异常控制流(ECF)1
控制流
首先我们要了解控制流的概念,从给处理器加点到断电为止,程序计数器假设一个值得序列如下:
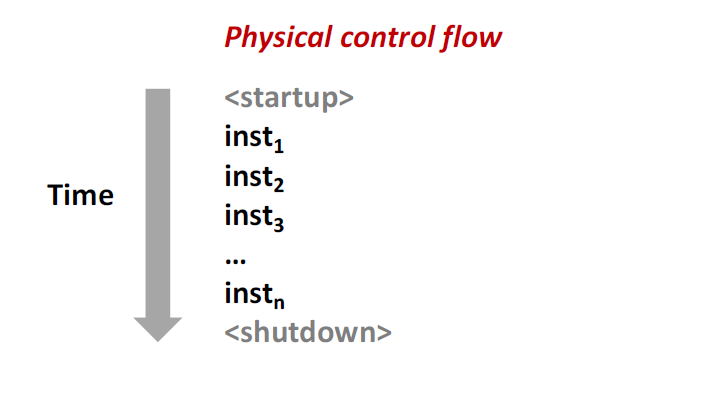
其中 $inst_k$ 代表着一条条指令。每次从 $inst_1$ 到 $inst_2$ 的过渡被称为控制转移。这样的控制转移序列叫做处理器的控制流。
更改控制流
我们知道,进程有三个状态,running(拿到CPU并运行),waiting(在等一个事件发生,在这个事件没有发生之前即使拿到了CPU也做不了事),ready(已就绪,但是还没拿到CPU,等拿到了立即可以执行)
当哪些事件发生的时候系统会更改控制流呢?
two mechanisms for changing control flow
- Jump and branches
- Call and return
Insufficient for a useful system
- Data arrives from a disk or a network adapter
- 当磁盘或者网络的数据到达的时候,系统会发出一个事件,代表数据传输完成。这时候从waiting进入到ready状态。这时候就需要操作系统中的代码来做。操作系统会把一个队列移动到另一个队列去,特别是这个进程优先级很高,我们甚至要直接把现在在running的进程拉下来然后把这个进程直接拿到CPU去运行
- Instruction divides by zero
- 代码除以0了。这也需要操作系统来做。
- User hits Ctrl-C at the key board
- 按Ctrl-C 退出程序。这时候也是操作系统来执行的
- System timer expires
- 如果一个操作系统很多人在运行,那么操作系统会让每个人轮流运行一段时长。时间一到操作系统会把当前执行的挂起,状态设置为ready,然后把下一个进程放到CPU当中去
因此,系统需要一个 ECF的机制,也就是异常控制流来对这些变化做出反应。
异常控制流
在异常发生的时候,很多时候要执行的代码并不是用户写的,而是操作系统写的。这些操作系统执行的代码块就放置在地址空间中的Kernel code and data 层里面,如下图所示:
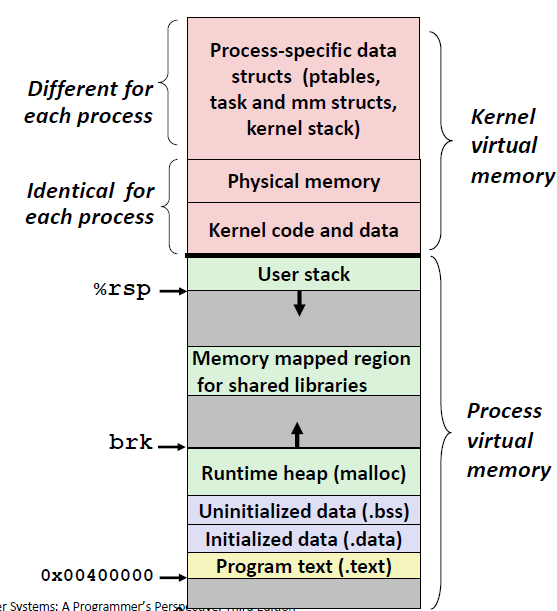
异常控制流在计算机系统的各个层级都有涉及。
底层
Exceptions
Change in control flow in response to a system event
implemented using combination of hardware and OS software
在操作系统层面是比较底层的Exception(也叫interruption),这时候需要硬件和软件来共同完成。
高层
在操作系统层面以上的,一共有三种
- Process context switch
一个进程在运行过程中的状态被称为context。 那么当状态切换的时候,就是context switch。再说得简单一点,就是进程切换
context switch要做这样一些工作:
- 保留寄存器(包括栈顶指针)
- 状态字需要保留
- pc要保留,并指向新的进程开始的第一条指令
- Signals - Implemented by OS software
一个进程可以主动的发一个signal,比如说 kill 指令可以杀死一个进程;或者yield指令,可以将CPU让出来让别人用;sleep指令可以先睡眠,过一会再回来运行
- Nonlocal jumps:setjump() 和 longjmp()
跳到很远的地方去执行
异常
异常(exception)就是控制流中的突变,用来响应处理器状态中的某些变化。
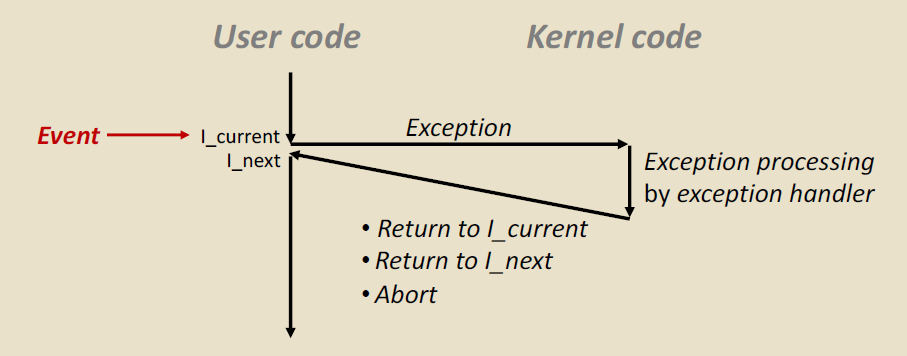
异常处理
在这张图中,当处理器状态中发生一个重要变化的时候,处理器正在处理 $I_{current}$ 。在处理器中,状态被编码为不同的位和信号。状态变化称为 event(事件)。
事件可能和当前指令的执行直接相关。比如发生内存缺页、算术溢出、或者一条指令试图除以0等等。
另一方面,事件也可能和当前指令的执行没有关系,比如一个系统定时器产生信号或者一个I/O请求完成
在任何情况下,当处理器检测到有事件发生的时候,它就会通过一张 异常表 的跳转表来跳到一个专门设计用来处理这类事件的操作系统子程序。

当异常处理程序完成处理后,根据引起的异常的事件的类型,会发生一下三种情况:
- 处理程序将控制返回给当前指令 $I_{curr}$ ,即当事件发生的时候正在执行的指令。比如说缺页 page fault
- 处理程序将控制返回给 $I_{next}$,如果没有异常将会执行下一条指令。比如说 arithmetic overflow 溢出了
- 处理程序终止被中断的程序。比如说 ctrl+c
异常类别
首先我们要了解同步和异步的概念。
同步代表着我必须马上回应出现的异常,处理完才能进行下一步操作。异步则代表我可以先执行其他操作,让系统去处理这个异常,等处理完后再回来也可以。
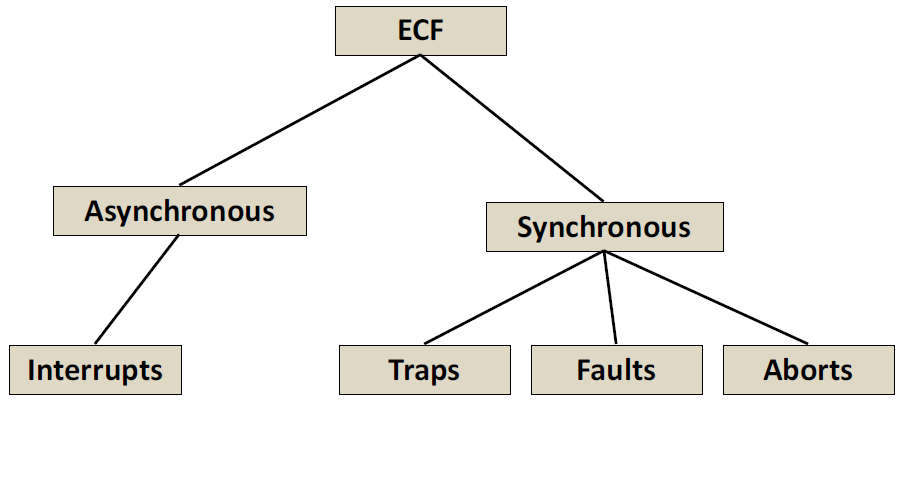

Interrupts(中断)
中断时异步发生的,这是来自处理器外部 的I/O设备信号的结果。硬件中断并不是由任何一条专门的指令造成的,从这个意义上说他是异步的。
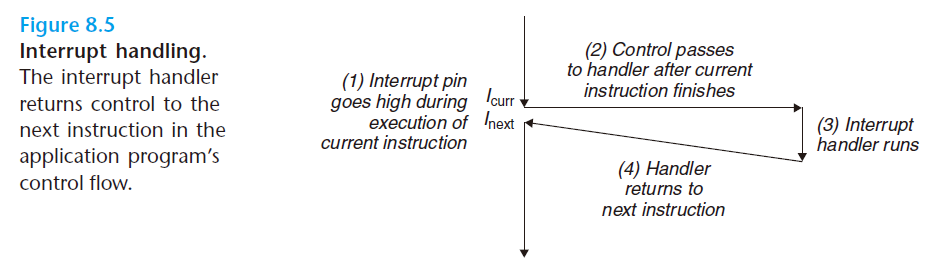
当处理程序返回时,它就将控制返回给下一条指令(也即如果没有发生中断,在控制流中会在当前指令之后的那条指令)。结果是程序继续执行,就好像没有发生过一样
比如说:Timer interrupt,这个意思是说我的时钟周期到了,不给我用了,系统强制把我的进程中断,执行其他进程。
又比如说外部的I/O设备中断,比如我按下 Ctrl-C,直接退出进程;网络或者磁盘上的数据到了,那么这个时候就会去执行其他进程
Trap(陷阱)
陷阱是有意的异常,是执行一条指令的结果。就像中断处理程序一样,陷阱处理程序将控制返回到下一条指令。陷阱最重要的用途是在用户程序和内核之间提供一个像过程一样的接口,叫做系统调用。
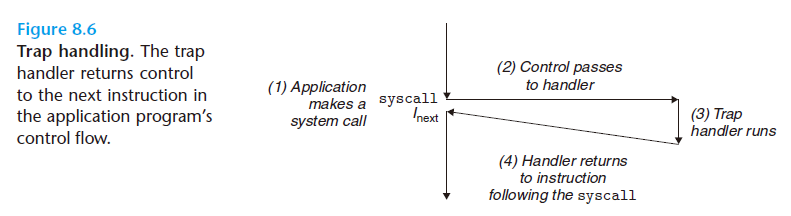
用户程序经常需要向内核请求服务,比如读一个文件(read)、创建一个新的进程(fork) 加载一个新的程序(execve),或者终止当前进程(exit)。为了允许对这些内核服务的受控的访问,处理器提供了一条特殊的syscall n指令,当用户程序想要请求服务n时,可以执行这条指令。执行syscall指令会导致一个到异常处理程序的陷阱, 这个处理程序解析参数,并调用适当的内核程序。
比如说我们在用 gdb调试的时候设置的breakpoints
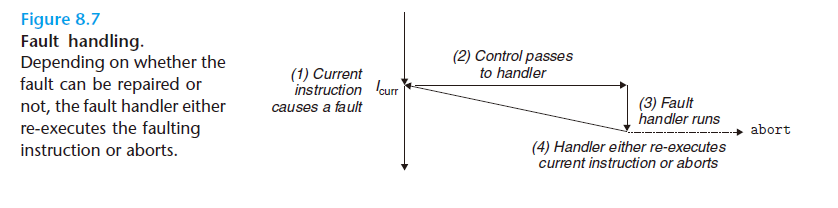
Fault
故障由错误情况引起,它可能能够被故障处理程序修正。当故障发生时,处理器将控制转移给故障处理程序。如果处理程序能够修正这个错误情况,它就将控制返回到引起故障的指令,从而重新执行它。否则,处理程序返回到内核中的abort 例程,abort 例程会终止引起故障的应用程序
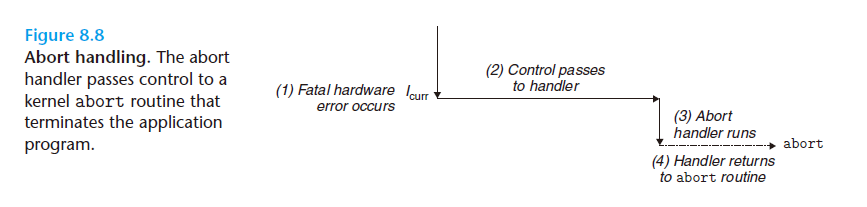
Aborts(终止)
终止是不可恢复的致命错误造成的结果,通常是一些硬件错误,比如DRAM 或者 SRAM 位被损坏时发生的奇偶错误。终止处理程序从不将控制返回给应用程序。
Linux/x86-64 系统中的异常
x86-64 系统定义了256种不同的异常类型。
x86-64 的故障与终止
除法错误。当应用试图除以零时,或者当一个除法指令的结果对于目标操作数来说太大了的时候,就会发生除法错误(异常0)。Unix 不会试图从除法错误中恢复,而是选择终止程序。Linux shell 通常会把除法错误报告为“浮点异常(Floatmg exception)”
一般保护故障。许多原因都会导致不为人知的一般保护故障(异常13),通常是因为一个程序引用了一个未定义的虚拟内存区域,或者因为程序试图写一个只读的文本段。Linux 不会尝试恢复这类故障。Linux shell 通常会把这种一般保护故障报告为“段故障(Segmentation fault)”
缺页(异常14)是会重新执行产生故障的指令的一个异常示例。处理程序将适当的磁盘上虚拟内存的一个页面映射到物理内存的一个页面,然后重新执行这条产生故障的指令。我们将在第9 章中看到缺页是如何工作的细节。
机器检查。机器检査(异常18)是在导致故障的指令执行中检测到致命的硬件错误时发生的。机器检査处理程序从不返回控制给应用程序。
x86-64 的系统调用
当我们system call的时候,汇编指令用的是 syscall,注意,这时候rsp并不是在用户栈里面,而会把栈指针指导Kernel里面去
进程
进程和线程的区别
进程:进程就是在运行中的程序。CPU在使用的时候都是以进程为单位的。
线程:随着我们的应用程序越来越复杂,我们希望CPU能处理一个程序的并行任务。也就是一个进程里面有多个指令执行的序列,这些序列可以是异步的。比如说把一个人比作一个进程,那么他可以学算法、可以学CSAPP、可以学音乐,这些科目就是线程,它们共享人的大脑、书包、宿舍(cache,memory等资源)
注意,当有多个线程的时候,每个线程的stack是不共享的,因为他们有不同的指令序列。
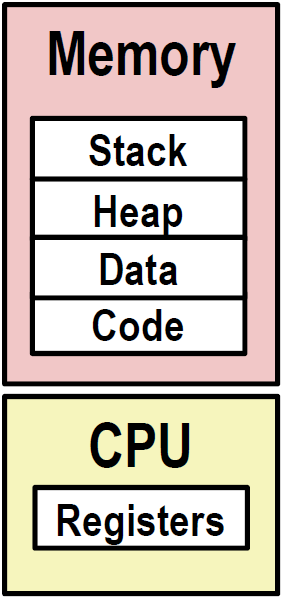
上下文:上下文是由程序正确运行所需的状态组成的。这个状态包括存放在内存中的程序的代码和数据,它的栈、通用目的寄存器的内容、程序计数器、环境变量以及 打开文件描述符的集合
每次用户通过向shell 输人一个可执行目标文件的名字,运行程序时,shell 就会创建一个新的进程,然后在这个新进程的上下文中运行这个可执行目标文件。应用程序也能够创建新进程,并且在这个新进程的上下文中运行它们自己的代码或其他应用程序。
在这一节,我们将关注进程提供给应用程序的关键抽象:
- Logical control flow:一个独立的逻辑控制流,它提供了一个假象,好像我们程序独占地使用处理器
- Private address space:一个私有的地址空间,它提供了一个假象,好像我们的程序独占地使用内存系统
逻辑控制流
multi-programming 多道程序,也就是是多个进程的意思。
multi-threading: 多线程
multi-tasking: 多任务,机器进行多项任务批处理,交互性差
multi-processing : 多任务处理
Time sharing(分时):将时间划分成时间片,进程按时间片轮流执行
Multi-programming(多道):系统中存在多个程序同时执行,增加CP的利用率。
区别:分时主要针对提高系统的响应速度,改善用户体验;多道主要针对增加系统的利用
multi-threading 和 multi-tasking 是一回事。
我们刚才说了进程会向每个人提供一种假象,好像它在独占地使用处理器。那么我们如果这时候去看PC(程序计数器)的值,就会发现这些值唯一地对应于包含在程序的可执行目标文件中的指令。这个PC值得序列就叫做逻辑控制流(简称逻辑流)
比如说下图,一个运行着三个进程的系统。处理器的一个物理控制流被分成了三个逻辑流,每个进程一个。 每个竖直的条表示一个进程的逻辑流的一部分。
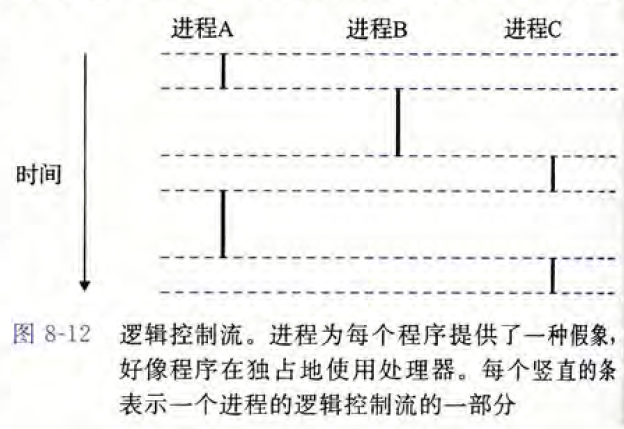
在这个例子中,三个逻辑流的执行是交错的。进程A运行了一会儿,然后是进程B开始运行到完成。然后,进程C运行了一会,进程A接着运行直到完成。最后进程C可以运行到结束了。
上图的关键点在于进程是轮流使用处理器的。每个进程执行它的流的一部分,然后被抢占(暂时挂起),然后轮到其他进程。对于一个运行在这些进程之一的上下文中的程序,它看上去就像是在独占地使用处理器。
但是如果我们精确地测量每条指令使用的时间,会发现在程序中一些指令的执行之间,CPU好像会周期性地停顿。但是这并不会改变程序内存位置或者寄存器的内容。
并发流
一个逻辑流的执行在时间上与另一个流重叠,称为并发流(concurrent flow),这两个流被称为并发地运行。
比如说流X和Y互相并发,当且仅当 (X在Y开始之后和Y结束之前开始|Y在X开始之后和X结束之前开始)
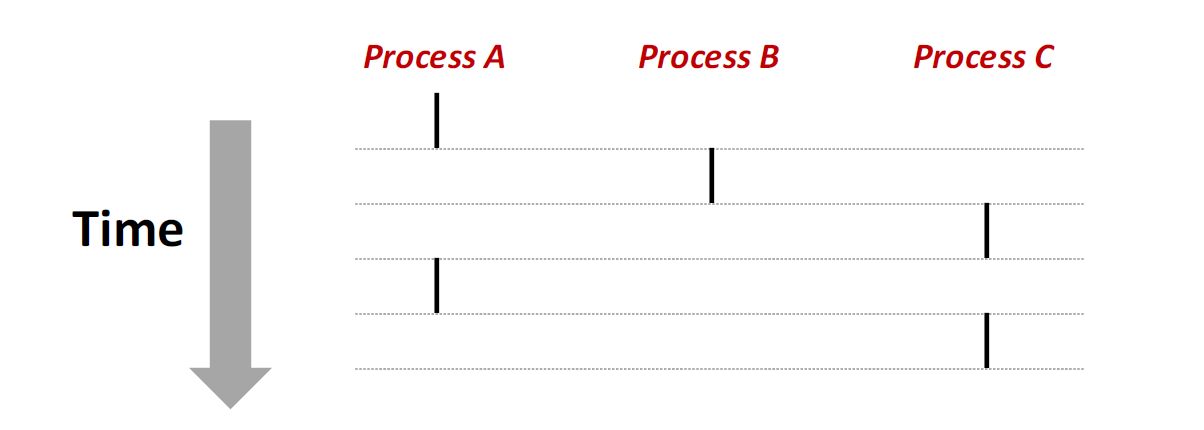
在这张图中,进程A和B并发地运行,A和C也是并发运行,但是B和C不是并发运行,因为B的最后一条指令在C的第一条指令之前执行
多个流并发地执行的一般现象被称为并发(concurrency)。一个进程和其他进程轮流运行的概念称为多任务(multitasking)。一个进程执行它的控制流的一部分的每一时间段叫做时间片(time slicing) 因此,多任务也叫做时间分片(time slicing).比如说上图,进程A的流是由两个时间片组成的。
但是在真正的执行过程中间,它们是不相交的,分离的。不过从用户的角度来看,并发地进程是相交的。因此在用户看来,三个进程是这样运行的。
私有地址空间
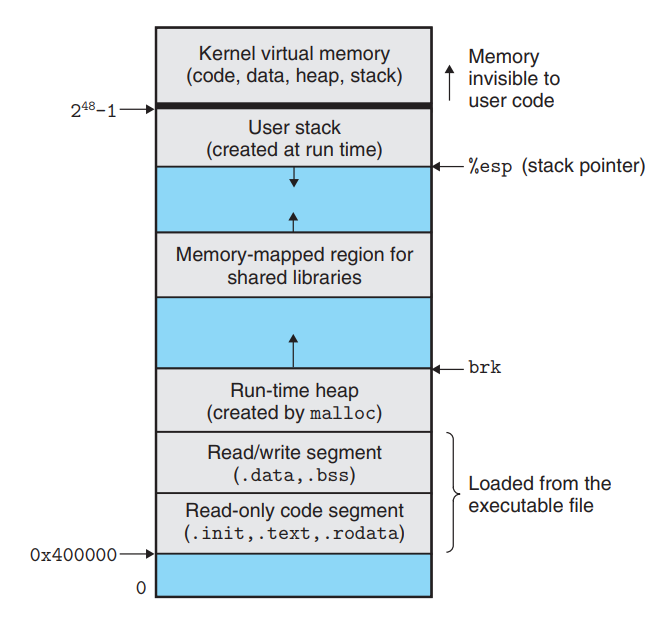
进程会为每个程序提供它自己的私有地址空间。一般而言,和这个空间中某个地址相关联的那个内存字节是不能被其他进程读或者写的,因此说这个地址空间是私有的。
每一个地址空间的组织结构都是类似的。
上下文切换
内核为每一个进程都维持一个上下文。上下文就是内核重新启动一个被抢占的进程所需的状态。
它由一些对象的值组成,这些对象包括通用目的寄存器、浮点寄存器、程序计数器、用户栈、状态寄存器、内核栈、各种内核数据结构(页表、进程表、文件表等)
在进程执行的某些时刻,内核可以决定抢占当前进程,并重新开始一个先前被抢占了的进程。这种决策就叫调度,是由内核中称为调度器的代码处理的。
在内核调度了一个新的进程运行后,它就抢占当前的进程,并使用一种称为上下文切换的机制来将控制转移到新的进程
上下文切换有三个步骤:
- 保存当前进程的上下文
- 恢复某个先前被抢占的进程被保存的上下文
- 将控制传递给这个新恢复的进程
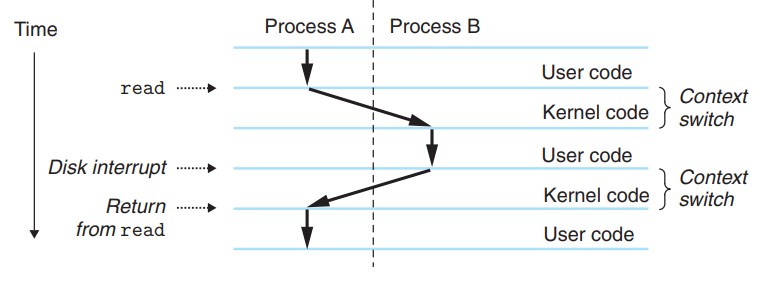
如上图所示,进程A进行了read的系统调用,此时内核不会只等待读取的完成而什么都不做,而是切换到进程B继续执行。磁盘发出中断信号表面数据以及存入内存中,此时内核又会切换回进程A,继续执行read后的指令。
进程控制
System Call Error Handling
在出现错误时,Linux系统级函数通常返回-1和设置全局变量errno来指示原因
比如说fork()函数,它是用来创建一个新进程的。如果它的pid小于0,就说明创建新进程失败了,因此我们需要报告并打印这个错误信息。
1 | if ((pid = fork()) < 0) { |
但是我们对每个错误都这样写的话,会非常麻烦而且容易出错,因此我们可以把这个函数封装一下。
1 | void unix_error(char *msg) /* Unix-style error */ |
这样以后,我只要 写一个unix_error函数,然后调用即可
Wrappers
1 | pid_t Fork(void) |
我们可以写得更有层次一点,将fork()函数封装在Fork()函数当中
这里我们再关注一下fork()函数,fork()是仅有的调用一次返回两次的函数。return的数值有两种情况,一种是return自己的 pid,另一种是return 子进程的 pid
Obtaining Process IDs
pid_t getpid(void) 这个函数返回当前进程的PID
pid_t getppid(void)这个函数返回父进程的PID
创建和终止进程
从一个程序员的角度,我们可以认为一个进程一定是这三个状态中的一个
Running:
Running 状态就是拿到CPU直接可以运行;也可以说是Ready,即现在还没拿到CPU,但是拿到CPU之后可以马上运行
Stopping:
进程的执行被挂起,处于等待状态。当收到 SIGSTOP、SIGTSTP、SIGTTIN或者SIGTTOU信号时,进程就会停止,并且保持停止到它收到一个SIGCONT信号,在这个时刻,进程再次开始运行
Terminated:
结束状态,但是分配给进程的资源还没有回收。这种状态也叫做Zombie ,也就是我们常说的僵尸进程。
Terminating
当发生以下三个情况的时候,进程就会被终止
- Receiving a signal whose default action is to terminate
- Returning from the main routine
- Calling the exit function
exit 函数 void exit(int status)
- Terminates with an exit status of status
- Convention: normal return status is 0,nonzero on error
- Another way to explicitly set the exit status is to return an integer value from the main routine
exit没有return,只有call。因此在exit()后面写代码是毫无意义的。
Creating Processes
当我们调用fork函数的时候,父进程会创造一个新的子进程
int fork(void) 的一些注意点
Returns 0 to the child process,child’s PID to parent process
- 即如果我拿到了一个PID,就说明我是父进程;如果我拿到了一个0,就说明我是一个子进程
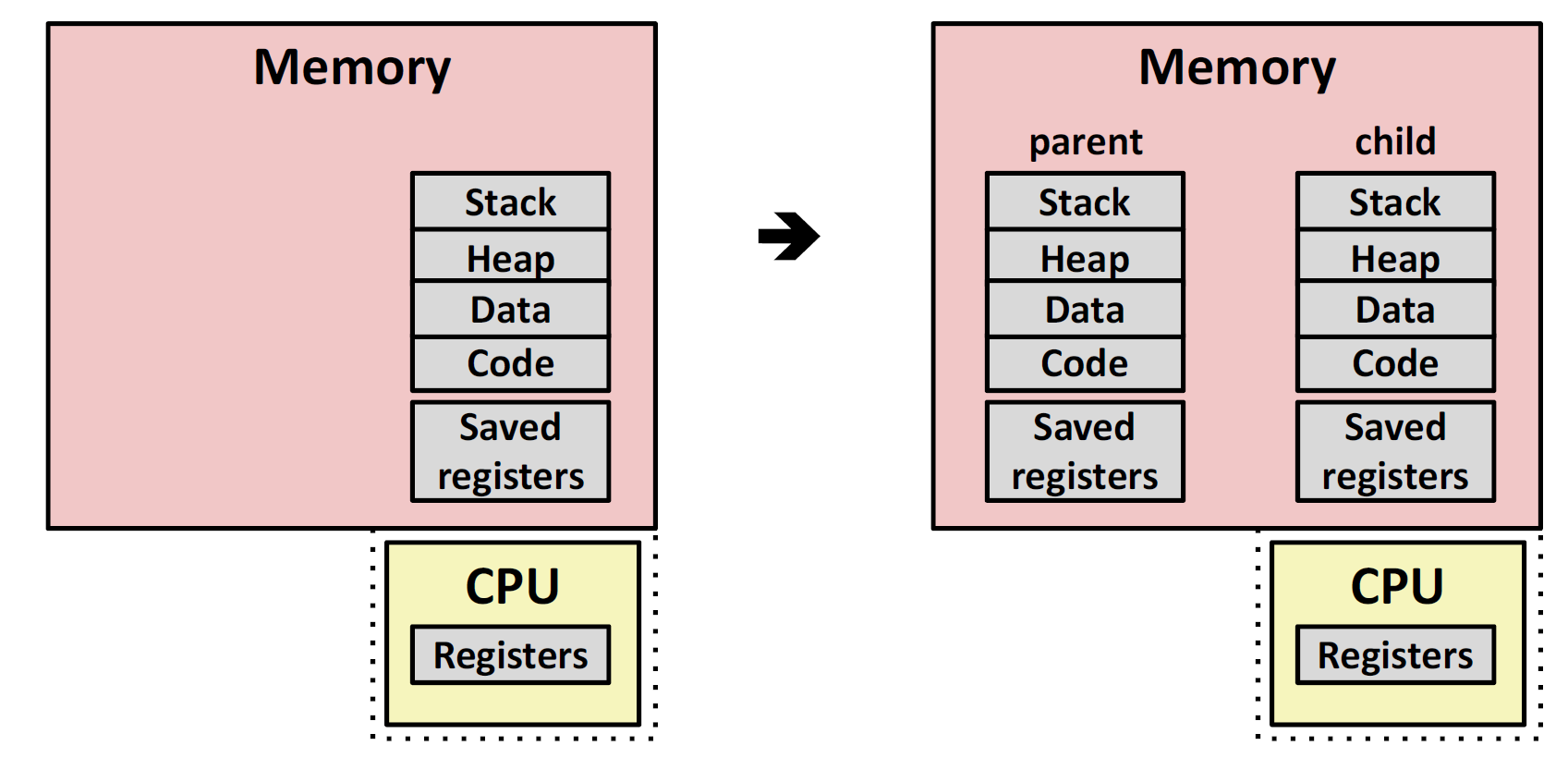
子进程和父进程基本是一样的:
- 子进程得到了一个和父进程一模一样的虚拟地址空间,连页表都是相等的。但是请注意,只是长得一样,他们的地址空间还是相互独立的,并不会因为子进程修改了某个值从而影响父进程中的值
- 子进程拿到的资源、打开文件的列表,也是和父进程一样的
- 只有PID和父进程是不一样的。
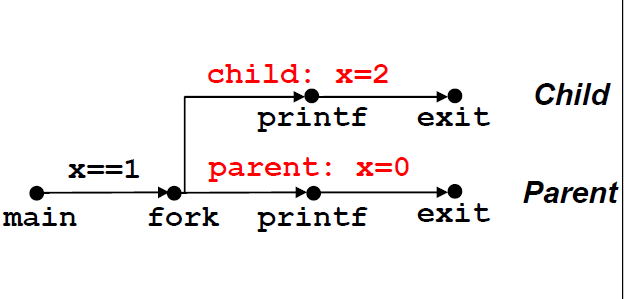
下面是一段fork的例子,当pid\=\=0,代表这是一个子进程,并++x; 否则就说明这是一个父进程,并—x。
请注意
- 父进程和子进程是并发运行的==父进程和子进程谁先拿到CPU是没有规定的==, 因此不能预测谁先回来谁后回来。
- Duplicate but separate address space.也就是我上面所说,修改父进程中的x是不会对子进程中的x造成影响的,反之亦然
- Shared open files,父进程打开的文件,子进程看到的话也是打开着的
1 | int main(int argc, char** argv) |

如果我们一定要某一个进程在另一个进程之后,我们可以这样来设计我们的程序。
1 | /* fork wrapper function */ |
Modeling fork with Process Graphs
我们可以针对fork之后的进程画一张进程图。流程图是捕获并发程序中语句的偏序关系的有用工具。
- 在这张图中每一个结点是我代码中的一条指令。
- $a\rightarrow b$ 代表着 a在b之前发生
- 边能够打标签,表示某一个变量的值
printf结点可以被标为 输出- 每张图最早的是由一个没有入读的结点开始的。
对于这张图,我们做拓扑排序。并且图的任何拓扑类型都对应于一个可行的总体排序
下面是一个例子:
1 | int main(int argc, char** argv) |
对于之前那个例子,我们画出流程图如下
此外,我们还可以画出更加抽象的 Relabled Graph , Feasible total ordering

小练习1
1 | void fork2() |
我们对这个程序画流程图,如下:
第一次是乘2,第二次对子进程和父进程同时乘2.因此会出来两个L1,4个Bye
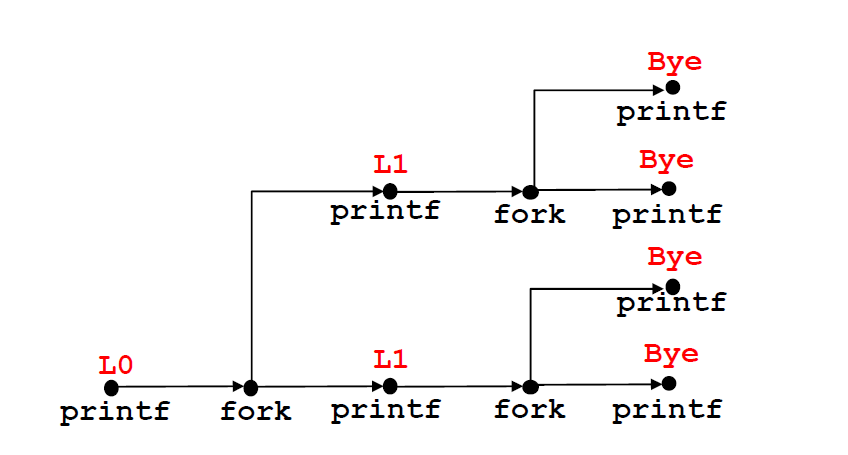
根据这幅图 我们可以得到一个可行的输出
$L0\rightarrow L1\rightarrow Bye\rightarrow Bye\rightarrow L1\rightarrow Bye\rightarrow Bye$
我们知道L1必定在两个Bye之前,但是这两个分支输出的顺序是不知道的。
小练习2
1 | void fork4() |
当代码中存在if 判断的时候,那么流程图又该怎么画?
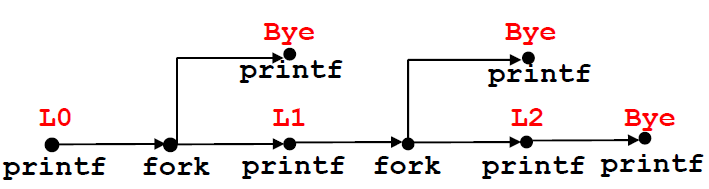
我们看到if的条件是 Fork()!=0 ,也就是必须是父进程才能进行L1和L2的输出,如果是子进程,那么会直接输出Bye
一个可能的答案是: $L0\rightarrow L1\rightarrow Bye\rightarrow Bye\rightarrow L2\rightarrow Bye$
小练习3
1 | void fork5() |
和练习2不同,这里是只有子进程能输出L1、L2,父进程是只能输出Bye的
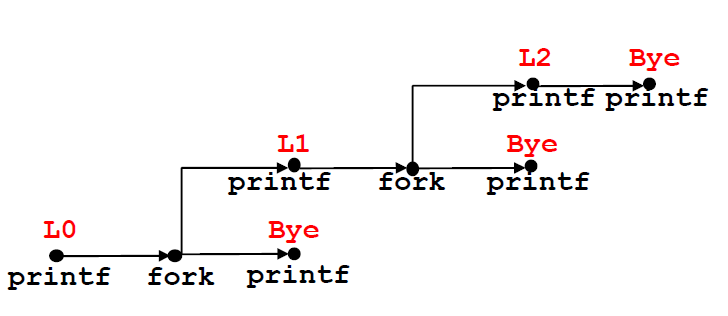
我们可以通过拓扑排序输出一个可行的序列
$L0\rightarrow Bye\rightarrow L1\rightarrow L2\rightarrow Bye\rightarrow Bye$
回收子进程
当一个进程由于某种原因终止时,内核并不是立即把它从系统中清除。相反,进程被保持在一种已终止的状态中,直到被它的父进程回收(reaped)。当父进程回收已终止的子进程时,内核将子进程的退出状态传递给父进程,然后抛弃已终止的进程,从此时开始,该进程就不存在了。一个终止了但还未被回收的进程称为 僵尸进程
如果一个父进程先于子进程终止,那么Kernel会安排init进程(PID=1,在系统启动时由内核创建)作为孤儿进程的养父。然后由init进程来回收他们。然而长时间运行的程序(shell/服务器),总是应该回收他们的僵尸子进程,因为即使它们没有运行,也会消耗系统的内存资源。
父进程可以通过wait或者waitpid函数来等待 它的子进程终止或者停止
1 |
|
父进程得到返回值之后,Kernel需要将僵尸子进程删除。
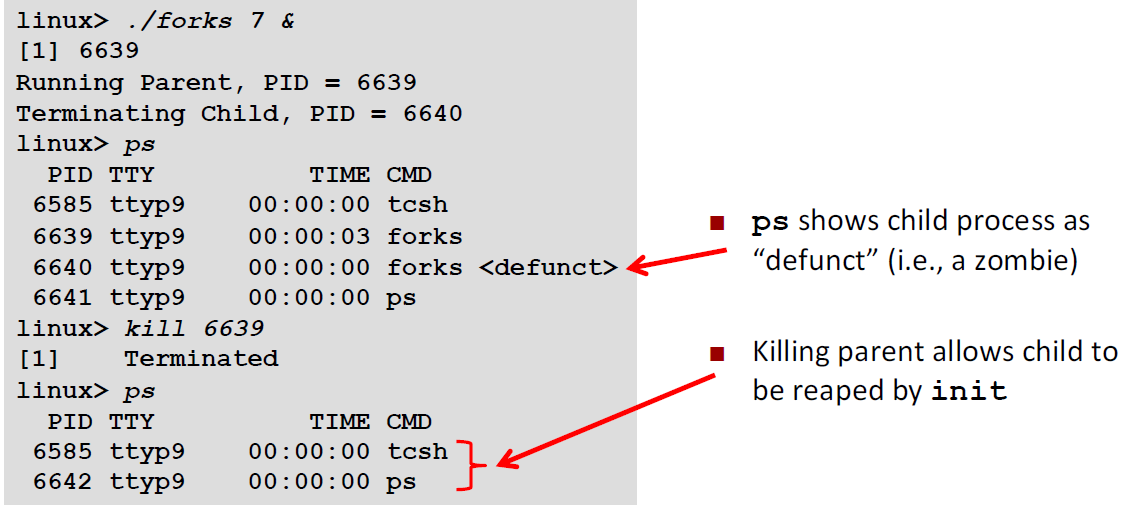
例子1:Zombie Example
1 | void fork7() { |
父进程是6639,子进程是6640
因为子进程先exit(0)了,但是父进程没有收回子进程,所以子进程现在是 defunct的,说明这个进程是僵尸进程。
这时候我们如果 kill 6639 ,那么会同时回收父进程和子进程。
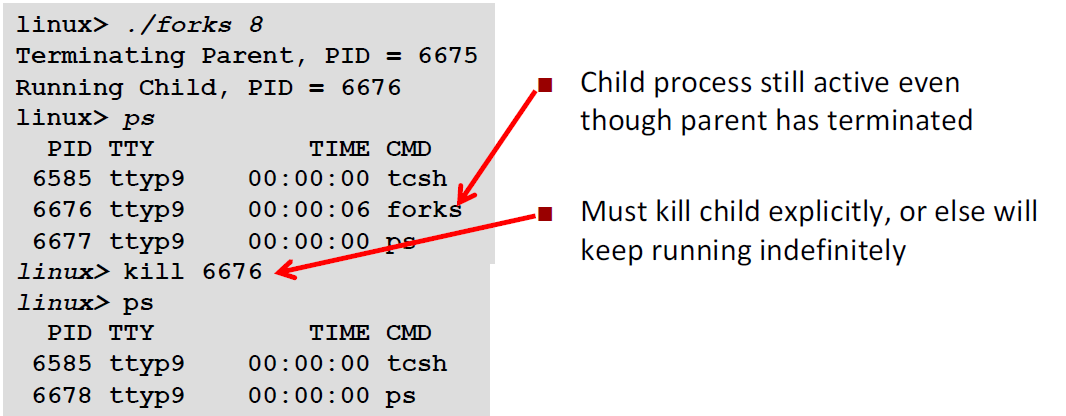
例子2: Non-terminating Child Example
1 | void fork8() |
在这里,如果我们先终止的是父进程,我们发现即使父进程已经被终止了,但是子进程还是在运行当中。我们一定要显式地Kill 子进程才能终止。
wait: Synchronizing with Children
如果我不去杀掉父进程,如何仍能在子进程 $exit(0)$ 的时候收回子进程?我们可以用wait函数。wait函数可以通过系统调用和子进程的状态进行同步。
int wait (int *child_status) 这是wait函数的用法,后面跟的时子进程的状态
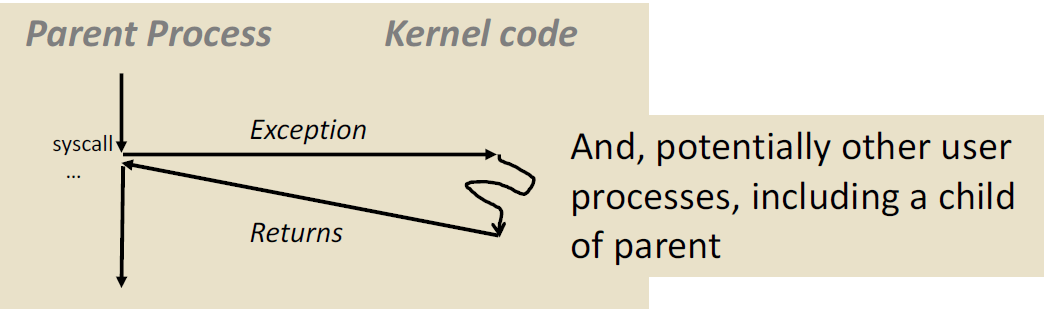
调用wait之后,父进程就会进入一个suspended状态,等到子进程的特定的状态产生,才会做后面的事情。也就是做一个同步的工作。wait函数的返回值就是这个被终止掉的子进程的 pid,如果child_status!=NULL,那么它所指向的整数将被设置为一个值,该值指示子进程终止的原因和退出状态:

例子1
1 | void fork9() { |
请画出这个例子的流程图:
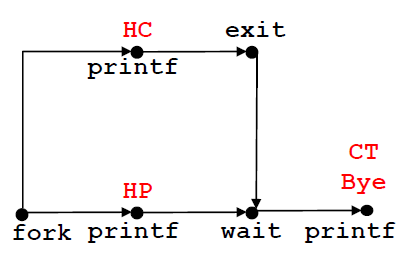
我们看到,在fork之后,子进程会打印HC: hello from child ;而父进程会打印 HP: hello from parent 打印完之后父进程并不会直接打印 CT ,因为这时候他在等待子进程结束,等子进程结束之后,父进程才会打印CT: child has terminated 最后打印Bye
所以 Feasible output 可以为 HC HF CT Bye 或者 HP HC CT Bye
例子2
如果多个子进程结束了,这时候该怎么办? 这时候wait会接收任何一个子进程发出的信号。这时候对于父进程,需要得到终止的到底是哪个子进程,然后将终止的子进程的pid和子进程终止的状态显示出来。
1 | void fork10() { |
如果我有很多的子进程,但我只关心某一个特定的子进程,那么我可以使用waitpid这个函数。通过这个函数,我们可以按照顺序依次回收进程。如果前面一个进程没有结束,那么后面一个进程也不能提前被回收。
1 | void fork11() { |
execve
Fork是创建一个进程,但是这个进程所有的东西都是和父亲共享的。但是有时候我们想要一个进程运行一个新的程序。这时候我们就需要构建一个程序的代码并加载程序,这时候就需要execve 来帮助我们完成
int execve(char *filename,char *argv[],char *envp[])
filename 表明了文件在哪个地方,*argv[]是一个指针数组 argv[0]就是指这个filename ,没有*argc[] 的原因是因为 argc 代表了参数的个数,但是execve并不需要这个量
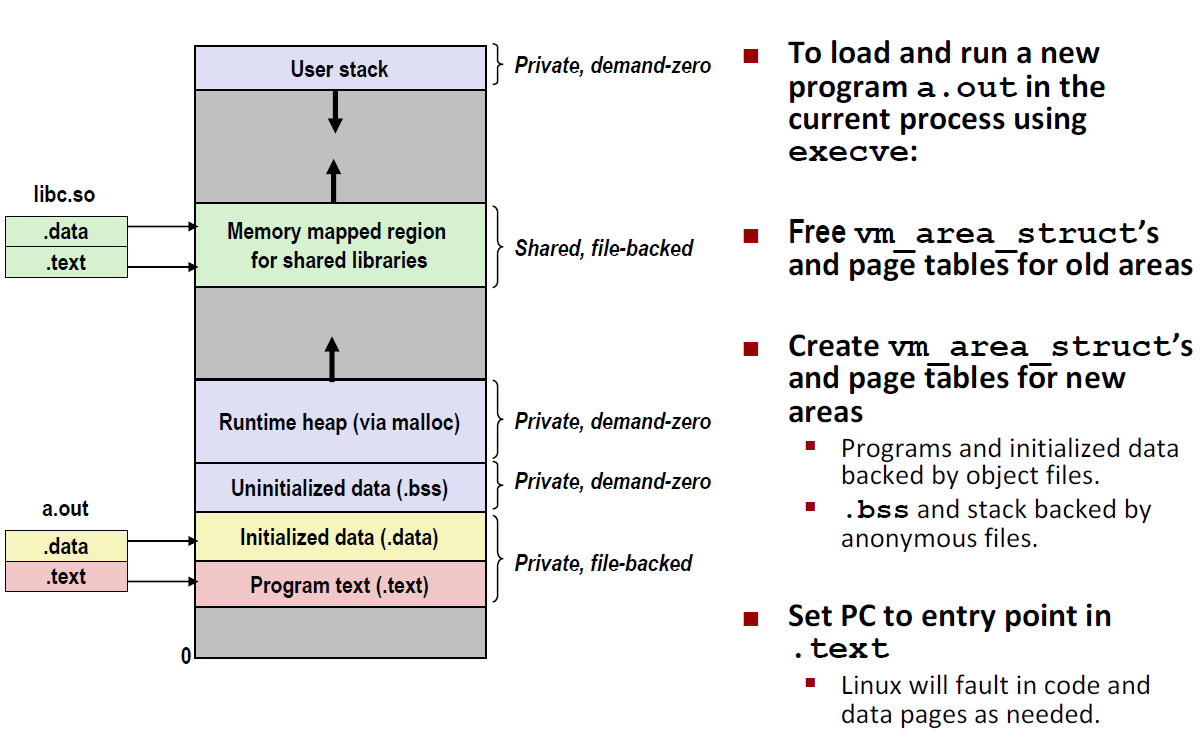
作用就是 Overwrites code, data, and stack . 保留了 PID, open files and signal context
execve函数仅调用一次,(成功的话)并且不会返回,这是因为函数将栈清除了,也就是说return地址没了,所以不会返回。fork是调用则会返回两次- 但是如果
execve调用不成功,那么就会返回-1
比如说这样一段代码,首先创建一个子进程,然后对其执行 /bin/ls -lt /usr/include 命令。
1 | if ((pid = Fork()) == 0) { /* Child runs program */ |
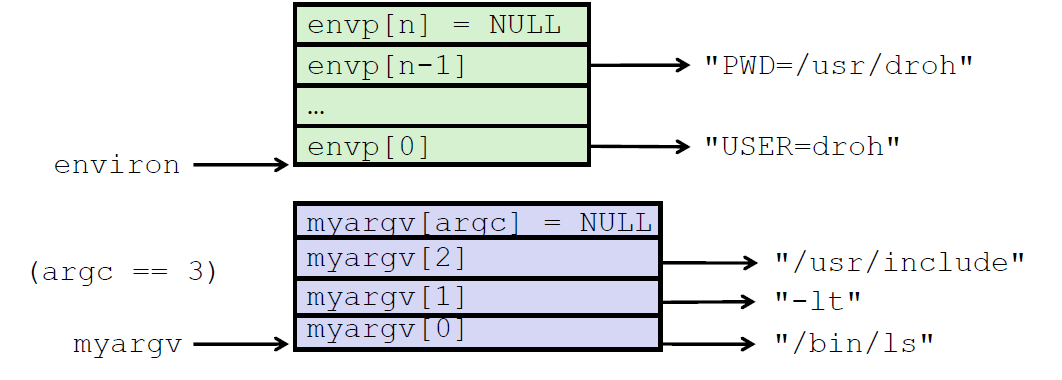
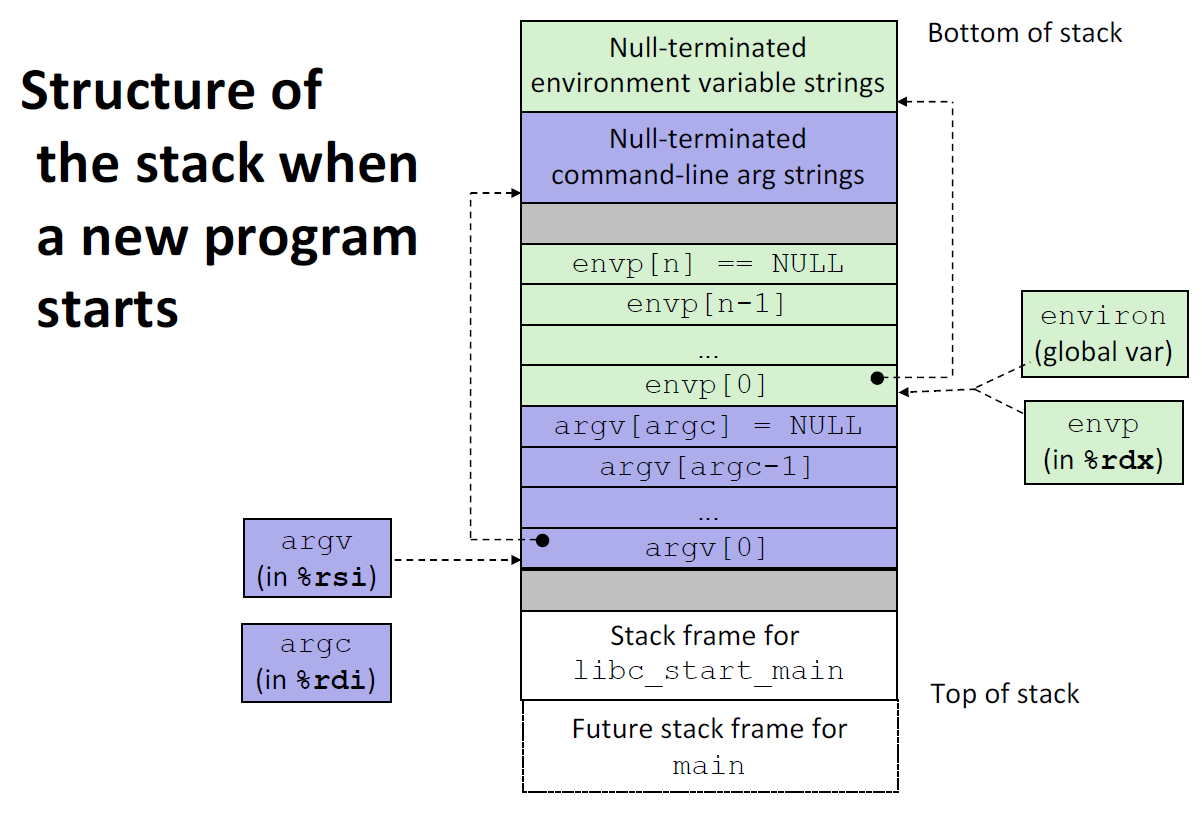
在execve 加载了 filename之后,它调用了启动代码。启动代码设置栈,并将控制传递给了新程序的主函数,该主函数有如下形式的原型:int main(int argc,char **argv,char **envp);
当main开始执行的时候,用户栈的组织结构如下图所示 。让我们从栈底(高地址)往栈顶(低地址)依次看一看。首先是参数和环境字符串。全局变量environ指向这些指针中的第一个 envp[0].紧随环境变量数组之后的是以null 结尾的argv[]数组,其中每个元素都指向栈中的一个参数字符串.