mysql基础下
承接上文:https://jasonxqh.github.io/2020/05/16/Mysql%E5%9F%BA%E7%A1%80/
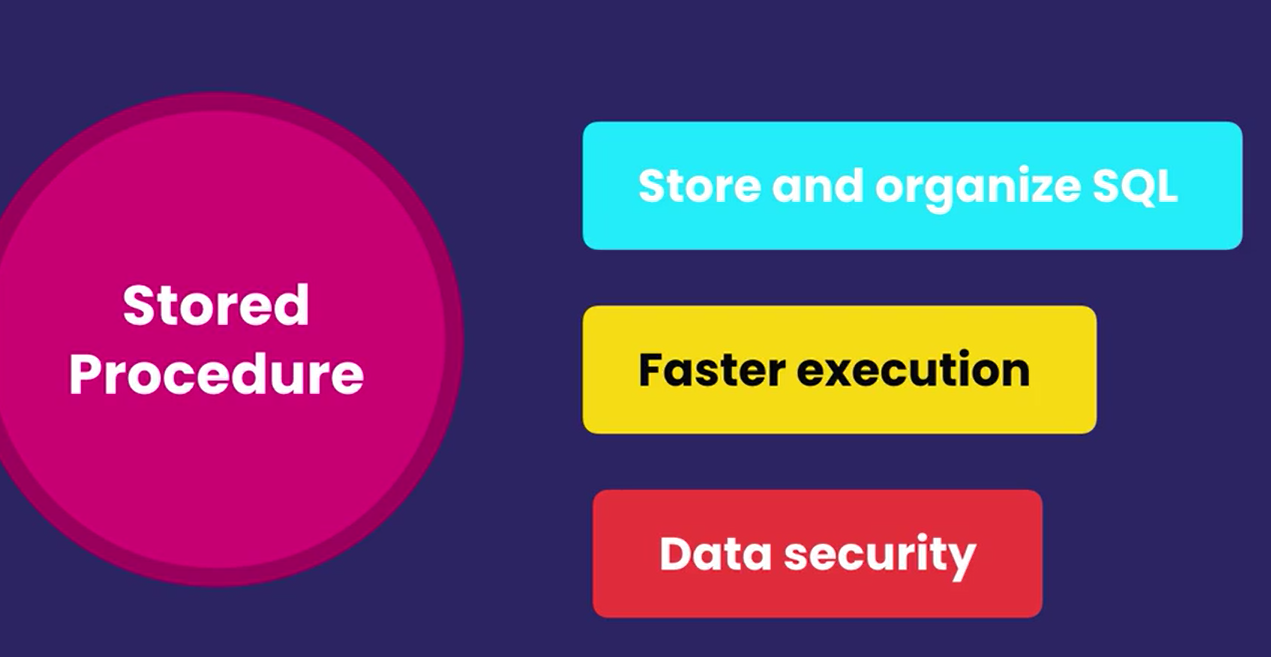
Stored Prodedure
What are Stored Procedures
假设我们在开发一个应用,应用中有一个数据库。那么我们在哪里写SQL语句呢?我们总不能把sql语句和java,C#这种的语句混合着写吧,那么维护起来就很麻烦。另外,一些C# Java的编程语言需要编译工作。如果我们在应用中写这sql语句,那么当我想修改查询语句的时候,会发现需要重新编译,甚至重新部署。所以我们需要把SQL代码和应用的代码分开。把SQL代码存储在它应属的数据库里 :那就是 Stored Prodedure
Stored Prodedure 是一个包含一堆SQL代码的数据库对象。在我们的应用代码里,我们调用这些过程来获取或者保存数据
他还能让查询变得更快。并且它能像View一样,加强数据的安全性.比如我们可以取消所有的表的直接访问权限。让插入、更新、删除数据由存储过程来完成。然后我们指定一个能进行此操作的人。这样可以防止一些用户删除我们的数据。
Creating a Stored Procedure
首先我们想让MYSQL 为这一个这个整体创建一个存储过程叫做 get_clients。我么不想单独执行SELECT * FROM clients,那么我们必须把默认分隔符从分号改成$$(国际公约)然后在END后写两个$ 这相当于告诉mysql这是一个新的分隔符,把这些CREATE PROCEDURE语句看成一个整体。
最后我们需要把默认分隔符改回来: DELIMITER ; 运行后,我么发现他已经成为了一个存储过程了。
1 | DELIMITER $$ |
在query中,我们可以使用CALL语句来调用存储过程: CALL get_clients()
在应用中我们会用python,Java等语言来调用
小练习:
Create a stored procedure called
- get_invoices_with_balance
- to return all the invoices with a balance>0 返回所有结余大于0 的发票
之前我们创建了 invoices_with_balance 的view视图,所以我们直接从这里找,更直观。
1 | DELIMITER $$ |
通过: call sql_invoicing.get_invoices_with_balance()调用
Creating Procedures Using MySQLWorkbench
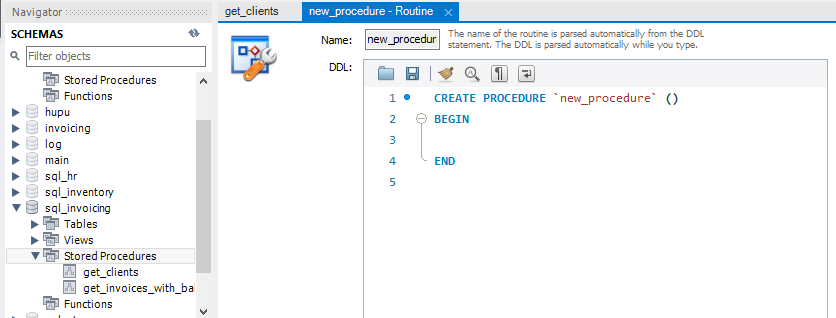
当然我们可以直接右键点击 Stored Procedures ,点击 Create Stored Procedure 然后我们只需要专注于我们的sql语句了。到时候,只要点击下面的apply,workbench就会自动帮我们生成存储过程

Dropping Stored Procedures
1 | DROP PROCEDURE IF EXISTS get_clients; |
我们最好把删除和创建每一个存储过程的代码存储在不同的sql文件当中。并把文件放在Git 中,这样就能和组员共享了。任何人都能可以用他们电脑上的所有相关视图和存储过程来再建这个数据库。
我们建立了一个 存储过程之后可以保存为 一个sql文件,保存在新建的存储视图文件夹之下:
1 | DROP PROCEDURE IF EXISTS get_clients; |
Parameters
现在我们来在存储过程中添加参数。我们一般使用参数为存储过程传递值,我们也可以使用参数为调用程序赋值。
参数写在() 之内。 在这里,我们令state 这个字段名 是一个 长度为2的字符串。注意,如果类型是CHAR, 它只能是长度为特定值,如果我们想要长度可变的值,那么我们需要用VARCHAR
因为我们不能直接 选择 WHERE state = state 所以我们给clients一个别名 c, 这样我们就可以写成 WHERE state = c.state
1 | DROP PROCEDURE IF EXISTS get_clients_by_state; |
小练习:
Write a stored procedure to return invoices
for a given client
get_invoice_by_client
1 | DELIMITER $$ |
Parameters with Default Value
1 | DROP PROCEDURE IF EXISTS get_clients_by_state; |
1 | CALL get_clients_by_state(NULL) |
注意,这里我们还是要传入空的参数NULL,否则mysql会报错
当然,我们也可以默认返回所有客户:我们只需要在IF中写语句即可
1 | DELIMITER $$ |
或者我们可以把两段查询合并成一段:
运用IFNULL 函数,如果第一个值是控制,那个就会返回c.state,也就是把所有的客户都返回
1 | DELIMITER $$ |
小练习:
Write a stored procedure called get_payments
with two parameters
client_id => INT //4字节 ,存储更大的数字
payment_method_id => TINYINT //1字节,存储0-255的数字
如果这两个系数都传递NULL,那么返回数据库里的所有付款记录
如果提供client_id 那么返回这个客户的所有付款
如果client_id 和 payment_method_id 返回指定客户使用指定付款方式支付的所有付款记录
1 | DELIMITER $$ |
Parameter Validation
我们也可以用存储过程来存储、删除、更新数据库当中的信息。在这之前,我们需要进行数据验证。确保我们不会意外存入坏的数据。
那么运用 IF END IF 语句我们可以对输入的数值进行判断。
如果payment_amount <= 0 那么就 SIGNAL (类似于抛出一个异常,try except) 出一个状态码:
状态码详解: https://blog.csdn.net/u014653854/article/details/78986780
并抛出 一个MESSAGE : Invalid payment amount
1 | CREATE DEFINER=`root`@`localhost` PROCEDURE `make_payment`( |

当我们运行这个存储过程并尝试输入一个负值的时候,会出现报错
Output Parameters
我们可以用参数向过程调用者返回数据
一般的,我们在括号中输入的参数都是INPUT variables,意思是我们只能通过它们向存储过程提供数据。我们用OUT来标记需要传出来的参数。这样就约定这些参数是要输出的参数
然后,我们在主体重用invoices_count和invoices)total来接收传递出来的数据,用INTO关键字
1 | CREATE DEFINER=`root`@`localhost` PROCEDURE `get_unpaid_invoices_for_client`( |
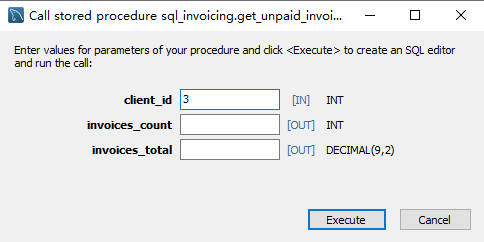
调用后我们有了这样的代码: 首先我们定义了两个变量: invoices_count 和invoices_total 这就是我们说的用户定义变量,这种变量就是可以把数据保存在内存当中的量。定义变量之前需要用@修饰。
然后调用存储过程,并传入三个变量。第一个是传入的,后两个是传出的。 最后我们选择传出的两个变量,显示在表格当中
1 | set @invoices_count = 0; |
比较麻烦,不建议使用
Variables
上面我们定义了User variables,这些变量时使用SET 语句来定义的,并且用@前缀修饰的。这种变量常常出现在有输出变量的存储过程当中.这些变量在整个客户端session周期中都存储在内存当中。当客户端终止与数据库的连接时,那么这些变量就会被释放。
还有一种变量叫做本地变量。这是在存储过程或者函数当中定义的变量。本地变量是不会再session周期保存在内存当中的。只要存储过程运行结束,这些变量就会被释放。大多数时候这些变量用作存储过程中的运算。
1 | CREATE DEFINER=`root`@`localhost` PROCEDURE `get_rist_factor`() |
Functions
我们已经知道了很多built-in 函数了。我们现在可以自己创建函数。但是函数和存储过程是不一样的,因为函数不能返回有行有列的结果集,函数只能返回单一的值。所以如果我们想要得到单一的值,那么可以使用函数。一个比较好的例子就是上面我们得到的 risk_factor.我们现在为每一个用户得到一个risk_factor
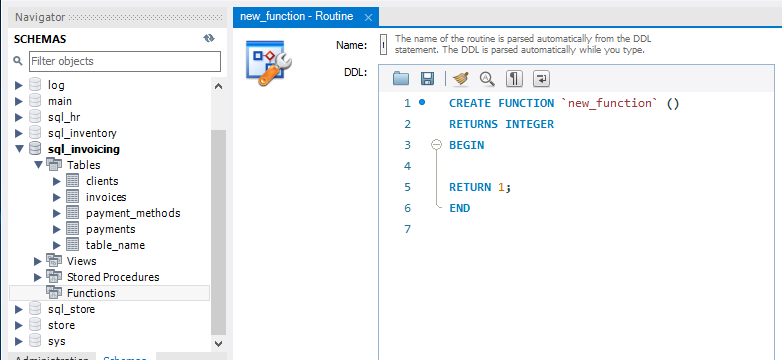
创建函数的语法和创建存储过程的非常类似
首先是取一个名字,括号里面定义参数,然后是RETURNS INTEGER 意思就是返回一个整数。
在RETURNS语句的下面,我们需要设置函数的特性:
DETEMINISTIC:这是说如果给函数同样的设置值,他就总返回相同的值(输入一样,输出也一样)。这在不依赖于数据库数据计算返回值的时候就会很有用,因为数据库中的数据是变化的。就比如计算运费或者税金就可以用DETEMINISTIC。因为其中都是根据一些公式来进行计算,相同的参数一定得到相同的值。
READS SQL DATA:这个意思就是在函数主体当中我们需要用SELECT 语句从数据库中获得信息
MODIFIES SQL DATA:对数据库进行增删改查的时候就会用到这个特性。
在这个函数,我们要计算顾客的风险指数,这是会随着顾客支付他的订单而变化的,所以不需要DETEMINISTIC,而且这个函数也不需要对数据库进行CRUD操作,仅仅是计算。所以我们用READS SQL DATA 特性
然后我们把刚才的语句复制过来。并做一些修改: WHERE i.client_id = client_id;
并且,如果风险指数为NULL的话,我们通过IFNULL 将其设置为0。
APPLY 应用之后,我们可以对其进行运行了。
1 | CREATE DEFINER=`root`@`localhost` FUNCTION `get_risk_factor_for_client`( |
新建了函数之后,我们在sql语句当中可以使用内建函数一样使用自定义函数了:
1 | SELECT |
我们看到结果,如果这个人没有任何账单,那么根据计算出来的结果,再使用IFNULL函数之后,他们的风险指数就是0了

不同的人,使用函数的时候有着不同的习惯。比如命名时喜欢驼峰命名法,或者像刚才那样下划线命名法。不同的人也会有不同的分隔符号,有些人喜欢$$ 有些人喜欢 //
触发器和事件
Triggers
Trigger is a block of SQL code that automatically gets executed befor or after an insert ,update or delete statement.
通常触发器用来维持数据的连贯性。比如在sql中,给定的发票可以有多个支付记录。有一列 payment_total 是专门用来统计了现在已经支付了多少金钱了。所以,当我们想支付记录表中添加了一条记录,我们需要保证发票表中的 payment_total 需要实时更新。这就需要 Trigger
这是创建一个基本触发器的语法。首先我们要切换分隔符为$$
其次我们 CREATE TRIGGER + 触发器的名字。触发器的命名也有一定的规矩。payments是数据表的名字,after或者before代表了这个触发器是在行为之后运行还是在之前运行。这里是在插入了payments之后,触发Trigger,第三个代表触发这个Trigger的命令类型。所以这个触发器的意思是在payments表中插入信息之后触发。
下面是触发器的命令。可以是AFTER也可以选BEFORE,INSERT 也可以是DELETE,FOR EACH ROW代表了每次插入都会修改。如果一次插入了5行,那么就会修改5行
然后是BEGIN和END代码块,其中可以输入任何为了保持表格连续性所需的代码。可以直接写语句或者调用存储过程。我们这里要更新payment_total这列的值,所以使用UPDATE invoices表格,然后设置 payment_total = payment_total+NEW.amount,注意这里改变调用的是刚刚插入的amount信息,所以我们要用NEW修饰。
最后我们需要设定那些是需要更新的,是invoice_id和我们插入的invoice_id相匹配的信息才需要更新,用WHERE来描述
1 | DELIMITER $$ |
运行后,我们插入一条信息
1 | INSERT INTO payments |
然后5号信息的payment_total已经更新为10了
小练习
Create a trigger that gets fired when we delete a payment
1 | DELIMITER $$ |
这是用来当我们删除一条payment之后,会自动更新payment_total的值的trigger
Viewing Triggers
我们没有办法在mysql workbench 查看触发器。我们可以使用SQL语句显示TRIGGER
运行
1 | SHOW TRIGGERS |

如果我只想看特定的触发器,我们可以这样
1 | SHOW TRIGGERS LIKE 'payments%' |
Dropping Triggers
删除Trigger和删除存储过程差不多。
1 | DROP TRIGGER IF EXISTS payments_after_insert; |
Using Triggers for Auditing
还有一种触发器的应用场景,就是记录对数据库的修改。比如,某人插入或者删除了某个记录,我们可以在某处记录下来,这样可以在今后回头检查。
1 | USE sql_invoicing; |
我们先新建一张表用来保存日志。然后我们在BEGIN和END之间的代码块新建INSERT INTO 语句,也就是当我们插入一条信息的时候,同时会向payments_audit表格中插入一条日志
1 | DELIMITER $$ |
但是这样比较麻烦,因为我们如果需要系统地记录日志,就必须对每张表都创建一个TRIGGER。在后面我们可以创建通用审计日志来达成这个目的。
Events
Event is a task (or block of SQL code) that gets executed according to a schedule
我们可以设置event 每天进行几次,每个几个小时进行。利用event我们可以简化数据库维护工作。比如删除状态数据,将数据从一个表拷贝到另一个表,或者把数据聚合起来生成报告。
在mysql中,有一个event_schedule 功能,这个功能默认是打开的,只有当这个功能打开的时候,event才能发挥它定时运作的功能,如果不想打开,可以 利用代码 关闭
1 | SET GLOBAL event_scheduler = OFF |
现在来看看怎么创建一个 Event
首先切换分隔符为$$
利用CREATE EVENT来创建一个事件,我们需要给事件创建一个一目了然的名字。
按时间间隔来给时间命名是一个好习惯。第一个可以实daily,hourly,once之类的。这样我们可以很容易找到某种事件的时间间隔。
接着用ON SCHEDULE 给这个事件创造一个时间计划:多长时间执行一次,是一次性的还是固定时刻的。如果只进行一次,那么用AT + ‘YYYY-MM-DD’ ,如果想要按找特定的事件进行,那么EVERY 1 YEAR/2 DAY ,如果想要规定开始时间和终止时间,只要在后面加上 STARTS ‘YYYY-MM-DD’ ENDS ‘YYYY-MM-DD’ 即可
- 在DO BEGIN中加入EVENT想要执行的操作。这里是删除距今超过1年的action_date 信息。我们也可以利用DATESUB(NOW(),INTERVAL 1 YEAR) 来表达相同的意思。
1 | DELIMITER $$ |
Viewing, Dropping and Altering Events
我们可以用 SHOW EVENTS语句 来显示当前的EVENT
利用 DROP EVENT IF EXISTS + 名字 来删除事件
利用 ALTER来修改事件,只需要把 CREATE EVENT 改成 ALTER EVENT 即可,利用ALTER 我们可以临时启动或者关闭一个事件
1 | ALTER EVENT yearly_delete_stale_audit_rows ENABLE; |
事务和并发
Transactions
Transaction is a group of sql statements that represent a single unit of work
我们是在需要对数据库进行多处修改的场景使用Transaction,所有的语句必须成功执行,否则Transaction就会失败。
我们不想要一些插入语句进行到一半的时候程序崩了,导致信息半生不熟的情况,这时候就要使用Transaction,也就是如果出现错误,整个语句块都作废。
Transaction有几个特性:
第一个是Atomicity,也就是不可分割的,一个事务不管其包含多少语句都是一个完整的整体。除非事务中所有的语句都成功执行,Transaction才算执行成功,否则所有修改都会回滚。
第二个特性是Consistency,也就是说我们使用了Transaction之后,我们的数据库永远保持一致。我们不会保存没有商品的订单记录。
第三个特性是Isolation。也就是说 Transaction之间是相互隔离的,特别是他们要修改同一个数据的时候。他们之间不受影响。如果多个Transaction要修改同一个数据,这条记录就会被锁定,每次只能有一个Transaction有权修改。其他的Transaction需要等待这个Transaction执行完毕
最后一个是Durability, 意思是一但一个Transaction被提交,它的修改就是永久性的,任何崩溃的情况(停电、宕机),也不会影响数据的修改
我们称这四个属性为 ACID
Creating Transactions
我们利用 START TRANSACTION 标志着创建一个Transaction,然后在里面进行我们想要的操作,比如插入、删除信息。最后用COMMIT 代表提交 Transaction 。如果在执行到第一个INSERT INTO 之后与Mysql断开连接,那么这第一条信息将不会出现在表中,因为回滚了。
有时候我们会手工创建Transaction 回滚来进行某些测试。这时候可以使用ROLLBACK代替COMMIT
1 | USE sql_store; |
事实上,当我们在对数据库执行UPDATE ,DELETE 等操作的时候,Mysql会自动把他包裹上Transaction 的外衣并自动提交。这个功能通过全局环境变量 Autocommit : ON 来控制
Concurrency and Locking
迄今为止,我们的数据库只有一个用户。但现实中可能是同一个数据库同时被好几个用户同时访问。这就是我们说的并发(Concurrency )。
比如,我们对一个数据库同时开两个连接。并对同一条信息执行一模一样的Transaction,这v时,当第一个Transaction在执行的时候,这条信息就会上锁,第二个Transaction只有在第一个结束之后,才能继续运行。
Concurrency Problems
Lost Updates
在特殊情况下,当两个事务试图更新相同的数据而我们不使用锁的时候,会发生 Lost Updates
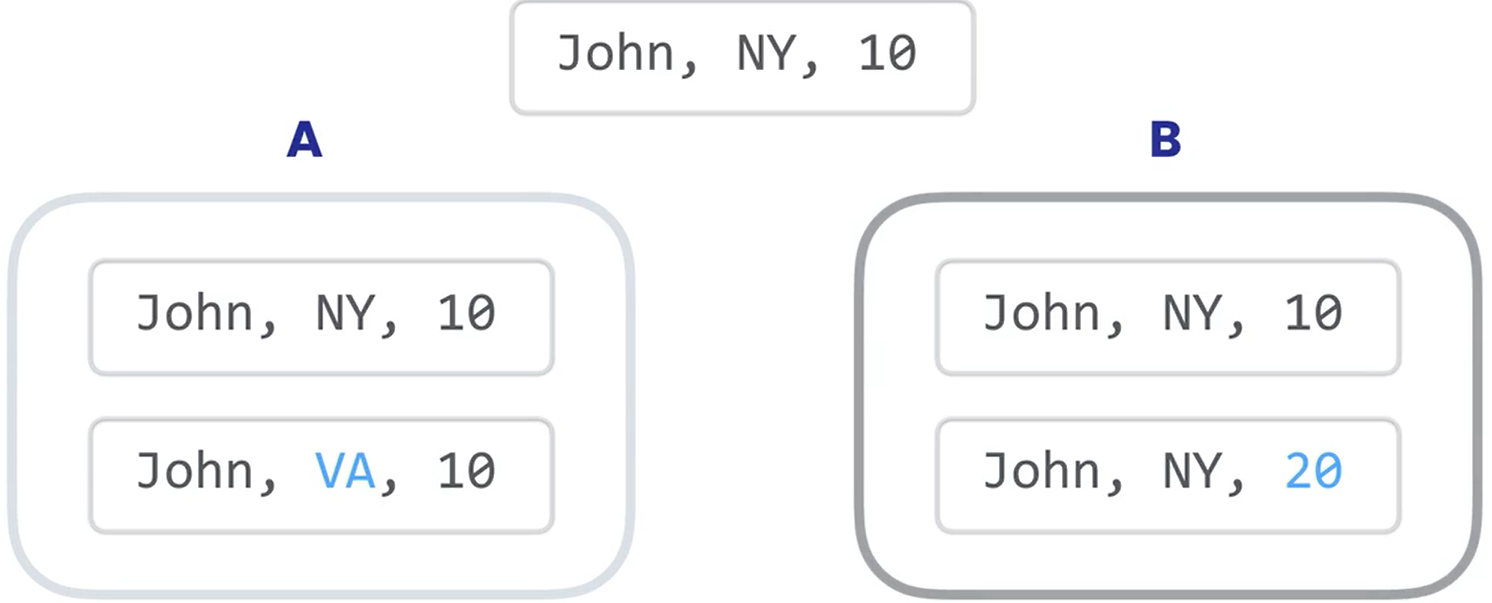
我们对一条数据进行两次更新,一次更改洲名,一次更改积分,但是这样一来,如果B是后更新的,那么B中的数据会覆盖掉A中更新的数据,造成更新丢失。我们这时候就需要Locks来规避这种情况的发生,默认情况下,Mysql使用了锁定机制以防止两个事务同时更新相同的数据,他们在一个队列中,按照顺序进行。
Dirty Reads
Dirty Reads 发生在事务读取还没有提交的数据时,比如下图。事务A想把顾客的分设置为20,在还没有提交的时候,事务B读取了表中更新过后的数据。如果每一分代表优惠一元,那么这位顾客可以优惠20元。但是事务A在提交前发生回滚。这时候事务B还没结束,所以事务B读取的数据是非法的。也就是说,在这种情况下,白给了顾客20元的优惠,因为事务B中读取了未提交的数据 。这就是 Dirty Reads,很形象。因为我们读取了污染的数据。
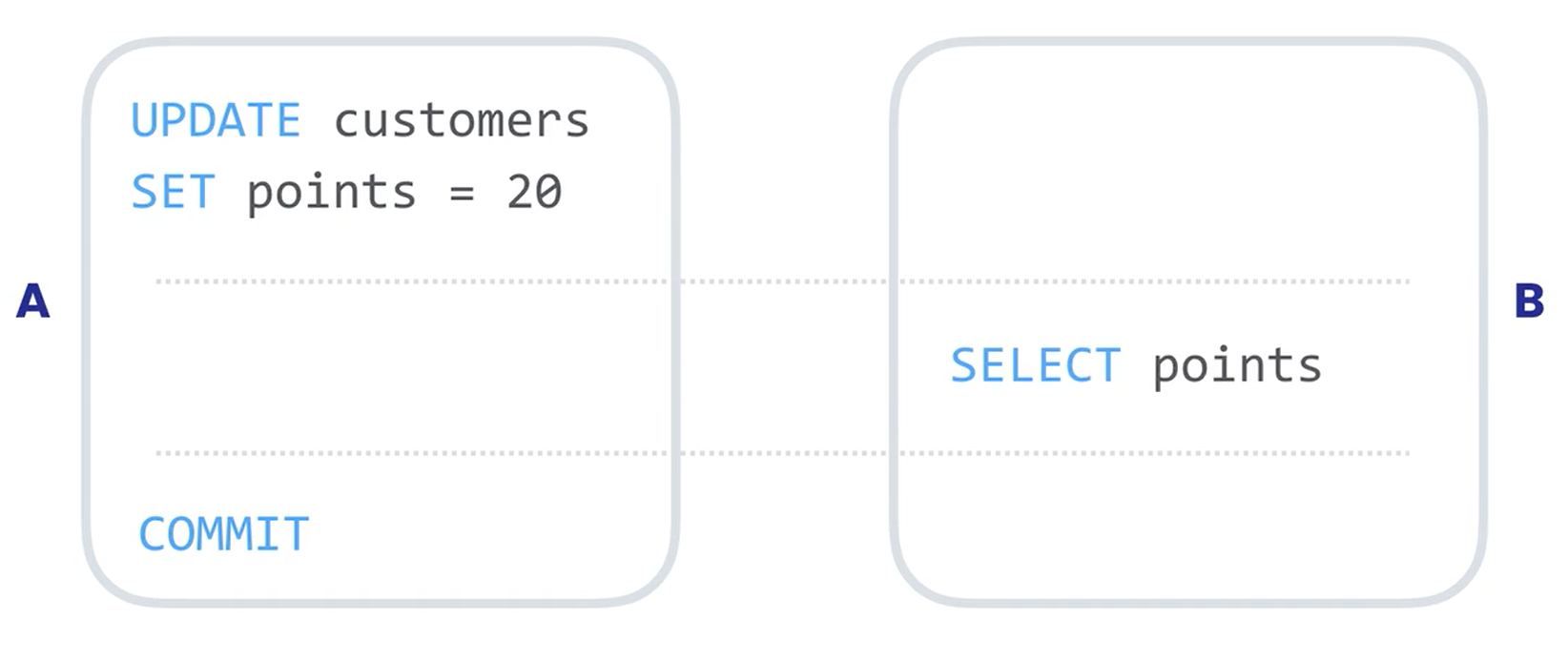
为了解决这个问题,我们需要围绕事务提供一定程度的隔离度。所以事务修改的数据并不会立刻被其他事务读取到。之前我们提到的,实现Recovery Schedule的话,就不会发生这种问题了
Non-repeating Reads
如果在事务进行过程中,我们读取了两次、得到了不一样的结果怎么办.比如下图。事务A中选择了数据表中一条值为10的信息,但是这时候,B把这条信息的数据改成了0,现在A中的子查询又想读取这条信息,发现这时候其值已经变成0了。对于这种不重复读取问题,我们可以声明,任何时候都以最新的数据作为计算依据

Phantom Reads
假设有个事务A,我们查询了所有积分大于10的客户,发给他们额外的打折券。这时候,一个事务B修改了一位顾客甲,把他的分修改到了20。但这时候事务A已经完成查询,甲并不在查询结果当中。这就是我们说的Phantom Read,数据有时候会像幽灵一样突然冒出来。是否解决这个问题要看我们的业务、以及把这个客户纳入我们的事务中的重要性。
Isolation Levels
Read Uncommitted
是最低级别的隔离等级。它什么都不会做,漏洞最多。会出现上面所说的所有问题。因为事务之间没有互相隔离,他们可以读取互相做出的未提交修改。
Read Committed
当我们使用这个隔离级别时,事务只能读取已经提交了的数据。如果我们需要在事务中进行商务上的计算,我们的决定是基于有效的、已经提交的数据。事务运行之后有数据发生了变化,事务也不会去关注这个问题。这个隔离级别可以避免Dirty Read这个问题
Repeatable Read:
在这种级别下,读取的内容是可重复的,就算是数据被其他的事务修改了也没事。我们看到的只是第一次读取时就生成的快照。这个级别可以避免 Lost Updates, Dirty Reads 和 Non-repeating Reads这三个问题

Serializable
出现Phantom Reads的时候,我们可以将这个事务的隔离级别设置为Serializable.这将保证事务会知道其他事务正在对数据进行修改。如果这时候其他事务正在对数据进行修改的画,那么设置为Serializable的事务就需要等待,直到其他事务完成才能进行查询等操作。这是应用于事务的最高级别的隔离,可以规避所有的问题。但是当修改的事务越来越多,我们的系统会变得越来越慢,所以这种隔离等级牺牲了性能和扩展性。因此,我们应该谨慎使用,只有在绝对关键并且一定要有防止Phantom Read的情况下。
Transaction Isolation Levels
下面这张图是一个很好的归纳。功能越强大的隔离等级,性能和扩展性越差。但是越低的隔离等级,性能越好。这样能让更多的用户同时访问数据库。
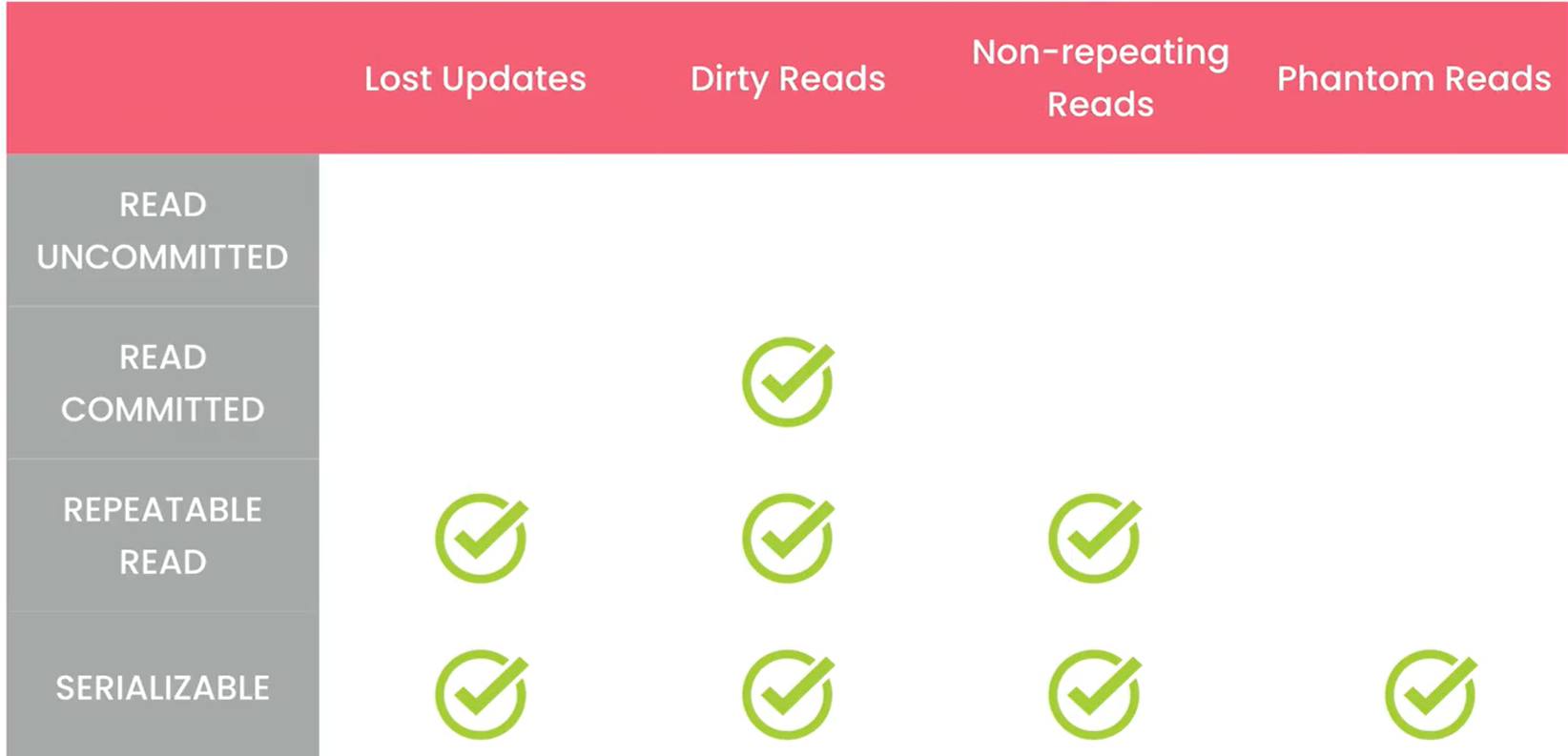
Mysql中默认分的隔离等级是 Repeatable Read,这在大部分场景下都很好用。性能表现很好并解决了大部分问题(除了 Phantom Reads) .如果我们想规避Phantom Reads,我们可以把隔离等级设置为Serialization。对于剩下两个等级,我们可以在不需要精确的一致性的情况下使用,如批量报告(这时候数据肯定是更新好的,我需要的是更好的性能)
用这行代码可以显示当前的隔离等级
1 | SHOW VARIABLES LIKE 'transaction_isolation' |

我们使用下面这句话可以修改隔离等级
1 | SET TRANSACTION ISOLATION LEVEL SERIALIZABLE ; |
执行后,会在下一次事务执行时修改隔离等级。我们也可以在当前的session或者connection中设置隔离等级。我们在前面加SESSION关键字,只要我们的这个连接任务还打开着,所有的事务都会被设置。当然我们也可以把SESSION换成GLOBAL。
当我们的程序中有个执行某些事务的函数,那么当运行的时候,我们使用SESSION即可,因为我们只需要为这个Session或者connection修改等级,步骤是:连接到库,修改等级,执行事务,关闭连接。这种操作并不会影响到其他的事物
Deadlocks
死锁发生在不同的事务都无法完成的情况下,因为每个事务都持有另一个事务需要的锁,所以事务都会上对方等待而不会释放自己的锁
数据类型
Introduction
在mysql中有几种数据类型的分类。

String Types
String Types 分为 好几种
Char字符用来存放固定长度的字符,比如世界各个国家的缩写,美国各个州的缩写。Varchar是用来保存可变长度的字符,比如用户名、密码、Email地址等。String类型也可以用来保存数字类型的数据,比如邮政编码、电话号码,因为这些数字并不是用来计算的。另外,这样的数据也会包含短横线或者括号。这也是另一个要用字符串保存着类数据的理由。
我们需要有良好的习惯。给一些特定类别的数据类型固定字符串规则。比如
VARCHAR(50) for short strings
VARCHAR(255) for medium-length strings
如果VARCHAR不够用了,我们可以用MEDIUMTEXT ,其可存储16MB的数据,非常适合存储JSON对象,CS视图字符串以及短至中型的文章。
当然LONGTEXT可以存储4GB的内存,可以存储日志等。
还有TINYTEXT和TEXT,各自有各自的存储空间
| 类型 | 容量及描述 |
|---|---|
| CHAR(x) | fixed-length |
| VARCHAR(x) | max: 65535 characters(~64kb) |
| MEDIUMTEXT | max:16MB |
| LONGTEXT | max:4GB |
| TINYTEXT | max: 255bytes |
| TEXT | max:64kb |
比起TEXT最好使用VARCHAR,因为VARCHAR是可以作为索引的。索引可以加快查询数据。
英文字母占1字节;欧洲和中东文字占2字节;亚洲文字(中文、日文)占3字节
Integer Types
我们使用整数来保存并没有小数位的数字,比如1234,mysql有5中整数类型,各自能存储的容量不同。
TINYINTY 短整数,只占用1个字节。取值[-128,127]
UNSIGNED TINYINT 无符号短整数,取值[0,255]用来存储人类年龄很合适,可以防止意外输入赋值的问题。
SMALLINT 2byte 取值[-32k,32k]
MEDIUMINT 3byte 取值[-8M,8M]
INT 4byte 取值[-2B,2B]
BIGINT 8byte 取值[-9Z,9Z]
除了UNSIGNED,数字类型还有一个属性,就是ZEROFILL,这种情况用0填充虚位。比如 0001,0003
最好永远选择适合我的最小数据类型。
Fixed-point and Floating-point Types
mysql中有3种保存小数的类型。
DECIMAL(p,s) 这种类型的数字,小数点后面的位数是固定的。当使用DECIMAL类型时,需要指定小数位数。p代表整数的维数,可以选择1到65。s代表保留小数位数。比如DECIMAL(9,2) =>1234567.89
DECIMAL可以用DEC, NUMERIC,FIXED
第二种是FLOAT ,4b
第三种是DOUBLE, 8b
但是FLOAT和DOUBLE不能精确的记录数字,所以我们如果想要精确的记录数字就必须要用DECIMAL,但是如果我需要做科学计算中使用很大或者很小的数,那么可以用FLOAT或者 DOUBLE
Boolean Types
布尔值实际上就是短整数的另外一个形态。 数值类型可以是BOOL或者BOOLEAN
TRUE代表1,FALSE代表0
Enum and Set Types
有时候我们需要某个字段的取值是有限的若干字符串。比如,有个列只能插入 small,medium,big三种。那么在表格中我们可以这样设置其数据类型
ENUM(‘small’,’medium’,’big’ )
这时候,只能三选一,任何其他的值都会让mysql报错。
但是ENUM类型的效率不是很好,当我们想增加一种选项的时候我们必须重新设计表格。
更好的方式是新建一张叫做Size的表,这个表中既可以保存大小,又可以保存其精确值。这样我们就可以重复利用这张表格了。如果想列出所有的大小,只需要写一局查询语句即可,这种表格叫做查询表。比如:

mysql中还有一种类似的数据类型为SET,它让我们在列中可以保存SET提供的多个数据。但也不建议使用
Date and Time Types
mysql中有几种保存日期时间的类型。
DATE 用于保存日期,但是没有时间部分
TIME 用来保存时间
DATETIME 8b
TIMESTAMP 4b 我们经常使用TIMESTAMP时间戳来记录数据插入和最后修改的时间,最大年份是2038年。超过2038年只能使用DATETIME来保存。
YEAR
Blob Types
Blob用来保存大的二进制数据,如图像、视频、PDF、几乎任何二进制文件。mysql有四种BLOB类型
TINYBLOB 255b
BLOB 65KB
MEDIUMBLOB 16MB
LONGBLOB 4GB
通常来说,我们应该将文件放到数据库外面。因为关系型数据库是用来处理结构化数据的,而不是二进制数据。如果将文件保存到库当中,库的大小将会增长非常快、备份起来非常慢、性能上出现严重问题(从库中读取图片的速度永远慢于直接从文件系统读取。最后,我们还需要单独编写文件的存储代码
JSON Type
mysql也可以存储JSON文件。

在设计了一列数据类型为JSON之后,我们可以这样插入一条JSON信息
1 | UPDATE products |
此外,我们还可以看看另一个创建JSON对象的方法:使用特定的哈数来创建JSON对象
1 | UPDATE products |
对于JSON类型,我们可以检索特定的键值对,这比VARCHAR的优势更大,因为String类通常不能对字符串进行分割
比如用这样的mysql语句进行查询. $ 代表了JSON对象,用点运算符连接对象中的KEY
1 | SELECT product_id,JSON_EXTRACT(properties,'$.weight') AS weight |
但是我们还有更简单的写法。我们可以用路径指示符,也就是箭头符号来执行查询。这里,dimentions是一个数组,所以我们可以通过用中括号的方法来获取数组中某个特定的值
1 | SELECT product_id,properties -> '$.dimentions[1]' |
又比如,->> 是为了让manufacturer的name属性 sony没有引号出现
1 | SELECT product_id,properties ->> '$.manufacturer.name' |

还有一些可以更新JSON数据的方法。比如我想修改weight对应的键值,怎么办?我们可以使用JSON_SET方法。它不仅可以修改键值,还可以增加键
1 | UPDATE products |
现在我们可以使用JSON_REMOVE来意出我们不需要的键
1 | UPDATE products |