监督学习与非监督学习
监督学习
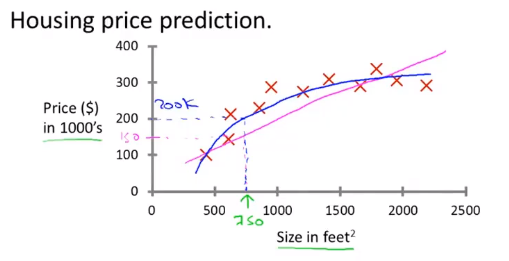
监督学习是指我们给计算机一个包含了正确数据(答案)的数据集,算法的目的就是给出更多的真确答案。这也被称为回归问题。比如说下面这张图,叉叉代表着搜集到的正确的数字。而我们要做的,是找出一条拟合的曲线,来预测某一个大小的房子的价格是多少。
虽然说价格最小精确到分,但是我们仍然可以将其认为是一个连续的值,因此可以用回归的模型来解决。回归的定义就是 : Predict continuous valued output.也就是预测连续的值。
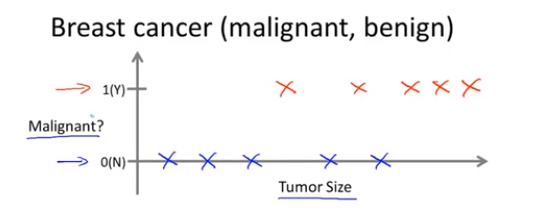
下面是另外一种监督学习的例子,横轴是肿瘤的大小,而数轴只有0和1,0代表良性肿瘤,1代表是恶性肿瘤。
或者是这样的一个有两个维度的分布:
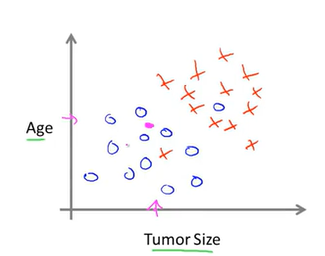
现在我们观测到一个肿瘤,我们的目的就是通过学习算法就将其归为某一类当中去。这是一个分类问题。比如第二张图,我们就可以在图上划出一条直线。
事实上,很多数据集不仅仅只有一个或者两个维度,可能有四五个或者更多特征。那怎么让学习算法能够处理这些特征呢?比如对于SVM(支持向量机),就有一个特别灵巧的数学方法(核函数),来允许计算机处理无穷多的特征
无监督学习
对于无监督学习,我们给出的数据是没有标签的,如下:
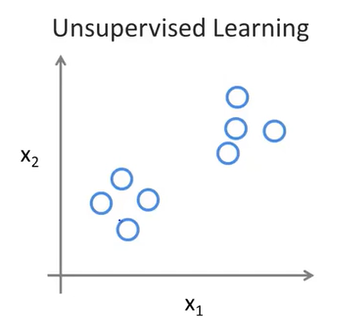
我们不知道每个数据点代表什么,我们只被告知这里有一个数据集,我们能不能在这里找到某种结构。通过无监督学习,我们可以在这个数据集中找到两个 clusters(簇) ,也就是说,这是我们之前学习过的聚类算法(K-Means)
无监督学习的一些实践:
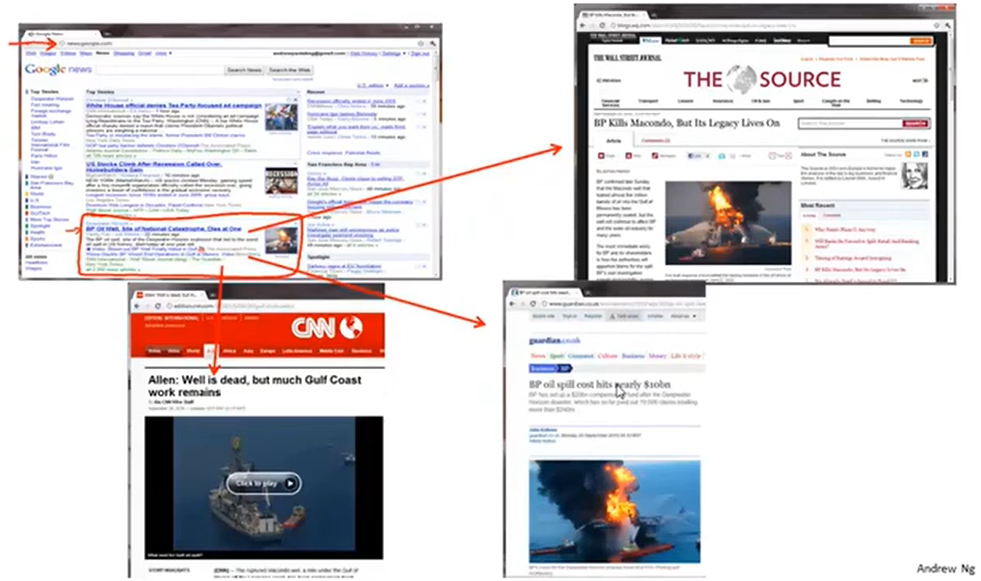
Google news:Google 每天会爬去数十万条新闻链接,然后将其聚类成一个一个新闻。比如说钻井平台新闻,集合了很多url,每个url指向不同新闻网站
聚类算法在基因组学中也有很多的应用。比如对于一个DNA微阵列数据的例子.
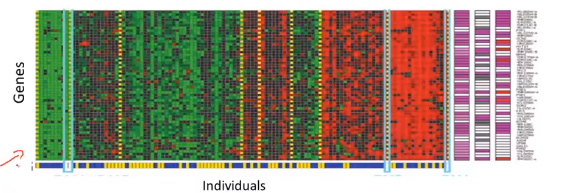
我们要做的就是运行一个聚类算法,把不同的个体归入不同的类或者归为不同类型的人。这是一种非监督学习,因为我们没有提前告知这个算法这些个体属于那一类人
非监督学习还可以用于社交圈,分析出和我们关系比较好的人,判断出哪些人互相认识并做推荐。在商业中,非监督学习可以将很多客户进行一个分类并进行精准的广告投放或者市场调研。