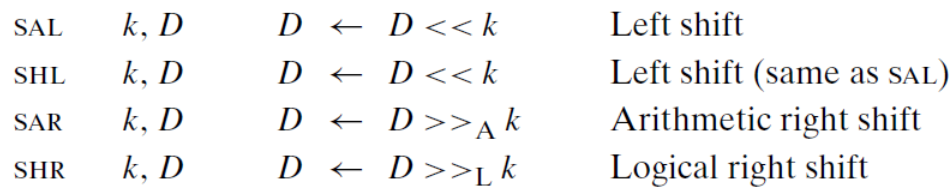CSAPP程序的机器级表示1
本章内容:
- 快速浏览C语言、汇编代码以及机器代码之间的关系。
- 介绍 x86-64 的细节:从数据的表示和处理以及控制的实现(C语言中的if,while,switch等控制结构)
- 过程的实现(如程序如何维护一个运行栈来支持过程间数据和控制的传递,以及局部变量的存储)
- 考虑在机器级如何实现像数组、结构和联合这样的数据结构
- 讨论内存访问越界问题、洗头膏容易遭到缓冲区溢出攻击的问题。
- 用GDB调试器检查机器级程序运行时行为的技巧
- 浮点数据和操作的代码的机器程序表示
程序编码
之前我们讲过用
1 | gcc -Og -o p p1.c p2.c |
来编译 p1.c 和 p2.c 两个文件。编译选项 -Og 告诉编译器使用会产生符合原始C代码整体结构的机器代码的优化等级。因为使用较高级别的优化代码会使其严重变形,以至于产生的机器代码和源代码的关系变得难以理解。所以我们先从最基础的-Og开始,再看看较高级别的优化(-o1或-o2)会发生什么。
机器级代码
在整个编译过程中,编译器会完成大部分的工作,把C语言转化成处理器执行的非常基本的指令。汇编代码非常接近于机器代码,与机器代码的二进制格式比,汇编的主要特点就是他用可读性更好的文本格式表示。能够理解汇编代码以及它原始C代码的联系,使理解计算机如何执行程序的关键一步。
我们先了解一些寄存器的概念:
- 程序计数器(通常称为 “PC”, 在 x86-64中用 %rip 表示) 给出将要执行的下一条指令在内存当中的地址
- 整数寄存器文件包含16个命名的位置用来存储64位的值。这些寄存器可以存储地址(对应于C语言的指针) 或整数数据。有的寄存器被用来记录某些重要的程序状态;其他的寄存器哟个来保存临时数据(参数、局部变量、返回值)
- 条形码寄存器保存着最近执行的算术或者逻辑指令的状态信息。它们用来实现控制数据流中的条件变化(if 和 while)
- 一组向量寄存器可以存放一个或者多个整数或浮点数值
一条机器指令只执行一个非常基本的操作。例如将存放在寄存器中的两个数字相加,在寄存器和存储器之间传送数据,或是条件分支转移到新的指令地址。编译器必须产生这些指令的序列,从而实现(如算术表达式求值、循环或者过程调用和返回)程序结构
代码示例
比如我写一个C语言代码
1 |
|
然后我们用 gcc -Og -S mstore.c 命令来进行编译
得到mulstore的汇编语言形式:
1 | multstore: |
上面代码mulstore下的每行都代表一条机器指令。比如 pushq指令表示应该将寄存器 %rbx 的内容压入程序栈当中。这段代码中已经除去了所有关于局部变量名或者数据类型的信息。
我们再进一步用 gcc -Og -c mstore.c 来进行编译,这就会产生目标代码文件 mstore.c ,他是二进制格式的无法直接查看。转换为十六进制之后可以看到汇编指令对应的目标代码。
我们从中得到一个重要信息,即机器执行的程序只是一个字节序列,它是对一系列指令的编码。机器对产生这些指令的源代码几乎一无所知
要查看机器代码文件的内容,有一类称为 反汇编器的程序非常有用。这些程序根据机器代码产生一种类似于汇编代码的格式。我们可以用命令 objdump -d mstore.o 来实现
1 | 0000000000000000 <multstore>: |
在左边十六进制字节值被分成了机组,每组都是一条指令,右边是等价的汇编语言。
其中,一些关于机器代码和它的反汇编表示的特性值得注意:
- x86-64 的指令长度从1到15个字节不等。常用的指令以及操作数较少 的指令所需的字节数少,而那些不太常用或操作数较多的指令所需的字节数较多
- 设计指令格式的方式是,从某个给定位置开始,可以将字节唯一地解码成机器指令。例如,只有指令pushq %rbx 是以字节值53 开头的。
- 反汇编器只是基于机器代码文件中的字节序列来确定汇编代码。它不需要访问该程序的源代码或汇编代码。
- 反汇编器使用的指令命名规则与GCC 生成的汇编代码使用的有些细微的差别。在我们的示例中,它省略了很多指令结尾的 ‘q’ 这些后缀是大小指示符,在大多数情况中可以省略。相反,反汇编器给call 和ret 指令添加了 ‘q’ 后缀,同样,省略这些后缀也没有问题。
关于格式的注解
所有以 ‘.’ 开头的行 都是指导汇编器和链接器工作的伪指令。我们通常可以忽略这些行。另一方面,也没有关于指令的用途以及他们与源代码之间关系的解释说明。
为了清楚的说明汇编代码,我们用下面这种格式来表示汇编代码,他省略了大部分伪指令,但包括行号和解释性说明。
1 | void multstore(long x, long y, long *dest) |
上面这种格式简单地描述了指令的效果以及它与原始C语言代码中的计算操作的关系。这是一种汇编语言程序员写代码的风格
数据格式
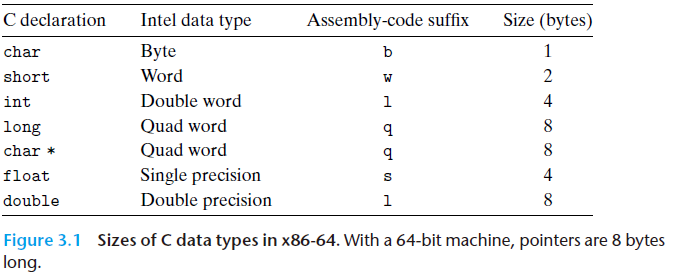
Intel用 “word” 表示16位数据类型。因此称32位数为 “double words” ,64位数为 “quad words” . 下图是C语言基本数据类型对应的 x86-64表示的表格
浮点数主要有两种形式
单精度(4字节) 值,对应于C中的 Float
双精度(8字节) 值,对应于C中的 Double
大多数GCC生成的汇编代码指令都有一个字符的后缀,表明操作数的大小。比如
moveb(传送字节)、movw(传送字)…后缀‘l’用来表示双字,因为32 位数被看成是“长字(long word)” 。注意,汇编代码也使用后缀‘l’来表示4 字节整数和8 字节双精度浮点数。这不会产生歧义,因为浮点数使用的是一组完全不同的指令和寄存器。
访问信息
我们首先来了解一下寄存器(register) 的历史
最初的8086处理器中8个16位的寄存器,即位下面的 $\%ax$ 到 $\%bp$ 。 每一个寄存器都有特殊的用处。
当扩展到IA32架构时 ,这些寄存器也扩展成32位了,标号从 $\%eax$ 到 $\%ebp$
扩展到 x86-64 之后,从原来的8个寄存器扩展成64位,标号从 $\%rax$ 到 $\%rbp$ .此外还增加了8个新的寄存器,它们的表好是按照新的命名规则制定的 $\%r8$ 到 $\%r15$
在常见的程序里不同的寄存器扮演着不同的角色。其中最特别的是栈指针 $\%rsp$ 用来指明栈的结束位置。有些程序会明确地读写这个寄存器。
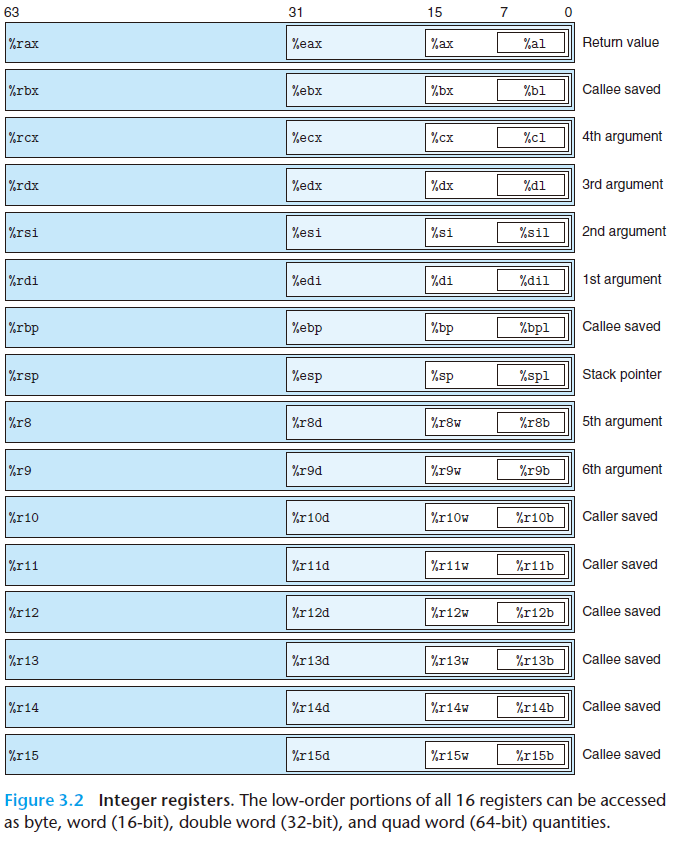
指令可以对这16个寄存器的低位字节中存放的不同的数据进行操作。
- 字节级操作可以访问最低的字节(the least significant byte)
- 16位的操作能访问最低的2个字节
- 32位操作可以访问最低的4个字节
- 64位操作可以访问整个寄存器。
当生成的指令以寄存器为目标时,对于生成小于8字节结果的指令,寄存器中剩下的字节会怎么样,对此有两条规则
- 生成1字节和2字节数字的指令会保持剩下的字节不变
- 生成4字节的数字的指令会把高位4个字节设置为0。后面这条规则是作为从IA32到x86-64 的扩展的一部分而采用的
操作数指示符
大多数指令都有一个或者多个操作数(operand) , 指示出执行一个操作中要使用的源数据值以及放置结果的目的位置。
源数值可以存放在寄存器或内存当中。因此,各种不同的操作数的可能性被分成三种类型:
- 立即数(immediate) ,用来表示常数值。 书写方式是 $ 后面跟一个标准C表示法表示的整数,比如 $-577 或$ 0x1F
- 寄存器(register), 我们用 $r_0$ 来表示任意寄存器 a, 用引用 $R[r_a]$ 来表示它的值,这是将寄存器集合看成一个数组R,用寄存器标识符作为索引
- 内存引用。它会根据计算出来的地址访问某个内存位置。因为将内存看成一个很大的字节数组,我们用负号$M_b[Addr]$ 表示对存储在内存中从地址 $Addr$ 开始的b个字节值的引用。为了简便,我们通常省略下标b
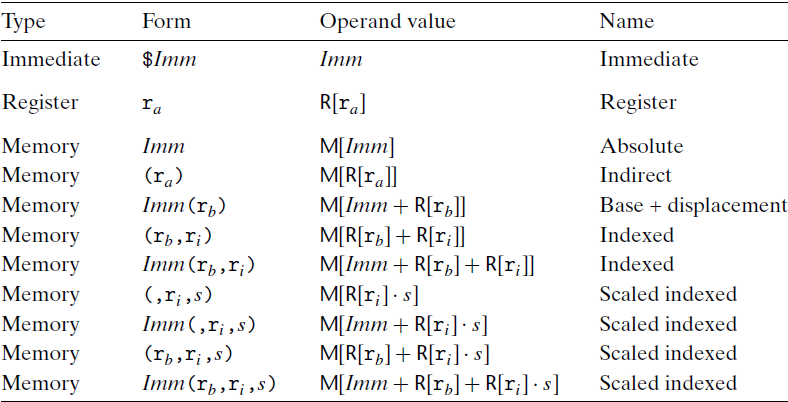
我们来 仔细解读一下这张表格,$$Imm 和R[r_a]$ 就不用说了。
- $M[Imm]$ 是绝对寻址。也就是按照
Imm取内存中寻址 - $M[R[r_0]]$ 是间接寻址。也就是说寄存器R中指定了一段内存地址,然后以此去寻址。
moveq (%rcx),%rax
- $M[Imm+R[r_b]]$ 是 基址+偏移量 寻址。寄存器指定了一段内存空间,然后 $Imm$ 表明了偏移量
move 8(%rbp),%rdx
- $M[R[r_b]+R[r_i]]$ 变址寻址
- $M[R[r_b]+R[r_i]+Imm]$ 变址寻址
最后一行是 $M[Imm+R[r_b]+R[r_i]\cdot s]$
$IMM$ 就代表着 偏移数,1,2或者4个字节
$r_b$ 就是基址:任意一个寄存器
$r_i$ 是变址寄存器
s是比例因子,必须是1、2、4或者8
比如说,对于 $2(\%rsp,\%rax,4)$ 这个操作数来讲,它代表的是内存地址为 $2+\%rsp+4\cdot \%rax$ 的存储器区域的值。
练习
比如说 现在 $\%rdx$中的数字为 $0xf000$ ,$\%rcx$ 中的数字为 $0x0100$ ,我们可以做一个这样的表格
| Expression | Address Computation | Address |
|---|---|---|
| $0x8(\%rdx)$ | 0xf000+0x8 | 0xf008 |
| $(\%rdx,\%rcx)$ | 0xf000+0x100 | 0xf100 |
| $(\%rdx,\%rcx,4)$ | 0xf000+4*0x100 | 0xf400 |
| $0x80(,rdx,2)$ | 2*0xf000+0x80 | 0x1e080 |
数据传送指令
下图列出了形式最简单的数据传送指令 $MOV$ 类。这些指令把数据从原位置复制到目的位置而不做任何变化。
MOV跟着的后缀不同,则指令可操作的数据大小也不同。
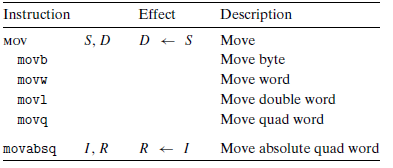
源操作数指定的值是一个立即数,存储在寄存器或者内存中。
目的操作数指定一个位置们要么是一个寄存器地址要么是一个内存地址。
x86-64规定传送指令的两个操作数不能都指向内存位置。将一个值从一个内存位置复制到另一个内存位置需要两条指令:第一条指令将源值加载到寄存器中,第二条将该寄存器值写入目的位置。
这些指令的寄存器可以是16个寄存器有标号部分中的任意一个,寄存器部分的大小必须和指令的后缀(bwlq) 指定的大小相匹配。
有一个例外,当movl指令以寄存器位目的时,它会把该寄存器的高位4字节设置为0。这是因为x86-64采用的任何寄存器生成32位值都会把该寄存器的高位部分设置为0这一惯例。
例子:
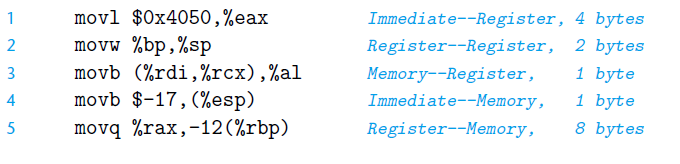
第一个是源操作数(source),第二个是目的操作数(destination).
- 第一行就是将一个立即数放到寄存器当中,长度为4个字节
- 第二行是将寄存器转移到寄存器当中,长度为2个字节
- 第三行是将内存中的数据转移到寄存器当中,长度为1个字节
- 第四行是将立即数存储到内存当中,长度为1个字节
- 第五行是将寄存器中的数存到内存当中,长度为8个字节
下面两张表格记录的是两类移动指令,是当将较小的源值复制到较大的目的时使用的。
MOVZ类中的指令是在复制到寄存器后将剩余的字节填充为0
MOVS类中的指令则是通过符号扩展来填充,把源操作数的最高位进行赋值。
我们可以看到每条指令名字的后两个字符都是大小指示符,第一个字符指定源的大小,而第二个指明destination的大小
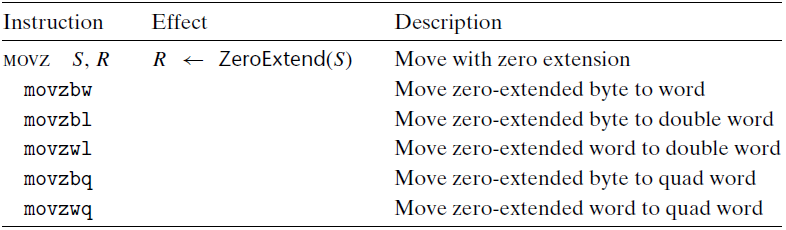
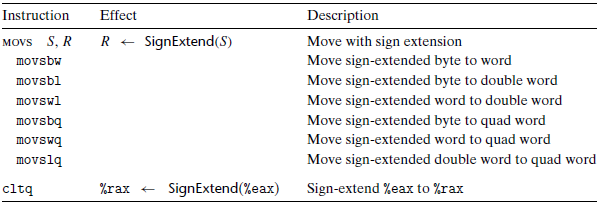
注意:cltq指令没有操作数,它总是以寄存器$\%eax$ 作为源,$\%rax$ 作为符号扩展结果的目的。它的效果与指令$moveslq~~ \%eax,\%rax$ 完全一致,不过编码更紧凑。
练习:

我们知道,两个地址之间不能传值.操作指令的后缀取决于寄存器的大小: 两个寄存器之间如果要传值必须要保证两个寄存器的位数大小相同。地址和寄存器之间传递数据,指令后缀取决于寄存器。
- 因为从%eax 传向 地址,所以后缀和 %eax相匹配,为
movl - 因为从地址传向 %dx ,所以后缀和 %dx 相匹配,为
movw - 因为从地址传向 %bl,所以后缀和 %bl 匹配,为
movb - 同上,为
movb - 从地址传向 %rax,所以后缀和%rax相匹配,为
movq - 从%dx传向地址,和%dx相匹配,为
movw

| 错误之处 |
|---|
%bx系列寄存器时被调用者保存的寄存器,不能拿来当成地址 |
%rax是64位的寄存器,而movl匹配的是32位的寄存器,应该改为 movq |
| 不能在两个地址之间传递数据 |
没有%sl这个名字的寄存器 |
不能将寄存器中的数据移动给一个 Immediate(直接值) |
| 在两个寄存器之间传递值的时候,两个寄存器的大小要保持相等 |
%si 是16位寄存器,而 movb匹配的是8位寄存器,应该改为 movw |
数据传送示例
我们现在来考虑一个exchange代码
1 | long exchange(long *xp, long y) |
然后看看这个函数的汇编代码:
1 | long exchange(long *xp, long y) |
我们看到函数exchange由三条指令实现:两个数据传送(movq) 加上一条返回函数被调用点的指令(ret)
当过程开始时,参数xp和y分别存储在 $\%rdi$ 和$\%rsi$ 中。然后,指令2从内存中读出xp指向的x,将其存到寄存器$\%rax$ 中,直接实现了C程序中的操作 $x=*xp$ 。然后用 $\%rax$ 从这个函数返回一个值,因而返回的值就是x
指令3将y写入到寄存器$\%rdi$ 中的 $xp$ 指向的内存位置,直接实现了操作 $*xp=y$ 这个例子说明了如何用 $MOV$ 指令从内存中读值到寄存器,如何从寄存器写到内存当中。
我们要注意两点
- C语言中所谓的指针其实就是地址。简介引用指针就是将指针放在一个寄存器中,然后在内存引用中使用这个寄存器
- 像x这样的局部变量常常是保存在寄存器当中而不是内存中。访问寄存器比访问内存要快得多

这道题要注意几个点:
- 高位转向低位(如 int 转成 char; unsigned 转换为 unsigned char) 不需要用
movzbl,movsbl之类的命令,直接将后几位移动到相应大小的寄存器即可 - 低位转为高位,需要进行符号扩展或零扩展;选择那种扩展取决于源数据的数据类型。比如源数据是char,转换为unsigned,那么就要用
movsbl来进行符号扩展; 如果原来是unsigned char 要转换为long类型,那么就要用movzbl来 进行 零扩展。

%r8,%rcx,%rax是三个新的变量,我们不妨将其命名为x,y,z
1 | void decode1(long *xp,long *yp,long *zp) |
压入和弹出栈数据
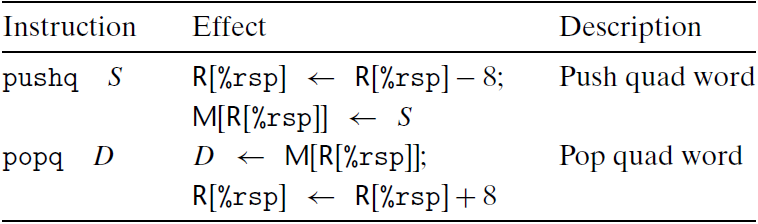
pushq指令的功能就是把数据压入到栈上,而popq指令是弹出数据。这些指令都只有一个操作数-压入的数据源 和 弹出的数据目的
将一个四字值压入栈中,首先要将栈指针减去8,然后将值写到新的栈顶地址。因此指令 $pushq ~~\%rbp$ 的行为等价于
1 | subq $8,%rsp |
只是前面的 $pushq ~~\%rbp$ 只是一个字节,而后面两条指令一共需要8个字节。
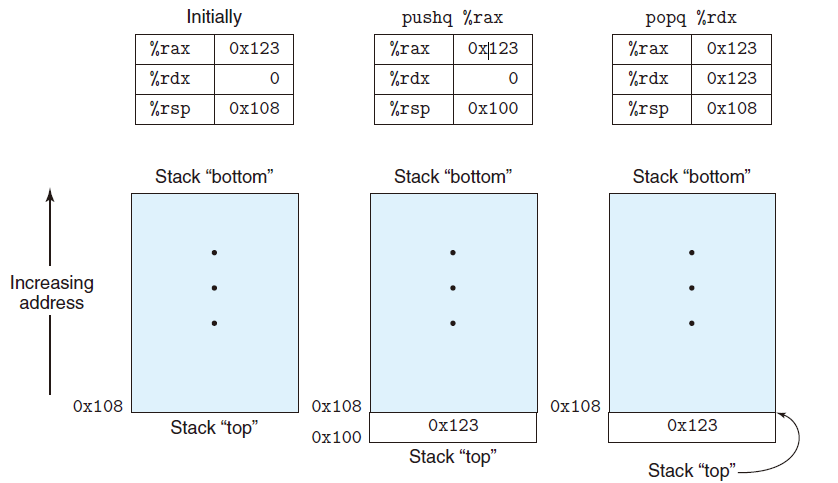
上图的最右边说得是在pushq后立即执行指令 popq %rdx 的效果。先从内存中读取值 0x123,再写道寄存器 $\%rdx$ 中,然后,寄存器 $\%rsp$ 的值将从 0x100增加到 0x108 . 如图,值0x123仍然会保存在内存位置 $0x100$ 中,直到被覆盖。无论如何,$\% rsp$ 指向的地址总是栈顶。
因为栈和程序代码以及其他形式的程序数据都是放在同一内存中,所以程序可以用标准的内存寻址方法访问栈内的任意位置。例如,假设栈顶元素是四字,指令movq 8(rsp),%rdx 会将第二个四字从栈中复制到寄存器 %rdx
算数和逻辑操作
下面是一些整数和逻辑操作。大多数操作分成了指令类,这些指令类有各种带不同大小操作数的变种(除了leaq外)。 例如ADD由四条加法指令 addb、addw、addl、addq 组成。
事实上给出的每个指令类都有对这四种大小不同的数据的指令。这些操作被分为四组:加载有效地址、一元操作、二元操作和移位。二元操作有两个操作数,而一元操作有一个操作数。
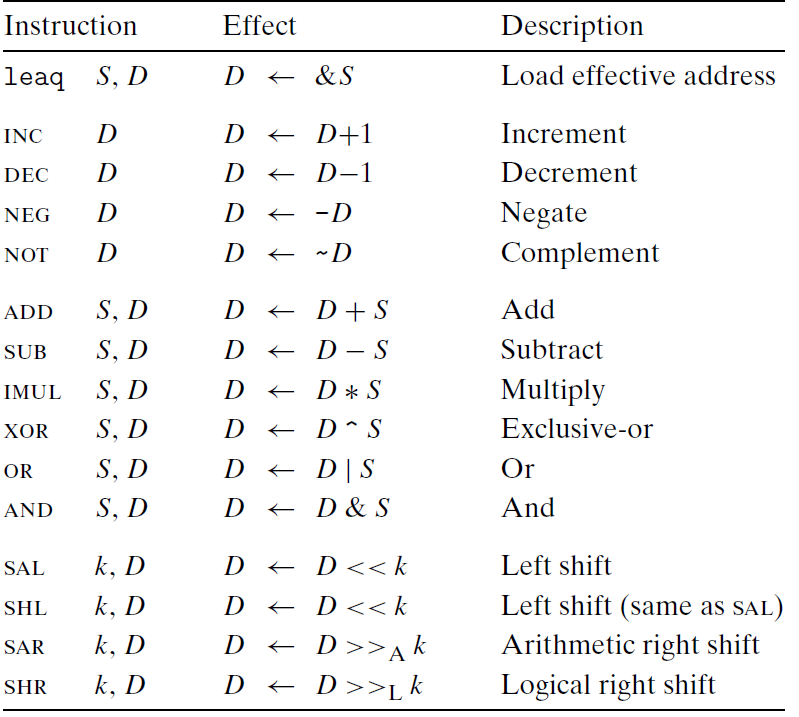
加载有效地址
load effective address(加载有效地址)指令leaq 实际上是 movq的变形。
leaq src,Dst
- Src is address mode expression
- Set Dst to address denoted by expression
leaq主要用来简洁的描述普通的算术操作。例如如果寄存器 $\%rdx$ 的值为x,那么指令 $leaq ~~7(\%rdx,\%rdx,4),\%rax$ 将设置寄存器 $\%rax$ 的值为 $5x+7$ ,编译器经常发现 leaq 的一些灵活用法,根本和有效地址计算无关
比如下面这个C程序
1 | long scale(long x, long y, long z) { |
编译成汇编语言的到
1 | long scale(long x, long y, long z) |
leaq 能执行加法和有限形式的乘法,在编译如上简单的算术表达式时,是很有用处的。
一元和二元操作
这一组操作是一元操作,只有一个操作数,既是源又是目的。这个操作数可以实寄存器也可以是一个内存位置。
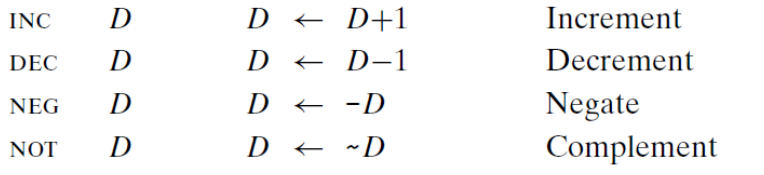
第三组是二元操作,其中,第二个操作数既是源又是目的。这种语法让人想起C 语言中的赋值运算符,例如x-=y。 不过,要注意,源操作数是第一个,目的操作数是第二个, 对于不可交换操作来说,这看上去很奇特。例如,指令subq%rax,%rdx 使寄存器%rdx的值减去%rax 中的值。(将指令解成”从%rdx 中减去%rax” 会有所帮助。)第一个操作数可以是立即数、寄存器或是内存位置。第二个操作数可以是寄存器或是内存位置。注意,当第二个操作数为内存地址时,处理器必须从内存读出值,执行操作,再把结果写回内存.
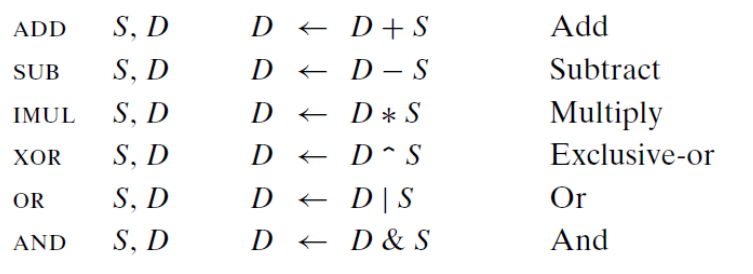
移位操作
最后一组是移位操作,先给出移位量,然后第二项给出的是要移位的数。可以进行算术和逻辑右移。移位量可以是一个立即数,或者放在单字节寄存器%cl 中。(这些指令很特别,因为只允许以这个特定的寄存器作为操作数。)原则上来说,1 个字节的移位量使得移位量的编码范围可以达到$2^8-1= 255$。X86-64 中,移位操作对w 位长的数据值进行操作,移位量是由%cl 寄存器的低m 位决定的,这里$2^m=w$ 高位会被忽略。所以,例如当寄存器%cl 的十六进制值为OxFF 时,指令salb 会移7 位,salw 会移15 位,sail 会移31 位,而salq 会移63 位。
如下图所示,左移指令有两个名字:SAL 和SHL。两者的效果是一样的,都是将右边填上0。右移指令不同,SAR 执行算术移位(填上符号位), 而SHR 执行逻辑移位(填上0)。
移位操作的目的操作数可以是一个寄存器或是一个内存位置。图 3-10 中用$>>_A$(算术)和$>>_L$(逻辑)来表示这两种不同的右移运算。