Apriori算法
参考博客:https://www.jianshu.com/p/ab23a7444d2a
原理
Apriori 是先验算法之意。简单来说就是找出不同事件之间的联系。比如一个人在超市买了产品A,他可能会买货物B。最有名的例子就是沃尔玛百货将他们的纸尿裤和啤酒并排摆在一起销售,结果纸尿裤和啤酒的销量双双增长。
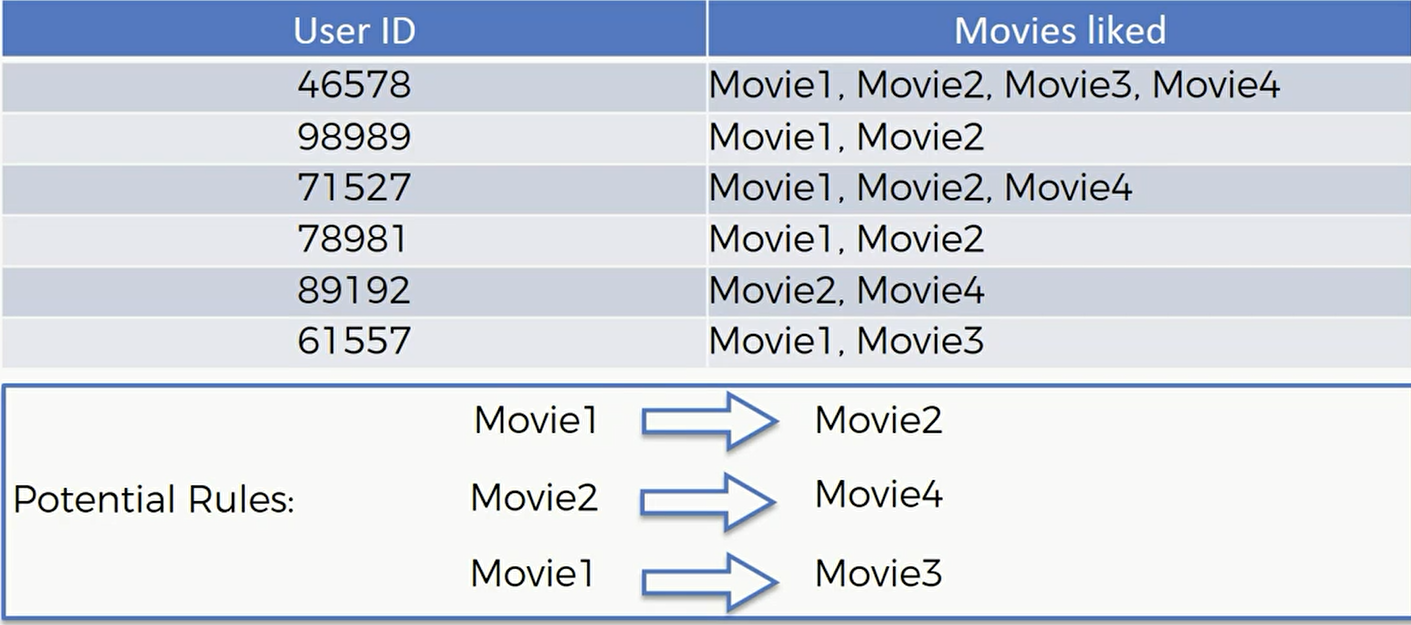
从这个用户喜欢的电影表分析,我们或许可以得到以上三个潜在的关系。看过Movie1的基本都会看Movie2,和Movie3之类的。这些潜在的关系可能是联系性很强的也可能是联系性很弱的。我们想要找到的就是那些关联性很强的对象来作为商业决策的依据
下面是另外一个例子:
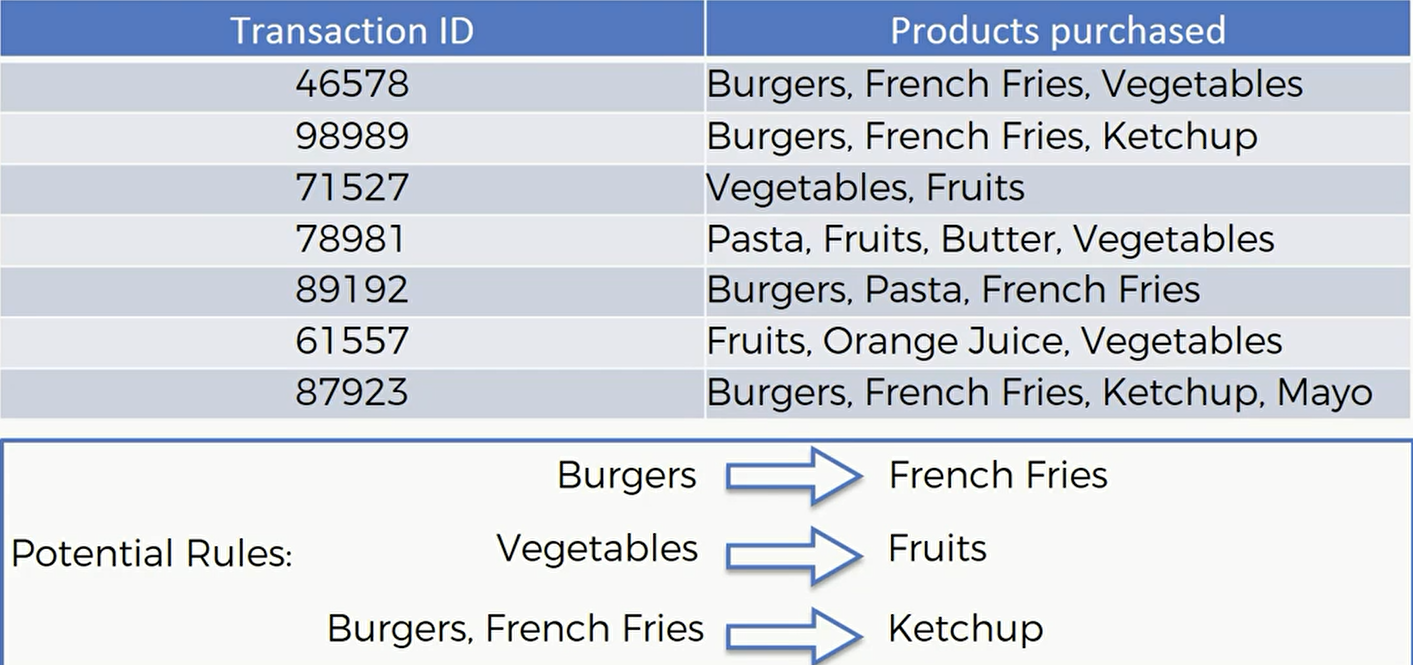
先验算法当中有三个核心概念,support(支持度),confidence(信心水准) ,lift(提升度)。
先来看看支持度,比如交易的例子,对于一个商品I来说,那么就是所有包含商品I的交易数目除以总的交易数目:

然后我们来看看confidence(信心水准) :
M1代表电影1,M2代表电影2,那么信心水准就是同时看过电影1和2的人除以看过电影1但没看过电影2的人
这里I1表示商品1,I2表示商品2,那么信心水准就是同时包含商品1和2的交易除以包含商品1的交易记录个数。

第三个概念,提升度,这个和支持度和信心水准有关,就是configdence除以support。当这个提升度大于1时,我们可以认为商品 $I_1$对$I_2$是有提升的。

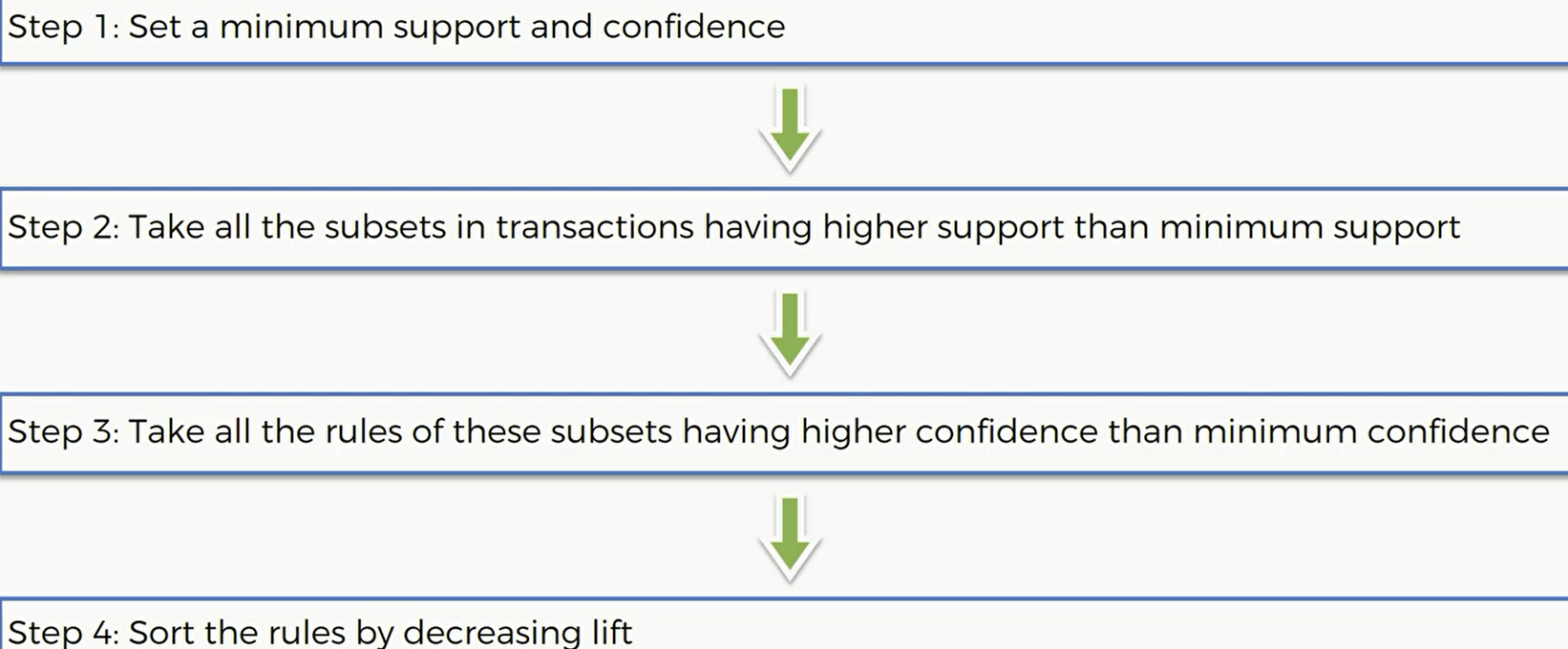
那么现在做个总结,这个先验算法主要可以分为四步:
- 设置一个最低的support和confidence
- 选择所有support比刚刚设置的要大的商品
- 根据刚刚已经选择的商品,选择所有比刚刚定义的最小confidence要高的所有规则的集合
把刚刚的规则从大到小排序,选出提升度最高的几个。
这就是基本的先验算法的步骤,他只提供了最基本、最直接的解决找出事务之间相互联系的方法。但是像谷歌、脸书这样的大公司,他们有自己的推荐算法,会比Apriori要先进、复杂很多。
代码
这是我们使用的数据集,每一行记录了一周以来的每一个顾客购买的所有商品,一共有7501 行
Importing the libraries
首先我们导入库并安装一下apyori包,这个包是独立于scikit-learn 的,所以我们要另外安装
!pip install apyori
1 | import numpy as np |
Data Preprocessing
然后我们导入数据集 Market_Basket_Optimisation 并对数据进行初步的处理
因为这张数据表没有表头,所以我们在导入的时候先要提醒pandas : header = None 以免它把第一行变成列名。
随后我们需要把数据集整合成一个二维数组,一共有 7501行,我们就做7501次循环
1 | dataset = pd.read_csv('Market_Basket_Optimisation.csv', header = None) |
在每次循环当中,我们用append方法将一行中每一个单元格中的字符串一一串联。因为最长的一行有20个物品,所以我们要用 range(0,20) 以确保每一件商品都囊括在内。
最后每一个transaction的结果如下:

没有到20个商品的行表示如下:

Training the Apriori model on the dataset
随后我们要用Apriori模型训练我们的数据集:
1 | # WARNING: Make sure to upload the apyori.py file into this Colab notebook before running this cell |
在导入apyori中的apriori类之后,我们需要对这个算法制定一些规则:第一个参数存放我们的二维数组
min_support 即最小的支持度,通常我们这个值会设的比较低,我们就假设一件商品每天至少出现3次,那么计算(3*7)/7501=0.0028 后得到min_support 的值为0.003
min_confidence 即最小的信心水准.设置得太高会导致没有association rule,设置得太低导致association rule过多不易选择。我们可以多尝试几次,这里我们取0.2
min_lift 即最小的提升度,我们也可以多次尝试找到合适的最小提升度。这里我们推荐 min_lift = 3
min_length ,max_length 都等于2 的意思是只求一件物品和另一件物品之间的联系,而不是一件对多件/多件对多件之间的联系。这样我们可以针对某件特殊的商品给出一点优惠政策之类的销售方案。
Visualizing the results
Displaying the first results coming directly from the output of the apriori function
要显示训练之后的结恶果,我们只要将rules放到一个list中即可
1 | results = list(rules) |

Putting the results well organized into a Pandas DataFrame
但是上面的结果毕竟可读性很差,我们需要将其改成一个DataFrame,会更直观。
我们发现一个 RelationRecord 的结构如下,分为三个部分:items,support和ordered_statistics.其中ordered_statistics是一个列表。列表中又是一个元组,元组的第一、二个元素是frozenset也就是冻结的集合(冻结后集合不能再添加或删除任何元素):
1 | RelationRecord(items=frozenset({'chicken', 'light cream'}), |
所以 result[2]先定位到了 ordered_statistics
因为ordered_statistics中只有一个列表,所以定位到 result[2][0] .
result[2][0][0]和result[2][0][1] 则定位到了 items_base和items_add,因为这两个都是冻结集合,我们将其转换为tuple之后从中取出第一个元素(总共才一个元素)作为我们的Left Hand Side 和 Right Hand Side (我们假设这两件商品将会分别放到顾客的左手边和右手边)
1 | def inspect(results): |
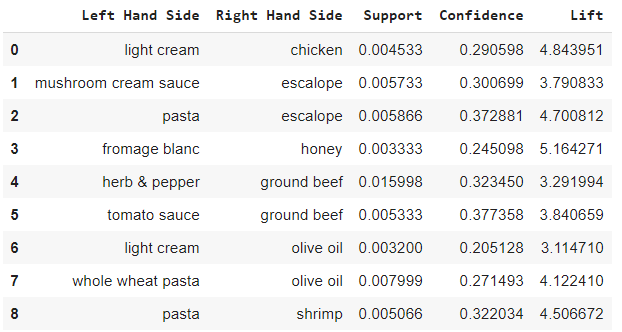
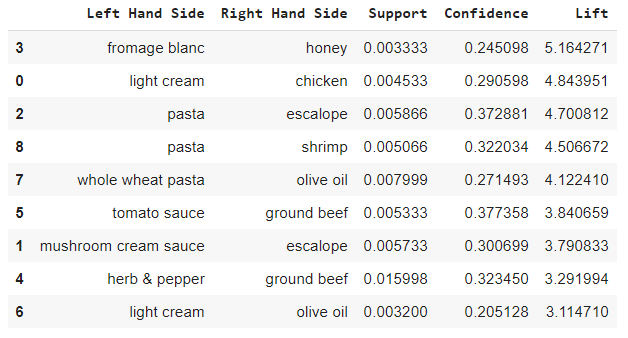
我们看到一共有9件商品组合,于是我们可以将这九种组合打包销售或者放在货架的两边以提高两件商品的销售量。
Displaying the results sorted by descending lifts
然后我们可以降序来选择相关度最高的十种商品组合(总共只有9种)。
1 | resultsinDataFrame.nlargest(n = 10, columns = 'Lift') |