Pandas Series
First Steps with Pandas Series
1 | import pandas as pd |
1 | titanic = pd.read_csv("titanic.csv") |
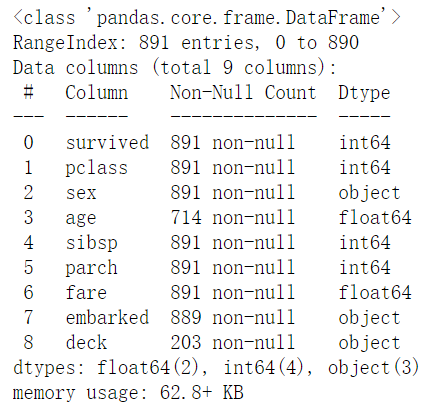
1 | titanic.info() |
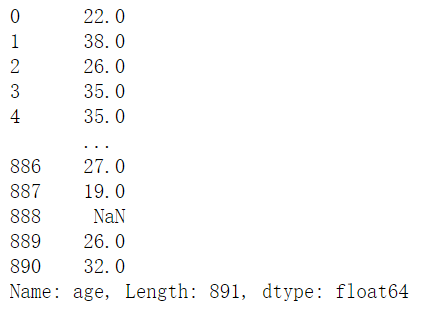
1 | titanic["age"] |
从DataFrame当中选出一列,它的类型是 Series,所以说DataFrame是由Series组合形成的
1 | type(titanic["age"]) |
从下面的代码也可以看得出选择一列可以使用方括号或者点运算符
1 | titanic["age"].equals(titanic.age) |
我们选则其中一列,看一下这个Series的参数
1 | age = titanic["age"] |
dtype 顾名思义就是 data type 代表了这一列中数据的数据类型
1 | age.dtype |
shape 代表这一列(Series) 的形状,从结果看这是一个长达 891的数组
1 | age.shape |
len就代表Series长度
1 | len(age) |
index就代表这个series的索引是怎么排列的,从结果可以看出,索引是从0开始,891结束,步长为1
1 | age.index |
如果直接 age.info()是会报错的,因为age是Series,但是并不是DataFrame,只有DataFrame才具有info()这个属性。所以我们要先用to_frame()把age给转换为DataFrame才可以
1 | age.info() |
1 | age.to_frame().info() |

Analyzing Numerical Series
接下来我们以age为例分析数字类型的 Series
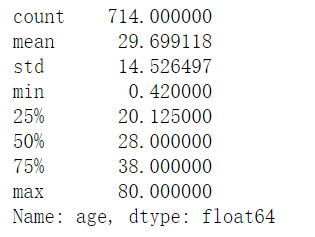
1 | age.describe() |
count()会计算出Series中非空数字的数量
1 | age.count() |
size则是包括非空和空值在内的总大小
1 | age.size |
1 | len(age) |
sum可以计算这列的总和,当skipna = False时,如果当列中有空值,那么结果会变成nan
1 | age.sum(skipna = False) |
想要跳过空值,计算可以累加的数值,那么就要设置skipna = True
1 | age.sum(skipna = True) |
unique是Series中去除重复的数值(包括nan)之后留下的数值
1 | age.unique() |
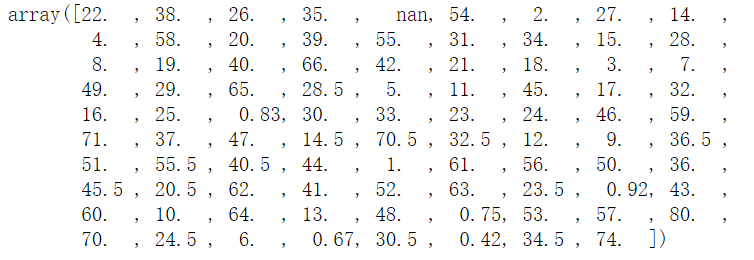
1 | len(age.unique()) |
1 | age.nunique(dropna = False) |
value_counts(sort = True)是默认的,直接用value_counts()即为排好序后的结果
1 | age.value_counts() |

1 | age.value_counts(sort = False) |
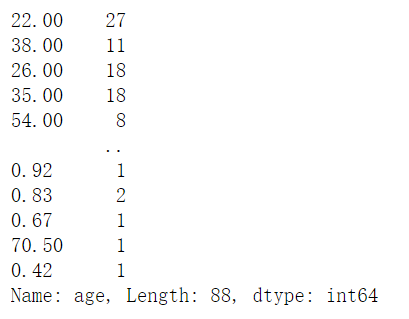
默认是dropna(跳过空值)为True的
1 | age.value_counts(dropna = True) |
1 | age.value_counts(dropna = False) |
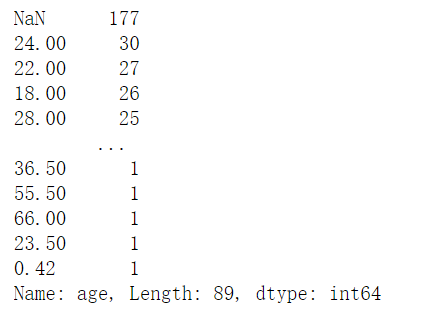
默认是降序从多到少排列的
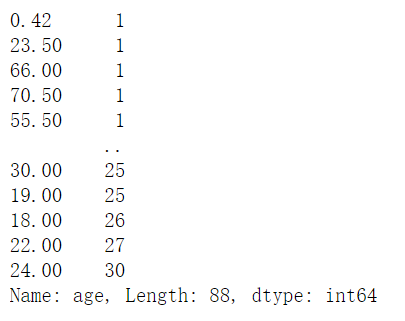
1 | age.value_counts(ascending = False) |
1 | age.value_counts(ascending = True) |
我们可以对比一下 normalize False与True的区别。当设置为True时,反应的各个分类所占的比例
1 | age.value_counts(sort = True, dropna = True, ascending = False, normalize = False) |
1 | age.value_counts(sort = True, dropna = True, ascending = False, normalize = True) |
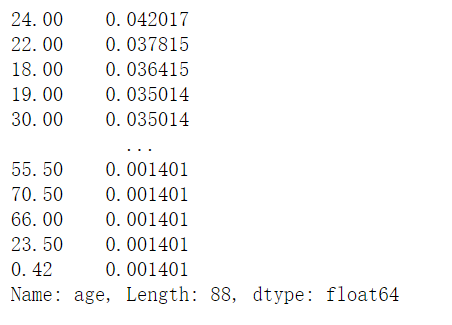
1 | age.value_counts(sort = True, dropna = False, ascending = False, normalize = True) |
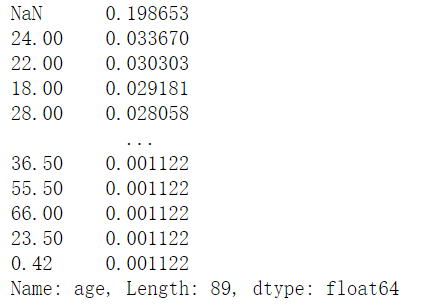
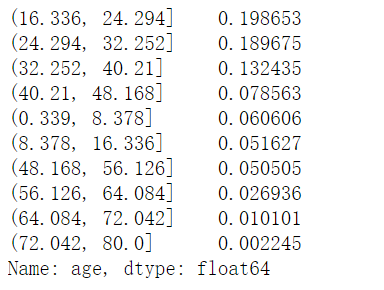
我们可以通过设置 bins,来把Series按照分布分成长度相等的几个区间,然后再统计数量。下面是分成5组和10组后的不同结果
1 | age.value_counts(sort = True, dropna = True, ascending= False, normalize = False, bins = 5) |

1 | age.value_counts(sort = True, dropna = True, ascending= False, normalize = True, bins = 10) |
Analyzing non-numerical Series
那么如果Series中的Data是非数值的呢?我们来研究一下其性质
1 | import pandas as pd |
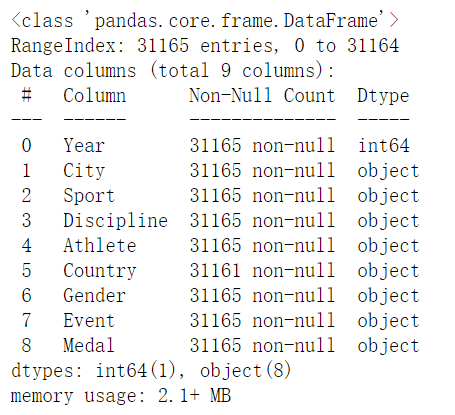
1 | summer = pd.read_csv("summer.csv") |
1 | summer.info() |
1 | athlete = summer["Athlete"] |
我们看到 athlete这个Series是非数字的。
1 | athlete.head() |

1 | type(athlete) |
dtype(‘o’)代表object类型
1 | athlete.dtype |
1 | athlete.shape |
describe()中可以看出一些简单讯息
1 | athlete.describe() |

1 | athlete.size |
1 | athlete.count() |
min()是按照字符串排序后的结果
1 | athlete.min() |
1 | athlete.unique() |
1 | len(athlete.unique()) |
1 | athlete.nunique(dropna= False) |
1 | athlete.value_counts() |
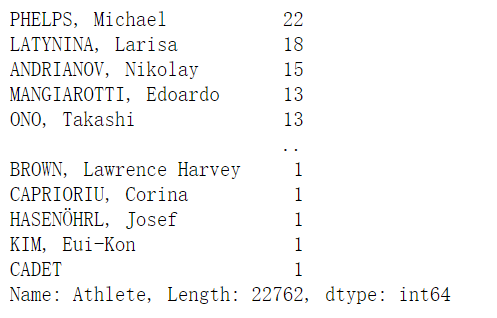
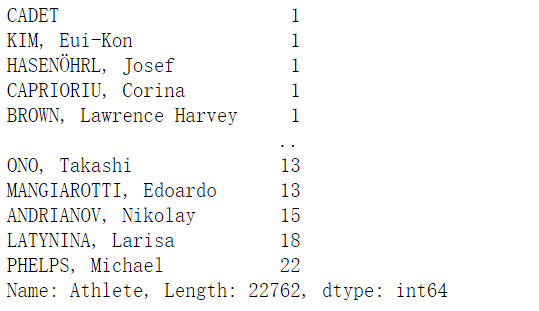
1 | athlete.value_counts(sort = True, ascending=True) |
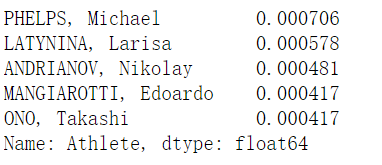
1 | athlete.value_counts(sort = True, ascending=False, normalize = True).head() |
Creating Pandas Series (Part 1)
现在我们来看看怎么创建一个Pandas Series。我们可以从DataFrame中选出一列作为Series,可以从csv中选出一列作为Series,也可以从零开始创建一个Series
1 | import pandas as pd |
from DataFrame
1 | summer = pd.read_csv("summer.csv") |
1 | summer.iloc[0] |
Importing from CSV
1 | pd.read_csv("summer.csv", usecols = ["Athlete"], squeeze = True) |
Creating from scratch with pd.Series()
直接创建一列的话,要注意,index要与值一一对应,多一个少一个都会报错!我们同时可以规定names = “” 也就是这个Series的名字
1 | pd.Series([10,25,6,36,2]) |
1 | #pd.Series([10,25,6,36,2], index=["Mon","Tue","Wed","Thu", "Fri", "Sat"]) |
1 | pd.Series([10,25,6,36,2], index=["Mon","Tue","Wed","Thu", "Fri"], name = "Sales") |
Creating Pandas Series (Part 2)
除了从上面的文件中导入、直接创建等方法。Series还可以从Array、List和Dictionary中导入。
from Numpy Array
1 | import pandas as pd |
1 | sales = np.array([10,25,6,36,2]) |
1 | pd.Series(sales) |
from List
1 | sales = [10,25,6,36,2] |
1 | pd.Series(sales) |
from Dictionary
注意,从Dictionary转换成Series的时候,key即为Index,我们人为规定index的话,必须和dic中的key一一对应,否则值就是NaN。
1 | dic = {"Mon":10, "Tue":25, "Wed":6, "Thu": 36, "Fri": 2} |
1 | sales = pd.Series(dic) |
1 | sales |
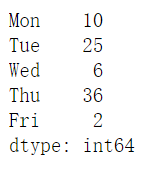
1 | pd.Series(dic, index = ["Fri", "Sat", "Sun", "Mon", "Tue", "Wed"]) |
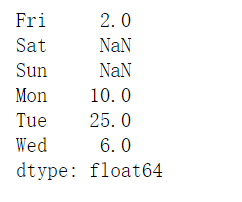
1 | pd.Series(dic, index = [1,2,3,4,5]) |

Indexing and Slicing
1 | import pandas as pd |
1 | titanic = pd.read_csv("titanic.csv") |
1 | age = titanic.age |
1 | age[0] |
1 | age[2] |
1 | age.iloc[-1] |
1 | age[890] |
1 | age[[3,4]] |

1 | age.loc[:3] |

1 | summer = pd.read_csv("summer.csv", index_col = "Athlete") |
1 | event = summer.Event |
1 | event.head() |

1 | event.index |

1 | event[0] |
1 | event.iloc[-1] |
1 | event.iloc[:3] |

1 | event["DRIVAS, Dimitrios"] |
1 | event[:"DRIVAS, Dimitrios"] |

1 | event.loc["PHELPS, Michael"] |

1 | event.loc["PHELPS, Michael"].equals(event["PHELPS, Michael"]) |
不能这样写,因为PHELPS, Michael有好多行,python会不知道到底锁定在哪一行
1 | #event[:"PHELPS, Michael"] |
1 | event.loc[["PHELPS, Michael", "LEWIS, Carl"]] |
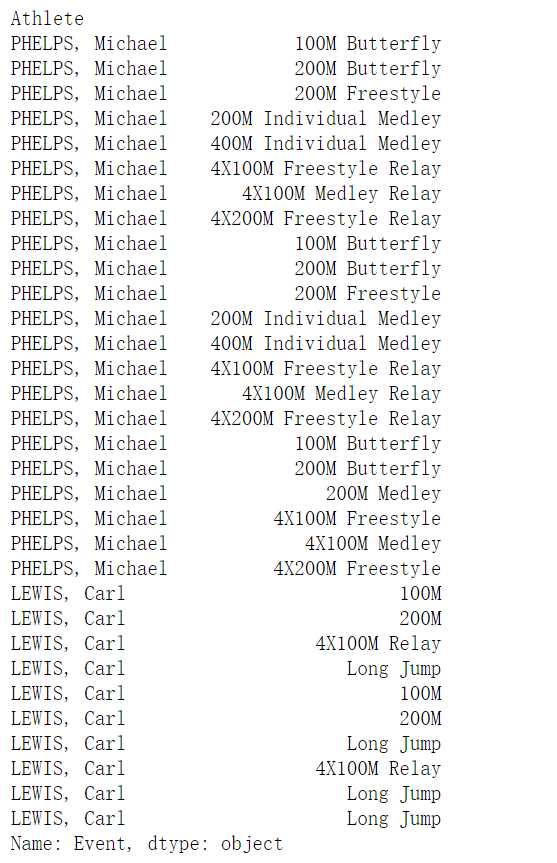
前提是这个索引是存在的哦,唐老鸭不在,所以会报错噢
1 | #event[["PHELPS, Michael", "DUCK, Donald"]] |
Sorting and introduction to the inplace-parameter
inplace = False 是缺省值,如果将其设置为True 的话,那么即为在原对象上进行修改,而不是另生成一个对象
1 | import pandas as pd |
1 | dic = {1:10, 3:25, 2:6, 4:36, 5:2, 6:0, 7:None} |
1 | sales = pd.Series(dic) |

1 | sales.sort_index() |

1 | sales.sort_index(ascending = True, inplace= True) |
1 | sales.sort_values(inplace=False) |

1 | sales.sort_values(ascending=False, na_position="last", inplace= True) |

1 | dic = {"Mon":10, "Tue":25, "Wed":6, "Thu": 36, "Fri": 2} |
1 | sales = pd.Series(dic) |
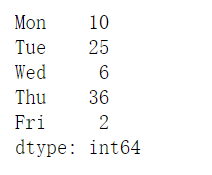
1 | sales.sort_index(ascending=False) |

nlargest() and nsmallest()
在pandas库里面,我们常常关心的是最大的前几个,比如销售最好的几个产品,几个店,等。之前讲到的head(), 能够看到看到DF里面的前几行,如果需要看到最大或者最小的几行就需要先进行排序。max()和min()可以看到最大或者最小值,但是只能看到一个值。
所以我们可以使用nlargest()函数,nlargest()的优点就是能一次看到最大的几行,而且不需要排序。 同理nsmallest()则是一次看到最小的几行
1 | import pandas as pd |
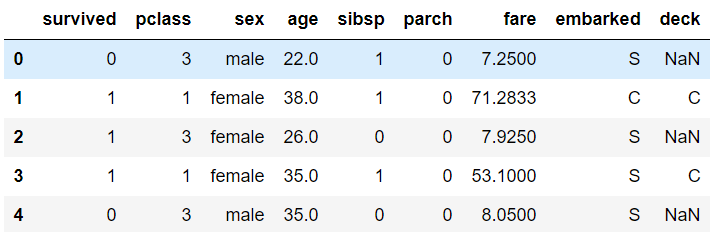
1 | titanic = pd.read_csv("titanic.csv") |
1 | titanic.head() |
1 | age = titanic.age |
1 | age.sort_values(ascending=False).head(3) |

1 | age.sort_values(ascending=True).iloc[:3] |
1 | age.nlargest(n = 3).index[0] |
1 | age.nsmallest(n = 3).index[0] |
idxmin() and idxmax()
1 | titanic.age.idxmax() |
1 | titanic.age.idxmin() |
1 | titanic.loc[630] |

1 | titanic.loc[titanic.age.idxmin()] |
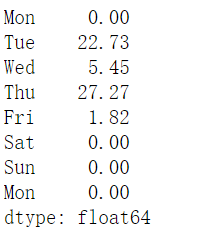
1 | dic = {"Mon":10,"Tue":25, "Wed":6, "Thu":36, "Fri":2, "Sat":0, "Sun":None} |
1 | sales.sort_values(ascending=True).index[0] |
1 | sales.idxmin() |
1 | sales.sort_values(ascending=False).index[0] |
1 | sales.idxmax() |
Manipulating Series
1 | import pandas as pd |
1 | sales = pd.Series([10,25,6,36,2,0,None,5], index = ["Mon", "Tue", "Wed", "Thu", "Fri", "Sat", "Sun", "Mon"]) |
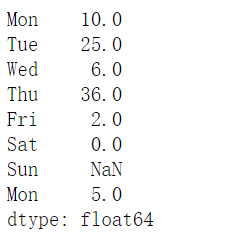
1 | sales["Sun"] = 0 |
1 | sales |
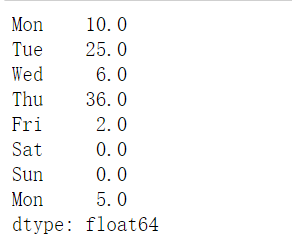
1 | sales.iloc[3] = 30 |
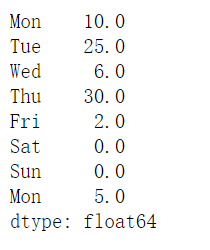
1 | sales_EUR = (sales/1.1).round(2) |
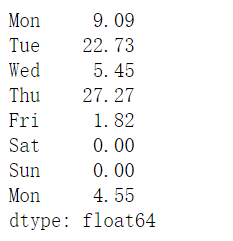
1 | sales = (sales/1.1).round(2) |
1 | sales["Mon"] = 0 |