PostgreSql基础
学习视频:
https://www.youtube.com/watch?v=FFo8pH-kfQ8&list=PLwvrYc43l1MxAEOI_KwGe8l42uJxMoKeS&index=6
首先我们下载Postgresql11
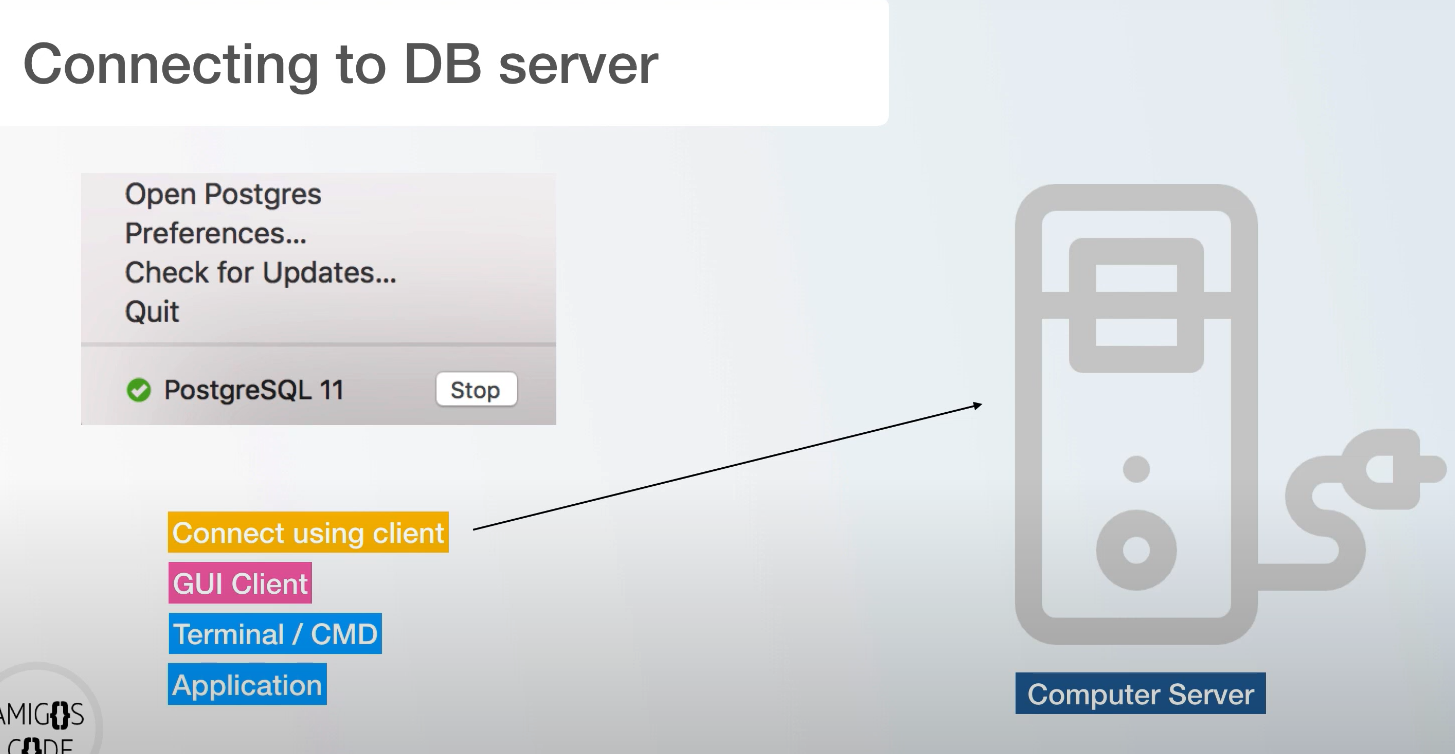
GUI Clients vs Terminal/CMD Clients
链接postgresql的方法有好几种,我们这里使用在终端链接并操作,因为这样能够“吃得苦中苦“ 而且当我链接远程postgresql的时候会更加得心应手
连接工具的话,我们当前的DataGrip是一个不错的选择。当然可以用Postgresql自己的pgadmin
Setup PSQL (Windows)
使用 SQL shell的时候
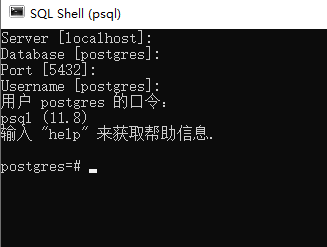
因为我们是在本地测试,所以我们直接选择默认的即可。 用户 postgres 的口令即我们安装时设置的密码
使用 pgAdmin的话就是傻瓜操作了
How to Create Database
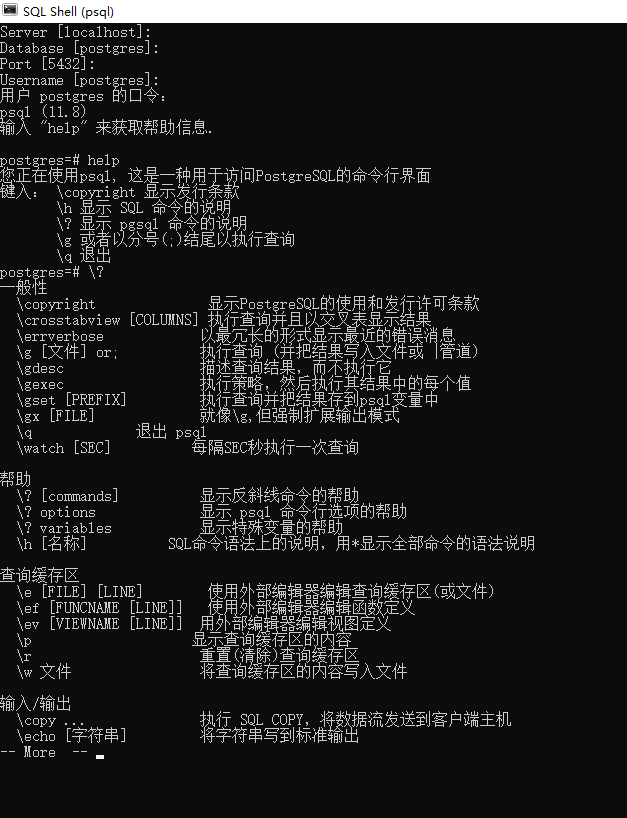
\? 代表着 获取提示
\l 时显示当前所有的数据库列表的
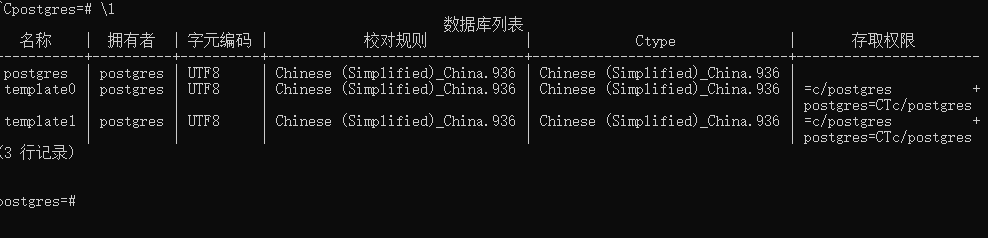
我们可以创建自己的database
1 | postgres=# CREATE DATABASE test; |

How to Connect to Databases
我们有两种方法连接数据库
psql —help 来获取帮助:

连接到刚才的test数据库,我们可以采用这样的方法: psql -h localhost -p 5432 -U postgres test
还有一种则更加方便:
1 | postgres=# \c test |
A Very Dangerous Command
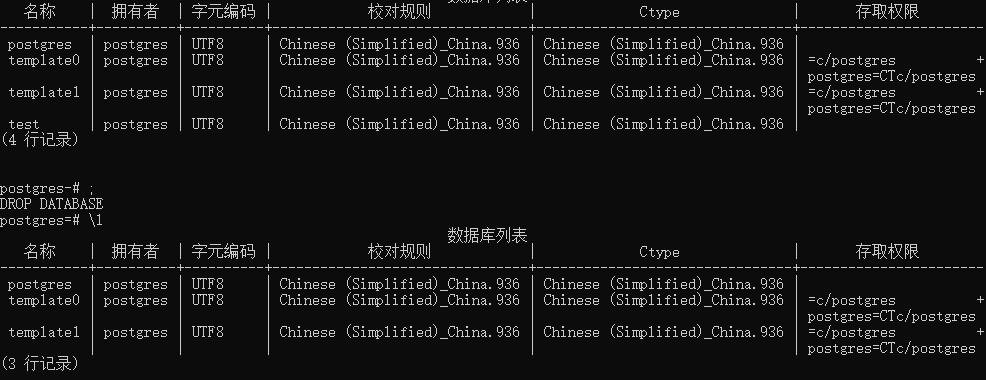
我们应该注意一行非常危险的命令: 删除库命令
删除库: DROP DATABASE test;
注意所有语句必须加上分号!
How To Create Tables
简历表格的模板:
1 | CREATE TABLE table_name( |
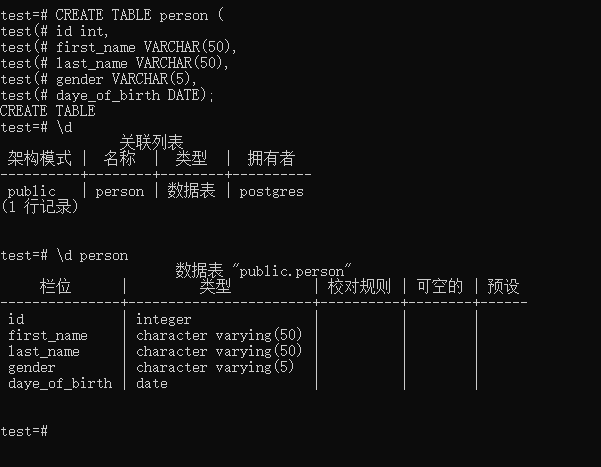
然后我们具体实现一个 关于人的表格
在里面我们定义了5个字段,id是Interger类型,first_name,last_name,gender 都是VARCHAR类型的,date_of_birth 是TIMESTAMP(包括日期和时分秒)或者DATE(仅有日期)
1 | CREATE TABLE person ( |
https://www.postgresql.org/docs/11/datatype.html 这是postgre 的文档,里面有所有的数据类型
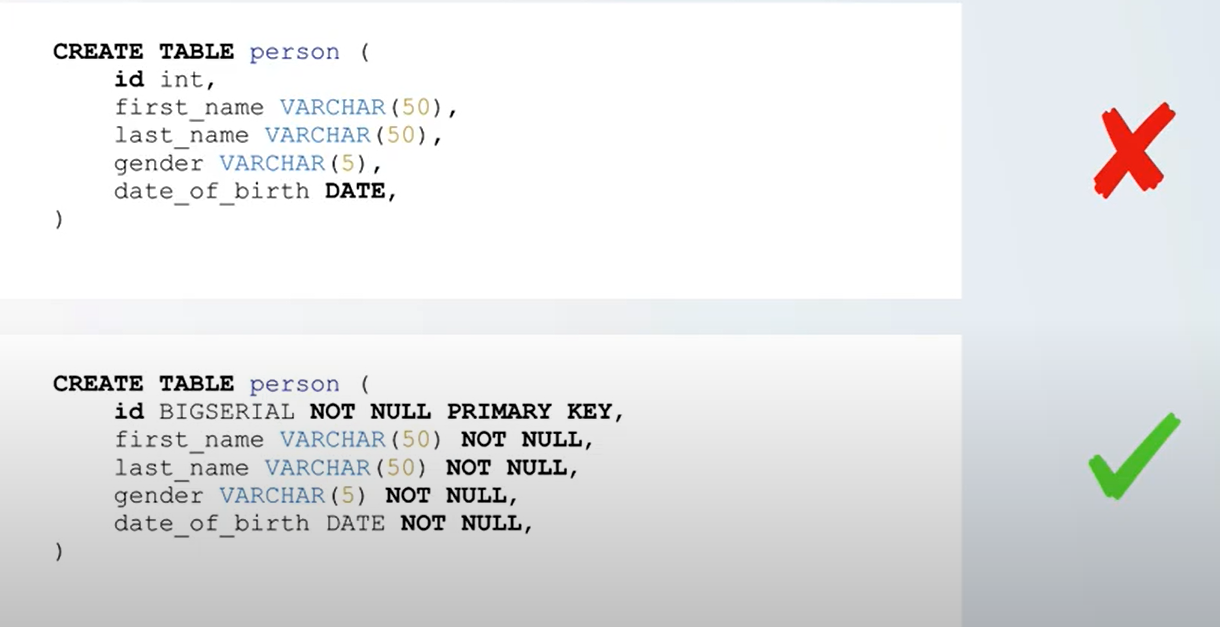
Creating Tables Without Constraint
Creating Tables with Constraints
我们刚才没有写任何校对规则,这就导致这张数据表不是很安全.我们想添加一些额外的限制条件到我们的表格当中。让插入的信息能够满足一些条件。因为我们不想让一个人没有id,没有名字,没有出生日期就被插入到这个表格当中去了。
所以我们需要在字段之后加入一些 constraints如下图所示
1 | CREATE TABLE person ( |
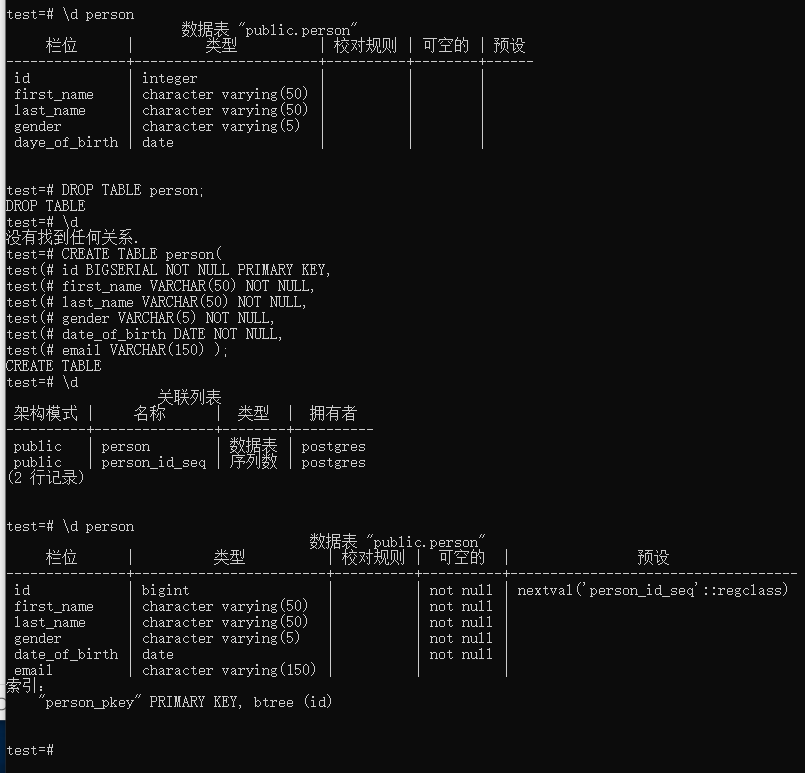
我们设置id 是一个BIGSERIAL,也就是说它可以自动增长的,那么表建立以后发现有一个person_id_seq,他其实只是一个序列,并不是一张表格 我们可以用 \dt 来只显示table
Insert Into
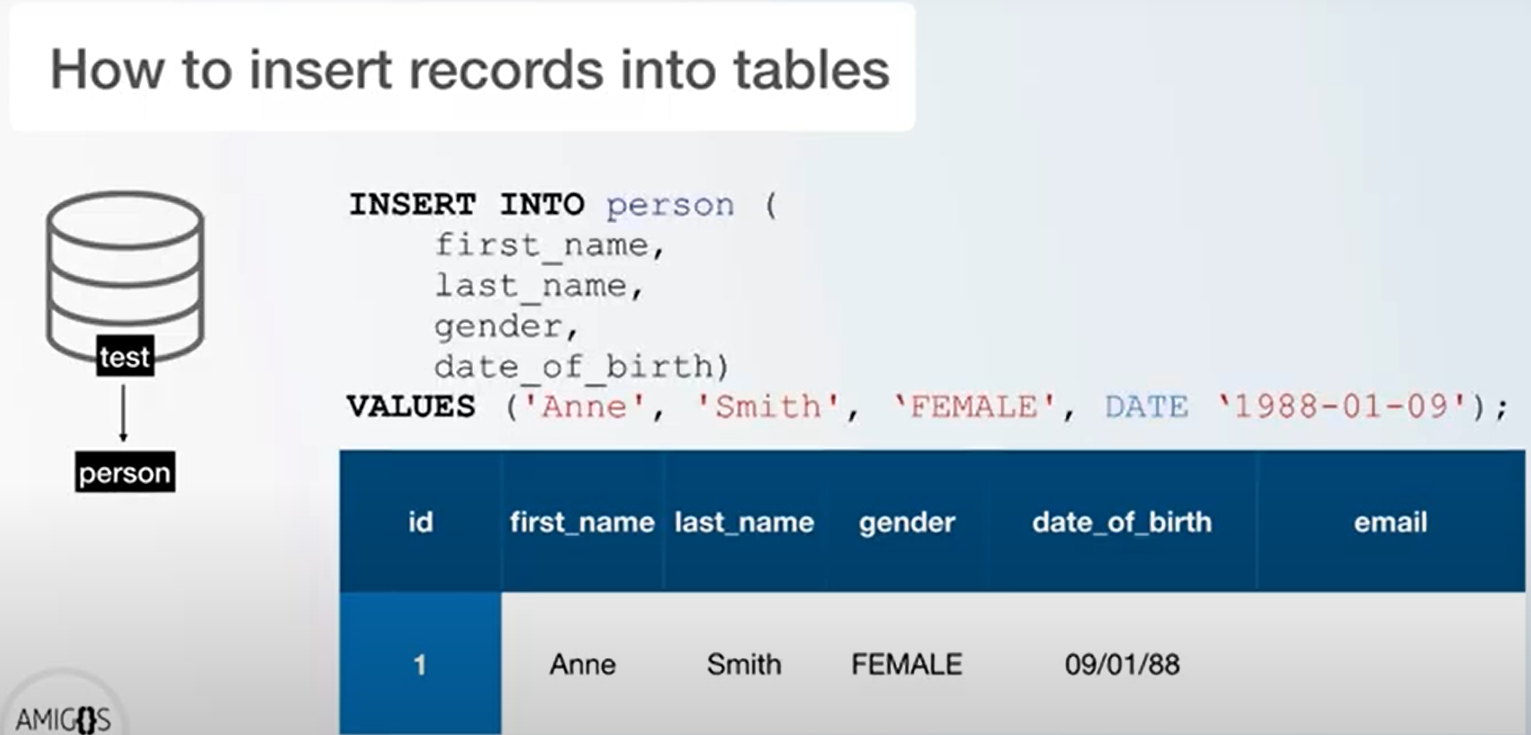
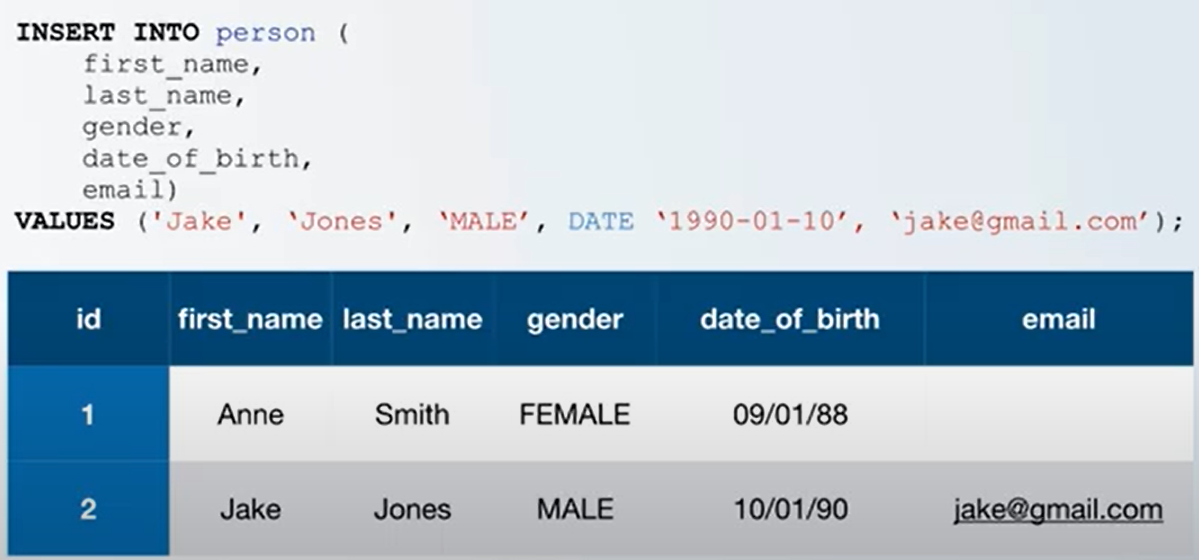
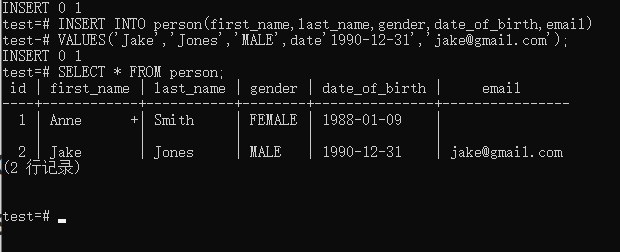
Insert Into Example
Generate 1000 Rows with Mockaroo
刚才我们添加了两条数据,现在我们添加1000条数据试试
https://mockaroo.com/ 我们需要用这个网站帮我们生成数据
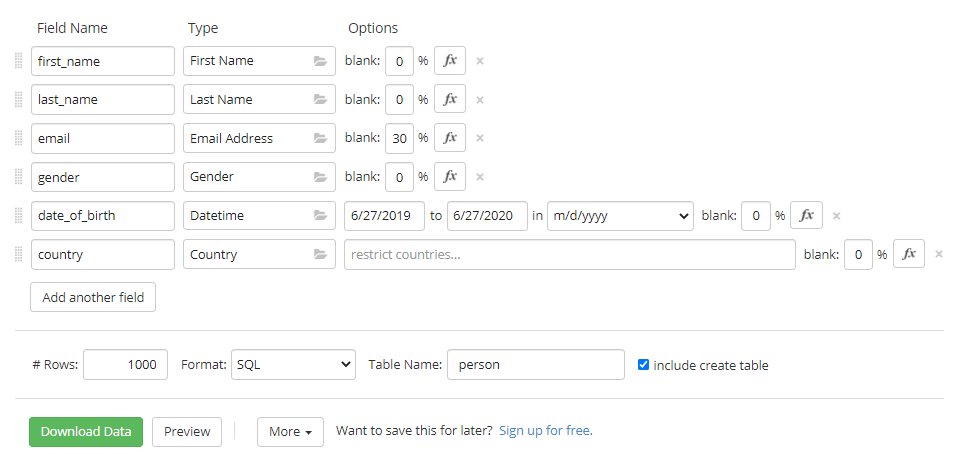
我们选择SQL格式,然后点击Download Data,这样就生成了我们的1000条数据
我们可以通过 \i FILEPATH 来导入一个sql文件,这回大大减少我们的工作
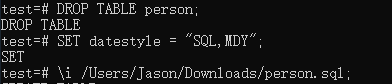
我们插入的时候 date是这样的 : ‘1/29/2020’ 是 “月/日/年”的类型,所以我们要设置 datestyle = “SQL,MDY”
Select From
Order By
Distinct
为了不重复:
SELECT DISTINCT state FROM customers
SELECT country_of_birth FROM person ORDER BY country_of_birth
Where Clause and AND
Comparison Operators
此外还可以用 > ,<,>=,<=,=,!=,<> 其中<>也是不等于的意思
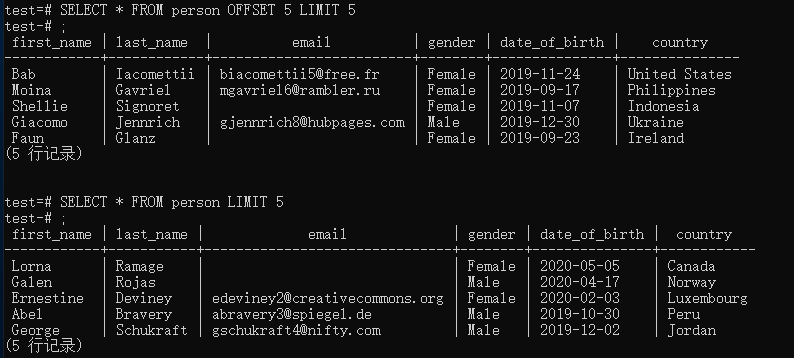
Limit, Offset & Fetch
Offset 是跳过前面多少条数据的意思:
1 | SELECT * FROM person OFFSET 5 LIMIT 5 |
用 FETCH 也可以达到LIMIT的功能:
SELECT * FROM person OFFSET 5 FETCH FIRST ROW ONLY = SELECT * FROM person OFFSET 5 LIMIT 1
IN
Between
Like And iLike
ILIKE 的意思是不区分大小写的LIKE
Group By
Group By Having
Adding New Table And Data Using Mockaroo
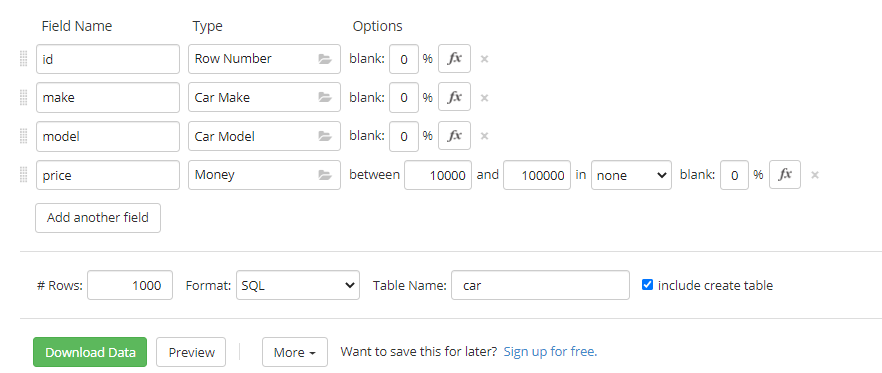
Calculating Min, Max & Average
Sum
1 | SELECT SUM(price) FROM car; |
Basics of Arithmetic Operators
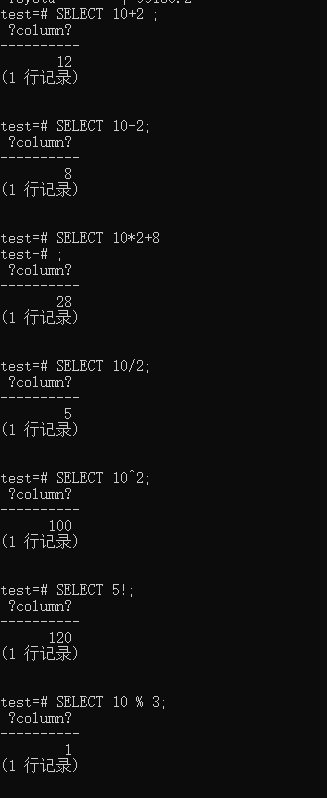
Arithmetic Operators (ROUND)
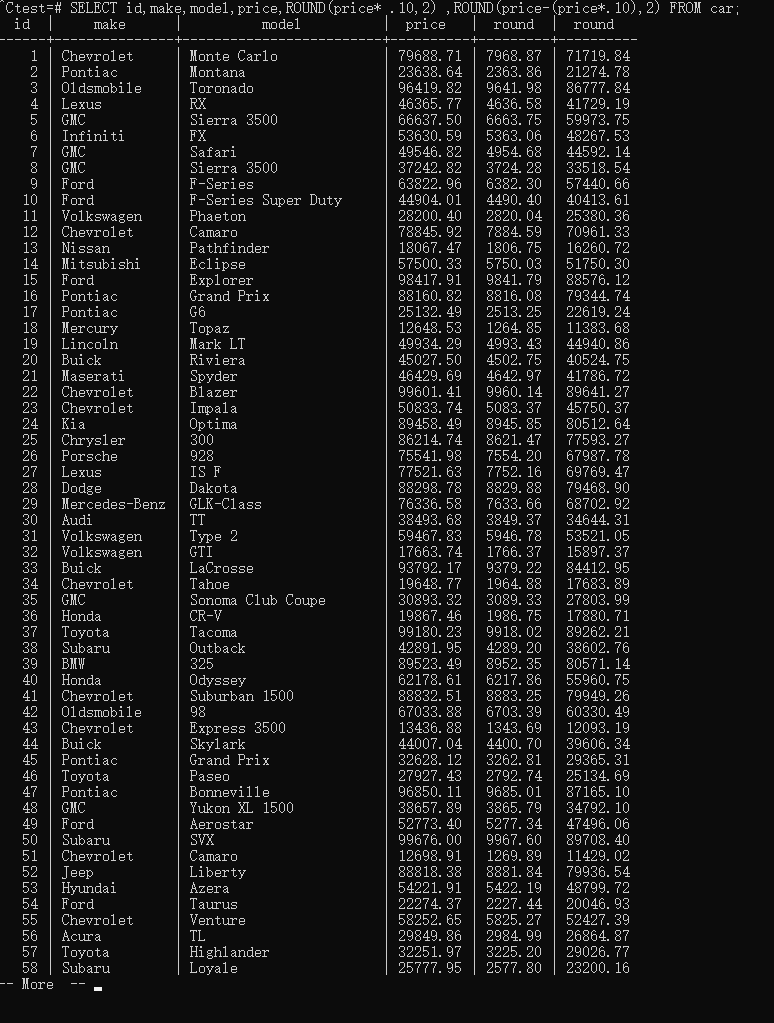
注意,要能够使用ROUND函数,我们需要把字段设置成 NUMERIC(19,2)
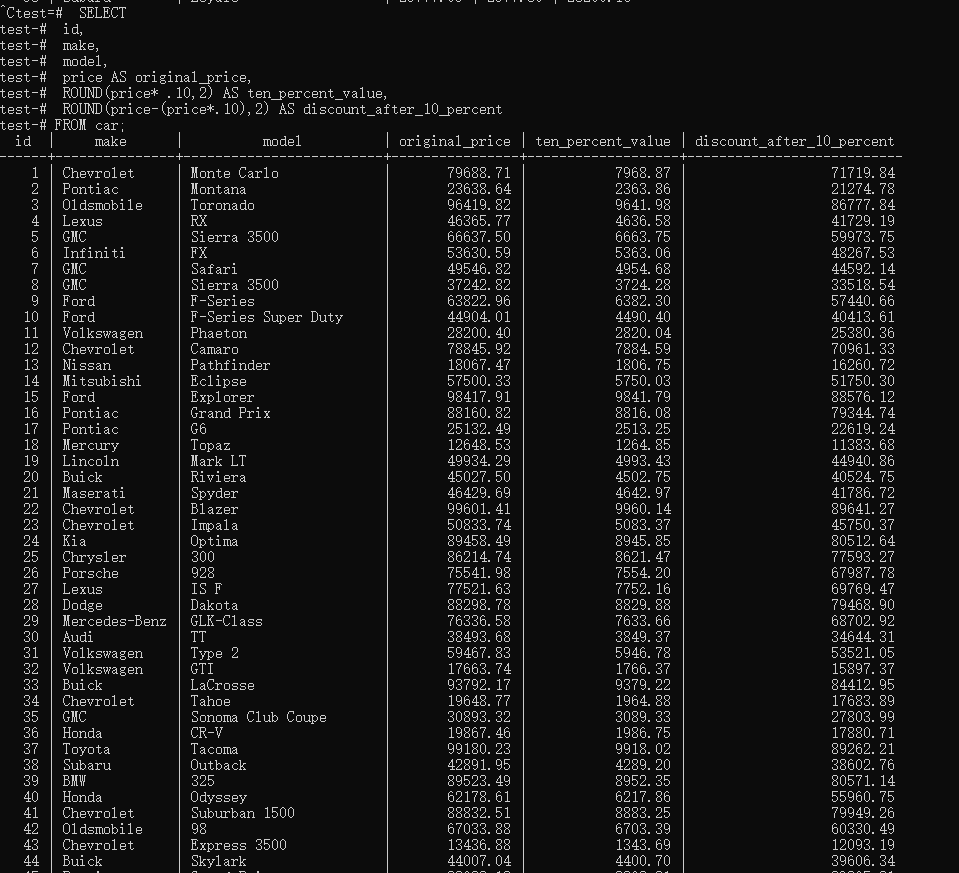
1 | SELECT id,make,model,price,ROUND(price* .10,2) ,ROUND(price-(price*.10),2) FROM car; |
Alias
1 | SELECT |
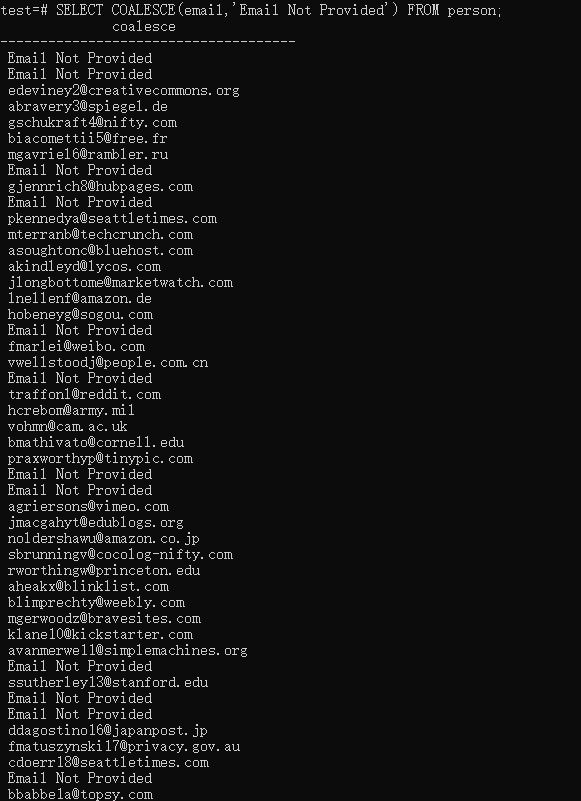
Coalesce
The IFNULL and COALESCE Function
1 | SELECT COALESCE(email,'Email Not Provided') FROM person; |
NULLIF
那么如果我在计算时出现了 分母为0的数字, 比如说SELECT 10/0;
postgresql会报错: ERROR division by zero;
而 SELECT 10/null 那么就不会报错,所以null在除法的时候比0更安全
为了解决这个问题,我们需要写NULLIF 关键词. NULLIF(0,0) 这个值为NULL,NULLIF(0,10) 这样是0
1 | SELECT COALESCE(10/NULLIF(0,0),0); |
Timestamps And Dates Course
TimeStamps在数据库当中是比较重要的
1 | test=# SELECT NOW(); |
Adding And Subtracting With Dates
1 | test=# SELECT NOW()-INTERVAL '10 YEAR'; |
Extracting Fields From Timestamp
比如我们希望把YEAR单独拿出来 需要用到EXTRACT方法
1 |
|
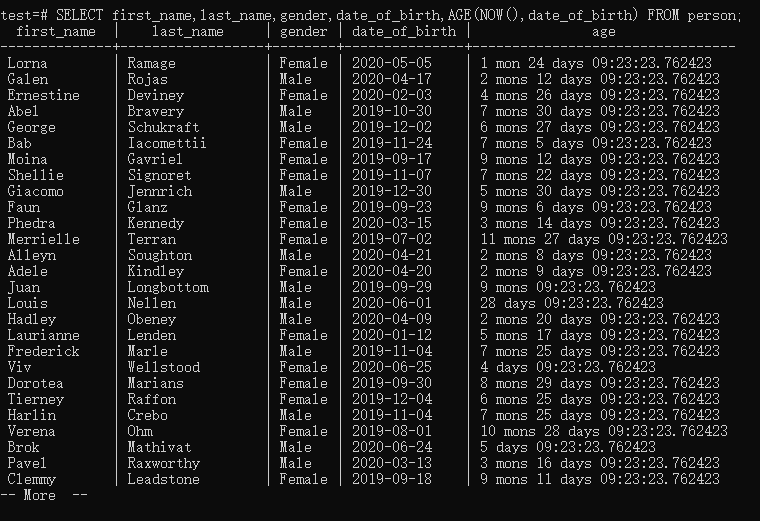
Age Function
AGE() 可以自动计算现在到某一时间的时间段。常用来计算年龄。 第一个参数是NOW() ,代表现在的时间;第二个参数一般是过去的一个日期,常常是人的出生年月
1 | SELECT first_name,last_name,gender,date_of_birth,AGE(NOW(),date_of_birth) FROM person; |
What Are Primary Keys
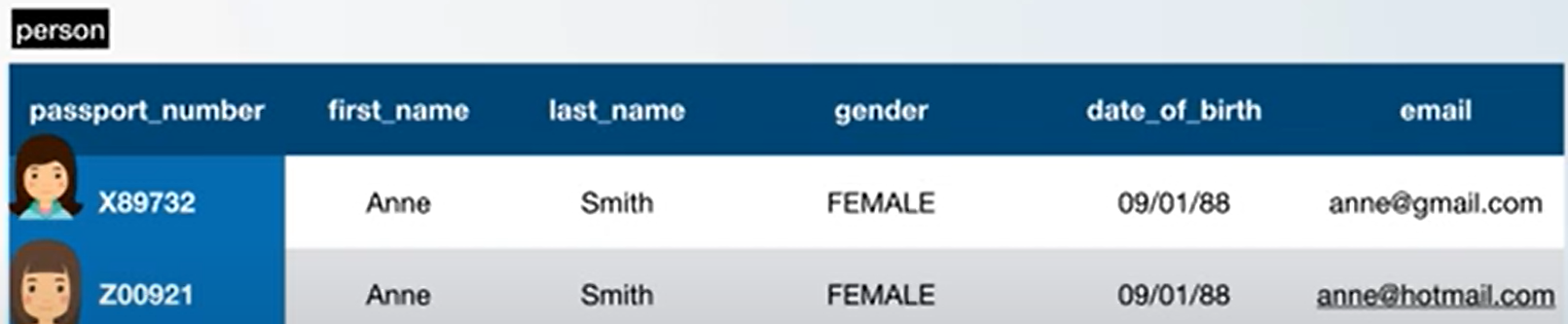
主键(PK)是对每一条信息都独一无二的
主键可以为很多形式,也有很多的数据类型可以充当主键。现在 Bigserial 已经足够了
Understanding Primary Keys

如果我们尝试插入一条信息:主键与表中信息重复,那么会发生什么结果?
test=# insert into person (id, first_name, last_name, email, gender, date_of_birth, country_of_birth) values (1, ‘Kirbee’, ‘Lampitt’, ‘klampitt0@so-net.ne.jp’, ‘Female’, ‘27/7/1995’, ‘Kazakhstan’);
错误: 重复键违反唯一约束”person_pkey”
描述: 键值”(id)=(1)” 已经存在
现在我们修改表格,把id的主键地位去掉,然后再试试,会发生什么结果呢?
1 | ALTER TABLE person DROP CONSTRAINT person_pkey; |

Adding Primary Key
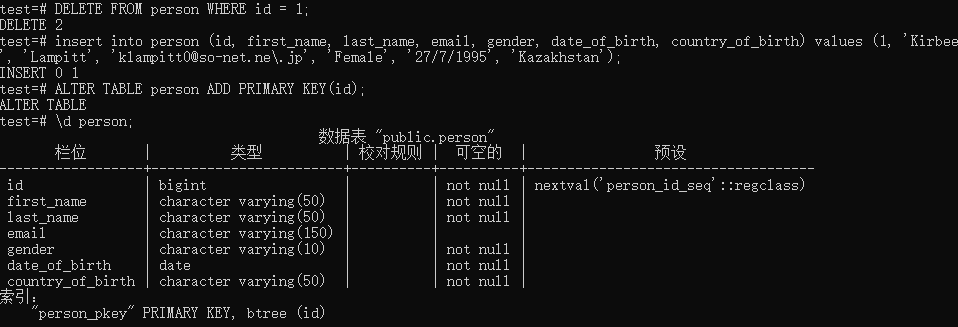
删除主键是 DROP CONSTRAINT person_pkey; 那么添加主键是 ADD PRIMARY KEY() 我们可以设置多个字段同时为主键。比如说我们设置三个字段为主键,那么任意连那个条信息,这三个字段都不能相等,但是两个字段可以相等
现在我们尝试把主键CONSTRAINT加上去,但是会发生什么?
test=# ALTER TABLE person ADD PRIMARY KEY(id);
错误: 无法创建唯一索引”person_pkey”
描述: 键值(id)=(1)重复了
所以,我们先删除
1 | DELETE FROM person WHERE id = 1; |
Unique Constraints
Unique Constraints allow us to have unique values for a given column
比如说,我现在有两个邮箱一模一样的人,那么当我们发送邮件的时候,我们就不知道发给谁了。所以我们需要把邮件设置为UNIQUE。
test=# ALTER TABLE person ADD CONSTRAINT unique_email_address UNIQUE (email);
ALTER TABLE

现在我们来插入一个邮件和库中某一个人一样的信息
test=# insert into person (id, first_name, last_name, email, gender, date_of_birth, country_of_birth) values (1001, ‘Doris’, ‘Carayol’, ‘dcarayol1@lulu.com’, ‘Female’, ‘8/9/1974’, ‘China’);
错误: 重复键违反唯一约束”unique_email_address”
描述: 键值”(email)=(dcarayol1@lulu.com)” 已经存在
当然,我们也可以简化添加 CONSTRAINT的方法,也就是让postgres自动帮我生成 CONSTRAINT的名字
ALTER TABLE person ADD UNIQUE(email);
这个constraint的 就变成
“person_email_key” UNIQUE CONSTRAINT,btree(email)
Check Constraints
Check constraint allows us to add a constraint based on a boolean condition
比如我新插入一条信息:
insert into person (id, first_name, last_name, email, gender, date_of_birth, country_of_birth) values (1002, ‘Theressa’, ‘Mounsie’, ‘HELLO2@icio.us’, ‘HELLO’, ‘22/2/1980’, ‘Mexico’);
我们把他的信息改成了: gender : HELLO ,但是我们还是能成功插入,这就乱了套了
所以我们需要添加 Check Constraint 这样能让gender字段中输入的字符串,要么是Female,要么是 Male
语法就是 CHECK(字段名=’ ‘ OR 字段名 = ‘ ’ ……)可以添加很多
test=# ALTER TABLE person ADD CONSTRAINT gender_constraint CHECK(gender = ‘Female’ OR gender = ‘Male’);
ALTER TABLE
这样我们尝试插入的时候,
test=# insert into person (id, first_name, last_name, email, gender, date_of_birth, country_of_birth) values (1002, ‘Theressa’, ‘Mounsie’, ‘HELLO2@icio.us’, ‘HELLO’, ‘22/2/1980’, ‘Mexico’);
错误: 关系 “person” 的新列违反了检查约束 “gender_constraint”
描述: 失败, 行包含(1002, Theressa, Mounsie, HELLO2@icio.us, HELLO, 22/02/1980, Mexico).
How to Delete Records
test=# DELETE FROM person WHERE id = 11;
DELETE 1DELETE FROM person WHERE gender = ‘Female’ AND country_of_birth =’Nigeria’;
请注意: DELETE FROM person 非常非常危险,他会删除表中的所有数据
How to Update Records
例子:
UPDATE person SET email = ‘ommar@gmail.com’ WHERE id = 9; 单行更新
UPDATE person SET email = ‘ommar@gmail.com’ WHERE id < 9; 多行更新
UPDATE person SET first_name = ‘Omar’, last_name =’Montana’ , email =”Montana@gmail.com”;多列更新
On Conflict Do Nothing
当我们想新插入一条信息的时候,如果信息中的某些字段与设为主键或者有Unique constraints的字段重复的时候,postgres会报错。这时候我们需要ON CONFLICT 关键字,ON COFLICT (字段名)会检测该字段输入的信息是否重复,如果重复,就显示插入失败。前提是这个字段是主键或者有constraints
例子:
test=# INSERT INTO person(id,first_name,last_name,gender,email,date_of_birth ,country_of_birth) VALUES(7,’Russ’, ‘Ruddoch’,’Male’,’rruddoch7@hhs.gov’,DATE ‘1952-09-25’ , ‘Norway’ ) ON CONFLICT (id) DO NOTHING;
INSERT 0 0
如果我输入了一个既不是主键,有没有constraints的字段
test=# INSERT INTO person(id,first_name,last_name,gender,email,date_of_birth ,country_of_birth) VALUES(7,’Russ’, ‘Ruddoch’,’Male’,’rruddoch7@hhs.gov’,DATE ‘1952-09-25’ , ‘Norway’ ) ON CONFLICT (first_name) DO NOTHING;
错误: 没有匹配ON CONFLICT说明的唯一或者排除约束
Upsert
当用户第一次发送多个表单过来,我么需要对表单的内容进行更新。这种情况往往只需要更新一个或者两个字段即可
所以我们需要把DO NOTHING 变成 DO UPDATE SET 字段 = EXCLUDED.字段,字段 = EXCLUDE.字段,……
test=# INSERT INTO person(id,first_name,last_name,gender,email,date_of_birth ,country_of_birth) VALUES(1927,’Russ’, ‘Ruddoch’,’Male’,’rruddoch7@hhs.gov.uk‘,DATE ‘1952-09-25’ , ‘Norway’ ) ON CONFLICT (id) DO UPDATE SET email= EXCLUDED.email;
INSERT 0 1
test=# SELECT * FROM person WHERE id = 1927;
1927 | Russ | Ruddoch | rruddoch7@hhs.gov.uk | Male | 1952-09-25 | Norway
(1 行记录)
这个语句和更新不同,如果这条信息(根据id判断)已经存在了,那么就更新信息;否则就新建这条信息。而UPDATE仅仅更新已经存在的信息。
What Is A Relationship/Foreign Keys
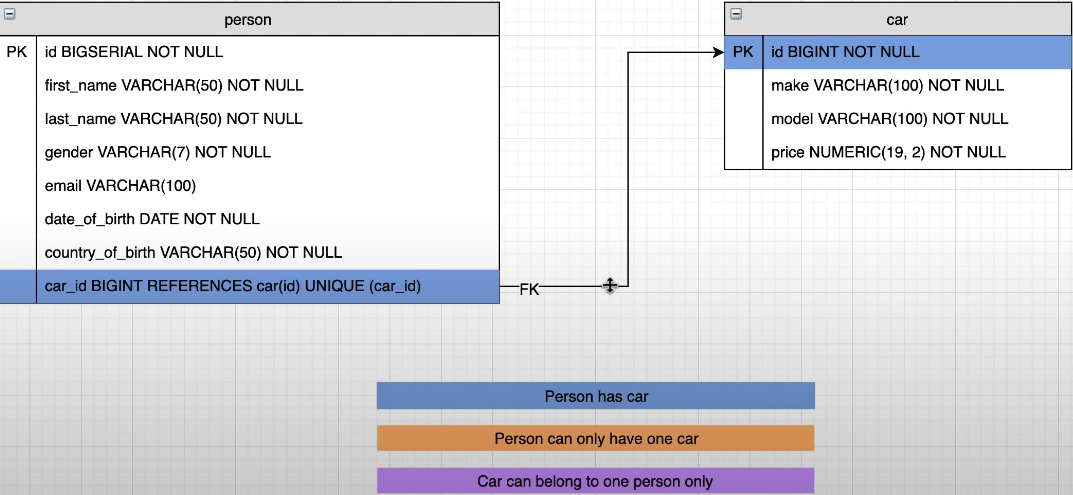
Adding Relationship Between Tables
删除car表和person表,在这里下载 person-car.sql:
https://drive.google.com/drive/folders/1v0I19Ed2his8otHRLm5i6W7feD9sIMc6
进行一些修改,在person中加入一个foreign key: car_id 让其和car表当中的id字段相联系:
然后新建两张表即可
1 | create table car ( |
Updating Foreign Keys Columns

我们需要为person表添加car_id 这个列
UPDATE person SET car_id = 1 WHERE id = 2;
UPDATE person SET car_id = 2 WHERE id = 1;

如果我插入了car表中不存在的id
test=# UPDATE person SET car_id =3 WHERE id= 1;
错误: 插入或更新表 “person” 违反外键约束 “person_car_id_fkey”
描述: 键值对(car_id)=(3)没有在表”car”中出现.
Inner Joins

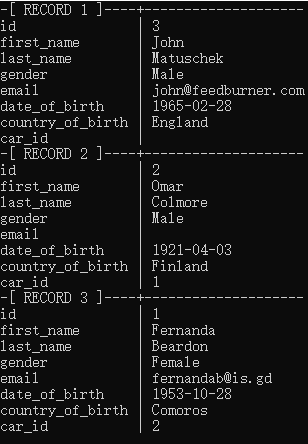
test=# SELECT * FROM person
test-# JOIN car ON person.car_id = car.id;

test=# SELECT person.first_name,car.make,car.model,car.price FROM person JOIN car ON person.car_id = car.id;
first_name | make | model | price
——————+——————+—————+—————
Omar | Land Rover | Sterling | 87665.38
Fernanda | GMC | Acadia | 17662.69
(2 行记录)
注: \x 可以关闭或开启扩展,让数据以表格的方式展示或者以列的方式展示
Left Joins

SELECT * FROM person LEFT JOIN car ON car.id = person.car_id;

Deleting Records With Foreign Keys
我们现在想删除car中的id= 13的一条信息(已经和person绑定了)我们发现直接删除的话会报错:
test=# DELETE FROM car WHERE id = 13;
错误: 在 “car” 上的更新或删除操作违反了在 “person” 上的外键约束 “person_car_id_fkey”
描述: 键值对(id)=(13)仍然是从表”person”引用的.
我们必须先删除person中和这条car的信息绑定的person信息,才能成功删除:
test=# DELETE FROM person WHERE id = 9000;
DELETE 1
test=# DELETE FROM car WHERE id = 13;
DELETE 1
我们可以选择 CASCADING 但是太危险了,千万别用。
Exporting Query Results to CSV
我们现在把查询到的内容变成CSV文件。
输入/输出
\copy … 执行 SQL COPY,将数据流发送到客户端主机
\echo [字符串] 将字符串写到标准输出
\i 文件 从文件中执行命令
\ir FILE 与 \i类似, 但是相对于当前脚本的位置
\o [文件] 将全部查询结果写入文件或 |管道
\qecho [字符串] 将字符串写到查询输出串流(参考 \o)
我们采用 \copy
test=# \copy (SELECT * FROM person LIMIT 10) TO ‘/Users/Jason/Desktop/results’ DELIMITER ‘,’ CSV HEADER;
COPY 10
桌面上就有一个文件(很奇怪为什么不是.csv需要自己加上后缀名…),但是内容完整
Serial & Sequences
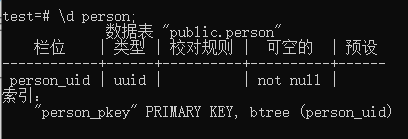
现在我们来了解一下 BIGSERIAL 这个数据类型。当我么设置一个字段的datatype是BIGSERIAL的话,在表格中他是这么存在的
数据表 “public.person”
栏位 | 类型 | 校对规则 | 可空的 | 预设
id | bigint | | not null | nextval(‘person_id_seq’::regclass)
索引:
“person_pkey” PRIMARY KEY, btree (id)SELECT * FROM person_id_seq;
Extensions
查看扩展列表需要在postgres文件夹下敲入条语句
SELECT * FROM pg_available_extensions;
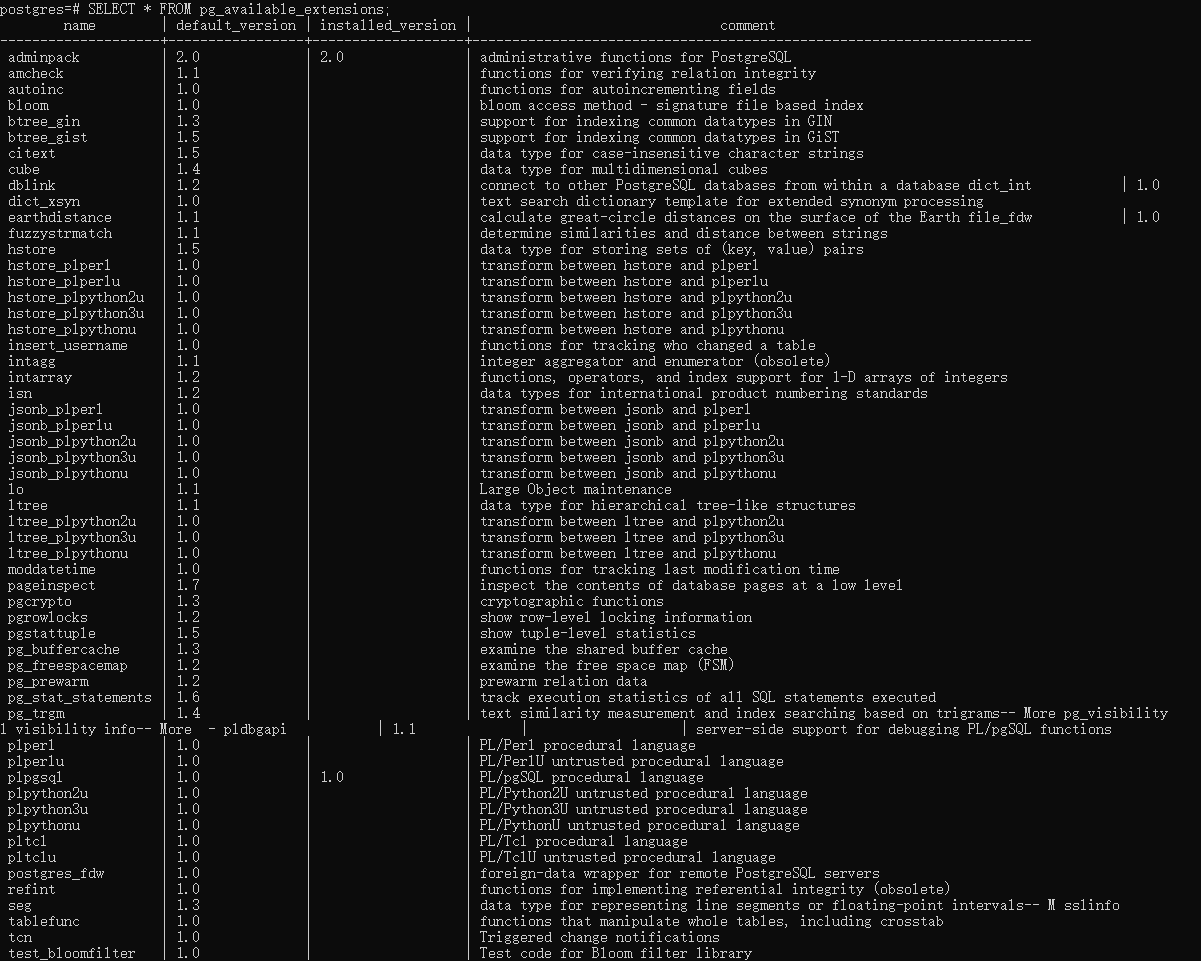
每个扩展的名字,版本,简短的作用都一一对应
接下来我们着重了解一下uuid-ossp 其作用是 generate universally unique identifiers (UUIDs)
Understanding UUID Data Type
https://en.wikipedia.org/wiki/Universally_unique_identifier
我们用 下面的语句来添加扩展
CREATE EXTENSION IF NOT EXISTS “uuid-oosp”;

我们试试这些函数
test=# SELECT uuid_generate_v4();
uuid_generate_v4
4f734c86-2b8a-46ea-bd12-8a19d666839f
(1 行记录)
使用uuid ,可以让 攻击者很难攻破我们的数据库。而且,当我们需要把数据库A中的部分数据插入到数据库B当中,如果数据类型是 BIGSERIAL的话,很容易导致主键重复而无法插入。但是uuid是不可能相等的,所以可以放心插入。这是使用uuid的优点
UUID As Primary Keys
1 | create table person( |
test=# create table person(
test(# person_uid UUID NOT NULL PRIMARY KEY
test(# );
CREATE TABLE
test=# insert into person(person_uid) values(uuid_generate_v4());
INSERT 0 1
test=# SELECT * FROM person;
person_uid
d55ff522-9121-42f0-a249-fdd0f3071349
(1 行记录)
当我们执行 \x 会关闭extension,再执行\x会重新开启