网络核心
学习博客: https://www.zhihu.com/column/p/44316491
所谓交换,就是指服务器与服务器之间的数据交换。我们介绍分组交换和电路交换
电路交换
假设A要和E打个电话,那么当A输入E的电话号码,开始拨号之后,那么服务器要做的第一件事就是根据E的电话号码找到E在哪里,由于A通往E的路径有多条,会根据某种算法找到E之后,建立一条通路,然后进行数据的传输。
我们假设选的路径是A—>D—->E
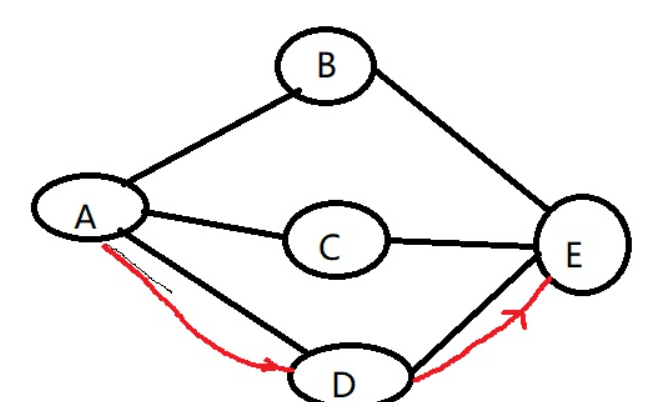
电路交换总共有3个阶段:
建立连接,就是说找到一条A通往E的路径并建立会话的过程,之后A和E在通话的过程中会始终霸占着这条路径
数据传输,数据沿着这条找到的路径从A直接传到E
释放连接。 A和E只要有一方挂了电话,就释放连接。
在这个过程中,新建连接需要花销一定的额外时间(想象你打电话的时候是不是出现正在拨号的字眼),释放连接也会花销一些额外的时间。
那么,电话交换的过程中,数据需要分组来传送吗?
不用的,因为电路交换的过程中,A和E两个人始终霸占着一条通信电路,他们每说一句话,都会实时被对方获取,因此数据是不用分组的。
优点
- 数据不需要分组,传输速度快、高效
- 实时
缺点
- 资源利用率低
- 新建连接需要占据一定的时间,甚至比通话时间还长
分组交换
分组的概念就是将一个数据包分成一个个更小的数据包。例如,我们把一个10Gb的数据包拆分成几个小的数据包,每个分组数据块都有文件头和数据两部分。
文件头一般是一些说明性数据,例如源地址和目标地址,数据类型等;数据部分就是真正要传达给对象的内容。
我们还是以A给E传输数据为例,这个数据包很大,假设其要分成3组更小的数据包:$p_1,p_2,p_3$
这时候A给E传输数据的时候就不需要寻找一个通往E的路径了。A只要把小的数据包直接丢给附近的路由器,然后A就不管了,例如A把p1丢给了B,这个时候A就不在去管p1的,当B收到p1这个完整的小数据包之后,B再丢给E。
但是A不一定都会把剩下的数据包都丢给B,有可能会把其他的数据包p2丢给C,之后再把p3丢给D,然后C和D在转发丢给E。这些都是不确定的,会根据路由选择协议的选择路由器。
路由器必须收到完整的数据包才能进行转发, 这是因为数据包中的头部包含了源地址和目标地址,必须接收到完整的数据包,路由器才能正确转发。
缺点:
1、不具有实时性。因为服务器把数据包丢给路由器后就不管了,因此路由器可能会再绕几个圈子发给另外一个服务器。
2、存在延时。因为路由器必须收到完整的包才能继续传送这个包。在这个过程中存在传输时延。此外还存在传播时延和处理时延。
3、会造成通信阻塞。当路由器需要收到很多包的时候,会出现排队的状况。
4、存在无用的重复数据。 由于p1,p2,p3数据包都有文件头,里面都包含了A和E的一些信息,当然还有其他的信息。可以说这些文件头有很多重复的数据
5、会出现丢包的情况。当一个路由器收的包太多,撑满了路由器空间,就会出现丢包
优点:
- 相比于电路交换,更简单、更有效,实现成本更低
- 它提供了比电路交换更好的带宽共享
- 资源利用率很高。
应用举例:
假设多个用户共享一条1Mbps 链路
- 假定每个用户活跃周期时变化的——某用户时而以100kbps很速率产生数据,时而静止不产生数据。
- 假定该用户仅有10%的时间活跃
那么,对于电路交换,再所有时间内必须 为每个用户预留100kbps,因此,该电路交换电路仅能支持10个并发的用户。
但是,对于分组交换,如果有35个用户,根据排列组合定理,计算得到当有10个或者更少并发用户的概率为0.9996 时,到达的聚合数据速率小于等于该链路的输出速率1Mbps。
因此相同带宽的链路,使用分组交换可以支持更多的并发用户。
网络的网络
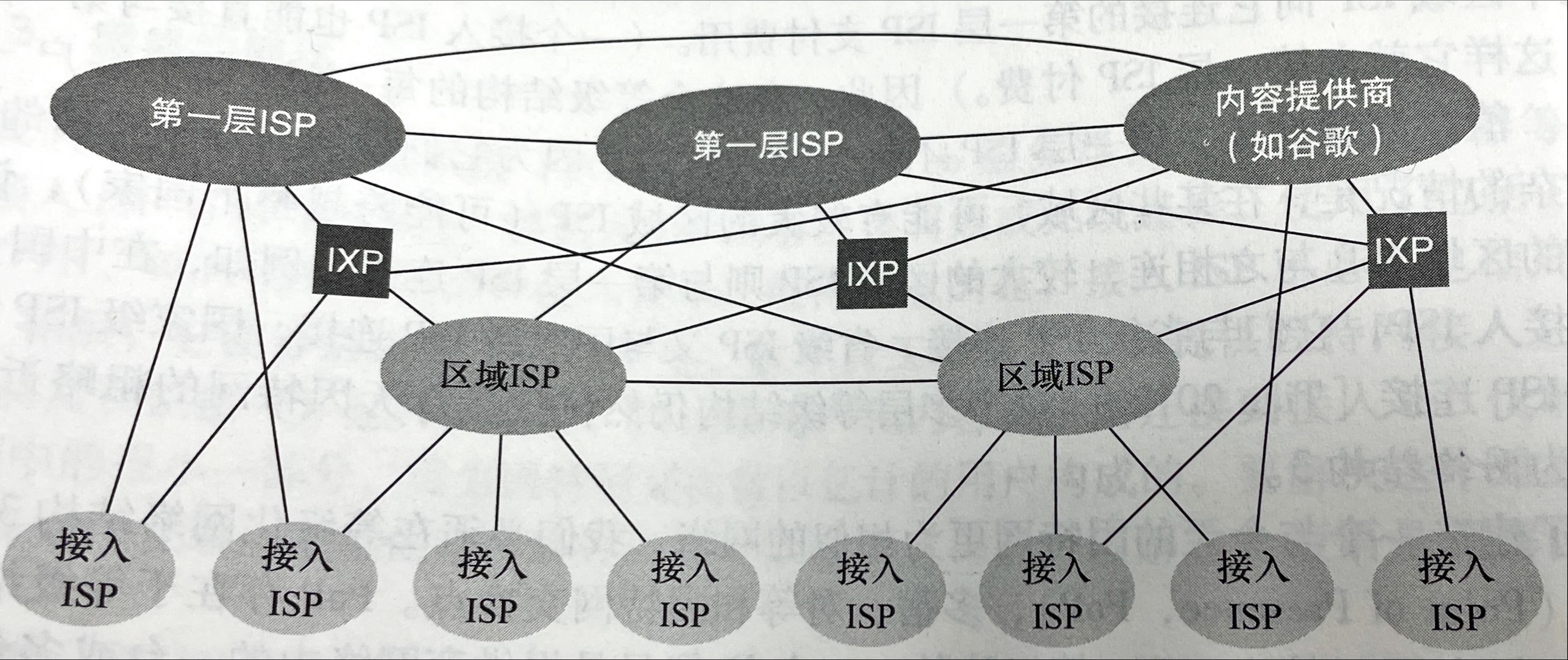
总结一下,今天的因特网是一个网络的网络,其结构复杂,由十多个第一层ISP和数十万个较低层ISP组成。ISP覆盖的区域多种多样,有些跨越多个大洲和大洋,有些限于狭窄的地理区域。
较低层的ISP与较高层的ISP相连,较高层ISP彼此互联。
用户和内容提供商是较低层ISP的客户,较低层ISP是较高层ISP的客户。
近年来,主要的内容提供商也已经创建自己的网络,直接在可能的地方与较低层ISP互联。
分组交换网中的时延、丢包、吞吐量
时延概述
有很多种不同类型的时延:
- 节点处理时延 $d_{proc}$
- 排队时延 $d_{queue}$
- 传输时延 $d_{trans}$
- 传播时延 $d_{prop}$
这些时延总统累加起来是节点总时延
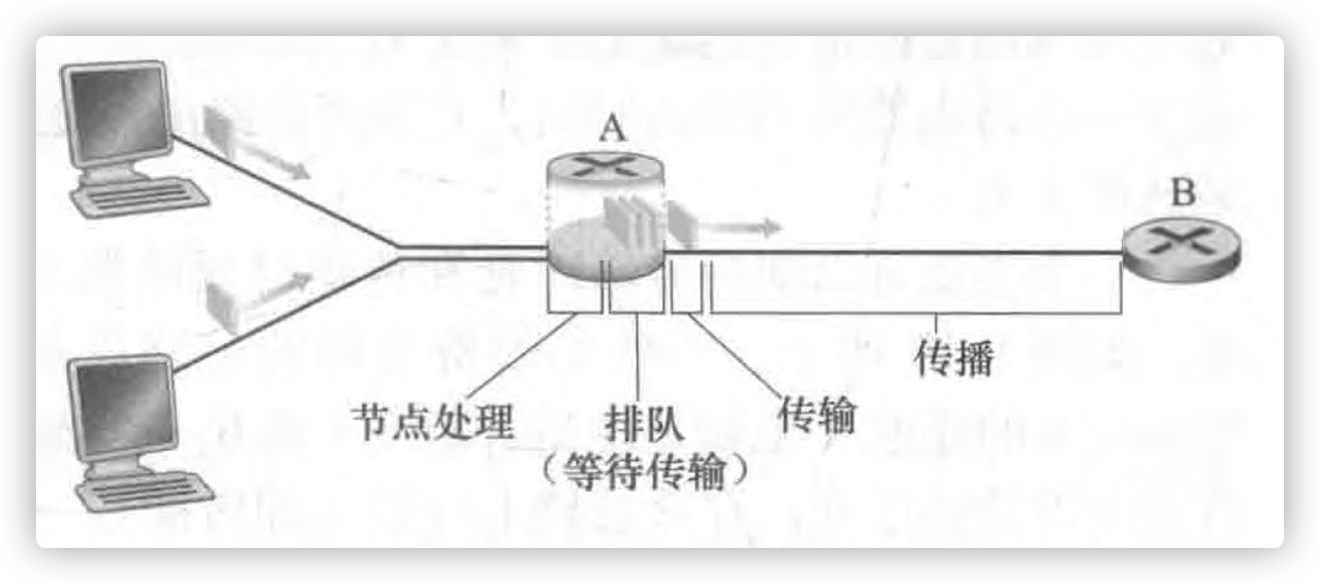
处理时延
这一部分包含了检查分组首部和决定将该分组导向何处所需要的时间。高速路由器的处理时延通常是微秒或更低的数量级。
上面说了是高速路由器,说明 $d_{proc}$ 只要计算有几个路由器,路由器个数 = 链路数-1
排队时延
在队列中,当分组在链路上等待传输时,就会出现排队时延。
- 如果该队列是空的,并且当前没有其他分组正在传输,则该分组的排队时延为0
- 如果流量很大,并且许多其他分组也在等待传输,该排队时延会很长
实际的排队时延是毫秒到微秒量级
传输时延
用L比特表示该分组的长度,用 $R bps$ 表示从路由器A到路由器B的链路传输速率。那么传输时延就是 $L/R$
这是将所有分组的比特推向链路所需要的时间(也可以说是发射出去)。实际的传输时延通常在毫秒到微秒量级
传播时延
一旦一个比特被推向链路,该比特需要向路由器B传播。从该链路的起点到路由器B的传播所需要的时间就是传播时延。传播速率取决于该链路的物理媒体(光纤,铜线)等,其速率范围是$2\times 10^8 m/s \sim 3\times 10^8 m/s$
传播时延的计算方法: 两台路由器之间的距离除以传播速率,$\frac{d}{s}$
需要注意的是,传播时延是两台路由器之间的距离除以传播速率 ,也就是说如果路上有三个路由器,实际上只走了两段路
在广域网中,传播时延为毫秒量级
时延和丢包
我们令 $La/R$ 为流量强度,其中 $a$为分组到达的速率,L为分组的长度,R为传输速率。如果流量强度$>1$, 则比特到达队列的平均速率超过从该队列出去的速率。在这种情况下,该队列趋向于无线增加,并且排队时延将趋向无穷大。
在现实中,一条链路前的队列只有有限的容量,尽管排队容量极大的依赖于路由器设计和成本。因为该排队容量是有限的。当到达的分组塞满整个队列的时候,路由器就会丢弃新到达的分组。这就是丢包
分组丢失的比例随着流量强度的增加而增加
吞吐量
考虑从服务器传送一个文件到客户的吞吐量,令$R_s$表示服务器与服务器之间的链路速率;$R_c$ 表示路由器与客户之间的链路速率。那么,服务器到哭护的吞吐量是多少?显然,其吞吐量是$\min{R_c,R_s }$ ,这就是说,吞吐率是瓶颈链路 的传输速率。
那么拓展到服务器和客户之间有N条链路的网络,这N条链路的传输速率分别是 $R_1,R_2,\cdots,R_N$ ,我们发现从服务器到客户的文件传输吞吐量是 $\min{R_1,R_2,\cdots,R_N}$ ,这同样是瓶颈链路的传输速率。
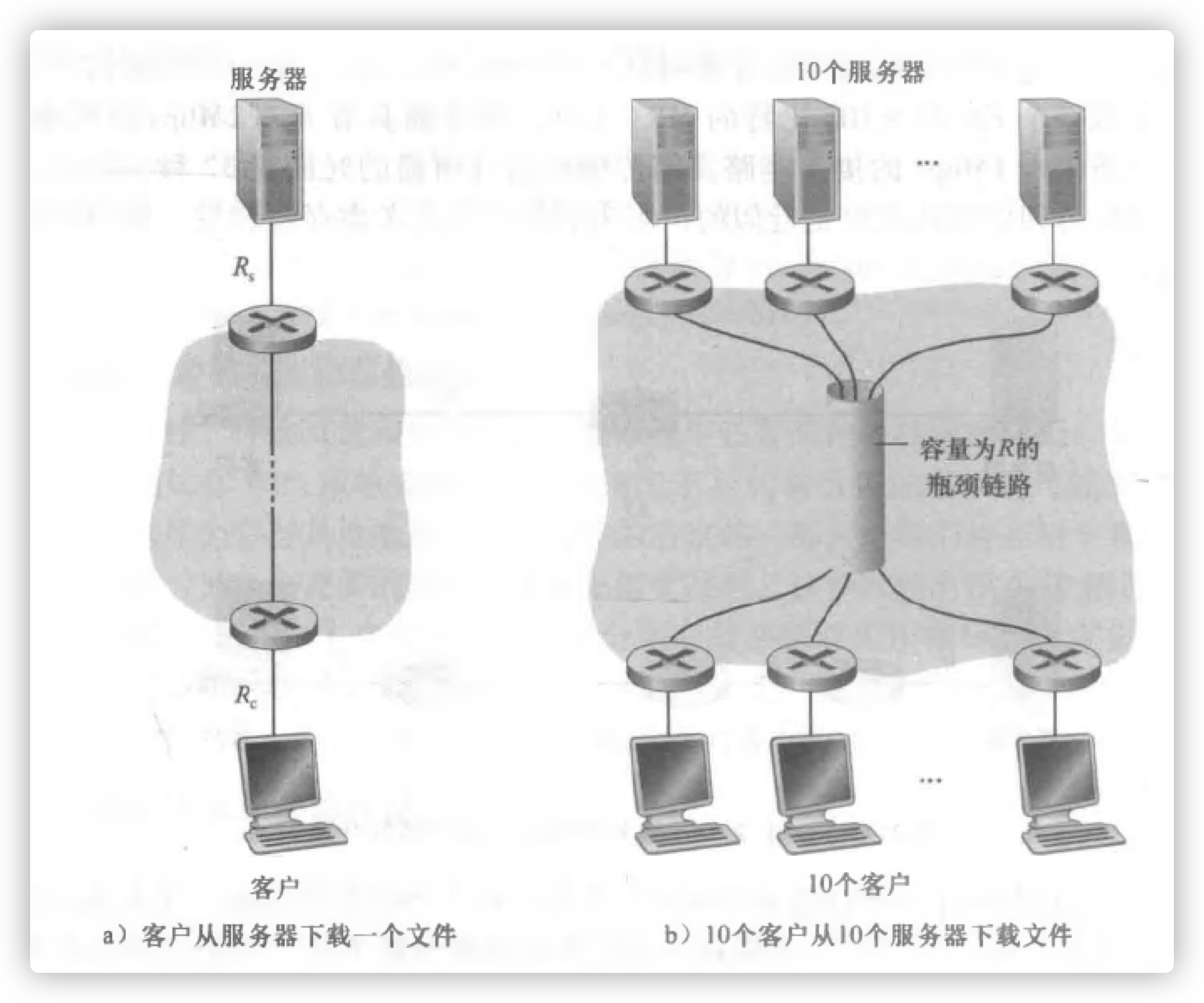
假定$R_s=2Mbps, R_c=1 Mbps, R=5Mbps$, 并且公共链路为10个下载平等划分它的传输速率。这时每个下载的瓶颈不再位于接入网中,而是位于核心中的共享链路了,该瓶颈仅能为每个下载提供 500kbps的吞吐量。因此每个下载的端到端吞吐量现在减少到500kbps.
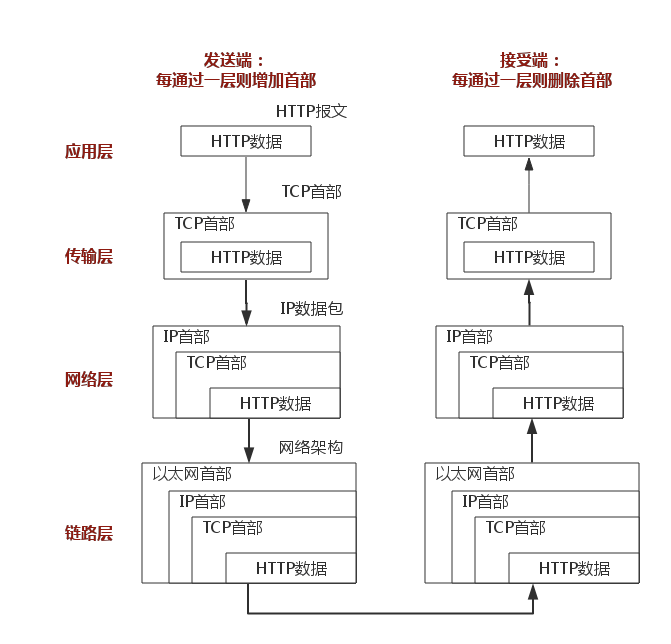
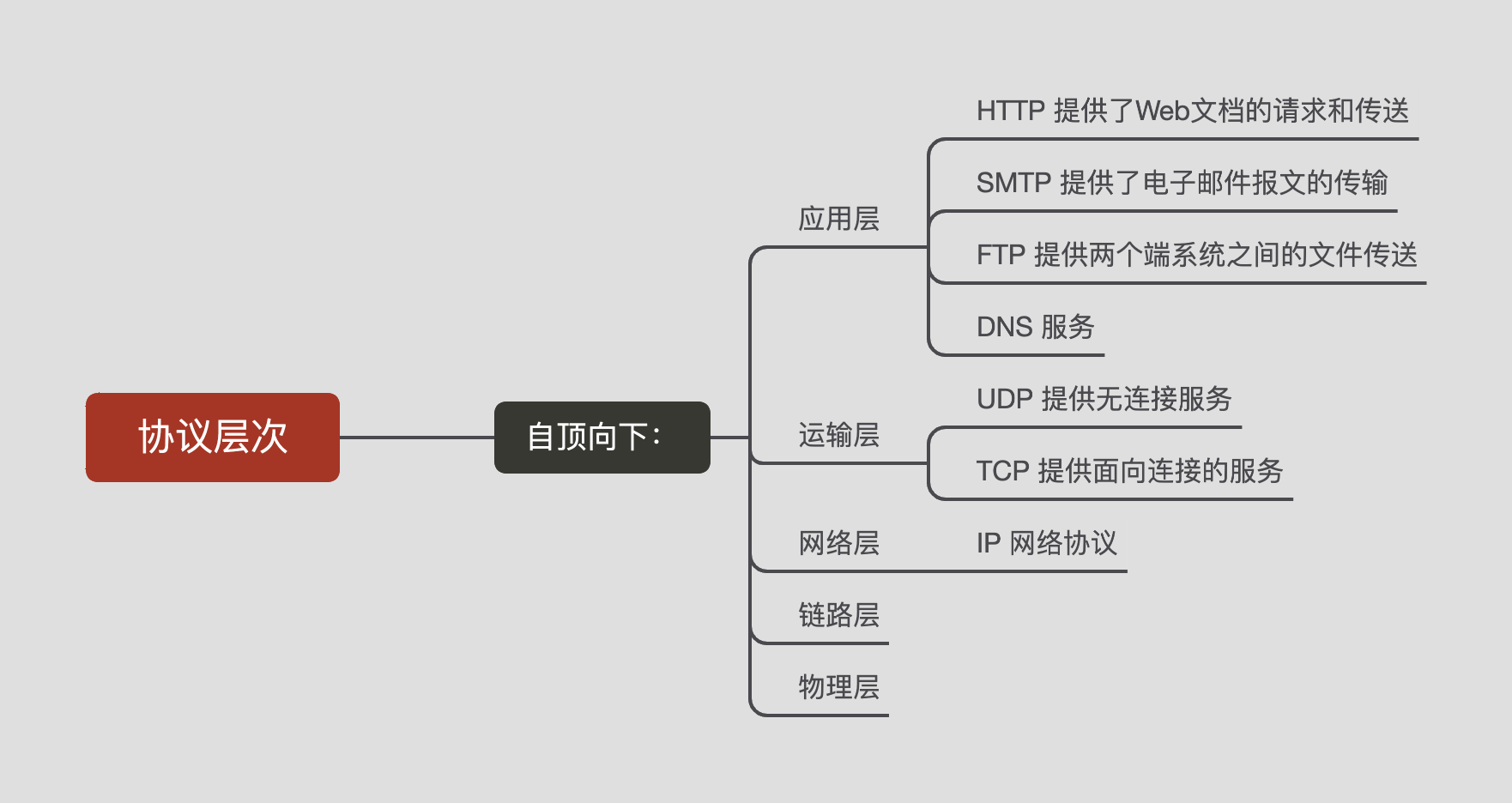
协议层次及其服务模型
因特网的协议栈由5个层次组成:物理层、链路层、网络层、运输层和应用层。我们采用了自顶向下方法,首先处理应用层,然后向下进行处理。
数据包的发送与接收如下所示