CSAPP程序的机器级表示3
数组的分配和访问
基本原则
我们首先来看看数组的声明
T A[N]
其中T是数据类型,N是整形常数。
这个声明有两个效果
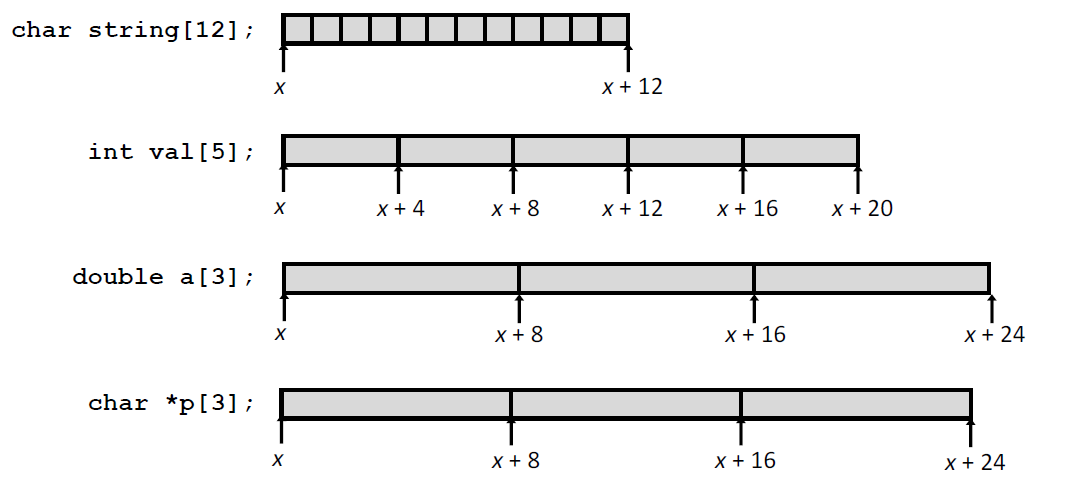
- 在内存中分配了一个 $L\cdot N$ 字节的连续区域,这里L是数据类型T的大小(单位为字节)。
- 引入了标识符A,可以用A来做指向数组开头的指针,记为 $x_A$。然后可以用 $0\sim {N-1}$ 的整数索引来范根该数组元素。数组元素i会被存放在地址为 $x_A+L\cdot i$ 的地方
下面申请了几个数组,我们可以看到数组成员在地址上的位置
假如 E 是一个int型的数组,而我们想计算 $E[i]$ ,在此,E的地址存放在寄存器 $\%rdx$ 中,而 i 存放在寄存器 $\%rcx$ 中。然后再指令
$movl~~(\%rdx,\%rcx,4),\%eax$ 会执行计算 $x_E+4i$ 读取这个内存位置的值,并将结果存放到寄存器 $\%eax$ 中。允许的伸缩因子 1、2、4、8 刚好能覆盖了所有基本简单数据类型的大小。
访问数组
访问数组的形式非常多样
C语言允许对指针进行运算,而计算出来的值会根据该指针引用的数据类型大小进行伸缩。也就是说如果 p 是一个指向 类型为T 的数据的指针,那么表达式 p+i 就等于 $x_p+L\cdot i$
| 表达式 | 类型 | 值 | 汇编代码 |
|---|---|---|---|
| E | int * | $x_E$ | movq %rdx,%rax |
| E[0] | int | $M[x_E]$ //在$x_E$ 地址上的值 | movl (%rdx),%rax |
| E[i] | int | $M[x_E+4i]$ | movl (%rdx,%rcx,4) ,%eax |
| &E[2] | int* | $x_E+8$ | leaq 8(%rdx),%rax |
| E+i-1 | int* | $x_E+4i-4$ | leaq -4(%rdx,%rcx,4) ,%rax |
| *(E+i-3) | int | $M[x_E+4i-12]$ | movl -12(%rdx,%rcx,4),%eax |
| &E[i]-E | long | i | movq %rcx,%rax |
最后一个例子是两个指针之差,结果的数据类型为long
Array Loop Example
1 | void zincr(zip_dig z) { |
这个 函数的汇编代码如下:
1 | # %rdi = z |
.L3 中,需要用 i 和 4相比,如果小于等于4,那么就跳转到 .L4
现在我们举几个数组和指针的例子
Comp: Compiles (Y/N)
Bad: Possible bad pointer reference (Y/N)
Size: Value returned by sizeof
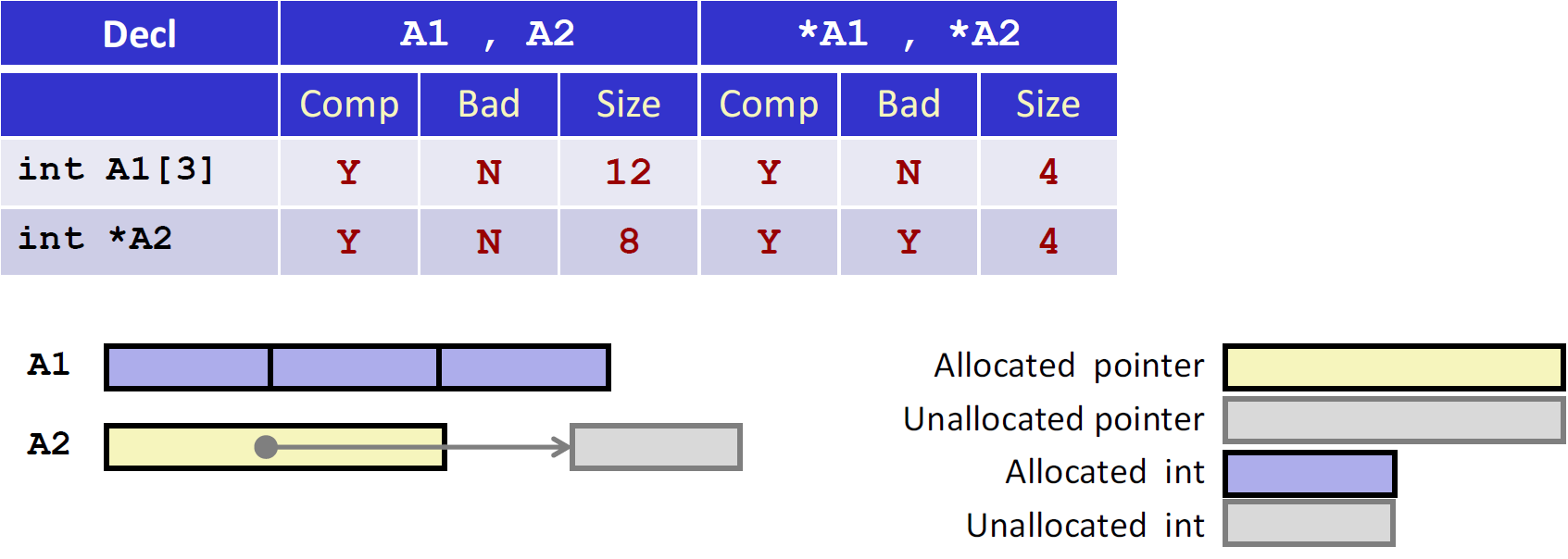
- 首先 $A1[3]$ 和 $*A2$ 都是 可以通过编译的,而且指针都不是非法的。
- 因为A1有3个int,所以数组大小是 12个字节,*A2 是指针,长度为8个字节
- 对于 *A1和 *A2,它们都是能通过编译的,但是对A1来说,在声明之初已经申请了地址了,只是没有初始化,所以*A1 是任意一个值,而 *A2则没有为其分配内存,输出*A2 就会出错,而对于*A1 和 *A2,声明之初是int,所以Size为4个字节
现在来看看更加复杂的问题:
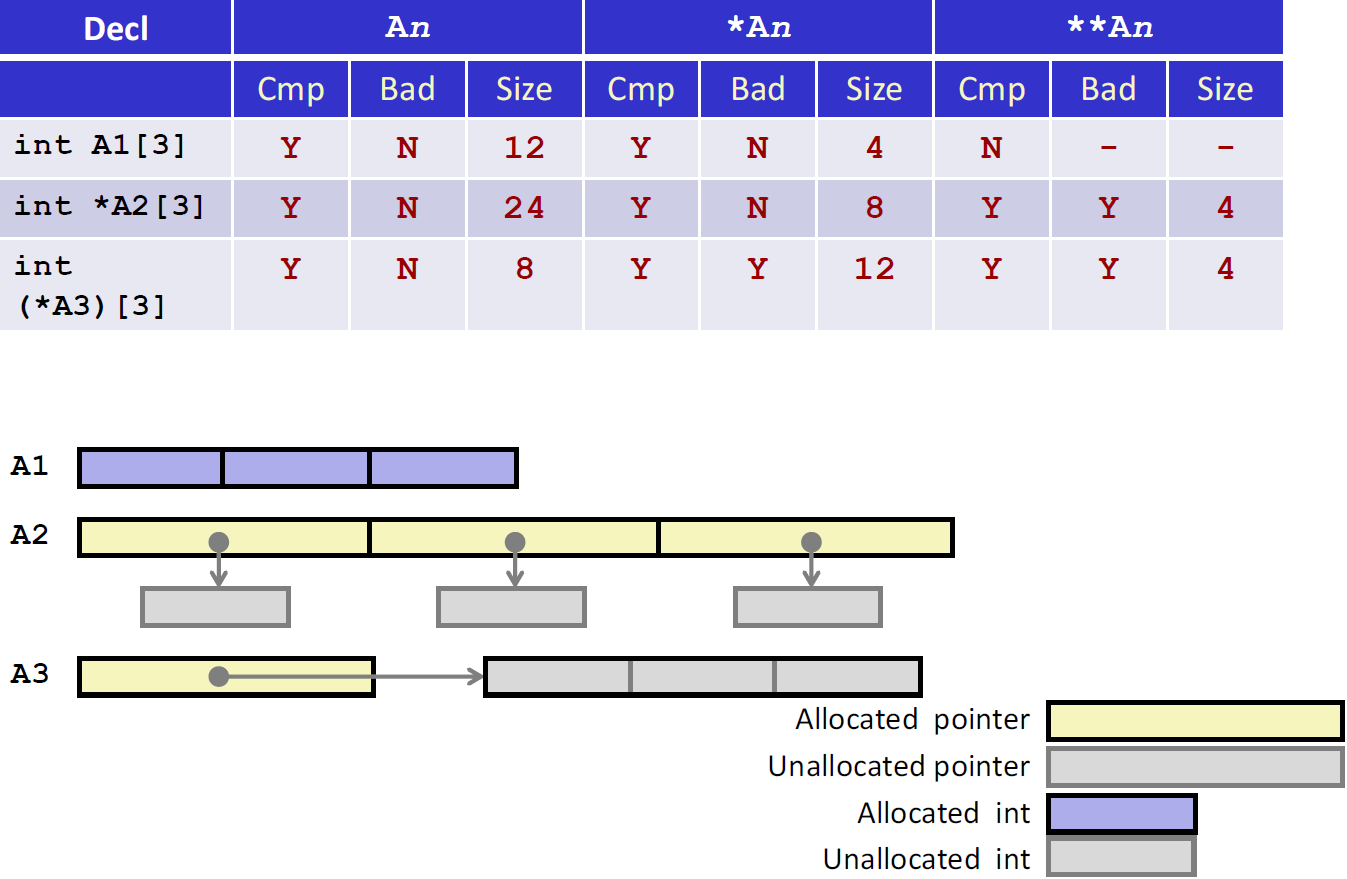
- A1[3]是一维数组, *A2[3]是指针数组 ,也就是用来存放指针的数组,这些指针会指向 int 类型的数据。 (*A3)[3]是一个数组指针,也就是指向长度为3的数组的指针 这三者都能通过编译。
- 对于 (*A3)[3] 来说,*An就是它指向的地方也就是数组,数组有3个int数据,大小为 12 size 。但这个数组的内存尚未分配,所以是 Bad Reference。对于 *A2[3] 来说,*An 就是指针数组中的指针,是分配过内存的,大小为8size
- 对于A1[3]来说 **An 不存在这种定义。对 *A2[3] 来说,\An 是指针指向的区域,但因为这些区域没有分配内存,所以是非法的。对(*A3)[3] 来说,** An 是数组中存放的数据,大小为4byte,但是因为没有分配内存,所以也是Bad Reference
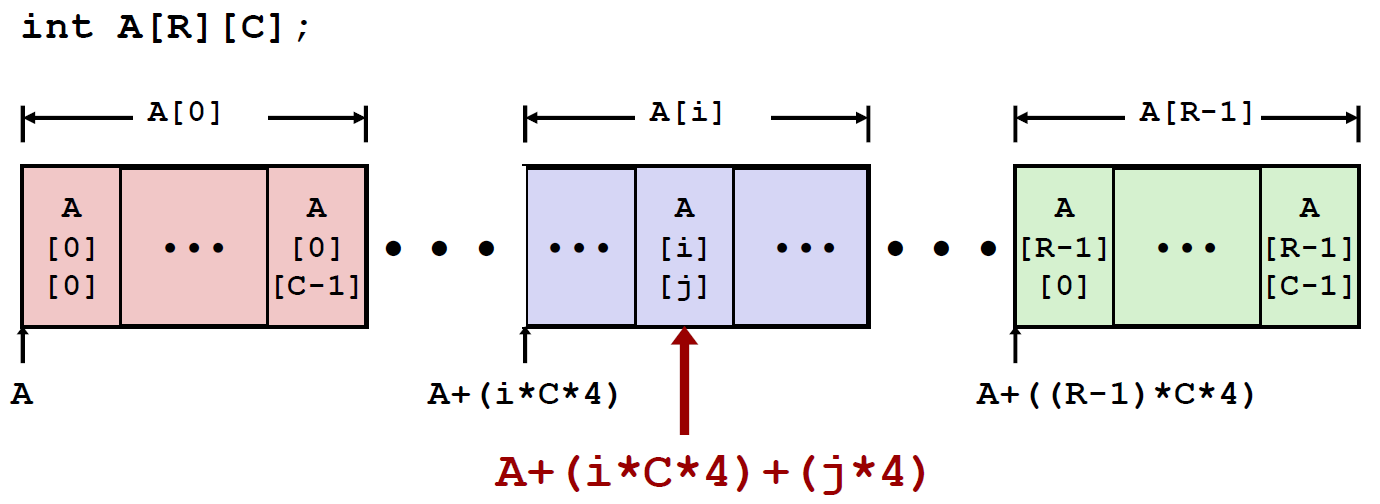
嵌套数组(Nested)
嵌套数组这样声明:
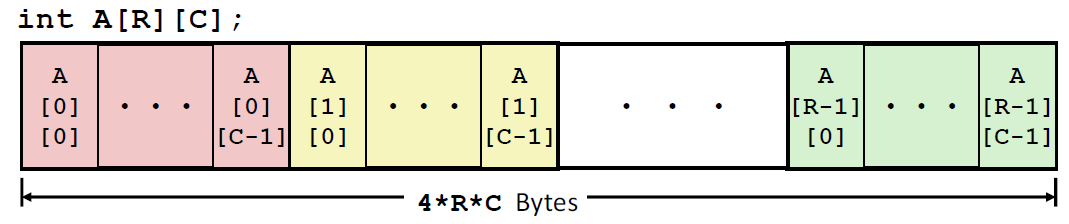
T A[R][C]:
这是一个二维数组:数据类型为T,R行C列

Array的大小就是 $R\cdot C\cdot sizeof(T)$ bytes
嵌套数组是以行为主导顺序分配内存的:Row-Major
这是嵌套数组的另外一种定义方式:
1 |
|

Nested Array Row access
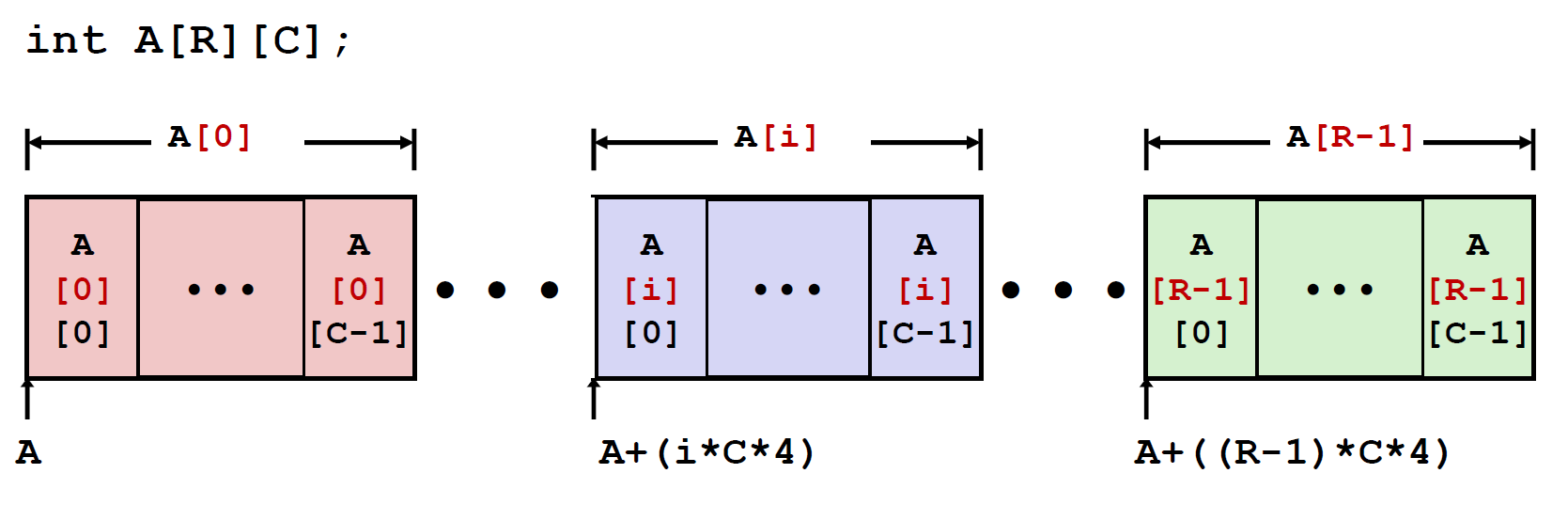
对于 嵌套数组 A[R][C] 那么我们要访问一个数组中的一行,我们该怎么办:
行向量的开始地址是 :$A+i\cdot (C\cdot sizeof(T))$
Nested Array Element access
A[i][j] 是一个类型为T的数据,设T有K个字节,那么其地址可以这样来写 : $A+i\cdot(C\cdot K)+j\cdot K=A+(i\cdot C+j)\cdot K$
具体用 int 举例我们可以这样表示:
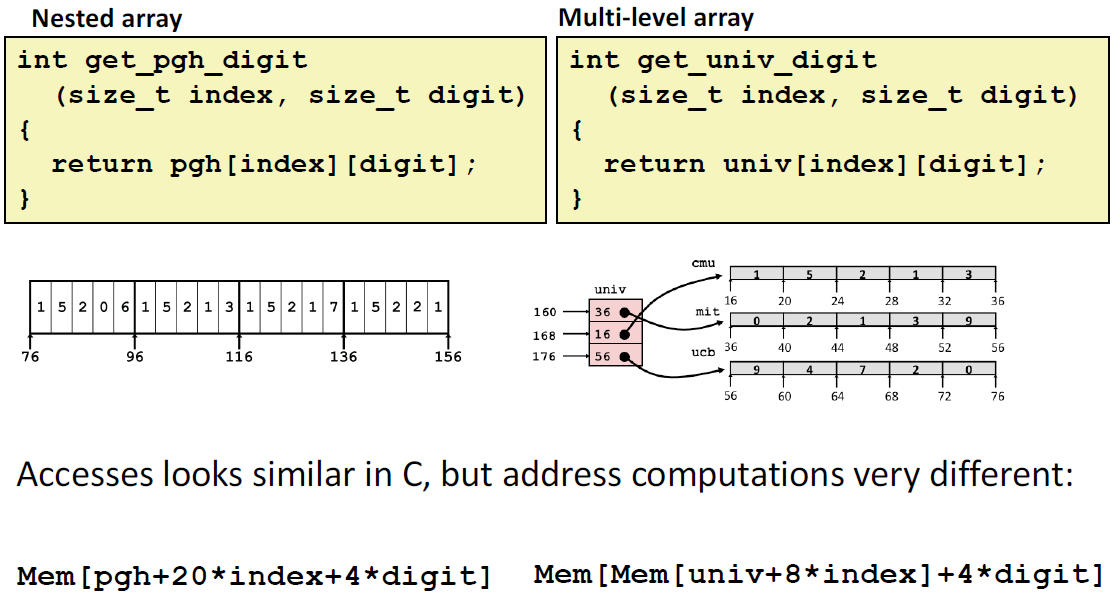
1 | int get_pgh_digit(int index, int dig) |
其汇编代码如下:
1 | leaq (%rdi,%rdi,4), %rax # 5*index |
Address: pgh + 20*index + 4*dig = pgh + 4*(5*index + dig)
Multi-Level Array
1 | zip_dig cmu = { 1, 5, 2, 1, 3 }; |
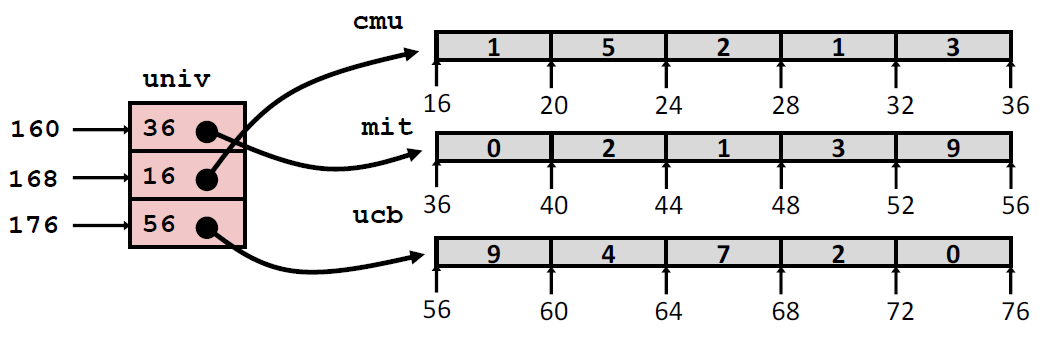
获得一个具体位置的数据
1 | int get_univ_digit(size_t index, size_t digit) |
下面是函数的汇编代码
1 | salq $2, %rsi # 4*digit |
Element access Mem[Mem[univ+8*index]+4*digit]
对二维数组的两种存储方法(Nested array和 Multi-level array) ,我们可以做一个对比:
异质的数据结构
C语言中有 structure(结构),用struct声明,将多个对象集合到一个单位中
union(联合),用关键字union来声明,允许用几种不同类型来引用一个对象。
结构
struct结构类似于数组的实现,它将所有组成部分都存放在内存中一段连续的区域内,而只想结构的指针就是结构第一个字节的地址。
比如下面这个例子:
1 | struct rec { |
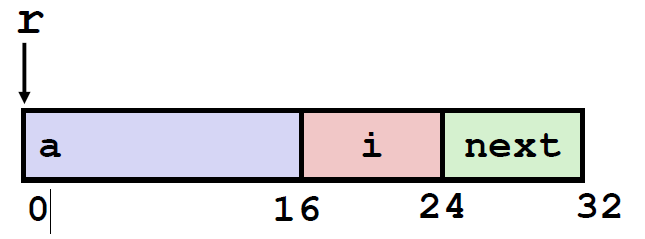
我们看到首先声明的是 一个int类型的数组,占用 4x4 =16 个字节。然后是size_t ,在64位机器下是8个字节。 next是一个指针,至下关下一个struct,所以占用8个byte。 可以观察到 数组 a 是嵌入到这个结构当中的。
现在我想计算出指向a中某个数据的指针,我们应该如何操作?
代码如下:
1 | int *get_ap (struct rec *r, size_t idx) |
在汇编代码中,编译器会这么处理:
1 | # r in %rdi, idx in %rsi |
现在我想计算一条链表中的长度,我们可以写一个这样的代码:
1 | long length(struct rec*r) { |
其汇编代码如下:
1 | .L11: # loop: |
因为一个struct占用的空间为32byte,但是最后8byte指向的是下一个struct 开始的地址,所以我们只要读出 在 r+24处的地址并判断其是否为空即可判断链表是否已经到达尾端
r+24 是 next的地址,next地址上的值 = 下一个struct的开头地址
再来看看下面这个可能会出现问题的代码:
1 | void set_val (struct rec *r, int val) |
先把 i 命令成 struct里面的 i,然后将 val的值赋给 a[i] ,然后再指向下一个struct
其汇编代码如下:
1 | .L11: # loop: |
先取出 r+16 地址上的值赋给 i,然后再将$r+4\cdot i $地址上的值赋值给 $val$
但是这样写会出现意想不到的结果,因为a只有4个位置,如果 struct 中的 $i\geq 4$ 的话,事实上 r->a[i] = val 实际上改动的是 r->i =val甚至报错 因为struct是在内存上连续存储的,C语言也不会检查数组是否会越界。于是 a[4] 其实修改的是 r->i 的值,而如果 i继续增大的话,到了没有分配内存的区域,C语言就会报错。
联合
数据对齐
在struct中,我们要进行数据对齐。
对于一个 struct 例子:
1 | struct S1 { |
在真实的内存当中,它其实是这么存储的:
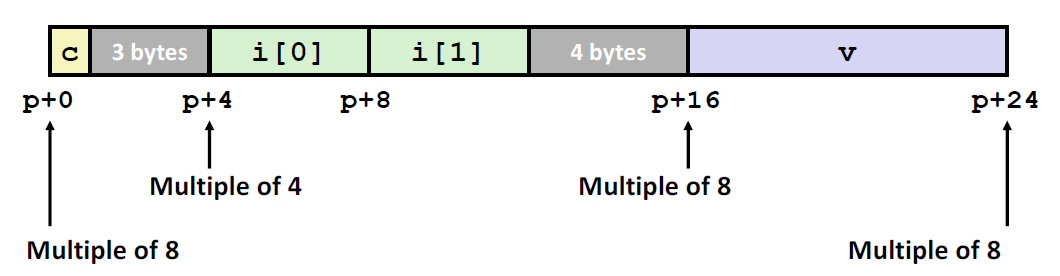
对于一个数据类型,它在内存里的起始位置必须是它大小的倍数:
对于一个 character来说,它在哪里存储都可以,因为其长度只有1byte
对于一个 int 来说,他的起始位置必须是4的倍数
对以一个double来说,它的起始位置必须是8的倍数。
这就造成了中间空出来的空间。虽然一个struct只要17个字节,但是像这样写C语言,存储的时候却需要24的字节
为什么要对齐?
因为数据不一定放在内存里,而放在cache里面,从 cache里面取数据会比内存里取快很多。cache是很小的,一个cache line是64个byte。我们希望当取一个struct的时候,我们希望这个数据项不要跨两个cache,而放在一个 cache line里面。如果一个结构跨cache line存储,那么取了一条cache line,还有一条在外面:这样就导致即没有让速度变快,又浪费了cache line。这种情况叫做 miss,会极大的影响机器的性能。
所以对于struct来说,我们宁可空出一段内存,也要让cache的命中率增加,从而提升整个程序的运算速度。
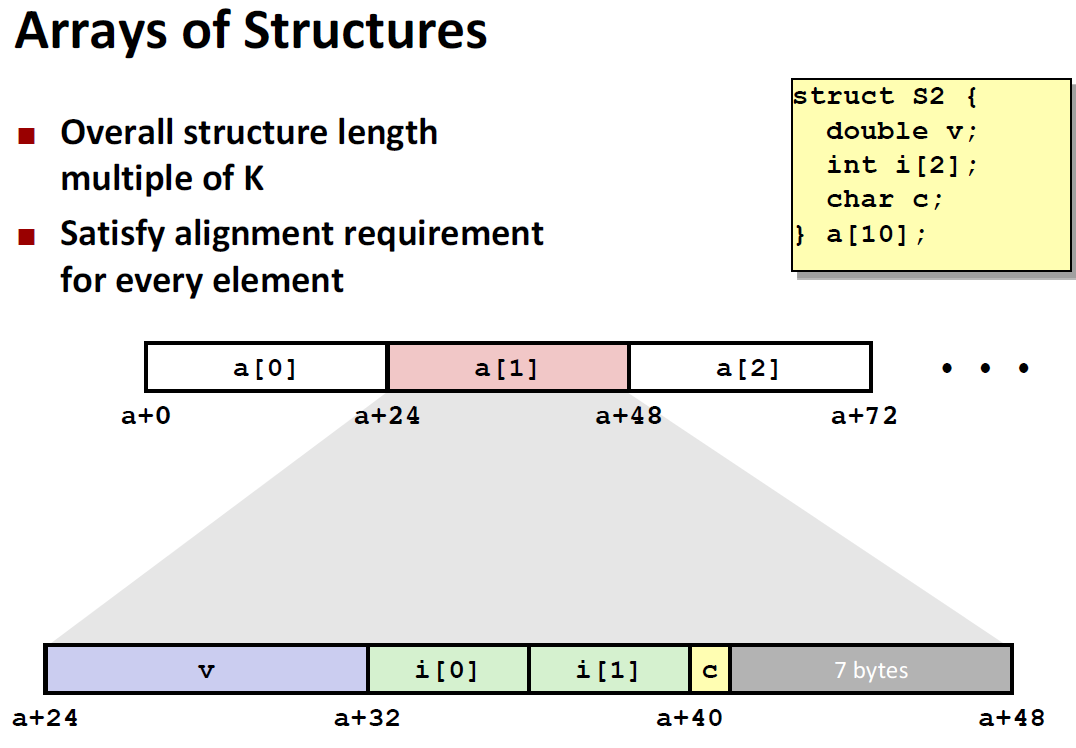
对于一个结构数组,我们发现,即使是把最大的数据放在前面,满打满算用完17个字节,在存储的时候仍然要在最后补上空白的一些空间。这是因为要将整个struct大小补全到8的倍数,这里是24个字节。
1 | short get_j(int idx) |
1 | # %rdi = idx |
在某种情况下,我们可以节省空间:
在机器及程序中将控制和数据结合起来
Memory Layout
在CSAPP的第一篇文章中我就讲过一个程序中不同的变量等在内存中的分布。现在我们在来复习一下。
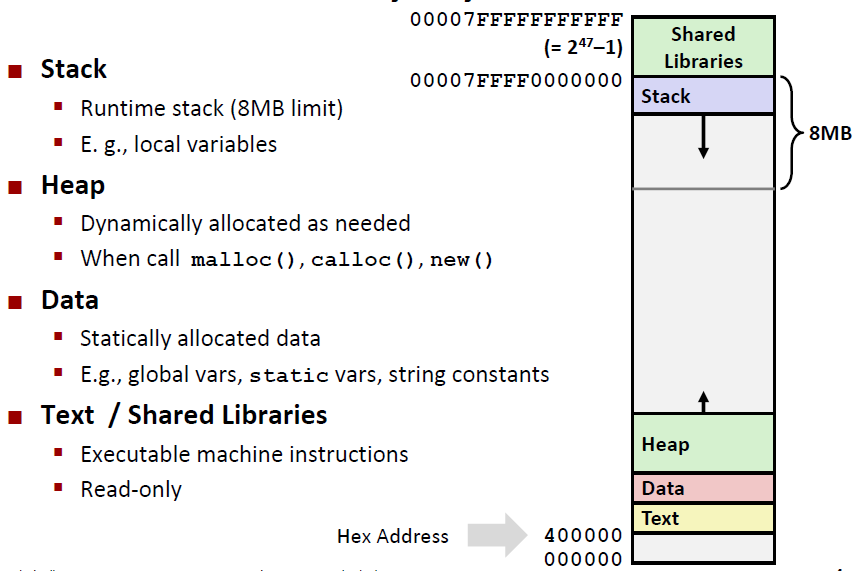
这里所说的Memory是 address space之意,是虚拟内存
首先我们来看 Shared Libraries,这里存放的是一些库函数、头文件之类的。即不是我们自己写的代码
然后我们看看Stack,stack有8M的内存空间,朝着低地址伸展。Stack中主要存放的是局部变量等数据
Heap和Stack不同,它是向上生长的。主要存放的是动态分配出来的内存,比如C++中new出来的、C中malloc() 出来的地址空间
然后是Data区域,Data主要存放的是静态变量和全局变量。这里我们要再声明一下静态变量和全局变量的区别:
1、全局变量在整个工程文件内都有效;
2、静态全局变量 只在定义它的文件内有效;
3、静态局部变量只在定义它的函数内有效,且程序仅分配一次内存,函数返回后,该变量不会消失;局部变量在定义它的函数内有效,但是函数返回后失效。
4、全局变量和静态变量如果没有手工初始化,则由编译器初始化为0。局部变量的值不可知。
5、静态局部变量与全局变量共享全局数据区,但静态局部变量只在定义它的函数中可见。静态局部变量与局部变量在存储位置上不同,使得其存在的时限也不同,导致对这两者操作 的运行结果也不同。
最后一个Text区域是代码区,里面存放着我们写的这个文件的代码。
我们来看一个具体的例子:
1 | char big_array[1L<<24]; /* 16 MB */ |
big_array 和 huge_array,global 是全局变量,应该放到Data当中
useless() 是一个函数,属于我们写的代码,所以放到Text当中
local 是局部变量,放到栈中
phuge1,psmall2,phuge3,psmall4 是malloc盛情的指针。所以它们会放到Heap中去
下面是一个让栈溢出的例子:
1 | int recurse(int x) { |
每次递归,函数都会开一个大小为128KB的数组。
最后的运行结果如下,如果x等于67输入,到最后一次分配内存的时候,数组会撑满8M的栈空间。
1 | ./runaway 67 |
Buffer Overflow
我们现在来看一个向上溢出的例子:
1 | typedef struct { |
首先,这个struct s是放在栈里面的,我们之前说栈里面的元素是按照低地址到高地址排列的,画出来就是从下到上排列的。示意图如下 :
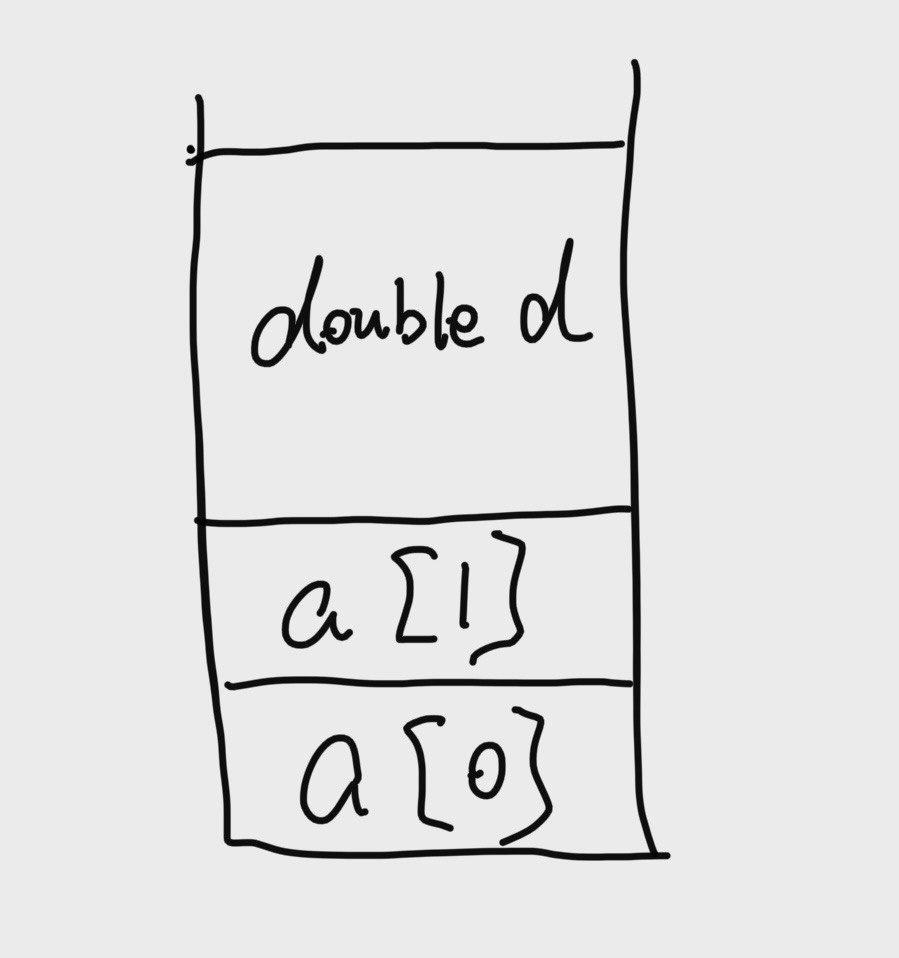
现在我们调用fun(8),会出现segmentation fault,因为a[8] 已经向上冲出这个结构趋于了,因此我们将这个现象叫做 stack overflow
如果调用 fun(0) 或者 fun(1),返回值是3.14,很正常。
但是如果调用 fun(2) 返回值变成了:3.1399998665 为什么是这个答案?
这就要考虑到double 这个浮点数在栈里面是怎么放的:如下图
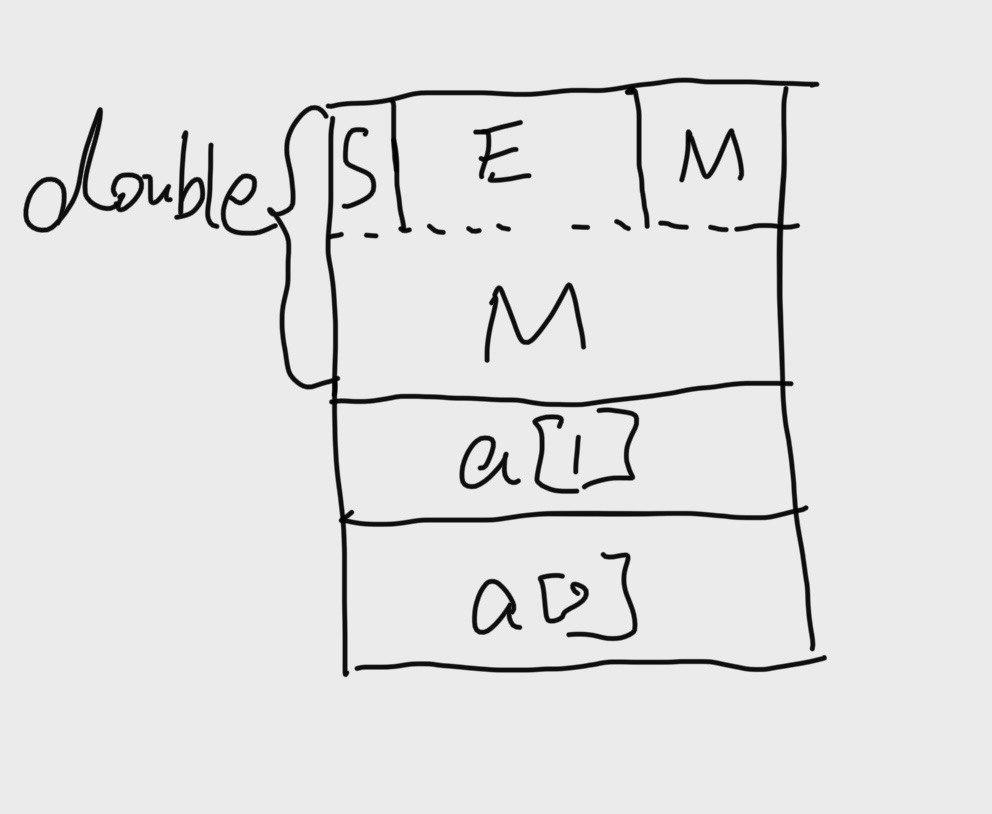
当我们调用fun(2),其结果就是将double d中的部分M修改成了 1073741824。也就是说我们对这个浮点数的小数部分进行了修改,但是并没有修改其符号和阶码。因此我们看到结果是仅仅影响了一些精度,并没有影响很大。
当我们调用 fun(3),那么就是对上面的S、E、M都进行了修改,但是如果运气足够好,事实上和原来的值相差也不是很大。这李调用fun(3) 返回的值是 2.0000006104
fun(4)到fun(7)我们看到栈里面放的是Critical State,这时候还不会立马报segmentation fault,而是会提醒我们 Stack smashing detected
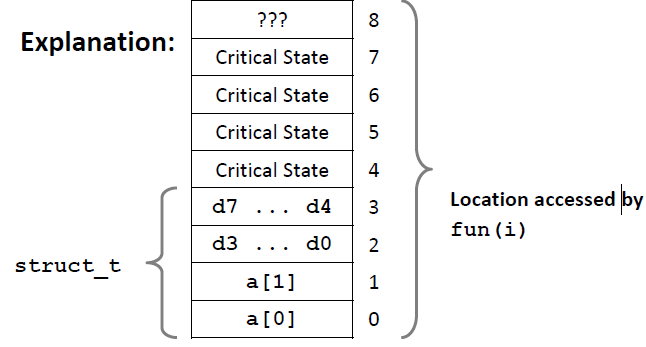
还有一种情况,是这样的:

我们调用fun(8),结果反而又对了,这就好比一开始我们撞墙了(segmentation fault) ,那么我们干脆直接写到墙的另外一端去,反而对结构内的数据不影响了。
如果出现这样的问题,通常我们将其称为 buffer overflow。我们通过调试是很难发现的。这种错误是非常微小但在某些情况下是非常致命的。
接下来我们通过几个例子来看看如何攻击一个不安全的代码和如何来保护我们的代码不受他人攻击
Vulnerability 弱点
我们先举几个例子:
C语言标准库里有一个gets函数,这个函数的写法如下:
1 | /* Get string from stdin */ |
这个函数是说,如果没有结束或者回车的话,gets会一直读入字符。看起来没有问题,但是这个函数没有检查这个指针 *dest 指向的地址以及地址之后的一段地址是合法的还是非法的。
正确的应该是我们应该malloc一段地址来存放string,如果输入的string大于malloc的大小,函数就会报越界。
同样的:
strcpy, strcat: Copy strings of arbitrary length
scanf, fscanf, sscanf, when given %s conversion specification
这些函数都存在着一些问题。
在实际的例子中,比如这个函数,按照设想来说我们只开了一个 4个byte的字符数组。
1 | /* Echo Line */ |
但是,我们这样输入,却不会报错:
1 | unix>./bufdemo-nsp |
而再多输入一个字符,函数就会报segmentation fault
1 | unix>./bufdemo-nsp |
前面不报错的原因是地址上可能有一部分原来就是合法的,那你读取的话也无伤大雅,关键是我们不知道程序什么时候会报segmentation fault
现在我们来看看这个程序运行的机制:
首先我们将其反编译:
echo
1 | 000000000040069c <echo>: |
call_echo
1 | 4006b5: 48 83 ec 08 sub $0x8,%rsp |
再调用gets之前,这个echo函数栈帧如下:最上面的是caller也就是call_echo的栈帧。接下来是一段return address也就是返回的地址。然后是20个未被使用但是合法的bytes(这也是为什么我们之前输入了23个数字仍然没有报错的原因了) ,最后是我们申请的 buf 数组。
像之前我们输入了23个数字,加上\0刚好将unused 部分和buf数组全部填满。这时候是不会报错的。但是如果我输入24个数字,那么有一个数字就会冲出合法的数组,将返回地址改写。但是返回地址的内容是会收到保护的,于是整个程序就会崩溃,报return地址出错。
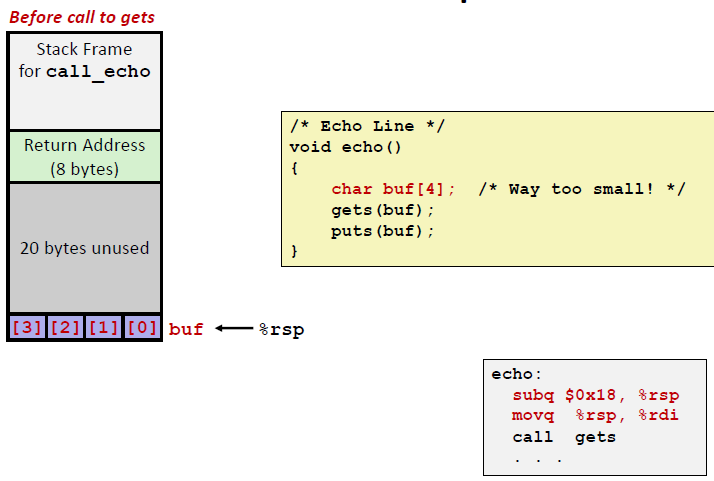
从上面的汇编语言可以得出,call_echo在0x4006be处调用了echo,所以echo的返回地址是 0x4006c3
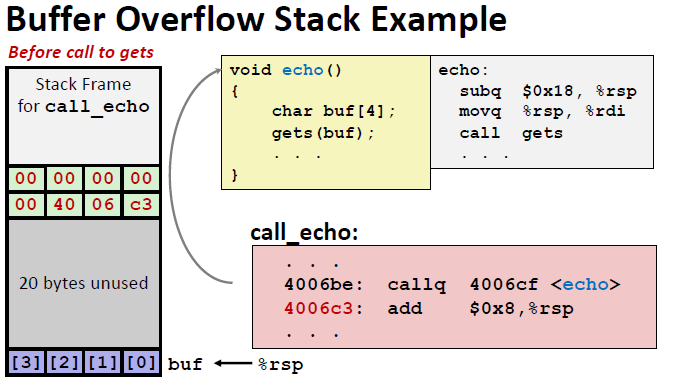
这是我输入23个数字后,栈帧的结构,我们发现除了buf数组被填满了,20个未被使用的buf也被填满了。
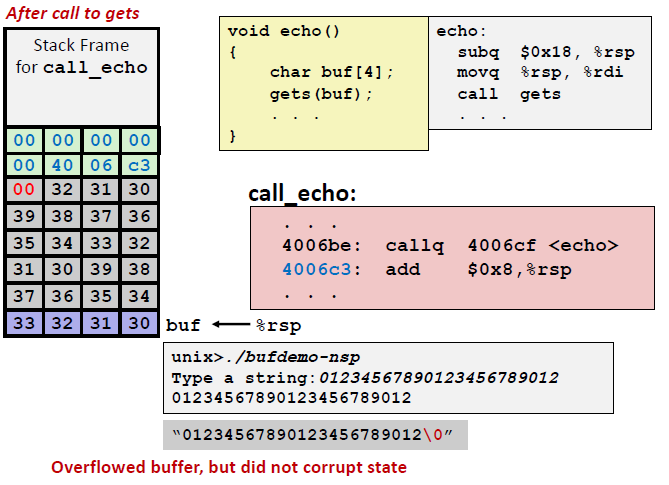
如果我输入了24个数进去,我们就会发现返回地址中的低位被修改了。结果就是返回到了一个非法的地址上去,程序崩溃。
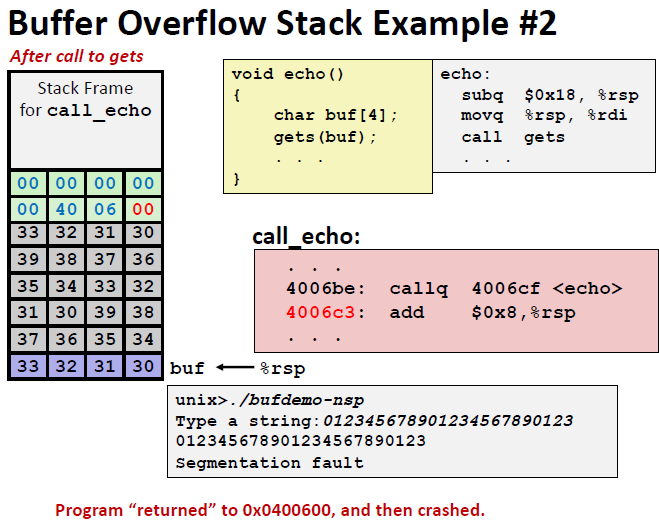
由此我们可以得出,如果有些别有用心的人通过查看你的代码,计算你的栈帧并将你的返回地址修改成某段他希望跳转到的地址,这样你的程序就会变得非常不安全。之后的attacklab就要求我们去攻击那些不是非常安全的代码。而在我们写程序的时候,我们要做的就是对我们的程序进行一个保护。
Protection
Avoid overflow vulnerabilities
1 | /* Echo Line */ |
For example, use library routines that limit string lengths
- fgets instead of gets
- strncpy instead of strcpy
- Don’t use scanf with %s conversion specification
- Use fgets to read the string
- Or use %ns where n is a suitable integer
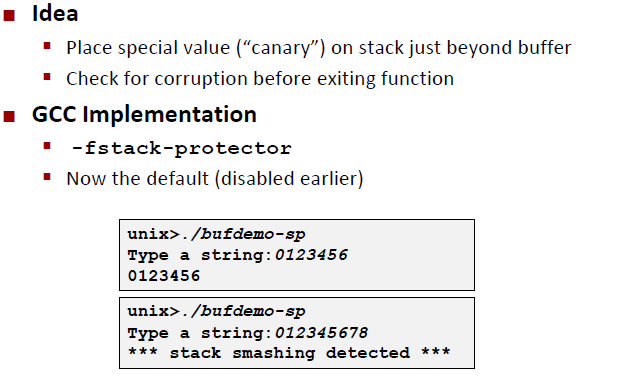
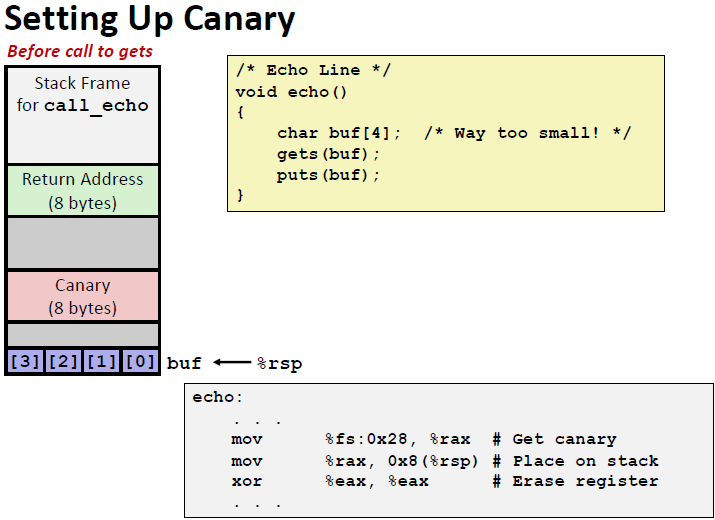
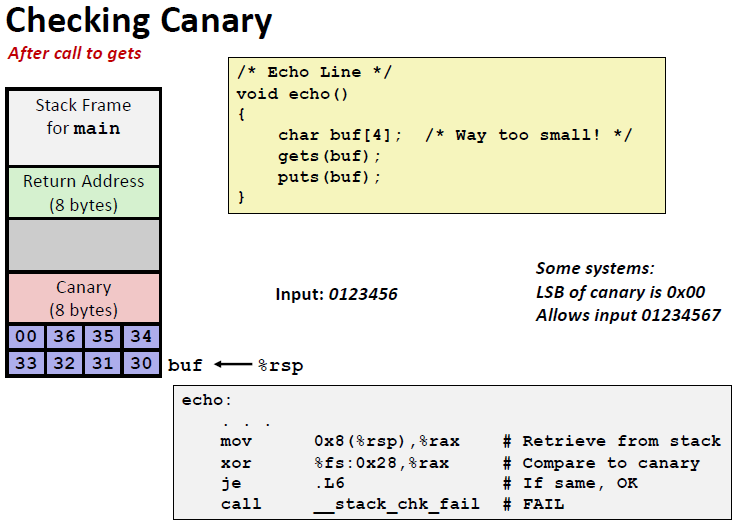
Employ system-level protections

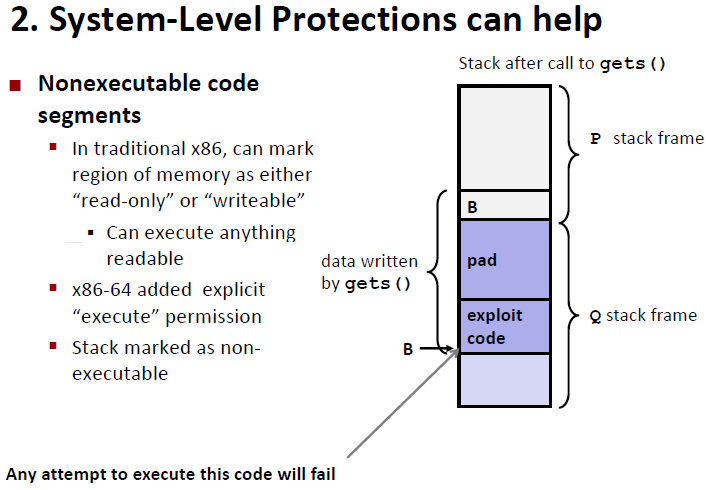
Have compiler use “stack canaries”