Thompson Sampling 抽样算法
文章搬运、修改自博客: https://www.jianshu.com/p/b4b9f72a505f
本文继续讲一个强化学习的算法,叫做Thompson抽样算法。这个算法的数学理论基础要用到的是贝叶斯推断(Bayesian Inference)。我们先谈谈这个算法的基本原理。
基本原理
我们依然使用之前的多臂老虎机的问题。如图所示,横轴代表奖励,越往右边表示奖励越多。三条竖线代表三个不同的老虎机它们的平均奖励。

算法步骤:

我们依然使用之前的多臂老虎机的问题来介绍这个算法。如图所示,横轴代表奖励,越往右边表示奖励越多。三条竖线代表三个不同的老虎机它们的平均奖励。
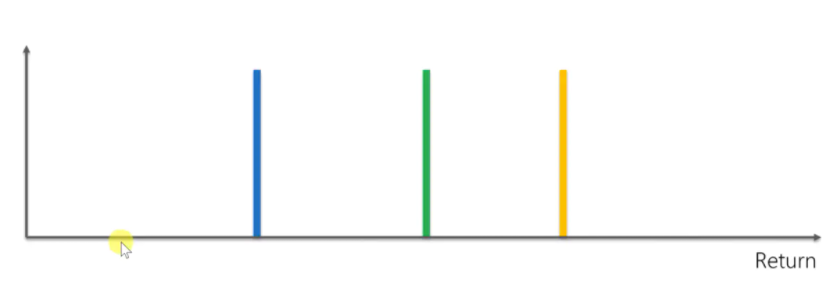
在算法开始前,我们是什么都不知道的,因此需要得到一些基础数据。图中有四个蓝色的数据,表示按下蓝色老虎机得到的奖励,根据这几个得到的奖励,可以得到一个数学分布。同样绿色的老虎机也能得到一个分布,黄色同理。

这三个分布预测的是这三个机器给我们带来奖励实际上可能的数学期望的概率分布。接下来基于这三个随机分布,我们得到几个随机抽样,选择获得最大抽样值的机器按下去。但由于是随机的,虽然黄色的实际期望是最高的,但我们依然可能会选出一个绿色大于黄色数据结果。
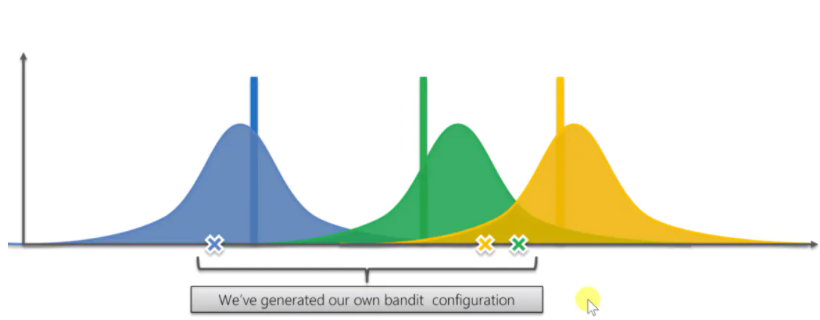
按下去后我们会得到一个新的观察到的奖励值,得到新的奖励值后就要调整绿色机器的分布。
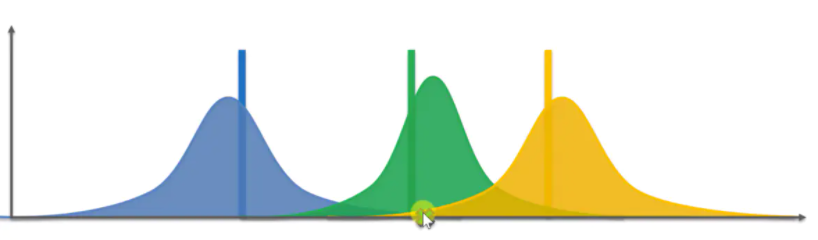
显然这个绿色的分布变得更高更窄了,后面的步骤和这里其实是一样的,也是依然选择奖励值最高的机器按下去,通过得到的结果继续调整分布。
当这个游戏进行到很多步骤之后,这些分布都会变得非常窄,尤其是黄色的基本会和实际期望吻合
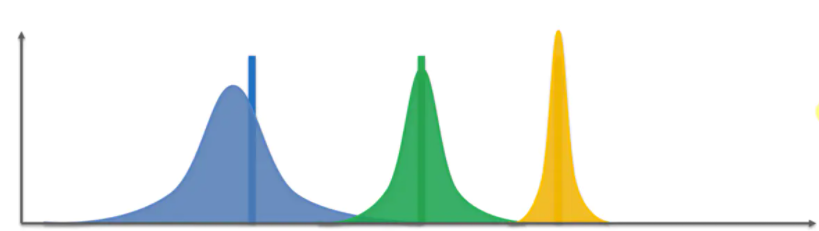
这时由于我们一直选择奖励值最高的机器,因此按下黄色的概率会比较高,导致黄色的会越来越窄,而蓝色的很少玩到,因此相对要宽一点。
Thompson抽样算法 vs. 置信区间上界算法
我们使用Thompson抽样算法和ucb算法都处理了多臂老虎机问题,那么现在来比较下两个算法。来看看这两个算法的基本原理图。

首先这个UCB算法,它是一个确定性算法,当我们得到相同的奖励时,我们作出的决策时确定,因此我们每一轮的总收益和总收益都是确定的。每一轮中作出的决策只和置信区间的上界有关,而这个上界只和这个机器所有的观察值有关。所以说当所有机器的观察值相同时,我们永远会做相同的决策。对于Thompson算法,它是个随机性算法,它的某一步或者某几步是在一个随机函数控制下,跟运气是有关系的。它依赖于一些随机事件,就像我们上面选择点的时候,虽然黄色的实际期望大于绿色,但我们还是可能会选出绿色大于黄色的数据点。因此说它是个随机性的算法。
那么对于UCB,它还有个特点,就是需要实时更新上界,这个在之前的文章描述UCB算法原理的时候可以看出来。对于Thompson抽样算法,它是允许延迟更新甚至批量更新的,比如我们往网上投放一批广告,这里是允许它得到的结果是有延迟的。最后一点,在近些年的实际应用和研究中发现,Thompson抽样算法相对于置信区间算法,它是有更好的实际应用效果的。
代码
Importing the libraries
1 | import numpy as np |
Importing the dataset
1 | dataset = pd.read_csv('Ads_CTR_Optimisation.csv') |
Implementing Thompson Sampling
1 | import random |
Visualising the results - Histogram
1 | plt.hist(ads_selected) |
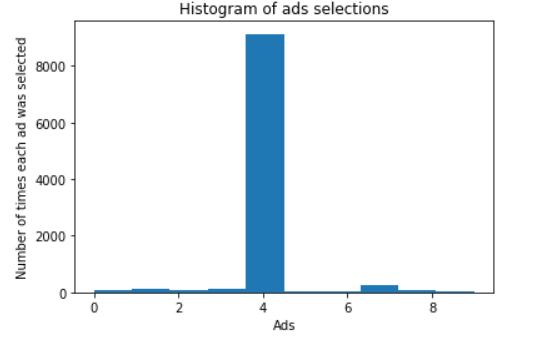
最终得到总奖励数相对于之前的置信区间算法要高很多,为2579.而且得到的图像很明显能看到最佳的广告是ad5,因此Thompson抽样算法的实际效果的确要优于置信区间算法。
以上,就是强化学习中的Thompson抽样算法的基础知识。