Mysql基础
简介
数据库分为 Relational 和 NoSQL 两种,也就是我们所说的关系型数据库和非关系型数据库。
Mysql是一个关系型数据库,可以通过sql语言进行各种操作。除此之外还有SQL server,Oracle等数据库
MongoDB是一个非关系型数据库,通过 键值对的方式来存储
SQL 的全称是 Structured English Query Language,
SQL语法规则
- sql不区分大小写,但是关键词最好大写
- 每句sql语句必须以分号‘;’结束
- WorkBench 上运行语句的快捷键: CTRL+Shift+ Enter,DataGrip上运行快捷键:Ctrl+Enter
- sql中语句注释,运用 — 或者快捷键 CTRL+/
- 当sql语句太长的时候,可以运用锁紧换行的操作,来让语句更加美观简洁
1 | SELECT |
选择语句
SELECT 语句
1 | SELECT * FROM customers |
查询所有内容,*代表所有的列
1 | SELECT * FROM customers WHERE customer_id = 1 |
加了限制条件, 意思是customers中 customer_id 这列为1 的信息
1 | SELECT * FROM customers ORDER BY first_name; |
这句的意思是信息按照 first_name 的大小进行,排序,如果是字母,那就按照alphabet顺序排列
1 | SELECT first_name, last_name,points,points+10 FROM customers; |
此外还可以对数字列做四则运算的操作
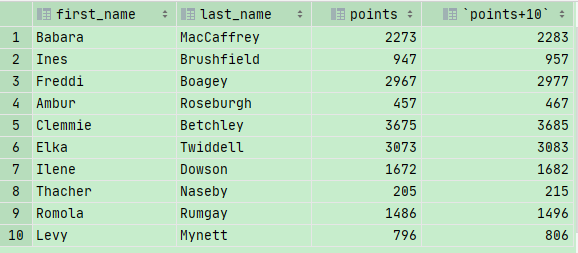
1 | SELECT |
把新操作的列重命名。
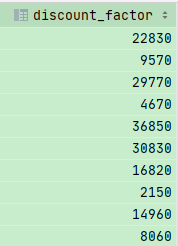
1 | SELECT DISTINCT state FROM customers |
这能让表单内容不重复
小练习:

1 | USE sql_store; |
WHERE语句
where 语句可以用来进一步筛选
1 | SELECT * |
此外还可以用 > ,<,>=,<=,=,!=,<> 其中<>也是不等于的意思
1 | SELECT * |
或者可以让他等于一个字符串
1 | SELECT * |
这是对date类型的列进行比较,这里是筛选在1990-01-01之后出生的信息,注意是之后!
小练习

1 | SELECT * |

利用and,or,not 实现多条件查询
1 | SELECT * |
1 | SELECT * |
上面的是都要满足,下面是择一满足即可
1 | SELECT * |
birth_date>’1990-01-01’ 是一个条件,points >1000 AND state = ‘VA’又是另外一个条件
也可以用()修改逻辑
1 | SELECT * |
当我们用NOT 语句,就是对后面的条件进行否定
小练习

1 | SELECT * |

1 | USE store; |
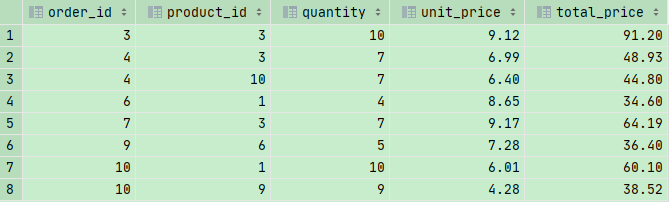
IN 操作符
1 | use store; |
如果我们要通过or语句选择很多信息,但是 不可以用 state = ‘VA’ or ‘GA’ or ‘FL’,那么我们就可以用 IN操作符,在 IN前也可以用 NOT 进行取反操作
1 | use store; |
1 | use store; |
小练习

1 | use store; |

因为没有 quantity_in_stock为72 的信息,所以只显示了2条
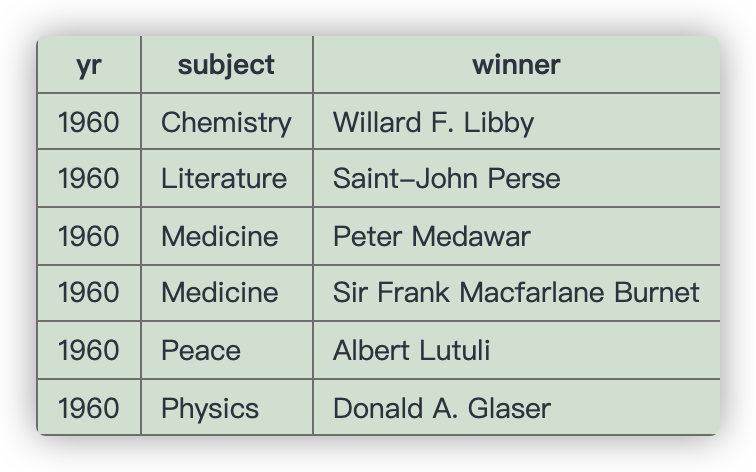
- SQLZOO nobel p14
Show the 1984 winners and subject ordered by subject and winner name; but list Chemistry and Physics last.
表格如下所示,我们要对1984年的得奖者进行筛选,但是要求我们把Chemistry和Physics的获奖者列在最后,这要怎么实现?
这就要依赖与 IN 关键词了,它将符合条件的信息置为1,不符合条件的置为0,比如说:
1 | SELECT winner, subject, subject IN ('Physics','Chemistry') |
结果如下:
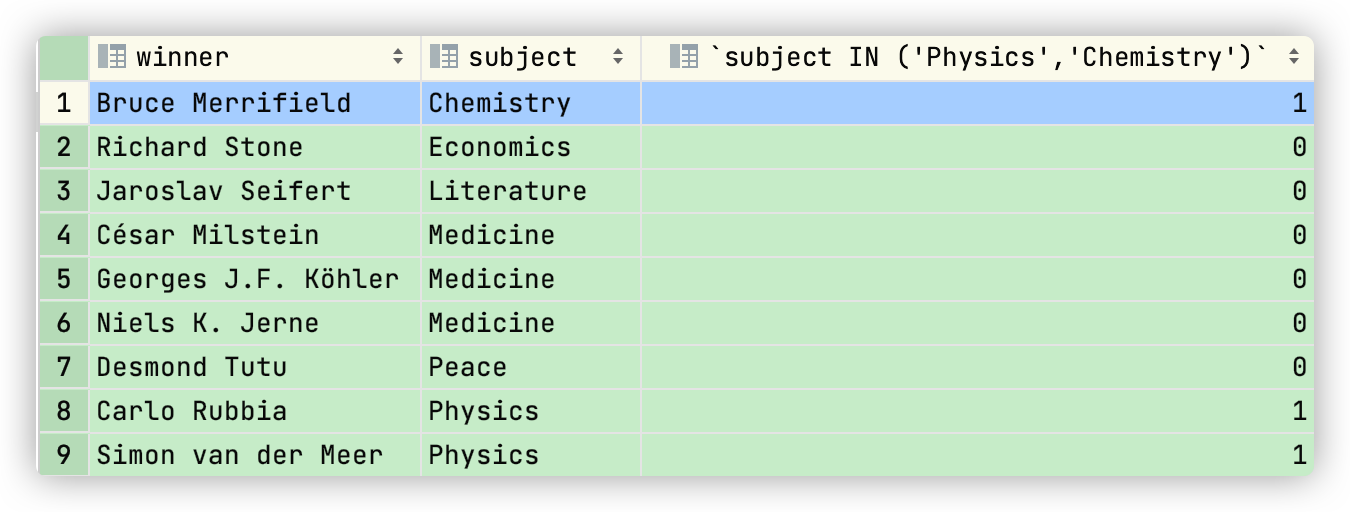
我们就可以根据这0和1来排序
1 | SELECT winner, subject |
按照01排好之后,别忘了题目说还是要按照subject和winner排列,因此最终排序的关键词有三个。
BETWEEN 运算符
当我们要写如下语句时
1 | SELECT * |
我们可以利用BETWEEN 操作符
1 | SELECT * |
注意,BETEWEEN 是大于等于和小于等于
小练习:

1 | SELECT * |

LIKE 运算符
like操作符可以匹配字符串等操作,实现模糊查询
这里的 % 和 _ 被称为 wildcard,也就是”癞子”,可以替代其他字符。
1 | SELECT * |

就可以匹配到姓以大写或小写b开头信息
1 | SELECT * |
这里是匹配第六个字母是y的信息,前面写 5个_ ,匹配随便五个字符
还可以这样,匹配以b开头,以y结尾,长度为6的信息
1 | SELECT * |
注意点来了
%代表任意多个字符_仅仅代表一个字符
小练习

1 | SELECT * |

1 | SELECT * |

Equatorial Guinea and Dominican Republic have all of the vowels (a e i o u) in the name. They don’t count because they have more than one word in the name.
Find the country that has all the vowels and no spaces in its name.
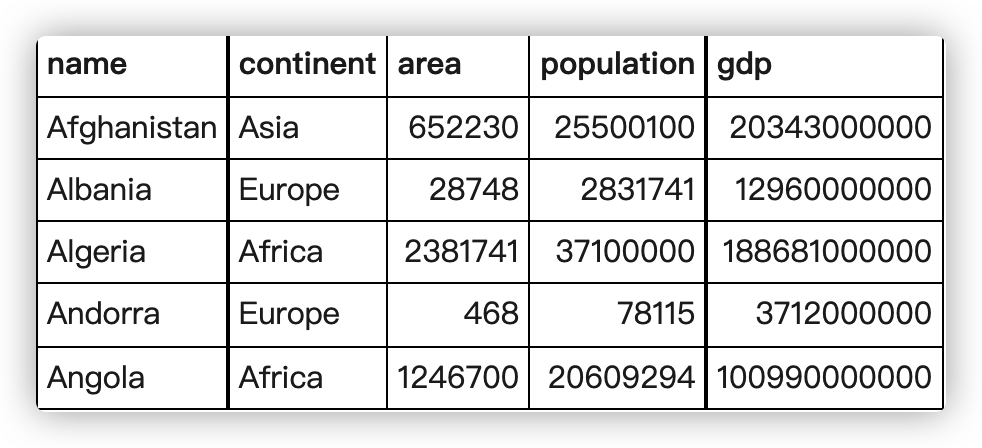
这题让我们查询国名中包含五个元音字母且不包含空格的国家,我们这里不能用 REGEXP 因为我们不知道其排列顺序。 因此我们只能傻乎乎的一个一个找。
1 | SELECT name |
REGEXP 运算符
所谓REGEXP 就是正则表达式
1 | SELECT * |
用正则表达式就不用再前面写%%这类的匹配符号了,如果想找field,mysql就会自动搜寻last_name 中包含field的信息
1 | WHERE last_name REGEXP '^field' -- 如果在前面加上 ^ 符号,代表必须以field开头 |
小练习

1 | SELECT * |

1 | SELECT * |

1 | SELECT * |

1 | SELECT * |

IS NULL 运算符
IS NULL 可以筛选所有该列为值 NULL 的信息
1 | SELECT * |
IS NOT NULL 可以筛选非空信息
1 | SELECT * |
小练习

1 | SELECT * |

The ORDER BY 子句
选择信息的排列方式
按照first_name 正序排列
1 | SELECT * |
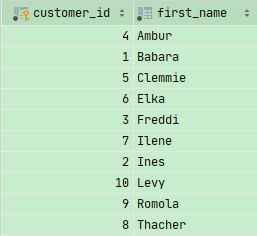
按照first_name 逆序排列
1 | SELECT * |
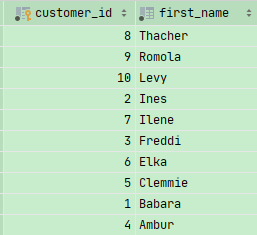
多关键词排列
1 | SELECT * |
先按照state排列,如果state相同,再按照first_name 进行排列
Mysql 支持 不显示排序列,只显示选择列
1 | SELECT first_name,last_name |
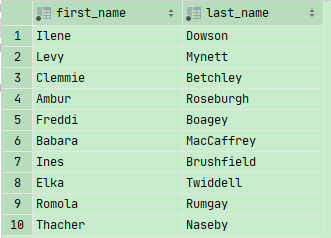
mysql支持对零时新建列进行排序
1 | SELECT first_name,last_name,10+customer_id AS points |
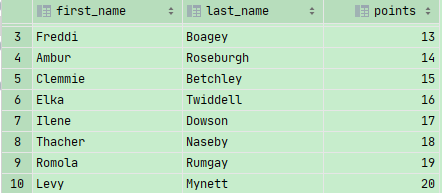
也可以用1,2代替first_name和last_name (不推荐)
1 | SELECT first_name,last_name,10+customer_id AS points |
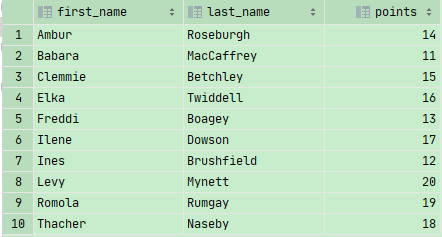
小练习
筛选出 order_items 中 order_id =2,且总价降序排列
1 | USE store; |

LIMIT运算符
限制返回的信息数量,如果小于3,那么全返回,否则就返回三条
1 | SELECT * |
通过偏移量来选择
1 | SELECT * |
这句话的意思就是跳过6条信息,然后从第七条开始返回3条信息,也就是7,8,9

小测试
1 | SELECT * |


TIPS
学到这我总结几个小的细节点:
- BETWEEN a AND b ; IN (a,b) 这两个语法要区分开来
- 在做限定的时候,如果是字符串,一定要用引号括起来
- 当字符串中有单引号
'时,将其替换成两个单引号。比如:SELECT * FROM nobel WHERE winner LIKE 'Eugene O''Neill', 这个人原本的名字叫: Eugene O’Neill(尤金 奥尼尔)
连接方式(在多张表各种检索)
Inner Joins 内连接
到现在我们只筛选了一张表中的信息,那么如何筛选多张表中的信息呢?
1 | SELECT * |
这个意思是 把customers表格也加入进来,但是要让customer中的id和orders中的id一一对应,形成一张完整的表格
为了简化表格,我们只选择有需要的信息
1 | order_id,first_name ,last_name |
当我们要在两张表中选择名字相同的列的时候,我们需要使用前缀,不然Mysql不知道我们到底想要那张表格中的信息
1 | SELECT order_id,orders.customer_id,customers.customer_id,first_name ,last_name |
也可以通过缩写,简短我们的代码量
1 | SELECT order_id,o.customer_id,c.customer_id,first_name ,last_name |
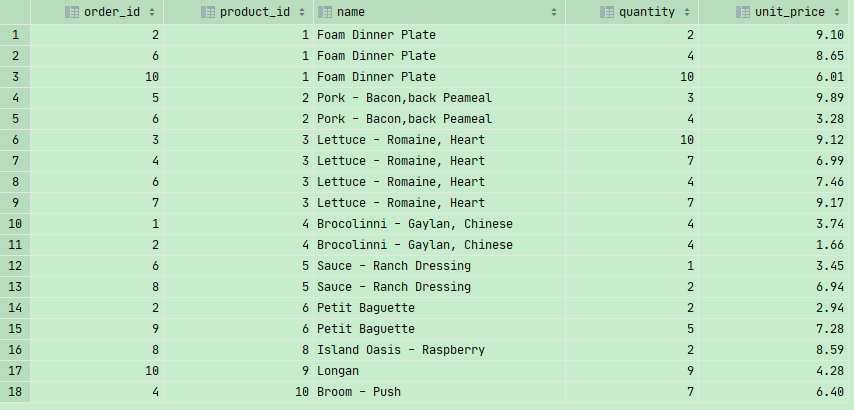
小练习
1 | SELECT order_id,o.product_id,p.name, quantity, o.unit_price |
小练习2
这是SQLZOO-JOIN上的题目,数据表如下:
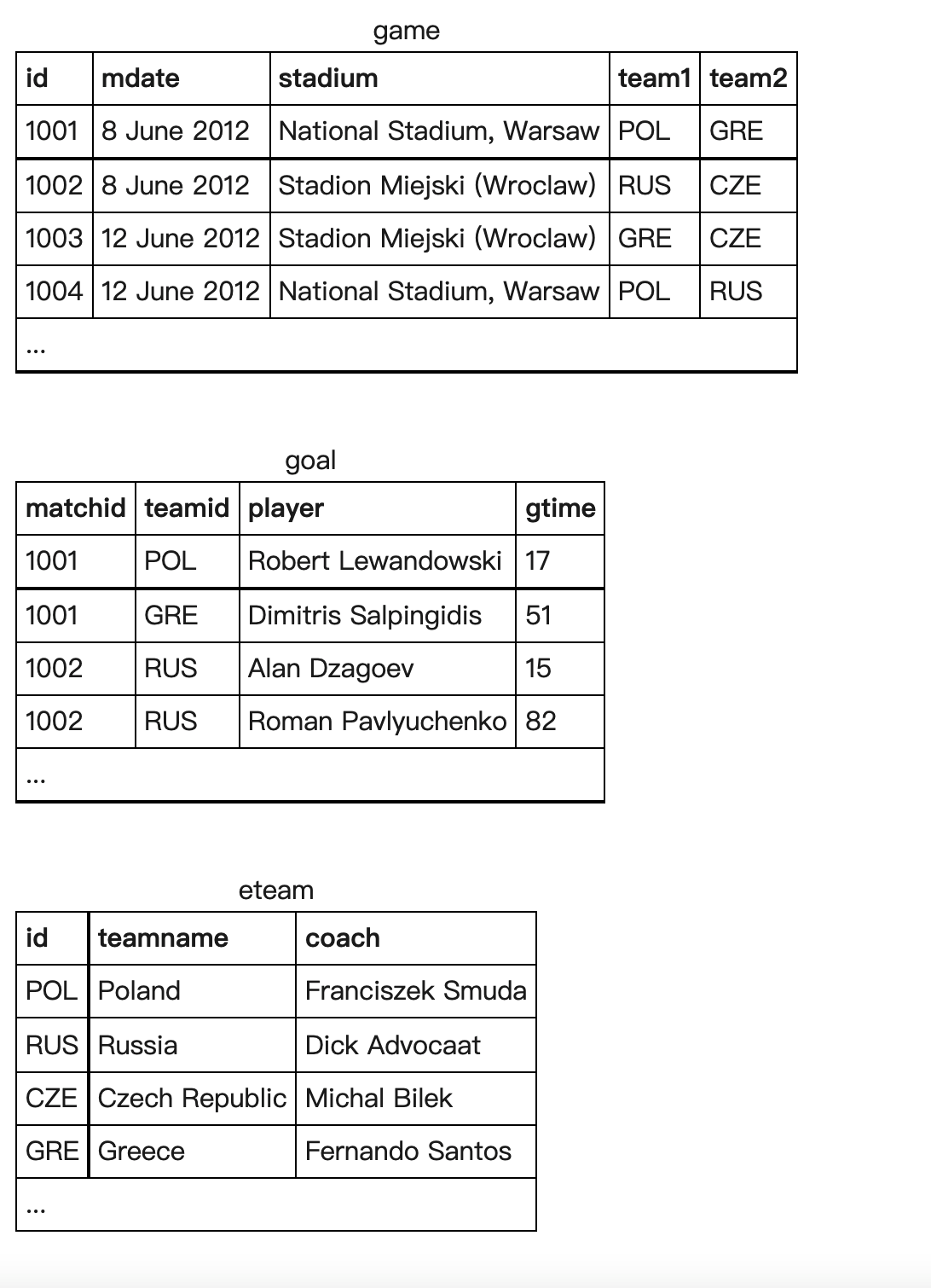
1.For every match involving ‘POL’, show the matchid, date and the number of goals scored.
要我们找出 所有关于波兰的比赛,并列出比赛中进的球数。
一开始我是这么写的:
1 | SELECT matchid,mdate,COUNT(*) |
结果报错了,说是
[42000][1055] Expression #2 of SELECT list is not in GROUP BY clause and contains nonaggregated column ‘nobel.game.mdate’ which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
ONLY_FULL_GROUP_BY的意思是:对于GROUP BY聚合操作,如果在SELECT中的列,没有在GROUP BY中出现,那么这个SQL是不合法的,因为列不在GROUP BY从句中,也就是说查出来的列必须在group by后面出现,否则就会报错,或者这个字段出现在聚合函数里面。
因此这里正确的做法是: `GROUP BY matchid,mdate
- 同理,For every match where ‘GER’ scored, show matchid, match date and the number of goals scored by ‘GER’
的做法也是一样:
1 | SELECT matchid, mdate, COUNT(*) |
Joining Across Databases 跨数据库连接
刚才是搜寻一个数据库中多张表的内容,现在搜寻多个数据库中的内容
1 | USE store; |
上面用的是在store数据库里的操作
那么如果我 改成sql_inventory 的话,就需要在order_items前加上前缀
1 | USE sql_inventory; |
Self Joining自连接
首先我们来分析一下这张表格
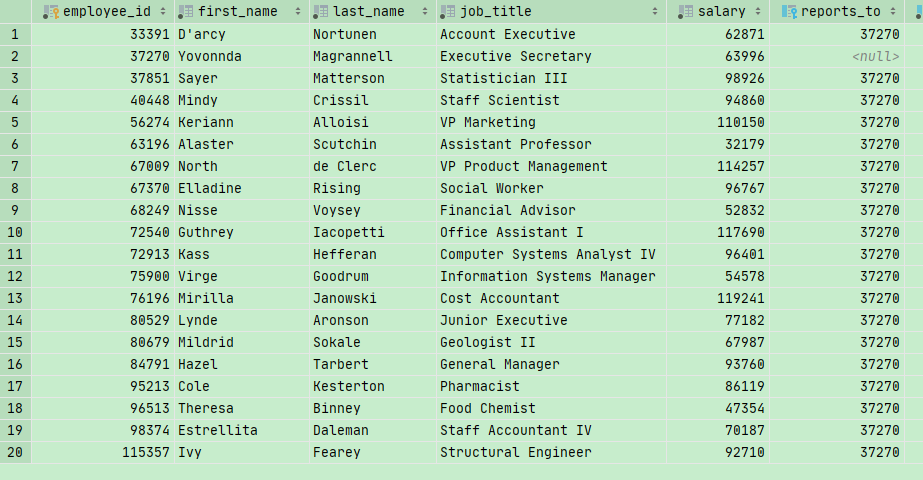
如果我们要找到这些员工的经理是谁,我们需要看reports_to 和 employee_id两列,那么我们知道第二行的员工是没有reports_to这一行的,而其他人的reports_to都指向了第二个人,所以说第二个人就是经理
现在我们要在mysql中筛选出所有员工的信息
1 | USE sql_hr; |
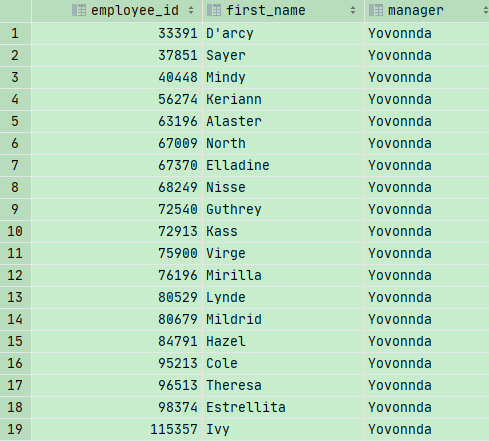
我们再来看几个例子:
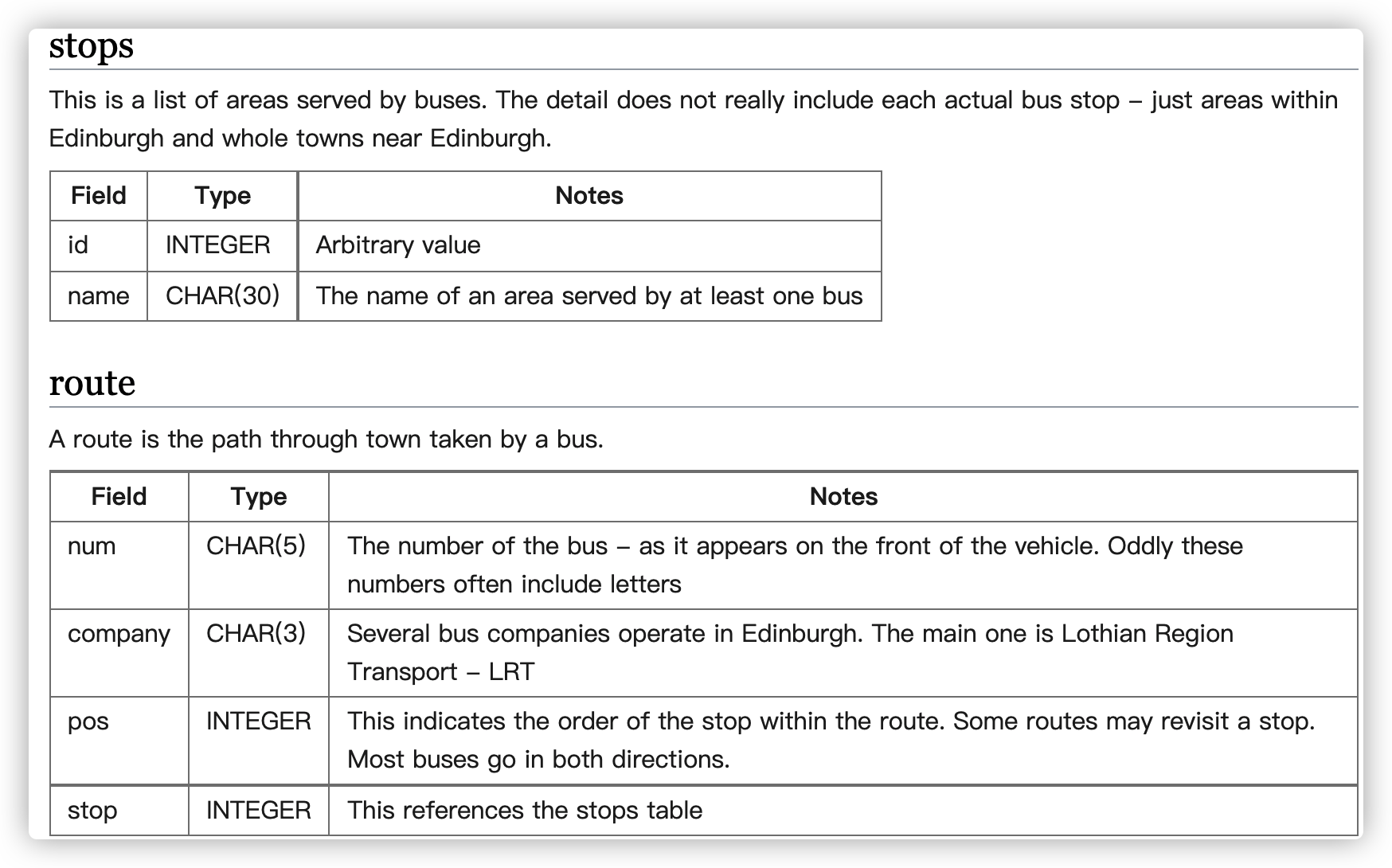
- Execute the self join shown and observe that b.stop gives all the places you can get to from Craiglockhart, without changing routes. Change the query so that it shows the services from Craiglockhart(149) to London Road(149).
这道题要我们使用自连接,给出从Craiglockhart到London Road 的公交路线。这里在匹配的时候注意要匹配两个字段,一个是company一个是num。因为要从Craiglock出发去LondonRoad, 但是公交线路一般是双向的,因此只要让a.stop和b.stop一个等于53 一个等于149即可(分别是两站的id)
1 | SELECT a.company, a.num, a.stop, b.stop |
- Give a list of the services which connect the stops ‘Craiglockhart’ and ‘Tollcross’进阶一点,如果要让我们直接找出连接这两站的路线,那么除了自连接意外,还需要连接stops表,但是注意了stop表也要连两次,分别与a和b
1 | SELECT a.company, a.num |
- Find the routes involving two buses that can go from Craiglockhart to Lochend.
Show the bus no. and company for the first bus, the name of the stop for the transfer,
and the bus no. and company for the second bus.
这道题让我们找出换乘路线,以及对应的换乘站点。即要找两路公交车,始发站是 Craiglockhart,终点站是Lochend,在当中的某一站换乘。
思路:做两次Self-Join,第一次自连接得到的结果v1是所有从Craiglockhart发出的公交车
第二次自连接得到的结果v2是所有可以到达Lochend 的公交车
然后把这两张表连接,连接条件是V1路线的末站等于V2路线的初站
得到结果
1 | SELECT DISTINCT v1.num,v1.company, name,v2.num,v2.company |
Join Multiple tables 多表连接
比如我们要把 order_status ,orders,customers三张数据表联合
1 | USE sql_store; |
小练习
请筛选出sql_invoicing 数据库中 clients,payments和payments_methods 三张数据表中的顾客,发票,付款方式等信息
1 | USE sql_invoicing; |
Compound Join Conditions复合连接条件
1 | USE sql_store; |
Implicit Join Syntax隐式连接语法(不建议)
利用JOIN 语句
1 | USE store; |
隐式联合语法,可以这样写
1 | USE store; |
因为如果不写where的话会交叉显示,所以不建议,还是写显示
Outer Joins外连接
我们先来看看inner joins的效果
1 | SELECT |
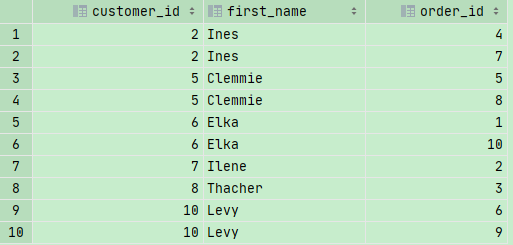
我们看到 customer_id 中没有1,3这种的信息,因为在orders表格中,customers_id并不是连续的,因为没有收到customer_id =1,3的客户的订单。所以我们要用Outer Joins
LEFT JOIN
所有在左半边的记录,这里是c.customer_id 不管有没有匹配到,都会返回
1 | SELECT |
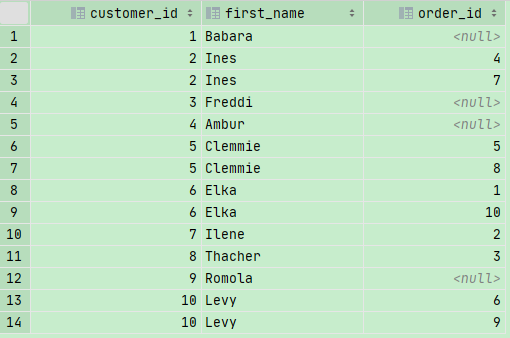
RIGHT JOIN
所有在右半边的记录,这里是o.customer_id 不管有没有匹配到,都会返回
在这种情况下RIGHT JOIN 和 JOIN的效果是一样的
注意: LEFT OUTER JOIN 和 LEFT JOIN 是一样的,可选可不选
1 | SELECT |
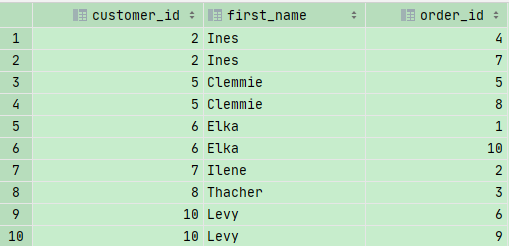
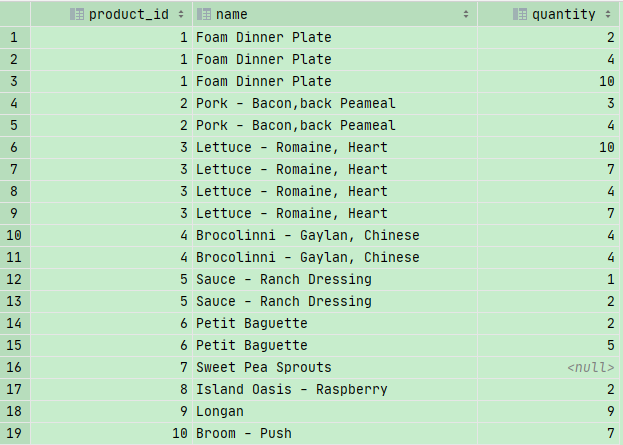
小测试
我们要在sql_store 数据库中筛选出product_id 和 它对应的quantity,因为存在有些products还没有订购数量,所以我们也要把它囊括在内,这里我用了RIGHT JOIN,显示所走右边,也就是p.product_id 的所有内容,不管有没有匹配到
1 | SELECT p.product_id,name,quantity |
Outer Joins Between Multiple Tables多表外连接
我们先要分析几张表格 :
orders

shippers:

customers:
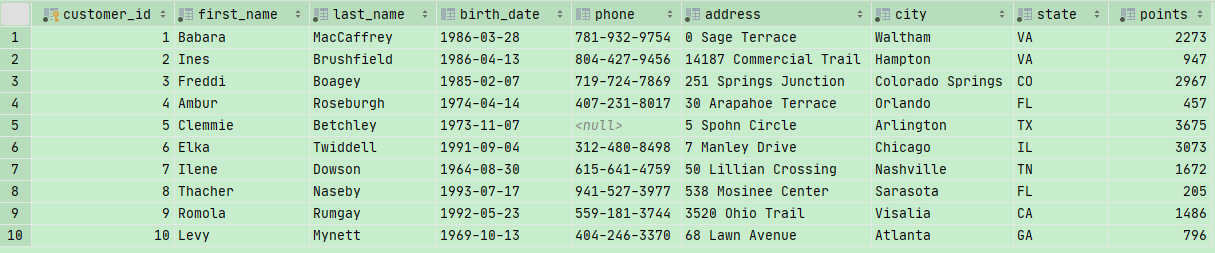
目标就是我们要找customer订购的订单信息和运送信息
1 | SELECT |
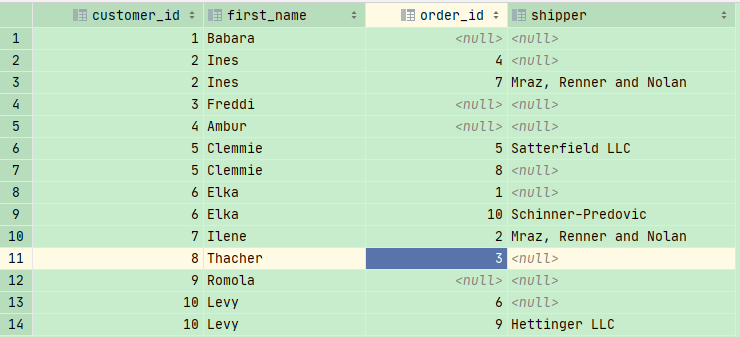
注意,我们最好使用LEFT JOIN,否则太乱了
小练习
1 | SELECT |
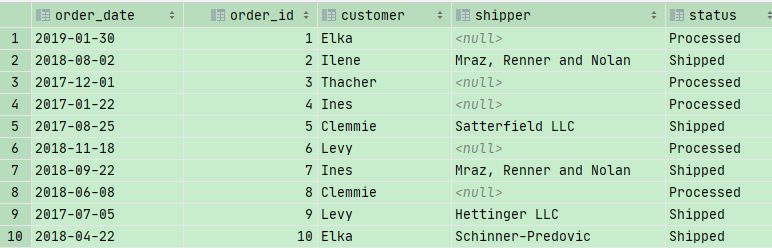
Self Outer Joins 自外连接
我们之前在搜索manager的时候,有了员工的信息,但是没有manager的信息。为什么?因为我们的 Inner Join做的判断,会筛选掉Manager。这时候如果运用LEFT JOIN ,就会显示这个manager的信息了
1 | USE sql_hr; |
USING CLAUSE (using子句)
原来我们可以这么查询
1 | USE sql_store; |
现在,可以用using子句来减少代码量
1 | USE sql_store; |
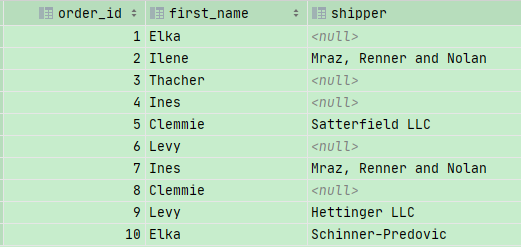
注意,USING 子句只能应用在不同表中的相同列名称中,如果这两列是不同名称的,那么我们将不能使用USING ,而只能使用ON语句
此外,USING 子句也可以多条件选择,避免了复杂的逻辑和代码量,比如,原来的代码如下
1 | SELECT * |
通过USING修改,可以变成
1 | USING(order_id,product_id) |
小测验:
produce something like this
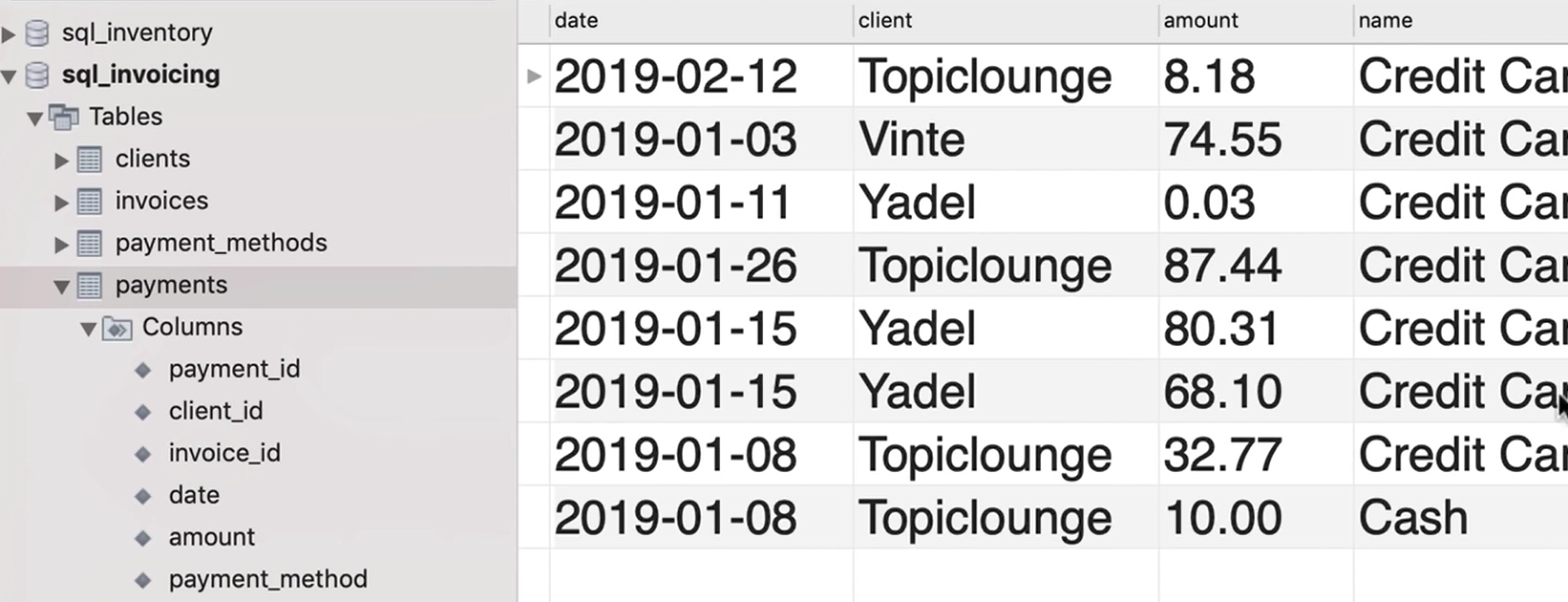
1 | USE sql_invoicing |
NATURAL JOIN
1 | USE sql_store; |
natrual join 会自动匹配不同table中相同的列名,但是会有危险。因为我们让数据库的搜索引擎猜想连接,我们无法控制。
CROSS JOIN交叉连接
1 | USE sql_store; |
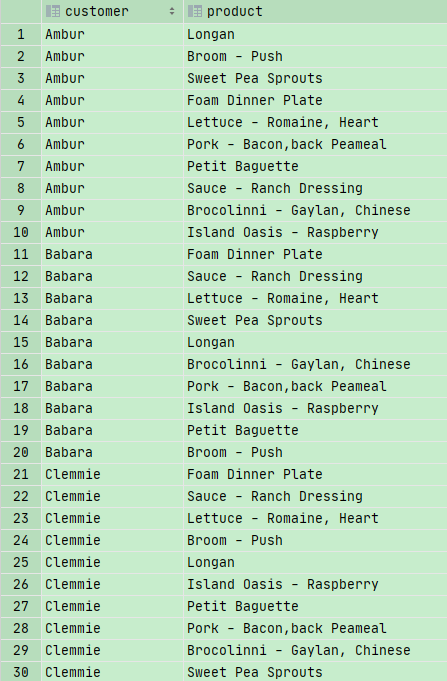
我们看到这样就是对每一个名字都和每一个product名字做了一个组合。可以显示所有组合信息,即笛卡尔积
CROSS JOIN 的隐式写法
1 | USE sql_store; |
小练习

隐式写法
1 | USE sql_store; |
显示写法
1 | USE sql_store; |
Union
UNION运算符能把两个查询到的表格合并成一张表
1 | USE sql_store; |
又如:
1 | SELECT first_name |
注意:
先查询到的先放在上面,后查询的放到下面
如果第一条sql语句返回的列数和第二条返回的列数不相等,这样会报错的!!
小练习
do something like this
其中要求如下
| Points | Type |
|---|---|
| <2000 | Bronze |
| 2000<=x<3000 | Silver |
| >=3000 | Gold |
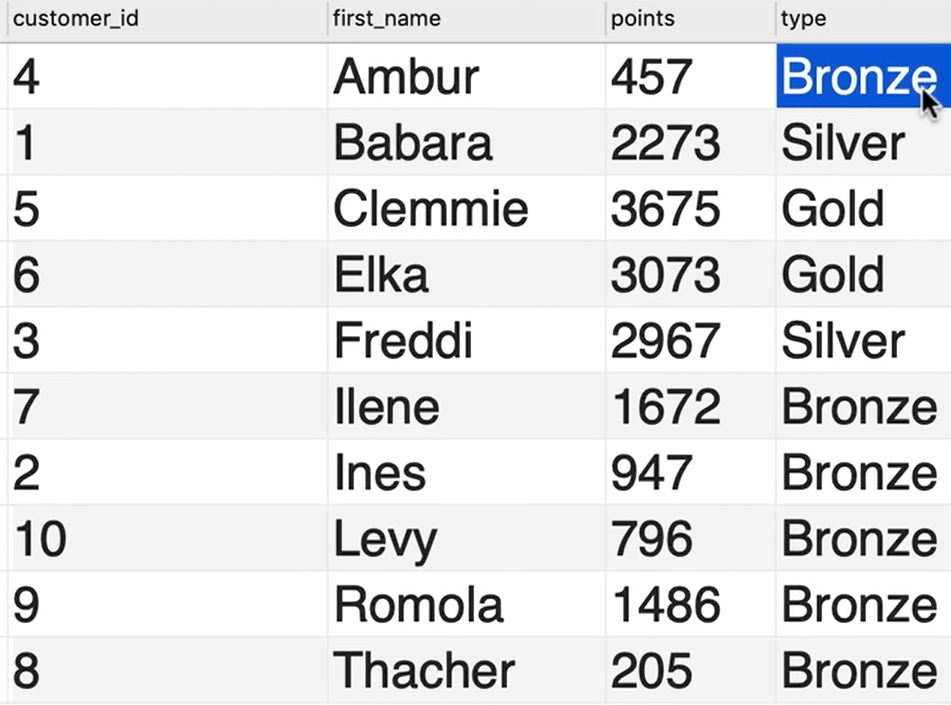
1 | SELECT |
数据表操作
Column Attributes 列属性
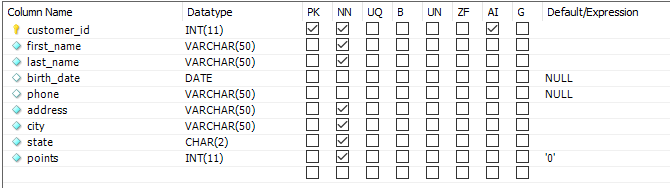
INT(11)代表只能存储数字
VARCHAR(50) variable char,是动态的,是最多可以有50个字符,所以并不会浪费空间
CHAR(50),如果这样的话,多余的空间会用空白填满,造成空间浪费
PK是主键的意思,选中的话会有黄钥匙图标
NN是非空的意思,如果选中的话,这个单元格一定要有内容
AI:auto increament 常常用在主键列中,会自动填充
Default/Expression 默认值,如果你不填,mysql会自动帮你填充,默认内容
Inseting a Single Row 插入单行
1 | INSERT INTO customers |
我们也可以指定特定列进行单行插入
1 | INSERT INTO customers(first_name, |
这两种方法的效果是一样的,我们看到在表中的最后一列,已经显示了这条记录

Inseting multiple Row 插入多行
Inserting Hierachical Rows插入分层行
我们首先来看orders 和 order_items 这两张表格
orders
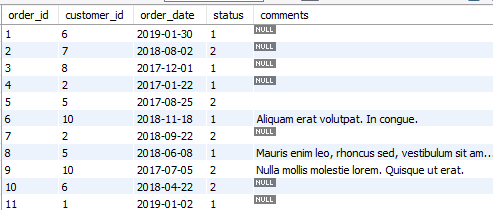
order_items
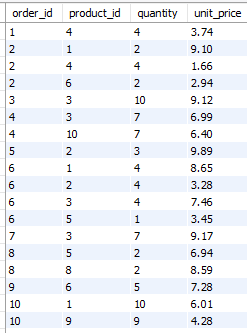
所以我们可以看到,一个订单号,可以订购很多产品,然后数量,价格,也可以不经相同,所以我们说orders是order_items的母表,了解了这个我们就可以做如下操作。
1 | INSERT INTO orders(customer_id, order_date, status) |
Creating a Copy of a Table表赋值
那么如何做一个数据表的备份呢?
1 | CREATE TABLE orders_archived AS SELECT * FROM orders |
单单这样写一下,是没有列属性中的主键之类的信息的。需要自己设置
那么如何复制部分表呢?
当orders_archived这张数据表存在时,(可用Truncate Table键删除所有行但保留字段值),可以用这样的方法插入数据
1 | INSERT INTO orders_archived |
小练习
创建一份invoice部分记录的备份表,名字叫invoices archive 但是那张表里我们不想要客户的id列,我们要客户名列,另外,只选择有付款日期的发票进行操作
1 | CREATE TABLE invoices_archive AS |
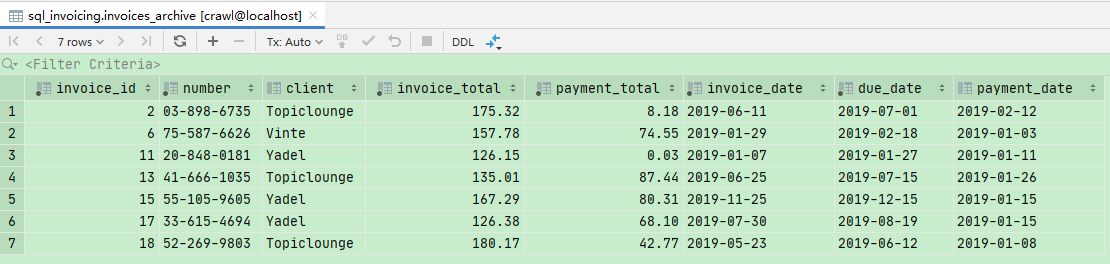
Updating a Single Row更新单行
1 | UPDATE invoices |
1 | UPDATE invoices |
Updating Multiple rows更新多行
修改where 后面的语句即可
1 | UPDATE invoices |
小测验

1 | UPDATE sql_store.customers |
Using Subqueries in Updates 在Updates中使用子查询
情景:比如我想修改 一个人的发票信息,但是呢我只有他的名字,而没有他的client_id,但是发票信息是根据client_id 存储的,所以我们要先根据他的名字找到他的client_id 然后再根据他的client_id 执行 UPDATE 操作
1 | UPDATE sql_invoicing.invoices |
同时,这也可以进行多行更新 ,注意,这里要改两个地方,client_id后面因为多条信息,所以要用in
1 | WHERE client_id IN |
小练习
在orders 数据表中,把金牌客户(clients中points分数大于3000的)下的订单备注改为 GOLD Customer
1 | UPDATE orders |
Deleting Rows删除行
1 | DELETE FROM sql_invoicing.invoices |
汇总数据
Aggregate function聚合函数
我们需要把相同属性的数据聚合起来,这时候就要运用聚合函数了
1 | USE sql_invoicing; |

1 | USE sql_invoicing; |

小练习
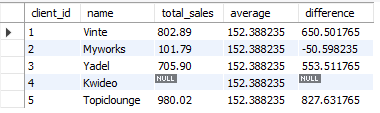
做一张表格,计算上半年,下半年,全年的销售额,付款额,和差值
1 | SELECT |

The GROUO BY clause
1 | SELECT |
注意了,GROUP BY
小练习
1 | SELECT |
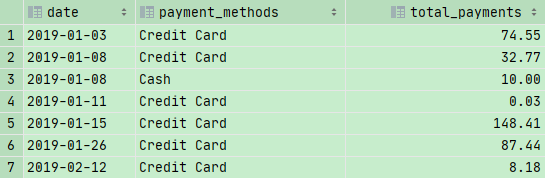
上图是正确结果
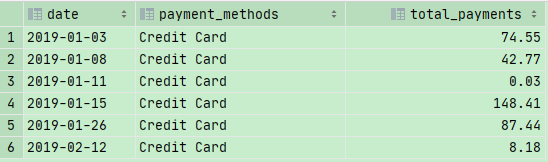
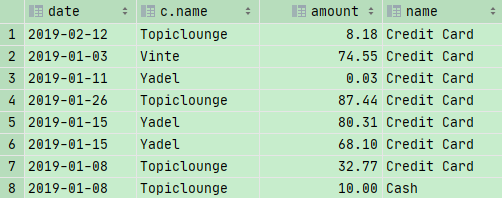
如果我们仅仅GROUP BY date,那么两个就如上图所示,两个2019-01-08的数值合并在了一起
The HAVING clause
问题导入
1 | SELECT |
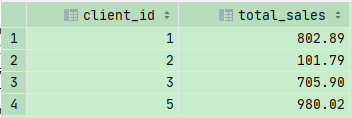
那么,我们如果只想筛选总销售量大于500的客户,那么应该如何选择呢?
因为一个客户可以买很多单,所以用了SUM,但是我们在这里无法使用WHERE语句,因为WHERE必须放在GROUP BY之前,所以在WHERE的时候,数据汇总还没有出来,这时候我们就需要用到HAVING 语句了。
the differences between HAVING AND WHERE
HAVING 语句用在GROUP BY的后面,而WHERE 必须用在 GROUP BY 的前面
此外,HAVING 子句后选择的列,一定要是SELECT中的列,但是WHERE语句可以选择表中的任何一列
1 | SELECT |

小练习

1 | SELECT |

The ROLLUP Operator
RollUP就是对Group BY 汇聚起来的数据进行求和操作
1 | USE sql_invoicing; |
1 | SELECT |

编写复杂查询
Subqueries 子查询
— Find products that are more expensive than Lettuce(id=3)
那么其实我们就是在找比莴苣要贵的产品的信息
所以我们先要搜寻莴苣的信息,作为子查询。然后再拿道WHERE子句中,供母查询
1 | SELECT * |

小练习
— In sql_hr database: Find employees whose earn more than average
1 | USE sql_hr; |

IN Operator IN操作符
— Find the products that have never been ordered
我们知道再order items 表格里 有每个产品的订购次数。所以我们先要找到这张表里的产品,然后再返回没有在这张表中的产品,就是没有被订购过的产品
也就是说,刚才的子查询是返回一个值,但是现在是返回一个列表,所以用 IN 操作符
1 | USE sql_store; |

小练习
— Find clients without invoices
1 | USE invoicing; |

Suqueries VS Joins 子查询和连接
我们经常用连接来写一个子查询。比如我们对上衣个小练习用连接重写
1 | USE invoicing; |
子查询和连接都能达到我们的目标,但是子查询更加直观。
有时候子查询会过于繁杂,那么我们就要用连接
小练习
— Find customers who have ordered lettuce(id=3)
— Select customer_id ,first_name,last_name
运用子查询,我们这么写
1 | USE sql_store; |
运用连接,我们这样写
1 | USE sql_store; |
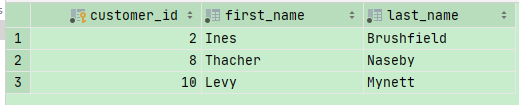
The ALL Keyword
— Select invoices larger than all invoices of client 3
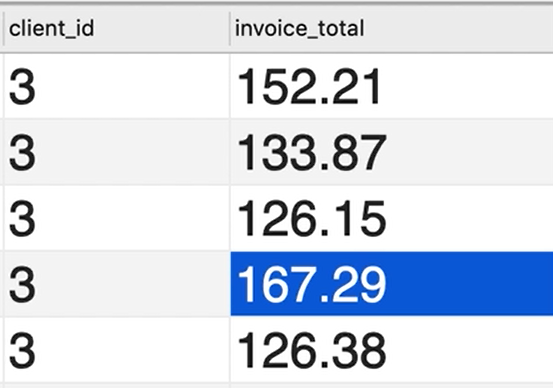
也就是选择大于167.29的所有发票
原来,我们可以用MAX+子查询
1 | USE sql_invoicing; |
现在我们用ALL关键字+子查询也可以达到
ALL关键字的原理就是把 invoice_total 把子查询中所有的返回值进行比较,然后全部符合的就为目标(听起来效率不是很高的样子)
怎么用ALL和MAX 看个人喜好
1 | USE sql_invoicing; |

The ANY Keyword
还是拿发票来举例子,ANY 就是得到发票总额高于这段子查询返回的任意值的信息
— Select clients with at least two invoices
1 | SELECT * |
所以 =ANY 就等于 IN

Correlated Subqueries 相关查询
— Select employees whose salary is above the average in their office
1 | USE sql_hr |
这句话是说:对每一个员工进行子查询,子查询里面计算他所在部门的所有人的薪水的平均值。然后把这个员工的薪水和返回的平均值比较,如果大于平均值的就返回
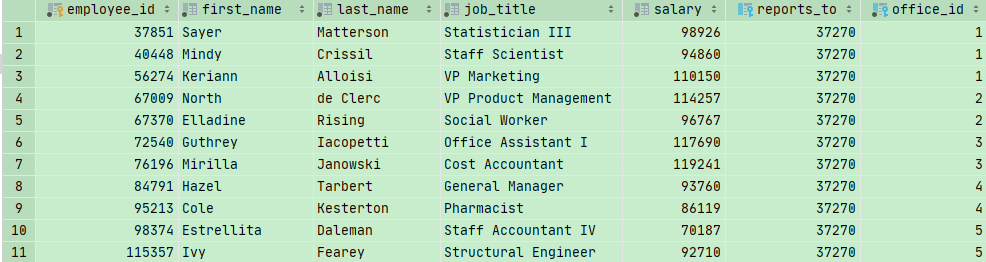
小练习
— Get invoices that are larger than the client’s average invoice amount
1 | USE invoicing; |

The EXISTS Operator
— Select clients that have an invoice
使用IN 操作符我们可以这么写
1 | USE invoicing; |
但是我们现在可以用EXISTS操作符完成
1 | USE invoicing; |
使用 IN 和 EXISTS的区别:
使用IN的时候,返回的个是一个可迭代的id列表,也就是说(1,2,3,4….),然后再用clients_id 在这个列表中去取值,再查询返回
使用EXISTS的时候,再子查询中,判断子查询的client_id是否和母查询中的client_id 相匹配。如果匹配成功,直接进入返回信息当中
当数据量很大的时候,EXISTS的效率比IN要高
小练习
— Find the products that have never been ordered
1 | USE sql_store; |

Subqueries in SELECT clause
子查询不仅仅局限于 WHERE子句当中,还存在于SELECT子句和接下来要讲的FROM子句当中
1 | SELECT |
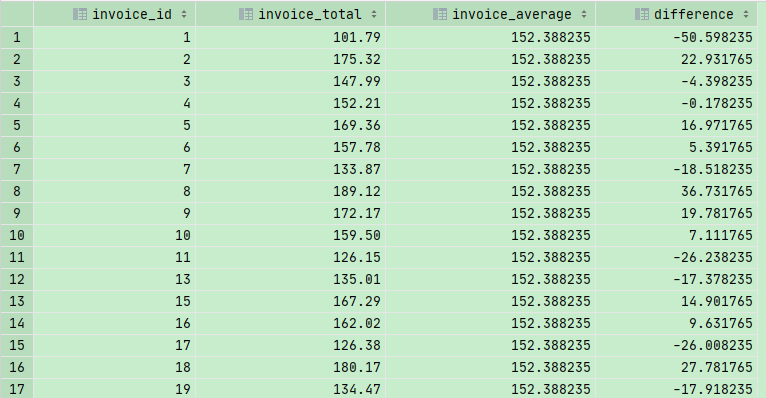
小练习
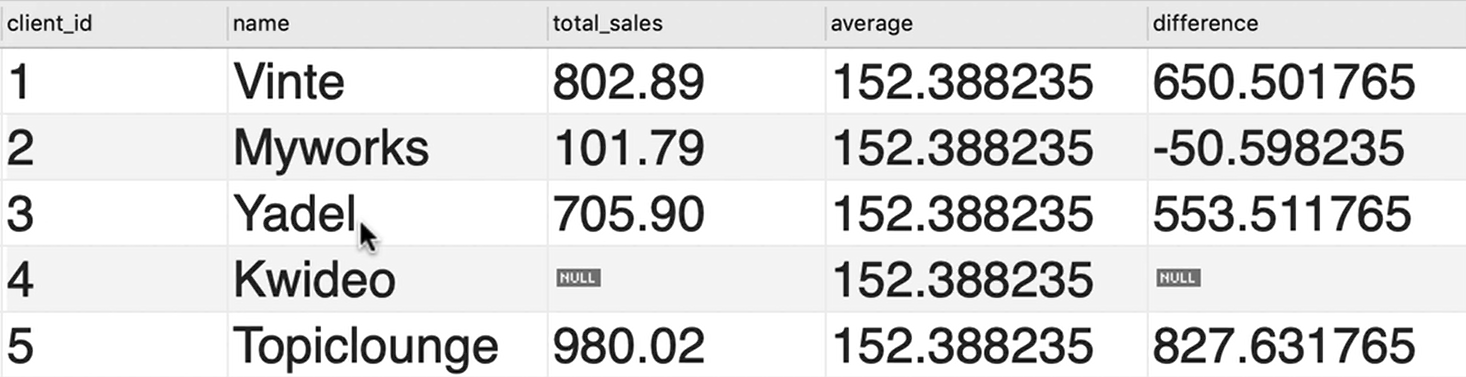
制作出这张表格
1 | USE sql_invoicing; |
Subqueries in FROM clause
也就是说,可以把我们选择的表格作为一张新的表格,然后在这张表格的基础上进行操作,但是这样或让子查询变得复杂,所以运用视图的方法会更加简化代码。关于视图,在接下来会讲到
1 | SELECT * |
SQLZOO 练习
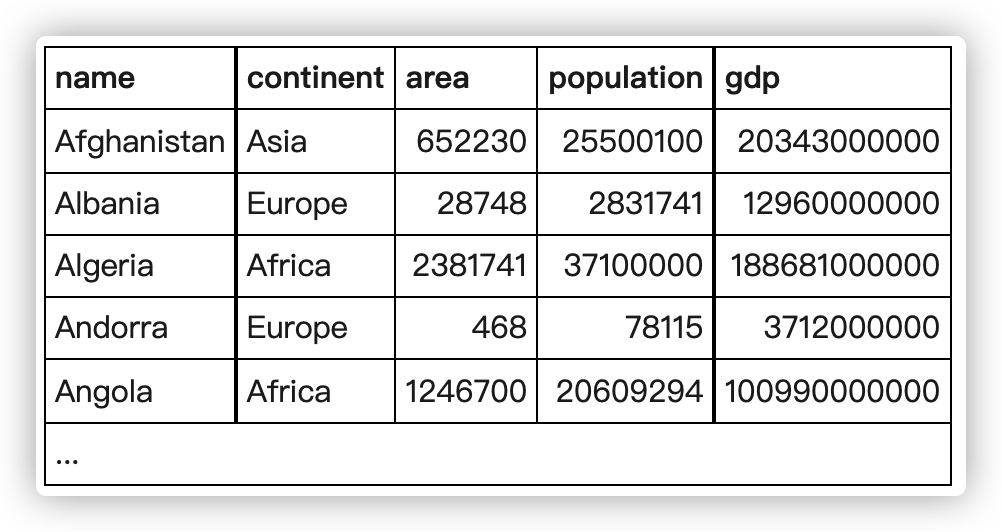
有表如上图所示
List each continent and the name of the country that comes first alphabetically.
让我们筛选出每个大洲中字母表的第一顺位国家,那么肯定需要用 ORDER BY name , 只需要一个,那么需要 LIMIT 1
1 | SELECT continent,name |
Find the continents where all countries have a population <= 25000000. Then find the names of the countries associated with these continents. Show name ,continent and population
这题要我们筛选出一个州的所有国家人数都小于25000000的国家信息,因此我们可以使用 ALL关键词:
1 | select name, continent,population |
Some countries have populations more than three times that of any of their neighbours (in the same continent). Give the countries and continents.
这题要我们筛选出每个州内的一个国家,它的人口数量是这个州其他任何国家的人口数量的三倍。其实这也需要用到 ALL ,只是在写子查询的时候需注意,要添加 x.name != y.name 因为自己人数不能比自己的三倍还多
1 | SELECT name ,continent |
Mysql中的基本函数
Numeric Function
1 | SELECT ROUND(5.746,2); # 四舍五入,后面是保留几位 |
String Functions
1 | SELECT UPPER('sky'); # 大写 |
1 | USE sql_store; |
小练习
有表如下:
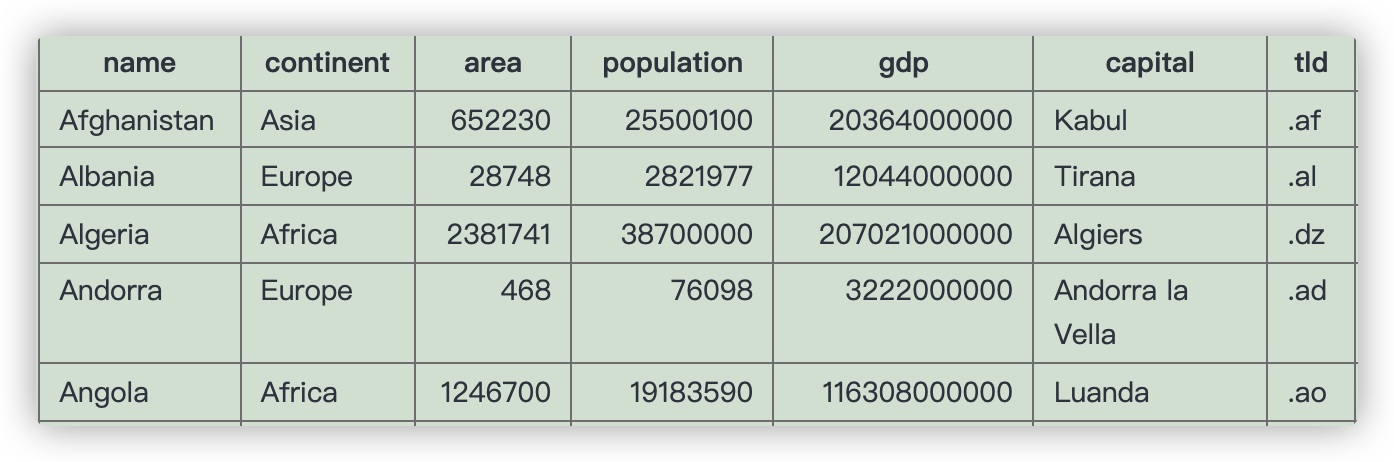
- Find the capital and the name where the capital includes the name of the country.
这一题需要用到 LIKE 以及 CONCAT 这两个关键字。因为我们不能直接 LIKE '%name%' 这样是查名字中有无name的信息了,因此我们要这么写:
1 | SELECT name , capital |
用 CONCAT 将 name 和 % 连接起来
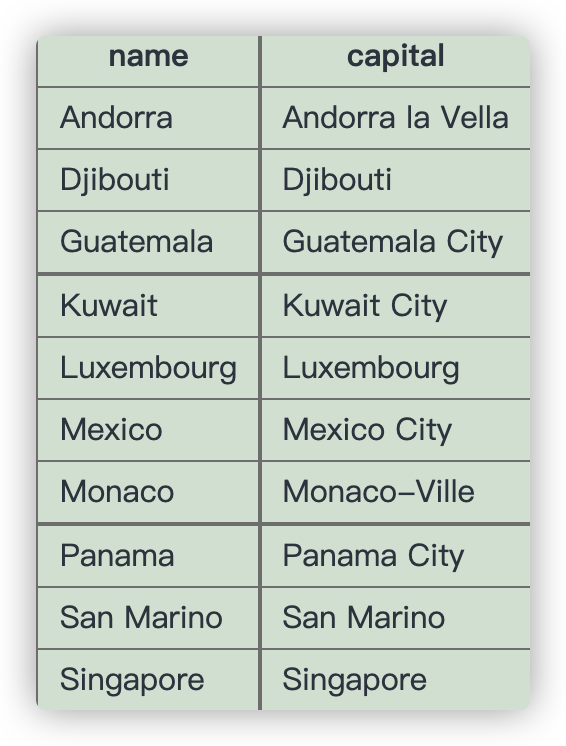
Find the capital and the name where the capital is an extension of name of the country.
You should include Mexico City as it is longer than Mexico. You should not include Luxembourg as the capital is the same as the country
1 | SELECT name , capital |
这题要我们进一步找寻首都名字包含国家名且长于国家名的,因此只要加一个 AND 条件就行了
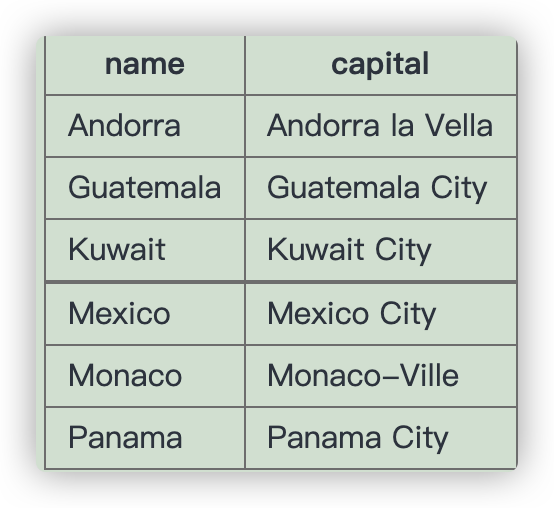
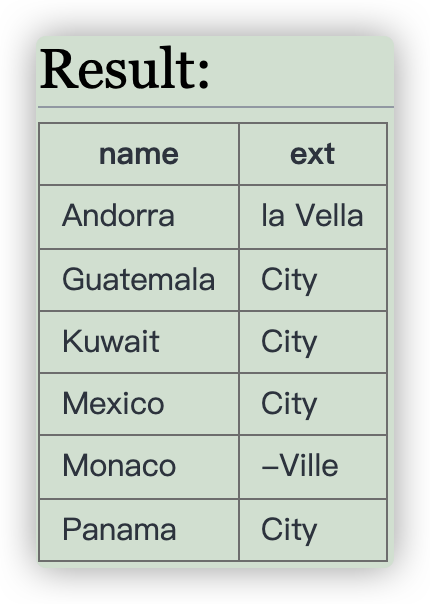
For Monaco-Ville the name is Monaco and the extension is -Ville.
Show the name and the extension where the capital is an extension of name of the country.
You can use the SQL function REPLACE.
这一题要我们把后缀也筛选出来,于是我们可以使用REPLACE 函数,将capital中的name部分删除后生成一个新列 extension, 然后再进行刚才的筛选。
1 | SELECT name , capital ,REPLACE(capital,name,'') AS extension |
Date Functions in Mysql
1 | SELECT NOW(),CURDATE(),CURTIME(); |
小练习
改写下列查询语句,选择2019年开始的所订单
1 | SELECT * |
因为今年是2020,所以我减去了1
1 | USE sql_store; |
Formatting Dates and Times
1 | SELECT DATE_FORMAT(NOW(),'%y'); # 20 |
Caculating Dates and Times
1 | SELECT DATE_ADD(NOW(),INTERVAL 1 YEAR ); # 加1 |
The IFNULL and COALESCE Function
shipper_id 有的话,那就写。如果 shipper_id 没有的话,那就在这行上写上 Not assigned
1 | USE sql_store; |
有shipper_id就写上, 如果 shipper_id 没有,那么就看看comment有没有,comment如果有的话就写上的话,那么才写 Not assigned
也就是说COALESCE 可以写多行,有多个选择。范围比 IFNULL 更大
1 | USE sql_store; |
小练习
—制作下面这张表格

1 | USE sql_store; |
The IF Function
IF(expression, first, second)
如果满足第一个expression,那么就把first的内容赋值给该信息,反之把second的内容赋值给该信息
1 | SELECT |
小练习
制作下列表格
1 | SELECT |
The CASE Operator
那么,知道了IF能执行一个expression以后,怎么进行多个expression的赋值分配呢?
注意CASE 的语法结构
1 | CASE |
1 | SELECT |
小练习
- 写这张表格,利用CASE Operator
1 | USE sql_store; |
有这样一张表格,我希望用 CASE WHEN 来制作出如下表格:
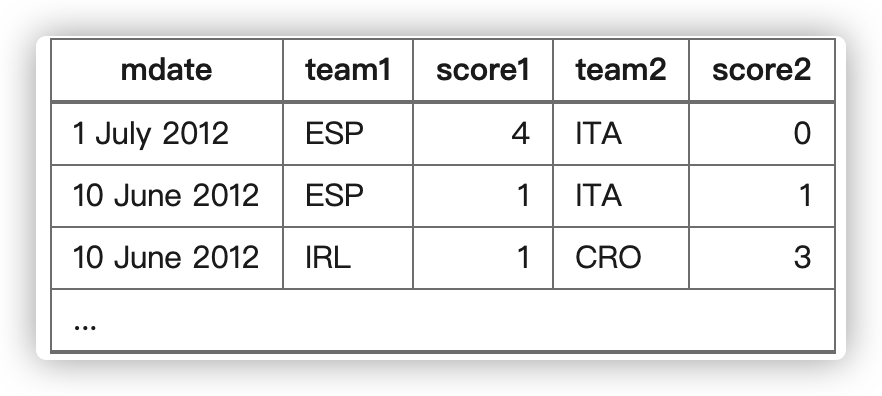
这时候为了计算每支队伍的进球个数,在用到CASE之外还需要使用 SUM,也就是先利用CASE将进球标位1,然后统计1的个数。
因此score1这一列可以这样写: SUM(CASE WHEN teamid=team1 THEN 1 ELSE 0 END) 说明如果team1进球了,那么这一球记为1,然后求和。
最终sql语句如下所示:
1 | SELECT |
视图
Creating views创建视图
视图就是一张子表格,我们把我们需要的信息筛选出来后创建成一张视图。然后就可以把这张视图当作一个表格,进行更多操作。
1 | CREATE VIEW sales_by_clients AS |
1 | SELECT * |

小练习:
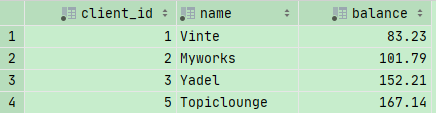
Create a view to see the balance for each client called clients_balance,including client_id,name and balance
(balance = invoice_total - payment_total)
1 | CREATE VIEW clients_balance AS |
1 | SELECT * |
Altering or Dropping Views 更改或删除视图
删除视图后重新创建
1 | DROP VIEW sales_by_clients |
所以我们需要把创建视图时候的源代码保存为sql文件
Updatable Views 可更新视图
当一张视图没有
1 | DISTINCT |
这些函数或者关键词的时候,我们称这张视图为可更新视图
1 | CREATE OR REPLACE VIEW invoices_with_balance AS |
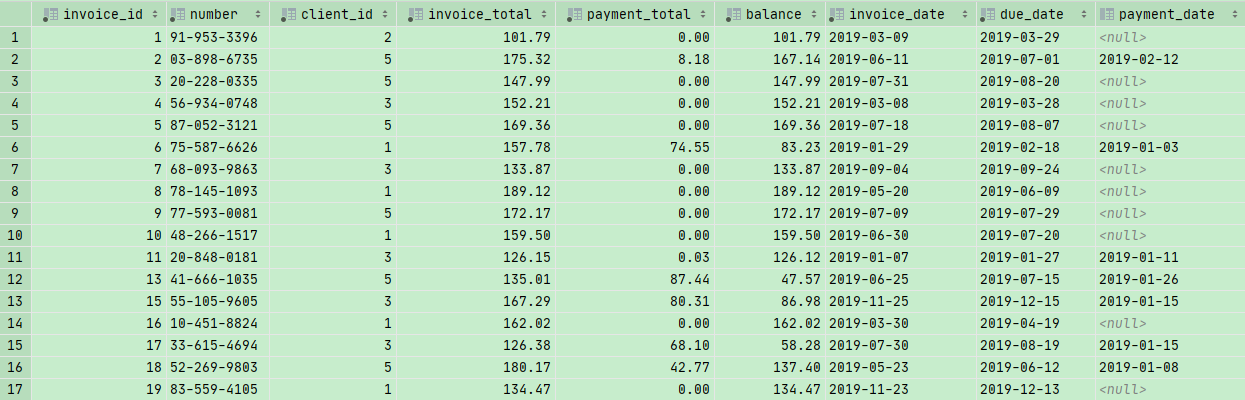
1 | DELETE FROM invoices_with_balance |
删除invoice_id =1 的数据
1 | UPDATE invoices_with_balance |
把due_date 调后两天
WITH OPTION CHECK Clause
WITH CHECK OPTION的作用?
1.对于update,有with check option,要保证update后,数据要被视图查询出来;
2.对于delete,有无with check option都一样;
4.对于insert,有with check option,要保证insert后,数据要被视图查询出来;
5.对于没有where 子句的视图,使用with check option是多余的。
如果修改后的条件不满足在创建VIEW的时候给出的条件,那么就会报错。
否则就随便改了,不符合我们的条件
Other Benefits of Views
如果需要经常执行某项复杂查询,可以基于这个复杂查询建立视图,此后查询此视图即可,简化复杂查询;
视图本质上就是一条SELECT语句,所以当访问视图时,只能访问到所对应的SELECT语句中涉及到的列,对基表中的其它列起到安全和保密的作用,可以限制数据访问。
1、数据库视图允许简化复杂查询:数据库视图由与许多基础表相关联的SQL语句定义。 您可以使用数据库视图来隐藏最终用户和外部应用程序的基础表的复杂性。 通过数据库视图,您只需使用简单的SQL语句,而不是使用具有多个连接的复杂的SQL语句。
2、数据库视图有助于限制对特定用户的数据访问。 您可能不希望所有用户都可以查询敏感数据的子集。可以使用数据库视图将非敏感数据仅显示给特定用户组。
3、数据库视图提供额外的安全层。 安全是任何关系数据库管理系统的重要组成部分。 数据库视图为数据库管理系统提供了额外的安全性。 数据库视图允许您创建只读视图,以将只读数据公开给特定用户。 用户只能以只读视图检索数据,但无法更新。
4、数据库视图启用计算列。 数据库表不应该具有计算列,但数据库视图可以这样。 假设在orderDetails表中有quantityOrder(产品的数量)和priceEach(产品的价格)列。 但是,orderDetails表没有一个列用来存储订单的每个订单项的总销售额。如果有,数据库模式不是一个好的设计。 在这种情况下,您可以创建一个名为total的计算列,该列是quantityOrder和priceEach的乘积,以表示计算结果。当您从数据库视图中查询数据时,计算列的数据将随机计算产生。
5、数据库视图实现向后兼容。 假设你有一个中央数据库,许多应用程序正在使用它。 有一天,您决定重新设计数据库以适应新的业务需求。删除一些表并创建新的表,并且不希望更改影响其他应用程序。在这种情况下,可以创建与将要删除的旧表相同的模式的数据库视图。

SQLZOO练习
MORE JOIN
https://sqlzoo.net/wiki/More_JOIN_operations
有数据表如下:
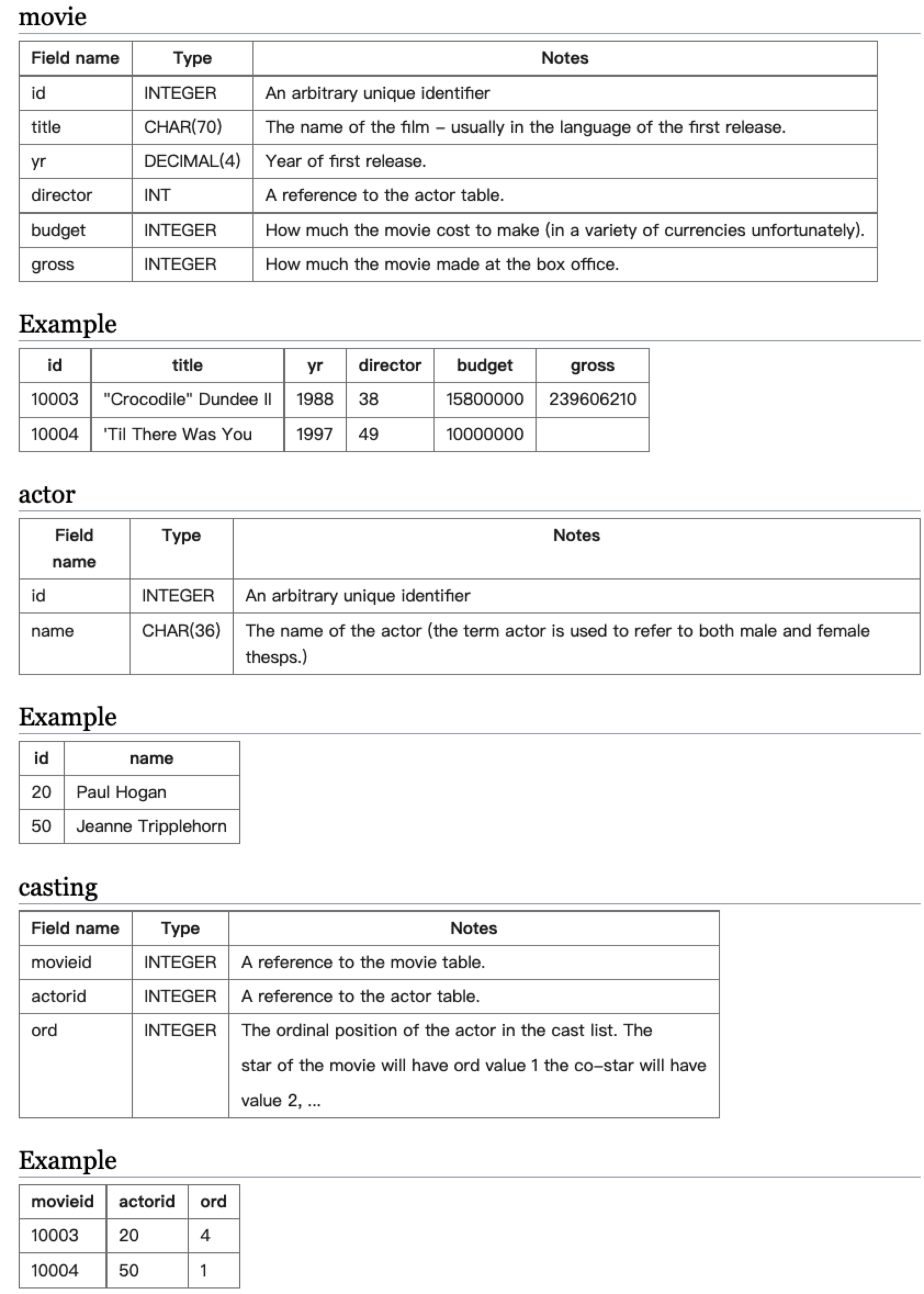
- Obtain a list, in alphabetical order, of actors who’ve had at least 15 starring roles.
这道题要我们列出主演过15部电影的电影明星并按照字母表顺序排列
首先要计算演过的电影数量,必然要使用到COUNT,其次如果明星主演了一部电影,那么它的ord=1。 这题不需要使用JOIN,可以使用子查询,先查询主演电影数超过15的actorid,然后再在actor中查询这些id即可
1 | SELECT name |
- List the films released in the year 1978 ordered by the number of actors in the cast, then by title.
这道题要我们查询1978年所有的电影的卡司数量,还是比较简单的
1 | SELECT title, COUNT(actorid) AS num |
- List all the people who have worked with ‘Art Garfunkel’.
这道题要我们找出所有和演员Art Garfunkel共事过的人。
这题是比较难的,我们来层层深入分析
首先,因为这个人可能演过很多电影,我们先要将其找出。
为了找出这个人演的电影,需要用到子查询,也就是
1 | SELECT movieid |
然后,需要找到这些电影中所有的卡司人员,除了Art Garfunkel之外,因此外面还需要套一层选择语句。
1 | SELECT name |