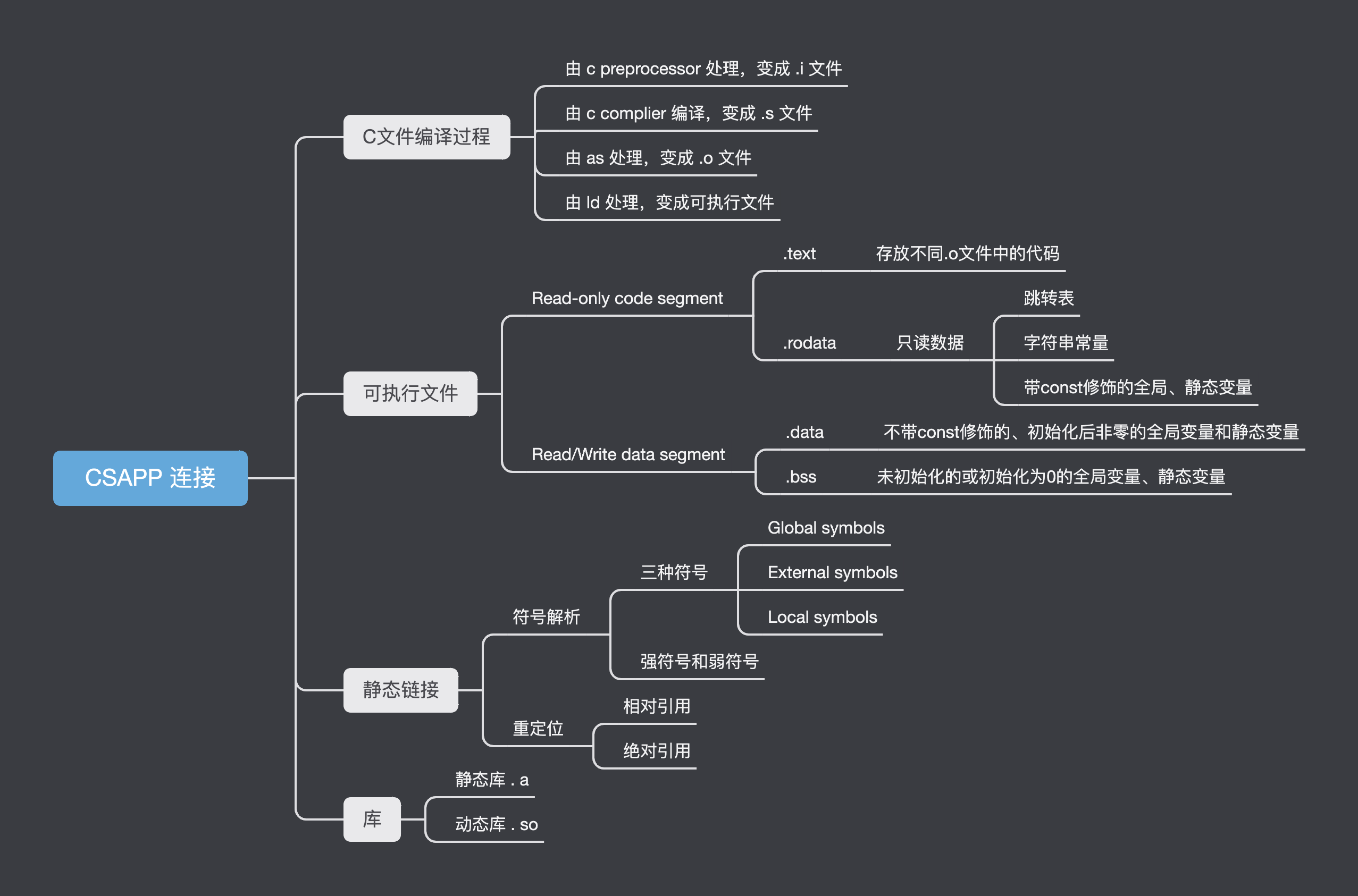
CSAPP链接(Linking)
为什么要用 Linking?
- 能让程序模块化
- Linking可以让程序写成一个包含了较小源文件的集合,而不是将所有代码整合到一起。
- Linking允许我们构建一些包含常用函数的库(Math library,standard C library)
- 能提高整个程序的运行效率
- 在时间方面,可以单独编译
- 改变其中一个源文件即可,然后重新编译
- 不需要重新编译其他的源文件
- 可以同时编译多个文件
- 空间方便,可以编写库
- 常见的函数可以整合到一个文件夹当中
- 静态链接
- 静态链接的过程就已经把要链接的内容已经链接到了生成的可执行文件中,就算你在去把静态库删除也不会影响可执行程序的执行
- 动态链接
- 动态链接这个过程没有把内容链接进去,而是在执行的过程中,再去找要链接的内容,生成的可执行文件中并没有要链接的内容,所以当你删除动态库时,可执行程序就不能运行。
- 在时间方面,可以单独编译
编译器驱动程序
现在我们有两个 .c文件:
main.c
1 | int sum(int *a, int n); |
sum.c
1 | int sum(int *a, int n) |
当我们在shell中输入这样的命令之后:gcc -Og -o prog main.c sum.c
机器会调用 GCC 来驱动程序:流程如下
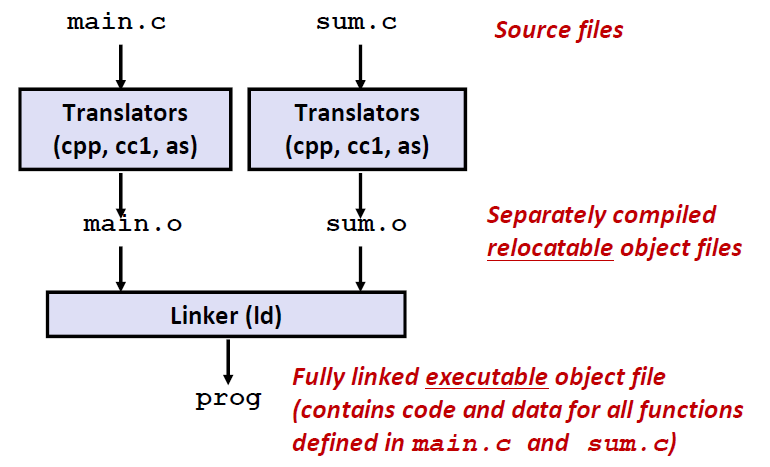
- 首先,驱动程序运行了 C 预处理器(C-preprocessor即cpp) ,它会将C的源程序main.c翻译成一个 ASCII 码的中间文件 main.i
- 接下来,驱动程序运行C编译器(C compiler即ccl) ,它将main.i 翻译成一个 ASCII汇编语言文件 main.s
- 然后驱动程序运行汇编器(assembler即as) 将main.s文件翻译成一个可重定位目标文件 main.o,同理,生成sum.o
- 最后,它运行链接器程序ld,将main.o 和 sum.o 以及一些必要的系统目标文件组合起来,创建一个可执行目标文件 prog:
- 要运行可执行proq,我们在linux shell 的命令行中下输入
./prog,shell就会调用一个叫做加载器(loader)的函数,他将可执行文件中的prog中的代码和数据复制到内存,然后将控制转移到这个程序的开头
三种 Object Files
Executable and Linkable Format (ELF)
ELF格式,是标准的目标文件的二进制格式。是三种对象文件统一的格式
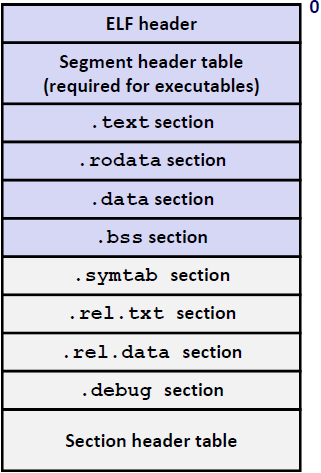
Elf header
- Word size, byte ordering, file type (.o, exec, .so),machine type, etc.
Segment header table
- Page size, virtual address memory segments (sections), segment sizes.
- .text section
- Code 代码
- .rodata section (read-only)
- 放只读的数据。如跳转表,字符串常量、带 const 修饰的全局变量和静态变量等
- .data section
- 用于维护初始化的且初始值非0的全局变量和静态变量(不带 const 修饰)
- 这部分需要空间
- .bss section 用于维护未初始化的或初始值为0的全局变量和静态变量(不带 const 修饰)
- Uninitialized global variables 没有初始化的全局变量
- “Block Started by Symbol”
- 不占用目标文件的空间,因此更节省空间
- .symtab section 符号表
- Symbol table 符号表
- Procedure and static variable names 静态变量的名字
- Section names and locations 对应所在的section的名字和位置
- .rel.text section
- Relocation info for .text section
- Addresses of instructions that will need to be modified in the executable
- Instructions for modifying.
- .rel.data section
- Relocation info for .data section
- Addresses of pointer data that will need to be modified in the merged executable
- .debug section
- Info for symbolic debugging (gcc -g) 编译成debug版本的时候会用
- Section header table
- Offsets and sizes of each section
Relocatable object file(.o file)
可重定位的文件,包含了代码和数据(初始化全局变量的数据,不包含局部变量的初始化,局部变量在真正压栈的时候才会将其初始化,在一开始连空间都没有给它分配)
可重定位文件只能和别人链接,不能单独运行
Executable object file(a.out file)
可执行文件,能直接被放在内存当中并被执行的。常常由多个.o文件链接而来
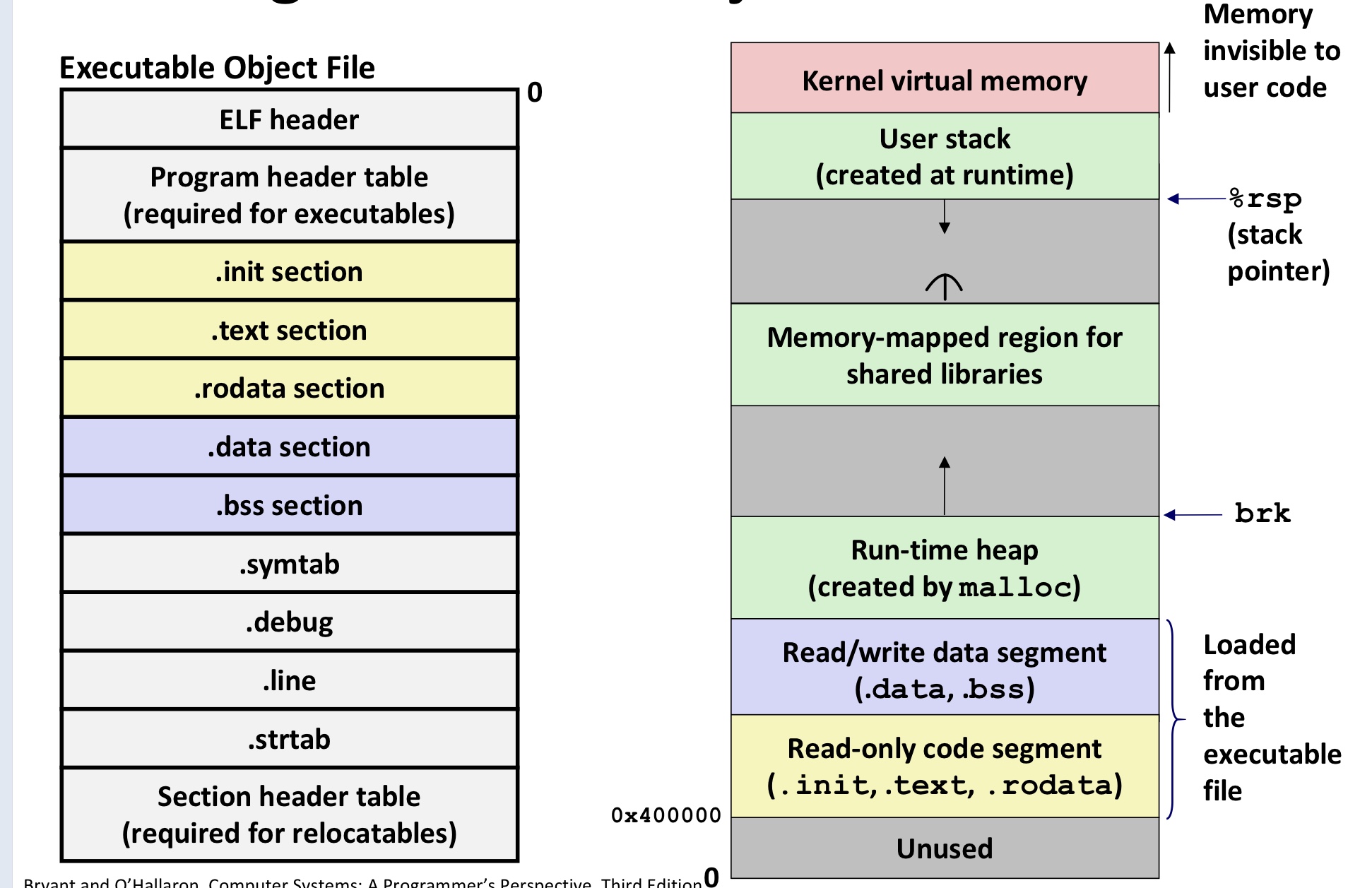
LF 可执行文件被设计得很容易加载到内存,可执行文件的连续的片(chunk)被映射到连续的内存段。程序头部表(program header table)描述了这种映射关系
加载可执行目标文件
我们可以在linux下用 ./prog 来运行可执行目标文件。
因为prog并不是一个内置的shell命令,所以shell会认为 prog是一个可执行目标文件,通过调用加载器的操作系统代码来运行它。加载器可以将可执行目标文件中的代码和数据从磁盘复制到内存当中,然后通过跳转到程序的第一条指令或入口点来运行该程序。这个过程叫做加载
在分配栈、共享库和堆的地址的时候,链接器会使用地址空间布局随机化。虽然每次程序运行的时候这些区域的地址都会改变,但是他们的相对位置是不变的。
当加载器运行时,它创建类似于下图所示的内存映像。在程序头部表的引导下,加载器将可执行文件的片(chunk)复制到代码段和数据段。
接下来,加载器跳转到程序的入口点,也就
_start函数的地址。这个函数是在系统目标文件ctrl.o中定义的,对所有的C程序都是一样的。_start函数调用系统启动函数__libc_start_main,该函数定义在libc.so中。它初始化执行环境,调用用户层的main函数,处理main函数的返回值,并且在需要的时候把控制返回给内核。
Share object file(.so file)
共享目标文件是一种特殊的可以重定位的目标文件,它只在运行的时候,由操作系统现成得加进去。在windows系统中 .so文件被叫做 .dll(Dynamic Link Libraries)
静态链接-符号解析(symbol resolution)
为了构造可执行文件,链接器必须完成两个主要任务:符号解析和重定向
目标文件定义和引用符号,每个符号对应于一个函数、一个全局变量或者一个静态变量(static 声明的变量),也就是说,除了关键字之外,我们写的都是符号。符号解析的目的是将每一个符号引用正好和一个符号定义关联起来。
比如说void swap()是定义了一个符号,而 swap() 是调用了一个符号
1 | void swap() {…} /* define symbol swap */ |
符号定义都被存放在一个符号表当中(symbol table),这张符号表记录了符号的名字大小和位置。这些记录组成了一个数组。
符号解析的目的是将每一个符号引用正好和一个符号定义关联起来。
静态变量、全局变量、局部变量
- 在内存里的位置不一样
- 静态变量不能被其他 .c文件访问,全局变量可以
- 静态变量可以在函数里面定义,出了函数再进来静态变量的值还是一样的。不会因为函数返回就没了。可以用来保留反复调用的函数的中间状态。
- 静态变量可以节省空间,减少无谓的压栈和出栈的次数
接下来我们还要详细讲解一下全局变量的注意事项
三种symbols
Global symbols
全局符号就是在本地.c文件中定义,在其他模块中也能引用 。 如非static函数和非static的全局变量(指不带static的全局变量)
External symbols
在外部文件定义,当前文件可以引用的,叫做外部符号。由其他模块定义并被模块m引用的全局符号(标志是extern,extern用来修饰全局变量,即声明在“最外层”)(要体现引用,否则不会进入符号表)
Local symbols
仅由模块m定义并能被本模块引用的本地符号。例如,在模块m中定义的带static的函数和变量(无论定义变量的位置,是全局还是在函数中,只要变量前面有static,都算是(本地)符号!)
注意:局部符号并不是局部变量!!!!
Local non-static C variables vs local static variables
- 本地非静态变量是存放在栈里的而本地静态变量是存放在 .bss或者 .data当中的

问2个问题:
- 一开头的
static int x和f()、g()中的static int x,这三个 x是不是同一个 x?
这是三个不同的静态变量,都在.data当中初始化了。在编译的时候,还要给x加上不同的后缀。
- 如果是同一个x,那么它们的值?如果不是x,那么return的x分别是哪一个x?
f()、g()中返回的值即在函数中定义的static int;h()返回的值是global的static int
第一次调用f(),g(),h()。返回的值分别是 17,33,42
第二次调用f(),g(),h()。返回的值分别是 18,47,69
因此我们也可以了解静态变量的性质:在进入函数,x还是之前的x,并不会重新声明
关于symbols划分的例题
例1
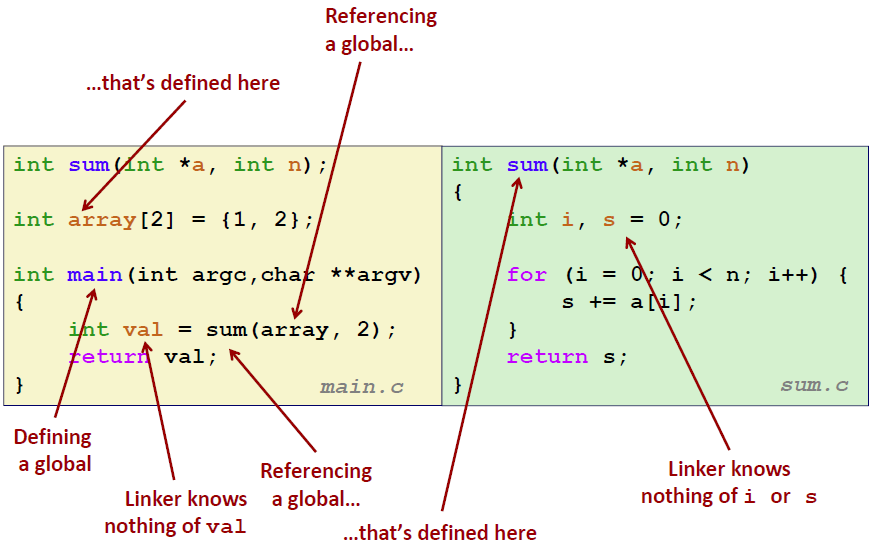
比如说在 main.c里面,sum() 并不是 global symbol,是一个 external symbol
array和 main都是global symbol
val是局部变量,并不是symbol
例2
我们再来看一个例子,下面这个.c文件哪些名字会被保存在 symbol table 当中呢?

incr 是全局变量 是 global symbol
foo 是static 修饰的,是local symbol
a,argc,argv都是参数,不是变量
main 是一个 global symbol
printf 是一个external symbol
我们可以用命令 readelf -s symbols.o 来看一下符号表
全局变量
Type Mismatch Example

这样两个.c文件编译,还是能打印出来的,只是最后答应出来的是类型为long int的3.14
所以,我们尽量不要用全局变量,在多人合作的情况下非常容易出错。
如果一定要用,那么要养成一些习惯
- 如果我自己的模块,要一直用,那就加static
- 在定义一个全局变量的时候顺便初始化它
- 如果我们引用了一个外部的全局变量,那么就用 关键词 extern 去修饰
- 这样能将其变成一个 weak symbol
- 当其他文件中没有定义这个变量,但我加了extern,linker 也会报错。
Use of extern in .h Files

我们做一个 .h文件,里面声明了全局变量 g和全局函数f(),然后在其他文件中通过 Include 来将这两个全局变量和全局函数加进来
这是标准的头文件使用方法,头文件一般只写声明,不写定义! 因为头文件是在预处理的时候将.h文件加入到.c文件去,如果在.h文件中写了定义,那么在预处理的时候c1.c和c2.c都会有.h中关于变量和函数的定义,在链接器将两个.c文件链接的时候会报重复定义的错误
链接器怎么解决重复定义的?
首先,我们要了解符号 是 strong 还是 weak的概念
Strong: procedures and initialized globals 初始化了的全局变量是Strong 的
Weak: uninitialized globals Or ones declared with specifier extern 没有初始化或者是外部符号是 Weak的

当发生冲突的时候,有一些规则
- Rule 1: 同名字且都为Strong的符号是不被允许的
- 相同名字的 strong 符号只能定义一次,否则 Linker是会报错的
- Rule 2: 如果有一个强的和若干个弱的符号,那么选择那个强的符号
- References to the weak symbol resolve to the strong symbol
- Rule 3如果没有一个强的,有很多弱的符号,那就随便选一个
- Can override this with gcc –fno-common
- 也可以要求编译器强制报错,不要产生任何的warning和error
下面是一些例子:
1:
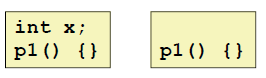
因为在两个文件里, p1都是strong的符号,因此 链接器会报错。
2:

p1和p2 不冲突,两个x都是弱符号,因此不冲突
3:
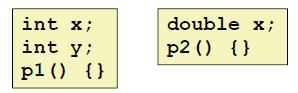
两个x的数据类型都是不同的,但是这也是被允许的。linker是不管类型的,他只管x在哪
然而,严格意义上来说这是不行的。因为double(8个字节)比int大,当我们在p2中写入的时候,因为x和y是连续存放的,因此可能会把 int y (4个字节)覆盖掉。
4:

同理,虽然是合法的,但是 double的x可能吧 int y给覆盖掉
5:

两个x是一强一弱的,会选择强的那个初始化,因此并不会冲突
注意:只有 compiler会注意到类型,linker是不会进行类型检查的
静态链接-重定位(relocation)
静态重定位是在目标程序装入内存时,由装入程序对目标程序中的指令和数据的地址进行修改,即把程序的逻辑地址都改成实际的地址。对每个程序来说,这种地址变换只是在装入时一次完成,在程序运行期间不再进行重定位。
例如,一个以“0”作为参考地址的装配模块,要装入以1000为起始地址的存储空间。显然,在装入之前要做某些修改,程序才能正确执行。例如,MOV EAX,[500]这条指令的意义,是把相对地址为500的存储单元内容1234装入eax寄存器。现在内容为1234的存储单元的实际地址为1500, 即为相对地址(500)加上装入的地址(1000),因此,MOV EAX,[500]这条指令中的直接地址码也要相应地加上起始地址,而成为MOV EAX,[1500]。
程序中涉及直接地址的每条指令都要进行这样的修改。需要修改的位置称为重定位项,所做的加实际装入模块起始地址修改中的块起始地址称为重定位因子。
我们看到,从可重定位目标文件到可执行目标文件,经历了下图这样一个过程:
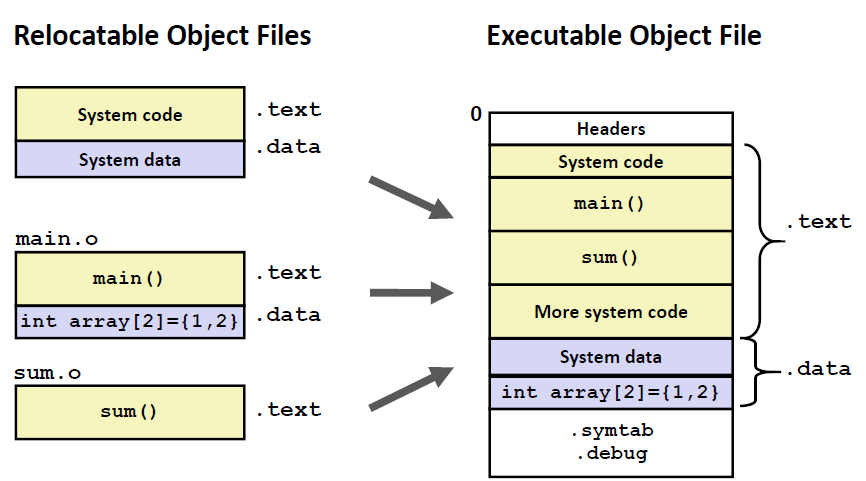
拿一个实际例子来说,可执行文件包含了从不同.o文件中来的内容。最终我们要生成一个可执行文件,其代码段和数据段是放在一起的。因此我们要对两个.o 文件做一个拼接。比如说我们要把main() 、sum()放在一起。 也就是说做一个将 .o文件剪开,再归类拼接到一起的过程 。
假设现在 main.o 和 sum.o 发生了链接;又有一个 main1和sum.o 还有 swap.o 一起发生了链接,构成另外一个可执行文件。这就可能造成了 sum() 在不同的可执行文件当中相对于main() 的相对位置也是不同的。因此,链接器需要为目标文件中的符号进行重定位
Relocation Entries
那么从左边的部分到右边的部分,需要解决的问题就是将 函数和.data中的一些变量的地址给固定下来(将地址填到相应位置)
1 | //main.c |
1 | //sum.c |
重定位算法
1 | foreach section s { |
我们看看这个链接器是如何进行重定位的。首先,可重定位目标文件main.o 如下:
我们看到这时候的 .o 文件用的都是相对地址,是以 0为起始地址的
我们注意到。array的地址一开始被初始化为0,然后后面还有一条注释表明在重定位的时候才会把绝对地址填进去
同理,sum() 函数也是一个相对位置(填入的是返回后的地址,也就是+13),在重定位的时候,才会填入绝对的地址
1 | 0000000000000000 <main>: |
main函数引用了两个全局符号,一个是array,还有一个是sum。为每个引用,汇编器都产生一个重定位条目,然后显示在后面一行上:这里是a: R_X86_64_32 array和f: R_X86_64_PC32 sum-0x4
这些重定位条目告诉链接器对sum的引用要进行32位相对地址进行重定位 ,表现为R_X86_64_PC32; 但是对 array的引用是进行32位绝对地址的重定位,表现为 R_X86_64_32
相对引用
在上面的汇编代码中,main函数在第六行调用sum数,sum函数是在模块sum.o 中的。call指令 开始于节偏移 0xe 的地方,包括一字节的操作码0xe8,后跟着的是PC相对引用的占位符。现在还是00
假设重定位条目 r 由 4个字段组成
1 | r.offset = 0xf |
这些字段告诉链接器修改开始于偏移量0xf 处的32 位PC相对引用,这样在运行时它会指向 sum 例程。现在,假设链接器已经确定 ADDR(.text)=0x4004d0和 ADDR(sum)=0x4004e8
然后通过相对寻址算法,连接器可以计算出引用的运行时地址
1 | refaddr = ADDR(s) + r.offset |
然后更新引用,让它在运行时指向sum程序
1 | *refptr = (unsigned) (ADDR(r.symbol) + r.addend - refaddr) |
因此,在在最后的.o文件中, call指令有着如下的重定位形式
4004de: e8 05 00 00 00 callq 4004e8 <sum> # sum()
在运行时,call指令将存放在地址0x4004de 处。当CPU执行call 指令时,PC 的值为0x4004e3, 即紧随在call 指令之后的指令的地址。为了执行这条指令,CPU 执行以下的步骤:
1) 将PC 压入栈中
2) $PC\leftarrow PC+0x5 = 0x4004e3+0x5 = 0x4004e8$
下面是重定位之后的在 可执行文件的text区域中的代码。
1 | 00000000004004d0 <main>: |
我们有发现,在 .o 文件当中 e: e8 00 00 00 00 callq 13 <main+0x13> # sum() 这行汇编代码已经变成了4004de: e8 05 00 00 00 callq 4004e8 <sum> # sum() ,其中 0x4004e8 是sum的绝对地址,因为产生跳转目标的编码是由目标指令的地址与紧跟在跳转指令后面那条指令的地址之间的差得出的。因此这时候产生跳转目标的编码 = 0x4004e8-0x4004e3 = 0x05,和指令的十六进制表示相匹配,callq 采用的这种方式就是基于PC的相对地址寻址方法。
绝对引用
重定位绝对引用相当简单。比如下面这段汇编。 mov指令将array的地址(一个32位立即地址)复制到寄存器$\%edi$当中。mov指令开始于偏移量0x9 的位置,包括1字节操作码 $0xbf$ ,后面跟着array 的32位绝对引用的占位符
1 | 0000000000000000 <main>: |
现在给出占位符条目 r ,包括4个字段:
1 | r.offset = 0xa |
这些字段告诉链接器要修改从偏移量$0xa$ 开始的绝对引用,这样在运行时它将会指向array的第一个字节。现在,假设链接器已经确定
ADDR(r.symbol)=ADDR(array)=0x601018
那么根据上面的算法,我们可以计算 *refptr的值
1 | *refptr = (unsigned) (ADDR(r.symbol) + r.addend) |
因此我们要将汇编改为
4004d9: bf 18 10 60 00 mov $0x601018,%edi 因为我们的机器是小端法
库(libraries)
什么是库?
库是一些常用函数的集合,比如说基于 Math,I/O,memory management,string manipulation 的一些操作函数。
那么我们要引用库中的函数,有两种方法:
- 选择1:将所有的函数放到一个源文件当中
- 这样程序员就会将一个很大的文件链接到自己的程序当中
- 空间和时间的效率都很差。我只用一个函数,但是我却要链接很多很多其他没用的函数链接进来,这样就会浪费内存和磁盘的空间。且每次编译都要进行很多无谓的工作。
- 选择2:将每一个库函数分别放在不同的源文件当中
- 程序员将合适的函数精确的链接到自己的程序当中
- 更加油效率,但对程序员来说很不友好,要记住更多函数的名字,压力更大。
这两种方法都不是特别好,于是我们提出了两种方案。
静态库(static library)
archive(.a库文件) 就是把所有的函数头尾相连,打包。前面加一个index索引
使用链接器,使其尝试通过在一个或多个存档中查找符号来解析未解析的外部引用。
- 当我和库文件( .a)连接的时候,会到 .a 文件当中去查找哪些.o 文件是我需要的。那么这一部分 .o文件链接到我的可执行文件当中
.a 和 .o 文件的关系如下:
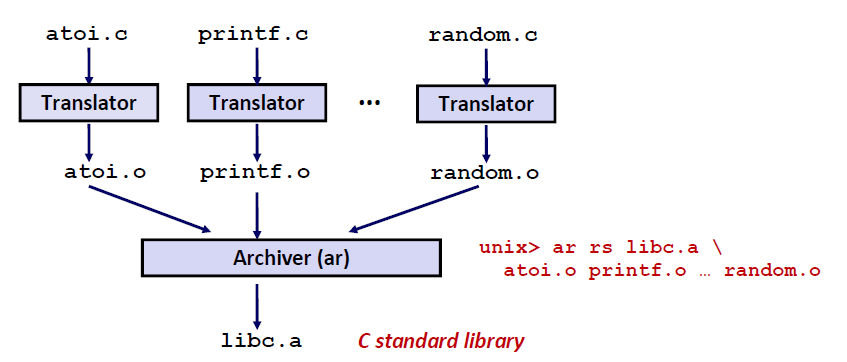
我们也可以字节编写一个 .a 文件:

在编译链接的过程如下图所示:
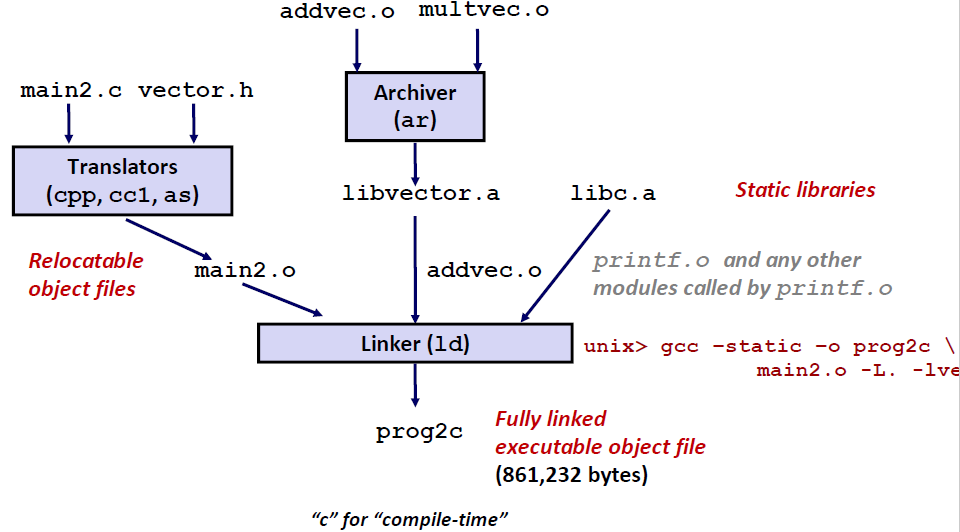
当我们安装环境的时候,已经把库的查找路径安装进去了,编译器会根据这些缺省的路径去查找。
查找的优先级:include 某一个文件可以用双引号”” 和一个\<> 双引号代表当前目录下的文件,而\<> 则代表在系统缺省路径中查找。
使用静态库
- 按顺序扫描.o文件和.a文件
- 在扫面描的时候,把unresolved 符号引用都保存下来
- 每当一个新的 .o 和 .a 进来,我们回去看前面的那张表,去看看前面保存的哪些unresolved 符号是否在这些 .o和 .a 文件中存在。逐个把这些unresolved 符号解析掉
- 如果整个过程结束,发现表中还有symbol没有找到,那么就会报 symbol not found ,链接失败
动态链接共享库(shared library)
静态链接库有如下缺点:
- 增加了硬盘的占用空间
- 增加了内存的占用空间,比如说一份printf的代码可能会在内存中存放100份
- 如果要更新某些库中的一些函数,我不得不将和这个库有关的程序重新编译链接一遍。这个代价是非常非常大的。编译一个程序是十分消耗时间的。
所以我们引入了共享库/动态链接库的概念
当我想要一个 对象文件的时候,我并不将其链接进我们的程序,只有在要使用这个文件的时候,再动态的加载进去。这样就能让磁盘只保存一份库的代码即可
那么有哪些情况需要用到 object file呢?
- 当加载可执行程序的时候,发现要用特定的object file,就将其加载到内存当中去
- 可执行程序要用到某个 object file中的某个全局变量或者函数的时候,到那句语句要执行的时候我在将对应的object file加载进去。
在windows中,这类库叫做 .dll ; 在linux环境下,叫做 .so
What dynamic libraries are required
- .interp section
- Specifies the dynamic linker to use (i.e.,ld-linux.so)
- .dynamic section
- Specifies the names, etc of the dynamic libraries to use
- where are the libraries found
- 专门有一个可执行文件 ldd帮我们去找到我们需要的动态链接库在什么地方
生成一个动态链接库的例子
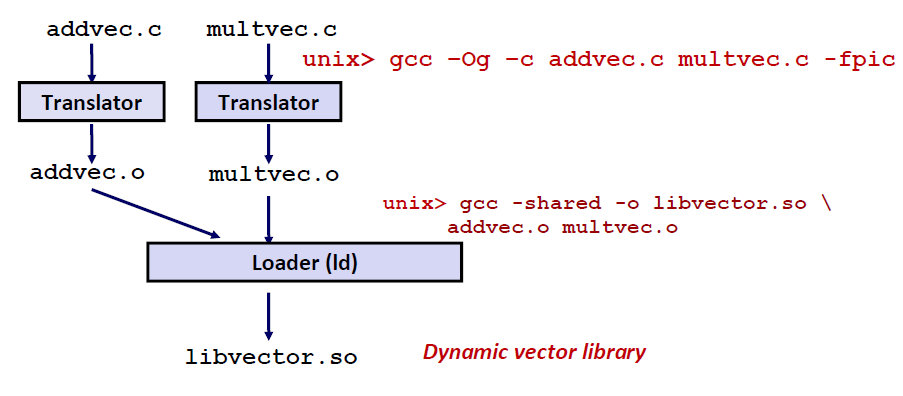
将两个 .o 文件,通过命令 gcc -shared -o libvector.so addvec.o multvec.o 这行命令来生成一个 .so 文件。 其中 .o 表示 output,即说明生成的这个文件(共享库)是什么名字。
Dynamic Linking at load-time
现在我们来讲一下加载过程中怎么样使用共享库
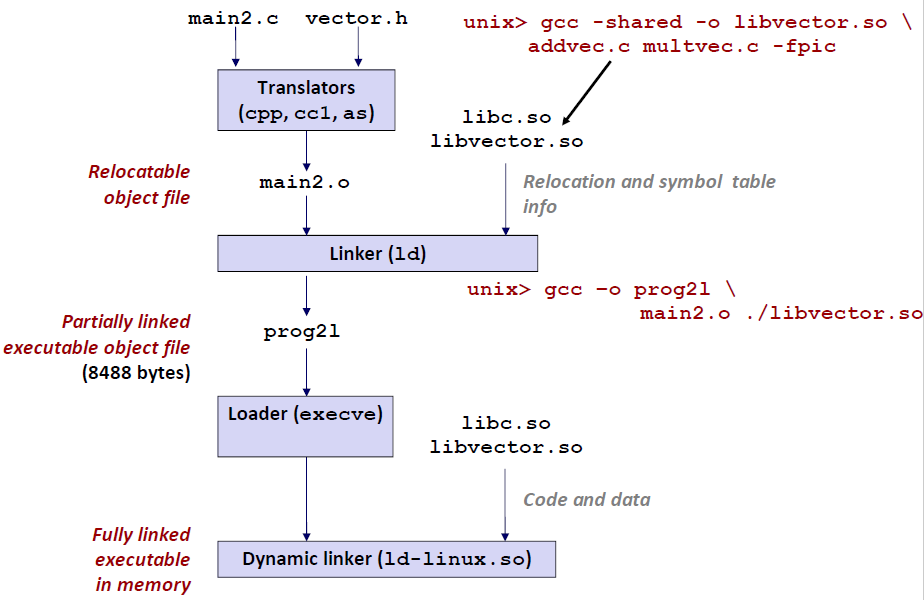
我们对程序采用动态链接,这就是编译链接生成函数的内部步骤。
我们通过 gcc -o prog21 main2.o ./libvector.so 这行命令就可以将main2.o 和我们需要的 libvector.so,libc.so 组合生成prog21文件。
但是这个prog21文件有 main2.o的代码,但是却没有 libvector.so 的代码,仅仅是在里面“埋了一个伏笔告诉我们会用到libvector.so “
当我们要运行的时候(最后),系统会通过动态链接器(ld-linux.so) 将需要的两个 .so 文件加载进去。最终形成一个完整的文件。
Dynamic Linking at Run-time
现在有一个程序如下:
1 |
|
这个工程的逻辑如下:
首先我们要在本地申明一个和要链接的动态库绑定的指针(handle)
然后打开这个共享库
然后正常使用共享库当中的符号
最后关闭这个共享库
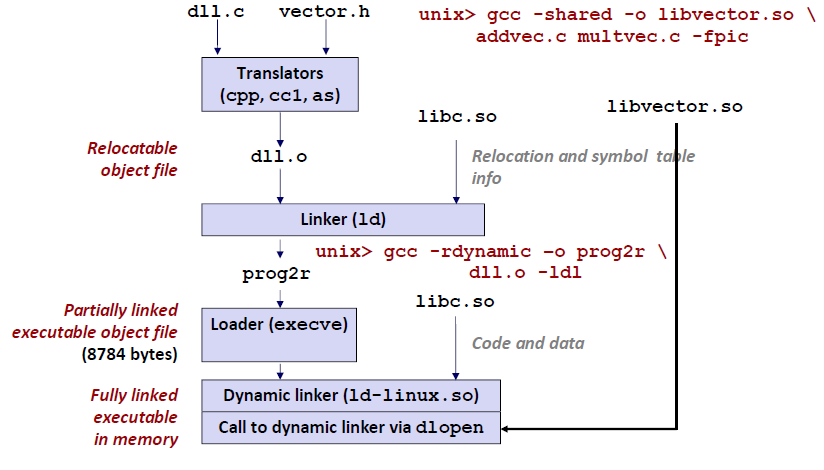
静态库 vs 动态库
静态库和动态库的载入时间是不一样的。
静态库的代码在编译的过程中已经载入到可执行文件中,所以最后生成的可执行文件相对较大。
动态库的代码在可执行程序运行时才载入内存,在编译过程中仅简单的引用,所以最后生成的可执行文件相对较小。可以提高代码的可复用度和降低程序的耦合度。
静态库在程序编译时会被连接到目标代码中,程序运行时将不再需要该静态库。
动态库在程序编译时并不会被连接到目标代码中,而是在程序运行是才被载入,因此在程序运行时还需要动态库存在。
无论静态库,还是动态库,都是由.o文件创建的。因此,我们必须将源程序hello.c通过gcc先编译成.o文件。
总结
链接能让多个目标文件最终组合成一个程序
链接可以在程序生命周期的不同时间发生:
- Compile time (when a program is compiled) 编译阶段,静态库
- Load time (when a program is loaded into memory) 加载阶段,动态库
- Run time (while a program is executing) 运行阶段, 动态库
了解链接能帮助我们避免恶心的错误