离散数学之图4
我们在购物的时候,常常会收到宝贝推荐,那么网站是根据什么原理来推送给我们的呢?
我们需要了解协同过滤的概念. 也就是我们需要衡量两个对象之间的距离、亲和度
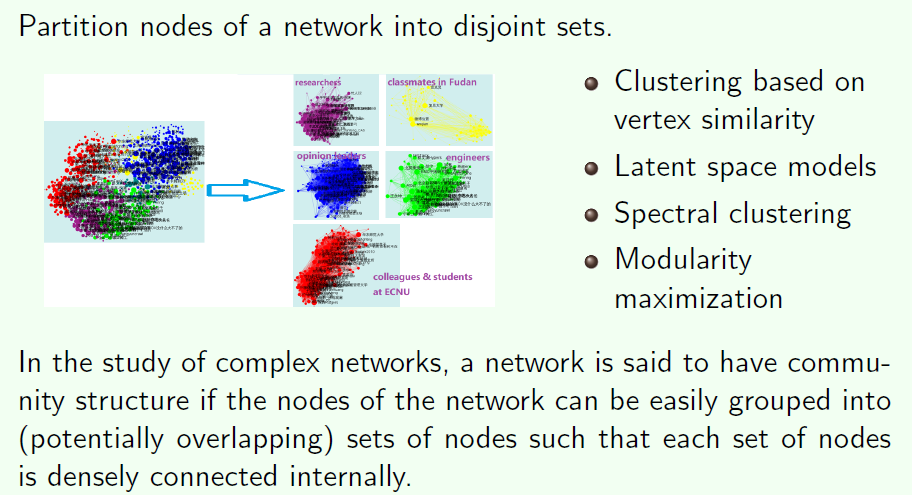
Community Structures
Definition
Community structure indicates that the network divides naturally into groups of nodes with dense connections internally and sparser connections between groups.
Community structure 就是说把一些节点分成几个部分,在每一个部分中节点之间连接比较紧密;但是在组和组之间的连接比较稀疏。比如根据国家与国家之间的关系网络,分成几大阵营
- Global community structures: clustering-based approach,spectral clustering, modularity-based approach, etc. 把每一个节点至少划分到一个社团当中
- Local community structures: node-centric community, group-centric community 只关心一小部分
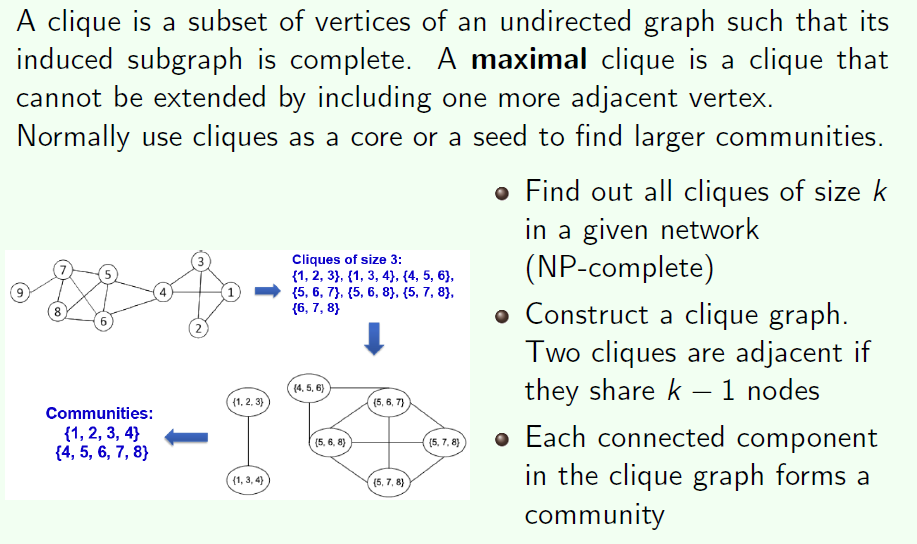
- Traditional network: clique完全图, quasi-clique接近完全图, k-clique, k-core, etc.
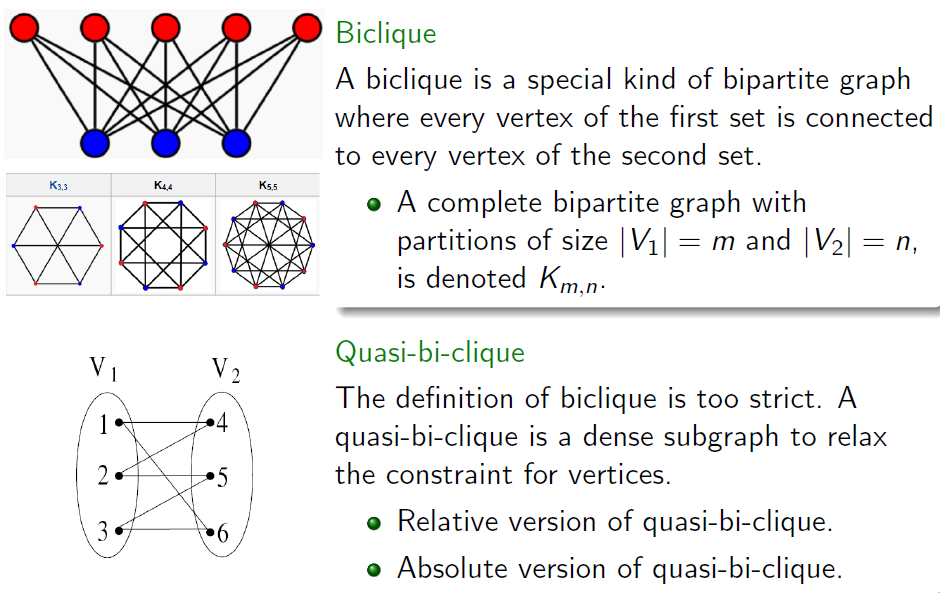
- Bipartite network: bi-clique二分完全图, quasi-bi-clique, etc.
- Signed network: antagonistic community, quasi-antagonistic community, etc. Signed network就是节点和节点之间有一条边,边可以是negative或者positive的:negative代表敌对,positive代表联合
- 敌人的敌人就是朋友
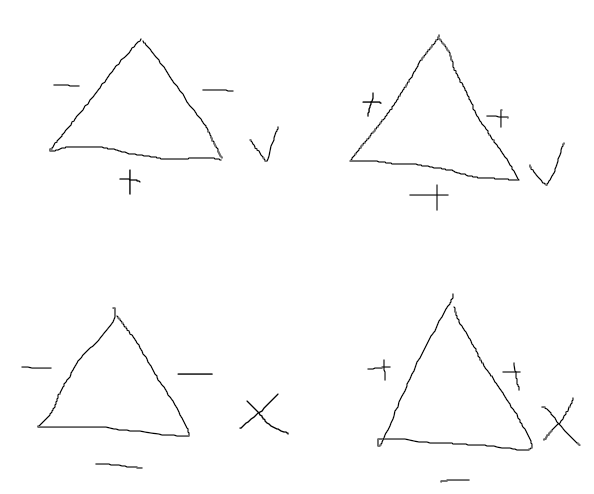
- 只有当三个符号相乘为正号的时候,才能说这个三角关系是稳定的,如果这三个符号相乘为符号,最终也会通过一个符号的改变趋于稳定。如果全是负号,说明三者都不对付,那么两个势必联合起来对服实力较强的一方从而转化成 - - +;又比如仅有一个负号,那么这两方就会劝另一方进入自己的阵营。变成—+或者两方和解称为+++
Global Structure
我们可以利用Global Structure 进行可视化:可以把社交圈分成几个部分
经过community detection之后,我们可以看到相同的圈子里,建立一条边非常容易。但是不同圈子里的人就很难联系上。所以利用这个可以做好友推荐。
Clustering based on vertex similarity
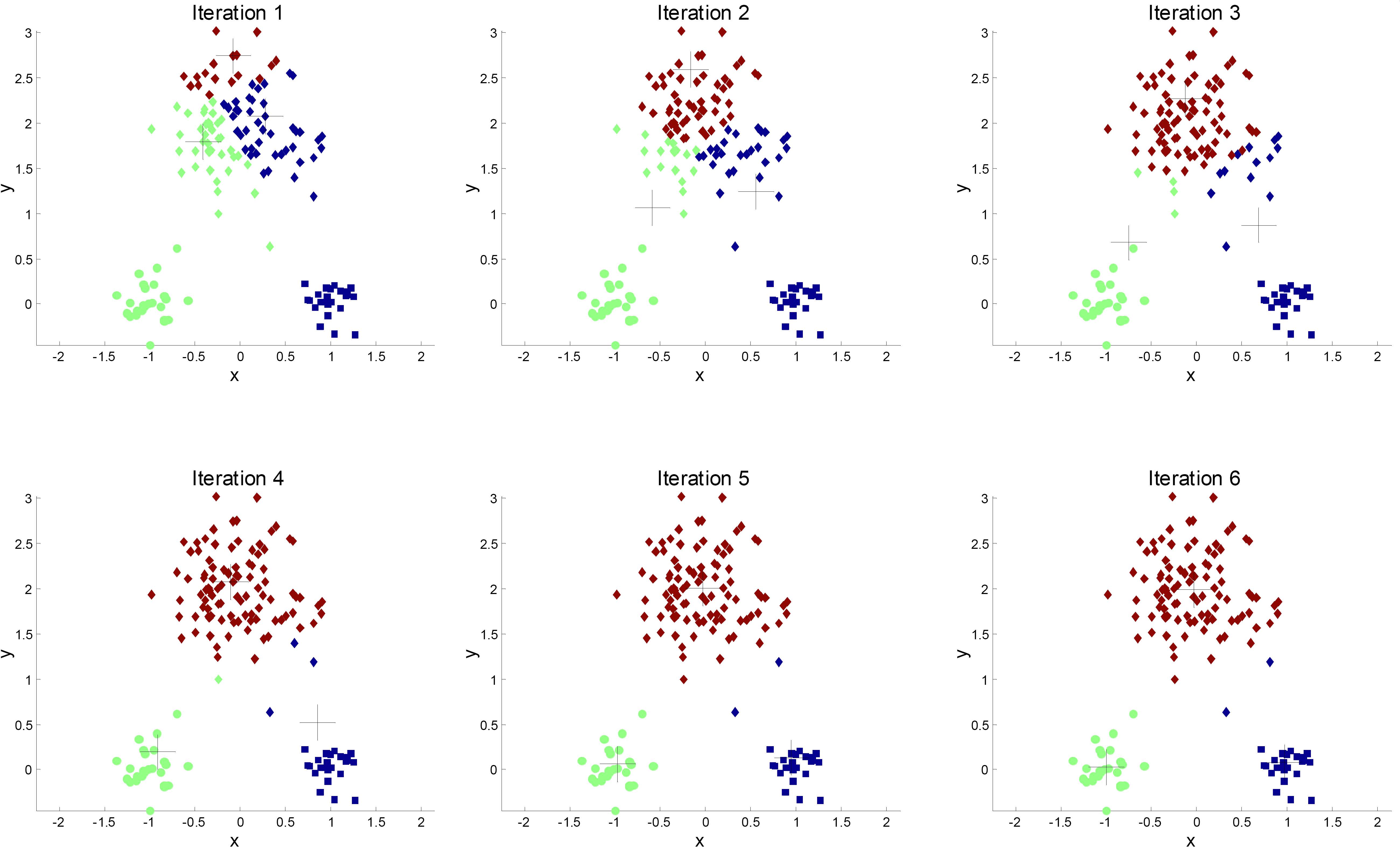
K-means是一种无监督的方法,也就是说不需要训练数据。给我一堆数据就可以挑选出什么是一类的,什么不是一类的。 K就代表 cluster(类)的数量
首先把点放到一个高维的空间当中,然后不断地计算点和点之间的距离,距离相近地归类,然后重新计算类中心。
经过多次 K-means的运算,一直到类的中心不再变化。完成聚类。

Spectral clustering
Let $L$ be normalized Laplacian of graph $G$, the algorithm partitions nodes into two sets $(B1, B2) $based on the eigenvector v corresponding to the second-smallest eigenvalue of $L$. Partitioning may be done in
various ways:
- Assign all nodes whose component in v satis es certain condition in $B_1$, and $B_2$ otherwise, e.g., larger than median, the sign of each entry of v.
- The algorithm can be used for hierarchical clustering by repeatedly partitioning the subsets in this fashion.
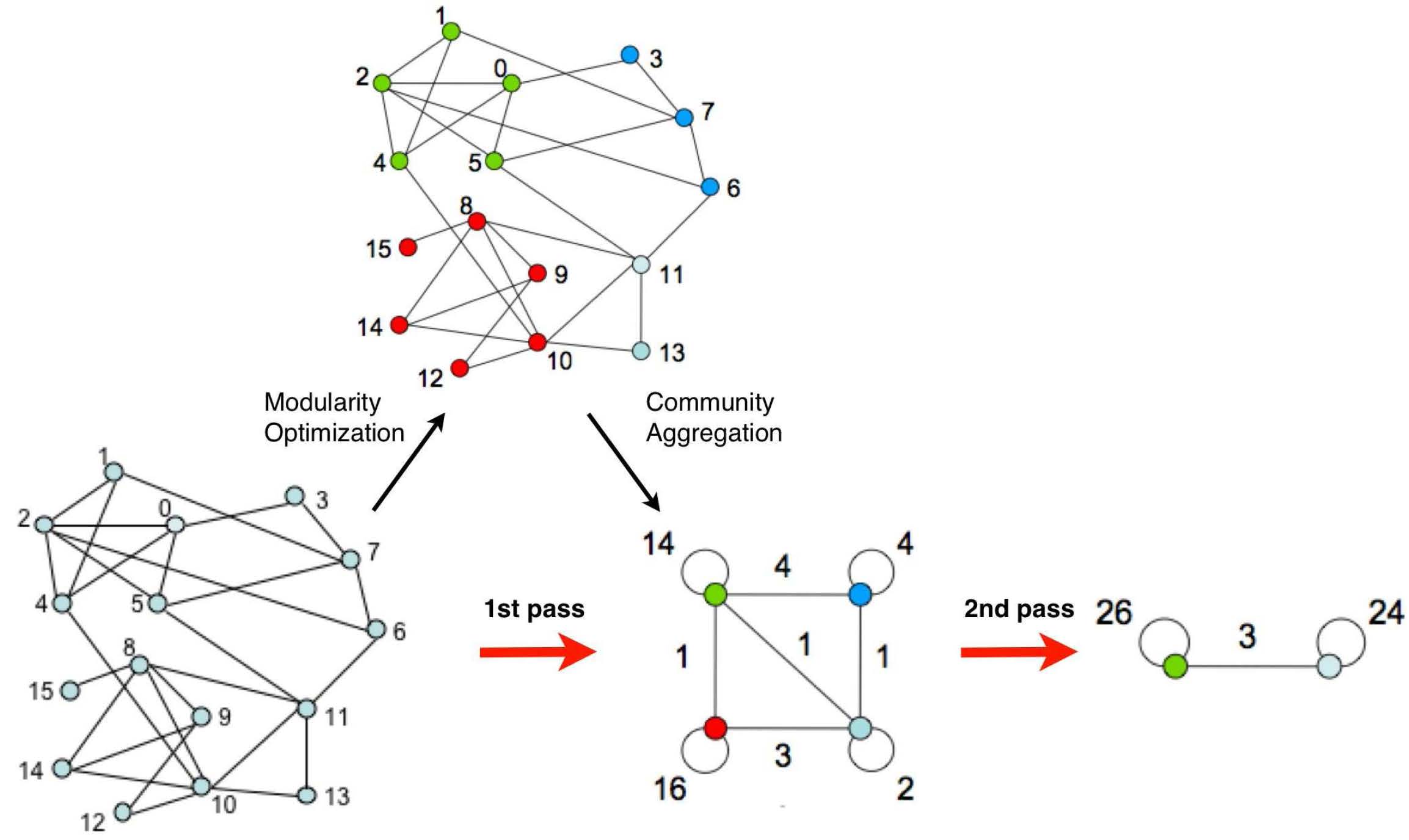
Modularity 模块度

Louvain method
Clique
Extensions of clique

local Structure
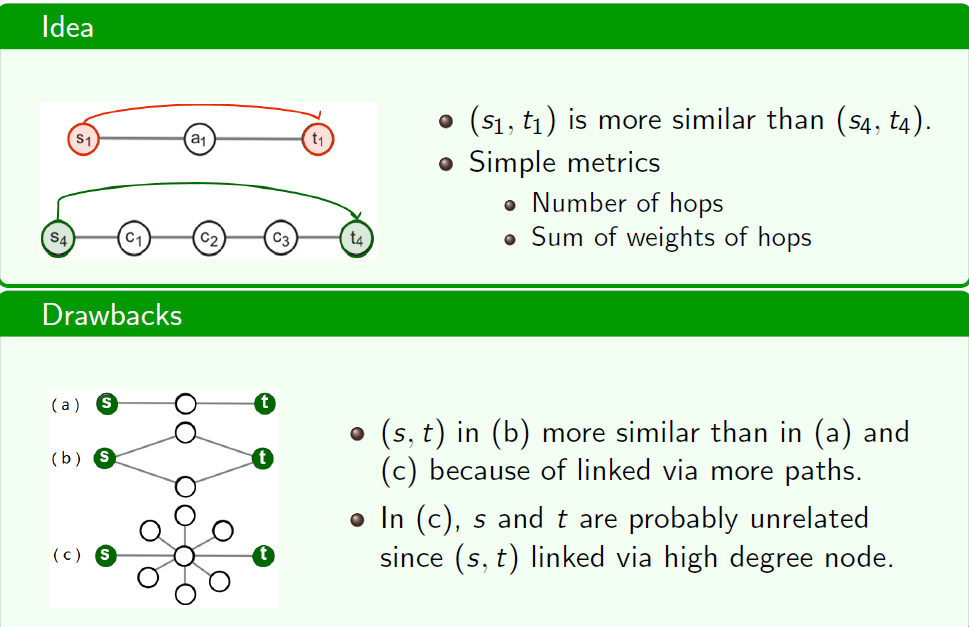
Node Proximity 顶点亲和度
Node proximity (= similarity or closeness, but $\not=$ distance) measures:
- Information exchange
- Latency/speed of information exchange
- Likelihood of future link
- Propagation of a product/idea/service/ disease
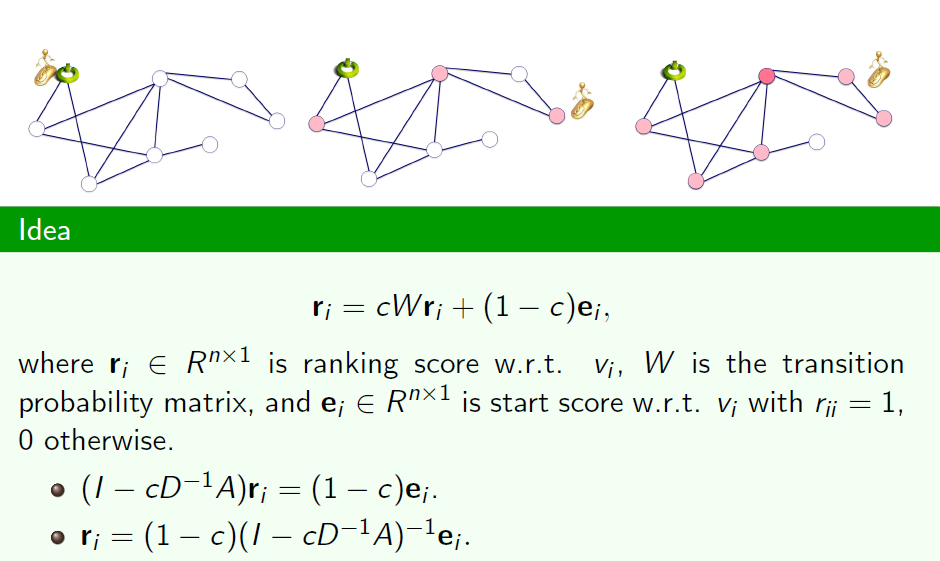
- Relevance: ranking
通过顶点和顶点之间的亲和度,我们可以计算出信息之间交换可能性的大小,信息传递速率的快慢,两点之间未来产生一条边的概率,产品、idea、服务、疾病的扩散情况,。
Simple Approaches
Jaccard比Common neighbors计算出来的相似度更准确
Adamic/Adar:公共好友的neighbors越多,那么做出的贡献越小。

缺点就是把这张图看成了集合,没有考虑朋友的朋友
Graph-theoretic Approaches

SimRank
SimRank假设每两个点之间都有一个相似度。然后迭代来算,每一轮计算a与b的相似度的时候,根据上一轮的结果来计算。如果a!=b,那么根据这个公式,通过c和d(ab的好友)的相似度加权集合来计算a和b的相似度

Random Walk based Approaches