哈夫曼编码
通常的编码方法有固定长度和不等长度编码两种。
最优的编码方案的目的是使总码长度最短。利用字符的使用频率来编码使不等长编码方法,使得经常使用的字符编码较短,不常使用的字符编码较长。
不等长编码方法需要解决的两个关键问题:
1) 编码尽可能的短
使用频率高的字符编码较短,使用频率低的编码较长,可提高压缩率,节省空间,也能提高运算和通信速率。 即出现频率越高,编码越短
2) 编码不能有二义性
解决方法是:任何一个字符的编码不能是另一个字符编码的前缀,即前缀码特性
于是我们可以通过二叉树编码,频率高的可以离根近一点,频率低的就可以离根远一点。而且,每一个字符都是一个叶子结点,这样就可以避免二义性,因为叶子是绝对不会有孩子的。
我们可以构造一颗哈夫曼树,这是一棵将所要编码的字符作为叶子结点,该字符在文件中的使用频率作为叶子结点的权值,以自底向上的方式,通过n-1次的合并运算后构造的树。其核心思想是让权值大的叶子离根最近。
哈夫曼采取的贪心策略是:每次从树的集合中取出没有双亲且权值最小的两颗树作为左右子树,并一次构建一颗新的树。新书根节点的权值为其左右孩子节点权值之和,将新树插入到树的集合中
例子

为了方便起见,我们可以将频率同时扩大100倍。
- 我们选择没有双亲且权值最小的两个结点,$t_1,t_2$
- 将$t_1,t_2$作为左右子树构建一颗新的树,这里是a和d
- 将他们组合成一个新的树,他们的父结点的权重为12,这个12也需要加入到集合中作比较
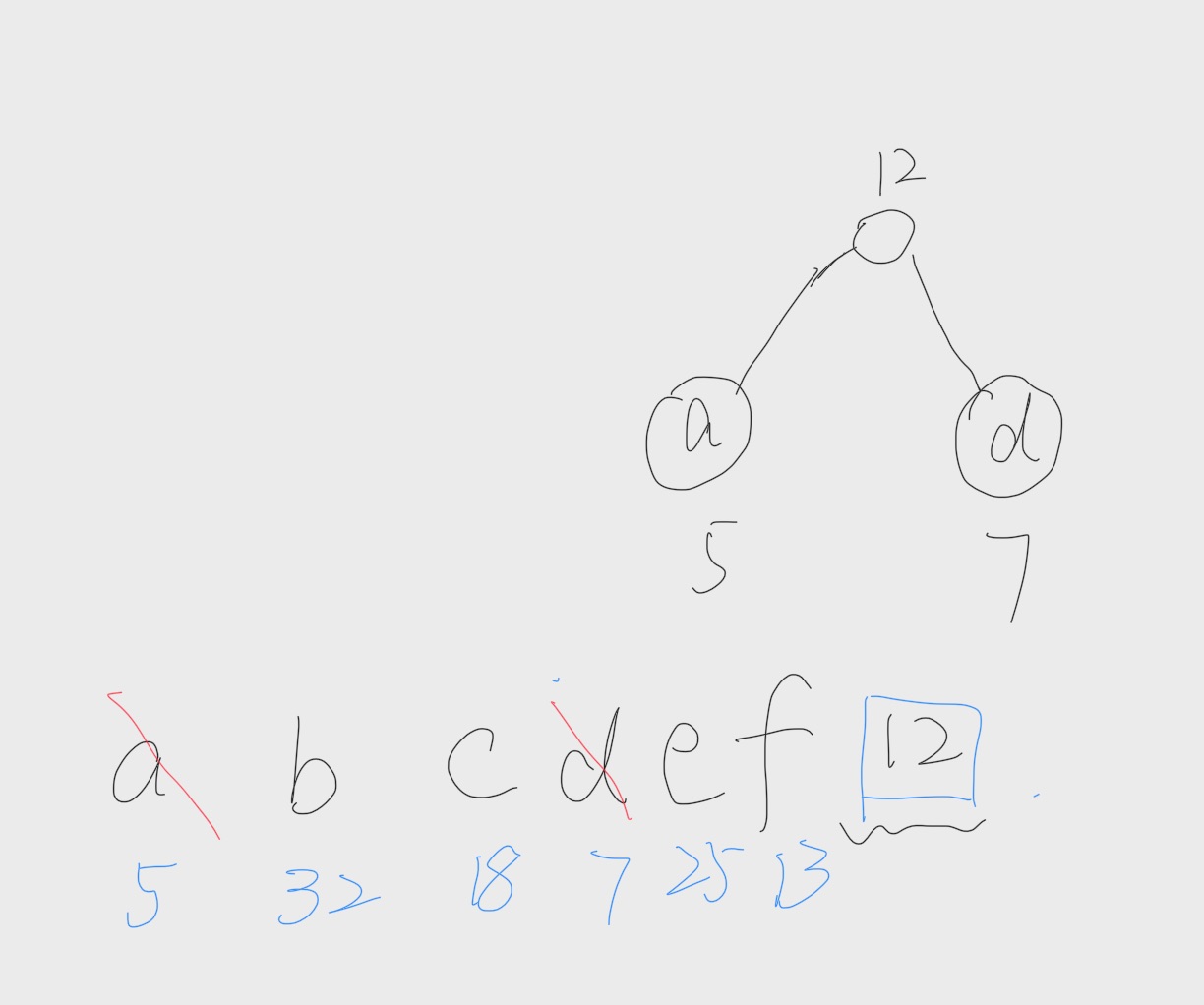
- 接下来,f 和新结点组合生成了新的树
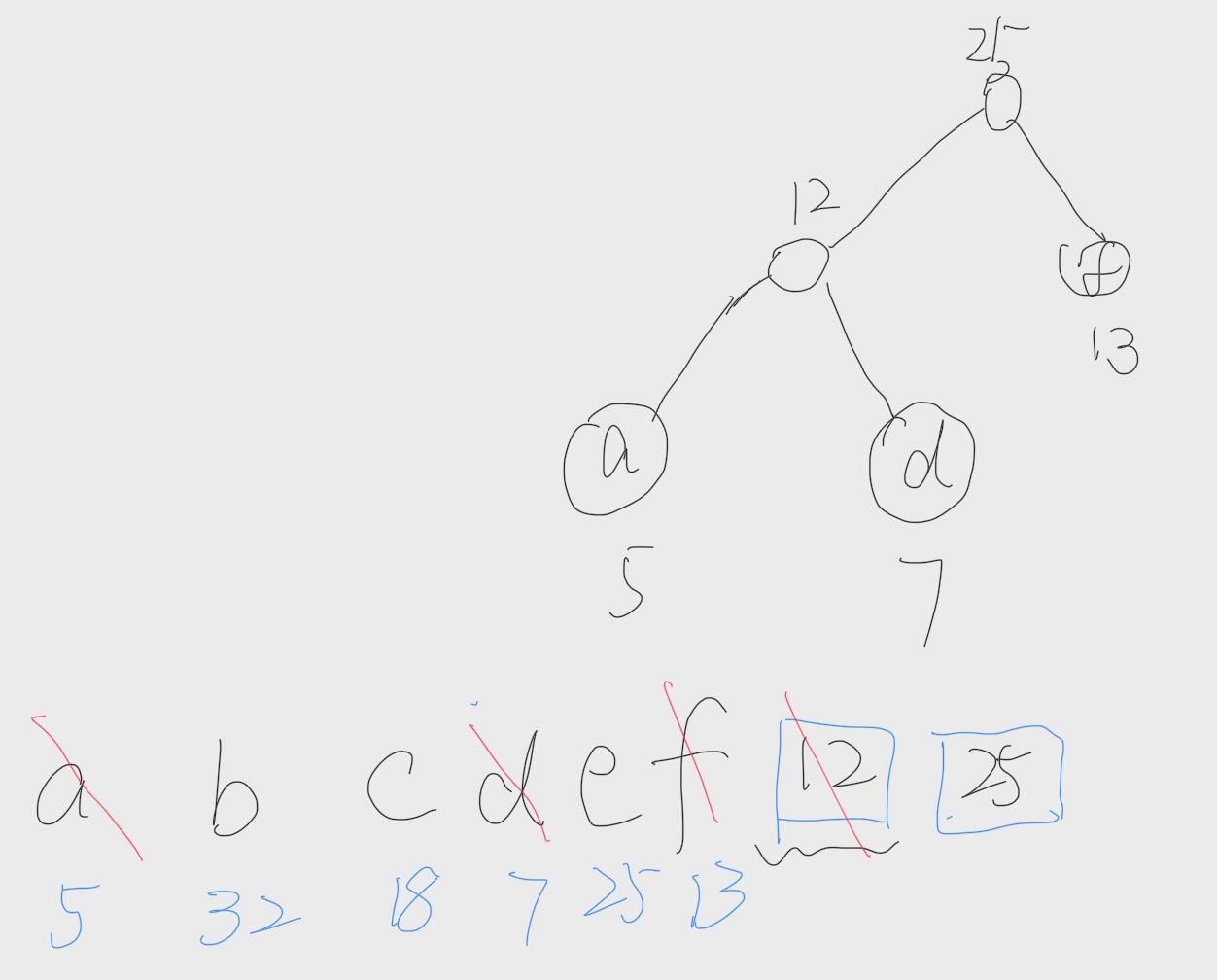
但是现在问题来了,当前的集合中,最小是c,次小为e和新的结点。我们该选哪个? 答案是选择 e。因为新产生的结点会放在集合的后面。我们碰到一样权重的节点的时候,选择前面那个。
最后,我们的哈夫曼树如下:
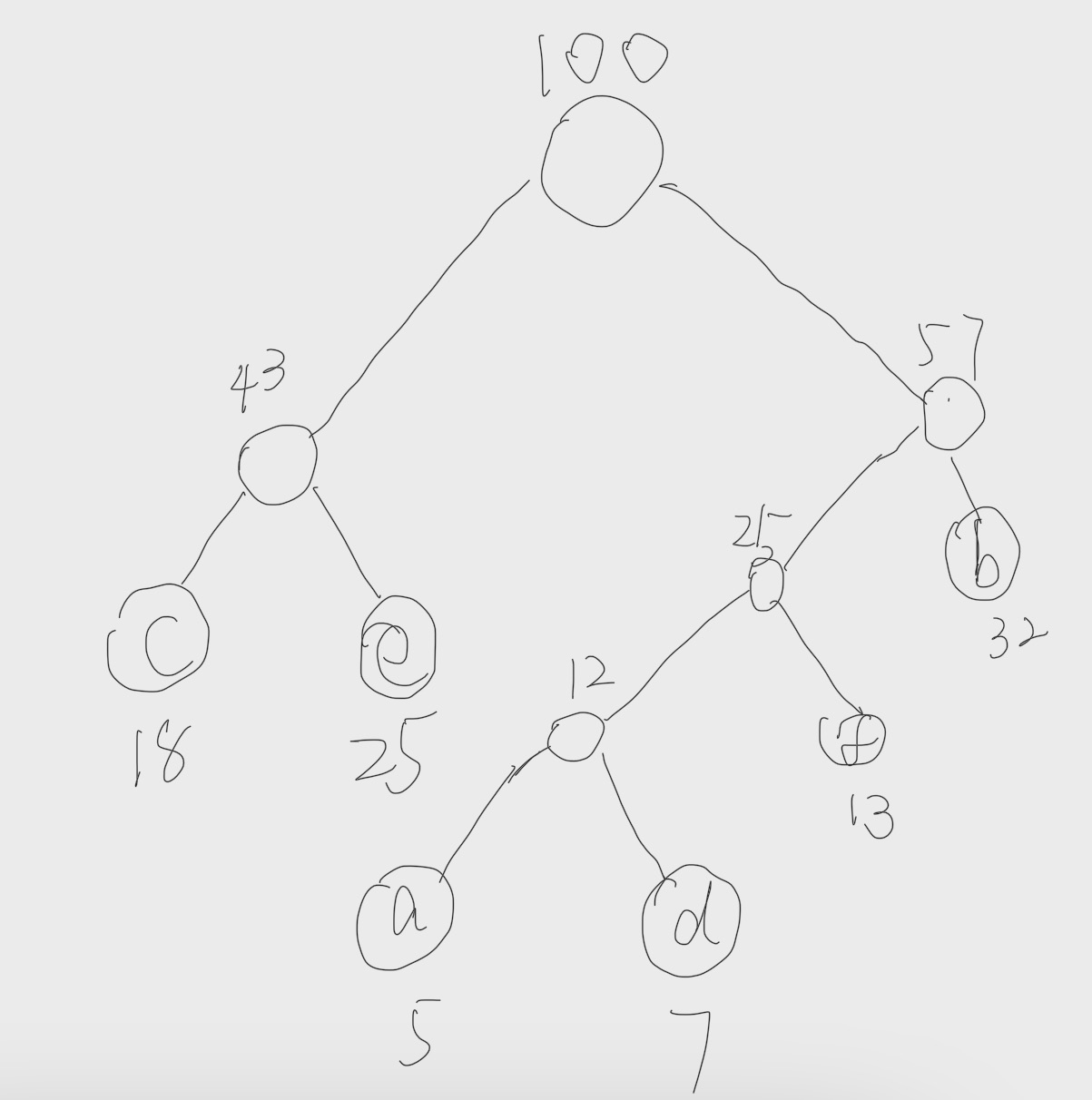
一般我们在程序中将最小的元素设置成左孩子,次小的设置成右孩子。
程序设计
确定合适的数据结构
- 哈夫曼树中没有度为1的结点,则一颗n个叶子结点的哈夫曼树共有 2n-1 个结点(n-1次的合并,每次产生一个新的结点)
- 构成哈夫曼树之后,为求编码需从叶子节点出发走一条从叶子到根的路径,是左孩子就编成0,是右孩子就编成1。
- 译码需要从根出发走一条从根到叶子的路径,那么对于每个结点而言,我们要知道每个结点的权值、双亲、左孩子和右孩子和节点的信息
1 | typedef struct |
下面我们来写出哈夫曼树的构建数组
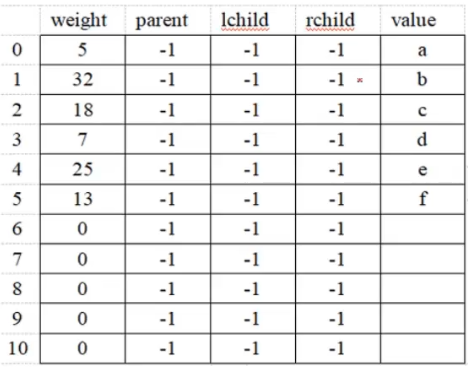
最终这张表如下图所示:
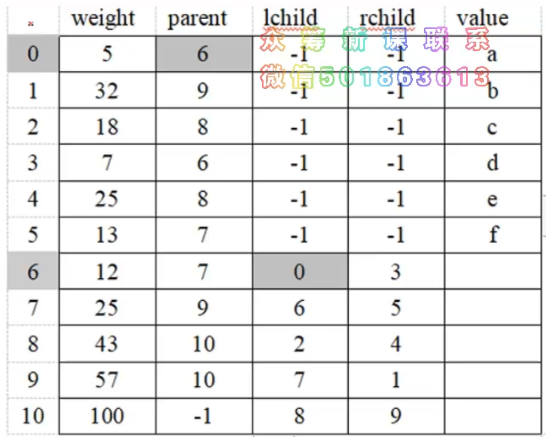
构建哈夫曼树的过程就是填写这张表的过程
编写哈夫曼编码的过程就是读表的过程
对于编码的存储,我们可以用这样一个struct数组:
1 | typedef struct |
哈夫曼树带权路径长度
WPL = 每个叶子的权值X该叶子到根的路径长度之和。 哈夫曼树带权路径长度之和等于各新生成节点的权值之和
1 |
|