Java基础3
Exceptions
What are Exceptions
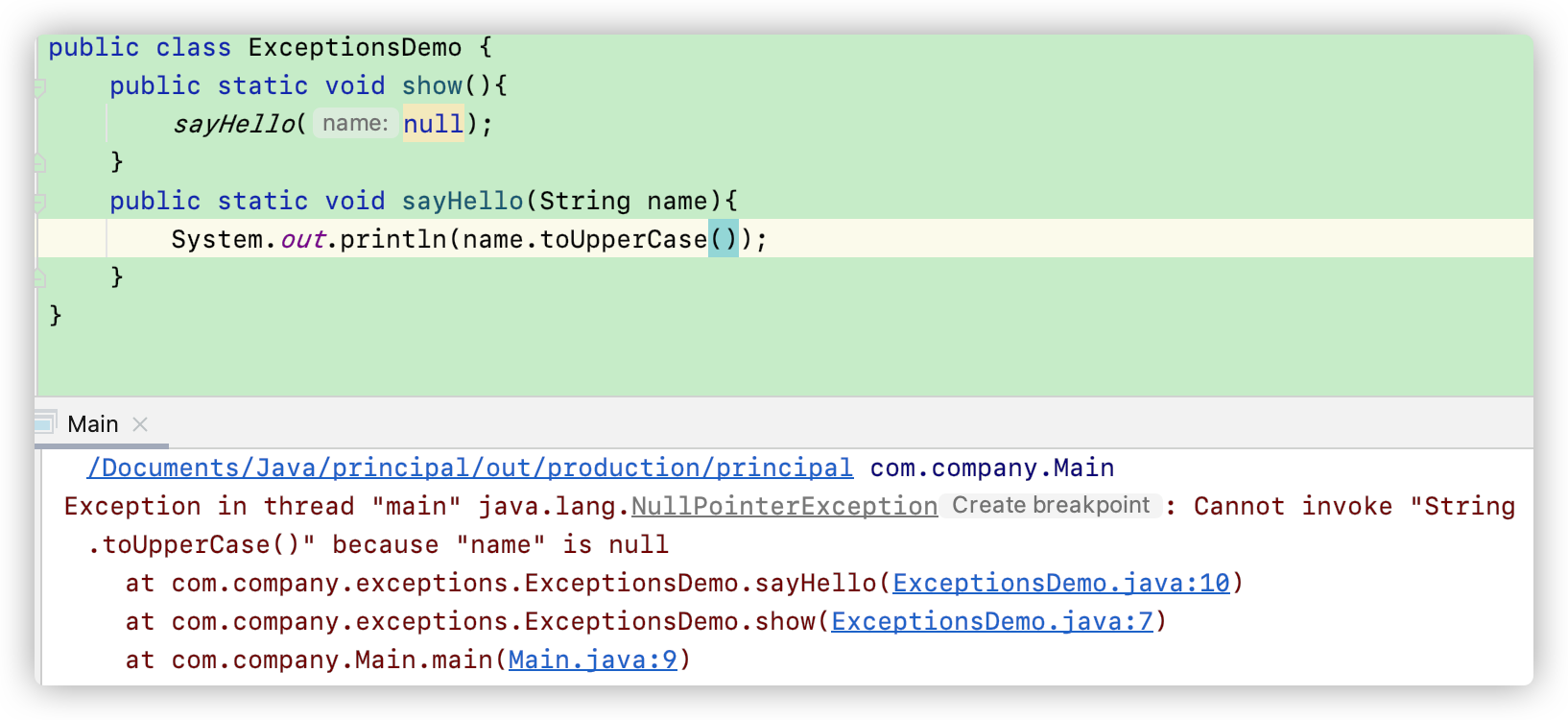
当我们调用一个将字符串变成大写的函数、传入的却是一个空指针。运行后Java就会给我们一个报错: “name is null“ 。
Java给我们的报错信息非常有用,因为他能帮我们将发生错误的每一句代码都列出,并且一直到最深处。
Types of Exceptions
Checked exception
比如说我想读取一个文件,但是这个文件刚刚被删掉了,这时候就会报错。Java 强迫我们在写这类代码的时候一定要做检查,是否存在该文件。否则在编译 的时候就会报错
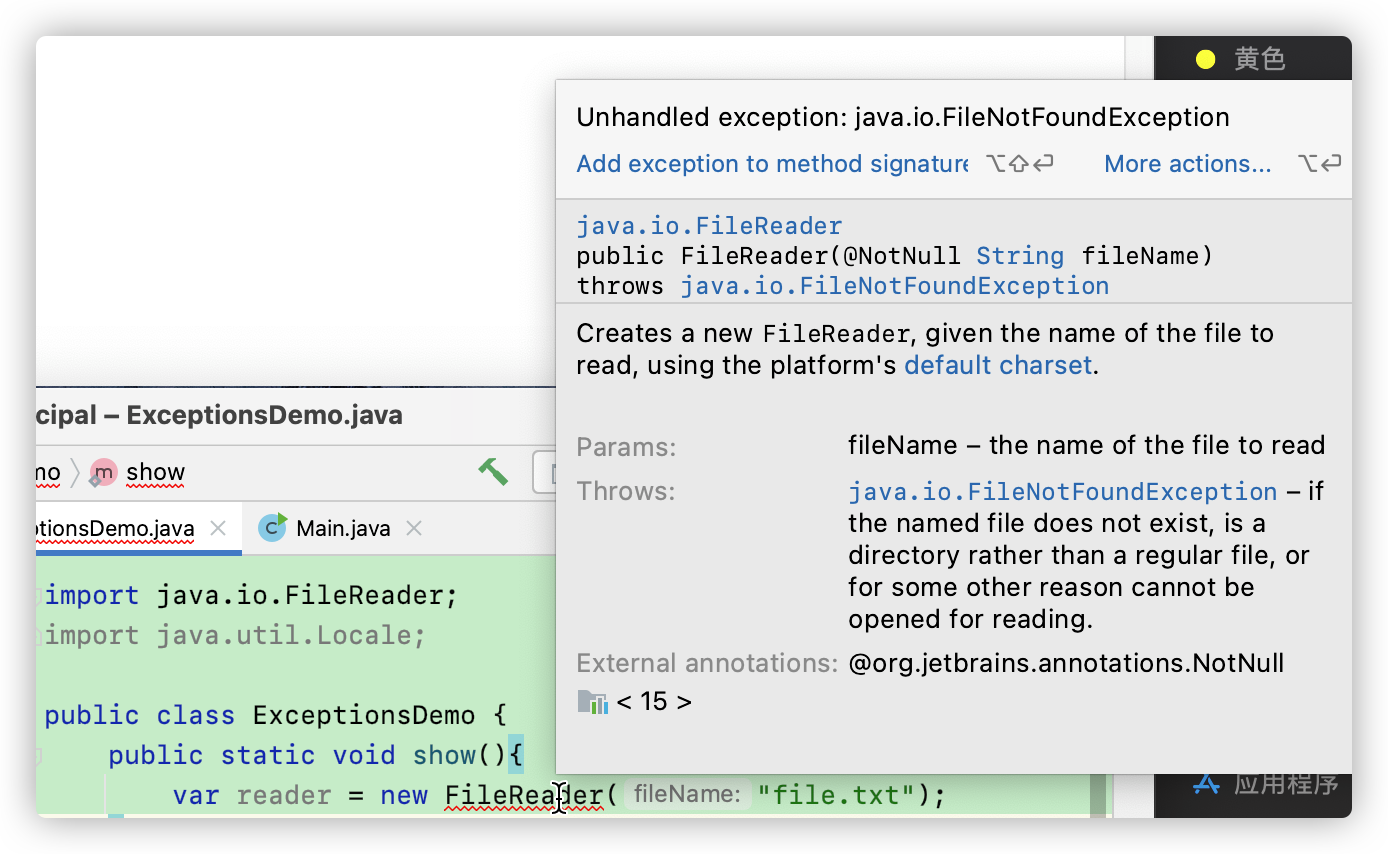
当我们新建了一个FileReader对象、要打开一个 file.txt文件时,Java会提醒我们要为其添加一个 exception,否则连编译都过不了。包括接下来我们要学的线程中的 sleep()、join()函数。
Unchecked exception/Runtime exception
如同我们刚才讲的例子: NullPointerException 还有其他几种 Runtime Exceptions ,它们不会在编译前就报错。因此我们要养成良好的编程习惯以及积累经验来规避这些问题
- ArithmeticException
- IllegalArgumentException
- IndexOutOfBoundsException
- IllegalStateException
Checked 和 Unchecked Excption 主要区别在:
- Runtime exceptions:
- 在定义方法时不需要声明会抛出runtime exception;
- 在调用这个方法时不需要捕获这个runtime exception;
runtime exception是从java.lang.RuntimeException或java.lang.Error类衍生出来的。
- Checked exceptions:
- 定义方法时必须声明所有可能会抛出的checked exception;
- 在调用这个方法时,必须捕获它的checked exception,不然就得把它的exception传递下去;
从逻辑的角度来说,checked exceptions和runtime exception是有不同的使用目的的。checked exception用来指示一种调用方能够直接处理的异常情况。而runtime exception则用来指示一种调用方本身无法处理或恢复的程序错误
Error
第三种是我们束手无策的错误,比如写了个无限循环,或者是内存溢出了。我们必须规避这种低级错误。
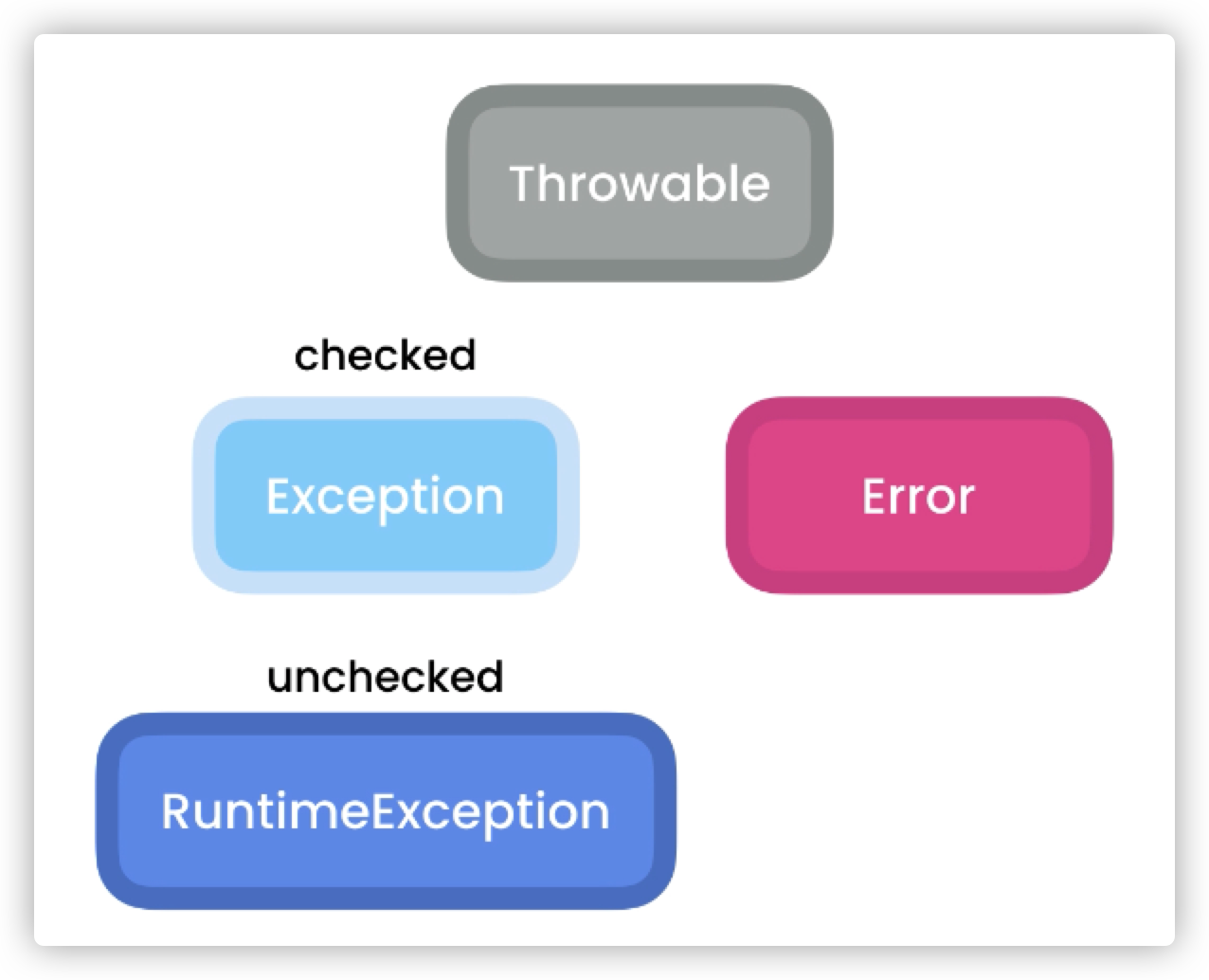
Exceptions Hierarchy
现在我们来看一下 Exception 的组织结构。首先,最上层的是 Throwable Class ,这个class中包含了Exception class和Error两个类。 Exception 类中又包括 RuntimeException class 也就是unchecked Exception
Catching Exceptions
对于 checked exception, 我们可以用 try-catch 代码块来捕捉错误:
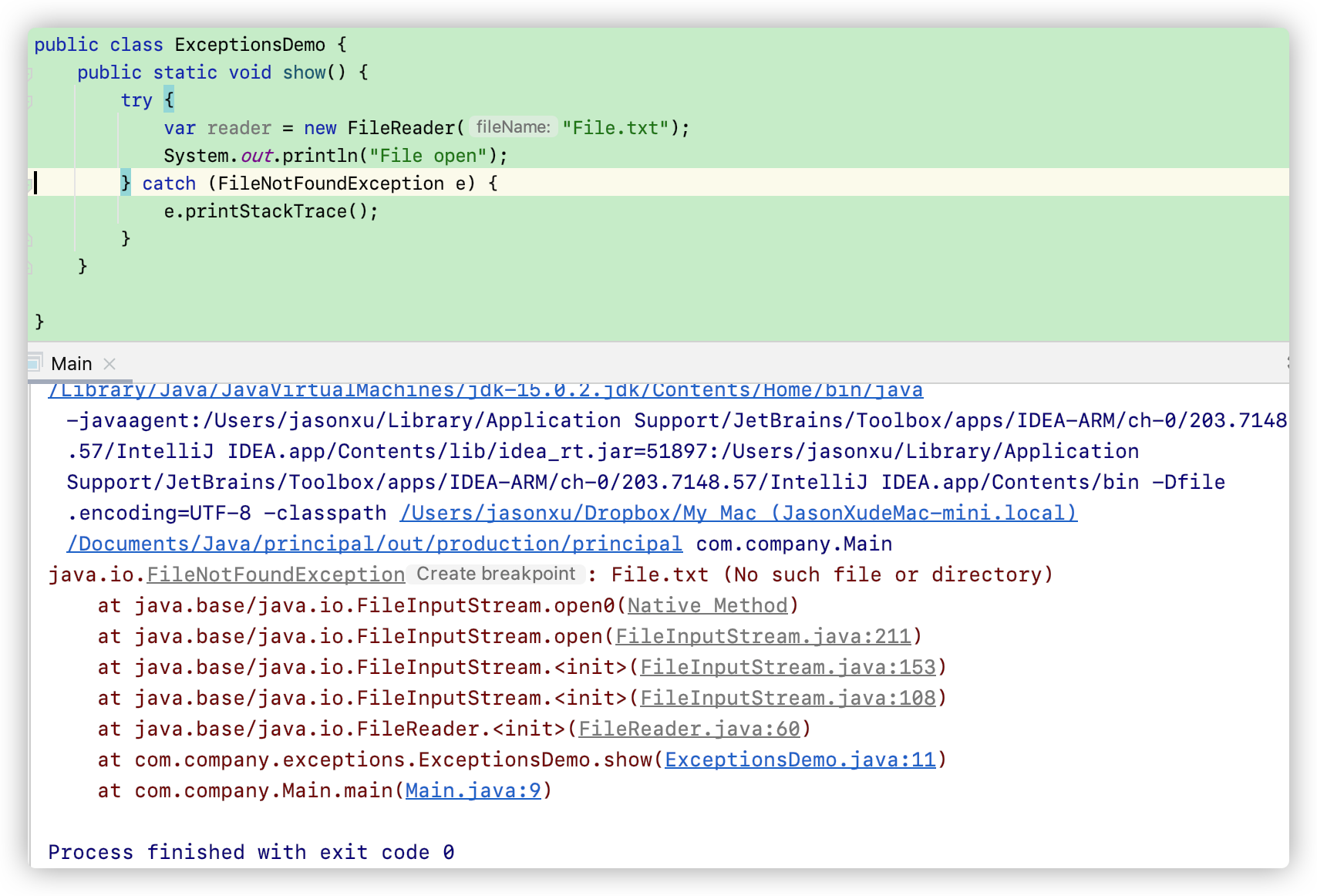
这样既可以打印 StackTrace来帮助我们找到错误,又可以让整个程序正常结束。最终,问题出在 Java.io库中的open0函数。
Catching Multiple Types of Exceptions
1 | public class ExceptionsDemo { |
如果我们想要捕捉多个 Exception,我们可以使用多个 catch块。如果报错的信息是一样的,我们还可以用 或 运算符将它们放在一起。
注意,IOException 这个 catch block不能放到前面,否则会报错:因为IOException 包含了所有输入输出的错误,是一个“兜底“的类,如果将其放在第一个,就导致FileNotFoundException被IOException处在的代码块率先捕捉了。
The finally Block
如果reader成功打开、我做好处理之后,想要把文件关掉,这时候应该怎么写?
我们应该把 reader.close()放在try代码块中吗? 显然不行,因为如果try成功打开了文件,但在var value = reader.read();时抛出了一个错误,会直接跳到catch块,try后面的代码就不再被执行了。
我们应该直接把 reader.close()放在catch之后吗? 貌似也不行。因为这样如果在未来我们在try-catch 和 close两者之间插入新的代码,并抛出新的错误的时候,reader还是不会被正常关闭。
因此,我们应该使用 finally block.
1 | public class ExceptionsDemo { |
finally在try代码块正常被进入执行,jvm正常执行处理的情况下,是一定会被执行的。 如果在 try block中存在return;那么finally的执行时间是:retrun表达式执行之后,在return返回操作之前。
The try-with-resources Statement
但是像刚才那样写finally block 会比较丑。我们有更好的方法来实现: 就是将申明对象、打开文件都放到 try后面的括号当中,如下:
1 | public class ExceptionsDemo { |
这种方法叫做 try-with-resources Statement,这样一来,我们就不用显式地写 close() 了,jvm会自动帮我们生成和上面的finally block一样的代码。
https://docs.oracle.com/en/java/javase/16/docs/api/index.html
在官方的文档中,我们可以找到AutoCloseable这个接口,这个接口下所有的子类都可以用这种try-with-resources Statement方法来自动关闭。比如说:FileReader、FileWriter这样的类。
Throwing Exceptions
之前我们做的都是找到错误、抓住错误,但是现在我们要来主动抛出一个错误。
首先我们来讲 defensive programming ,也就是说遇到了错误,我们主动抛出并终结整个程序,如:
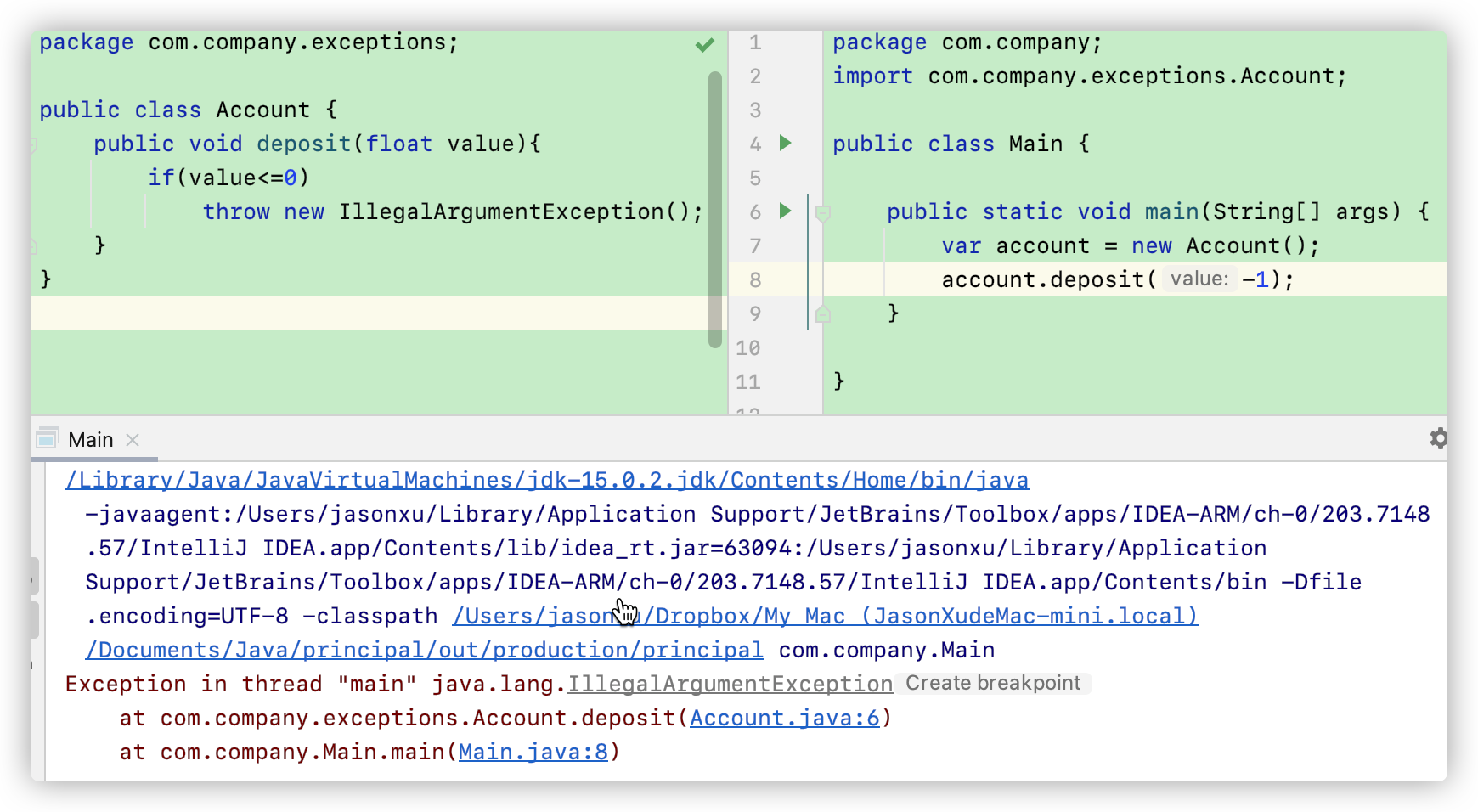
我们新建了一个类,这里面会对value值进行一个判断,如果value小于0,就会抛出一个 IllegalArgumentException()错误,并结束整个程序。
如果我们的程序对value值得符号要求很高,如果输入不合法的值对整个程序的性能造成很大的影响(如库、框架等供多人使用的程序),那么我们就应该适用这种 defensive programming 的方法,严格要求。
那么如果要throw一个 Checked Exception,该怎么写呢?比如说我在 Account 账户中抛出一个 IOException()这类异常,然后我必须在main函数中做一个 try-catch block 来接住这个exception
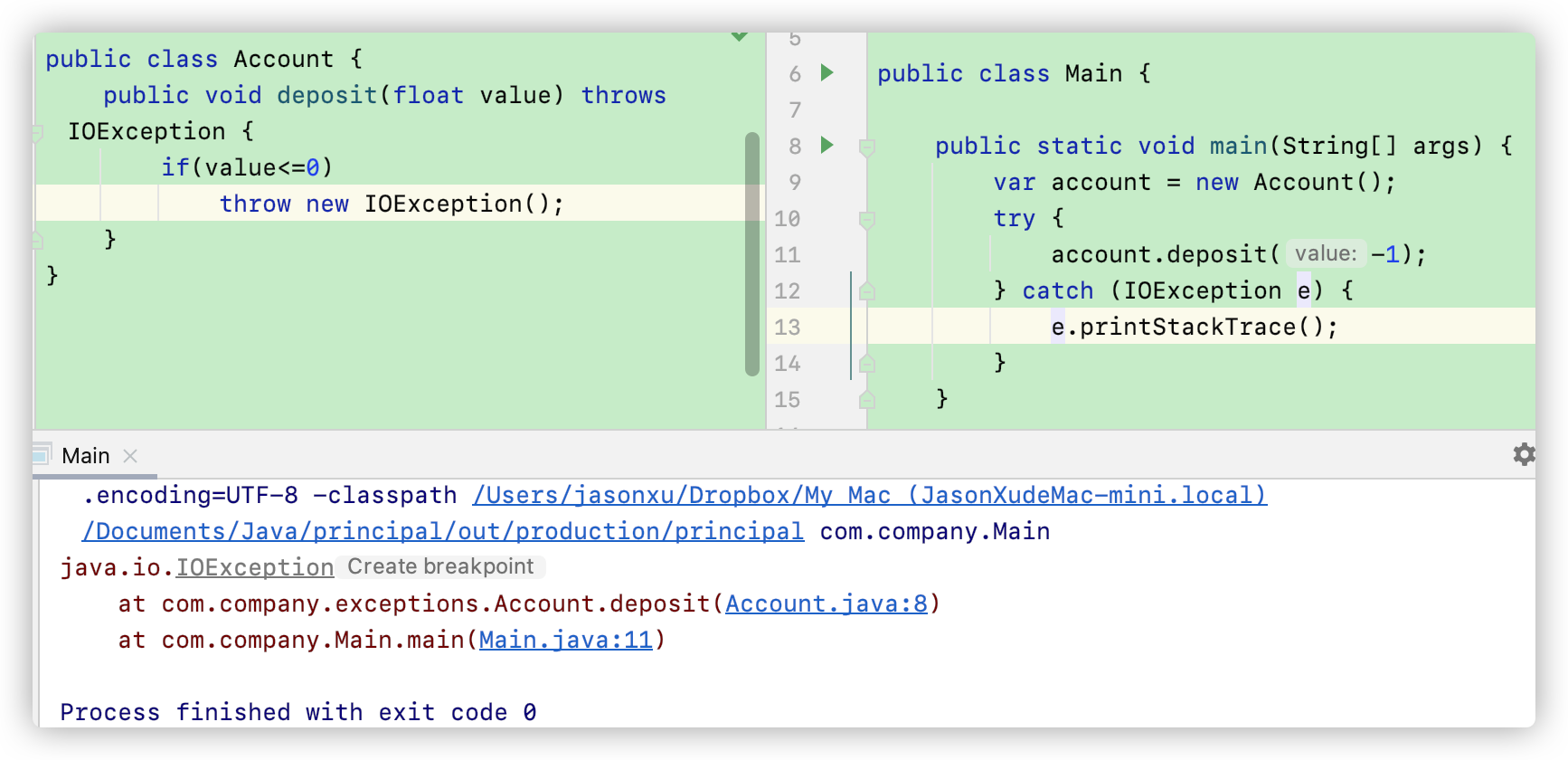
注意了,在 Account 类中的 desposit 函数如果要抛出一个 IOException的话,必须在函数声明后面标明:throws IOException来告诉调用方我这个方法可能会抛出一个异常,而你调用者需要接收。
Re-throwing Exceptions
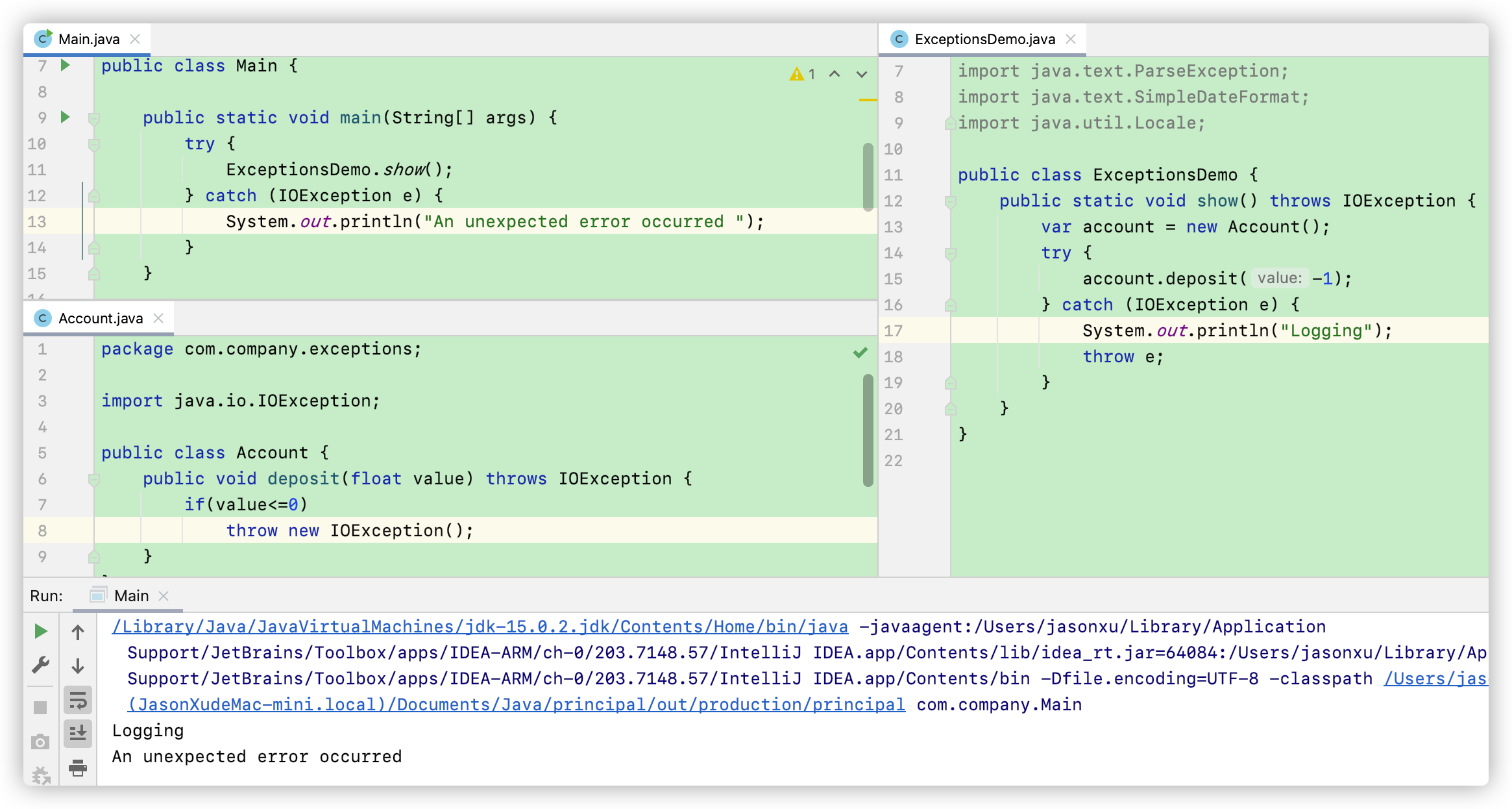
现在我们在 ExceptionDemo 中接收 Account 抛出来的信息,然后再main函数中调用 ExceptionDemo.show(), 如果我现在希望ExceptionDemo收到异常信息后能将 StackTrace 记录到日志,并让main函数向用户打印一个有好的信息,应该怎么办?
这时候,我们应该 Re-throwing ,也就是说在收到Account 发出的异常信号的时候,ExceptionsDemo再向它的调用方(也就是main) 抛出一个错误,类似于一个接力的效果。然后在main中用try-catch 接收信号并打印一些信息:
Custom Exceptions
Java已经为我们提供了很多基础异常类了,但是有些时候我们还是需要为我们的项目客制化一些异常。
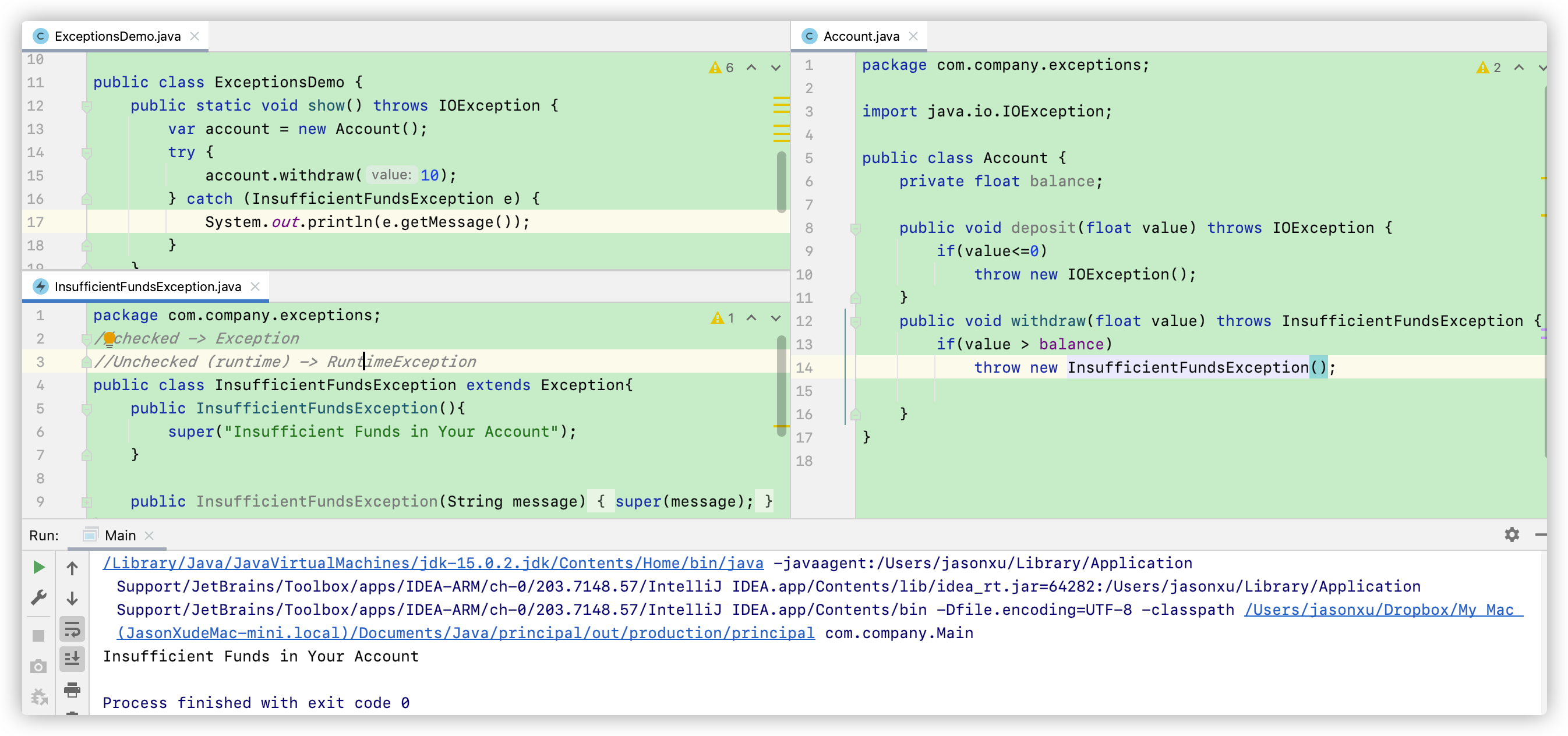
比如说刚才那个例子,我在Account 中设立一个 withdraw(取钱的函数),方法逻辑是:如果要取出的钱大于账户余额,那么就抛出一个异常。但这时用java提供的标准异常也不太贴切,因此我们可以自定义一个异常。
首先我们要创建一个自定义的异常类,异常类要以 Exception作为结尾,要有辨识度。然后我们要决定这个异常类是属于 checked exception (继承Exception类) 还是 unchecked exception (继承RuntimeException类),然后
继承Exception 类之后,我们要自定义异常警告。因为 异常类是一个有参构造函数,因此我们还需要设置super("异常信息") 。这里我们也提供了两种构造函数,一种默认构造函数直接设置异常信息为 Insufficient funds in your account, 第二种则是让调用者自定义报错信息的有参构造函数。
Chaining Exceptions
Chaining Exception 就是将一个更广泛的异常包裹一个比较具体的异常。那刚才的例子来说,我们有一个比较具体的异常: InsufficientFundsException() 但是造成取钱失败的异常还可能有很多种,因此我们可以创建一个更加广泛地异常类 AccountException() :
1 | package com.company.exceptions; |
然后在 Account 类当中,当取款大于余额的时候,我们会向上抛出一个 AccountException类,并在这个类中传入原因:InsufficientFundsException,告诉调用者这是因为余额不够导致的账户异常。这就是 chain exception
1 | public class Account { |
在ExceptionsDemo类中,我们捕捉一个 AccountException类,然后通过 e.getCause() 获取AccountException中的异常类型并通过getMessage()打印出改原因的异常信息。
1 | public class ExceptionsDemo { |
Generics
泛型就是参数化类型
- 适用于多种数据类型执行相同的代码
- 泛型中的类型在使用时指定
- 泛型归根到底就是C++中的“模版”
The Need for Generics
比如我创建了一个 List() 类,如下:

那么如果我想创建一个 User 类的List,就要创建一个新的 UserList 类,久而久之,类就变得很繁杂。这时候我们就需要用到泛型了。
A Poor Solution
遇到这种情况,使用 Object Class 是一种下策。因为虽然 所有的类都继承自Object类,但是有很多缺点
- 比如我向Object List中存放了很多的元素(如Integer.valueOf(1)), 现在我想通过get 取出 List当中的第一个元素,但是这时候返回的类型是 Object,要得到int类型的返回结果我们必须进行强制类型转换,否则就会造成报错。
- 此外,List的管理会变得比较混乱,我们会搞不清楚 List中到底存储着什么类型的数据。
Generic Classes
我们新创建一个 GenericList 类,需要在尖括号中一般使用 E或者T 来代表种类。
这里我们声明一个 类型为 T 的数组,因为我们没有办法直接 new T[10],因为我们不知道传进来的是 int还是string,没办法实例化。这里我们必须创建一个 Object数组然后将其用强制类型转换变成 T 类型。
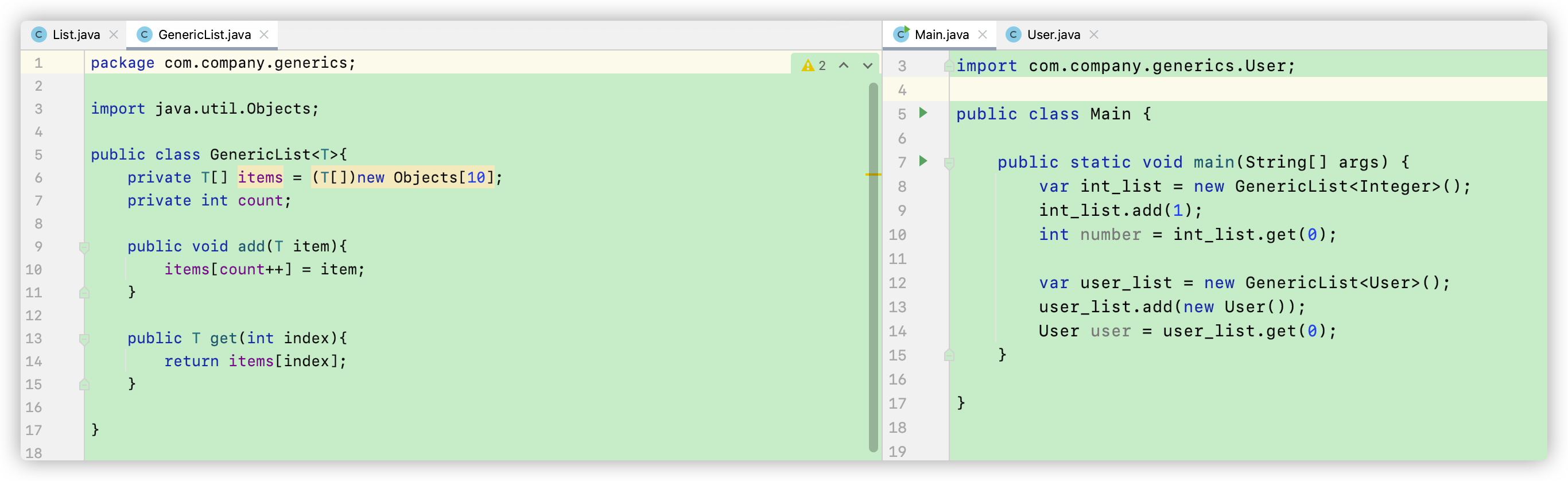
然后 我们在main函数就可以声明各种类型的 list了,注意在声明的时候要传入数据类型,而且调用get()方法的时候也不用进行强制类型转换了。
Generics and Primitive Types
在声明泛型类实例的时候,我们不能穿入 Primitive Types,即 int, boolean,float 之类
如果我们要将这些类型的数据存入到泛型类实例当中,我们就必须要使用到 Wrapper class
Java中每一个 Primitive Type 都有一个对应的 Wrapper class(包装类)
- int -> Integer
- float -> Float
- boolean -> Boolean
Constraints
如果我们只想让我们的泛型存储数值类型的数据,那么我们可以让 <T extends Number>
所有的包装类(Integer、Long、Byte、Double、Float、Short)都是抽象类 Number 的子类。
| 包装类 | 基本数据类型 |
|---|---|
| Boolean | boolean |
| Byte | byte |
| Short | short |
| Integer | int |
| Long | long |
| Float | float |
| Double | Double |
这时候,我再创建一个 String 类型的泛型实例就会报错了。
除了extends Number 之外,我们还可以 extends Comparable ,也就是只能使用可比较的数据类型: String, Integer等,但是如果我们直接传入 User,就会报错,因为我们自己申明的User类暂时是不能比较的。
要想 User能够比较,我们还需要在声明 User 类的时候让其 implements Comparable,如下:
1 | public class User implements Comparable<User>{ |
注意了,这里要在 Comparable后面用尖括号写上User,然后让Idea自动生成一个 compareTo 的重写函数,这样重写函数中的参数就是User,否则就是Object,而Object范围太广,不太安全。
还可以是 extends Cloneable,是另外一个很有用的接口。比如:<T extends Comparable & Cloneable >
Type Erasure
现在我们在底层看看泛型是怎么实现的。
我们首先看看没有限制条件的 Generics 的 Bytecode:
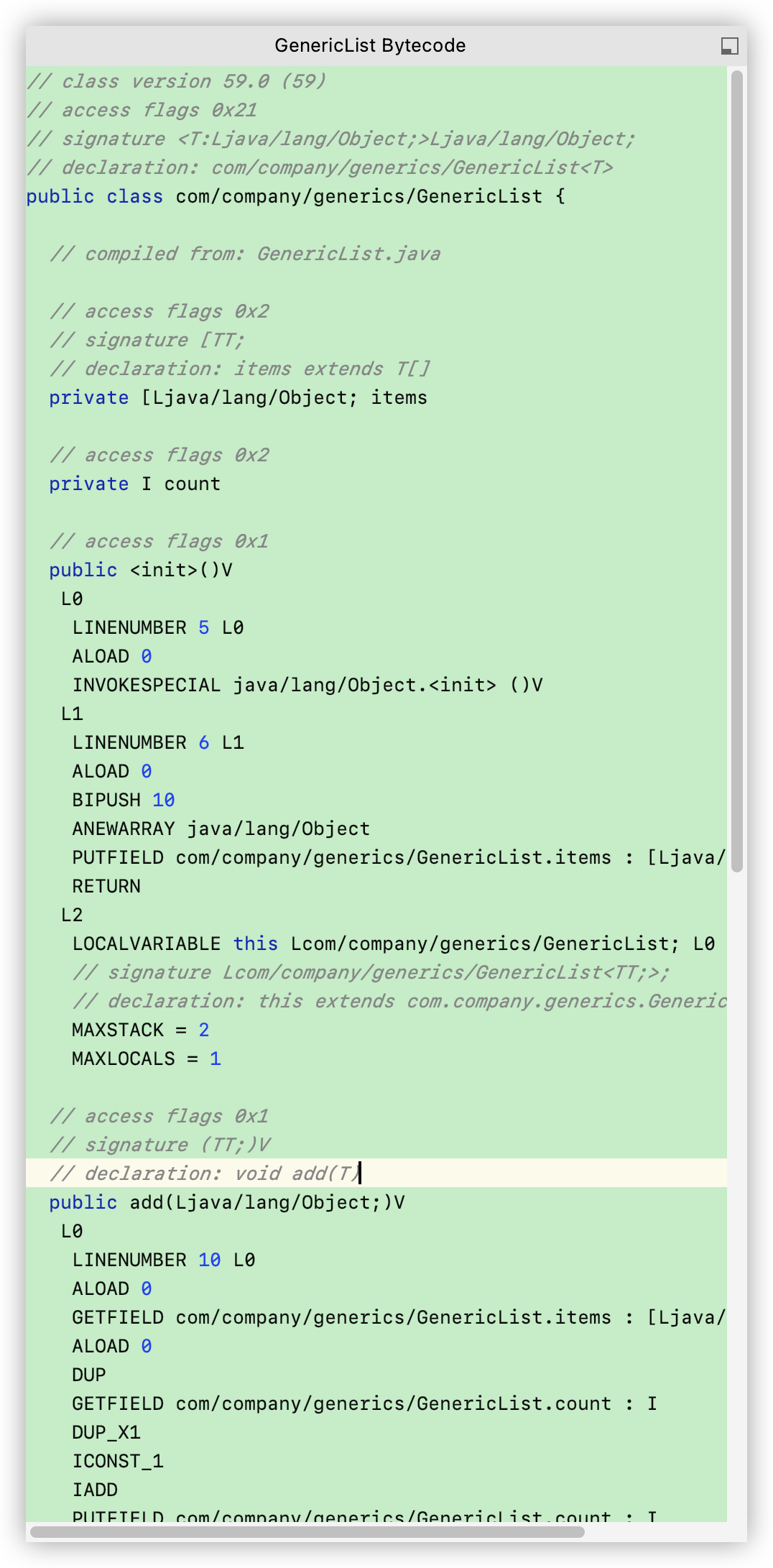
我们发现在ByteCode里面,我们声明的T类型的数组都变成了 Object数组。 也就是说和我们一开始自己写的Object数组是一样的,那么泛型和Object数组的区别在哪里呢?
在于编译的时候Java会帮助我们检查数据类型是否正确,而自己写的Object数组则不会判断,我们可以传入数字也可以是实例化的对象。因此,泛型更便于我们对数据进行管理。
当我们对泛型做出限定的时候,如 Comparable、Number, ByteCode中数据类型也会从Object变为Number、Comparable等。
Comparable Interface
https://docs.oracle.com/en/java/javase/16/docs/api/java.base/java/lang/Comparable.html
我们上面说了,可以通过 User implements Comparable来把User类变成可比较的类,注意了,这里我们要传入比较的数据类型,否则Java会默认是两个Object在做比较。
如下面这段代码,我们在User里面创建一个points的变量,然后对其进行比较。
1 | package com.company.generics; |
在main函数中,我们就可以对两个User实例进行比较
1 | import com.company.generics.User; |
Generic Methods
除了泛型类,还有泛型方法。 在使用限定词的时候,类是 implements, 而方法则是 extends
比如我创建一个 Utils 类,里面有一个max方法,用来返回两个对象中较大的那一个:
1 | package com.company.generics; |
在函数定义时,需要在尖括号中写 <T extends Comparable<T>> 返回数据类型也为T,然后利用compareTo 函数来比较二者的大小:
1 | public static void main(String[] args) { |
结果输出的却是这样的结果:com.company.generics.User@3f99bd52
是因为返回的对象调用 toString()函数,因此输出了一个hashcode,要解决这个问题,我们需要在 编写 User类的时候重写 toString() 函数
1 | public class User implements Comparable<User>{ |
再次运行得到: User{points=20}
Multiple Type Parameters
不管是泛型类还是泛型方法都可以传入多种不同类型的参数,我们各给出一个例子:
泛型类
这里我们创建了一个 键值对的类,K 代表key的数据类型,V代表value的数据类型
1 | package com.company.generics; |
同样的,对于方法我们也可以使用多个类型
1 | public static <T,V> void print(T key,V value){ |
Generic Classes and Inheritance
当我们用一个类来继承泛型类的时候,关系可如下图所示:
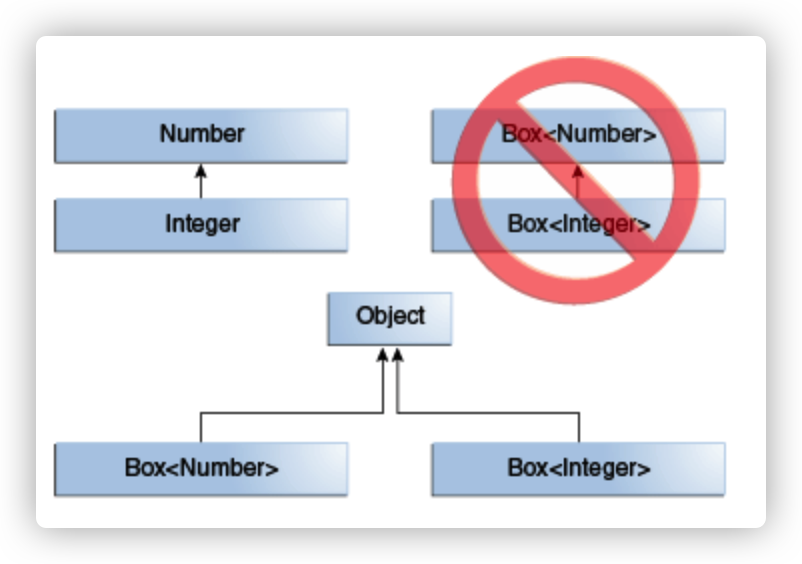
也就是说Integer继承了Number,在一般的实例中,Number 是可以接收 Interger类型的参数的;但是在泛型类的实例中 如Box<Number> 只能接收数据类型为Number的数据,不接受 Box<Integer> 和 Box<Double>的参数。
所以说在泛型类中,虽然传入的类之间存在继承关系,但是他们的泛型类是不存在继承关系的。原因在于它们都继承自Object类型,但是二者相互独立。
我们用刚才的例子看一下:
首先我们创建一个 Instructor 类,并让其继承自User 类
1 | package com.company.generics; |
然后我们在Utils中声明两个方法,一个是普通的 printUser方法,另一个则是接收 GenericList<User> 的printUsers方法
1 | public static void printUser(User user){ |
结果在 main 函数当中,可以用printUser来打印一个 Instructor实例,但是不能用 printUsers来打印一个 GenericList<Instructor> 实例:

为了解决这个问题,我们可以用Wildcards(术语叫通配符,其实就类似于扑克中的万能牌)
Wildcards
我们可以将 printUsers方法这样写:问号就是通配符,代表着一个unknown的数据类型。
1 | public static void printUsers(GenericList<?> users){ |
这样虽然解决了问题,但是这样一来,我们可以向 printUsers传入任何数据类型,比如Integer,String等,把他们当做Users打印出来显然是不行的。因此在使用通配符之后还需要加上限定条件
? + extends
当我们使用了通配符 ?之后,相当于java创建了一个我们看不见的 类叫做 CAP#1 用来存放未知的数据类型。 因为可能有多个通配符,所以CAP后面的编号也不同。
如果我们用 ?+extends User 的话,就相当于 Class CAP#1 继承了User,而 Instructor 也是继承User的,因此这时候可以向printUsers传入 User以及它的子类,而不能传入 Integer、String这种数据类型了。
1 | public static void printUsers(GenericList<? extends User> users){ |
比如这里我们可以用 User来接收get函数的返回值,因为User是 Cap#1的父类,但是不能用Instructor来接收,因为Instructor和Cap#1是”兄弟“关系,是独立的两个类。
但是,我们不能在这里使用 add()函数。因为CAP#1是个抽象概念,我们没有办法实例化一个CAP#1对象并将其加到Users当中去。
因此如果选择 ?+extends 对象是只读不可写的
? + super
super和extends则是刚好相反。只可写不可读
在使用了super关键词后,?相当于 User类的父类,也就是 Object Class
因此GenericList<? super User> users 之后,Java会把users看做是:GenericList<Object> temp 这个对象
这时候我们调用 add方法,因为添加的对象都是Object的子类,因此不会报错。然而我们却无法使用get方法了,因为这时候get的返回类型为Object,但是Java并不知道你用什么类型来接收。很可能两种数据类型是不兼容的,因此不能使用:
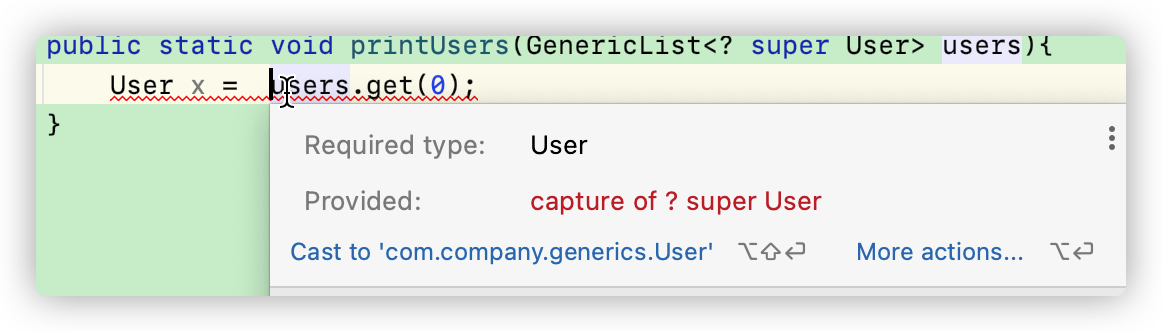
| 总结: | 可读 | 可写 |
|---|---|---|
| ?+extends | √ | × |
| ?+super | × | √ |
Collections
提到集合就不得不提一下数组,好多集合底层都是依赖于数组的实现。数组一旦初始化后,长度就确定了,存储数据对象不能达到动态扩展,其次数组存储元素不便于对数组进行添加、修改、删除操作,而且数组可以存储重复元素。这个时候集合对作用显现出来了。集合分为Collection和Map两种体系。Collection的集合类的继承树如下图所示:
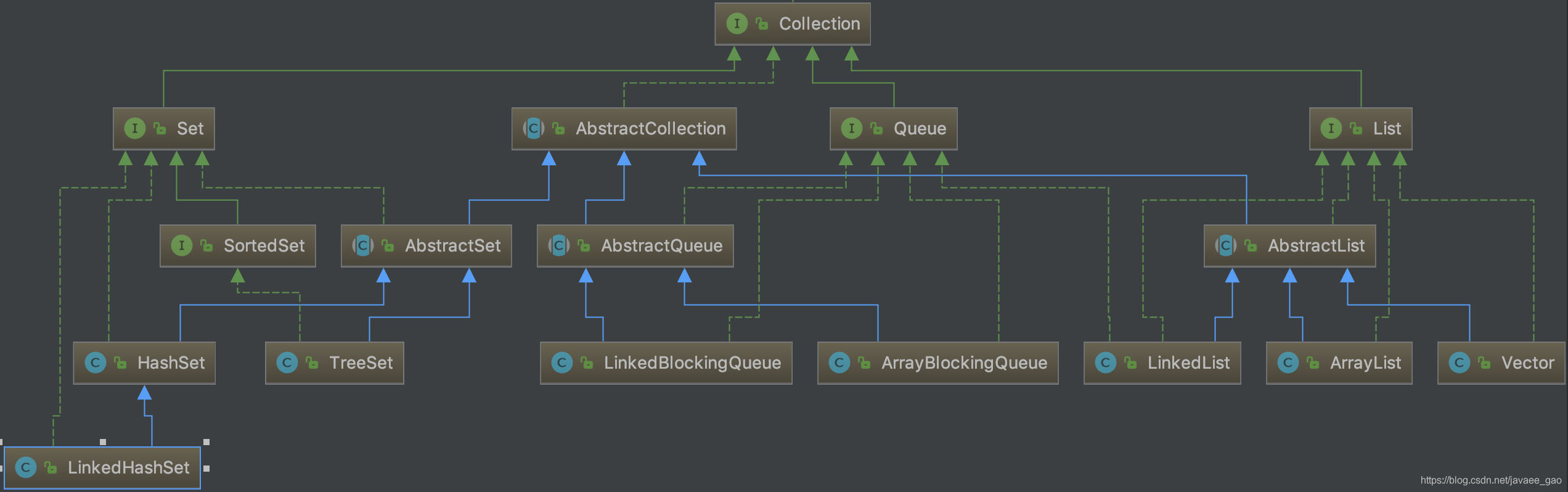
化简可得:
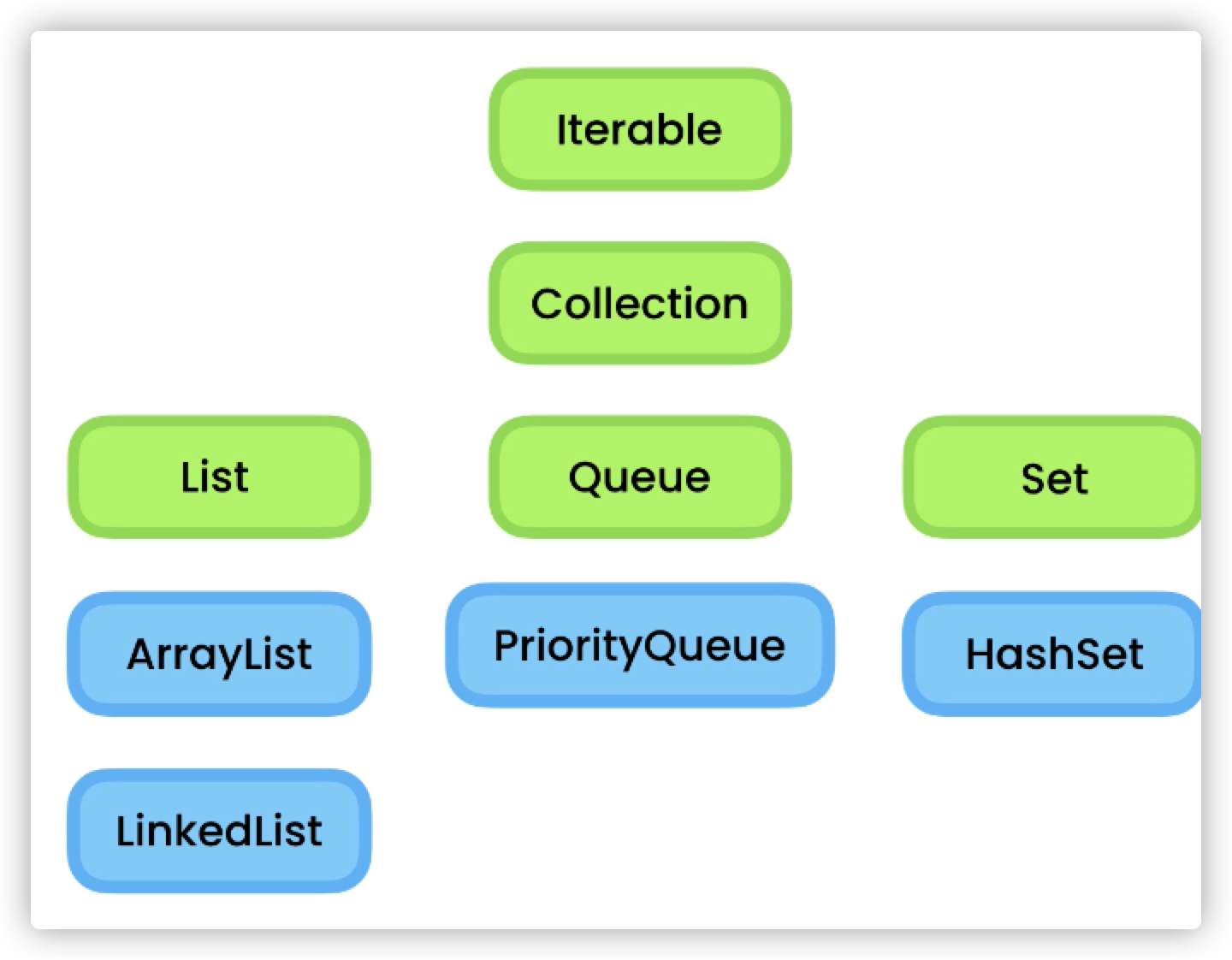
Collection 接口有 3 种子类型集合: List、Set 和 Queue,再下面是一些抽象类,最后是具体实现类。常用的有 ArrayList用来当数组用,LinkedList即链表;在Queue下常用的是PriorityQueue,即优先队列;在Set下常用 Hashset 用来做哈希映射。
简单的来说,Java中的collection类似于C++中的stl,有多种封装好的数据结构。
The Iterable Interface
下面是 Iterable的官方文档:
https://docs.oracle.com/en/java/javase/16/docs/api/java.base/java/lang/Iterable.html

在这个接口中一共有三个函数,我们要重写iterator()这个函数,因为这个函数会返回一个迭代器对象。迭代器的数据类型取决于泛型对象的数据类型
当一个类继承了 Iterable之后,他就可以被迭代了。这里,我们先用自建的代码来模拟 ArratList 。这里我虽然重写了Iterator但是没有写任何代码,只是为了做个演示。
1 | public class GenericList<T> implements Iterable<T>{ |
在main函数中,我们用iterator来接收迭代器,这里返回的是一个String 类型的迭代器。
iterator中两个内置方法很重要,一个是 hasNext(), 也就是用来判断是否存在下一个元素;还有一个是next()即让迭代器指向下一个元素。使用while循环,可以遍历对象中的所有元素。(虽然hasNext()和next()我暂时还没有重写)
1 | public static void main(String[] args) { |
其实,while循环可以这样来简化:
1 | for (var item : list){ |
在底层的bytecode都是一样的。
使用了Iterable接口,我们就没有必要在GenericList类中将 private T[] items设置成 public T[] items,照样可以迭代。
The Iterator Interface

现在我们继续实现我们自建的 GenericList,刚才只是说了我们可以实现什么功能,但并没有将方法都写出来。
首先我们要在 GenericList中创建一个新的类,叫做ListIterator, 这个类讲接入 Iterator接口并重写 hasNext()、next() 两个函数。并让GenericList中的 iterator方法的返回一个 ListIterator对象
1 | public class GenericList<T> implements Iterable<T>{ |
这样,一个建议的ArrayList就做完了,我们可以测试一下让其遍历输出:
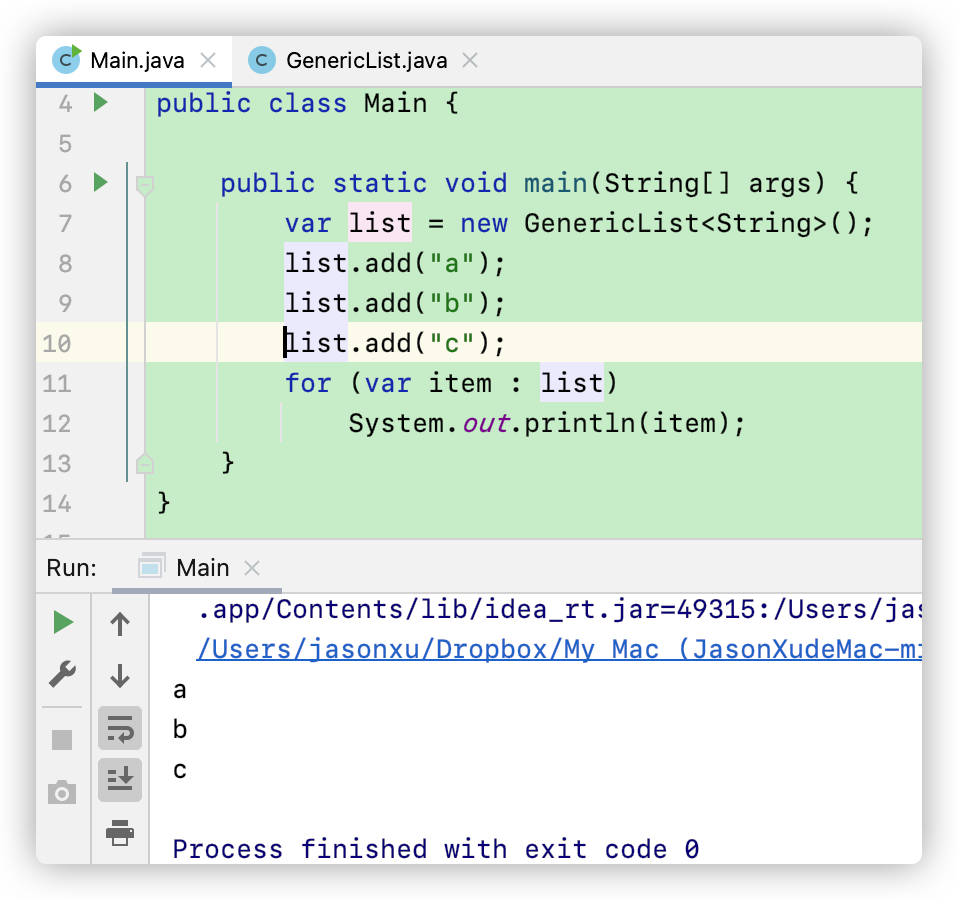
The Collection Interface
学会了ArrayList原理之后,我们正式来讲讲 Collection 接口, 这是官方文档
https://docs.oracle.com/en/java/javase/16/docs/api/java.base/java/util/Collection.html

在文档中,我们看到,Collection实现了 Iterable<E> 接口,这说明 collection中的子接口以及子类都是可以迭代的。
1 | public class CollectionsDemo { |
但是要注意了, collection是不支持通过索引访问的,即我们不能使用中括号或者 add(index,element)这种方法来添加元素的。
The List Interface
1 | public class ListDemo { |
The Comparable Interface
在泛型那章已经讲过 Comparable Interface了,一般来说我们自定义的类如果要实现Comparable接口的话,一般需要重写 compareTo 和 toString 两个方法,如下面这个比较字符串的 Customer类
1 | package com.company.collections; |
The Comparator Interface
现在我们虽然实现了 Customer的排名,但实现起来却比较的麻烦,需要在类内实现。这时Comparator这个接口就可以在类外实现对象的比较。
简单来说,Comparable就是定义一个单独的对象比较器,继承自Comparator接口,实现compare()方法
比如现在 Customer 中多了一个 Email 参数,然后我们就新建一个 EmailComparator类如下:
在这个类中我们重写 compare方法并按照email进行排序
1 | package com.company.collections; |
然后在main函数中我们对Customer数组进行一个排序
1 | public static void main(String[] args) { |
打印得到 [c, a, b],说明确实是按照email进行排列的
The Queue Interface
现在我们来讲 队列接口,这是Queue<E> 的文档:
https://docs.oracle.com/en/java/javase/16/docs/api/java.base/java/util/Queue.html
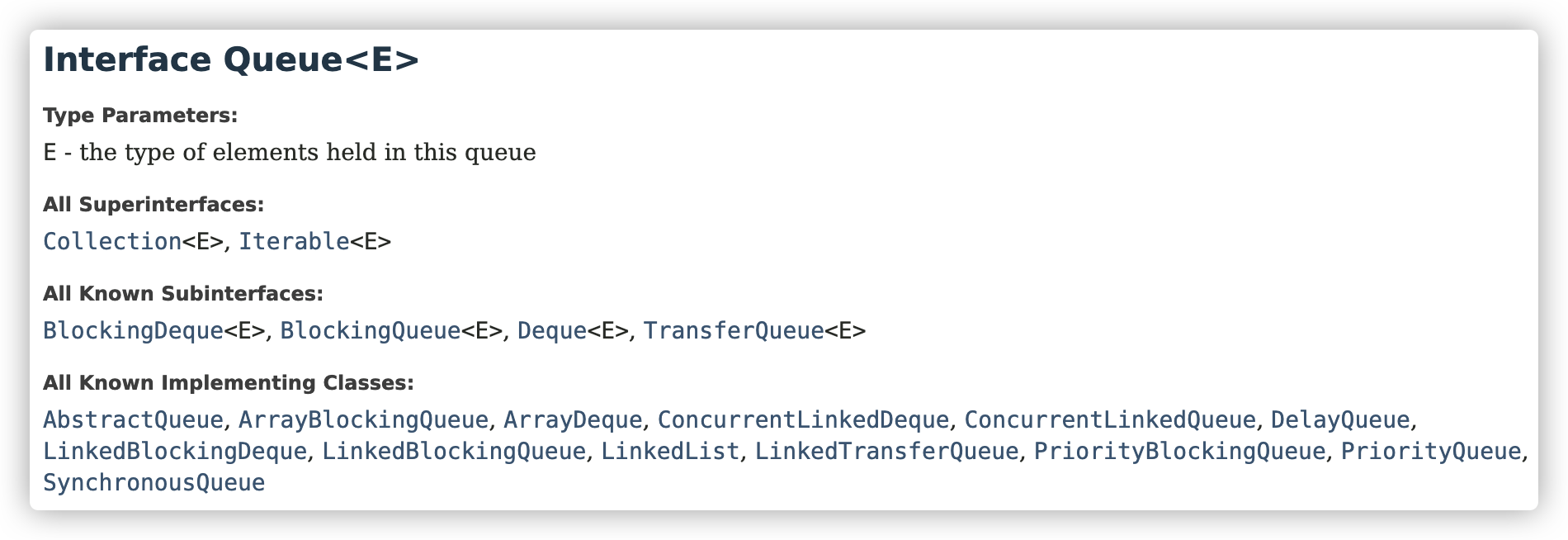
我们看到在 Queue接口下比较常用的就是 ArrayDeque(先进先出)、LinkedList(即继承自Queue又继承自List)、PriorityQueue等。
1 | public static void show(){ |
The Set Interface
https://docs.oracle.com/en/java/javase/16/docs/api/java.base/java/util/Set.html
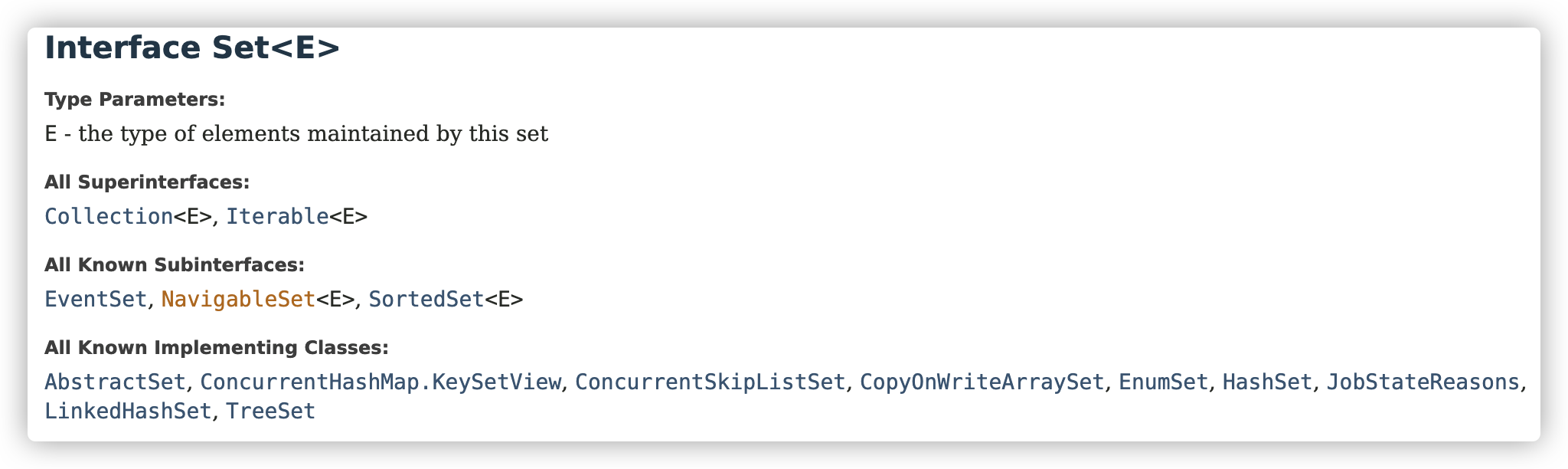
和C++一样,Set 是不包含重复的元素的. 如果把一个ArrayList放到Set当中,也会将其变成一个不重复的对象:
1 | public static void main(String[] args) { |
现在来介绍一些Set中的方法
set其实就是一个集合,数学上集合的操作在Java中都有对应的方法。
比如 并,就可以用 addAll() 方法求得
交,可以用 retainAll()方法求得
A-B, 可以用 removeAll()方法求得
1 | Set<String> set1 = new HashSet<>(Arrays.asList("a","b","c")); |
The Map Interface
在Java和C++中,哈希表可以用 Map接口来实现,在C#、python中,可以用Dictionary(词典)来实现
1 | var c1 = new Customer("a","e1"); |
但是注意了,map是不能够被迭代的,因此我们没用办法用for each loop来直接遍历map,但是我们有其他的方法:
我们可以使用map内置的 entrySet方法来获得每一组键值对
1 | for (var entry : map.entrySet()) { |
当然,也可以使用map.values()直接获得value
1 | for (customer : map.values()) { |
Lambda Expressions
Functional Interfaces
函数式接口,是指内部只有一个抽象方法的接口。注意,只能有一个,并且是抽象的方法
比如说我声明一个 Printer接口:
1 | package com.company.lambda; |
然后用一个ConsolePrinter类来实现这个接口:
1 | package com.company.lambda; |
最后在LambdasDemo类中将实例传入到参数为接口的greet()方法中,完成打印。
1 | package com.company.lambda; |
这与我们之前Java基础2中关于接口的操作思路一样,但是有时候我们并不想创建这样一个功能如此特殊的类来实现接口,因为用一次以后可能再也不会使用了。因此接下来我们要来介绍匿名内部类。
Anonymous Inner Classes
匿名内部类就是没有名字的、方法内部的类,通常用来简化代码的编写。
匿名内部类的使用场景: 我们只使用一次接口并用来实现某些特殊的功能的时候
匿名类是不能有名称的类,所以没办法引用它们。必须在创建时,作为new语句的一部分来声明它们。
比如:
1 | package com.company.lambda; |
匿名内部类,虽然已经方便了许多。但是更好的方法是使用 Lambda Expression
Lambda Expressions
Lambda 表达式的作用就像是一个匿名内部类,但是又不属于类。比如说我们重写刚才的匿名内部类代码:
1 | public static void show(){ |
也就是说使用 Lambda expression 可以代替一个类。在这里我们甚至不需要写 message的数据类型,因为当我们使用Lambda表达式的时候Java会根据调用它的方法(这里是greet())找到对应的接口及其数据类型。
当我们只传入1个参数的时候,参数不需要用括号包裹。但是当我们传入0个或者多个参数的时候,需要使用小括号包裹。
如果这个Lambda Expression花括号中只含有一句代码,那么花括号也可以被省略,如下:
1 | greet(message -> System.out.println(message)) |
Variable Capture
如果我们使用一个匿名内部类,我们可以在类内新建一些变量,但是在 Lambda Expression 中,是不能新建变量的。但是可以使用当前方法中定义的变量,比如:
1 | public static void show(){ |
也可使用当前类中定义的静态变量:
1 | public class LambdasDemo { |
当然,如果要使用非静态变量的话,需要将 show()方法也定义成非静态的。
Method References
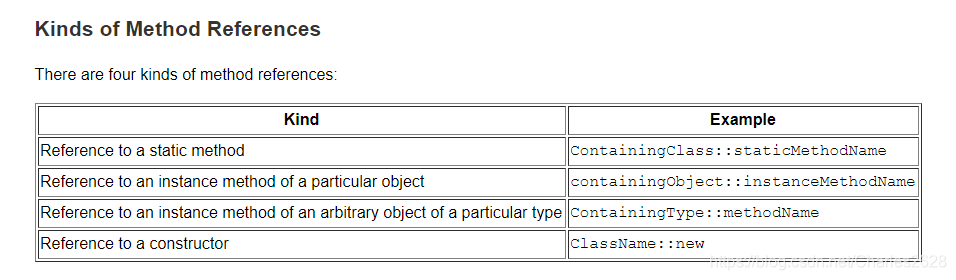
方法引用一共有四种,目的是用来简化Lambda表达式的。一般引用格式是: 类名+静态方法名,要求是引用的静态方法跟 Lambda表达式是客观等价的(参数值、参数类型、返回值一致)
比如说刚才的例子中 ,println方法就和Lambda表达式是客观等价的,因此我们可以直接简化为:
1 | public void show(){ |
当然,我们也可以在类中自定义一个静态函数然后实现函数引用:
在这里我们定义了静态函数 LambdaDemo 并在 greet中引用了它
1 | public class LambdasDemo { |
在上图,第四种方法就是引用一个构造函数。可以使用 类+new 的方法
1 | public class LambdasDemo { |
Built-in Functional Interfaces
文档:https://docs.oracle.com/en/java/javase/16/docs/api/java.base/java/util/function/package-summary.html
Java提供了四种内建的函数式接口:Consumer、Supplier、 Function、Predicate
Consumer接口的意思是它值接收一个参数,且不返回任何东西。就好像把一个值给消费掉了。
Supplier接口的意思是它并不接收任何参数,但返回一个值,就好像它在提供一个值。
Function接口的意思是它会把一个值映射到另一个值上, obj map(obj)
Predicate接口的意思是判断一个对象是否符合某个条件,bool test(condition)
现在我们来一一介绍四种接口
The Consumer Interface
文档:https://docs.oracle.com/en/java/javase/16/docs/api/java.base/java/util/function/Consumer.html
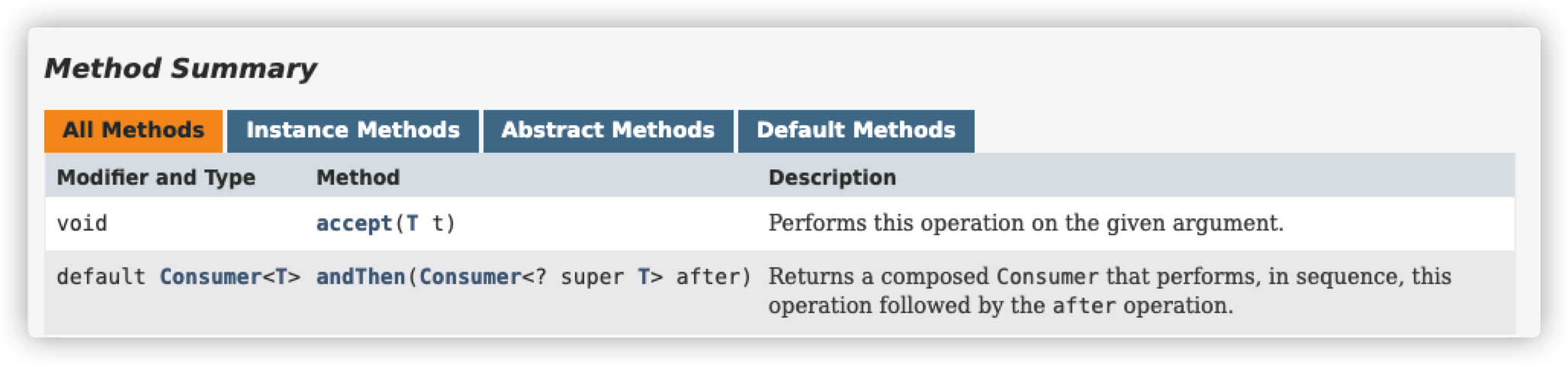
此外这个接口还有几个变形,比如 BiConsumer也就是接收两个参数但是不返回任何值
这里我们引用一个例子:
List集合中的 forEach()方法就实现了一个 Consumer接口,因此我们要传入一个值:
1 | list.forEach(System.out::println); |
这就是Declarative Programming, 也就是说这句命令做了些啥。
Chaining Consumer
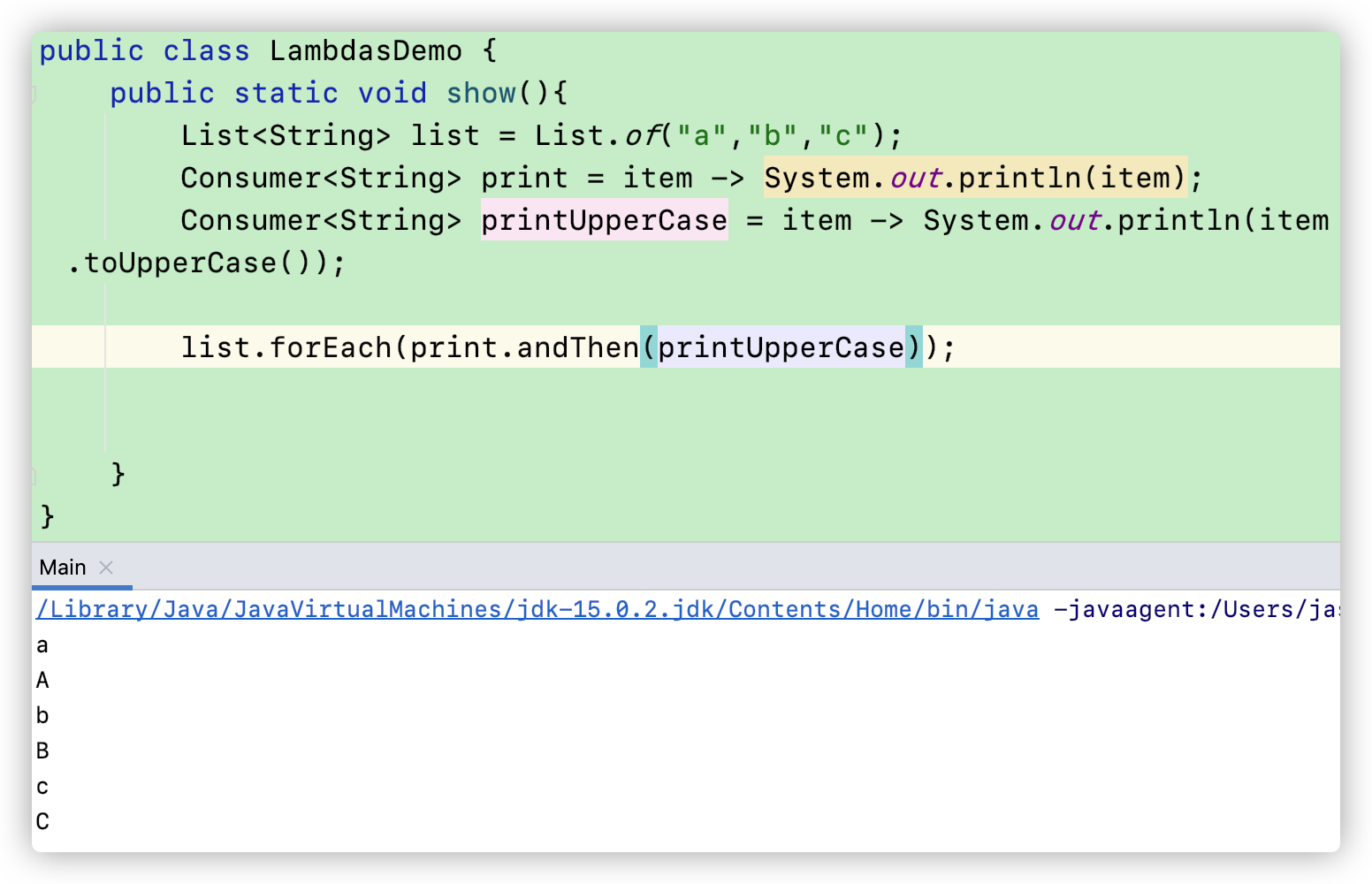
现在我们来说说 链式的Consumer,在这里我们定义了两个lambda函数分别实现 Consumer接口:一个是打印原来的元素,另一个打印大写后的元素。
然后我们使用forEach方法的时候,先调用print,在print后调用内建的 addThen,又可以调用一个 Consumer对象.可以一直这样调用下去,比如:list.forEach(print.andThen(printUpperCase).andThen(print));
调用顺序是:对于每一个元素,前调用print方法,然后调用printUpperCase方法,即先打印小写字母再打印大写祖母
我们查看Consumer的源码就能看出原理:
1 | default Consumer<T> andThen(Consumer<? super T> after) { |
我们发现这个函数的返回值也是一个 Consumer的对象,当一个Consumer调用andThen,它先执行前面的对象,再调用after执行后面的对象,这样就会使我们的传入的两个Consumer对象按照顺序执行。
The Supplier Interface
文档:https://docs.oracle.com/en/java/javase/16/docs/api/java.base/java/util/function/Consumer.html
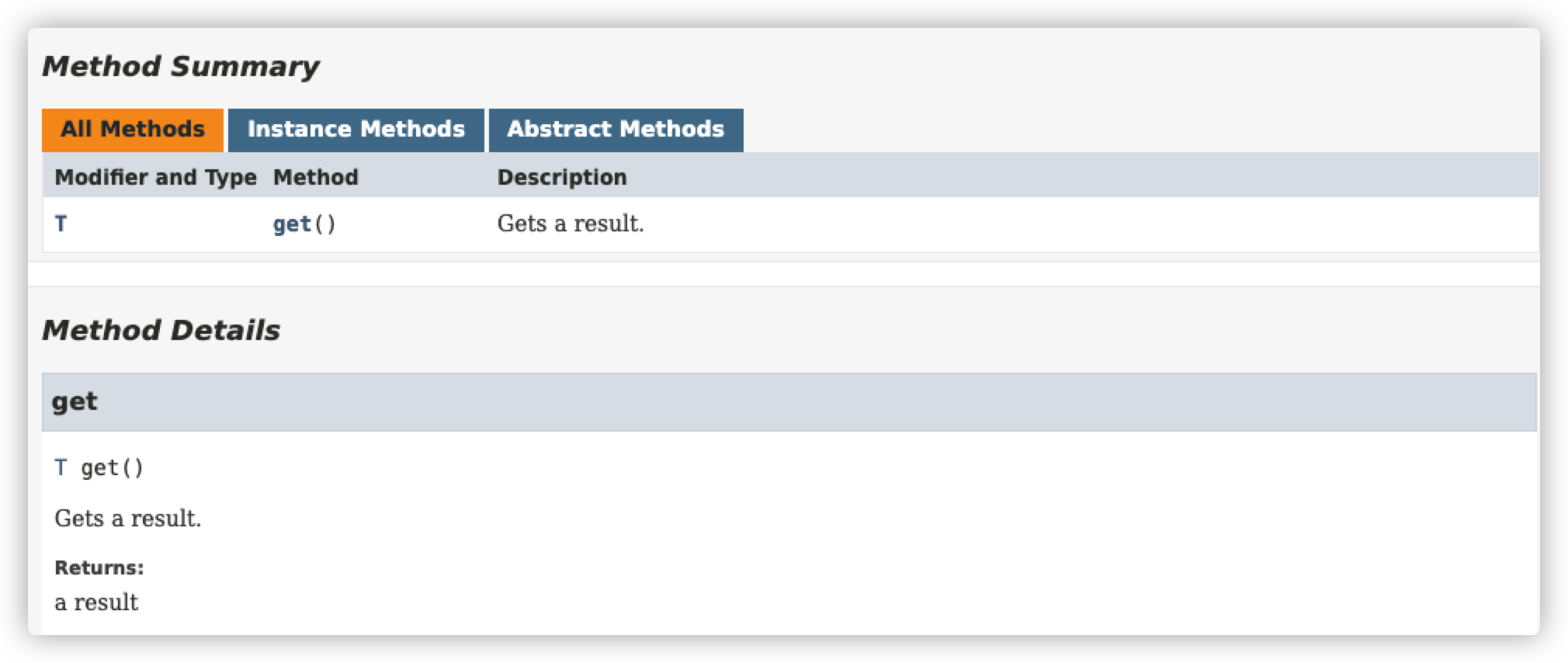
这个接口只有一个方法,即get
这里我们创建了一个 getRandom 的 Lambda 表达式,用来随机生成一个数。
1 | public class LambdasDemo { |
这边要注意的是,如果我们不调用 getRandom.get(),这个Lambda 表达式是不会执行的。这叫做:Lazy evaluation.
和Consumer接口一样,Supplier接口也有多种变形: DoubleSupplier,BooleanSupplier,IntSupplier等,这些接口只能返回特定类型的数据。
The Function Interface
文档:https://docs.oracle.com/en/java/javase/16/docs/api/java.base/java/util/function/Function.html
基本模板:Interface Function<T,R>

这个接口需要设置两个数据类型 T和R.文档中这么解释:
T - the type of the input to the function
R - the type of the result of the function
当然还有 Function 接口的变形如 BiFunction<T,U,R>,也就是设置三个数据类型,两个接收的和一个返回的:
T - the type of the first argument to the function
U - the type of the second argument to the function
R - the type of the result of the function
还有像 IntFunction<R>这种接口,因为它已经规定了接收值得数据类型为int,因此只要确定返回值类型 R即可;和IntFunction<R>相对的是 ToIntFunction<T>接口,它规定了返回值的数据类型为int,因此我们要确定其接收值得数据类型T
这里我们创建了 一个 Lambda函数map,其作用就是接收一个String类型的字符串并返回Integer类型的该字符串的长度。
1 | public class LambdasDemo { |
Composing Functions
因为 Function接口也有 andThen()方法,所以我们也可以链式使用 Function接口。
这里我们 同样定义了两个 lambda函数,第一个是将字符串中的’:’替换成’-‘。第二个是在字符串外面添加花括号。
我们有两种方式实现链式Function
我认为第一种更加直观:
1 | public class LambdasDemo { |
第二种:
1 | result = addBraces.compose(replaceColon).apply("Key:Value"); |
打印后得到: {key-value}
The Predicate Interface
https://docs.oracle.com/en/java/javase/16/docs/api/java.base/java/util/function/Predicate.html

我们使用这个接口来筛选数据。最重要的就是这个 test()方法,它会判断t是否符合某些条件。
此外还有 BiPredicate<T,U>,用来检测传入的两个参数是否符合某些条件;IntPredicate 它只接受Integer类型的数据并返回一个布尔值。
1 | public class LambdasDemo { |
这里我们设计了一个Lambda函数用来判断输入的String类型的字符串的长度是否大于5.
打印得到 false
Combining Predicates
将 Predicates结合起来又有些不太一样,因为这些都是条件。因此我们可以将两个条件通过 and(),or() 变成一个新的 Predicate,比如说:
1 | public class LambdasDemo { |
还有一个方法,叫做 negate(),也就是将条件取反变成新的条件,如 hasLeftBrace.negate()
1 | System.out.println(hasBothBrace.test("{sss")); // false |
The BinaryOperator Interface
现在我们来介绍一种特殊的函数式接口: BinaryOperator<T>
https://docs.oracle.com/en/java/javase/16/docs/api/java.base/java/util/function/BinaryOperator.html
这个接口是一个特殊的 BiFunction()接口,即接受两个参数,并返回一个值,这三个值得类型都必须相同。
比如说这里我们定义一个 BinaryOperator的函数为add,作用是将两个Integer类型的整数相加。我们还可以利用 andThen()将BinaryOperator和Function两个类型的函数复合起来,求两数之和的平方数。
1 | public class LambdasDemo { |
The UnaryOperator Interface
https://docs.oracle.com/en/java/javase/16/docs/api/java.base/java/util/function/UnaryOperator.html
UnaryOperator<T>接口是一种特殊的 Function()接口,即接受一个参数并返回一个值,但它们的类型必须相同
1 | public class LambdasDemo { |
这里我们新建了两个 UnaryOperator 对象,一个用来+1,一个用来求平方,使用andThen()将它们复合
Streams
Java8 引入了 Stream,这可以让你以一种声明的方式处理数据。也就是说,Stream使用了一种类似用SQL 语句从数据库查询数据的直观方式来提供一种对Java集合(collection)运算的表达的高阶抽象。这可以让我们写出高效率的、干净、简洁的代码。
比如:
1 | List<Integer> transactionsIds = |
Imperative vs Functional Programming
首先我们来看命令式编程和函数式编程之间的区别。
下面给出 Imperative Code的例子:我们看到命令式编程完全就是一步一步执行下去的,仿佛就是我们在对计算机下命令。
1 | public static void show(){ |
现在我们用函数式编程来重写上面这段命令式编程的代码:
1 | var count2 = movies.stream() |
命令式编程更像是我们告诉电脑应该怎么做:循环,判断;而stream则是直接show出来它做了什么:filter+count
它就好比是对Collection中的元素流通过管道,并在管道中进行筛选、分流、聚合等操作,最终得到我们想要的结果。

Creating a Stream
我们可以从这几处来创建流:
- From collections
- From arrays
- From an arbitrary number of objects
- Infinite/ finite streams
Stream 提供了新的方法 ‘forEach’ 来迭代流中的每个数据
1 | public static void show(){ |
Mapping Elements
map 方法用于映射每个元素到对应的结果。
1 | public static void show(){ |
此外还有flatmap()方法,The flatMap() operation has the effect of applying a one-to-many transformation to the elements of the stream, and then flattening the resulting elements into a new stream.
首先我们用 of()创建一个含有两个 List 集合的流,然后让其打印元素。
然后我们让其调用flatMap,让 传入的List集合扁平化。
1 | var stream = Stream.of(List.of(1,2,3),List.of(4,5,6)); |
Filtering Elements
filter 方法用于通过设置的条件过滤出元素, 这里我们要分清 stream的两种类型的操作:Intermediate Operation 以及 Terminal Operation
Intermediate Operation 就是 map()、filter() 之类的操作,它们会继续返回一个stream供我们后续操作
Terminal Operation 的例子就是 forEach(),它会直接在终端输出结果
如果只使用 Intermidiate Operation那么终端中什么都不会输出。为了使filter更加利于理解,我们可以将筛选条件单独定义成一个变量,如下面这个例子:
注:Predicate <T> 接口是一个函数式接口,它接受一个输入参数,然后返回一个布尔值结果。该接口用于测试对象是 true 或 false。
1 | public static void show(){ |
Slicing Streams
slicing stream是一个大类别,包含了 limit(n)、skip(n)、takeWhile(predicate)、dropWhile(predicate) 这些方法
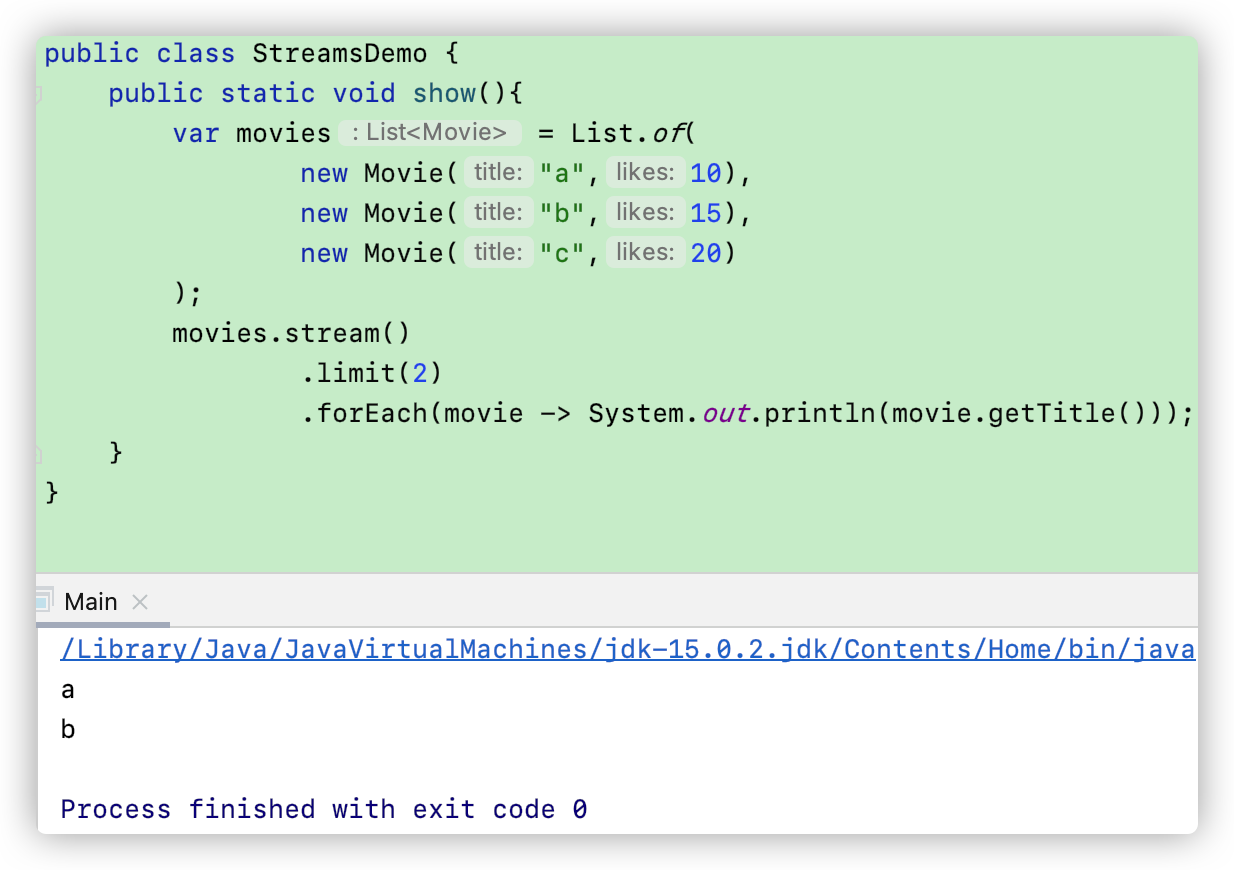
limit(n)
顾名思义,就是只限制 n 条数据,如下:
skip(n)
顾名思义,就是跳过前n条数据。
假设现在有1000条电影数据,每10条一页,我想看第三页的数据,应该怎么编写代码:
1 | movies.stream() |
takeWhile(predicate)
这个方法传入一个实现了 predicate接口的 lambda表达式,用来筛选满足条件的数据。但是注意了,这个和filter是不一样的。filter是筛选所有满足条件的数据,而takeWhile()方法则是一碰到不符合条件的数据就立即停止。
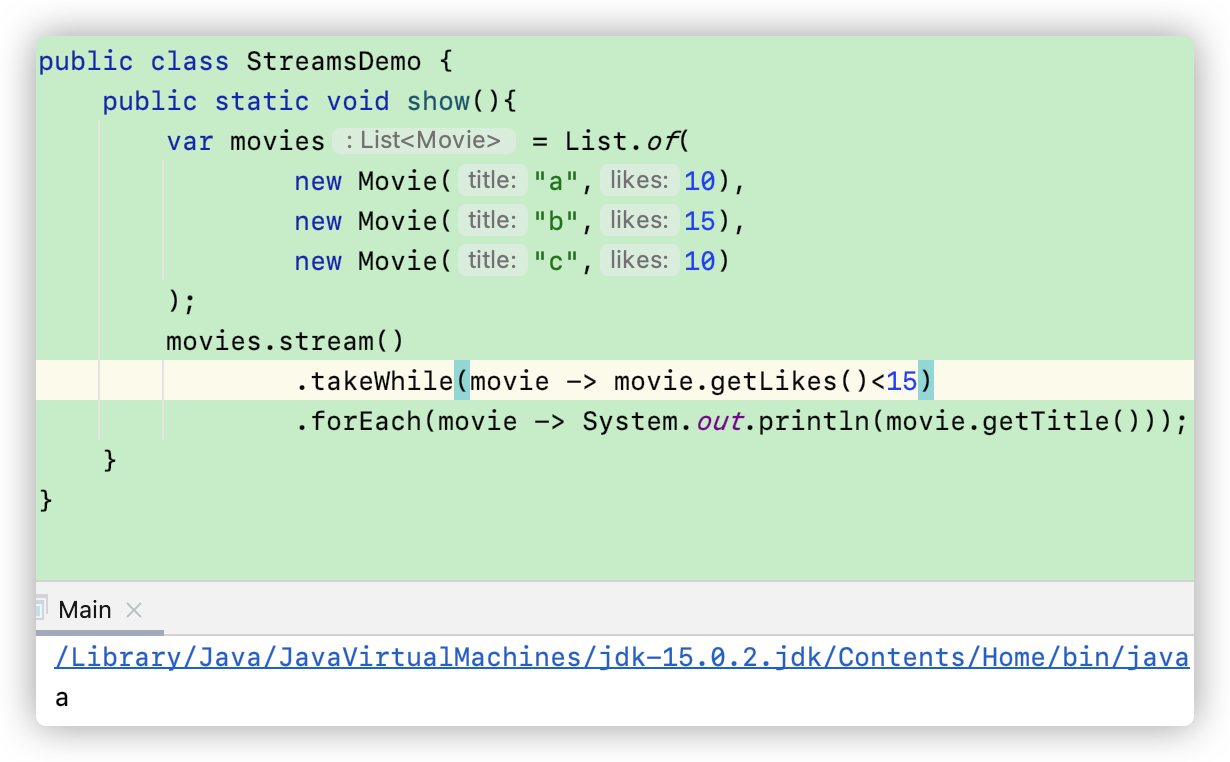
上面的例子中,虽然第三条数据的 likes<15,但是 takeWhile()在遇到第二条数据的时候就已经停止了筛选。
dropWhile(predicate)
dropWhile则和takeWhile恰好相反。就是去除掉那些符合条件的数据,直到遇到第一条不满足条件的数据为止。比如说刚才一模一样的代码,将takeWhile改成dropWhile,就会打印 b和c,因为会把a去除掉,而遇到b的时候就停止筛选了
Sorting Streams
我们之前介绍了 Comparable和Comparator接口,是用来对对象进行排序的方法。
现在在stream中我们可以简化写法:
1 | movies.stream() |
如果我们要倒序排列,那么:.sorted(Comparator.comparing(Movie::getTitle).reversed())即可
Getting Unique Elements
我们可以通过 stream中的 distinct()方法来获得集合中非重复的数据,比如说:
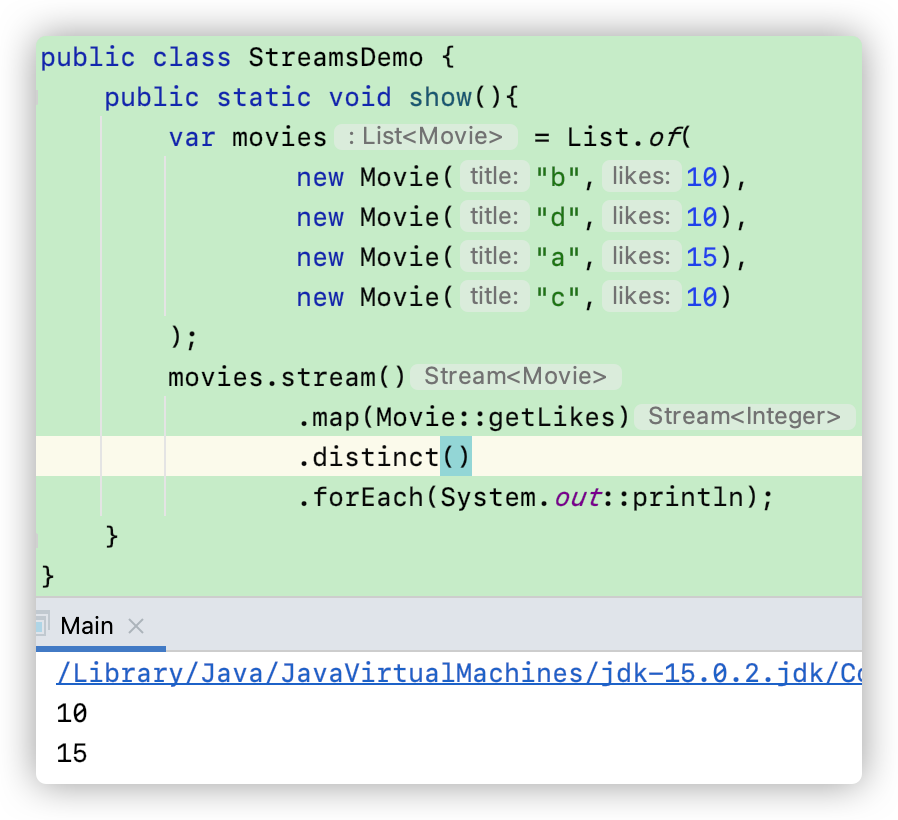
Peeking Elements
peek和map 有点相似,但是peek接收的是一个 Consumer,而map接受的是一个Function。
Consumer是没有返回值的,它只是对Stream中的元素进行某些操作,但是操作之后的数据并不返回到Stream中,所以Stream中的元素还是原来的元素。
而Function是有返回值的,这意味着对于Stream的元素的所有操作都会作为新的结果返回到Stream中。
我们常常用 peek()来debug我们的程序,因为它不会对Stream的元素作任何操作,又不是一个Terminal的操作会把Stream终止。
通过下面这个例子,我们能更深刻的理解 peek和map之间的差别了
1 | public class StreamsDemo { |
一开始我们筛选出了集合中点赞数大于10的数据,这里是两个Movie对象b和c
然后我们通过peek对其进行了一个输出
之后我们通过map将对象映射成他们的名字了,因此现在stream中只有两个字符串 b和c
然后我们再通过peek对其进行输出,这时候我们直接打印t和上面那样调用 getTitle()的效果是一样的,因为map已经对流进行了映射。

Simple Reducers
刚才我们讲的一系列操作,目的是创建客制化的管道。接下来我们来讲Reducer,其目的就是将流中的元素直接变成一个对象。比如说count(),它直接返回集合中的元素数量;
anyMatch(predicate), 返回布尔值,只要含有符合条件的就返回true;
allMatch(predicate)以及 noneMatch(predicate),逻辑和 anyMatch相同
findFirst() 返回 Optional 类,本质上,这是一个包含有可选值的包装类,这意味着 Optional 类既可以含有对象也可以为空。我们可以通过get()获取Optional中的对象本体。findFirst也就是返回集合中的第一个对象。
1 | public static void show(){ |
findAny()和 findFirst()逻辑相同,只不过是返回任意一个集合中的对象。
max(comparator) 这个方法需要接受一个 comparator 对象作为比较的依据. 用来返回拥有 最大参数的对象

1 | var result= movies.stream() |
min(comparator)和max()的逻辑相同。
Reducing a Stream
Collectors
Grouping Elements
Partitioning Elements
Primitive Type Streams
Concurrency and Multi-threading
Processes and Threads
我们在CSAPP中已经了解了进程和线程的关系。在一个进程中,一定有一个主线程,还可以有其他支线程。比如说我们在迅雷中一次下载了三个文件,那么这三个文件就可以占据三个线程。
现在我们来看一下关于这台电脑中关于线程的信息:
1 | public class Main { |
第一句是打印当前这个项目使用的进程数,下面一句打印当前电脑总的可用线程数。
因为 m1 是四大核四小盒,这里打印出来的是一共8个进程 。当我在 i7-9750(六核) 上运行时,打印得到12个线程。
Starting a Thread
现在我们来讲怎么创建一个线程。要创建一个线程,我们首先要让一个类引入 Runnable 接口,并在其中重写 run函数。Runnable接口是Java.lang 中一个内置的接口。引入这个接口就代表着这个任务将被在一条线程中执行。这个接口中只有一个函数: run() , 当启动线程开始运作之后,会自动调用 run()函数。
1 | package com.company.concurrency; |
然后,在 ThreadDemo 类中,将一个 DownloadFileTask() 实例传入,并调用 start()函数启动线程。
1 | public class ThreadDemo { |
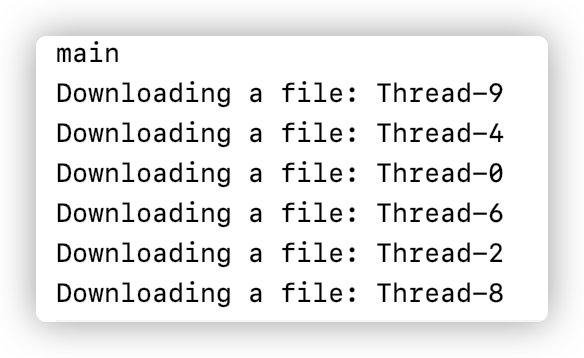
打印结果如上图所示:首先打印的是当前所在的线程,也就是 main,然后我们进行了一个循环,调用了十个新的线程,并依次打印出他们的名字。
Pausing a Thread
现在我们尝试将一个线程“挂起”一段时间以模仿下载的过程。
要让线程挂起,我们可以使用 sleep() 方法,这里我选择让线程挂起5秒钟(注意,5000是以毫秒为单位,但并不是非常精确的5000毫秒,这和底层操作系统有关系)
1 | public class DownloadFileTask implements Runnable { |
如果我直接写 Tread.sleep(5000),那么 idea会报错,我们需要用 try/catch 将其包裹起来。打印结果如下:
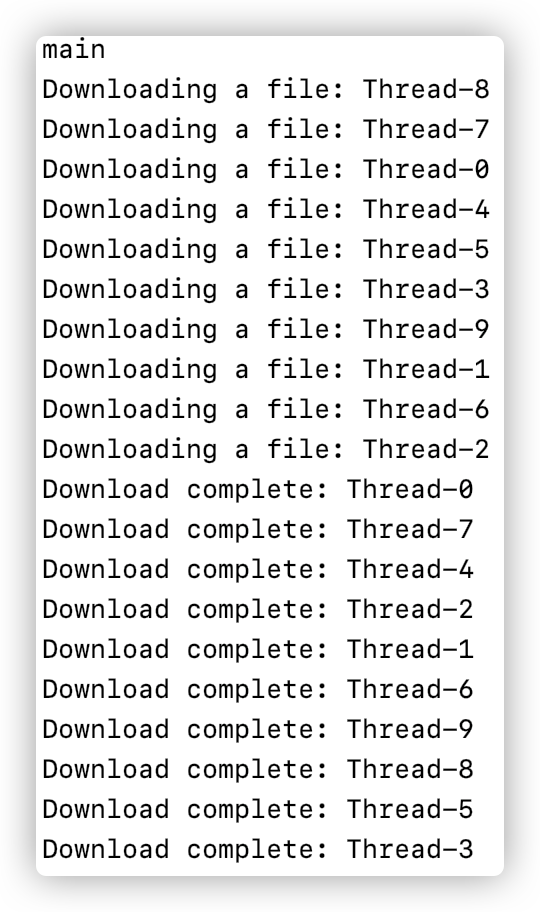
如果我们只有一个线程来下载这10个文件,那么就需要用50秒的时间,但是现在我们有10个线程,所以只需要5秒就能完成任务。
如果我们现在要下载成百上千的文件,但是我们电脑没有那么多线程。这时候,就要用到 JVM 中的 Thread Scheduler,这是用来决定 java中每条线程执行的时间。所以当任务量大于线程数的时候,JVM 会执行分时操作。也就是每一个线程都能分到一点时间,让我们用户看起来像是在并行下载。
Joining a Thread
join()方法是Thread类中的一个方法,该方法的定义是等待该线程终止。其实就是join()方法将挂起调用线程的执行,直到被调用的对象完成它的执行。
比如说,一开始我不使用 join(),这样,主线程就运行主进程自己的代码,只是开辟了一条线程运行其他的代码。因此我们看到打印出来的先是主线程的运行结果
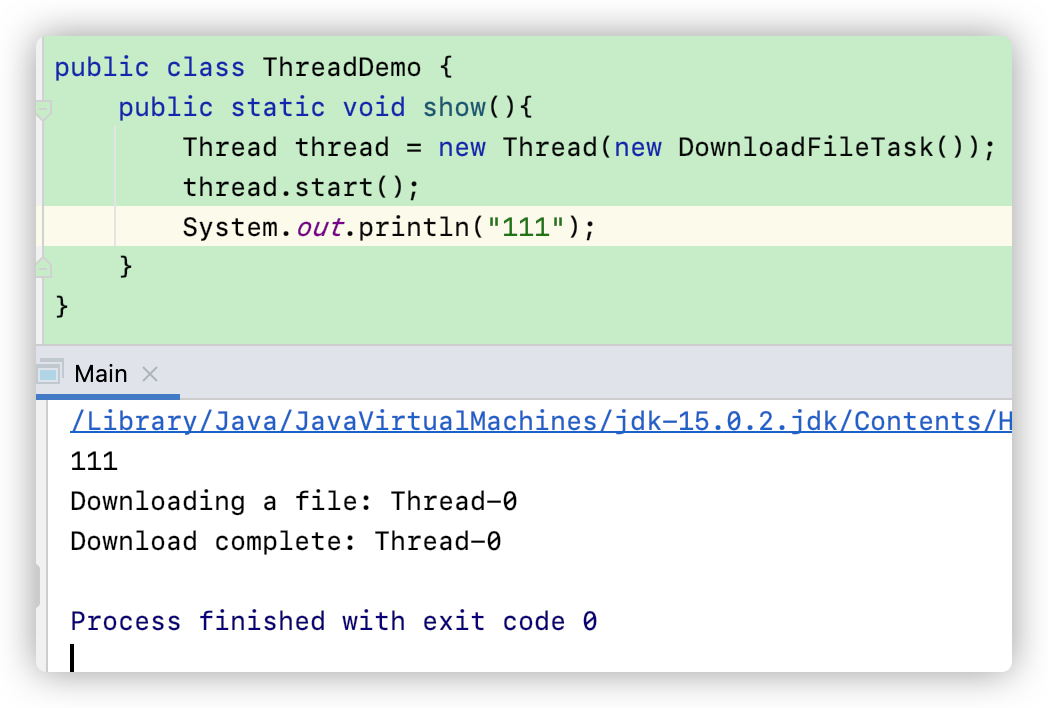
但是使用了 join()方法之后,主线程就会等待子线程结束后再运行。比如说:
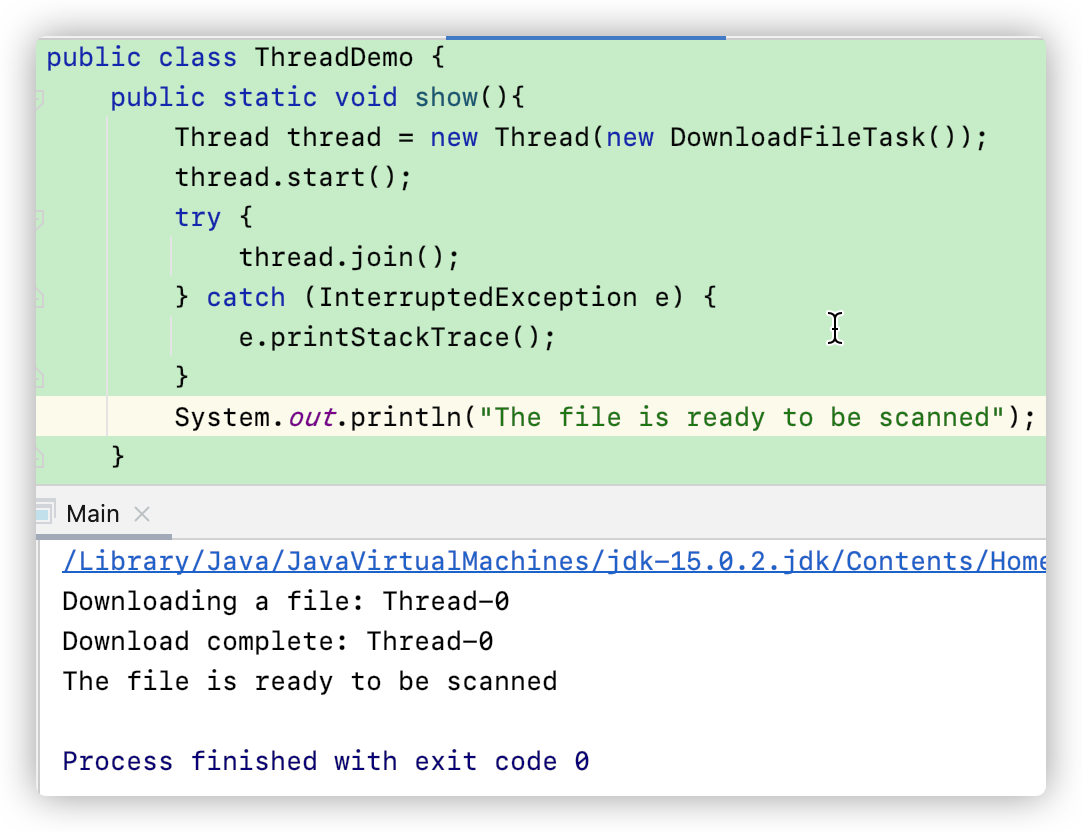
Interrupting a Thread
有时候我们必须要去终止一个运行中的线程,这时候就需要用到 thread.interrupt() 这个函数了。通常终止一个线程的逻辑是: 调用者发出一个interrupt信号,被调用的线程将对收到的信号做一个判断,如果是interrupt信号,就终止运行中的线程。否则就“充耳不闻”。
1 | public class DownloadFileTask implements Runnable { |
这边我进行一个无限循环,然后判断主线程是否给我发送了一个 Interrupt信号,如果是就return掉,否则就继续打印。
注意了,如果线程正在挂起时向其发送 interrupted 信号,这样是会报错的。因此我们在用 thread.sleep() 的时候,需要用 try-catch 来包裹。
Concurrency Issues
在编写并行程序的时候会遇到一些问题:
- 当很多不同的线程共用一个对象的时候,对对象的某些参数进行修改会导致“堵车”。这就好比三个人像同时吃掉一个汉堡。我们将这种情况叫做 “Race Condition”,
- 另一种情况就是,当一个线程对一个对象进行了修改,但是修改后的内容仅它自己可见,那么不同线程就会看到一个对象不同的状态。我们将这种情况叫做 ”Visibility Problem”
我们必须要写出 Thread-safe Code 来规避这些问题。在很多Java的文档中,对一个类的描述是 Thread Safe 也就是这个类可以再很多并行的线程中使用。
Race Conditions
当很多线程都想修改一个对象的时候,就出现了竞争关系。
比如说我有以下代码:
ThreadDemo类
在这个调用的类当中,我们创建一个线程数组,
1 | package com.company.concurrency; |
DownloadFileTask类
在这个Run函数当中,我们做一个10000次的循环,每一次循环都调用status对象的 incrementTotalBytes()函数。用来模拟下载一个 10000 bits的文件。
1 | package com.company.concurrency; |
DownloadStatus类
在这个类中,有一个下载总比特数的私有变量,当有线程中的对象调用incrementTotalBytes()的时候,totalBytes就会自增1
1 | package com.company.concurrency; |
在预期的情况下,我们打开了10 个线程,每个线程都会下载10_000比特的数据,那么totalBytes的结果应该是100_000, 但是我们多次运行之后,一直都是八九万,并没有到十万。这是因为发生了Race condition,线程在互相争抢修改同一个数据的时候,会发生数据丢失。
当我们调用 incrementTotalBytes() 的时候,电脑会从内存中找到totalBytes的值,然后存储至cpu,然后cpu对值进行加1操作;操作结束后,这个值会被重新存储至内存中。
那么现在假设两个线程同时读取了 totalBytes然后对其进行加1操作,这时候,CPU也只是会将totalBytes加上1而已,并不会加上2。这就是导致了刚才的数据丢失。
Strategies for Thread Safety
我们有一些写出 Thread Safe Code 的策略:
- Confinement
这个概念很简单,就是原本是多个线程操作一个对象,现在变成了每个线程都操作属于它自己的对象,最后将对象中的值加起来就得到最后的总值。
- Immutability
这个操作更加直白,就是我们将要操作的对象变成不可改变的。比如说 String 对象就是 Immutable 的,因为当我们对一个 String 对象进行修改的时候会创建一个新的String,之前的String并不会遭改变
- Synchronization
同步操作,这使得同一个对象在不同的线程之间可以协调、同步。我们可以利用lock以及Synchronize关键词来实现这个操作.
我们使用锁将”有争议的部分”锁起来,一次只能让一个线程来访问,这样就能做到隔离的效果。然而,这样很容易造成死锁,因此不推荐使用
- Atomic Object
原子对象。之前 若要对totalBytes 进行修改需要进行3个步骤,但是当我们使用原子对象的时候,只需要一个步骤即可,这就防止两个线程同时操作一个对象的情况出现了。
- Partitioning
中文叫分区
Confinement
现在我们重构刚才那段代码。之前发生Race condition的时候,我们只创建了一个 DownloadStatus 对象,十个线程都对一个 totalBytes 变量进行操作,因此它们开始争夺。
我们现在要做的就是“隔离”,简单来说就是给每一个thread都新建一个DownloadStatus,线程的操作只对它自己的DownloadStatus中的TotalBytes进行操作,最后将这十个 TotalBytes变量累加得到最后答案。
因为我们要对每一个线程新建一个下载任务,因此我们还要一个 列表来保存这些Tasks。并且我们不再需要向DownloadFileTask 构造器传入status参数了,因为我们要对每一个Task新建一个DownloadStatus对象 ,但是我们要在 DownloadFileTask类中为status做一个getter,方便外界获取当前的下载状态。
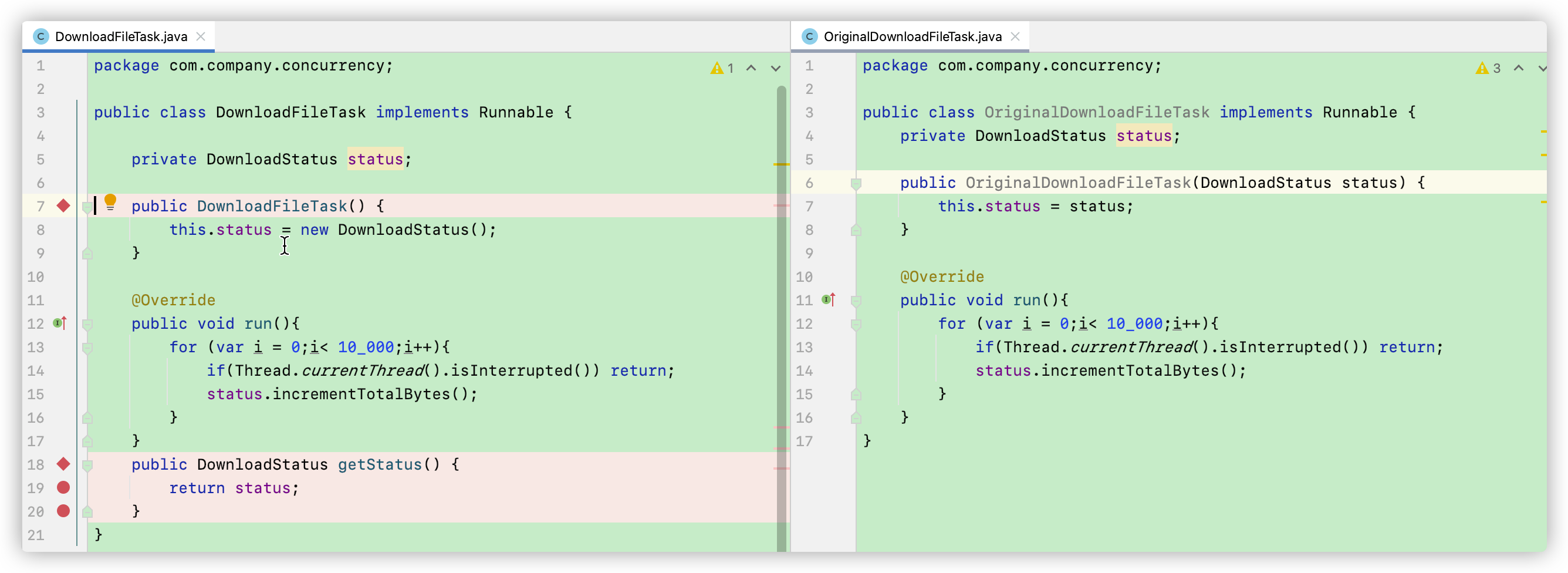
现在我们重构 ThreadDemo 类,因为我们要为每一个线程单独设一个DownloadFileTask,因此为了方便将其中的TotalBytes相加,我们要新建一个List对其进行管理。并在创建的时候将每一个Task加入到数组当中去。最后我们用 Stream 将tasks数组中的所有任务中的totalbytes相加,得到最终结果。

打印得: Optional[100000],即10个线程的下载总和,一个Byte都没丢掉
Locks
上面我们说了隔离,这里我们再提供一种方案。就是设计一个锁,使得同一个对象在同一时间只能被访问修改一次。当一个线程想要正在修改对象的时候,就把这个对象锁起来,别的线程都无法访问。
根据上面的信息,我们现在要在 DownloadStatus上加一个锁。首先我们声明一个lock:
private Lock lock = new ReentrantLock() 也就是一个可重入锁对象。reentrant 锁意味着什么呢?简单来说,它有一个与锁相关的获取计数器,如果拥有锁的某个线程再次得到锁,那么获取计数器就加1,然后锁需要被释放两次才能获得真正释放
然后我们在调用 incrementTotalBytes 的时候先上一个锁,等自增1结束后再解锁。这就好比一个人进了酒店房间办事,然后把门给锁了,办完事后再把门打开。
但是为了程序的正常运行,我们需要用 try-finally block ,因为如果在 totalBytes++的时候抛出了一个异常(我们当然知道自增1不会抛出异常,但是在未来我们自己的程序中这可能是一段很复杂的代码,因此必须要try),那么这个锁就永远无法打开了,会导致死锁。因此我们要保证 lock.unlock() 在任何情况下都能执行。

打印结果:100000
The synchronized Keyword
要让线程之间同步,我们还可以使用 synchronized 关键词。这样我们就不用很麻烦的先锁住、然后再解锁了。
但是Java程序依靠synchronized对线程进行同步,使用synchronized的时候,锁住的是哪个对象非常重要。
让线程自己选择锁对象往往会使得代码逻辑混乱,也不利于封装。更好的方法是把synchronized逻辑封装起来。
比如我们现在就要用synchronized来封装totalBytes++
1 | public void incrementTotalBytes(){ |
这样一来,线程调用incrementTotalBytes方法时,它不必关心同步逻辑,因为synchronized代码块在incrementTotalBytes方法内部。并且,我们注意到,synchronized锁住的对象是this,即当前实例,这又使得创建多个DownloadStatus实例的时候,它们之间互不影响,可以并发执行。
当我们锁住的是 this实例的时候,实际上可以用 synchronized来修饰这个方法,因此这两种方法是等价的:
1 | public synchronized void incrementTotalBytes(){ |
因此,用synchronized修饰的方法就是同步方法,它表示整个方法都必须用this实例加锁。不能对其他实例加锁。
但是,对 this 实例加锁也是有缺点的。比如说:我又新建了一个totalFiles变量来记录已下载完成的文件总数。因为文件一多,很可能是两个文件同时下载完成的,因此我们也需要用 synchronized关键字来修饰

那么问题来了:incrementTotalByts和incrementTotalFiles这两个方法都给 this对象上了锁。那么如果存在某一个时刻,要同时调用这两个方法的时候,必须等其中一个方法运行完之后把this对象解锁了之后才可以继续执行另一个方法。如果这只是一个小型应用,也许没事;但是如果这个应用非常庞大,需要上锁的参数非常多,那么同时调用的时刻会很多,会造成不必要的等待、降低程序的性能。
为了解决这个问题,我们可以给每一个需要上锁的变量新建一个专属对象。并用这个对象传入synchronized关键字。如下图所示:
我们创建了两个Object类型的对象,一个叫totalBytesLock用来锁住totalBytes; 以及totalFilesLock用来锁住totalFiles 变量。
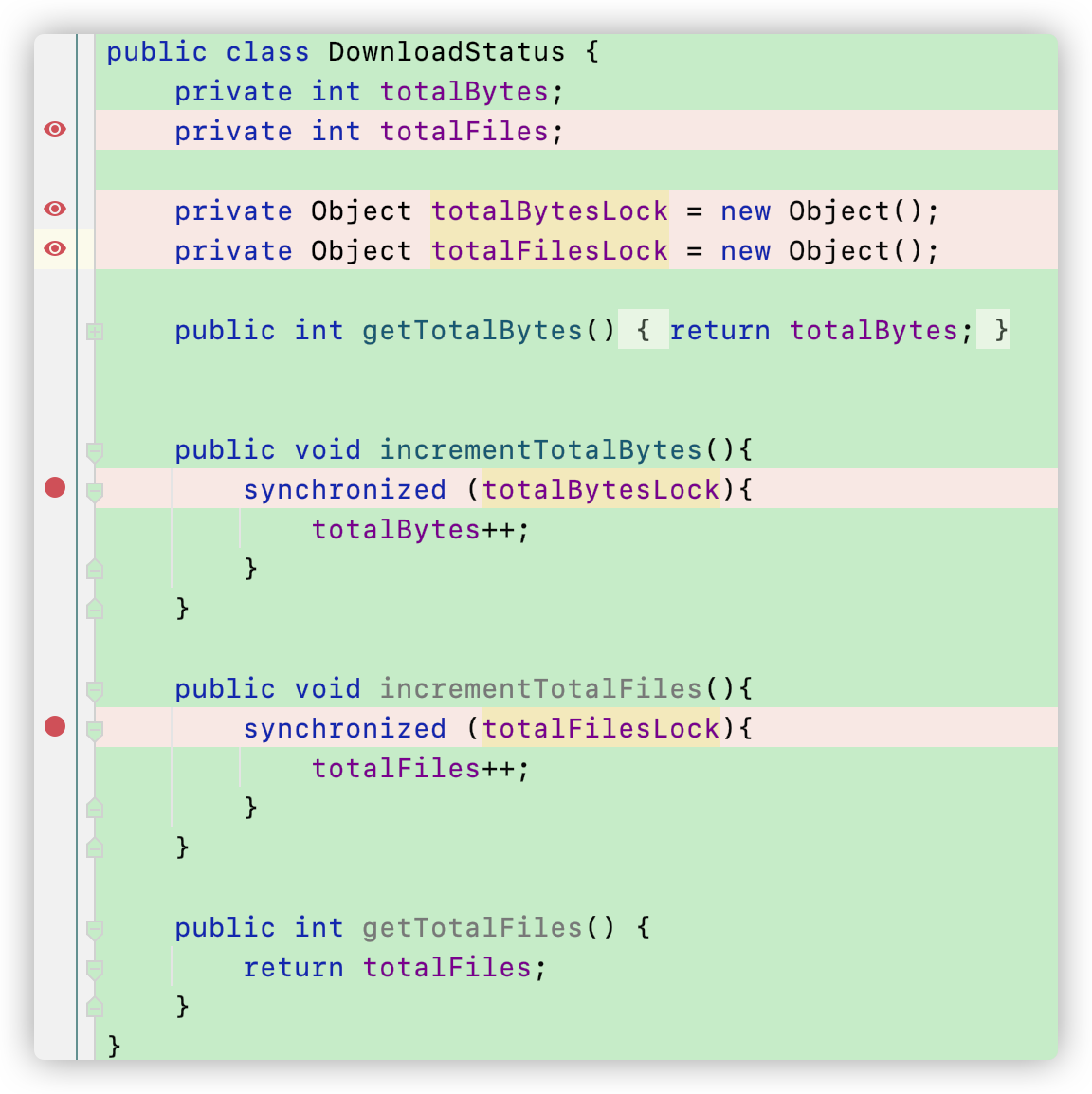
在今后的开发中我们最好选择变量的专属对象来上锁,而不要一直使用this对象
The volatile Keyword
https://blog.csdn.net/u012723673/article/details/80682208
Java 语言包含两种内在的同步机制:同步块(或方法)和 volatile 变量,相比于synchronized(synchronized通常称为重量级锁),volatile更轻量级,因为它不会引起线程上下文的切换和调度。但是volatile 变量的同步性较差(有时它更简单并且开销更低),而且其使用也更容易出错。
在多线程环境下,一个线程对共享变量的操作对其他线程是不可见的。Java提供了volatile来保证可见性,当一个变量被volatile修饰后,表示着线程本地缓存无效,当一个线程修改共享变量后他会立即被更新到主存中,其他线程读取共享变量时,会直接从主内存中读取
我们先来看一个没有 volatile 版本的代码,分析一下里面有什么错误:
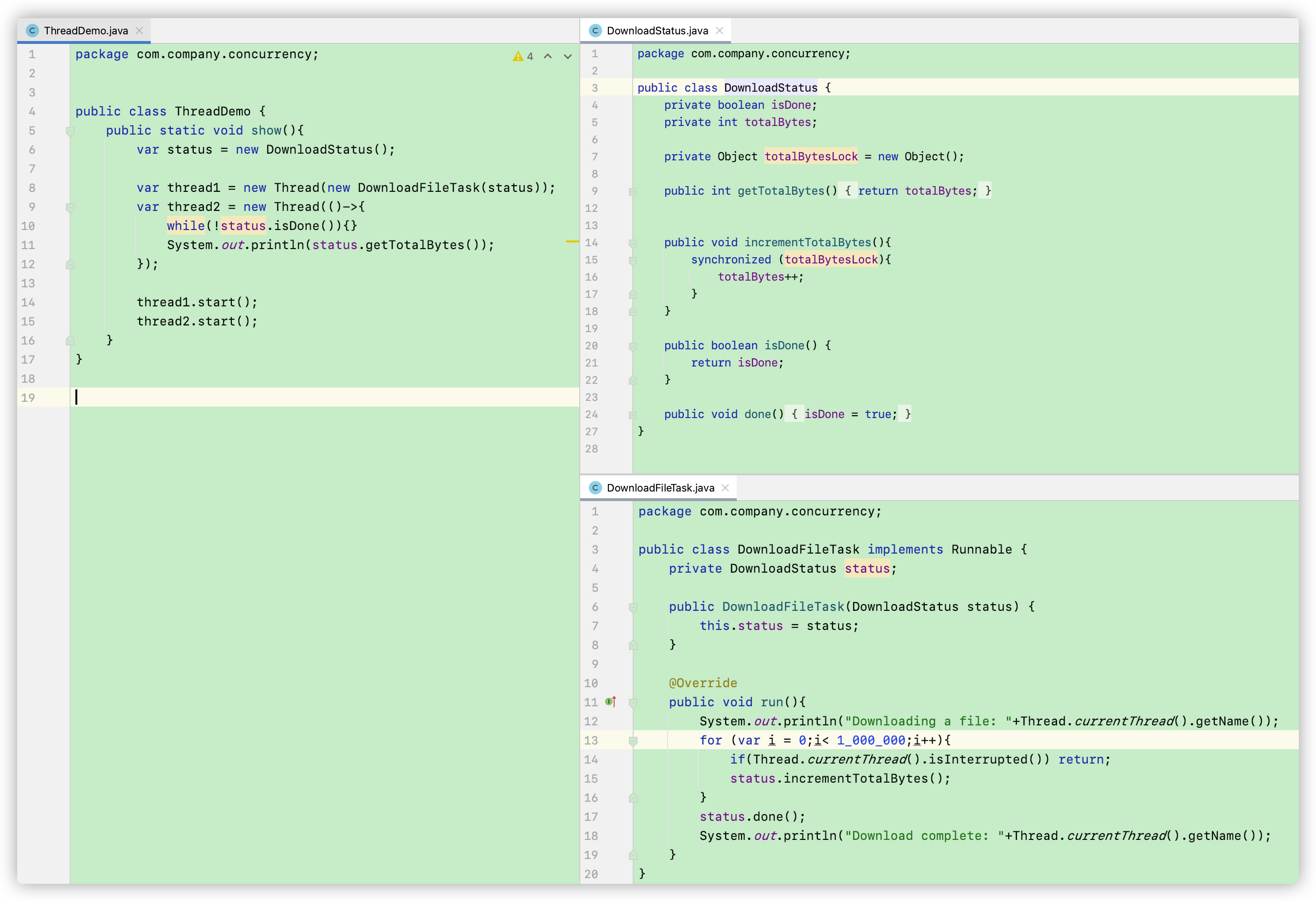
首先我们在 DownloadStatus 中新建一个 isDone布尔变量,来表明这个下载任务是否已经完成。并设定一个 getter返回isDone 和一个 setter将isDown设为True
然后在DownloadFileTask类中,我们在下载结束后调用 status.done()将isDone() 设置为True并输出Download complete
最后在ThreadDemo类中,新建两个线程,第一个线程传入DownloadFileTask对象,第二个线程里面是个 Lambda表达式,它会一直询问status中的变量isDone是否为True,一直到下载完成 ,isDone==True,才会跳出循环并输出totalBytes的值。
我们运行这个demo,却发现程序迟迟不打印totalBytes的值,事实上如果我们不关闭这个程序,它就会一直运行下去。
为什么会发生这种事情?原因就在于 thread1和thread2两个线程之间并没有完全同步,我们注意到虽然totalBytes是通过 synchronized关键字修饰的,但是 isDone 并没有同步。因此在thread2看来,isDone始终是False。这种不可见性要从底层的JVM优化机制cache开始说起:
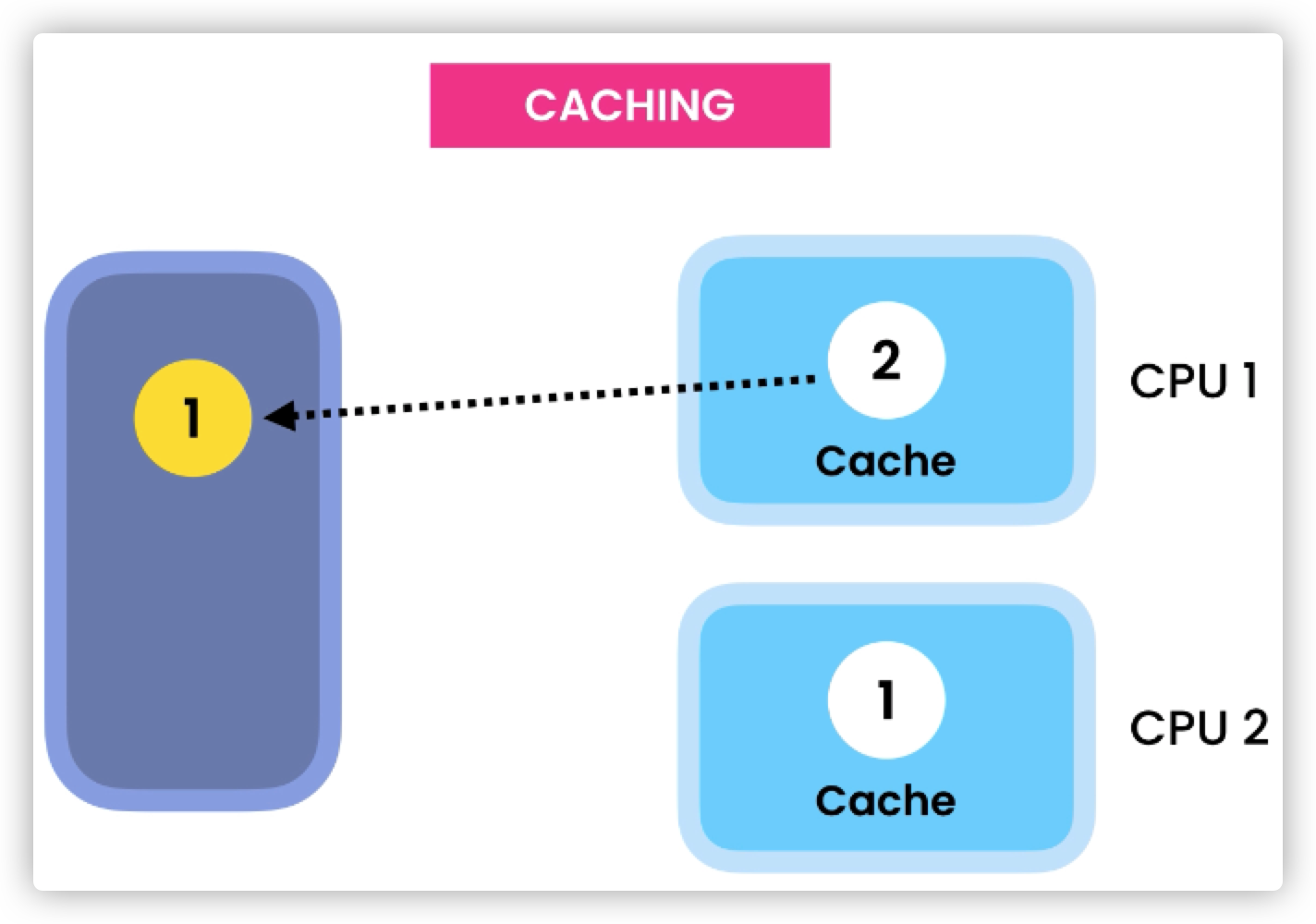
有一个变量,存储在主存中,值为1。现在CPU的两个核分别执行一条线程,将这个变量从主存中读入到CPU当中去,存储在不同的cache中,因为从cache中读取数据要比从主存中读取快得多。但是这两个CPU之间并不知道对方的cache中存的这个变量的值。因此,当CPU1将cache中的变量从1修改到2的时候,CPU2看到的该变量仍然是1,就算CPU将该变量回写到主存当中去,CPU2的cache中因为已经存储了该变量,因此仍然看不到改变后的结果。这就是多线程的不可见性
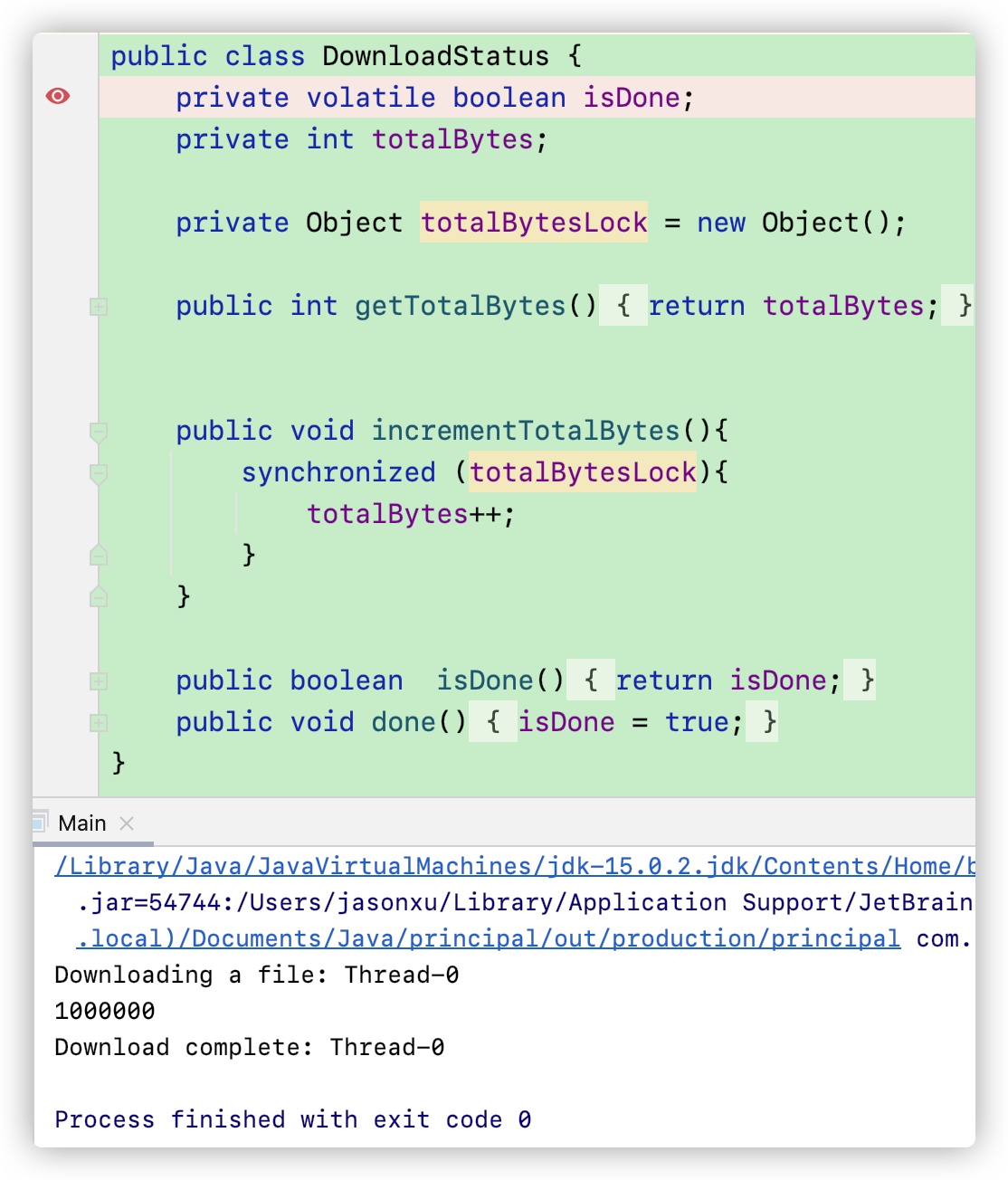
一种可行但是不建议的方法就是将 DownloadStatus中的isDone()和done()方法都使用synchronized关键字修饰。但是我们有更好的方法——volatile
在一开始我们也说了volatile的原理,那就是告诉JVM,我这个变量是随时会变的,是不稳定的。你每次访问必须从主存当中去读取,不能从cache中去读取。
Thread Signalling with wait() and notify()
有时候我们会使用无限循环询问一个变量是否发生变化,比如刚才例子中,一直询问下载完成没。但是这样是很占用CPU的资源的。它可能会重复循环上亿次才能等到结果。
为了优化上面这种情况,我们可以用wait()和notify()方法
顾名思义,调用wait()方法后,线程进入等待状态,wait()方法不会返回,直到将来某个时刻,线程从等待状态被其他线程唤醒后,wait()方法才会返回,然后,继续执行下一条语句。注意,只能在锁对象上调用wait()方法 。notify()则是在相同的锁对象上作用,完成某件事后发出一个信号,让wait()去接收
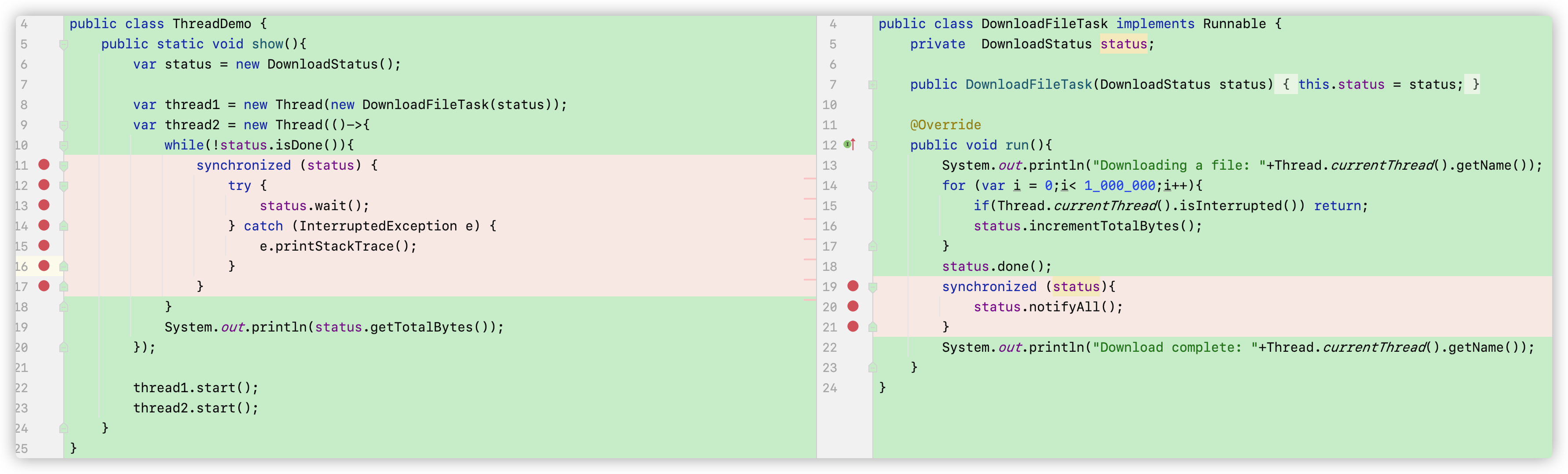
比如下面这个例子,当我们要用while来询问isDone()是否为true的时候,我们对status上了一个锁。然后在里面调用wait()让线程2沉睡。再跑到DownloadFileTask类中,当下载完成时我们在 status上锁了的情况下调用 notifyAll()发出讯号。wait()收到后就会跳出循环,执行打印命令。
通过这种机制我们可以降低CPU的负荷,优化程序性能。但同时,在不正确的地方使用wait()和notify()可能会造成很多难以解决的问题,因此我们不推荐这种方法。
Atomic Objects
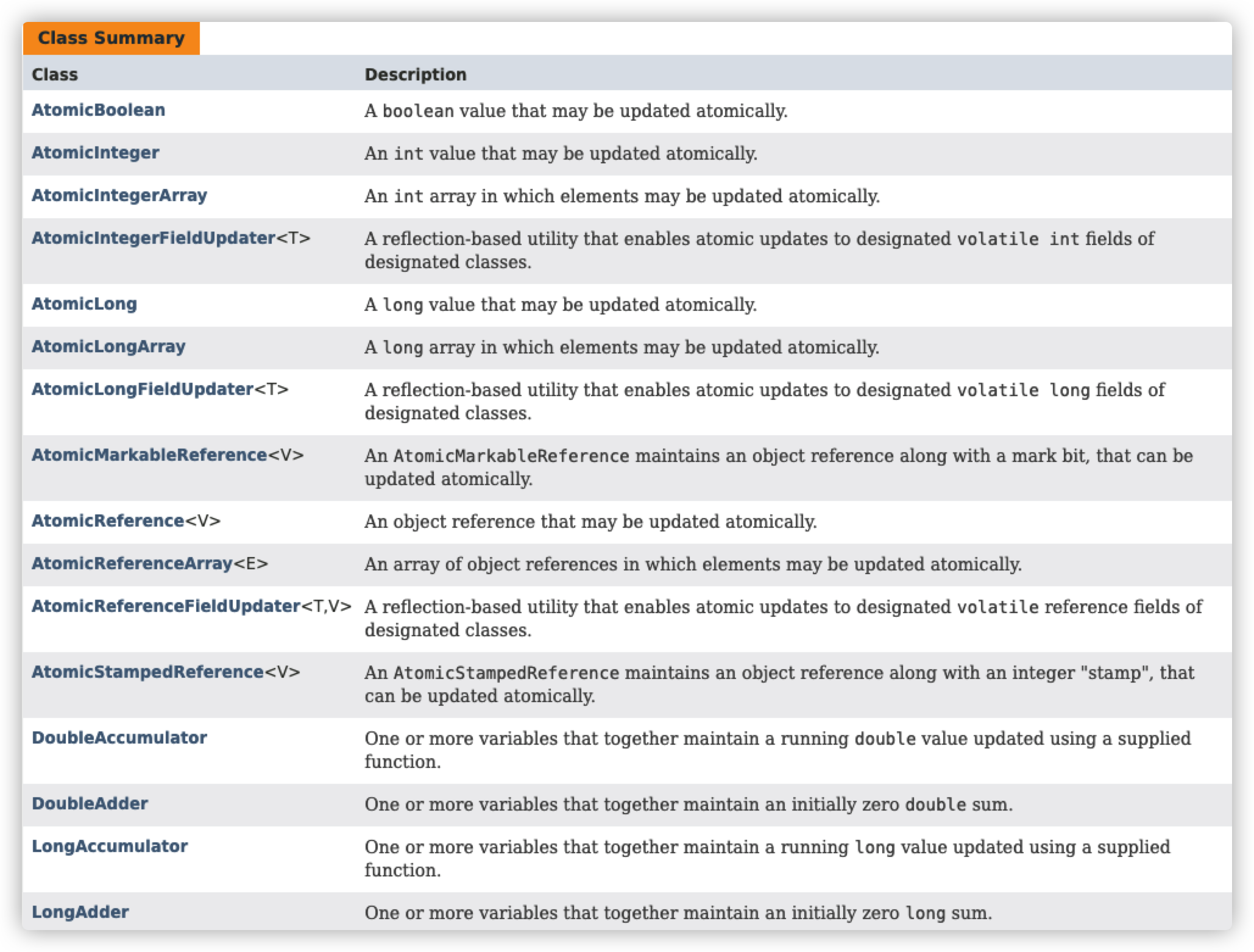
Atomic object翻译过来就是原子对象,顾名思义,这个对象是不可分割的(不要用夸克抬杠) 。 我们之前做的所有努力,就是想避免多个线程totalBytes++产生竞争关系,因为totalBytes++需要进行三步操作,并不是原子化的。
ava的java.util.concurrent包除了提供底层锁、并发集合外,还提供了一组原子操作的封装类,它们位于java.util.concurrent.atomic包。
我们以AtomicInteger为例,它提供的主要操作有:
- 增加值并返回新值:
int addAndGet(int delta) - 加1后返回新值:
int incrementAndGet() - 获取当前值:
int get() - 用CAS方式设置:
int compareAndSet(int expect, int update)
现在我们要做的就是将totalBytes++原子化,回到最初发生竞争状态的那段代码,我们要对DownloadStatus中的totalBytes进行修改,将其变成 AtomicInteger类型的数据。这时候就不能直接 return totalBytes 了,一定要调用 get()来获取当前的值;此外还要把++变成 incrementAndGet(),即自增1后返回。
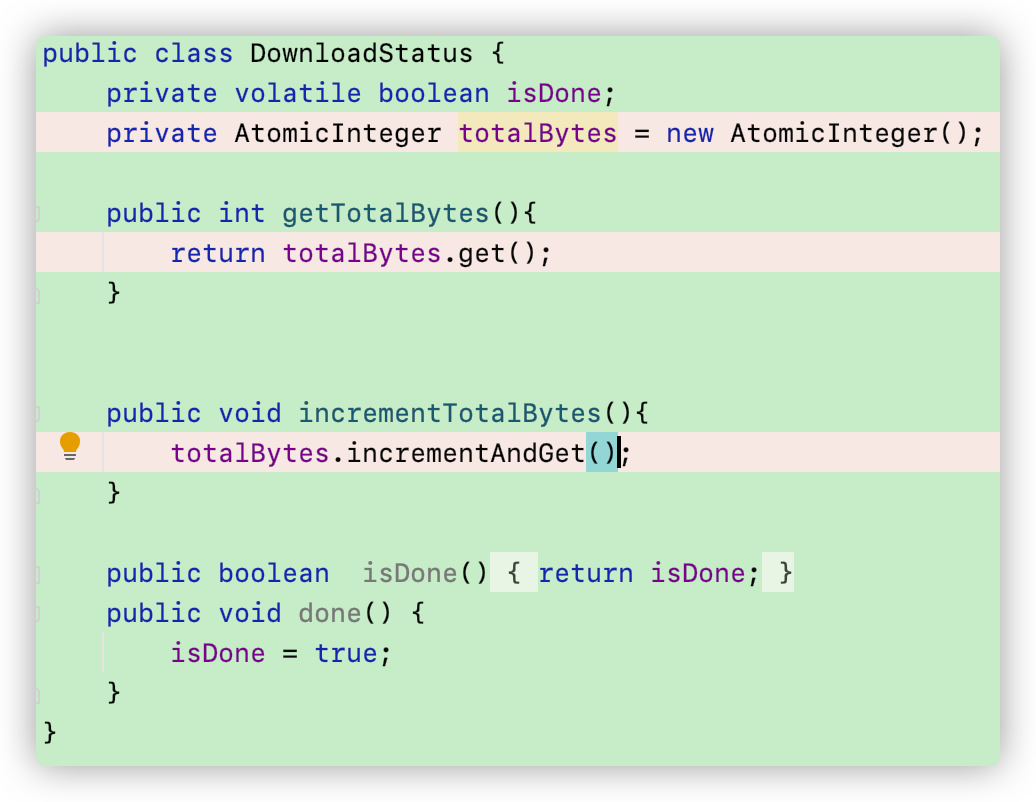
打印结果为: 100_000
原子类的实现原理就是compare and swap(CAS), 比如说我调用 incrementAndGet 的时候原子类型的数据就会比较当前值和期望值,如果他们不相等,就进行交换操作。
使用java.util.concurrent.atomic提供的原子操作可以简化多线程编程:
- 原子操作实现了无锁的线程安全;
- 适用于计数器,累加器等。
Adders
虽然说原子类适用于计数器、累加器等,但是当有多个线程同时对一个对象进行累加操作的时候,我们更推荐使用Adder类,它同样可以实现原子化,但是在高并发的情况下,其速度会比 Atomic更快, 简单来说,Adder具有更高的吞吐量。
原理:参考这篇博客
在LongAdder类中,我们使用 intValue()来获得当前totalBytes的值并返回为int 类型,同时在自增1的时候调用increment()方法。 总的来说和 Atomic 类是类似的。

Synchronized Collections
刚才我们讲的都是关于某一个变量的同步,现在我们来学对于一个集合的同步。
如果我们创建一个普通的 ArrayList集合,然后创建两个线程向集合中添加元素。有可能它们会发生 Race condition 导致数据丢失,为了规避这种情况的发生我们可以使用 Synchronized Collection:
1 | public class ThreadDemo { |
Concurrent Collections
当并发高的时候,使用 Synchronized Collection 会导致CPU占用过高、性能下降。这时候我们可以用 Concurrent Collection
在Concurrent官方文档 中,我们看到有 ConcurrentHashMap,ConcurrentLinkedDeque等并发集合
以Map为例,假如我们要对一个HashMap进行高并发的操作,我们就可以使用 ConcurrentHashMap类。事实上,ConcurrentHashMap和HashMap都是对 Map接口的实现类。
1 | public class ThreadDemo { |