CSAPP云计算
What is distributed computing
简单来说,分布式计算就是说我们可以利用多台计算机而不是一台计算机来获取某些东西并能做的很好。分布式在当今最大的应用就是建立一些大型网站,比如 eBay,Google ,Amazon等。我们使用的几乎所有的大型网站都是分布式建立的,它们正在使用数十万台可以为数百万用户提供服务的现成计算机。
现在我们来回答一个问题:
The first demonstration of how to build really large Internet sites out of clusters of computers was done by:
A. Stanford
B. Berkeley
C. Yahoo!
D. Google
E. IBM
答案是Berkeley
在1996年的时候,如果要建造一个大型的网站(如eBay或者Yahoo),我们可以用一台”超级计算机”,我们可以来看一下超级计算机和我们的PC之间的配置差别。

这样一台超级微机在当时的售价是100万美金,是一个不便宜的价格。但是eBay和其他一些非常迅速发展的大型网站,就必须使用这些设备。但是问题是,当网站不断地在发展、客流量在不断增长,有时候会超出这台机器的承受能力,这时候公司必须使用新的更大更先进的计算机来替换掉老的计算机。这样的操作模式非常烧钱,因为对于公司来说它们没有一个巨大的市场值得花数百万美元购置新的更大的计算机,但是老的计算机又不够用。
这时,伯克利大学有一个项目,就是说我们可以用很多很多台批量生产的PC电脑,它们虽然个体的计算能力比不上超级计算机,但是它们加起来的计算能力就有可能超过一台昂贵的超级计算机。
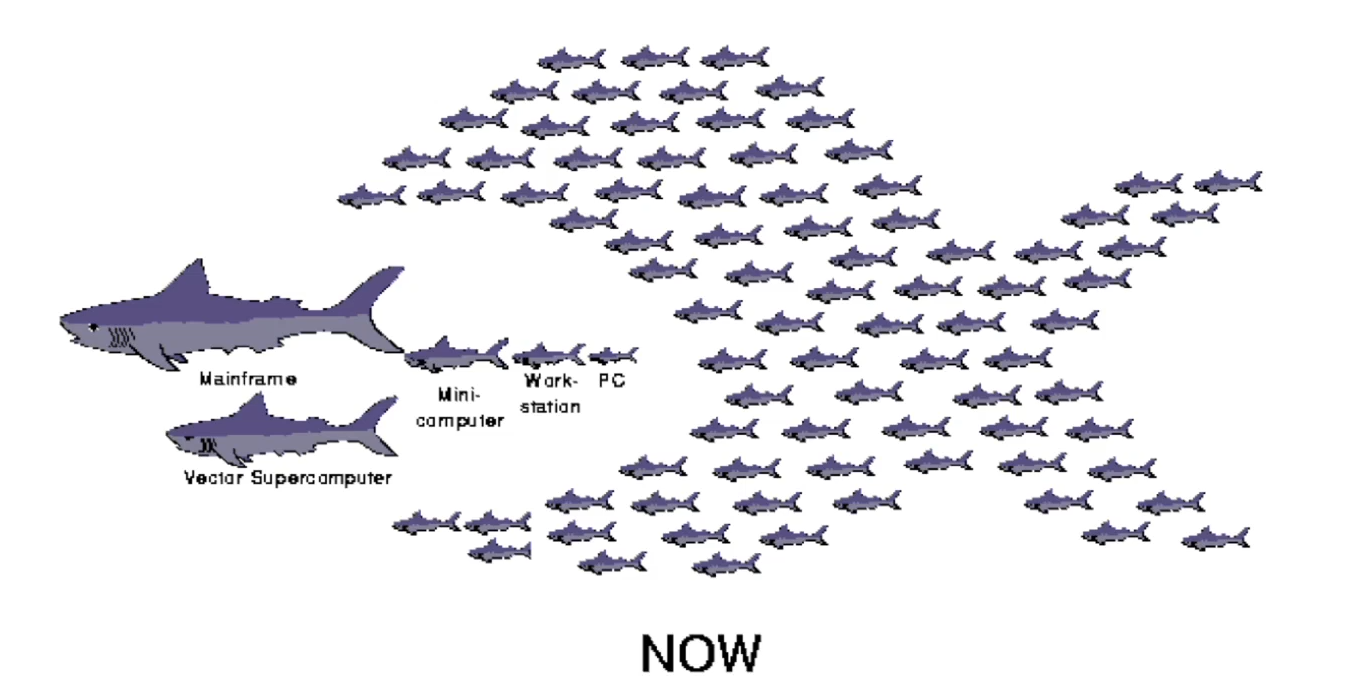
就如同上图所示,我们用很多台PC组合起来,就可能拥有吞噬”大鲨鱼“的能力。这是一种更节省成本、增加效益的方式,不仅是因为各个零件都更便宜写,而且我们可以通过将它们聚集起来达到一个惊人的计算量
于是,这就是分布式计算的雏形,这是1994年造出来的,没有显示器键盘和鼠标,只有四台 HP-735型号的机器

一年以后,已经从4台变到了32台 Sun SPARC-stations,都是由Sun公司捐赠的,而且理线也正常了许多。

从这之后,它变得越来越整齐有序了,在97年,由原来的32台变为了60台 Sun主机

分布式系统发展的越来越大之后,挑战也越来越大:How do you program a NOW?(or: what is it good-for)
之前在大型计算机或者是在supermini上编写程序非常方便,因为只要让一台计算机成功运行即可。这是程序员熟悉的体系,程序有变量、 内存分配云云。但是在分布式系统上,我们无法在其他计算机上命名数据,我必须明确向其发送消息并接收反馈。这种体系对于程序员来说是新颖且陌生的。
还有一件很难的事情,就是当这些计算机中的某一台或者某几台出现了故障该怎么办。之前在supermini上我们可以尝试重启,但现在我们不能将正在工作的好的计算机也重启了,因此我们必须合理的编写程序来让剩下的没有故障的计算机继续运行,但当时并没有这样一个model来实现这个功能
因此,在1990‘s中期,我们必须挑战在不同的计算机上的内存中运行程序,并进行故障管理。随着机器数量的增加,管理面临的挑战也就越多。
Palm设备
如果我们对移动计算机有所了解,可能会记得一个叫做Palm的设备。当时这个机器设计出来就是想要在小型设备上获取Web内容,这比智能手机要早很多很多。
假设现在所有的数据和服务都已经在网络上了 ,那么我就可以随时利用这个工具获得我想知道的东西,而不是必须坐在PC前面。

这是伯克利第一次演示了具有自动扩展功能的Internet服务器架构,如果更多的人使用该系统,它将自动添加更多的计算机。如果一些人不再使用,那么系统将自动释放多余的机器并让他们返回池中,以便其他人可以使用它们。这个思想虽然一开始的目标并不是建立一个搜索引擎,而是为了展示网络服务编程的通用技术,但是却造出了一第一个以这种方式架构的搜索引擎

小练习: A Google datacenter built c.2005 would be designed to house approximately ____ computers.
A. 1000
B. 5000
C. 10000
D. 50000
E. 100000
答案是 在D和E之间的某一个数
What is warehouse-scale computing

现在我们要建造仓库级别的服务站,能容纳数以千计的电脑、存储和被和网络。来提供如搜索、邮件、GIS等软件的功能
中间的图是Sun公司的“黑匣子“,里面装满了可以容纳250台计算机以及超过1PB的存储空间以及7TB的RAM。像这样的集装箱,又会像叶子一样被装到右边这张图中的数据中心里面。一排中有数百辆这样的拖车。
现在集群已经成为了主流,但是构建这些庞大服务的唯一问题是对这些计算机集群进行变成仍然是一件非常麻烦的事。需要大公司大资本的帮助才能完成。因此这就是 RAD lab建立的初衷。
要拥有这样一个大数据中心,首先你必须是一家大公司。因此 Amazon首先提出了 Elastic Compute Cloud(EC2) 的概念,所以他们可能是第一个用”云“一词的公司。它们的想法是:我们公司由这些数据中心,但有时候我们不需要这么多台计算机所有的能力:比如说在圣诞节和黑五,Amazon对服务器的需求巨大,而在平常它们并不需要用这么多服务器。因此我们为什么不能将这些闲置的计算机租出去呢?而且我们可以让人们按小时租用,且基本没有最低限度的购买,因此他们的价格一开始是10美分,现在是8美分/小时。
对于消费者,我们只要租我们需要的计算机数量并按照时间付钱就行了,用完后计算机就会被释放回池当中,并不用再继续为其付费了。

但是我们还没有仔细来讲怎么对这么多台计算机进行故障排查和管理。我们可以从这么多计算机中搜集信息并发现从中有趣的模式,因为这些数据可能会告诉我们一些信息。 比如说一旦一台计算机坏了,我们可以查看来自检测我们计算机的仪器的数据(在发生故障之前的那几分钟);又或者说我们的系统速度变慢了,那么我们可以通过比较不同的计算机来找出哪个或者哪些是”罪魁祸首”——因为我们不可能手动来调试几万台计算机并找出原因
RAD lab在做的就是一个”机器学习”的工作,只不过这个机器学习没有像谷歌一样用在搜索引擎当中,而是用于数据中心中正在运行的任何程序上。
对于Amazon对”云“这一概念的提出,甲骨文的CEO拉里表示不屑。随后 RAD lab就发表了一篇论文,这篇论文提出了关于云计算的新观点,有超过六万的下载量,并对许多公司在云计算方面的战略布局产生了非常大的影响力。这也改变了 拉里对云计算的看法

过去的云计算的观点就是将软件服务放在云上还是放在本地上。但是新的观点就是我们可以按照时间租赁计算机,只要我们愿意付钱,我们可以向Amazon这样的公司索要上百台计算机都可以。并且我们不用计算机的时候可以直接将他们释放,也不需要再付钱了。 之前也有公司(如Sun)做过类似的云服务,但是它们没有Amazon这样的专业技术,单价也更贵。这样一个Idea,在当时给Amazon带来了数百万美元的收益,而这是接近零成本的,因为Amazon只是在出租他们空闲的计算机而已。

问题是,云服务从上个世纪末就开始了,为什么只有Amazon到08年才开始着手做呢?因为一开始大公司都是被迫建属于自己的数据中心的。他们的计算机基本都是为自己的客户服务的。Amazon最初也没想到会从事这项业务,这并不是他们最初的目标——Amazon买那么多计算机只是为了能让他们的线上购物平台能容纳更多的流量而已。Google买那么多计算机只是为了用户对Gmail和Google地图等需求再不断增长。
我们发现如果公司能数以千计地购买计算机,那么所有的硬件设备都能比单价便宜5-7倍。之前之所以不买如此大批量的计算机是因为需求跟不上。但是 在过去的十几二十年中,互联网飞速发展,个人上网的成本也越来越低,因此对互联网的服务需求也越来越多。
还有,随着开源软件的数量越来越多,很多用户没有必要在自己的电脑上装很多开源软件,他们只需要租一台或者几台计算机并在上面运算就行了,更不用为运行的软件付钱,只需要付租金即可。

那么如果我们现在是一家网络创业公司,为什么我们会偏向使用云计算服务呢?因为使用云服务能节省能源和资金。当我们第一次将我们的产品上线的时候,我们很可能会高估了软件的受欢迎的程度。如左图所示,对于蓝色的需求曲线,如果我们卖如红色直线那么多的计算机的话,会发现在低谷的时候,大部分计算机都是空闲的,我们不得不为这些空闲的计算机付费(维护、电力等)。但是如果使用云服务,那么从理论上来讲,我们就可以根据产品的客流量来调整我租赁的计算机服务——在白天增加计算机,在晚上释放空闲的计算机。哦只需要为我使用的东西付款而并不需要购买固定数量的计算机。
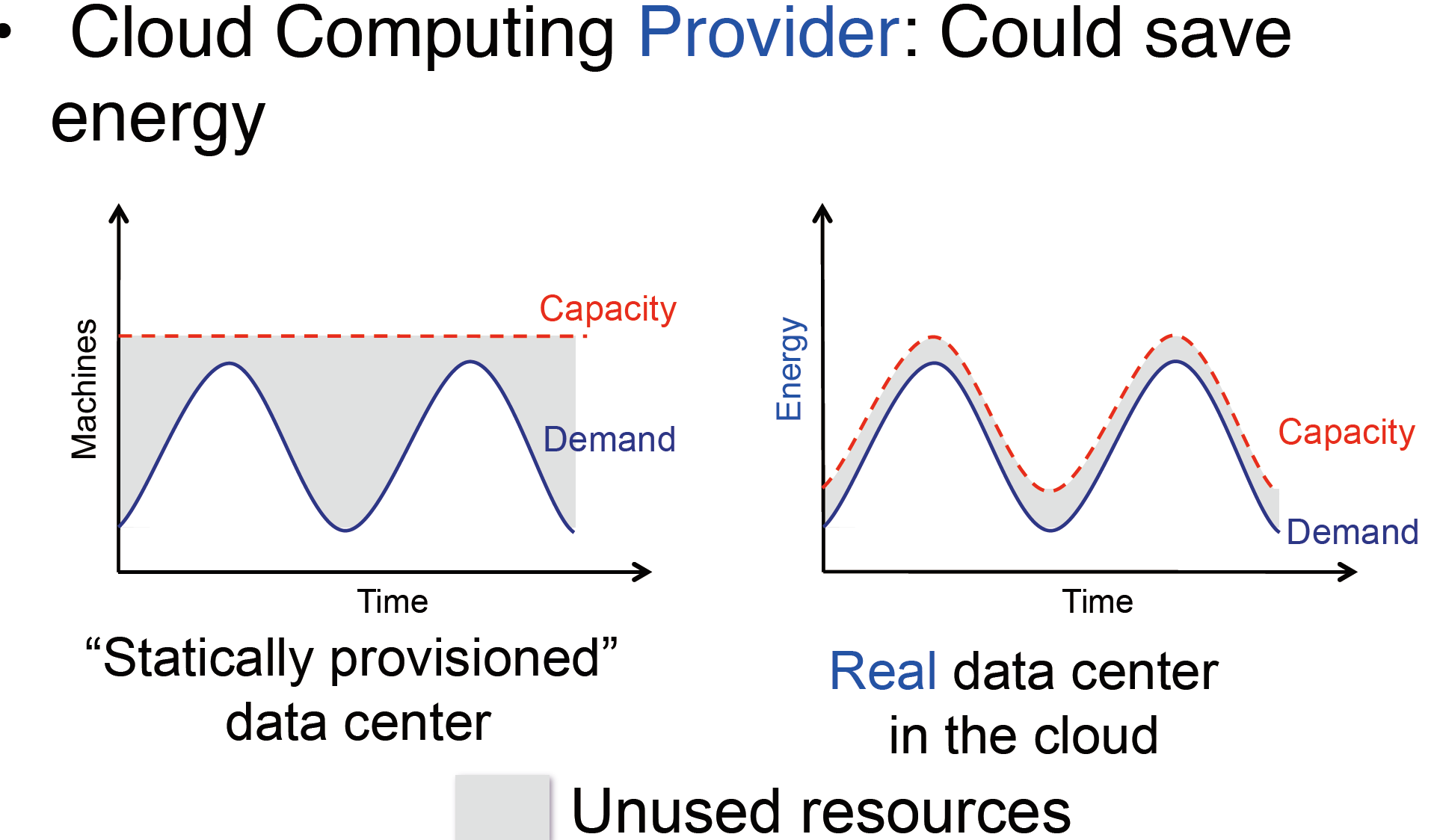
或者,当我的产品爆火的时候,如果购买固定数量的计算机,很有可能是带不动这么大的客流量的:久而久之,哪些觉得体验很差的客户就会因此流失。比如当时比Facebook更早的社交软件 Friendster,活跃于2005年前后,他们公司就是因为供应赶不上爆发式的需求量,从而让很多用户感到恼火,最后被抛弃。但云计算却能很好的规避这一限制。
What can you do with this
在没有云计算之前,我们是不能想象1000台电脑用1个小时需要花多少钱的,因为我们必须花钱买下1000台电脑才能运行。但是有了云计算之后,1000台电脑运行1小时的价格和1台电脑运行1000小时的价格是一样的,这是具有革命意义的。
举个例子来说吧,华盛顿邮报搜集并在网上披露了希拉里克林顿的旅行文件。这在没有云计算的时候,只有一台电脑可能需要几周的时间来完成这些工作。但是有了云计算之后,他们可以利用大约200台计算机去做文件识别等工作,他们在不到一天的时间内就完成了整个工作,而且只花了不到200美元,这就是云计算的强大之处——在短时间内能以较低的成本使用大量计算机。
RAD Lab的一些研究生在演示提升MapReduce的运行速度的时候,借助云计算利用了1000台服务器,这在没有云计算的情况下是不能想象的。因此云计算也给一些软件能向业界证明自己的实力和性能创造了实实在在的机会。

这是另外一个例子,当2001年911事件发生的时候,CNN网站的访问量在十五分钟内暴增10倍,这直接导致了他们使用的 minisuper超级计算机的宕机。而在2008年,当Animoto这个软件以插件的形式出现在Facebook当中的时候,在3天内每12个小时用户就翻一倍,但这个软件却能继续运行,因为它使用了云计算,只是从50台服务器增长到了3500台服务器,等到了使用高峰期过了以后,他们又削尖了服务器的规模。

这是另外一个例子,我们可以用机器学习算法来分类Twitter上的垃圾推文或者邮件。对于640GB的数据,在一台电脑上可能要运行270个小时,但是如果我们使用Amazon的云计算服务,我们可能只需要3小时就能训练完成,只是需要花费255美金。
云计算还应用于遗传学中的基因组测序

同时我们应该也注意到云计算所面临的挑战:
第一个就是cloud programming,也就是云编程。如果Mapreduce能在云上运行的话,那将是一件很好的事情。但这可能会非常棘手,因为Mapreduce依赖的是 令人尴尬的并行性。
在这里我们要了解以下并行计算的两种方式:1. 分布式计算机,电脑和电脑是通过网络相连接的;2. 并行式计算机,电脑和电脑是通过总线相连接的。不管怎么样,我将计算机连接起来的目的是为了增加并行度,然后我们希望编写的程序能将各台计算机的CPU都能有效地利用起来。
对于我们来说,大多数情况下我们的程序仅在一颗CPU上运行,但是给我32颗CPU,我能通过什么办法将这32台计算机为我服务呢?有专门做并行计算的程序员,他们会写好相关的API,对于要编写天气预测软件的专业人士来说,他们只需要调用API就行了。这就叫做“透明”,也就是说我们并不需要了解内部的具体运作原理,只需要调用API即可。
Mapreduce 是处于调包和自己写程序中间的一种工具,它要比自己用python写并行程序要方便很多,又有较强的自由性,能决定数据和计算机的分配。Mapreduce对程序员的要求比较高,因为并不存在一个通用的方法来讲一个普通的程序转换成Mapreduce的程序。有些程序甚至根本不能转换成Mapreduce程序。所以Mapreduce对程序员来说是一个比较大的挑战,需要对并行计算有很深入的理解才能将程序写的高效,没有经过足够多的训练是很难写的。因此,现在云计算还没有到达一个足够友好、足够易用、足够高效的一个水平,虽然已经有一些很有用的框架。


Big Data
另一个挑战是关于大数据的。因为建造大量的光缆网络来搭建远程传输网络是非常贵的,而且发展得也很慢。 比如说,我向复制8TB的数据到Amazon的云上,使用20Mbps的光宽带,那么就要耗时35天并支付800多美元。而事实上,如果我们使用快递将8TB的磁盘插入Amazon的电脑,进行数据传输,只要一天的时间并只要支付150的运输费即可(事实上Amazon确实在提供这样的服务)。

Summary
- 云计算能让更多人用得起”超级电脑”的计算力,我们只需要一张信用卡就行了
- 让学生和学术界在更平民化的竞争环境中对产业产生更大的影响
- 也许下一个如同Google,eBay,Amazon的大公司可能来自一个小的企业家团队,即使没有大量的资金。
