选择合适的回归模型
学习自: https://blog.csdn.net/zrh_CSDN/article/details/81190001
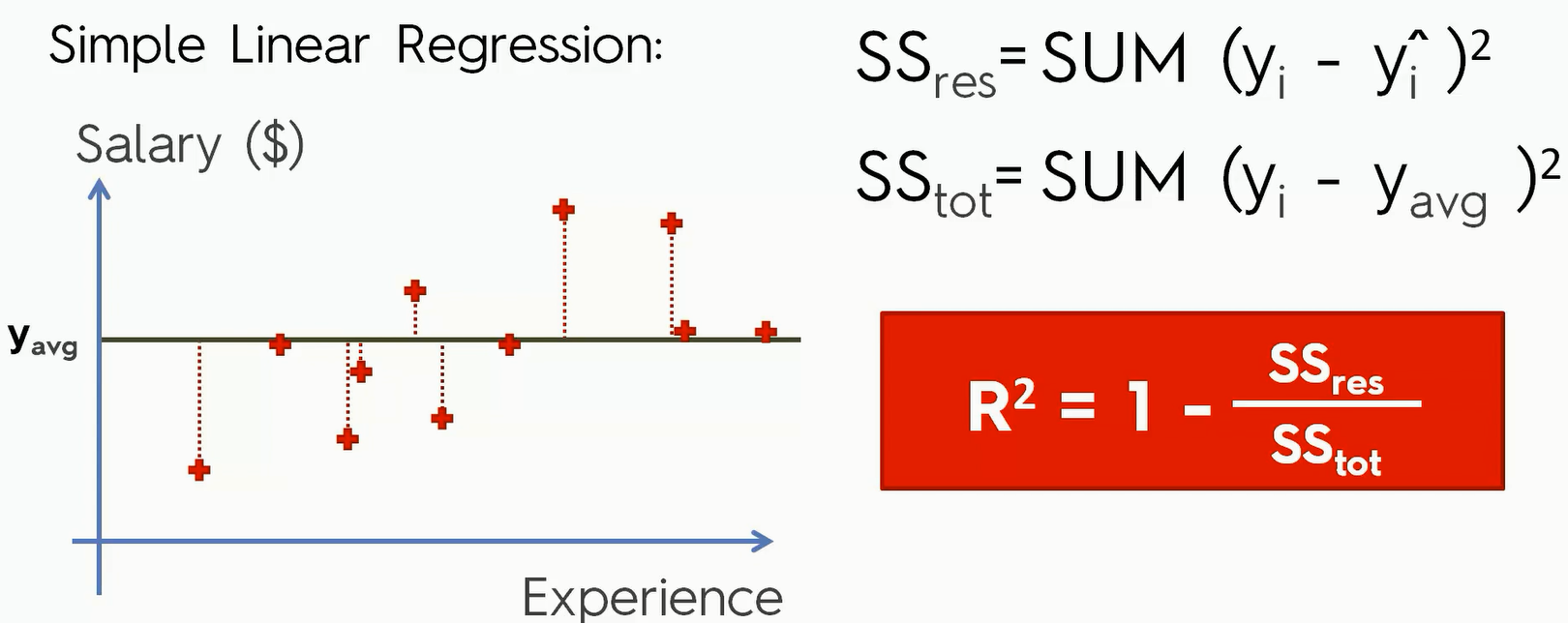
R-Squard Intuition
线性回归问题中,R-Squared 是用来衡量回归方程与真实样本输出之间的相似程度。其表达式如下所示:
$R^2 = 1-\frac{\sum(y-\hat y)^2}{\sum(y-\overline y)^2}$
上式中,分子部分表示真实值与预测值的平方差之和,类似于 均方差 MSE;分母部分表示真是值与均值的平方差之和,类似于方差Var。
根据 R-Squared 的取值,来判断模型的好坏:如果结果是 0,说明模型拟合效果很差;如果结果是 1,说明模型无错误。
一般来说,R-Squared 越大,表示模型拟合效果越好。R-Squared 反映的是大概有多准,因为,随着特征数量的增加,R-Square必然增加,无法真正定量说明准确程度,只能大概定量。
单独看 R-Squared,并不能推断出增加的特征是否有意义。通常来说,增加一个特征,R-Squared 可能变大也可能保持不变,两者不一定呈正相关。
Adjusted R-Squared
对于 $R-Squared$ 来说,如果加入一个新的 Feature,在回归模型下,系统会自动让 $SS{res}$ 趋向于最小。那么如果这个Feature会让整个模型预测准确性下降的话,算法就会让这个Feature的系数趋于0甚至等于0,那么$R-Squared$ 值就不会变化(甚至还可能有轻微的提升);如果这个Feature 会让整个模型的预测准确性上升,那么 $SS{res}$ 会变小,而$R-Squared$ 值就会变大,于是 这个值变成了一个只增不减的,是有一个局限性的。
所以 $R^2$ 并不能很好的让我们判断一个新的变量对整个模型的影响。
如果使用校正决定系数(Adjusted R-Square):
$R^2_adjust = 1-(1-R^2)\frac{(n-1)}{n-p-1}$
其中,n是样本数量(sample size),p是特征数量(number of regressors)。
我们看到如果我们一直增加特征数量的话, $\frac{n-1}{n-p-1}$ 就会增大,$(1-R^2)$ 会减小,所以这相当于是对增加样本做了一个补偿。
如果我们现在添加的特征是对整个模型基本没用的,那么 $\frac{n-1}{n-p-1}$ 对 $R^2-adjust$ 的影响就会高于其本身对$R^2$ 的影响,因此 $R^2-adjust$ 会下降。反之,如果这个变量是对整个模型特别有用的,那么其对$R^2$ 的影响就会大于 对$\frac{n-1}{n-p-1}$ 的影响,那么整个 $R^2-adjust$ 就会上升
$R^2-adjust$ 抵消样本数量对 R-Square 的影响,做到了真正的 $0\sim 1$ 越大越好
选择合适的回归模型
接下来我们通过一个实践,利用刚刚学习的$R^2$或者 $R^2-adjust$ 来选择最准确的模型。
Preparation of the Regression Code
我们使用的是一个大约有10000行数据的csv文件,没有缺失数据。数据来自https://archive.ics.uci.edu/ml/index.php 这里面有很多适合拿来练习data set。 接下来我会提供现在已经学到的五个模型的代码模板.并分别看看这些模板的准确性
multiple linear regression
Importing the libraries
1 | import numpy as np |
Importing the dataset
1 | dataset = pd.read_csv('ENTER_THE_NAME_OF_YOUR_DATASET_HERE.csv') |
Splitting the dataset into the Training set and Test set
1 | from sklearn.model_selection import train_test_split |
Training the Multiple Linear Regression model on the Training set
1 | from sklearn.linear_model import LinearRegression |
Predicting the Test set results
1 | y_pred = regressor.predict(X_test) |
Evaluating the Model Performance
1 | from sklearn.metrics import r2_score |
Polynomial Regression
Importing the libraries
1 | import numpy as np |
Importing the dataset
1 | dataset = pd.read_csv('ENTER_THE_NAME_OF_YOUR_DATASET_HERE.csv') |
Splitting the dataset into the Training set and Test set
1 | from sklearn.model_selection import train_test_split |
Training the Polynomial Regression model on the Training set
1 | from sklearn.preprocessing import PolynomialFeatures |
Predicting the Test set results
1 | y_pred = regressor.predict(poly_reg.transform(X_test)) |
Evaluating the Model Performance
1 | from sklearn.metrics import r2_score |
Support Vector Regression (SVR)
Importing the libraries
1 | import numpy as np |
Importing the dataset
1 | dataset = pd.read_csv('ENTER_THE_NAME_OF_YOUR_DATASET_HERE.csv') |
1 | y = y.reshape(len(y),1) |
Splitting the dataset into the Training set and Test set
1 | from sklearn.model_selection import train_test_split |
Feature Scaling
1 | from sklearn.preprocessing import StandardScaler |
Training the SVR model on the Training set
1 | from sklearn.svm import SVR |
Predicting the Test set results
1 | y_pred = sc_y.inverse_transform(regressor.predict(sc_X.transform(X_test))) |
Evaluating the Model Performance
1 | from sklearn.metrics import r2_score |
Decision Tree Regression
Importing the libraries
1 | import numpy as np |
Importing the dataset
1 | dataset = pd.read_csv('ENTER_THE_NAME_OF_YOUR_DATASET_HERE.csv') |
Splitting the dataset into the Training set and Test set
1 | from sklearn.model_selection import train_test_split |
Training the Decision Tree Regression model on the Training set
1 | from sklearn.tree import DecisionTreeRegressor |
Predicting the Test set results
1 | y_pred = regressor.predict(X_test) |
Evaluating the Model Performance
1 | from sklearn.metrics import r2_score |
Random Forest Regression
Importing the libraries
1 | import numpy as np |
Importing the dataset
1 | dataset = pd.read_csv('ENTER_THE_NAME_OF_YOUR_DATASET_HERE.csv') |
Splitting the dataset into the Training set and Test set
1 | from sklearn.model_selection import train_test_split |
Training the Random Forest Regression model on the whole dataset
1 | from sklearn.ensemble import RandomForestRegressor |
Predicting the Test set results
1 | y_pred = regressor.predict(X_test) |
Evaluating the Model Performance
1 | from sklearn.metrics import r2_score |
结果
我们接下来就对上面的模型进行跑分:
- Multiple Linear Regression : 0.9325315554761303
- Polynomial Regression : 0.945819297903489
- Support Vector Regression(SVR) : 0.9480784049986258
Decision Tree Regression : 0.9226091050550043
Random Forest : 0.9615980699813017
综上我们得到,Random Forest 随机森林模型对这个数据集的预测准确性在五个模型中分数最高,是最适合的回归模型。