Express框架在后端的应用
在写后端的时候,时常要用到我的学习博客
考虑到基础博客的篇幅普遍过长,所以为了阅读的体验,本文所有链接点击即可跳转至相应章节
根目录
server.js
server.js是最重要的一个文件了,他就像一棵树的树根,文件从它开始衍生开来
在Nodejs基础1的Middleware章节中,我详细讲了 expresss.json(),express.urlencoded(),express.static(),morgan.helmet这些中间件。所以他们的作用我在这里不细讲了
cors包是用来跨域的,这点在React框架在作业当中的应用 中的setupProxy.js有提到,
bodyParser是当请求体解析之后,解析值会被放到req.body属性中,当内容为空时候,为一个空对象{},json()—解析JSON格式 Express中间件body-parser
然后是一个登陆操作,我为了连接方便而且多电脑端都可以使用,所以把数据都上载到了云数据库当中。通过将useNewUrlParser设置为true来避免“不建议使用当前URL字符串解析器”警告
再后来就是把所有的路由接口全部导入,然后把前缀全改为/api,为了在apiRoutes中可以省略/api
最后导入一个检查错误的中间件。用来检查非法的路由和登陆错误
1 | const path = require('path'); |
记录日志始末
阶段1
一开始,我才用了morgan来记录日志
1 | const logger = require("morgan"); |
但这样只是打在终端里,显然我们是不满足的
阶段2
然后,我们向把日志记录在.csv 文件中
1 | const fs = require("fs"); |
启动服务后,我们看到在根目录下的access.csv文件中记录下了日志
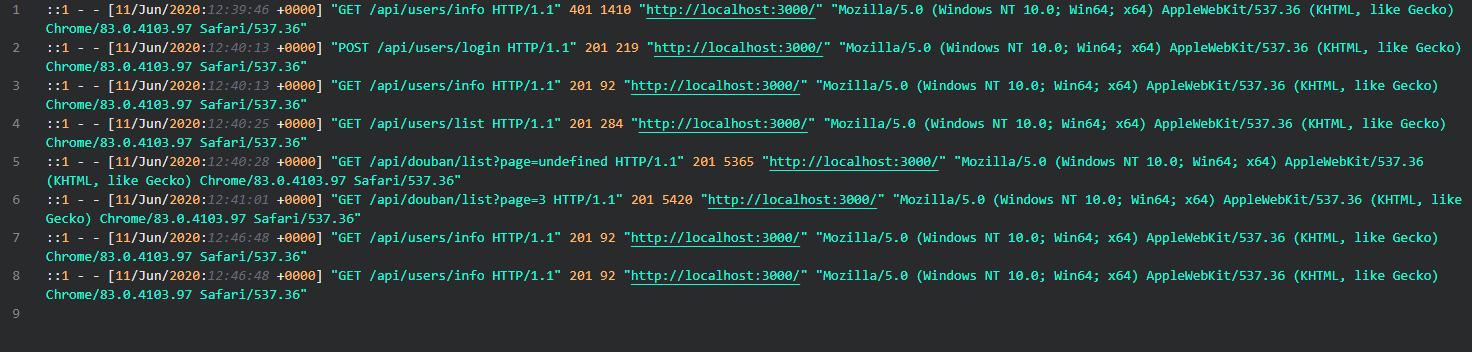
这里我先导入到csv文件当中,然后再利用DataGrip定期导入这个access.csv文件来达到数据库存储的一个效果。(虽然这么做不是很正规。。。)
阶段3
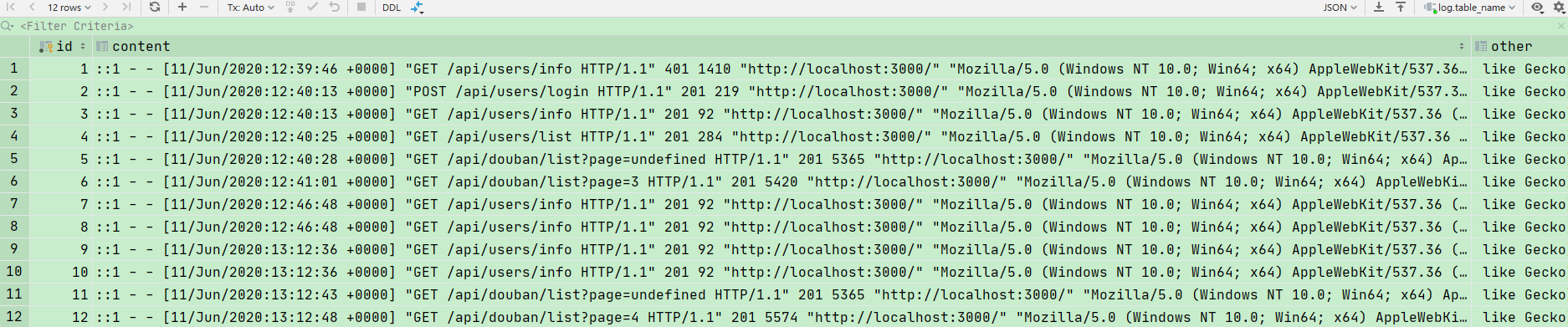
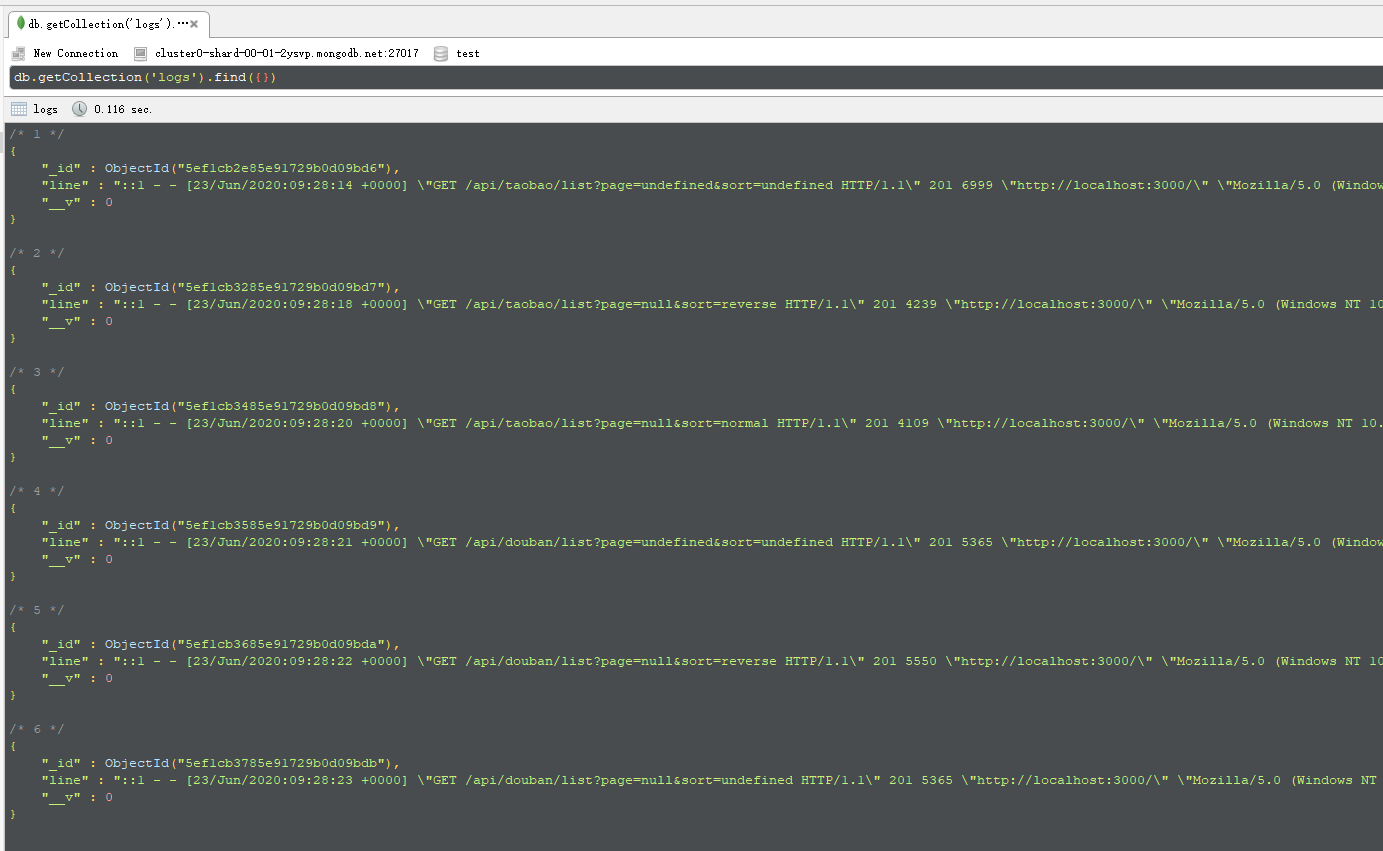
再然后,我们利用morgan把日志记录在 mongodb当中。
首先我们在models文件夹下新建log.js
为了方便起见,我就不掐头去尾了。直接记录整条日志
1 | // models/log.js |
然后我们在sever.js中引入
1 | const logger = require("morgan"); |
这样,我们就在mongodb中记录下了日志了.
阶段4
最后,学习了助教的代码之后,我们可以把这些日志记录在mysql当中
1 | const logger = require("morgan"); |
logDao.js
1 | // 用于存放用户操作记录 日志 |
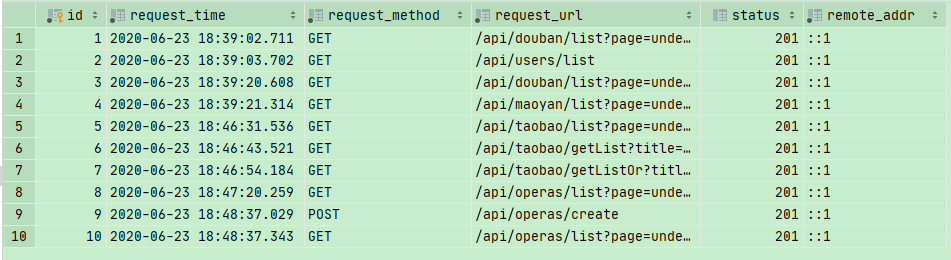
POST 是新建operas操作
config.js
1 | module.exports = { |
routes目录
api-routes.js
api-routes是所有的路由的集合,这里省区了/api/users前面的/api,因为在server.js中已经写了前缀/api
1 | const express = require('express'); |
下面介绍user-router和以豆瓣为代表的douban.js,这个几个文件的作用主要是定义api接口,然后通过api-routes来集成
user-router.js
user-router主要解决的是用户的登录和注册,管理员的删除用户操作。为了让文件的层次解构鲜明,具体的操作在controller中实现,这里只是解构了controller中的函数并引用。
具体的api功能我在controller会详细解释
1 | const express = require('express'); |
douban.js
具体的api功能我在controller会详细解释
首先我们从controller中解构我们需要的函数,然后再路由触发的时候调用这些函数
1 | const express = require('express'); |
models目录
schema
就是表格,利用mongoose创建一张表格来存放从数据库中获得的信息。所以这里的表格要和数据库中的表格一样
imestamps:true
timestamps选项会在创建文档时自动生成createAt和updateAt两个字段,值都为系统当前时间。并且在更新文档时自动更新updateAt字段的值为系统当前时间 .ture代表了使用默认的字段名
在Mongoose中,定义数据库model schemas时使用timestamps选项可以给我们带来许多便利。在创建文档时不用在代码中去指定createTime字段的值,在更新文档时也不用去修改updateTime字段的值。
Model
是由Schema编译而成的假想(fancy)构造器,具有抽象属性和行为。Model的每一个实例(instance)就是一个document。document可以保存到数据库和对数据库进行操作。
也就是说,model是用来选择集合的。
也就是说,我在云端有一张数据表叫Users,我想把里面的数据申请到本地。所以我们在本地需要建一张一模一样的表格来用以存放。但是我在这张表格中所做的增删改查,都会在数据库中同步。这就是model的用法。
user.js
1 | const mongoose = require('mongoose'); |
douban.js
1 | const mongoose = require('mongoose'); |
controller目录
想了解基本的CRUD操作 可以看我的博客 Nodejs基础2中的CRUD Operations Using Mongoose
里面详细介绍了增删改查的各种model. 方法
user.js
我从model/user中导入了这张在数据库中的User表格。现在我们就可以对他进行我需要的后端操作了。
login
首先是登录。前端会发一个request过来,我把里面的req.body当作我的target到User表格中去寻找,然后把结果赋值给user.如果user不存在,说明表格中不存在这一号人物,那当然返回一条name or password incorrect的json格式的信息。
1 | const jsonwebtoken = require('jsonwebtoken'); |
register
注册函数,就是我们从前端发来的req.body解构出name,然后我们查询一下User表格中是否存在这个人,如果存在,那么就返回一条json格式的user already exist。如果名字是admin的话,我们就向这个人的信息中添加auth=1 来证明他是管理员。其余的,我们就利用model.create方法来创建这条记录,然后返回一个user的信息
1 | // 注册 |
getInfo
获取user的信息。返回一条json格式的信息
1 | async getInfo(req, res) { |
findAll
把所有的user信息全部找到然后全部以json格式返回
1 | async findAll(req, res) { |
delete
删除操作,也就是管理员才能执行的删除用户的信息。
利用model.findByIdAndRemove方法来找到前端发来的request中的参数中的id信息,然后删除它并把删除的信息返回给一个result。再利用json的形式把result 映射data后传回
1 | async delete(req, res) { |
douban.js
我从model/douban中导入了这张在数据库中的DouBan表格。现在我们就可以对他进行我需要的后端操作了。
getAll
1 | async getAll(req, res) { |
findAll
这是前端显示数据是会用到的一个api
首先我们从request中解析出传过来的per_page也就是每页显示的电影条数,和排序的种类(升序or降序or不排序)
如果不排序,那么请求中sort = undefined,那么我们就不进行.sort
否则,我们就进行排序, 1代表升序,-1代表降序
(小插曲):在爬取数据的时候,数字也是按照string类型存储的,导致我一开始都在做字符串排序,1111111是小于9 的,这就很烦。然后我通过了robo 3T对mongodb进行批量修改
1 | db.getCollection('表格名字').find({'类型为string的字段' : { $type : 2 }}).forEach(function(x) { |
1 | db.getCollection('表格名字').find({'类型为string的字段' : { $type : 2 }}).forEach(function(x) { |
这样我们就完成了类型转换,从而可以对数字进行排序。
其次我们来计算per_page的多少,也就是至少为1条
然后我们计算表内总共的数据到底有几条并返回,这个在前端的分页器中需要用到,因为分页器得有总条数才能计算页数
最后我们在表中得到当前页面的信息,需要调过前面page*perpage条信息,然后取perpage条返回
1 | const jsonwebtoken = require('jsonwebtoken'); |
insertMany
这是插入操作,是为了利用postman向云数据库插入信息,在前端并没有用到。
1 | async insertMany(req, res) { |
getListByKey
这是前端布尔查询中的 AND 查询,在这篇博客中React框架在作业当中的应用我已经介绍了我们把数据返回之后前端进行的渲染操作,现在我们来讲讲从前端发来请求后如何在后端获得我想要的信息。
在Nodejs基础2Regular Expressions中我初步讲了正则表达式的使用方法。
首先来看看请求是什么
1 | Api.get(`/douban/getList?${keyWords}`,{...}); |
Object.keys() 方法会返回一个由一个给定对象的自身可枚举属性组成的数组,数组中属性名的排列顺序和正常循环遍历该对象时返回的顺序一致 。
$regex 为模糊查询的字符串提供正则表达式功能
首先我们建立一个params对象,这个对象中将存放寻找的条件。
然后我们利用forEach循环,对req.query里面,也就是前端传回来的条件(2个条件)进行操作
eval() 函数可计算某个字符串,并执行其中的的 JavaScript 代码。
${表达式du}用来输出或者计算一个表达式的内容值
比如 ${3+5},那么便会在页面上输出8
比如前端传来的是 电影名字:的 AND 评分:7
这时候item就是这个query的可枚举属性,也就是电影名字和评分
所及操作好以后结果如下:
1 | params = { |
然后用params作为查找条件到豆瓣这张表里去查
1 | async getListByKey(req, res) { |
getListByOr
这是前端布尔查询中的 OR 查询,
在Nodejs基础2Logical Query Operators中我已经讲了or操作的符是要传入一个对象数组的。所以这里我做的工作就是把上面已经求好的params转换成一个对象数组。
同样还是用到了Object.keys方法,我们把params对象转换成params2对象数组
最后就把这个传入到 $or 键值对后面即可
也可以 DouBan.or(params2);
这样我们返回的数据就是择一满足的了
1 | params2=[ |
1 | async getListByOr(req, res) { |
operas.js
因为已经完成基本操作了,现在我们就拓展一下内容,做一个新建operas 的操作(其实也hin简单)
前端实现请看 ,这里讲一下后端收到前端发来的表单请求该怎么把这条新建的信息插入到mongodb当中去?
我们知道所有的信息都藏在 req.body当中,那么我们只要用 . 把他们都提取出来,然后新建一个Operas对象即可
最后通过opera.save()来实现保存操作
1 | async create(req, res) { |
middleware目录
auth-handlers
这是用来认证的一个中间件,中间件的写法我在 Nodejs基础1的Middleware章节 中详细说了,这里简单讲一下他的逻辑
就是判断请求体重user的名字是不是admin,如果是的话,什么也不做,把控制权交给下一个中间件或者函数
如果不是的话,那就返回一个状态码500
1 | const User = require('../models/user'); |
error-handlers
这是一个开源的检查错误的文档。里面集成了一些中间件
我们主要用它来检查 异步操作的问题,验证路由,和用户验证的问题
1 | /** |