pyspider框架
安装使用pyspider框架遇到的麻烦
- 我的python版本是3.8,但是很显然pyspider的作者根本没想把pyspider与py38兼容,出现了关键字冲突的问题,对于那个人说修改run.py文件中的asnyc关键字,我改了也没luan用。最后装了3.6,真香
- 其次就是他说的WsgiDAV新版本版本和当前不兼容的问题,也是按照他说的降低版本解决了问题
- 昨晚运行的好好的,今天再次运行出现了DNS链接上的问题,难道dns被封了?
- 我换了一个文件夹运行pyspider all,输入一样的代码运行后。问题解决了
最后输入pyspider all,奇迹出现

利用pyspider框架爬取网站
步骤

- 我们这次选的是TripAdvisor网站和美剧天堂网站
步骤1:输入母页面,筛选我们需要的子页面链接
在其实页面,我们会看到很多已经帮我们封装好的函数,其中on_start就是我们要开始的地方
1 |
|
我们把START_URL 换成我们的母网站就行了,这里我们用的是伦敦城市景点
https://www.tripadvisor.cn/Attractions-g186338-Activities-c47-London_England.html
注意
- 如果想看效果,每次修改好以后要用save保存才能run
- 按照上面的方法我们很可能会报错 Exception: HTTP 599: SSL certificate problem: unable to get local issuer certificate.这是证书之类的问题,我们只需要在最后括号前加, validate_cert=False就足够了
- 效果如下
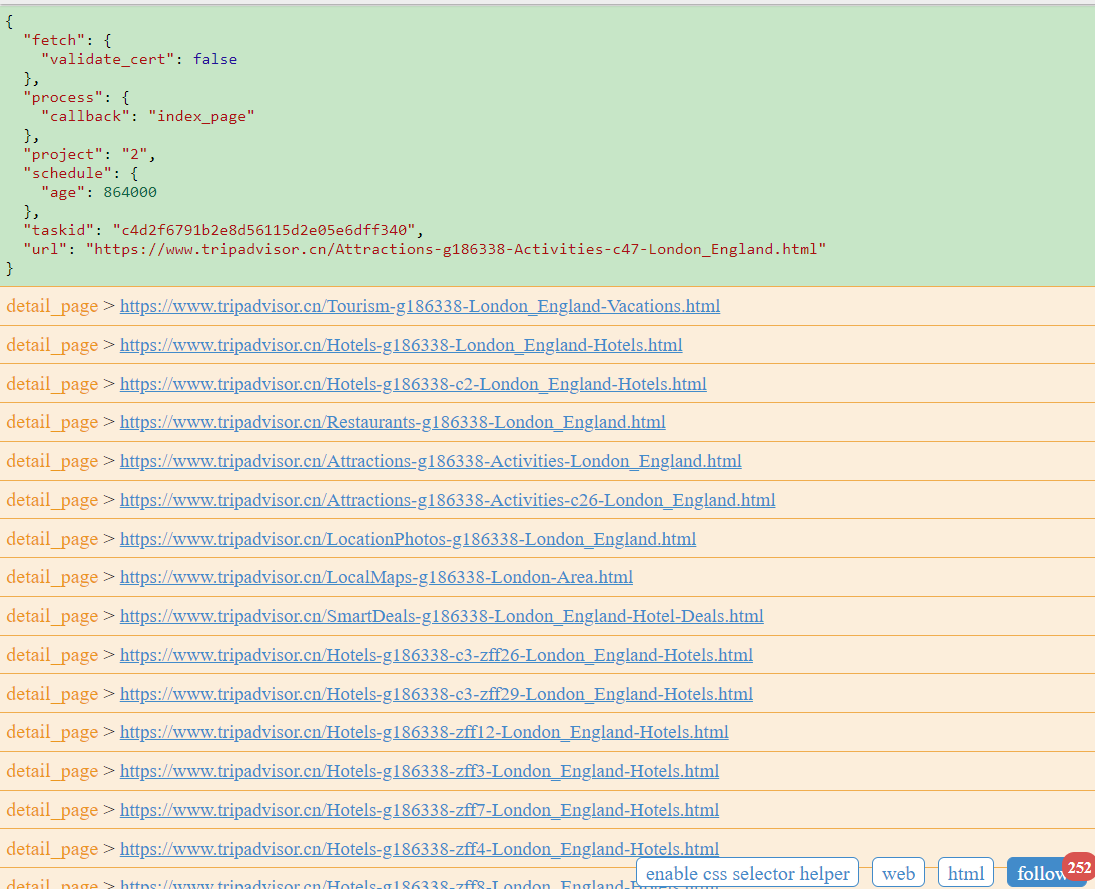
我们可以看到在母网站中一共有252条链接被我们抓取到了,那么能为我所用的子链接有哪些呢?
是这些景点,那么怎么才能获取景点的href呢?
这时候,pyspider框架的css选择器就派上用场了。在代码框中找到下面这块代码。
1
2
3
4
def index_page(self, response):
for each in response.doc('a[href^="http"]').items():
self.crawl(each.attr.href, callback=self.detail_page)
其中在response.doc(‘’)中放入我们目标所需要的css选择器,就可以了。点击网页下方的web,然后就会显示网页内容。在网页下方找到 enable css selector helper,点击我们的目标。。但是好像不灵光。没事,我们直接去网页devTool找


1 | def index_page(self, response): |
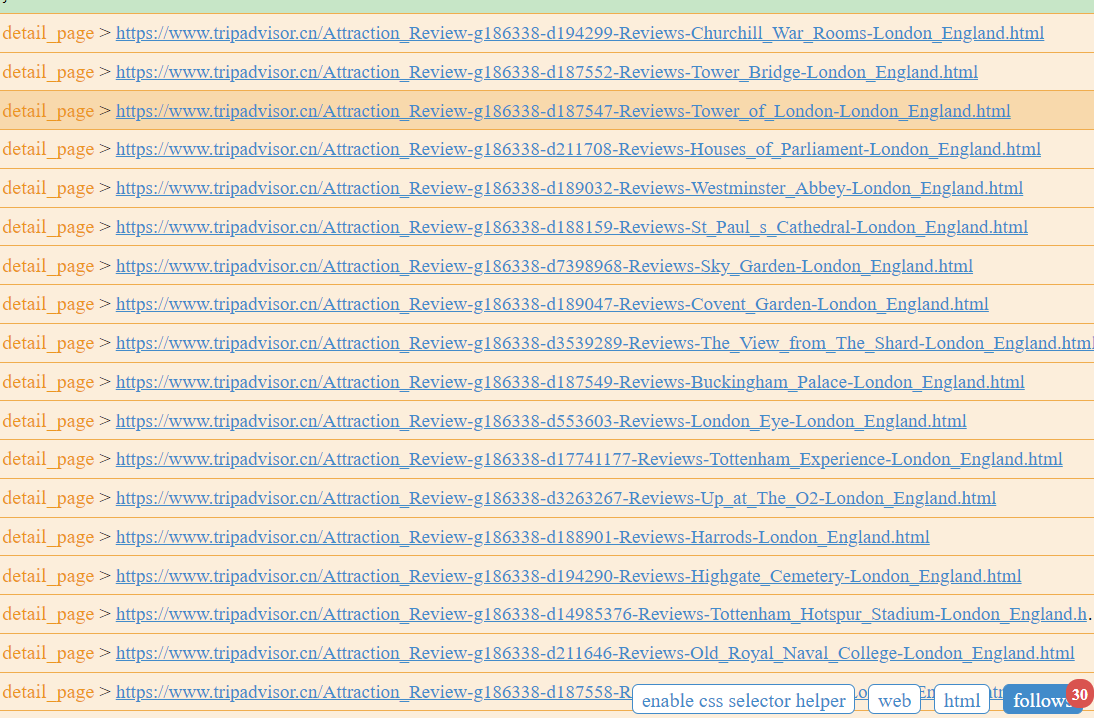
我们看见这样,30个景点的信息就被我们筛选出来了
步骤2:每次读取下一页的链接
我们可以看到在 每一个网页下面都有这样的按钮

我们只要模拟点出下一页按钮,然后爬取下一页的内容就可以了。
这里需要用个递归,这样,下一页就会调用下一页的下一页,直到所有的链接全部被我们读取完为止
要实现这个功能其实很简单。只要在原来的代码上添加下面两行代码即可
1 | #找到我们下一页的按钮所包含的href |

最后我们运行会发现多了一行信息,这其实就是下一页中的内容,点开发现又是31条,子子孙孙无穷尽也……

步骤3:分析子页面,筛选出我们需要的信息
首先我们点入一个子页面
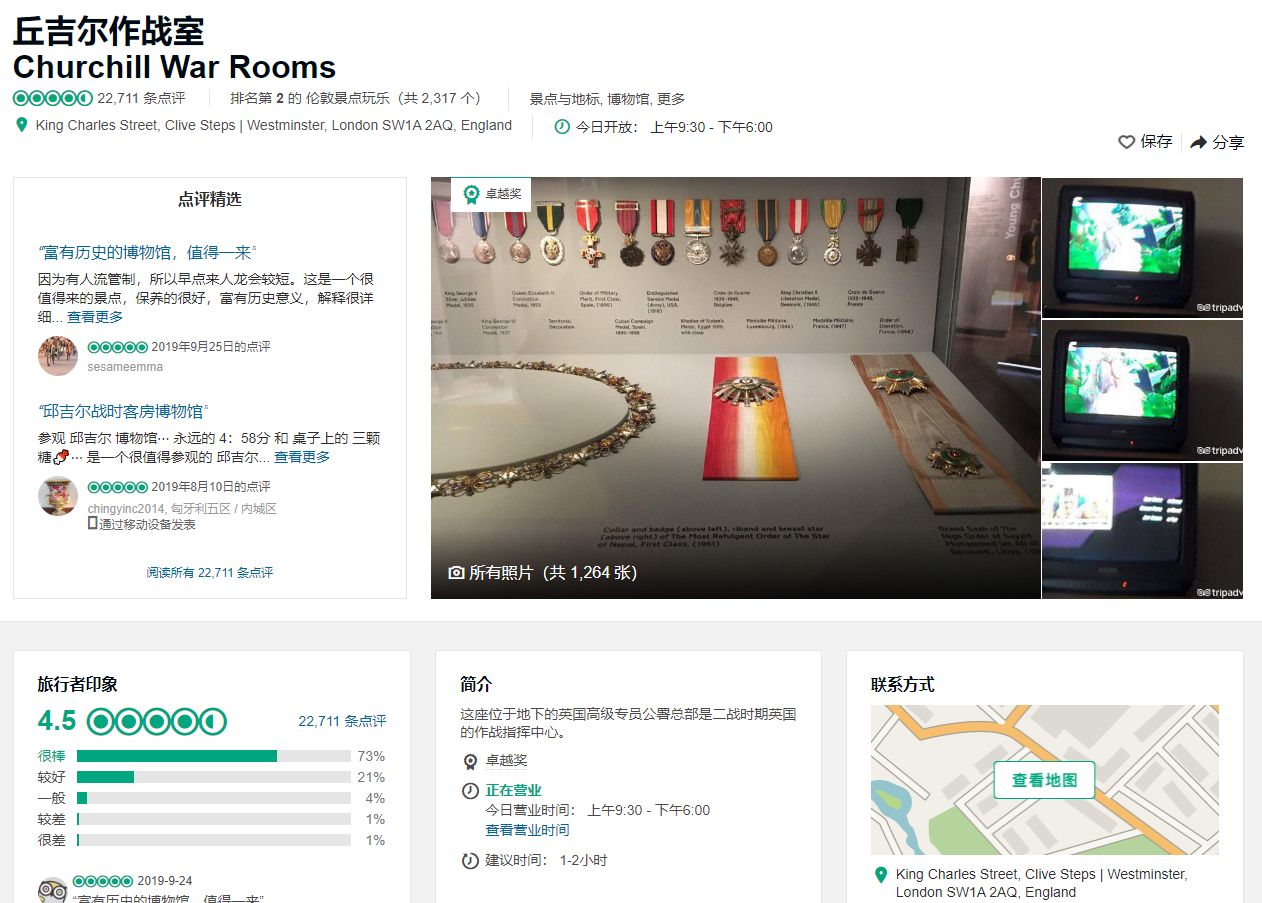
那么很显然,一个旅游景点的信息已经呈现了。我们要爬取的是景点名字,景点排名,评价个数,地址,电话,简介,默认已经爬取了网页的url,那么就留着。
可以选用css选择器,或者在devtool中copy selector完成对目标的检索。把信息都放在 detail_page 当中
1 | @config(priority=2) |
步骤4:save to mongo~
只需要在开始和结尾添加几段链接数据库和保存代码的代码就行了
1 | import pymongo |
1 | def on_result(self, result): |
小插曲
在爬取美剧天堂的时候,发现下一页的按钮好像不是特别灵光,所以用了截取字符串的再拼接的方式成功获得了下一页的信息
1 | next = response.doc('body > div.warp > div.list3_cn_box > div:nth-child(25) > a:nth-child(11)').attr.href |
成果一览
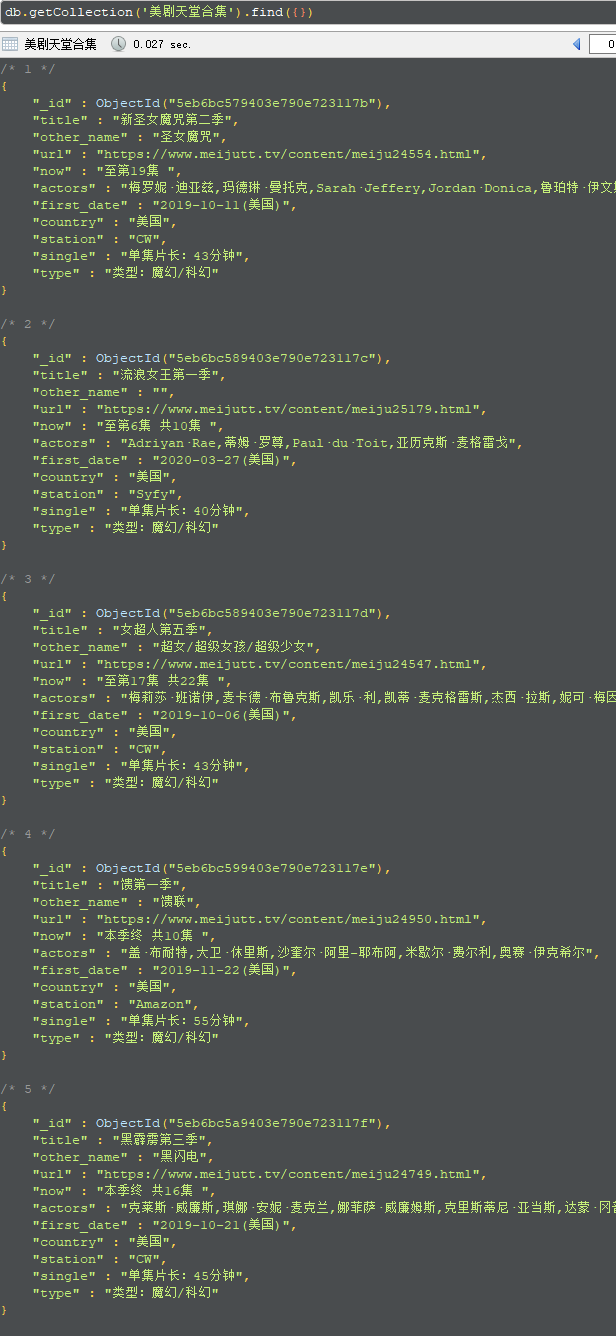
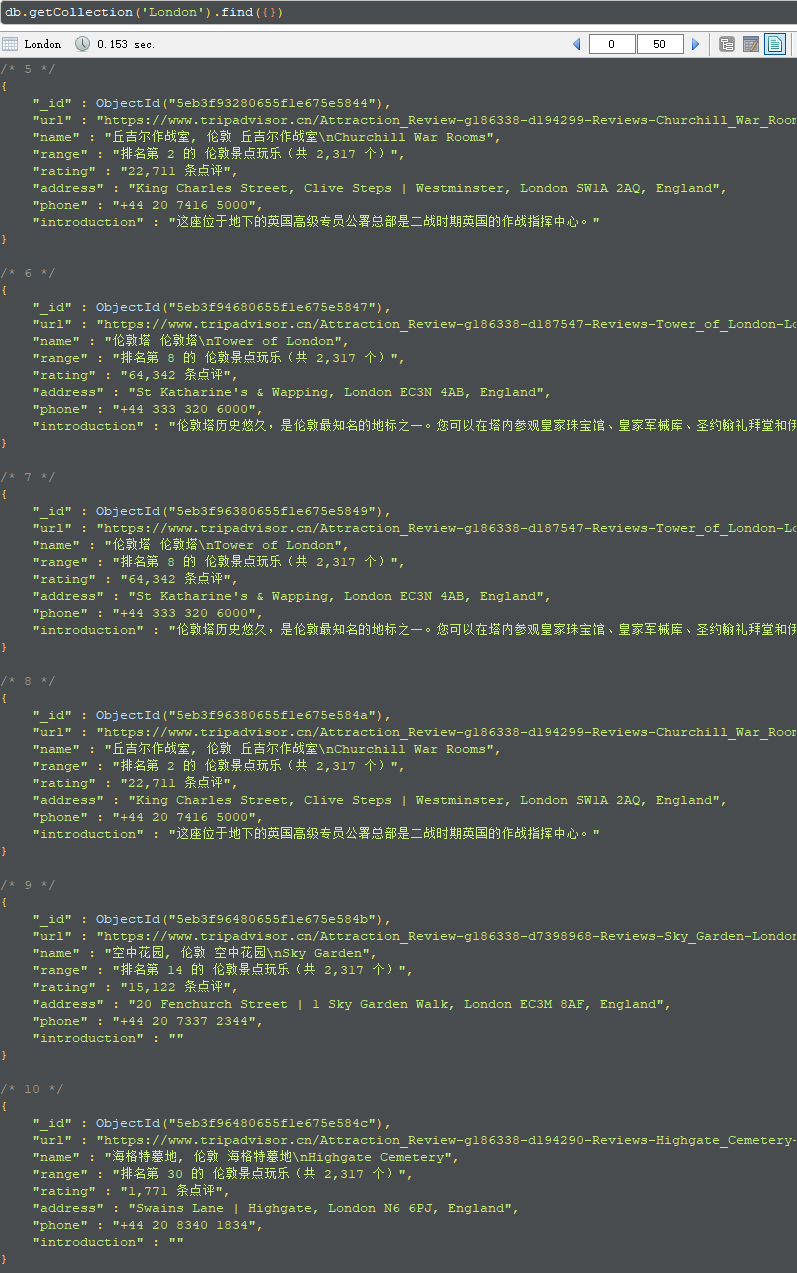
代码一览
TripAdvisor
1 | from pyspider.libs.base_handler import * |
美剧天堂
1 | from pyspider.libs.base_handler import * |