道这个199.193.124.87来自美国加利福尼亚洛杉矶
使用代理ip地址,可以伪装自己的ip地址,并保持切换,这样服务器就不会屏蔽我们这个爬虫
Coockie
cookie 是保存用户信息的文件,在爬虫中可以用来维持用户登陆状态。在dev-tools中清楚coockie,再次刷新浏览器,就需要重新登陆了
利用cookie可以爬取一些需要认证的网页
1 | import http.cookiejar,urllib.request |
- 如果cookie没有失效,那么可以一直使用这个cookie维持登录状态
利用MozillaCookieJar保存我们的cookie文件
1 | import http.cookiejar,urllib.request |
运行之后,文件夹里多出了一个cookie.txt 文件
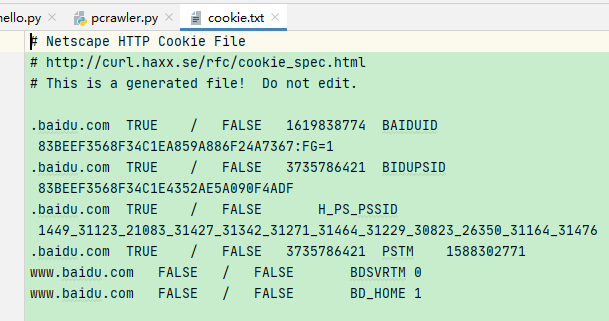
也可以用LWPcookieJar保存我们的cookie,只是格式不同
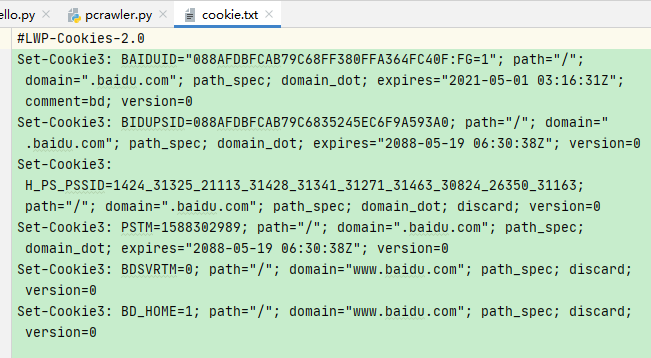
用load方法来把文件中的cookie赋值给新的cookie
1 | import http.cookiejar,urllib.request |
异常处理
URLError
1 | from urllib import request,error |
HTTPError
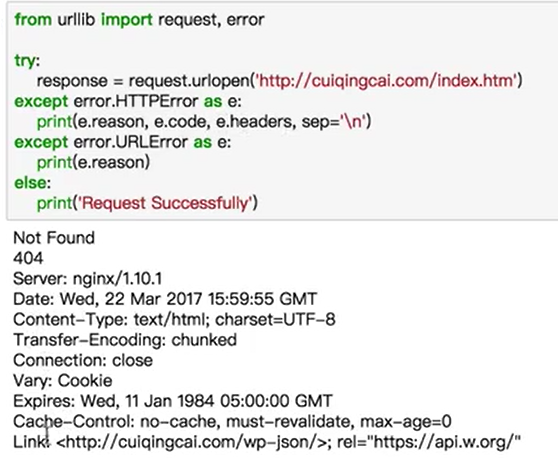
1 | import socket |
URL解析
urlparse
- 把URL拆分成几个标准的部分
1 | from urllib.parse import urlparse |
- 加上协议参数,如果本来就有http开头,那么第二个参数是不会生效的
1 | from urllib.parse import urlparse |
- allow_fragments参数
1 | from urllib.parse import urlparse |
urlunprse
- 拼接url,就是urlparse的反函数
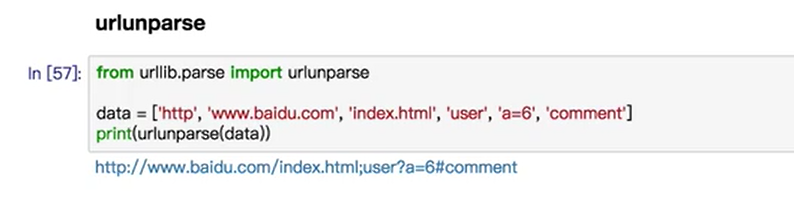
urljoin
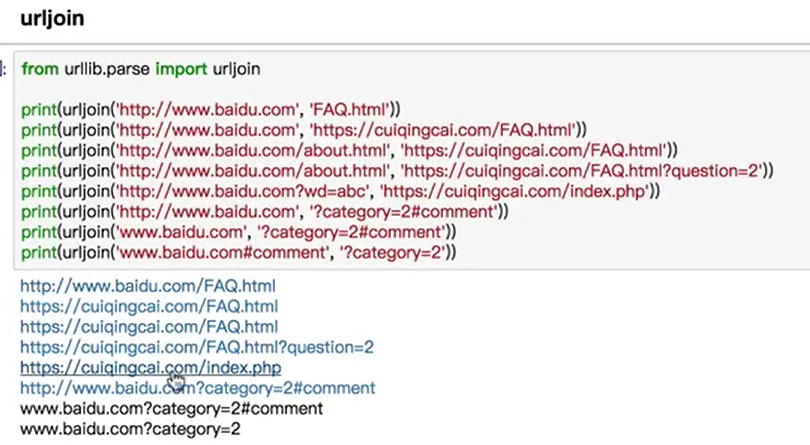
拼接两个字符串,因为一个url可以分成很多部分,如果后面的字符串的部分未出现,前面的来补,后面的出现了,那么以后面的为准
urlencode
把字典对象转换成get请求参数
1 | from urllib.parse import urlencode |
Requests库详解
- requests库的代码量相较于urllib更为简单,而且是基于urllib3编写的库。所以在写爬虫代码的时候建议用Requests库
实例引入
1 | import requests |
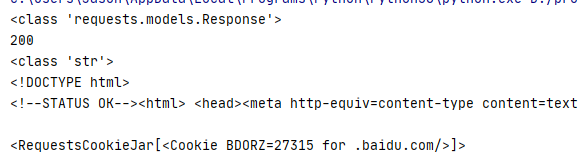
各种请求方式
1 | import requests |
基本get请求
基本写法
1 | import requests |
带参数的Get请求
原来这么写
1 | import requests |
现在这么写
1 | import requests |
- 返回内容都是一样的。但是后面的更加直观易懂,不需要自己编码
解析json
1 | import requests |

- response.json()相当于json库中的json.loads(response.txt)的用法
获取二进制数据
1 | import requests |
保存数据
1 | import requests |
- 我们看到图片就这样被下载了

添加headers
1 | import requests |
不加headers,会被某些网站ban掉
- 添加了headers后,好起来了
1 | import requests |
基本post请求
可以非常方便的传入一个字典,在urllib还要转码,配置,比较繁琐
1 | import requests |
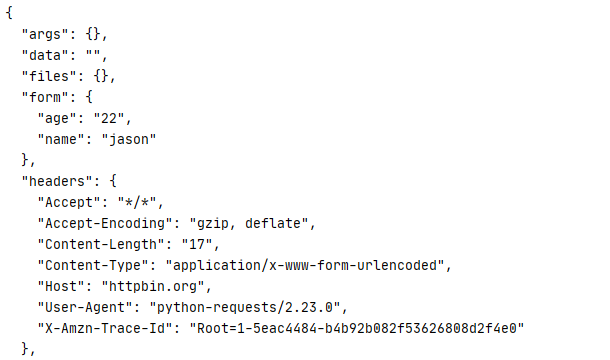
- 加入一个headers
1 | import requests |
响应
response属性
1 | import requests |
状态码判断
1 | import requests |

高级操作
文件上传
1 | import requests |
获取cookie
不用像urllib一样,用一个cookiejar然后再用handler获取cookie了
1 | import requests |
会话维持
模拟登陆
1 | import requests |
证书验证
- 如果要访问的网站的证书是不合法的,就会抛出一个错误,要避免这个错误就要设定一个verify参数
1 | import requests |
1 | import requests |
代理设置
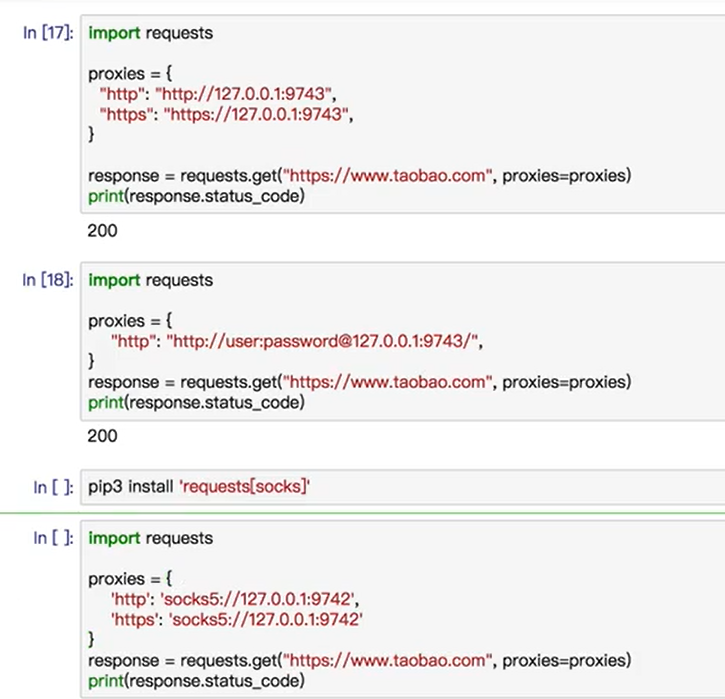
第一种是普通的,第二种是需要密码的,第三种是用socks代理的,需要pip一下socks包
超时设置
1 | import requests |
认证设置
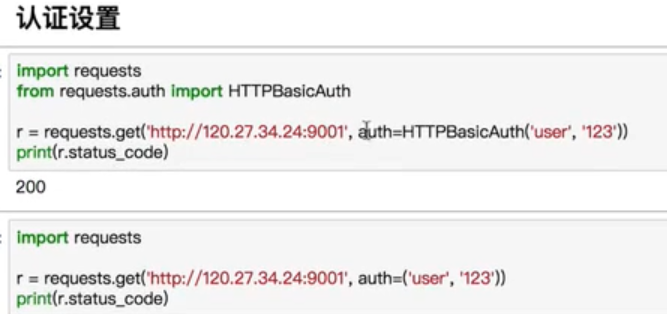
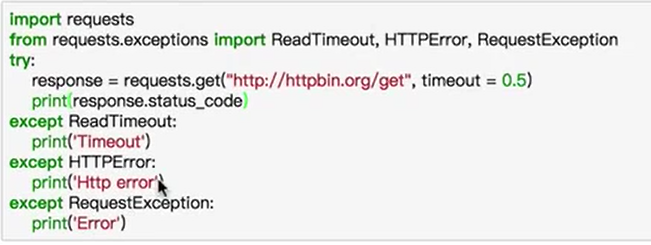
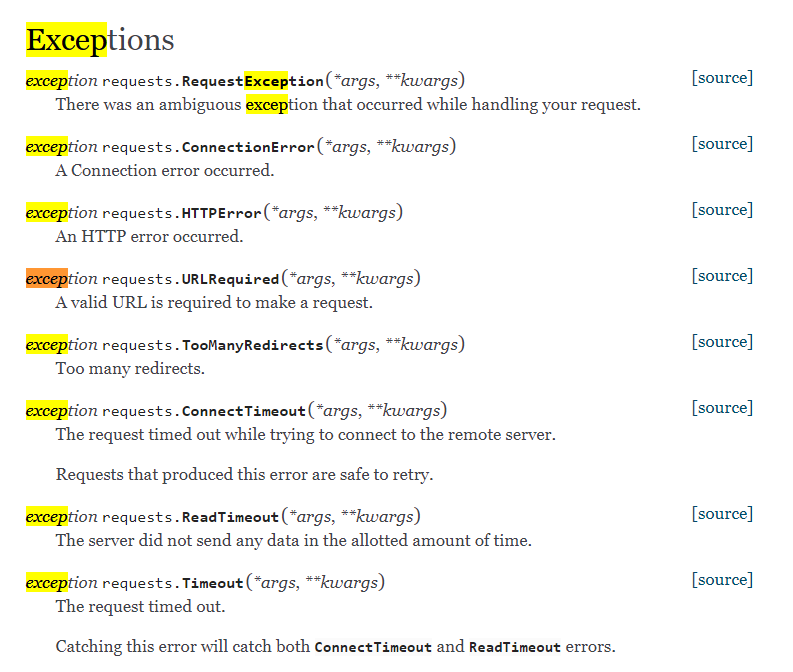
异常处理
BeautifulSoup 的基本用法
- 灵活又方便的网页解析库,处理高效,支持多种解析器。利用它不用编写正则表达式即可方便地实现网页信息的爬取
解析库
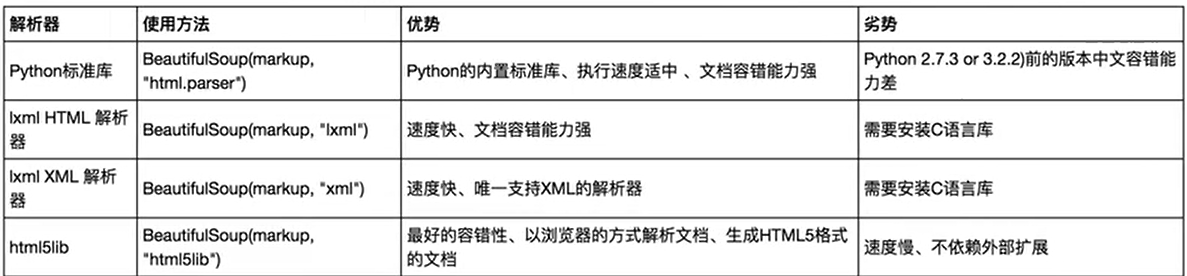
基本使用
1 | html = """ |
- 我们看到这就是结果

- 如果没有title标签,那么就会报错
标签选择器
- 这种选择器的选择速度是非常快的,根据标签的名字来选择
- 但是不能满足我们的一些需求,单纯用标签来选择是远远不够的
选择元素/标签
1 | from bs4 import BeautifulSoup |
- 我们很简单的把知乎的源代码当作html文件,这样我们看到打印出来的内容:

获取名称:返回最外层标签的名称
1 | from bs4 import BeautifulSoup |
获取属性
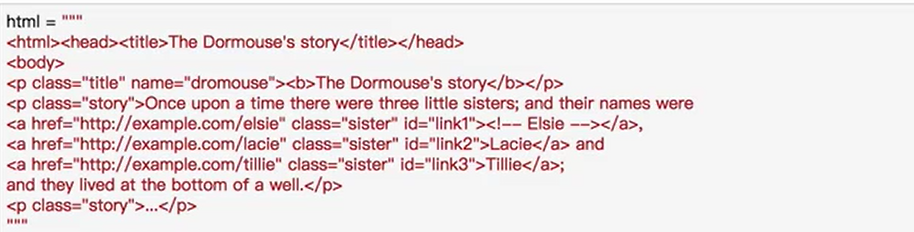
1 | from bs4 import BeautifulSoup |
获取内容
1 | from bs4 import BeautifulSoup |
嵌套选择
1 | from bs4 import BeautifulSoup |
子节点和子孙节点
- 对子节点输出 : child
1 | from bs4 import BeautifulSoup |
- 对所有子孙节点输出: descendants
1 | from bs4 import BeautifulSoup |
父节点和祖先节点
- 对指定标签的父节点进行输出:parent
1 | from bs4 import BeautifulSoup |
- 对指定标签的父节点和祖父节点进行输出:parents
1 | from bs4 import BeautifulSoup |
兄弟节点
- next_siblings 和 previous_siblings
1 | from bs4 import BeautifulSoup |
标准选择器 find 和 find_all
find_all(name,attrs,recursive,text,**kwargs)
name
- 这里是找标签为ul的代码,并且返回一个迭代器
1 | from bs4 import BeautifulSoup |
- 先把每一个ul拿出来,再嵌套一层遍历
1 | from bs4 import BeautifulSoup |
attrs
- 传入一个字典,键名是属性名,键值是属性值
1 | from bs4 import BeautifulSoup |
- 直接用等于会更加方便,也不会用到attrs了
- class比较特殊,需要用class_
1 | from bs4 import BeautifulSoup |
text
- 对文本的内容进行选择
1 | from bs4 import BeautifulSoup |
find(name,attrs,recursive,text,**kwargs)
find返回单个元素,find_all 返回所有元素
find_parents() 和find_parents()
- 前者返回所有祖先节点,后者返回父节点
- find_previous_siblings()和find_previous_sibling ()
- 前者返回所有的前面的兄弟节点,后者只返回前面的第一个兄弟节点
- find_next_siblings()和find_next_sibling ()
- 前者返回所有的后面的兄弟节点,后者只返回后面的第一个兄弟节点
- find_all_next{} 和 find_next()
- 前者返回节点后所有符合条件的节点,后面返回第一个符合条件的节点
- find_all_previous{}和find_previous()
- 同理
css 选择器 select()
- 通过select()直接传入CSS选择器即可完成选择
1 | from bs4 import BeautifulSoup |
- 层层迭代
1 | from bs4 import BeautifulSoup |
获取属性
1 | from bs4 import BeautifulSoup |
获取内容
- 把所有指定的标签中的内容进行输出
1 | from bs4 import BeautifulSoup |
总结
- 推荐使用lxml解析库,必要时使用html.parser
- 标签选择筛选功能弱但是速度快
- 建议使用find()或者find_all()来匹配结果
- 如果对CSS选择器熟悉用 select()
- 记住常用的获取属性和文本值的方法
pyquery 的基本用法
- 强大灵活的网页解析库。熟悉jQuery的语法乐意选择PyQuery
Selenium的基本用法
自动化测试工具,支持多种浏览器,爬虫中主要用来解决JavaScript渲染的问题
当urllib,requests无法获得渲染之后的源代码的时候,selenium可以派上用场
基本用法
1 | from selenium import webdriver |
声明浏览器对象
1 | from selenium import webdriver |
访问页面
1 | from selenium import webdriver |
查找元素
单个元素。find_element
- 找到输入框,输入信息。找到一些按钮,进行一些操作等等
1 | from selenium import webdriver |
可以看到这三种查询结果是一样的

- 常见的查找方式
1 | browser.find_element_by_xpath() |
- 通用查找方式
1 | from selenium import webdriver |
多个元素 find_elements
1 | from selenium import webdriver |
- 搜索的就是淘宝网的一些分类
- 通用查找方式
1 | from selenium import webdriver |
元素交互操作
- 对获取的元素调用交互方法
1 | from selenium import webdriver |
交互动作
- 把动作附加到动作链中串行执行

执行JavaScript
- 有些动作没有分装成api,所以我们传入JavaScript语句实现这个动作
1 | from selenium import webdriver |
获取元素信息
获取属性
1 | from selenium import webdriver |
获取文本值
1 | from selenium import webdriver |
获取ID,位置,标签名,大小
1 | from selenium import webdriver |
Frame
- 在父级frame中查找子级内容,必须实现frame切换
1 | from selenium import webdriver |

等待
隐式等待
- 当使用了隐式等待执行测试的时候,如果WebDriver没有在Dom中找到元素,将继续等待,超出设定时间后抛出找不到元素的异常,换句话说,当查找元素或元素并没有立即出现的时候,隐式等待将等待一段时间再查找DOM,默认时间为0
1 | from selenium import webdriver |
显示等待
- 指定一个等待条件
- 指定一个最长等待时间
- 如果在等待时间内符合等待条件,那么继续等待,等待到超出等待时间为止

下面是我们的等待条件,非常灵活可变
前进后退
1 | from selenium import webdriver |
Cookies
1 | from selenium import webdriver |
- 我们看到第二次打印的时候我们加上去的cookie已经出现了

选项卡(窗口)管理
- 通过执行一个js代码,打开一个新窗口
1 | import time |
异常处理
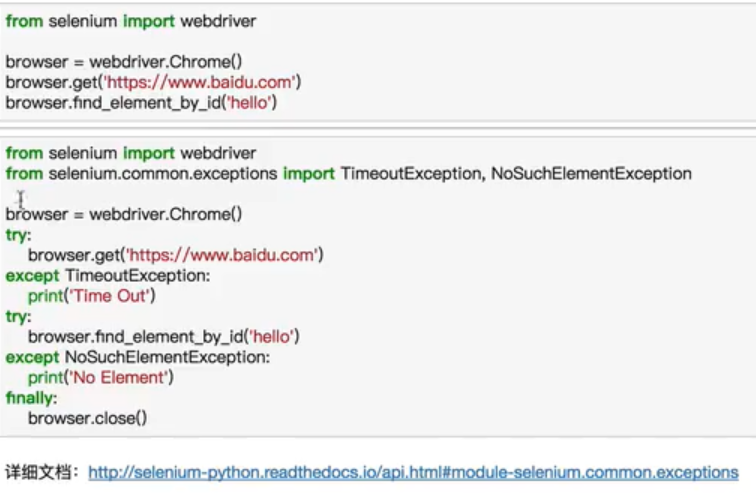
用Requests+正则表达式爬取猫眼电影Top100
- 流程框架
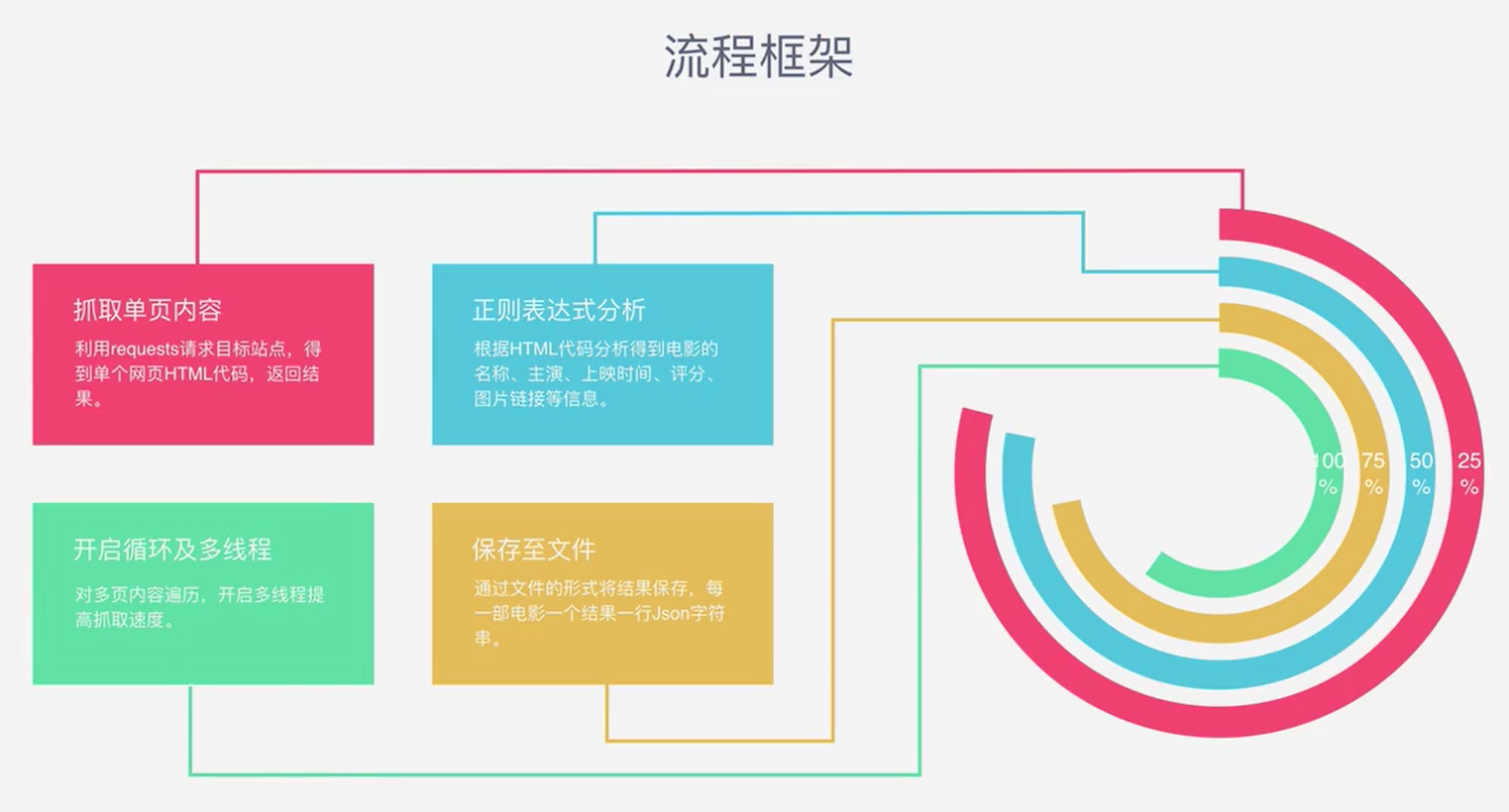
源码一览
1 | import re |
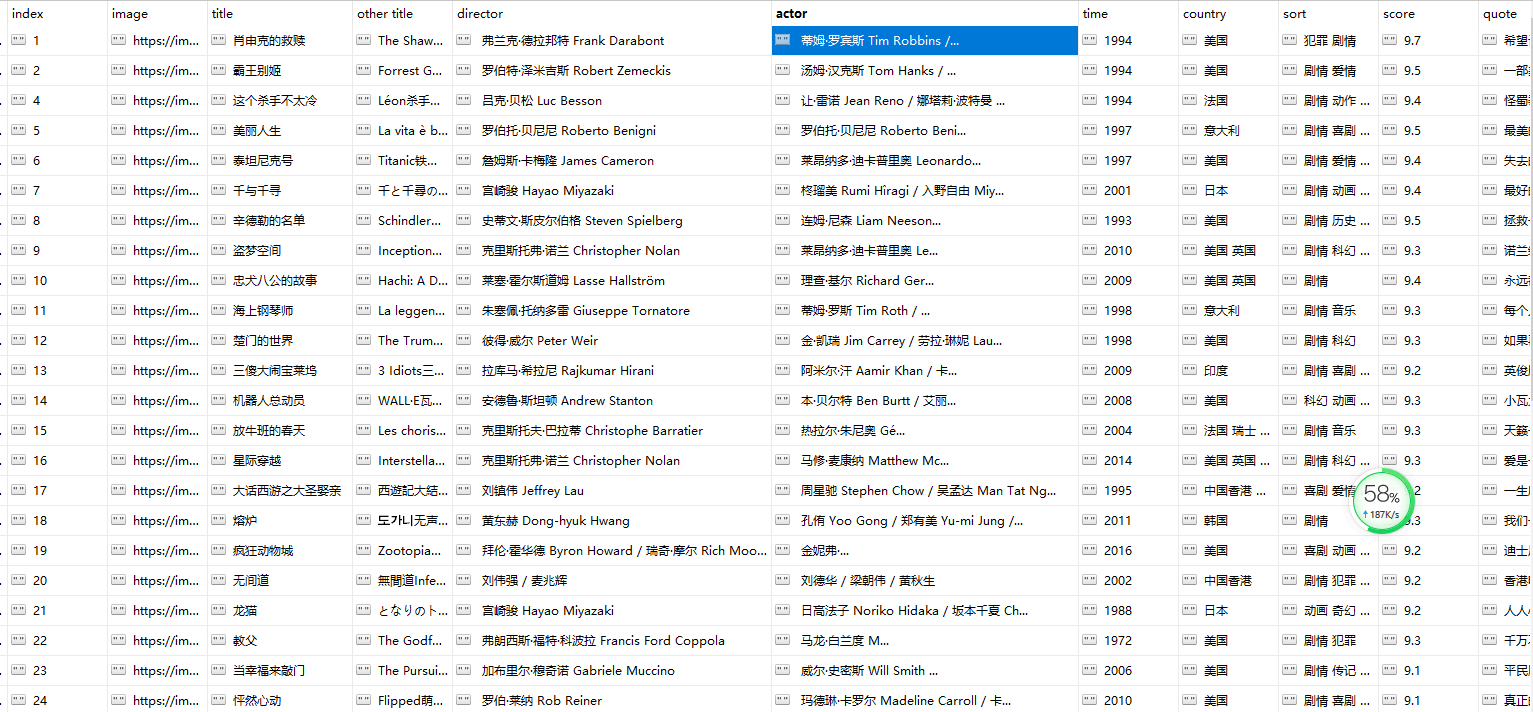
成果展示

分步解析
第一步:获取网页源代码
1 | import requests |
第二步:对目标信息编写正则表达式
- 我们可以看到,我们得信息源如下

括号括起来的内容,就是我们想要的结果
1 | <dd> 获取到标签 <dd> |
1 | def parse_one_page(html): |
- 把他们变成字典形式
1 | def parse_one_page(html): |
这一步的代码
1 | import re #即regular expression |
效果如图

第三步,把他们写入到我的文件中
1 | # 把我们的item写入 一个txt文件 |
加入这个函数后,效果如图

第四步,通过字符串改造的方式爬取10页
1 | # 最后用一个字符串叠加的方式,抓取1-10页的所有内容 |
番外,利用多线程实现秒爬(但是这样Top100顺序就乱了)
- 开头引入
1 | from multiprocessing import Pool |
- 对结尾进行改造
1 | if __name__ == '__main__': |
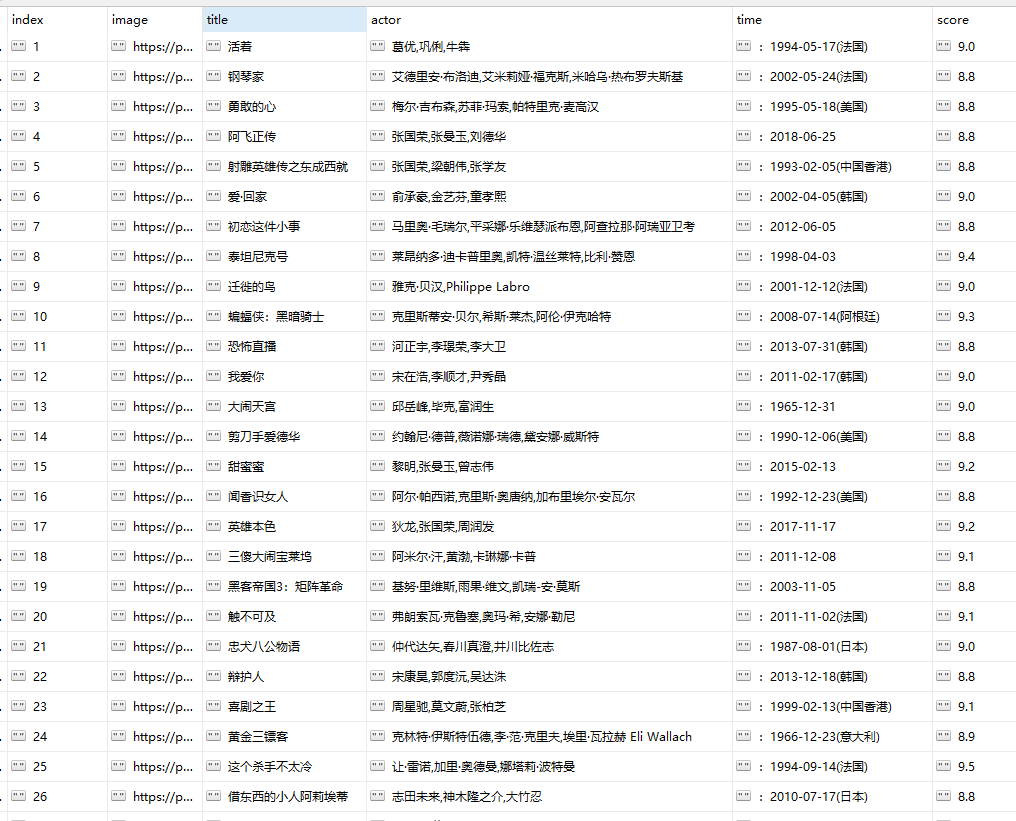
如法炮制,我也制作了一个爬取豆瓣top250的电影
1 | import re |
- 结果如下

用selenium + Chrome 爬取淘宝宝贝信息
所用工具: selenium包,Chrome.driver无头浏览器,pymongo+MongoDB数据库
源码一览
1 | import re |
成果展示
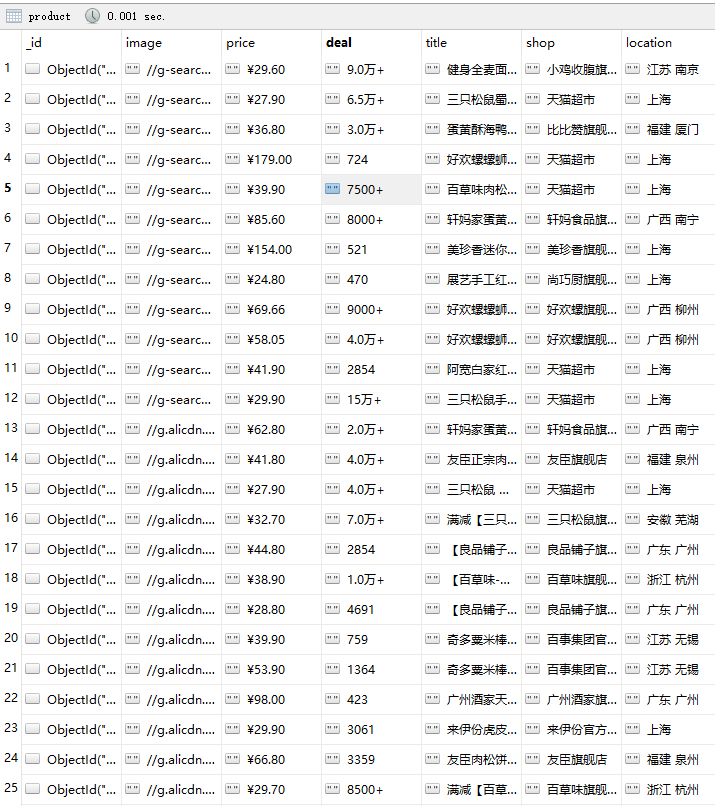
分步解析
搜索关键字
- 我们这一步的目的就是模拟搜索关键字的操作
- 找到搜索框
- 点击搜索
- 我们需要判断浏览器是否已经达到了我们想要的操作,要实现这一点,selenium中的wait模块可以解决Selenium官方文档
1 | from selenium import webdriver |
在我们的代码中,需要改一下
1 | wait = WebDriverWait(browser, 20) |
- 在main函数中的操作
1 | def main(): |
分析页码并翻页

我们可以看到,要实现这个翻页,一页一页按那个高亮按钮不太实际(每一个按钮的标签可能都不一样),所以我们在搜索框中输入第几页,然后点击确定后,再做一个判断即可完成
- 所以我们首先要拿到第几页这个输入框,然后拿到旁边的确定按钮,最后传入数字点击确认
1 | def next_page(page_number): |
分析提取商品内容
1 | def get_products(): |
- 写完get_products操作以后,需要在一开始的search函数中调用一下(因为next_page(page_number)是从第二页开始的,所以要获取第一页的宝贝信息
- 此外在next_page 这个函数中也要调用,来获得2-100页的所有宝贝信息
存储到MongoDB
新建一个config文件,存储一些连接到MongoDB的基本信息
1 | # 账户时localhost |
- 在开头设置一下配置信息
1 | import pymongo |
- 写一个写入函数
1 | def save_to_mongo(result): |
- 然后再get_product函数的item遍历中调用,把每条宝贝信息传入数据库
总结与反思
虽然是照着视频一步一步写下来的,但是中间仍然出现了很多错误和困难
淘宝网现在出了反爬虫机制,如果爬的太快我们就会受到永远都通不过的滑块验证码,这是因为淘宝检测出了你使用的webdriver,我在晚上爬取一次后换个关键词,也仍然解决不了问题(看来有冷却时间)第二天又运行一遍后才回复正常。不过我们写爬虫只是练手,并不要求高效率。所以我把等待时间调整为每次爬取一页停留十秒,这样在第一次爬取的时候可以轻松爬完100页。(再试一次就又有问题了)
通过这个爬虫经历学会了如何把数据存储到MongoDB中,这样稍作修改,那么我先前爬取的豆瓣电影和猫眼电影都可以通过这种方式存储了
这是两张电影排行表的最终效果
有话要说
python爬虫的故事到这里还并没有结束,只不过下面开始要进入PySpider框架和Scrapy框架的学习了,所占用的时间和空间过于繁琐,故另起炉灶。