Shell 在 Minix3中的实现
目的
Shell主体结构是一个while循环,不断地接受用户键盘输入行并给出反馈。Shell 将输入行分解成单词序列,根据命令名称分为二类分别处理 ,即shell内置命令(例如cd,history,exit)和 program 命令 (例如/bin/目录下的ls,grep 等) 。识别为shell内置命令后,执行对应操作。接受program命令后,利用minix自带的程序创建一个或多个新进程,并等待进程结束。如果末尾包含&参数,Shell可以不等待进程结束,直接返回。
Program命令
运行程序:利用fork调用创建进行子进程,利用execvp调用将minix程序装载到该进程,并赋予运行参数,最后Shell利用wait/waitpid调用等待子进程结束。(参见UNIX高级编程8.3,8.7和8.10节)
参考资料:
- Shell主要是为用户提供一个命令解释器,接收用户命令(如ls等),然后调用相应的应用程序。实现的Shell支持后台进程的运行。
- 在计算内存和CPU总体使用情况时,可参考top命令实现 https://github.com/0xffea/MINIX3/blob/master/usr.bin/top/top.c
- 推荐《UNIX环境高级编程》查找详细的系统调用使用方法。
1.实现带参数的程序运行功能
program arg1 arg2 ... argN
2. 重定向功能, 将文件作为程序的输入/输出
- “>” 表示覆盖写
program arg1 arg2 … argN > output-file - “>>” 表示追加写
program arg1 arg2 … argN >> output-file - “<” 表示文件的输入
program arg1 arg2 … argN < input-file
重定向:minix为每个进程赋予键盘输入和控制台输出的文件描述符默认为0和1。子进程装载程序前,利用close(0 or 1)将默认输入或者输出关闭,再调用dup(fd)将某个打开文件的文件描述fd映射到标准输入或输出。(参见UNIX高级编程3.12节)
3. 管道符号 “|”
在程序间传递数据 programA arg1 … argN | programB arg1 … argN
若有n个子进程组成管道流,Shell在fork前先用pipe调用创建n-1对管道描述符,关闭不需要的读写端。Shell运行fork后,每个子进程利用dup将前一个管道的读端映射到标准输入,后一个管道的写端映射到标准输出。(参见UNIX高级编程15.2节)
在实现管道时,需要用到pipe和dup系统调用等,重定向标准向输入输出(参见教材1.4.3节)。
4. 后台符号&
表示此命令将以后台运行的方式执行 program arg1 arg2 … argN &
后台运行:为了屏蔽键盘和控制台,子进程的标准输入、输出映射成/dev/null。子进程调用signal(SIGCHLD,SIG_IGN),使得minix接管此进程。因此Shell可以避免调用wait/waitpid直接运行下一条命令。
Shell 内置命令
1. 工作路劲移动命令 cd
提示: 因为Shell也是一个程序,启动时minix会分配一个当前工作目录,利用chdir系统调用可以移动Shell的工作目录。
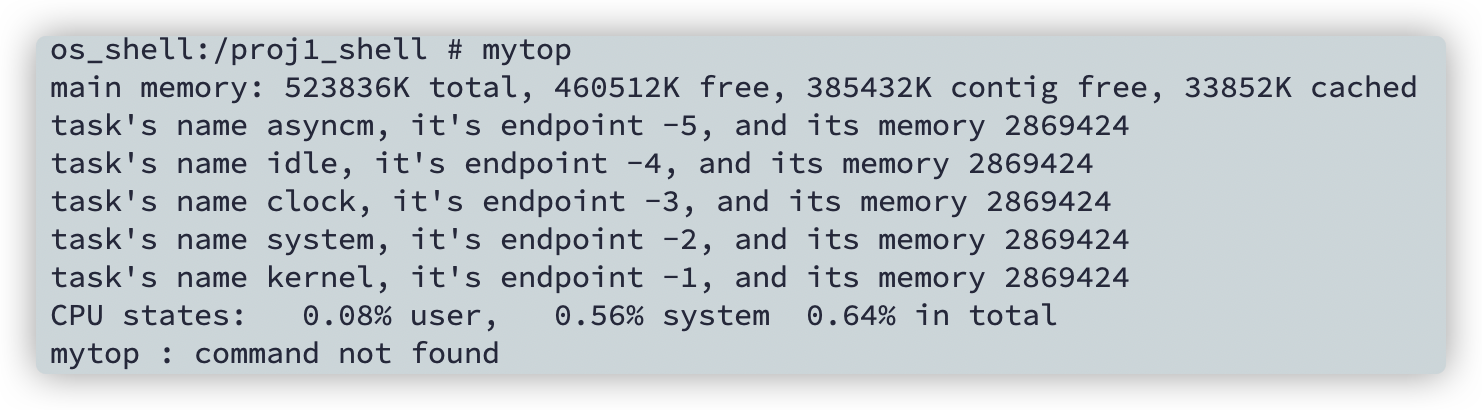
2. 程序运行统计mytop
提示:参考minix终端输入top命令的输出信息,在minix系统/proc文件夹中通过open/read系统调用输出进程信息。
- /proc/meminfo中,查看内存信息,每个参数对应含义依次是页面大小pagesize,总页数量total ,空闲页数量free ,最大页数量largest ,缓存页数量cached。可计算内存大小:$(pagesize ~*~total)/1024$,同理算出其他页内存大小。
- /proc/kinfo中,查看进程和任务数量。
- /proc/pid/psinfo中,例如/proc/107/psinfo文件中,查看pid为107的进程信息。每个参数对应含义依次是:版本version,类型type,端点endpt,名字name,状态state,阻塞状态blocked,动态优先级priority,滴答ticks,高周期highcycle,低周期lowcycle,内存memory,有效用户ID effuid,静态优先级nice等。其中会用到的参数有:类型,状态,滴答。进程时间$time=\frac{ticks}{(u32_t)60}$。
输出内容:
- 总体内存大小,空闲内存大小,缓存大小。
- 总体CPU使用占比。计算方法:得到进程和任务总数量total_proc,对每一个proc的ticks累加得到总体ticks,再计算空闲的ticks,最终可得到CPU使用百分比。
3. shell 退出命令 exit
提示: 退出Shell的while循环,结束Shell的main函数。
4. history n 显示最近执行的n条指令
提示: 保存Shell每次的输入行,打印所需字符串即可
测试用例
1 | cd /your/path |
内容与设计思想
这个实验主要是在Minix里面自己实现一个简单的shell,并实现一些基本的命令。
我会将整个project分割成很多小片段来一一实现。
使用环境
虚拟机: Guest OS
虚拟机软件: Oracle VirtualBox
物理机: Windows10
实验过程
首先我们先介绍一下 main函数的实现思路,然后再详细分析main函数中调用的各种函数
宏定义
1 |
|
全局变量
1 | char *message; //用于输出当前的路径 |
main函数
在main函数中,主要是实现一个循环。
首先我们要定义一些参数:
wordcount 即输入命令中的单词的个数
wordmatrix 即一个单词数组,每一行存储一个单词,每一列头字符为\0
buf 即存放我们命令的缓冲数组。
首先我们需要判断系统中还有没有足够的空间来存放下我们的语句。当空间不足的时候,malloc函数会返回NULL指针,然后我们就返回 malloc failed 并推出shell。这里,perror 是C语言标准库 <stdio.h> 的一个函数,它会将一个描述性错误消息输出到stderr .
1 | int main(int argc, char **argv){ |
接下来是循环的主体。 首先我们利用memset函数将buf 数组初始化清零。
然后我们要给 message申请一段空间。这里,message是全局变量
,通过 getcwd这个函数来获取当前所在的路径并通过printf打印出来。比如说,当前我正在 proj1_shell 文件夹当中启动 我们的shell,如下图所示:
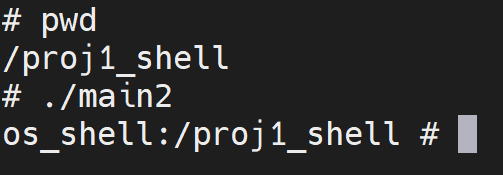
然后我们需要将 message 释放掉,因为每次循环我们都会重新申请message数组,如果不将其释放会产生很多垃圾、占用我们的虚拟机空间。
既然下来我们就要利用getOrder()函数从命令行中读取命令,并将其存储在我们刚刚声明的 buf数组当中。还需要将buf数组拷贝到msg二维数组中做一个备份,当收到history n的命令后,会从这个数组中查看之前输入过的命令。
如果输入的是exit命令,那么就直接跳出循环。
然后我们对 wordmatrix 二维数组的每一行的开头都设置为\0 (头插法),为接下来解析命令做准备。 anaOrder()即 analyze order的缩写,其目的就是解析buf中的命令,并将结果存入到wordmatrix数组当中去。
将命令全部解析完成之后,我们调用 execommand函数,也就是执行我们解析完的命令。这也是我们待会要着重分析的函数。因为所有的 内置命令、Program 命令都在这个函数中实现。
1 | int main(int argc, char **argv){ |
最后,当循环结束的时候,我们对buf数组进行回收。
1 | int main(int argc, char **argv){ |
getOrder函数
getOrder函数是从命令行窗口读取我们输入的命令、并将命令存放在buf数组当中。
首先我们要了解我们输入的命令长什么样: 有一些单词、符号,中间用空格隔开,然后以\n换行符号结尾。
我们使用 getchar()函数来单字符读取命令依次存储到buf数组,buf数组最后两个符号分别是\0(结束符)和\n (换行符)。
如果输入的命令过长,导致计数器已经到达256了,那么就会报错并退出函数。
1 | void getOrder(char *buf){ |
anaOrder函数
这个函数会解析buf中的命令,所谓解析,就是利用空格符,将buf中的命令一个单词一个单词的拆开,然后存放到wordmatrix当中去。
这个函数的整体架构是由一个双重循环组成的。大循环解析整个命令,小循环提取出命令中每一个word。
首先我们令 数组p和数组q都等于buf数组。
如果p数组一开始就是回车,说明我们什么命令都没输入或者命令已经解析完成,那么就直接跳出循环;如果命令前面字符都是空格,那么我们就从非空格字符的地方开始解析。
当排除了空白输入以及空格符号之后,我们令q=p ,计数器number等于0。然后一直读取到一个单词结束,这时候 number就等于这个单词的长度。接下来我们利用 strncpy 函数将p中的前number+1个字节复制到wordmatrix中属于这个单词的位置当中(*wordcount从0开始)——为什么要number+1呢?因为这时候第number+1个字符要么是''要么是'\n' 因此也要复制进去,方便之后将最后一个字符改成\0结束符。
最后,将单词计数器wordcount加上1,然后令p等于q,相当于砍掉了一个单词。
1 | void anaOrder(char* buf, int* wordcount, char (*wordmatrix)[256]){ |
exeCommand函数
exeCommand函数是整个shell中最关键也是最复杂的函数。因代码过长,我们将其拆分成数个小部分一一分析。
准备阶段
这一部分我们定义了一些变量:
1 | void exeCommand(int wordcount, char (*wordmatrix)[256]){ |
然后,我们通过一个循环将wordmatrix中的每个单词都复制到word指针数组当中去。并将最后一个指针设置为NULL
cd
如果我们命令的第一个单词为cd ,那么我们就看第二个word是什么。如果第二个word是NULL,说明我们的命令就是cd\n那就直接返回;否则我们就利用 chdir这个函数改变当前的目录、转到新的目录,如果返回-1就说明该目录不存在,于是我们调用perror抛出一个错误。
1 | void exeCommand(int wordcount, char (*wordmatrix)[256]){ |
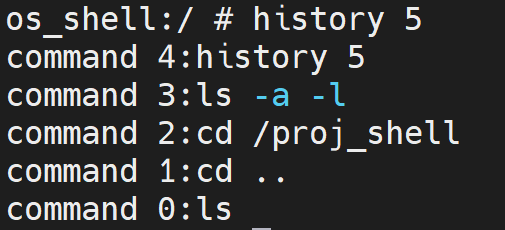
history n
如果我们命令的第一个word 是 history ,那么我们就要显示最近执行的n条指令。 这n条命令在main函数的时候已经被存到msg数组当中去了,我们现在要做的就是个打印的操作。
比如说我输入的命令是history 15,那么这时候 word[1] 就是 (char*)15 ,然后我们就需要将字符数组转换为整数——这里我们使用atoi函数。我们在main函数中用whilecnt来作为 命令的计数器, whilecnt的值就是当前msg 数组中存放的命令数量+1, 所以我们输出的5条是从 whilecnt-1开始计算,一直到 whilecnt-6结束,然后将命令依次打印输出。
注意,history和mytop 既可以创建一个子进程让其运行,也可以直接在父进程中运行。 但是因为我将program命令和shell内置命令放在一个 execommand函数中实现了。 如果这里不创建一个子进程,直接在父进程中运行,那么后面会出现奇奇怪怪的打印问题,因此为了安全和方便起见,我们这里也将其放到一个子进程当中去运行。
1 | if((pid = fork()) < 0){ |
效果如下:
mytop
这个函数需要输出的东西异常的多:
- 总体内存大小、空闲内存大小、缓存大小、总体CPU使用占比
我们用不同的函数来实现这些信息
1 | if(strcmp(word[0], "mytop") == 0){ |
print_memory();
这个函数就是打印出当前主存的使用情况。
首先我们打开 meminfo这个文件:
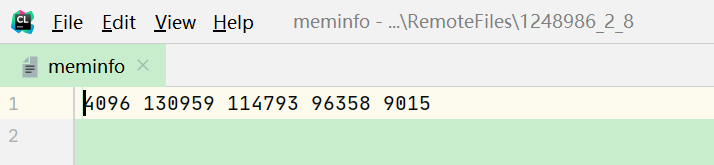
我们发现这里有5个数据,依次是:页面大小、总的页数、空闲页数、最大连续页、缓存页数量
那么这里我们就可以以此计算总的内存、空闲内存、最大页的内存、缓存。计算公式为:$(PAGESIZE * TOTAL)/1024$
1 | int print_memory() |
到这一步,我们可以试试看效果如何:

getkinfo();
这个函数就是读取/proc/kinfo得到总的进程和任务数。首先我们来看看 /proc/kinfo 中的记载的记录:
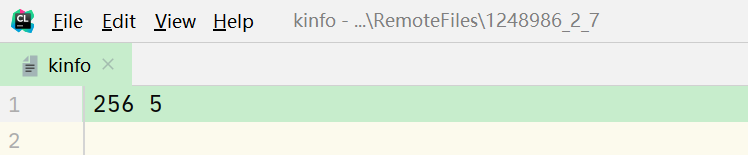
其中,256就代表进程数,5代表任务数量
然后我们将这两个数字读入。并返回 进程数与任务数量 之和。
1 | void getkinfo(){ |
get_procs();
这个函数的作用是将所有需要的信息放在结构数组proc[] 中,每个元素都是一个进程结构体。
首先我们在文件一开始已经定义了一个 proc 结构:
1 | struct proc { |
1 | void get_procs(){ |
parse_dir()
这个函数的作用是获取到/proc/ 下的所有进程pid
也就是获取这些文件夹的名字:
打开/proc文件夹之后,我们用一个循环来遍历目录及其子目录。
首先我们看一下 dirent结构
1 | struct dirent{ |
然后通过一个for循环,依次读取/proc目录下的子目录项,并将目录的名字转换成十进制整数。然后执行parse_file()操作以获取这个目录中的信息。
1 | void parse_dir(){ |
parse_file()
这个函数的作用是获取每一个进程信息,并判断信息是否可用。传入的参数是这个进程的进程号码。将有用的信息传入到一个结构数组中去,这个结构数组就是 之前声明的 *p,里面每一个元素就是每一个进程/任务。
这里我们要分清楚任务和进程的区别,才能在接下来中更清楚得区分他们。 首先,一个进程可能涉及到多个任务,一个任务也可对应多个进程。他们的一些信息都存放在 psinfo文件当中。但是,进程是表示资源分配的基本单位,又是调度运行的基本单位。为了避免重复运算,我们这里计算所有的进程,但是不计算任务。
首先我们设置一些变量。这些变量就是我们接下来要从进程的 /psinfo 读取的。
1 | void parse_file(pid_t pid) |
然后我们通过fopen()函数来读取("r")该进程的/psinfo文件
下面两张图片分别是任务的 psinfo 以及 进程的 psinfo

上图是一个任务,版本是0,类型为T(TASK), 端点是-5,任务名叫做 asyncm,状态是 W(WORK),我们发现在任务下面,动态优先级、嘀嗒、周期、ID都为0,

在这个编号为107的进程中:
版本是 0,(第一次读取)
类型为U(即USER),端点是32859 (第二次读取)
名字叫devmand , 状态是 ‘S’, 阻塞状态为 1,动态优先级为7,滴答为 25,高周期1186,低周期4 (第三次读取)
1 | void parse_file(pid_t pid) |
在这里,我们简单查看一下 各个 task 的名字以及他们的内存,我们发现他们的端点都是负的,原因我还没搞清楚。
我们再打印一部分的进程的信息:

print_procs()
首先我们在一开始定义一个结构体tp,用来存放进程结构体数组和它的嘀嗒
1 | struct tp{ |
这个函数输出CPU使用时间
1 |
|
cputicks
这个函数计算每个进程的运行周期
滴答并不是简单的结构体中的滴答,因为在写文件的时候需要更新。需要通过当前进程来和该进程一起计算
endp
1 | u64_t cputicks(struct proc *p1, struct proc *p2, int timemode) |
后台、重定向、管道
查看是否有 | ,>, >>, < , & 符号
首先我们要给不同的符号打上标签:
- & 后台符号, way = 5
- > 输出重定向 覆盖写 ,way = 1
- < 输入重定向,way=2
- | 管道符号, way = 3
- >> 追加写,way=4
预处理1-分类
1 |
|
格式错误时,例子如下:

预处理2-进一步
1 | void exeCommand(int wordcount, char (*wordmatrix)[256]){ |
switch case
这里我们直接使用了 execvp()来执行一些 ls -a -l 之类的命令
execvp()
定义函数:int execvp(const char *file, char * const argv []);
函数说明:execvp()会从PATH 环境变量所指的目录中查找符合参数file 的文件名, 找到后便执行该文件, 然后将第二个参数argv 传给该欲执行的文件。
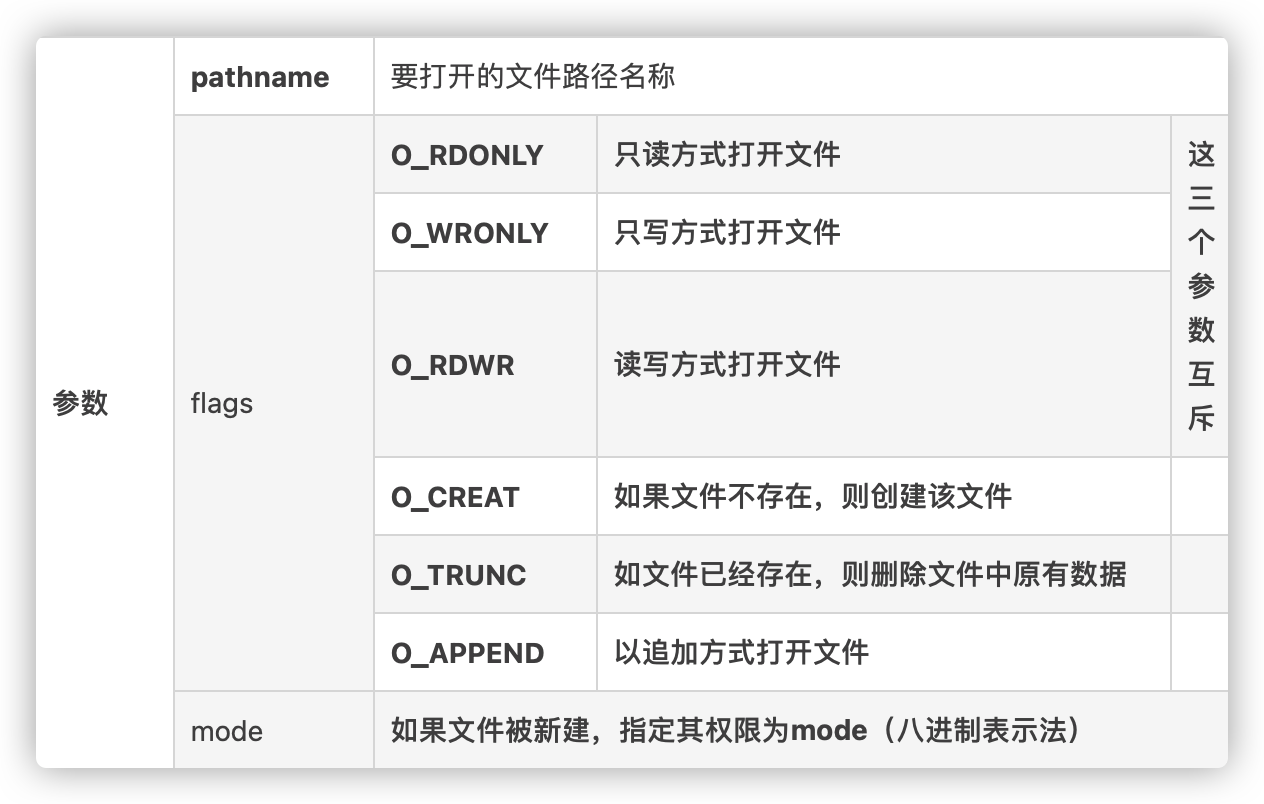
open()
此外我们还要学习一下 open函数的使用方法: open的第一个参数是要打开的文件路径名称;第二个参数是 flag,就是以何种方式打开文件;最后一个参数是 mode,也就是说文件被新建的话,我们要为其指定权限(8进制)
dup2()
dup2也是一个很有用的函数,定义如下:
1 |
|
这个函数的功能就是讲原本要打印在屏幕上的一些信息,写入到指定的文件当中去。 文件描述符的 0 1 2 分别对应着标准输入、标准输出、标准错误。
所以当我 dup2(fd, 1) 实际上是在说我将本来要输出在terminal中的信息重定向输入到fd所指向的文件当中去,在重定向输出中非常有用; 同理 dup2(fd,0) 就代表着本来从terminal中输入的信息重定向到 fd文件当中读入,这对重定向输入非常有用。
1 |
|
checkCommand函数
这个函数的目的就是在 ./ ;/bin;/usr/bin 这三个文件夹下查找可执行的命令文件。比如说在bin文件夹下有很多shell本来就有的命令:
这么多的可执行的命令文件,如 ls,cat,我们的目的就是判断我们输入的命令是否是其中之一,是的话返回1,否的话返回0
1 | int checkCommand(char *command){ |
代码重构
将所有的函数、声明都放在一个文件中不易维护代码,找起来也比较麻烦。因此我们将 main.c 文件拆分成几个头文件:
我们将一些头文件引用、宏和函数定义放到 main.h头文件中,把mytop中要调用的函数放到mytop.h 头文件中,将检查命令函数 放到checkcommand.h 头文件。
最后main.c文件只留下一个while循环,比较简洁直观。
测试结果
cd /your/path
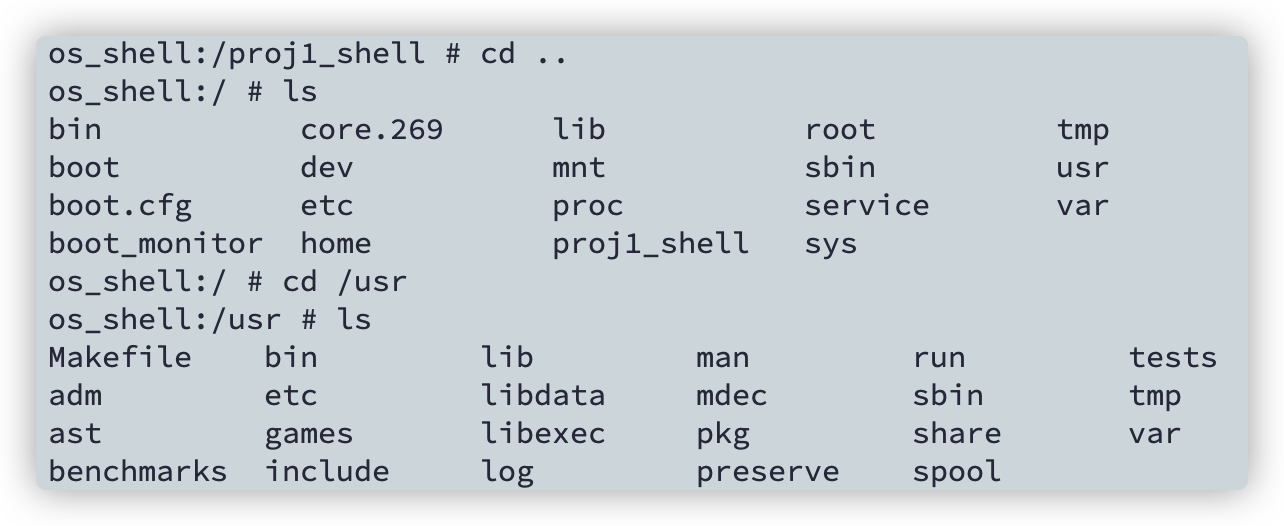
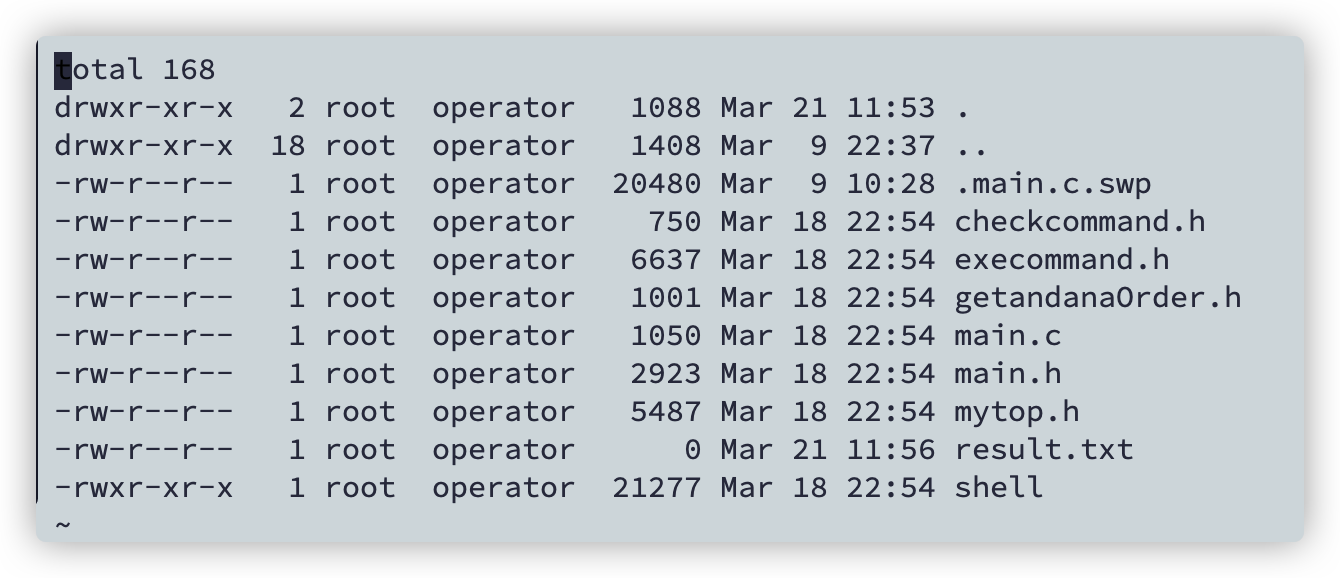
ls -a -l > result.txt+vi result.txt
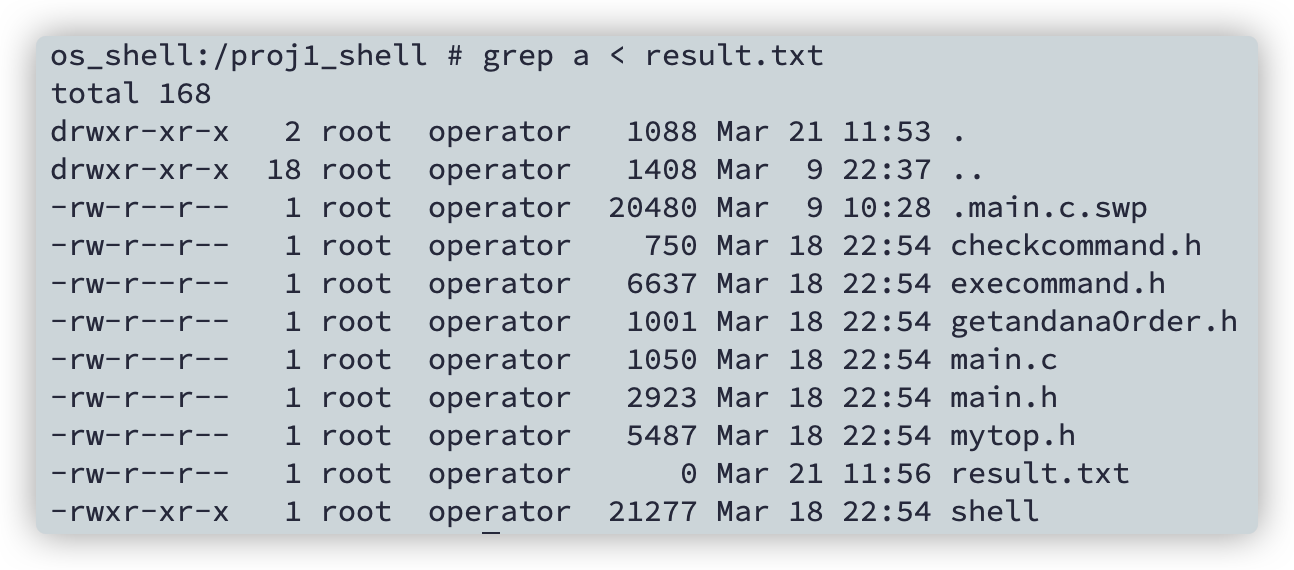
grep a < result.txt
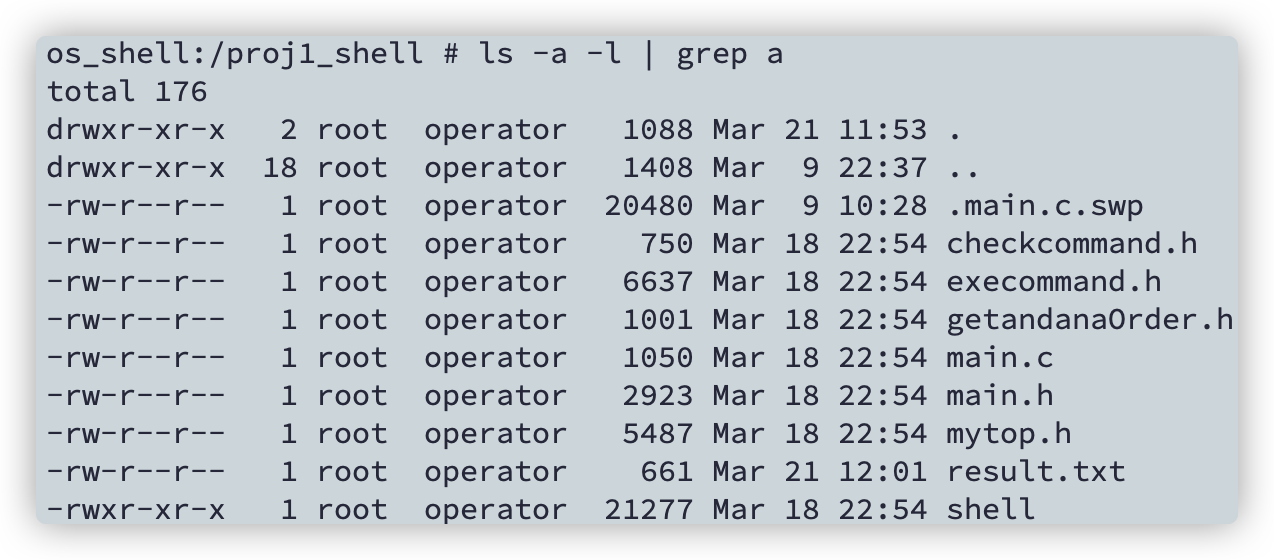
ls -a -l | grep a
vi result.txt &

这边,对 vi 指令进行后台操作,会报错。这是因为 vim 的标准输入和输出必须在一个终端当中。将其丢到后台去执行是不对的。
mytop

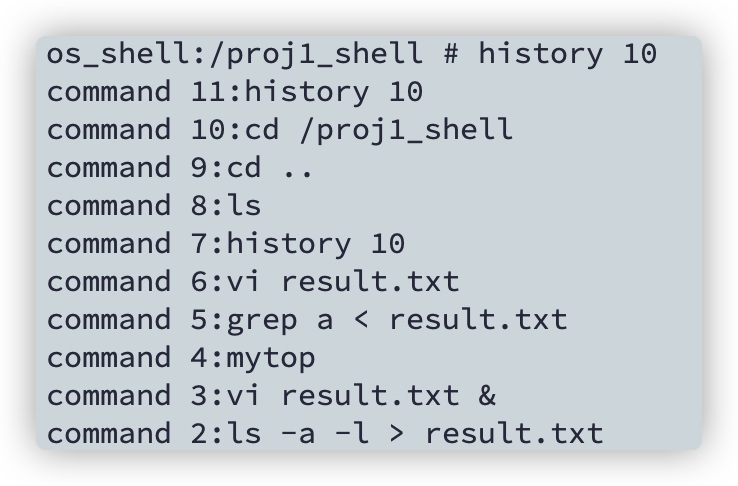
history n
exit

总结
这个project 的工程量很大。而且实现起来是比较困难的。因此,如何将整个project拆分成一个一个小任务就显得尤其重要。我先实现了 cd、mytop、history n 这类shell内置命令。然后再实现了 | ,\& ,> ,>> 等 Program命令。
此外,如何调试文件也显得十分重要。为此我尝试了很多工作流,最后选择了 mac中的Terminus、Transmit软件 远程连接 windows上开的Minix虚拟机,并通过clion修改、编写代码。这样虽然比在windows上直接连接繁琐一点。但是在mac下各种安装不了虚拟机的情况下,这已经不失为一种高效的解决方法了。
不足
没有实现 mytop 的实时更新
没有实现 多重管道
在未来需要继续完善。