决策树和随机森林回归
决策树
https://www.jianshu.com/p/fcbbd8f2acd5
首先我们来了解一下CART(Classification And Regression Tree) 的定义。它被分为两类:分类决策树(Classification Trees) 和 回归决策树 (Regression Trees). 这也是我们要用决策树解决的两类问题:分类问题和回归问题。
对于分类决策树,一般来说用于一些分类离散的数据,比如说人的性别是男或者女,水果的种类有苹果梨子等等都是离散的。反之回归决策树,那么对应的场景就是连续的数据,比如人的年龄或者室外的温度。当我们进行分类问题时,分类的组之间是无序的。这里首先介绍下什么是有序,可以举个例子比如年龄,又年龄大或者年龄小。那么对于性别问题,男或女,它是没有顺序的
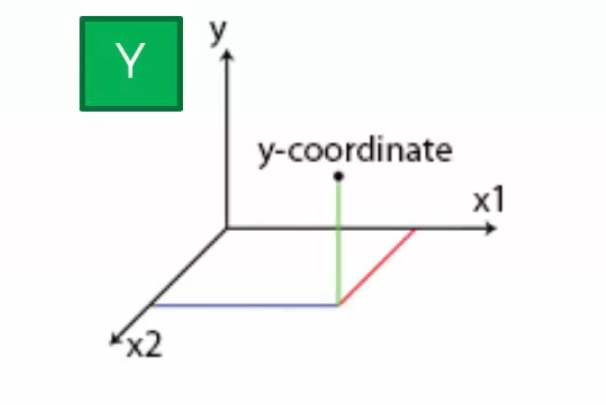
对于下面这幅散点图,我们要通过其来预测一个第三个维度的独立变量y,我们在二维平面中没有办法看到

如果将其放到一个三维空间里,那么我们就可以将这个y变量显示出来。
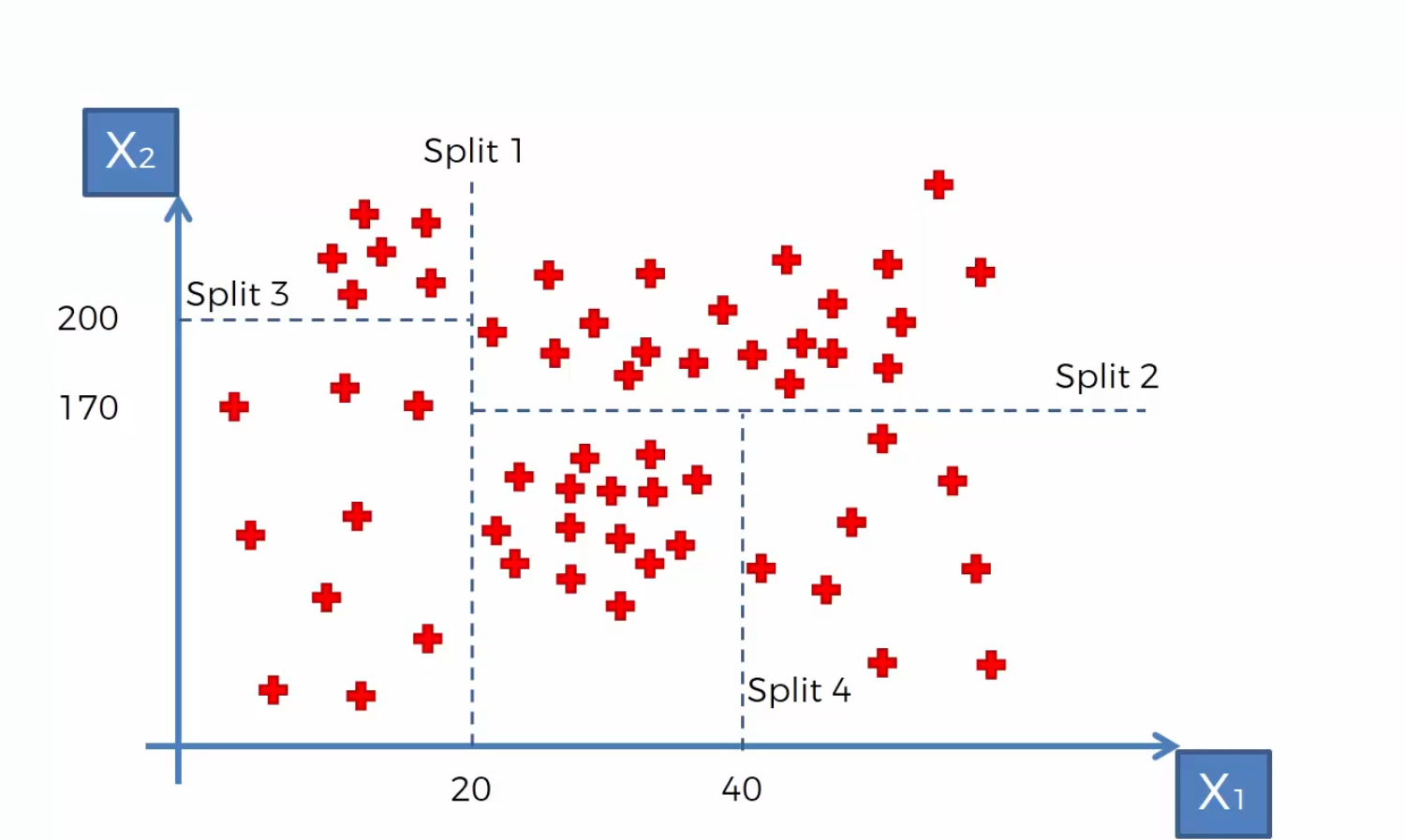
当我们运行回归树/决策树模型的时候,上面的散点图就会被分成几个部分,就向下图一样。算法会计算信息熵并决定在那里执行划分,将这些散点分组。那么怎么停止呢?比如说当算法增加一个splits,有一个组(leaves)中的数据低于所有数据的5%,那么这个splits就不会被划分。
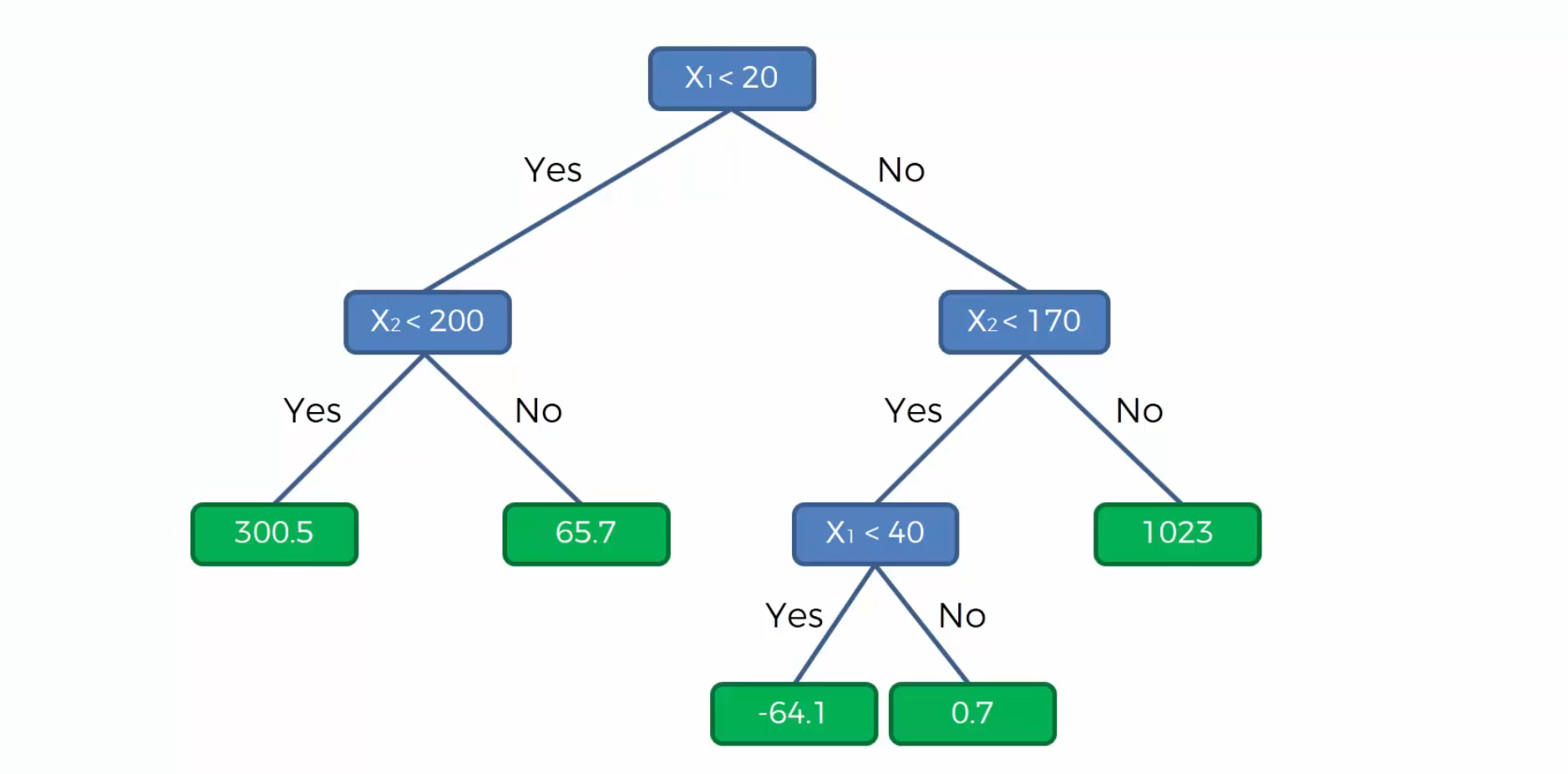
现在我们还原创建决策树的过程:
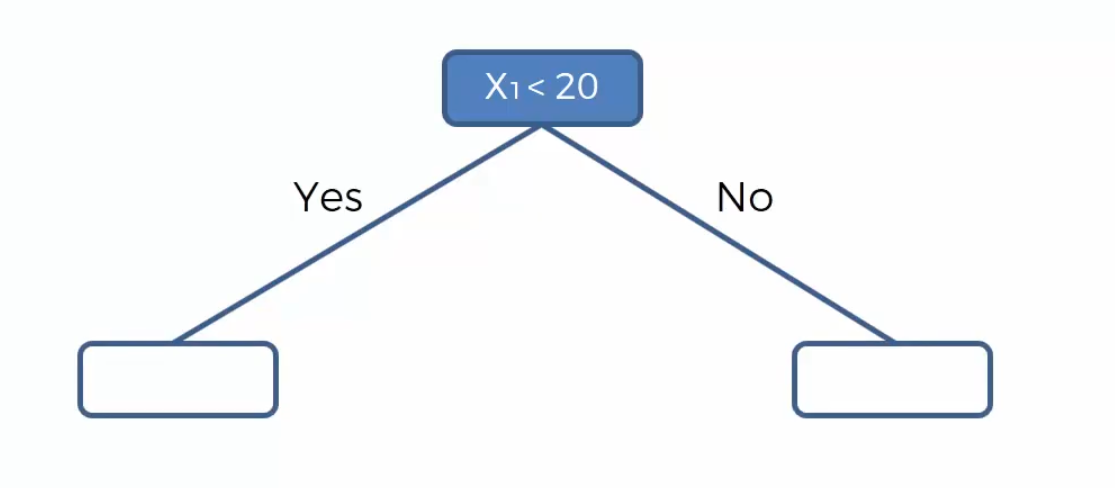
- 首先在 $x_1 = 20$ 处画一条分割线,那么决策树的第一个分支就是判断 $x_1$ 是否小于20,并分成2类。
- 然后我们在$x_2=170,x_1>20$ 处画一条分割线,那么决策树在右孩子会生成第二个分支,判断 $x_2$ 是否大于170
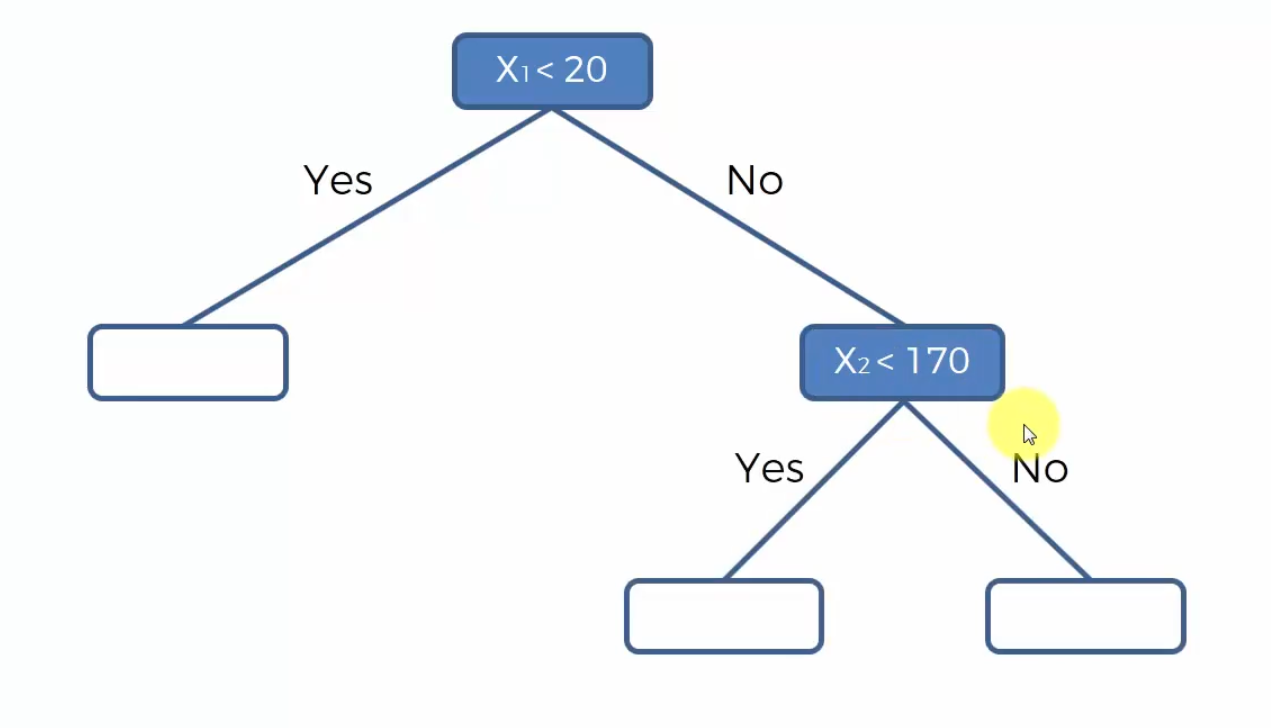
- 接着我们在 $x_2=200,x_1<20$ 画一条 分割线
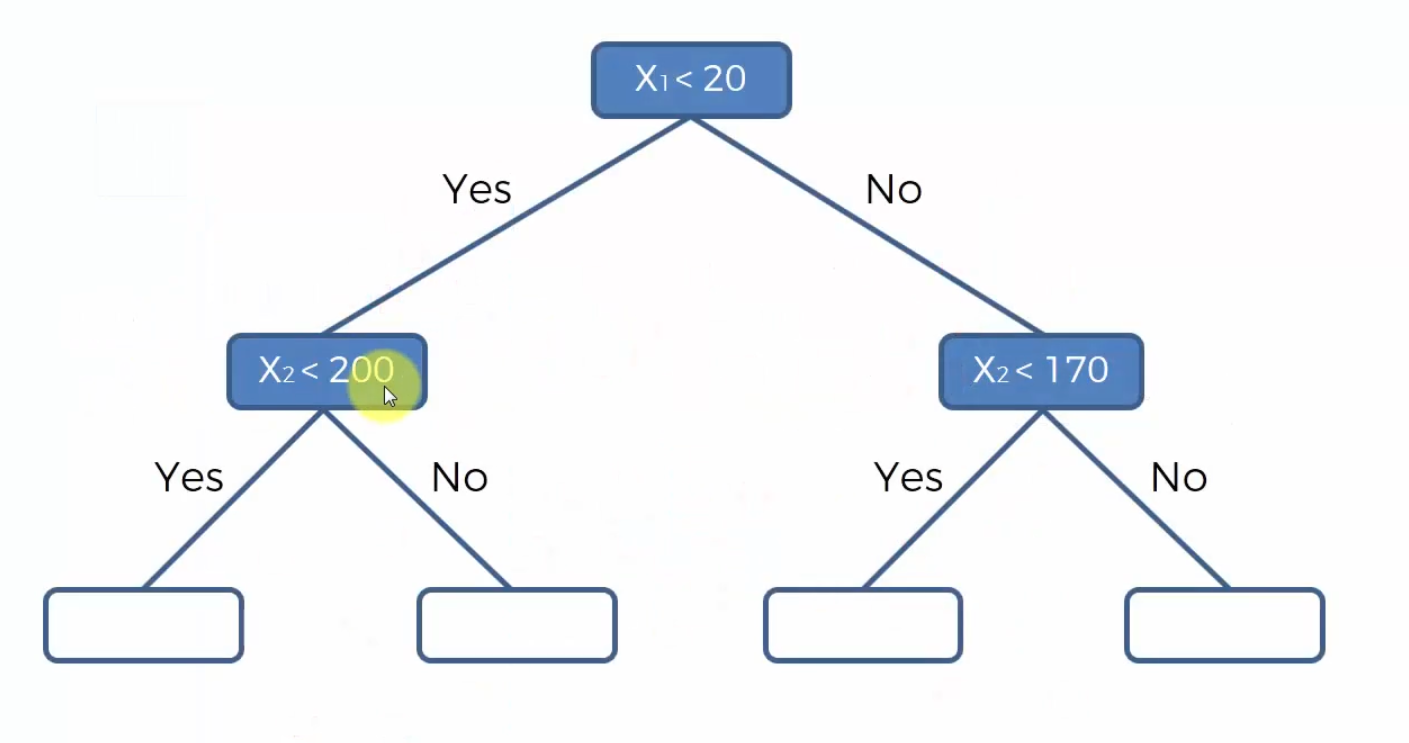
- 最后我们在$x_1=40,x_2<170$ 出画一条分割线,我们可以继续拓展一个分支。
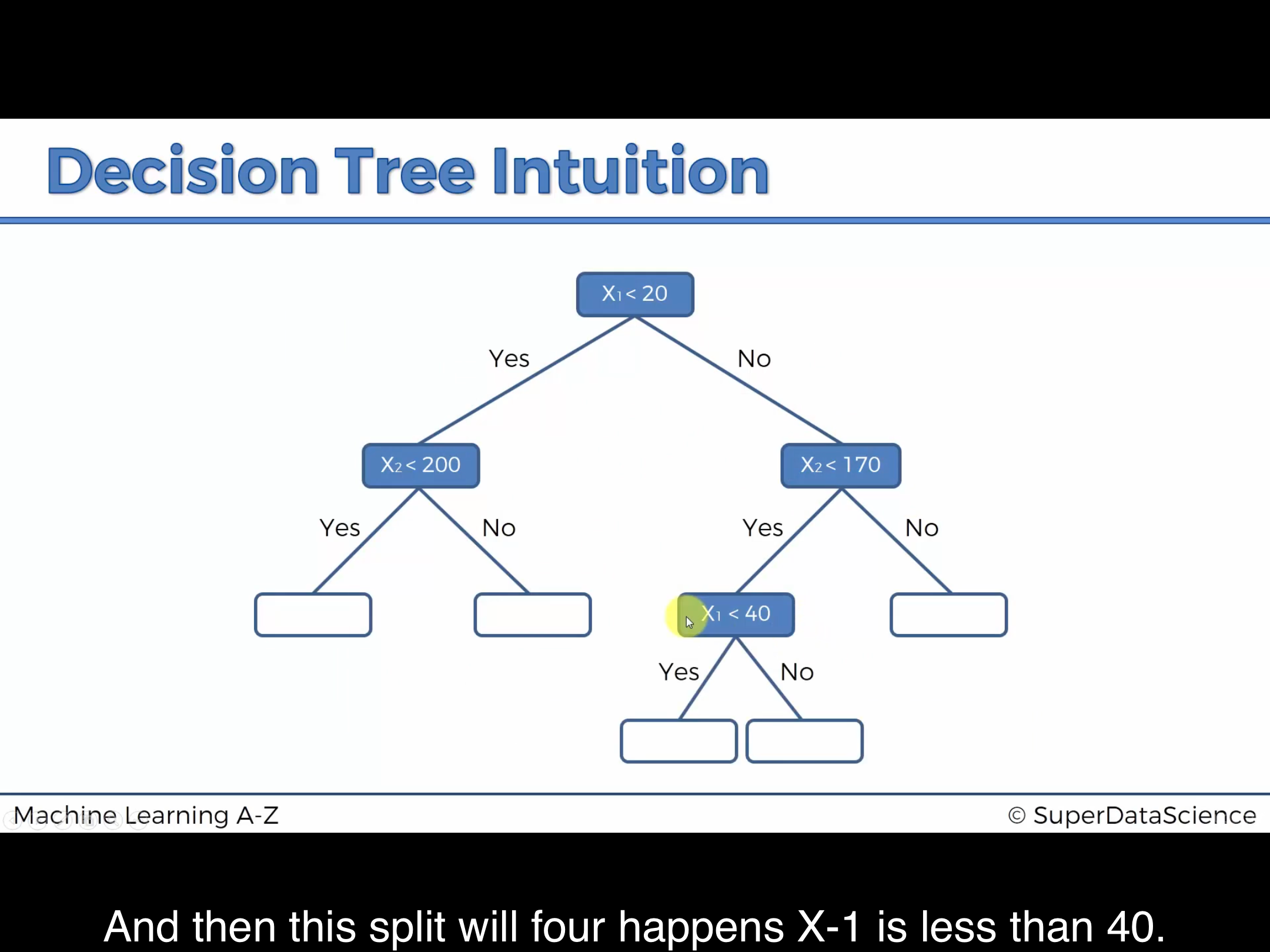
现在,我们分隔好了区域,我们怎么对一个新的数据进行预测呢?
其实很简单,我们把每个区域每一个散点的y值加起来求平均后,再赋值给新的、需要被预测的值。
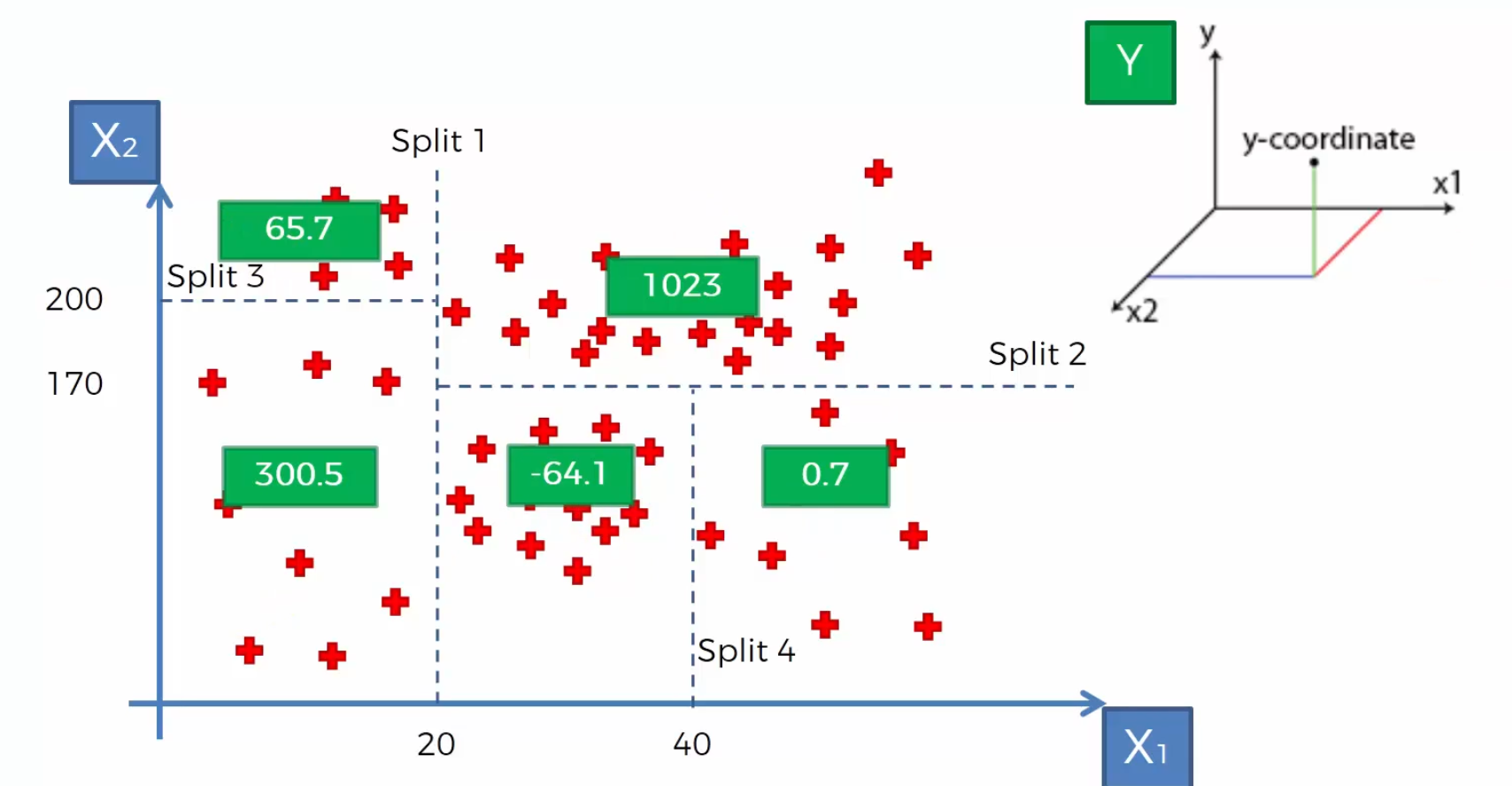
现在我们已经求出了各个区域中y的平均值,现在来一个点(30,50) ,我们可以看到这个点落在中下区域,这个区域的平均值是 -64.1 那么这个我们预测(30,50) 这一个点的y值就是 -64.1
最后我们补全我们的决策树:
代码
首先还是进行数据集导入、分割
1 | import numpy as np |
然后我们训练决策树模型:
对于决策树模型的参数选择和设置,先不要过于纠结。对所有的机器学习模型有了一个认知和比较之后我们再来谈论参数。在这里我们设置 random_state 参数= 0。这个问题是因为,学习一个最优决策树是一个NP问题。 所以实际应用中,生成决策树是基于启发式算法的,比如贪婪算法,贪婪算法可以在每个节点进行局部最优点求解,但它无法保证返回全局最优解。不论是random forest还是decision tree,贪婪算法会随机且多次抽取部分特征和样本,这个随机抽取过程可以通过random_state来决定。让他等于零的意思是让每次建立出来的决策树都是一样的。
1 | from sklearn.tree import DecisionTreeRegressor |

我们可以用训练出来的模型预测新的数据
1 | regressor.predict([[6.5]]) |
打印得到: array([150000.])
如果我们要预测两个数据,我们可以这样写:
1 | regressor.predict([[1],[2]]) |
我们可以这样理解,6.5经过了层层决策最后落到了一个区域,这个区域只有 Level=6这一个数据,那么这个数据的平均值 150000 就赋值给了6.5
最后进行一个可视化操作:
1 | X_grid = np.arange(min(X), max(X), 0.01) |
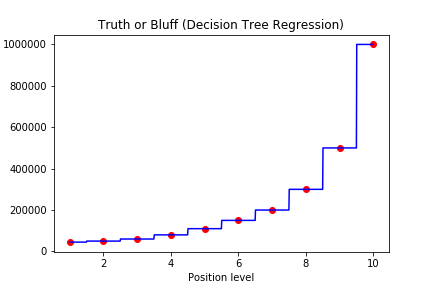
我们看到这个模型被训练成随机森林之后,因为数据量不足够,所以回归曲线呈现阶梯状。也就是说在一定范围内的所有的数都会被预测成相同的值。
随机森林
我们首先来了解一下 Ensemble Learning (集成学习)的概念。 Ensemble Learning 通俗的来说就是用多种算法或者一种算法运行多次来解决一个问题
那么随机森林的步骤可以概括如下:
STEP1: Pick at random K data points from the Training set
SETP2: Build the Decision Tree associated to these K data points
- 和决策树不同,决策树将所有的数据拿来建树而随机森林是从中选取K个数据来建树
STEP3: Choose the number Ntree of trees you want to build and repeat STEPs 1&2
- 然后我们只要选择要建的树,重复步骤1和2就可以了
- STEP4: For a new data point,make each one of your Ntree trees predict the value of Y to for the data point in question,and assign the new data point the average across all of the predicted Y values
- 对于预测的新数据,我们将其放到每一棵树里面去,分别对其预测,最后对这些预测值取平均,就得到了最终的预测值
这也是随机森林之所以叫做森林的原因了,因为我们创建了很多很多树。和决策树相比,随机森林模型会增加预测的准确性,因为我们对所有的预测值取了一个平均数。
此外,随机森林相对于决策树更加稳定,因为他是一个集成算法
代码
代码和决策树的差不多,但是实际效果要比决策树更好一些
前期准备是一模一样的
1 | import numpy as np |
然后 我们从 sklearn.ensemble 中导入 RandomForestRegressor 这个类
n_estimators 就代表我要建几棵树
1 | from sklearn.ensemble import RandomForestRegressor |
最后我们讲建立好的模型贴出,我们可以对比一下随机森林和决策树有哪些不同
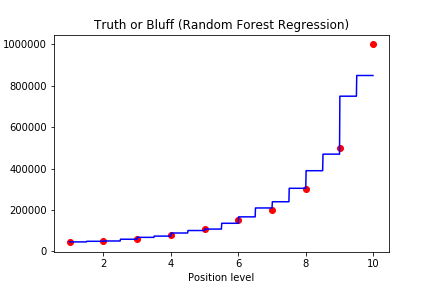
明显可以看到随机森林相对于决策树来说更准确,阶梯更多了
我们现在的重点是了解概念和初步时间,像这样一个简单的预测虽然在现实生活中是几乎不可能遇到的,但是能让我们更好的了解一些模型和对应建立模型的步骤。