BFSandDFS
DFS
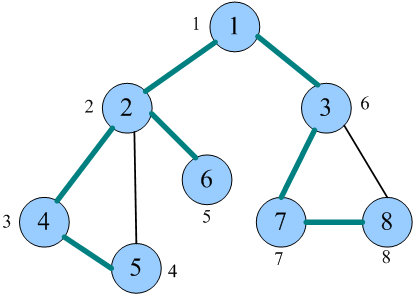
深度优先搜索(Depth First Search,DFS),是最常见的图搜索方法之一。深度优先搜索沿着一条路径一直走下去,无法行进时,回退回退到刚刚访问的结点,似不撞南墙不回头,不到黄河不死心。深度优先遍历是按照深度优先搜索的方式对图进行遍历。
时刻牢记: 后被访问的顶点,其邻接点先被访问。根据深度优先遍历秘籍,后来先服务,可以借助于栈实现。递归本身就是使用栈实现的,因此使用递归方法更方便。
1.初始化图中所有顶点未被访问。
2.从图中的某个顶点v出发,访问v并标记已访问;
3.依次检查v的所有邻接点w,如果w未被访问,则从w出发进行深度优先遍历(递归调用,重复2—3步)。
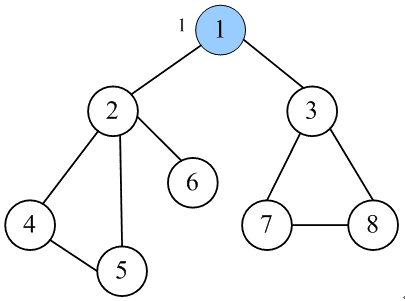
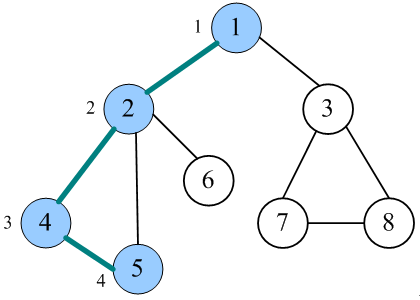
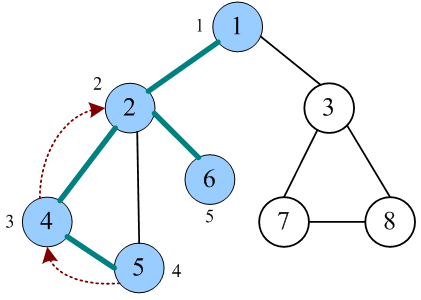
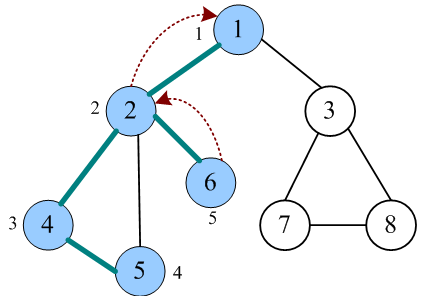
代码一览
基于邻接表的深度优先遍历
1 |
|
基于邻接矩阵的深度优先遍历。
1 |
|
算法分析
1.基于邻接矩阵的DFS算法
查找每个顶点的邻接点需要O(n)时间,一共n个顶点,总的时间复杂度为$O(n^2)$,使用了一个递归工作栈,空间复杂度为O(n)。
2.基于邻接表的DFS算法
查找顶点vi的邻接点需要O(d(vi))时间,d(vi)为vi的出度(无向图为度),对有向图而言,所有顶点的出度之和等于边数e,对无向图而言,所有顶点的度之和等于2e,因此查找邻接点的时间复杂度为$O(e)$,加上初始化时间$O(n)$,总的时间复杂度为$O(n+e)$,使用了一个递归工作栈,空间复杂度为$O(n)$。
BFS
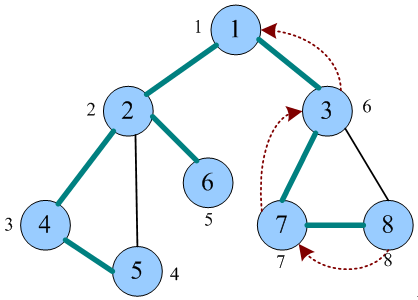
广度优先搜索(Breadth First Search,BFS),又称为宽度优先搜索,是最常见的图搜索方法之一。广度优先搜索是从某个顶点(源点)出发,一次性访问所有未被访问的邻接点,再依次从这些访问过邻接点出发,…,似水中涟漪,似声音传播,一层层地传播开来。广度优先遍历是按照广度优先搜索的方式对图进行遍历。
记住: 先被访问的顶点,其邻接点先被访问。
根据广度优先遍历秘籍,先来先服务,可以借助于队列实现。每个结点访问一次且只访问一次,因此可以设置一个辅助数组:
visited[i]=false,表示第i个顶点未访问;
visited[i]=true,表示第i个顶点已访问。
1.初始化图中所有顶点未被访问,初始化一个空队列。
2.从图中的某个顶点v出发,访问v并标记已访问,将v入队;
3.如果队列非空,则继续执行,否则算法结束;
4.队头元素v出队,依次访问v的所有未被访问邻接点,标记已访问并入队。转向步骤3;
代码一览
基于邻接表的广度优先遍历
1 |
|
基于邻接矩阵的广度优先遍历
1 |
|
算法分析
1.基于邻接矩阵的BFS算法
查找每个顶点的邻接点需要$O(n)$时间,一共$n$个顶点,总的时间复杂度为$O(n^2)$,使用了一个辅助队列,最坏的情况下每个顶点入队一次,空间复杂度为$O(n)$。
2.基于邻接表的BFS算法
查找顶点vi的邻接点需要O(d(vi))时间,d(vi)为$v_i$的出度(无向图为度),对有向图而言,所有顶点的出度之和等于边数e,对无向图而言,所有顶点的度之和等于2e,因此查找邻接点的时间复杂度为O(e),加上初始化时间$O(n)$,总的时间复杂度为$O(n+e)$,使用了一个辅助队列,最坏的情况下每个顶点入队一次,空间复杂度为$O(n)$。
总而言之,只要是邻接矩阵,BFS、DFS都是 $O(n^2)$ ; 只要是邻接表,BFS、DFS 时间复杂度都是 $O(n)$