CSAPP虚拟内存
物理和虚拟地址
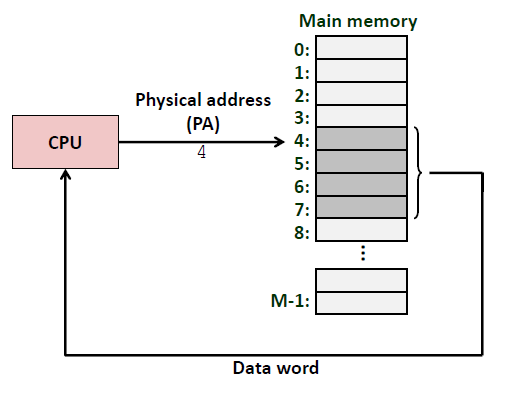
一个使用物理寻址的系统:
一个使用虚拟寻址的系统:
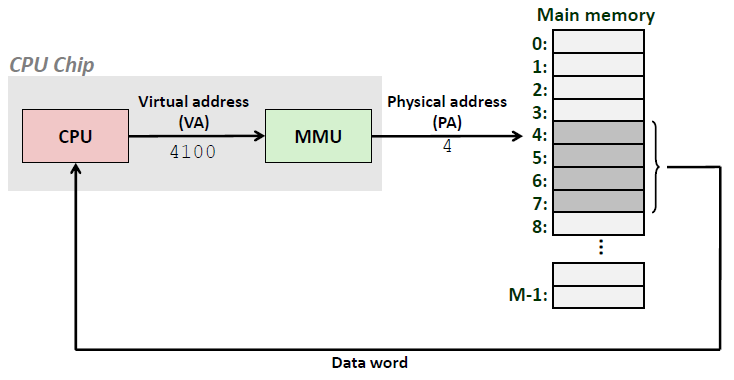
使用虚拟寻址,CPU通过生成一个虚拟地址来访问主存,这个虚拟地址在被送到内存之前先转换成适当的物理地址。将一个虚拟地址转换为物理地址的任务叫做地址翻译。 地址翻译需要CPU硬件和操作系统之间的紧密合作。CPU芯片上叫做内存管理单元(Memory Management Unit,简称MMU) 的专用硬件,利用存放在主存中的查询表来动态翻译虚拟地址,该表的内容由操作系统管理
地址空间
地址空间(address space)是一个非负整数地址的有序集合: ${0,1,2,\cdots}$ . 如果地址空间中的整数时连续的,那么我们说他是一个线性地址空间。
为了简化讨论,我们总是假设使用的是线性地址空间。在一个带虚拟内存的系统中,CPU 从一个有$N=2^n$个地址的地址空间中生成虚拟地址,这个地址空间称为虚拟地址空间(virtual address space) :
${0,1,2\cdots,N-1}$
一个地址空间的大小是由表示最大地址所需要的位数来描述的。例如,一个包含$N=2^n$个地址的虚拟地址空间就叫做一个n 位地址空间。现代系统通常支持32 位或者64 位虚拟地址空间。
一个系统还有— 个物理地址空间(physical address space),对应于系统中物理内存的M个字节:
${0,1,2\cdots,M-1}$, M不要求是2 的幂,但是为了简化讨论,我们假设 $W=2^m$
我们允许每个数据对象有多个独立的地址,其中每个地址都选自一个不同的地址空间。这就是虚拟内存的基本思想。主存中的每字节都有一个选自虚拟地址空间的虚拟地址和一个选自物理地址空间的物理地址
虚拟内存作为缓存的工具
接下来我我们来看看虚拟内存作为缓存的工具
一般来说,虚拟内存是一组连续的存放在硬盘当中的bytes
我们把虚拟地址空间分成很多很多小块,每一个小块叫做一个page。这些page会与真实的物理内存空间进行映射,物理内存也被分成了很多小块,每一个小块可以叫做page也可以叫做frame。虚拟内存的pages很多都是空的,不然的话物理空间没有那么多page和虚拟地址空间一一映射
注意,这里的物理地址空间所代表的是主存DRAM,并不是Cache SRAM。因为磁盘的缓存就是DRAM,此外,DRAM还需要SRAM作为它的缓存
如下图所示:
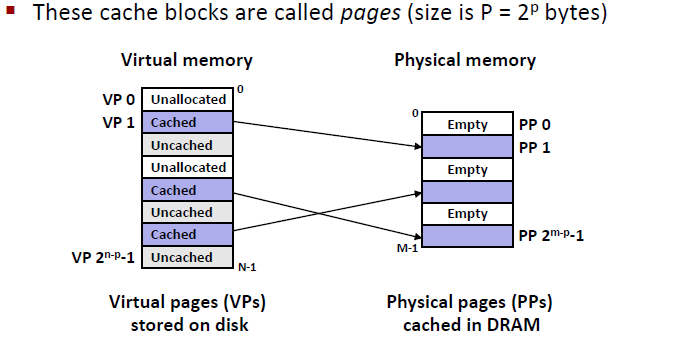
我们发现page有不同的状态
比较理想的的状态是page在我的缓存里面,这时候page的状态叫做 Cached
第二种状态叫做unallocated,代表这一个page在磁盘和内存中都没为其分配任何空间。
第三种叫做uncached,也就是还没有缓存的。表明我还没有用这个page,page中的数据当前并不在我的内存里面,他可能是在栈里面或者堆里面的某块空间。
DRAM Cache Organization
如果是DRAM作为磁盘的缓存的话,从磁盘中加载到Cache line中的block需要大于1ms的时间(一百万个运行周期)。因为DRAM比Disk要快差不多10000倍,而SRAM又比DRAM块十多倍。
因此,我们希望一次从磁盘中读取较多的信息,让读取的效率变高:
- Large page (block) size : typically 4KB
- Linux “huge pages” are 2MB(default) to 1GB
- Fully associative
- 当DRAM作为disk的Cache的时候,表现为全相连的cache,也就是说,所有的cache line都是连在一起的。整个Cache 就只有一个set
- 这样,任何一个virtual page可以放在物理内存当中的任意一个空的地方
- 但这样就需要一张很大的映射表,来记录哪一个virtual page映射到哪一个physical page. 比如说4G内存,需要一个 8bytes*1M 的空间
不命中时的替换策略也很重要,因为替换错了虚拟页的处罚也非常之高。因此,与硬件对SRAM 缓存相比,操作系统对DRAM 缓存使用了更复杂精密的替换算法
因为对磁盘的访问时间很长,DRAM 缓存总是使用回写,而不是直写。
Enabling Data Structure: Page Table
同Cache一样,虚拟内存系统必须有某种方法来判定一个虚拟页是否缓存在DRAM 中的某个地方。如果是,系统还必须确定这个虚拟页存放在哪个物理页中。如果不命中,系统必须判断这个虚拟页存放在磁盘的哪个位置,在物理内存中选择一个牺牲页,并将虚拟页从磁盘复制到DRAM 中,替换这个牺牲页。
我们提出了一个解决方案: page table (页表)
页表将虚拟页映射到物理页。每一次地址翻译硬件(MMU)将一个虚拟地址转换为物理地址的时候,都会读取页表。操作系统负责维护页表的内容,以及在磁盘和DRAM之间来回传送页
页表就是一个页表条目(Page Table Entry , PTE)的数组,每一个PTE都是由一个有效位和一个n位地址字段组成的。
- 其中,有效位表明了该虚拟页当前是否被缓存在DRAM当中。如果设置了有效位为1,那么地址字段就表示DRAM 中相应的物理页的起始位置,这个物理页中缓存了该虚拟页。
- 如果没有设置有效位,(0) ,那么一个空地址表示这个虚拟页还未被分配。
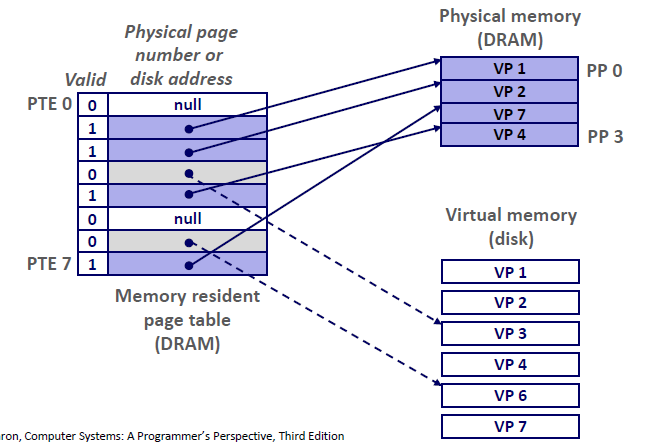
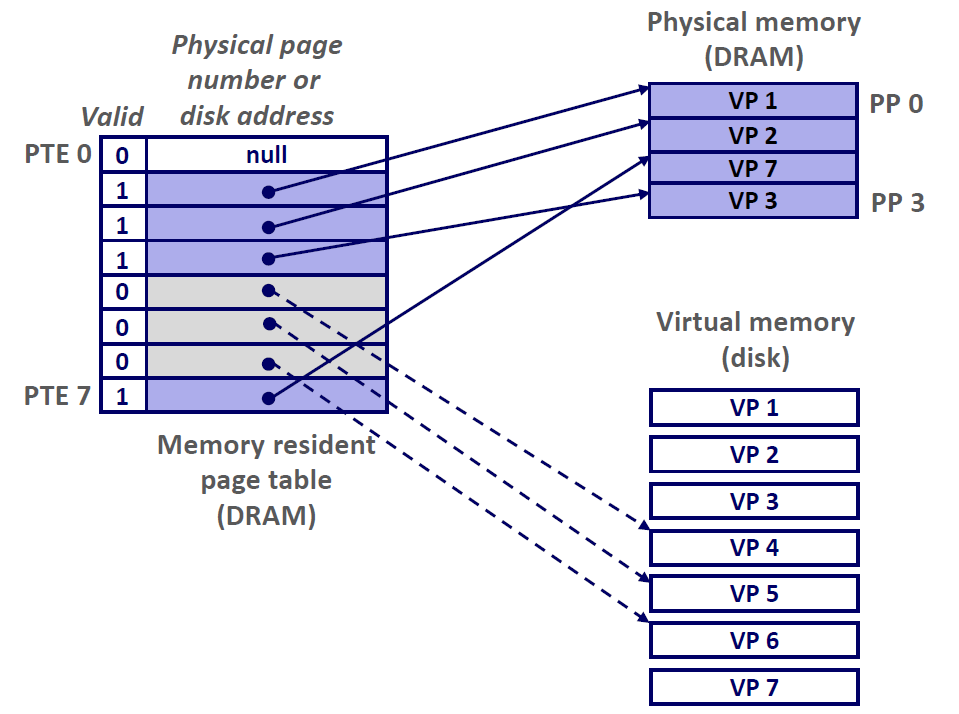
比如说下图,一共有8个虚拟页和4个物理页的系统的页表。
- 四个虚拟页(VP 1、2、7、4) 当前被缓存在DRAM当中。
- 两个页(VP0,5) 还没有被分配
- 剩下的页(VP3,6) 已经被分配了,但是当前还没有被缓存,(为其分配物理地址)
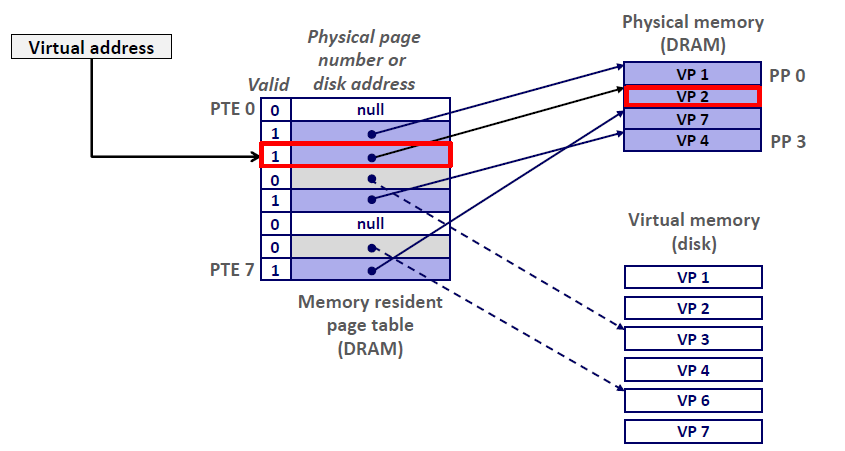
Page Hit
Page hit: reference to VM word that is in physical memory (DRAM cache hit)
当CPU想要读取包含在VP2的虚拟内存的一个字时(VP2已经被缓存在DRAM当中)。地址翻译硬件MMU 将虚拟地址作为一个索引来定位PTE2,并从内存中读取它,因为设置了有效位,那么地址翻译硬件就知道VP2是缓存在内存当中的了。
所以,地址翻译硬件用PTE中的物理内存地址,构造出这个字的物理地址并读取它
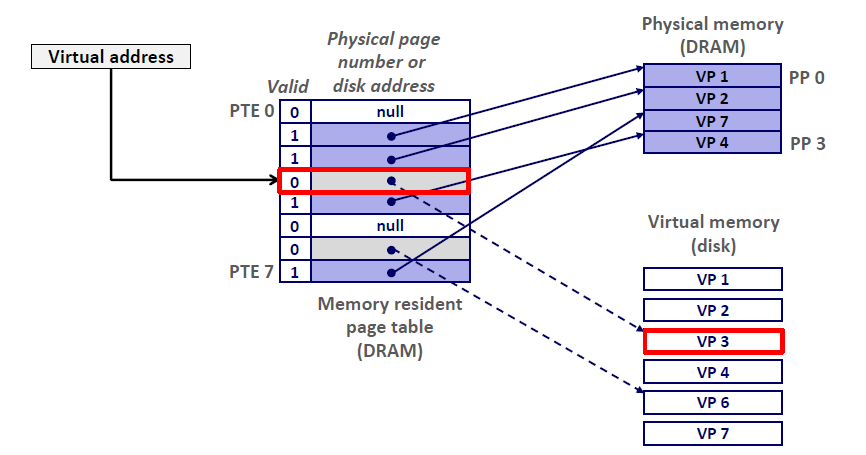
Page Fault
Page fault: reference to VM word that is not in physical memory (DRAM cache miss)
当我发生page fault的时候,也就是缺页。那么整个计算机的处理流程如下:
- CPU想引用VP3中的一个字,但是我们知道VP3并未缓存在DRAM当中。
- 地址翻译硬件从内存中读取PTE3,但是发现这个valid bit =0,推断出VP3未被缓存。而且出现了一个缺页异常
- 缺页异常调用内核中的缺页异常处理程序,该程序会选择牺牲一个页。这里我们选择的是PP3中存放的VP4
- 当VP4已经被写道磁盘当中去了,dirty bit =0,这时候它将直接删除
- 当VP4还没有写到磁盘当中,dirty bit =1,因此内核会先将其复制到磁盘
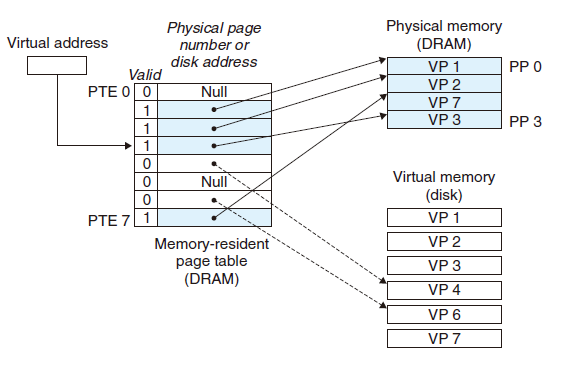
- 处理完VP4之后,内核从磁盘复制VP3到内存中的PP3,并更新PTE3,随后返回
- 当异常处理程序返回时,它会重新启动导致缺页的指令,该指令会把导致缺页的虚拟地址重发送到
地址翻译硬件。但是现在,VP 3 已经缓存在主存中了,那么页命中也能由地址翻译硬件正常处理了。
整个过程会消耗非常非常多的时间
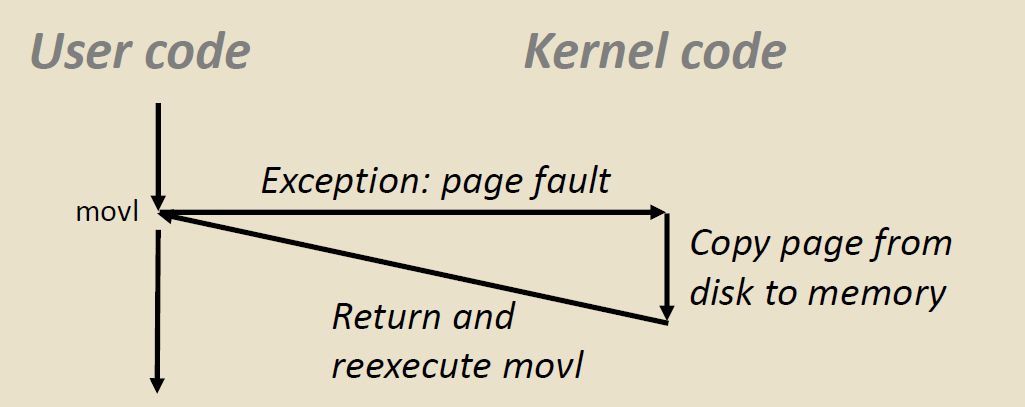
Triggering a Page Fault
什么时候会触发缺页?
比如说,当一个用户想要在一个地址中写入东西
1 | int a[1000]; |
其汇编语言如下:
80483b7: c7 05 10 9d 04 08 0d $0xd,0x8049d10
但是这个位置所在的page ,正在磁盘上面,于是MMU 就受到了缺页报错。

Completing page fault
- 发现缺页错误,操作系统的底层Kernel会协助我们将磁盘中的页复制到主存当中
- 然后返回并重新执行movl,这时候就没有缺页错误了。
Allocating Pages
下图为我们展示了一个分配一个新的虚拟内存页时(例如,调用malloc)对页表的影响。
在这个示例中,VP5的分配过程是在磁盘上创建空间并更新PTE5,使它能指向磁盘上这个新创建的页面
又是局部性救了我们
虚拟内存看起来效率很低,但实际上它十分有效,这归因于局部性原理
尽管在整个运行过程中程序引用的不同页面的总数可能超出物理内存总的大小,但是局部性原则保证了在任意时刻,程序将趋向于在一个较小的活动页面(active page)集合上工作,这个集合叫做工作集(working set)或者常驻集合(resident set)
如果 工作集的大小小于物理内存的大小,那么程序就会有良好的时间局部性,虚拟内存系统就能做的相当好
但是如果工作集的大小大于物理内存的大小,那么程序将进入一个 抖动(Trashing) 的状态,这是页面将不断地换进换出。
如果在多个进程同时运行的情况下,当所有的工作集大小之和大于主存的大小的时候,也会发生抖动。这时候我们需要”挂起”一个占用内存较大的进程,将其放到磁盘当中去,腾出空间给优先级比较高的、能快速跑完的程序。
虽然虚拟内存通常是有效的,但是如果一个程序的性能非常慢,那么程序员就需要考虑是不是电脑发生了抖动
虚拟地址对内存管理的简化
虚拟地址是一个有用的机制,因为它大大地简化了内存管理,并提供了一种自然的保护内存的方法
之前我们都是假设有一个单独的页表和所有的物理内存进行映射,但是我们要知道,实际上,操作系统为每一个进程提供了一个独立的页表,也就是一个独立的虚拟地址空间,如下图所示:
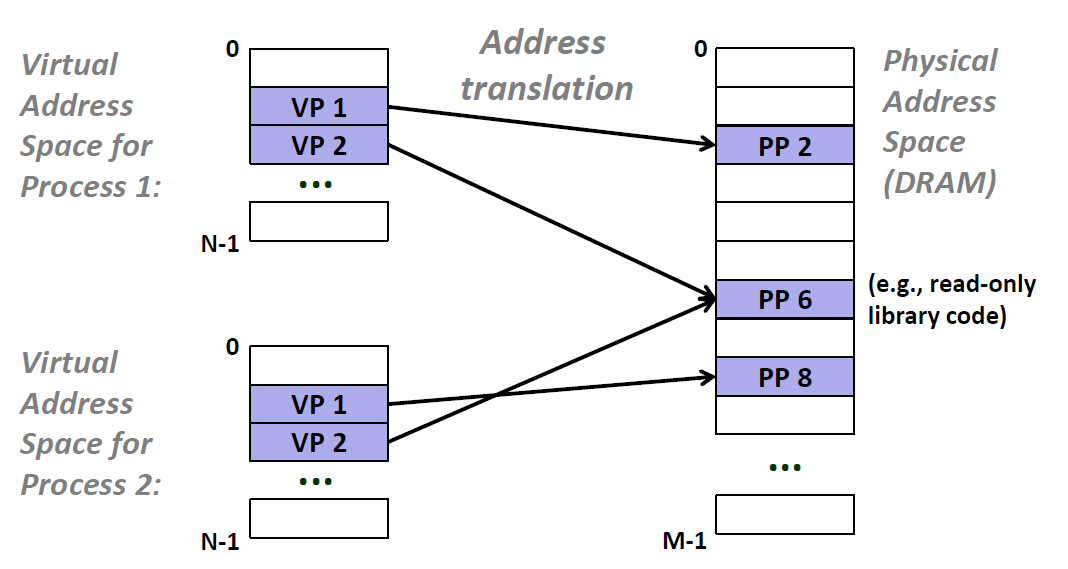
在这个实例当中,Process 1 的页表VP1映射到PP2,VP2映射到PP6 同理,Process2 的 页表的VP1映射到PP8,而Process2映射到PP6.因此,我们知道了多个虚拟页面可以同时映射到同一个共享物理页面上。==提问:这样为啥能提升局部性?==
按需页面调度和独立的虚拟地址空间的结合,对系统中内存的使用和管理造成了深远的影响。特别地,VM 简化了链接和加载、代码和数据共享,以及应用程序的内存分配
简化链接
独立的地址空间允许每个进程的内存映像使用相同的基本格式,而不管代码和数据实际存放在物理内存的何处
对于64 位地址空间,代码段总是从虚拟地址0x400000 开始。数据段跟在代码段之后,中间有一段符合要求的对齐空白。栈占据用户进程地址空间最高的部分,并向下生长。这样的一致性极大地简化了链接器的设计和实现,允许链接器生成完全链接的可执行文件,这些可执行文件是独立于物理内存中代码和数据的最终位置的。
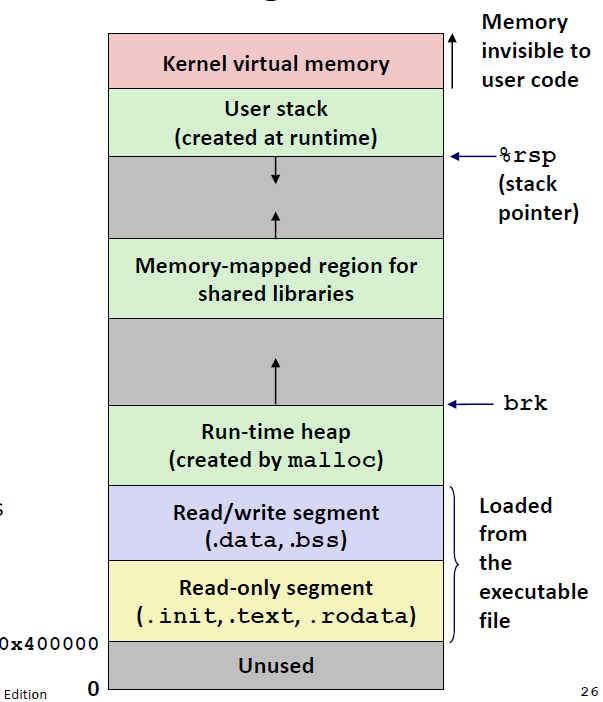
简化加载
虚拟内存还使得容易向内存中加载可执行文件和共享对象文件。要把目标文件中.text和.data 节加载到一个新创建的进程中,Linux 加载器为代码和数据段分配虚拟页,把它们标记为无效的(即未被缓存的), 将页表条目指向目标文件中适当的位置。
但是,加载器从不从磁盘到内存实际复制任何数据。在每个页初次被引用时,要么是CPU 取指令时引用的,要么是一条正在执行的指令引用一个内存位置时引用的,虚拟内存系统会按照需要自动地调整数据页。
简化共享
独立地址空间为操作系统提供了一个管理用户进程和操作系统自身之间共享的一致机制。一般而言,每个进程都有自己私有的代码、数据、堆以及栈区域,是不和其他进程共享的。在这种情况中,操作系统创建页表,将相应的虚拟页映射到不连续的物理页面。
然而,在一些情况中,还是需要进程来共享代码和数据。例如,每个进程必须调用相同的操作系统内核代码,而每个C 程序都会调用C 标准库中的程序,比如 printf() . 操作系统通过将不同进程中适当的虚拟页面映射到相同的物理页面,从而安排多个进程共享这部分代码的一个副本,而不是在每个进程中都包括单独的内核和C标准库的副本
简化内存分配
虚拟内存为向用户进程提供一个简单的分配额外内存的机制。当一个运行在用户进程中的程序要求额外的堆空间时(如调用malloc 的结果), 操作系统分配一个适当数字(例如k)个连续的虚拟内存页面,并且将它们映射到物理内存中任意位置的k个任意的物理页面。由于页表工作的方式,操作系统没有必要分配k个连续的物理内存页面。==页面可以随机地分散在物理内存中==。
虚拟地址对内存的保护
计算机系统必须为操作系统提供手段来控制对内存系统的访问。
- 不应该允许一个用户进程修改它的只读代码段。
- 不应该允许它读或修改任何内核中的代码和数据结构。
- 不应该允许它读或者写其他进程的私有内存
- 不允许它修改任何与其他进程共享的虚拟页面
除非所有的共享者都显式地允许它这么做
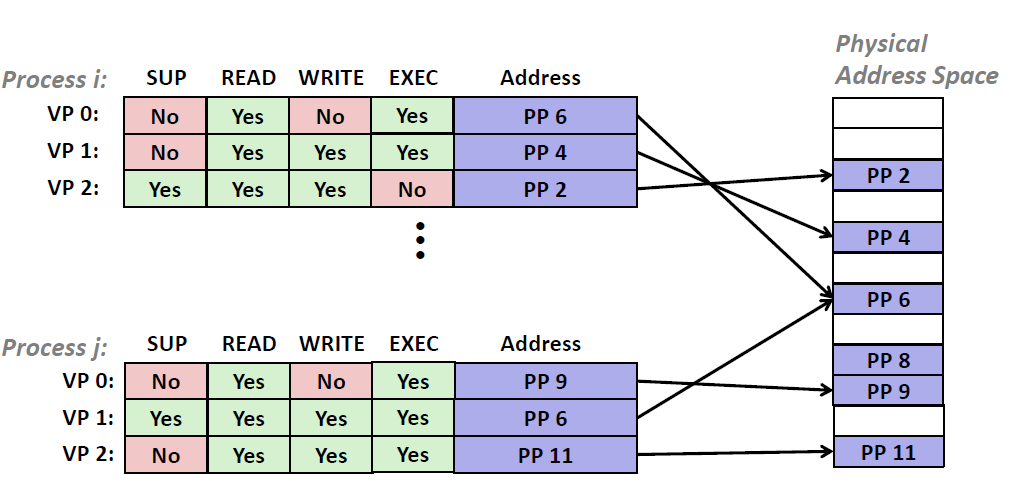
而提供独立的地址空间使得区分不同进程的私有内存变得容易 ,我们可以通过在PTE 上添加一些额外的许可位来控制对一个虚拟页面内容的读取、改写和运行之类的权限。
Address translation
现在我们来谈谈地址翻译的基础知识,为了让我们了解硬件在支持虚拟内存中的角色
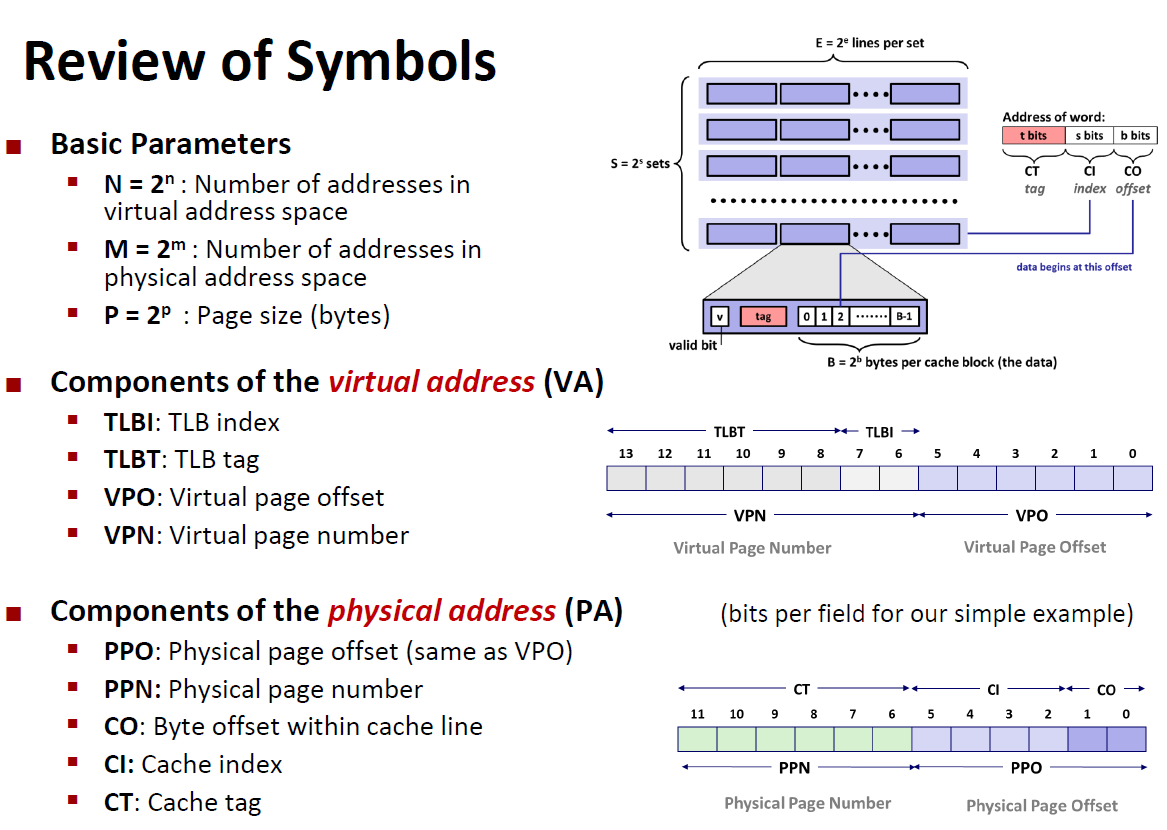
下面概括了我们在这节里将要使用的所有符号

形式上来说,地址翻译是一个 $N$ 元素的虚拟地址空间$(VAS)$中的元素和一个M元素的物理地址空间 $(PAS)$ 中元素之间的映射 : $MAP:VAS\rightarrow PAS \cup \emptyset$
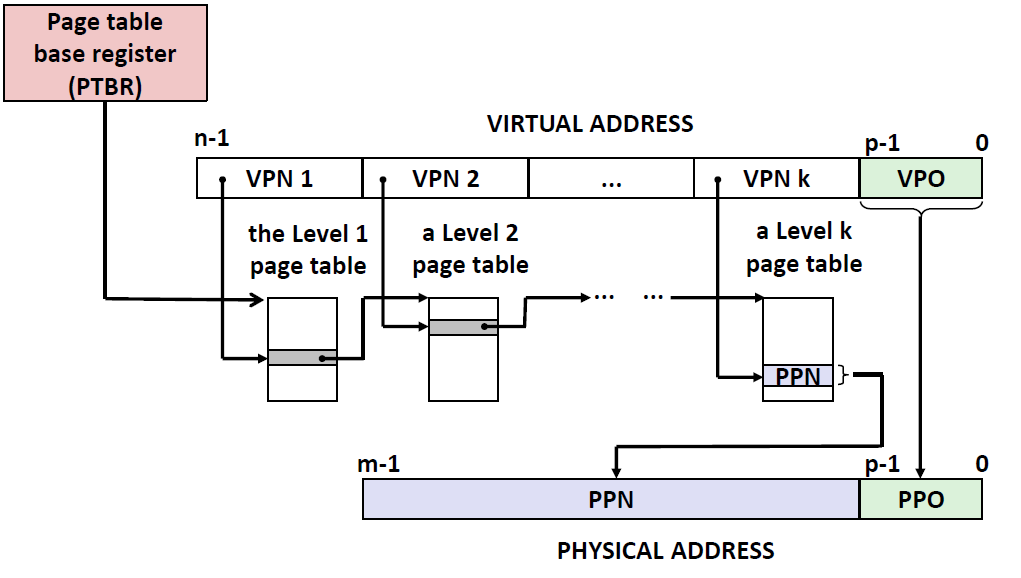
下面这张图展示了MMU如何利用页表来实现上述的映射。CPU中的一个控制寄存器,页表基址寄存器(Page Table Base Register,RTBR)指向当前的页表。 n位的虚拟地址包含两个部分: 一个p位的虚拟页面偏移量(Virtual Page Offset,VPO),p是由page的大小决定的,$P=2^p$(比如page的大小为64bytes,那么$P=2^6$,那么p就有6位)和一个*(n-p)位的虚拟页号(Virtual Number Page,VPN)
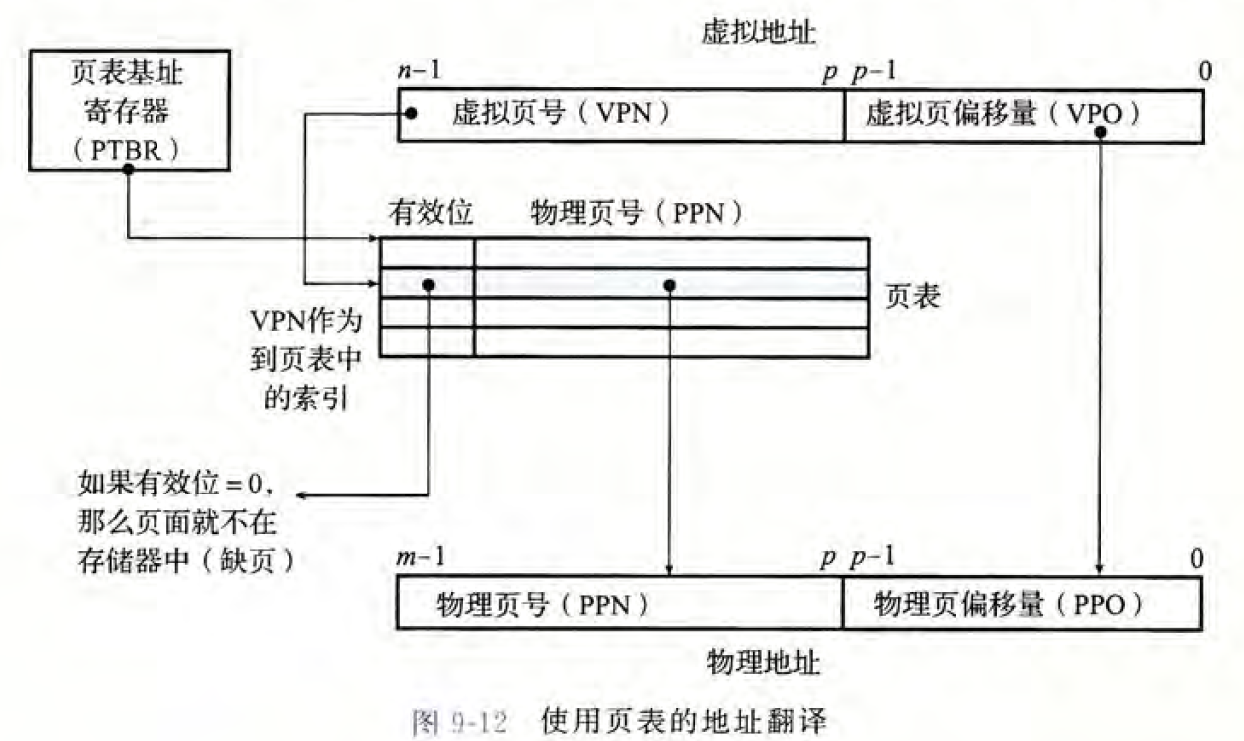
MMU 利用 VPN 来选择适当的PTE。例如,VPN0 选择PTE0 ; VPN1选择PTE1.以此类推。
将页表条目中物理页号(Physical Page Number, PPN)和虚拟地址中的VPO 串联起来,就得到相应的物理地址。注意,因为物理和虚拟页面都是P 字节的,所以物理页面偏移(Physical Page Offset, PPO)和VPO 是相同的。
Address Translation : Page Hit
当页命中的时候,CPU硬件执行的步骤:
- 第一步:处理器生成一个虚拟地址(VA),并把它传送给MMU
- 第二步:MMU 生成 PTE 地址 (PTEA),并从Cache/Main memory 请求得到它
- 第三步:高速缓存/主存 向MMU返回PTE
- 第四步:MMU构造物理地址,并把它传送给高速缓存/主存
- 第五步:高速缓存/主存返回所请求的数据给处理器
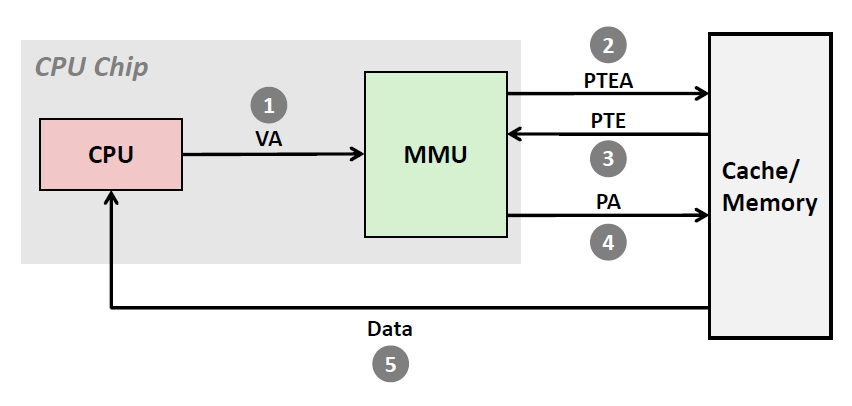
我们要注意到MMU是在Cache 之前的!
Address Translation :Page Fault
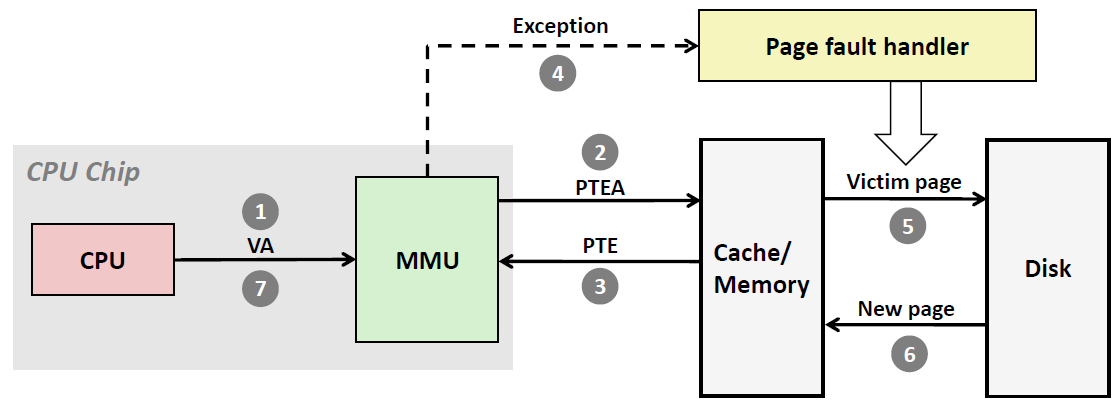
和页命中时完全由硬件处理不同,当缺页时,要求硬件和操作系统内核(Kernel)共同完成,如下图所示。
- 第一步:处理器生成一个虚拟地址(VA),并把它传送给MMU
- 第二步:MMU 生成 PTE 地址 (PTEA),并从Cache/Main memory 请求得到它
- 第三步:高速缓存/主存 向MMU返回PTE
- 第四步:发现PTE的有效位是0,说明缺页了。这时MMU触发了一次异常,传递了CPU中的控制到操作系统内核中的缺页异常处理程序
- 第五步:缺页处理程序确定出物理内存中的牺牲页,如果这个页面已经被修改了,则将其换出到磁盘。(回写)
- 第六步:缺页处理程序页面从磁盘中调取新的页面到Cache/Main Memory,并更新内存中的PTE
- 第七步:缺页处理程序返回到原来的进程,再次执行导致缺页的指令。CPU 将引起缺页的虚拟地址重新发送给MMU。
因为虚拟页面现在缓存在物理内存中,所以就会命中,在MMU 执行了页命中情况的几个步骤之后,主存就会将所请求字返回给处理器
结合Cache和VM
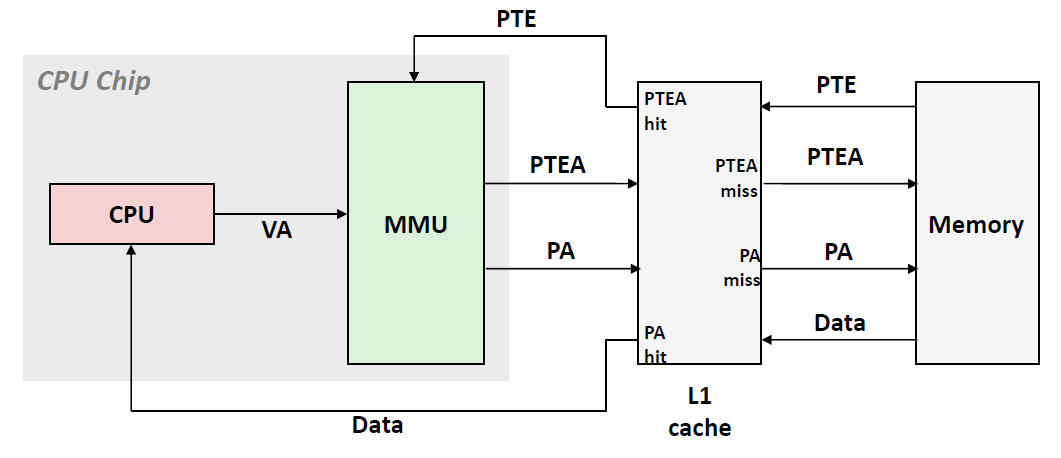
现在我们把Cache 和Memory拆开来,看看整一个取数据的逻辑:
首先我们要知道Page Table也有可能存放在L1 Cache当中的。因此从MMU出来的 PTEA首先会在L1 Cache中查找。
- 如果命中了,那么就从Cache返回PTE到MMU,然后MMU再生成物理地址去Cache中请求数据
- 如果Cache中有数据,那么Cache会返回数据给CPU
- 如果Cache中没有数据,那么就会跟着物理地址去内存中查找
- 如果未命中,那么就跑到主存中的页表当中去查找,然后的处理逻辑和上面所说的相同
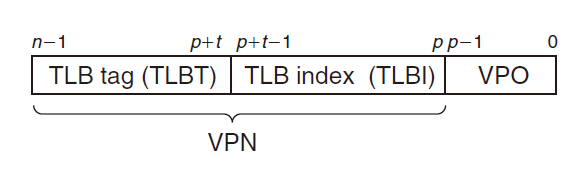
TLB(Translation Lookaside Buffer)
虽然说之前的查询,如果PTE在L1中,开销只要1-2个周期;如果在内存中则要几十上百个周期,已经是比较快了,但是很多系统还是不满意,希望消除这样的开销。于是,他是在MMU中放置了一个关于PTE的小缓存,我们称其为TLB
TLB是一个虚拟寻址的缓存,其中每一行都保存着一个由单个PTE组成的块。TLB通常有着高度的相联度。
用于组选择和行匹配的索引和标记字段是从虚拟地址中的虚拟页号(VPN)中提取出来的。如下图所示。如果TLB有 $T=2^t$个组,那么TLB索引(TLBI)是由VPN的t个最低位组成的,而TLB标记(TLBT)是由VPN剩余位组成的
TLB Hit
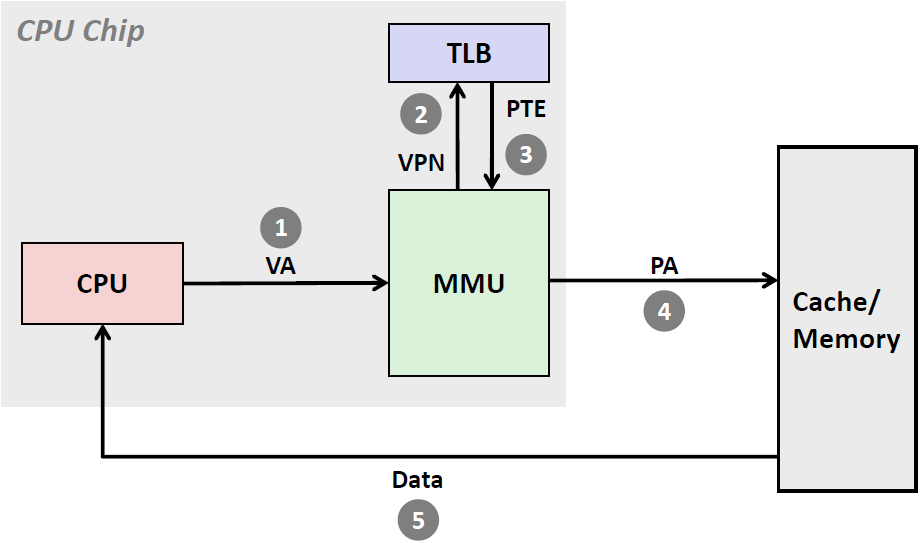
下图展示了当TLB 命中时(通常情况)所包括的步骤。这里的关键点是,所有的地址翻译步骤都是在芯片上的MMU 中执行的,因此非常快
第1 步:CPU 产生一个虚拟地址。
第2 步和第3 步:MMU拿着VPN去TLB中找,并从TLB 中取出相应的PTE。注意,这个查询速度是非常快的。因为有很多晶体管并行查询,时间接近于O(1)
第4 步:MMU 将这个虚拟地址翻译成一个物理地址,并且将它发送到高速缓存/主存。
第5 步:高速缓存/主存将所请求的数据字返回给CPU
TLB miss
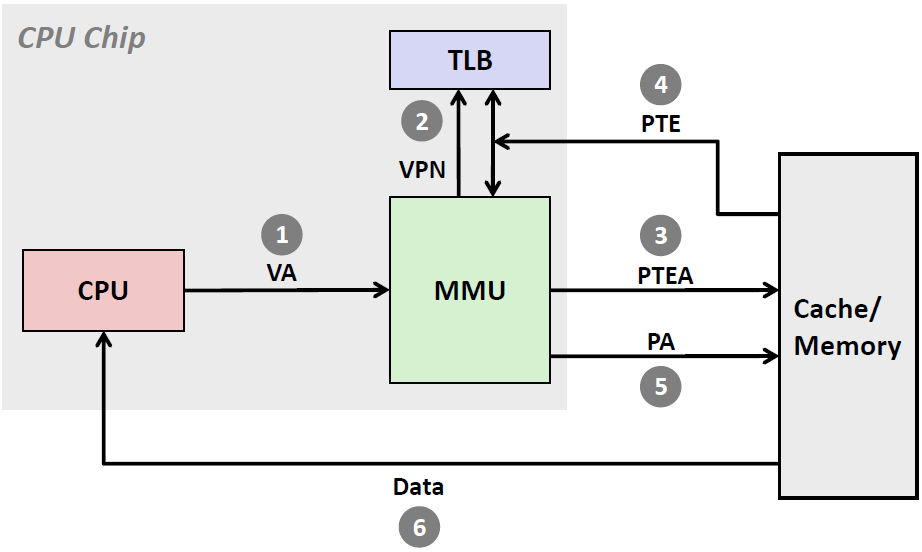
当TLB 不命中时,MMU 必须从L1 缓存中取出相应的PTE, 如下图所示。新取出的PTE 存放在TLB 中,可能会覆盖一个已经存在的条目。
Multi-Level Page Tables
假设我们的电脑是48位的,每个PTE大小是8 byte,每个页的大小是4kb,那么如果将这些PTE全放到一个page table当中的话,我们就需要 $2^{48}\cdot 2^{-12}\cdot 2^3 = 2^{39}$ bytes 也就是一张512GB的大表,而这张大表有很多的PTE为空,造成了很大浪费。因此仅创建一张页表显然是不现实的。所以我们采用了另一个方案:多层页表
为了简便,我们这里以二层页表为例:第一层页表中存放的PTE指向的是第二层的某一张页表,而第二层中存放的PTE则是指向内存当中的页
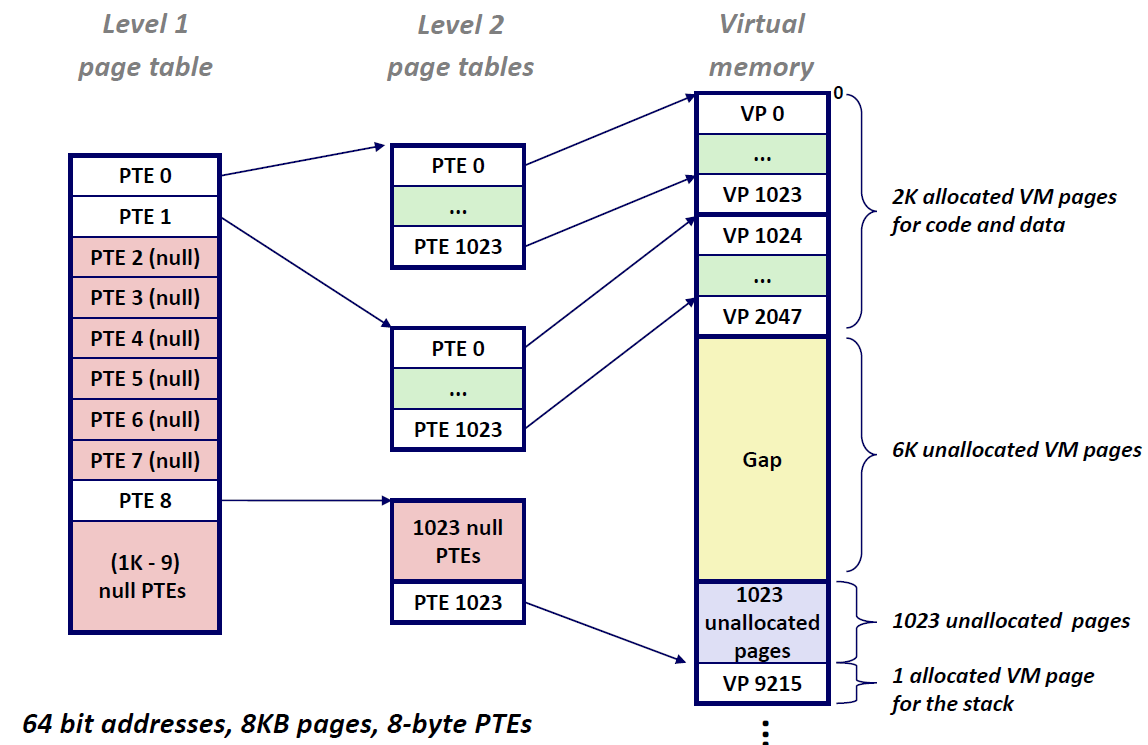
因为第一层很多PTE是空的,那么它们就不会指向一个页表,因此不用为其分配空间,因此节省下了不少内存。事实上,计算机采用的是多层页表,也就是说仅仅双层列表还是不够的。
Translating with a k-level Page Table
这是一个多级列表的示意图,只要最终找到了PPN,那么这一路页表都必须存在。此外,每一层都能节省下一定的空间,最后就能达到一个比较高效的、又体积比较小的方案。
地址翻译总结
例题
首先我们拿到的信息有3点
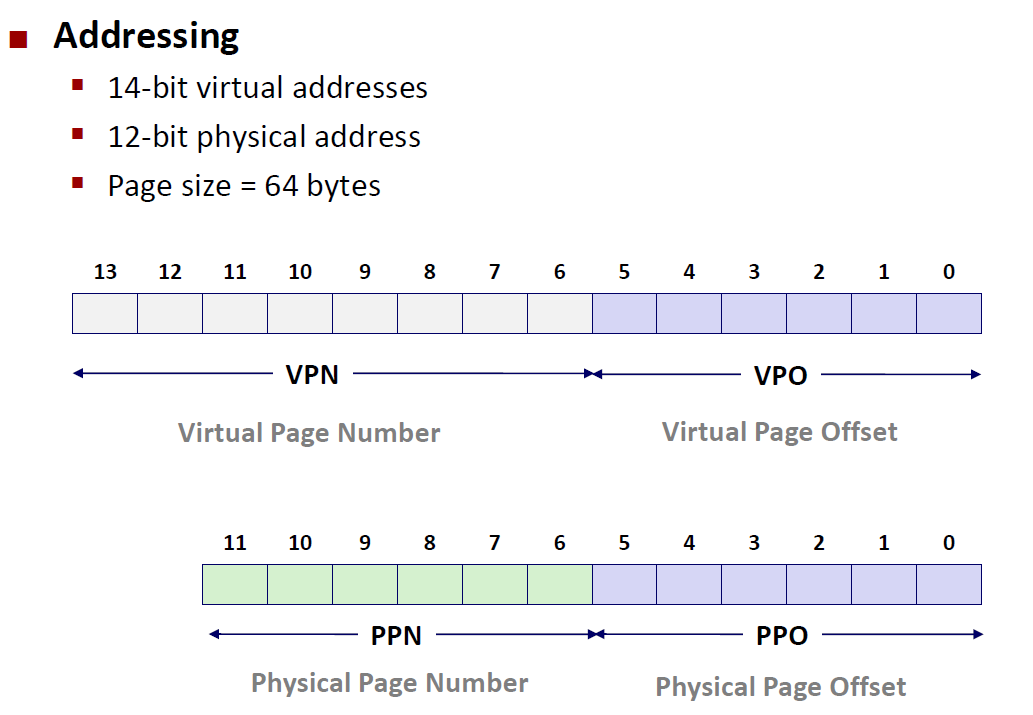
- 虚拟地址是14位的
- 物理地址是12位的
- 页的大小是64个bytes,也就是 $P= 2^6$ 因此 $p=6$ ,这点非常重要,因为p的大小即是 VPO和PPO的位数,因此我们可以在上图画出VPO、PPO所占的位置和PPN(12-6 = 6 位),VPN(14-6=8位)
现在有一个虚拟地址 : $00001101101001$ ,我们就知道它的VPN为 $00001101$ ,其VPO为$101001$
根据查找顺序,接下来应该是去TLB当中查找,因此我们还要再VPN的基础上求出TLBT和TLBI。TLBT是标签,TLBI是用于定位的,我们需要现根据TLB的组数来确定TLBI有几位,然后再将剩余位设置成TLBT
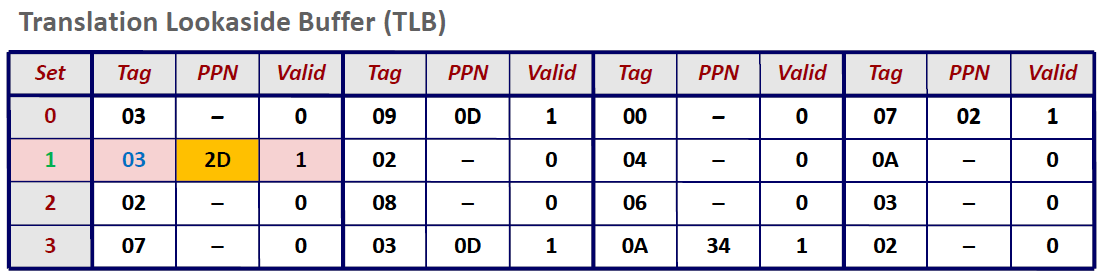
我们看到,TLB一共有$4 = 2^2$ 组。因此TLBI为2位,TLBT位6位,因此真个虚拟地址可以做如下划分:
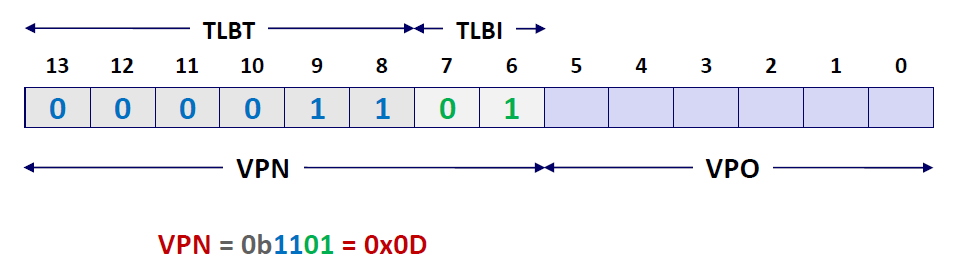
那么根据TLBI我们先定位到set1,然后再根据TLBT(0x03)进行匹配,发现valid位为1,匹配成功,于是我们可以从TLB中取出这个虚拟地址对应的PPN = 2D
我们知道物理地址是由PPN和PPO组成的,而PPO和VPO又是一模一样的,因此物理地址即可翻译出来:这里要注意,因为PPN只有6位,所以0x2d要写成0b101101(二进制)
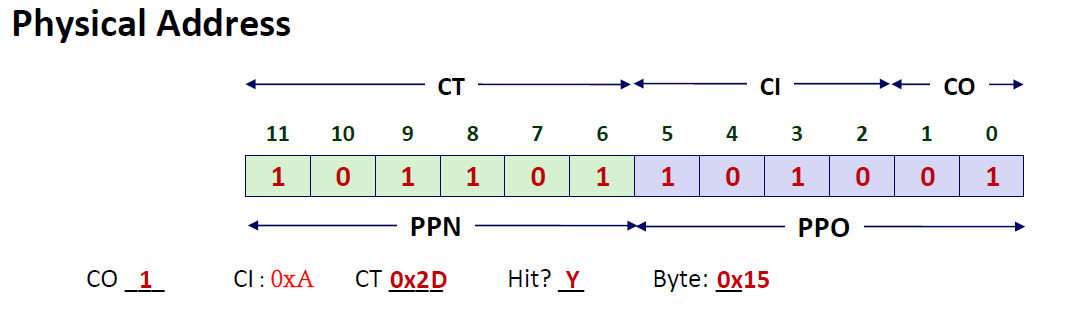
有了物理地址,我们就可以去Cache当中找数据了。那么我们首先看一下这个cache的结构,然后再来将物理地址分为Tag、Index和Offset3个部分
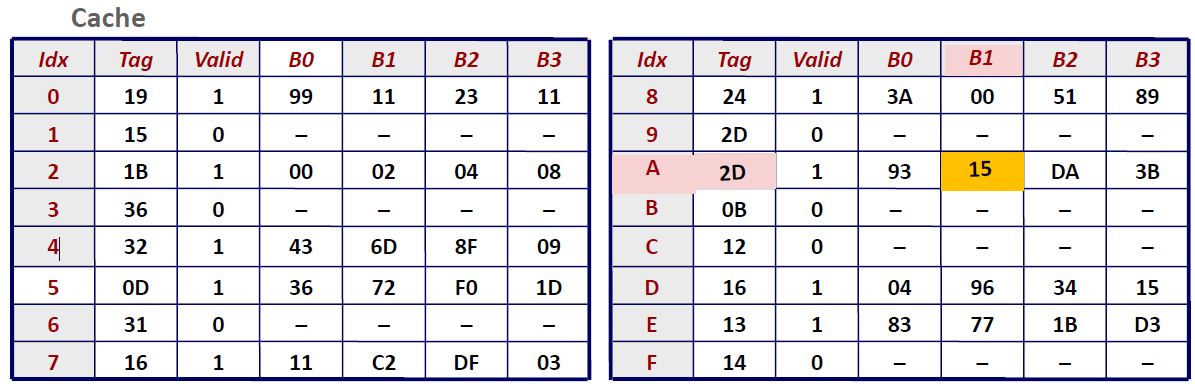
我们发现这个Cache一共有$16=2^4$组,那么我们就需要用4位来表示 Cache Index也就是CI,又因为每一组set中,有 $4 = 2^2$个block,因此Cache Offset 需要分配2位,剩下的就是 Cache Tag了。因此在物理内存中的划分如上图所示。
在Cache中查找数据的时候,首先要查Index,这里是0xA; 找到以后匹配Tag,这里是0x2D,发现匹配上了; 并且Valid bit = 1 。所以这是一个典型的Cache hit.我们根据offset = 1来锁定最终取到的数据为 0x15
Memory Mapping
Linux 通过将一个虚拟内存区域与一个磁盘上的对象(object)关联起来,以初始化这个虚拟内存区域的内容,这个过程称为内存映射(memory mapping)。有了内存映射,我们就只要访问像访问内存一样访问磁盘上的对象,而不需要用fopen ,fclose 这些函数去访问了。
虚拟内存可以映射到两种类型的对象:Linux文件系统中的普通文件 和 匿名文件 。
Linux文件系统中的普通文件
一个区域可以映射到一个普通磁盘文件的连续部分,例如一个可执行目标文件。
匿名文件
匿名文件是由内核 (kernel) 创建的,包含的全是二进制0.
CPU 第一次引用这样一个区域内的虚拟页面时,内核就在物理内存中找到一个合适的牺牲页面,如果该页面被修改过,就将这个页面换出来,用二进制零覆盖牺牲页面并更新页表,将这个页面标记为是驻留在内存中的。注意在磁盘和内存之间并没有实际的数据传送。
==这两类文件的区别和应用场景还没有搞明白==
无论在哪种情况中旦一个虚拟页面被初始化了,它就在一个由内核维护的专门的交换文件(swap file)之间换来换去。交换文件也叫做交换空间(swap space)或者交换区域 (swap area)
共享对象
内存映射给我们提供了一种清晰的机制,用来控制多个进程如何共享对象。
一个对象可以被映射到虚拟内存的一个区域,要么作为共享对象,要么作为私有对象。
共享对象:
如果一个进程将一个共享对象映射到它的虚拟地址空间的一个区域内,那么这个进程对这个区域的任何写操作,对其他进程而言(映射了这个共享对象的)也是可见的。而且,这些变化也会反映在磁盘上的原始对象中
私有对象 :
对其它进程来说不可见而且进程对这个区域所做的任何写操作都不会反映在磁盘上的对象当中。
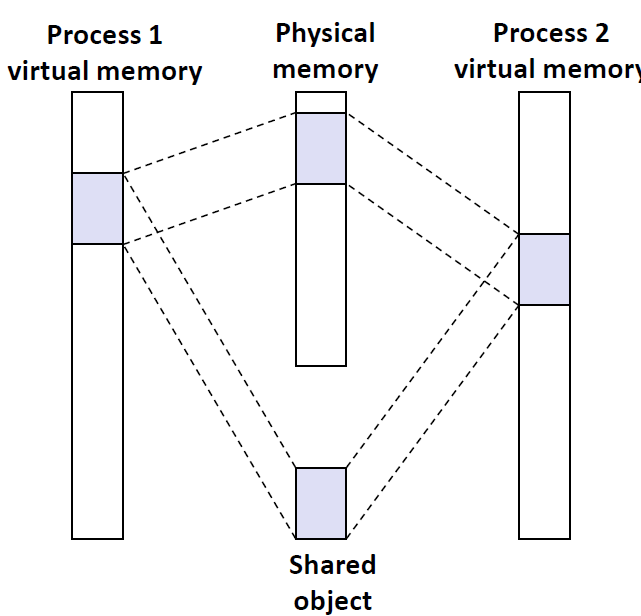
关键点在于即使对象被映射到了多个共享区域,物理内存中也只需要存放共享对象的一个副本,而这个对象在不同的进程当中所处的虚拟地址是不一样的。
Copy-On-Write
私有对象在被映射到虚拟内存的时候会使用一种Copy-On-Write的技术。因为私有对象要满足在被修改时对其它进程来说不可见、磁盘上的文件也不会进行改变的要求。Copy-On-Write顾名思义就是在写的时候复制。
其核心思想是,如果有多个调用者(callers)同时要求相同资源(如内存或磁盘上的数据存储),他们会共同获取相同的指针指向相同的资源,直到某个调用者试图修改资源的内容时,系统才会真正复制一份专用副本(private copy)给该调用者,而其他调用者所见到的最初的资源仍然保持不变。这过程对其他的调用者都是透明的(transparently)
对于每个映射私有对象的进程,相应私有区域的页表条目都被标记为只读,且物理内存上的页这时候被标记成了(Private copy-on-write), 当进程2要修改原来的对象的时候,会触发一个保护故障,这时候保护故障程序就会在物理内存中创建这个页面的一个新副本,更新页表条目指向这个新的副本,然后恢复这个页面的可写权限,当故障处理程序返回时,CPU 重新执行这个写操作,现在在新创建的页面上这个写操作就可以正常执行了。如下图所示
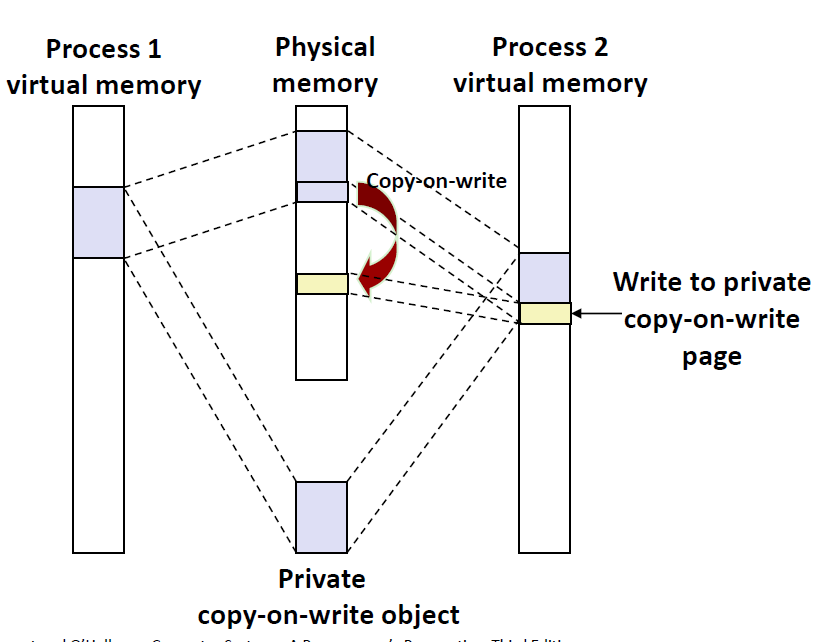
也就是说,读的时候大家可以一起读,只有在写的时候(迫不得已),才进行一个拷贝。是一种 Lazy Copy的模式。
这样做的好处是加快启动进程,加快相应时间。因为读取很快,但是写很慢,因此每次写只拷贝要写的那几个page。
使用 mmap 函数的用户级内存映射
Linux 进程可以使用 mmap函数来创建新的虚拟内存区域,并将对象映射到这些区域中。
1 |
|
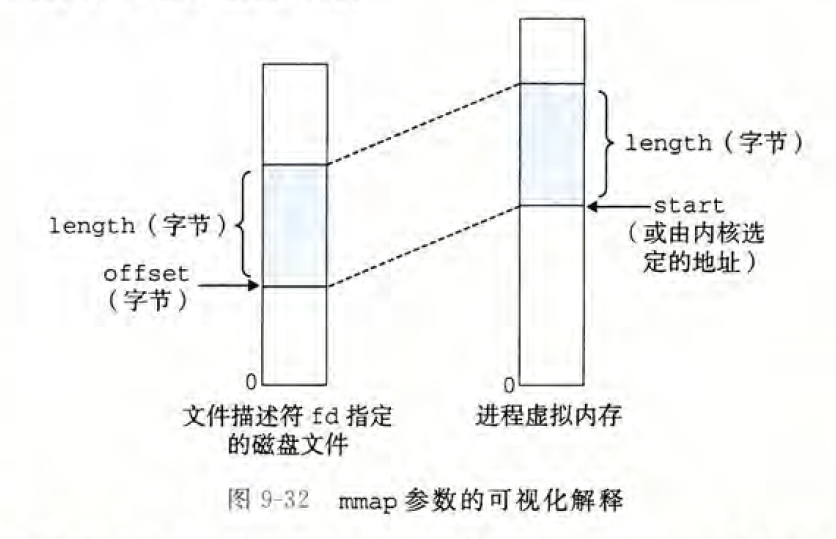
mmap 函数要求内核创建一个新的虚拟内存区域,最好是从地址start 开始的一个区域,并将文件描述符fd 指定的对象的一个连续的(chunk)映射到这个新的区域。
连续的对象片大小为length 字节,从距文件开始处偏移量为offset 字节的地方开始。start地址仅仅是一个暗示,通常被定义为NULL.
因为mmap的返回值是一个指针,这个指针并没有规定数据类型。我们就可以通过这个指针来访问磁盘上的文件,我访问、修改的所有东西可以在磁盘当中进行同步。
mmap的 用处
- 读取大文件
- mmap可以使用分页机制将文件放入内存中
- 共享数据结构
- When call with MAP_SHARED flag
- Multiple processes have access to same region of memory
- Risky!
- When call with MAP_SHARED flag
- File-based data structures
- E.g., database
- Give protargument PROT_READ | PROT_WRITE
- When unmap region, file will be updated via write-back
- Can implement load from file / update / write back to file