pandas基础1
pandas操作技巧:tab自动补全,shift+tab 显示方法中的参数等提示信息
Pandas Basics
如何创建,读取文件的操作这里就不再提了。
Pandas Display Option and head() & tail()
显示一张表格的内容我们可以直接输入dataframe的名字也可以利用python的语法print将其打印出
我们还可以利用代码现实一些pd显示的规律。
1 | pd.options.display.max_rows |
1 | pd.options.display.min_rows |
默认情况下, max_rows是60,也就是说60行以下的会全部打印或展示。
min_rows是10,也就是说当数据超过了60行之后,只会展示10行,也就是头5行和尾5行
我们可以设置 pd.options.display.min_rows =20,那么,就会显示头10行和尾10行
我们也可以利用 head()和tail()方法来显示头尾,默认是5 行,但是head(10)即是显示头10行
First Data Inspection
1 | titanic |
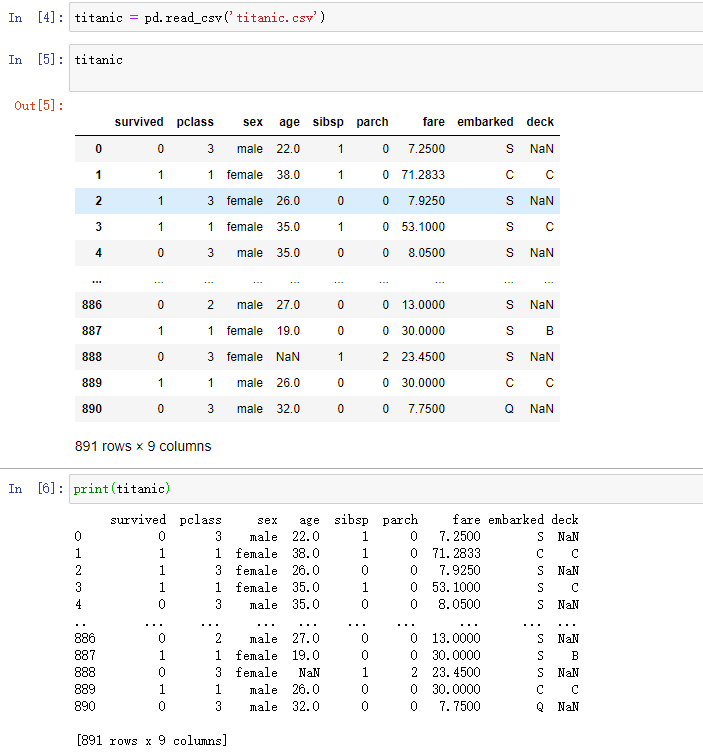
我们可以利用 info()方法展示titanic数据表的基本信息,比如数据类型之列的
1 | titanic.info() |
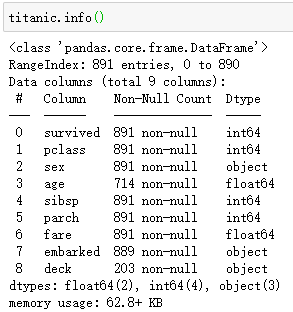
利用describe()方法,可以自动统计一些信息。每列的均值、标准差、最小值、最大值、中位数、四分位数
1 | titanic.describe() |
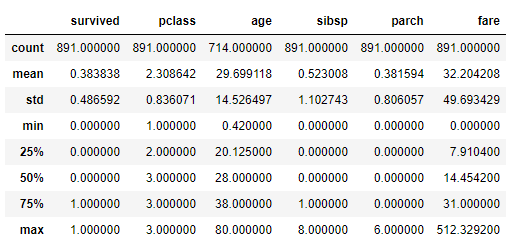
此外,我们利用describe,可进行特定数据类型的统计。比如这里include = “O” 就代表所有数据类型为Object的列
1 | titanic.describe(include = "O") |
Python Built-in Functions & DataFrame Attributes and Methods
DataFrames and Python Built-in Functions
利用type展示数据表类型
1 | type(titanic) |
利用len展示数据表的行数
1 | len(titanic) |
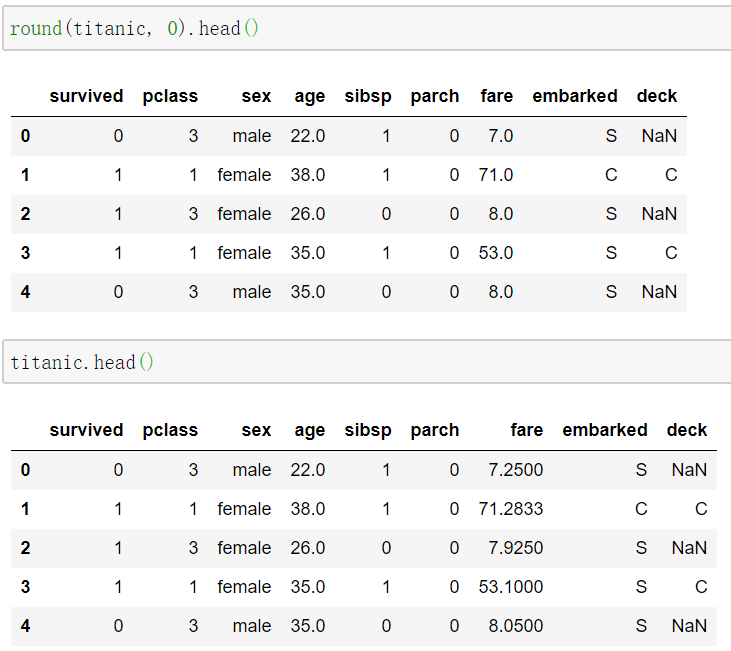
用round对数据表中的数值进行四舍五入
1 | round(titanic, 0) |
利用min(数据表) 只能得到 一个列名,这是由列字符表排序得到的。
1 | min(titanic) |
DataFrame Attributes
这里是一些DataFrame的属性。shape显示DataFrame的行列。titanic数据集有891行,9列
1 | titanic.shape |
size属性是行和列的积
1 | titanic.size |
index显示数据集的索引
1 | titanic.index |
columns显示数据集的列
1 | titanic.columns |
DataFrame Methods
head(n = 2) 也可以写作 head(2) ,显示头两列
1 | titanic.head(n = 2) |
1 | titanic.min() |
Method Chaining
https://pandas.pydata.org/pandas-docs/stable/reference/frame.html
采用链式方法可以很方便的达成一系列的功能
1 | titanic.mean().sort_values().head(2) |
Selecting Columns
1 | type(titanic["age"]) |
下面这种直接选两列的方法是错误的,会报错
1 | #titanic["age", "sex"] |
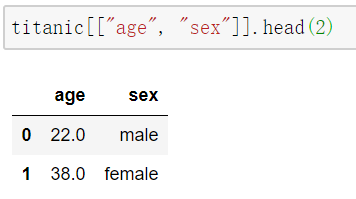
如果需要选择多列,需要用二维数组
1 | titanic[["age", "sex"]] |
单列是Series,多列则为DataFrame
1 | type(titanic[["age", "sex"]]) |
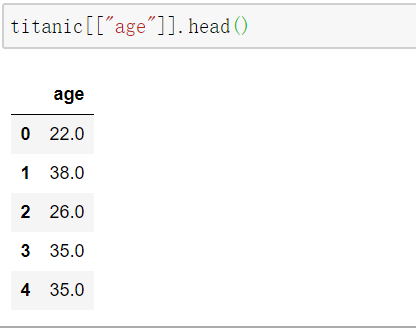
但是如果二维数组中只有一列,也是Dataframe
1 | type(titanic[["age"]]) |
Selecting one Column with “dot notation”
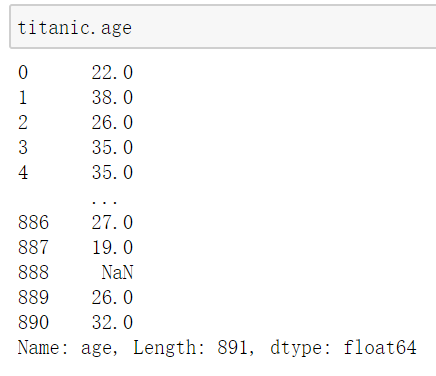
我们利用方括号获取一列,也可以通过点运算符来获取一列
1 | titanic.age |
1 | titanic.age.equals(titanic["age"]) |
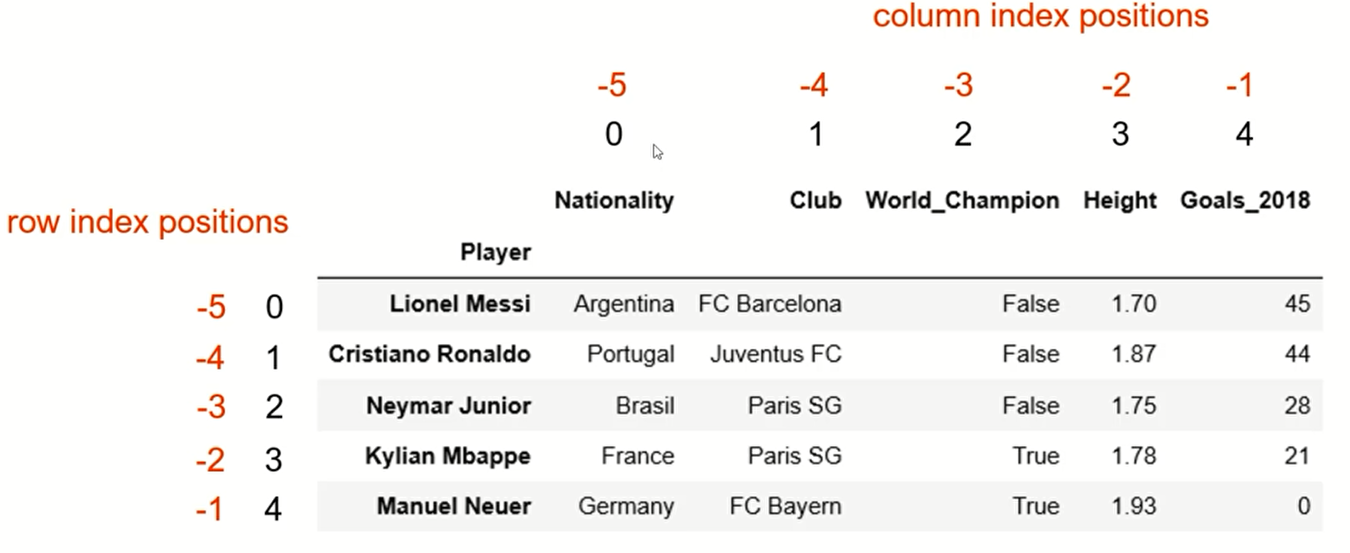
Position-based Indexing and Slicing with iloc[]
我们可以利用iloc来定位和选取特定行、列的信息
1 | import pandas as pd |
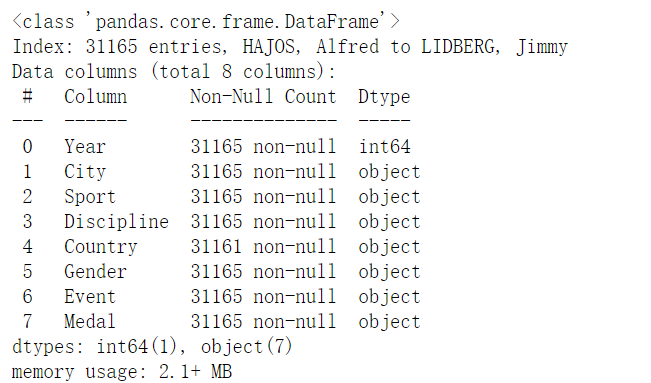
index_col得意思就是在读数据的时候将某一列作为索引,索引可以重复地出现
1 | summer = pd.read_csv("summer.csv", index_col = "Athlete") |
1 | summer.info() |
Selecting Rows with iloc[]
我们可以利用iloc[] 来定位行。
比如iloc[0]就是第一行 iloc[-1]是最后一行
1 | summer.iloc[0] |
1 | type(summer.iloc[0]) |
1 | summer.iloc[-1] |
用二维数组我们可以选择多行,这时候就组成一张表了
1 | summer.iloc[[1, 2, 3]] |
iloc[1:4]与summer.iloc[[1, 2, 3]]等价,就是2.3.4行iloc[4]不包含其中
1 | summer.iloc[1:4] |
前五行
1 | summer.iloc[:5] |
倒数五行
1 | summer.iloc[-5:] |
所有行
1 | summer.iloc[:] |
选择特定行组成表格
1 | summer.iloc[[2, 45, 5467]] |
Indexing/Slicing Rows and Columns with iloc[]
我们可以用iloc[]提取特定区域的信息
iloc[0,4]代表第一行第五列
1 | summer.iloc[0, 4] |
iloc[0, :3] 代表着第一行的前面3列
1 | summer.iloc[0, :3] |
iloc[0, [0, 2, 5, 7]]代表第一行的第1,3,6,8列
1 | summer.iloc[0, [0, 2, 5, 7]] |
iloc[34:39, [0, 2, 5, 7]] 代表第35-40行第1,3,6,8列信息
1 | summer.iloc[34:39, [0, 2, 5, 7]] |
Selecting Columns with iloc[]
我们同样通过iloc选择一整列的信息。
iloc[:,4]就是选择所有的行的第5列的信息
1 | summer.iloc[:,4] |
1 | summer.iloc[:, 4].equals(summer.Country) |
当然我们完全没必要用上面那么麻烦的方法,直接summer[‘Country’]可以获得相同的结果
1 | summer["Country"] |
Label-based Indexing and Slicing with loc[]
Selecting Rows with loc[]
除了坐标定位,我们可以直接标签定位。效果是一样的,但是要使用loc[]而不是iloc[]
1 | summer.iloc[2] |
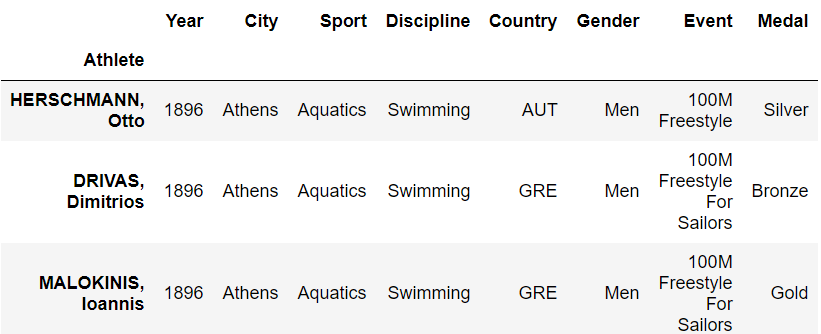
1 | summer.loc["DRIVAS, Dimitrios"] |
如果同一个运动员参加了多场比赛。那么他的数据就会形成一张Dataframe
1 | summer.loc['PHELPS,Michael'] |
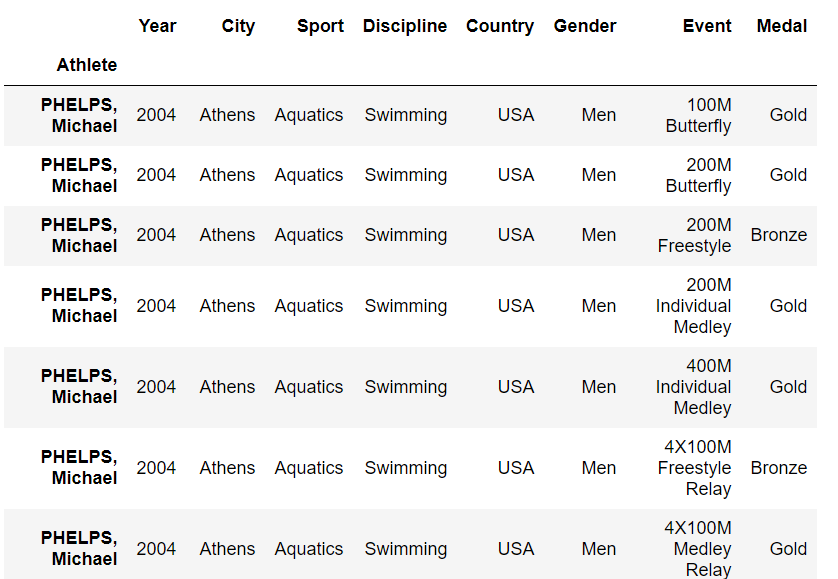
Indexing/Slicing Rows and Columns with loc[]
我们可以用标签定位数据或者截取特定区域的信息。
1 | summer.loc["PHELPS, Michael", "Medal"] |
1 | summer.loc["PHELPS, Michael", ["Medal", "Event"]] |
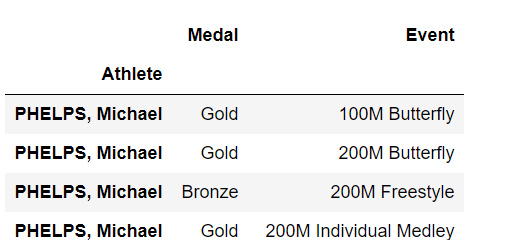
1 | summer.loc[["PHELPS, Michael", "LEWIS, Carl"], ["Medal", "Event"]] |
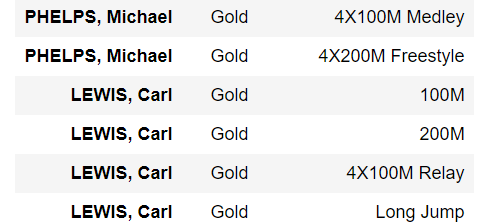
我们也可以选择所有的列,这笔数字更加直观
1 | summer.loc[:, ["Medal", "Event"]] |
loc[:”CHASAPIS, Spiridon”]选择前几行,一直到CHASAPIS, Spiridon所在的行为止(包含)
1 | summer.loc[:"CHASAPIS, Spiridon"] |
但是下面loc[:”PHELPS, Michael”]却是非法的,会报错。这是因为索引菲利普斯并不唯一,他参加过很多届奥运会。同理summer.loc[“PHELPS, Michael”:]也是错误的
1 | #summer.loc[:"PHELPS, Michael"] |
1 | #summer.loc["PHELPS, Michael":] |
选择从DRIVAS, Dimitrios到BLAKE, Arthur 关于City和Discipline两列的信息
1 | summer.loc["DRIVAS, Dimitrios":"BLAKE, Arthur", "City":"Discipline"] |
这样写在pandas 1.0中是非法的
1 | #summer.loc[["PHELPS, Michael", "DUCK, Donald"]] |
1 | #summer.loc["PHELPS, Michael", ["Year", "Age"]] |
Indexing and Slicing with reindex()
reindex()方法,可以让我们选出特定的行和列。在规定行列的时候一定要规定 index 和 columns 否则会报错
1 | import pandas as pd |
1 | summer = pd.read_csv("summer.csv") |
1 | summer |
1 | #summer.loc[[0, 5, 30000, 40000], ["Athlete", "Medal"]] |
1 | summer.reindex(index = [0, 5, 30000, 40000], columns = ["Athlete", "Medal", "Age"]) |
如果只选择列的话那么会默认选择所有行
1 | summer = pd.read_csv("summer.csv", index_col = "Athlete") |
1 | summer.reindex(columns = ["Medal", "Age"]) |
同样的,index不能选择重复的,否则会报错
1 | #summer.reindex(index = ["PHELPS, Michael"], columns = ["Medal", "Age"]) |
Summary and Outlook
Importing from CSV and first Inspection
1 | import pandas as pd |
1 | summer = pd.read_csv("summer.csv", index_col = "Athlete") |
1 | summer |
1 | summer.info() |
Selecting one Column
1 | summer.Medal |
1 | summer["Medal"] |
Selecting multiple Columns
1 | summer[["Year", "Medal"]] |
1 | summer.loc[:, ["Year", "Medal"]] |
Selecting positional rows
1 | summer.iloc[10:21] |
Selecting labeled rows
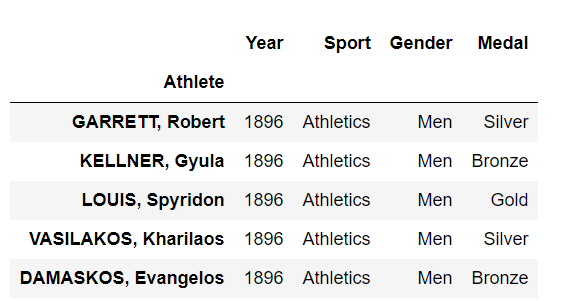
1 | summer.loc["LEWIS, Carl"] |
Putting it all together
1 | summer[["Year", "Event", "Medal"]].loc["LEWIS, Carl"] |
1 | summer.loc["LEWIS, Carl"][["Year", "Event", "Medal"]] |
1 | summer.loc["LEWIS, Carl", ["Year", "Event", "Medal"]] |
Outlook Pandas Objects
1 | summer |
1 | type(summer) |
1 | summer["Year"] |
1 | type(summer["Year"]) |
1 | summer.columns |
1 | type(summer.columns) |
1 | summer.index |
1 | type(summer.index) |
1 |
Advanced Indexing and Slicing (optional)
Case 1: Getting the first 5 rows and rows 354 and 765
1 | rows = list(range(5)) + [354, 765] |
[0, 1, 2, 3, 4, 354, 765]
1 | summer.iloc[rows] |
Case 2: Getting the first three columns and the columns “Gender” and “Event”
1 | summer.columns[:3].to_list() + ["Gender", "Event"] |
[‘Year’, ‘City’, ‘Sport’, ‘Gender’, ‘Event’]
1 | col = summer.columns[:3].to_list() + ["Gender", "Event"] |
[‘Year’, ‘City’, ‘Sport’, ‘Gender’, ‘Event’]
1 | summer.loc[:, col] |

Case 3: Combining Position- and label-based Indexing: Rows at Positions 200 and 300 and columns “Athlete” and “Medal”
1 | summer |
1 | summer.loc[[200, 300], ["Athlete", "Medal"]] |
Case 4: Combining Position- and label-based Indexing: Rows “PHELPS Michael” and positional columns 4 and 6
1 | summer = pd.read_csv("summer.csv", index_col = "Athlete") |
1 | summer |
1 | col = summer.columns[[4, 6]] |
1 | summer.loc["PHELPS, Michael", col] |
1 | #summer.ix["PHELPS, Michael", [4, 6]] |