绪论
总体与样本
总体与个体
在一个统计问题中,我们把研究对象的全体称为总体,构成总体的每个成员称为个体。比如说:
- 某大学的全体学生构成问题的总体,每一个学生就是一个个体
抛开实际背景,总体就是一堆数,这堆数中有大有小,因此用一个概率分布去描述和归纳总体是恰当的。从这个意义看,总体就是一个分布,而其数量指标就是服从这个分布的随机变量。所以从总体中抽样与从某分布中抽样是同一个意思
总体还有有限总体和无限总体,接下来将以无限总体作为主要研究对象。
样本
为了了解总体的分布,我们从总体中随机地抽取n个个体,记其指标值为$x_1,x_2\cdots,x_n$, 则 $x_1,x_2,\cdots,x_n$称为总体的一个样本。
样本数据的整理与显示
经验分布函数
设$x1,x_2\cdots,x_n$ 是取自总体分布函数为$F(x)$的样本,若将样本观测值有小到大进行排列,记为$x{(1)},x{(2)},\cdots,x{(n)}$ ,则$x{(1)},x{(2)},\cdots,x_{(n)}$ 称为有序样本,用有序样本定义如下函数:
则$F_n(x)$ 是一非减右连续函数,称$F_n(x)$为该样本的经验分布函数
设$x_1,x_2,\cdots,x_n$是取自总体分布函数为$F(x)$的样本,$F_n(x)$ 是经验分布函数,当$n\rightarrow \infty$时,有:
因此,经验分布函数的pdf和cdf可以写为:
统计量及其分布
统计量与抽样分布
设 $x_1,x_2\cdots,x_n$ 为取自某个总体的样本,若样本函数 $T=T(x_1,x_2\cdots,x_n)$ 中不含任何未知函数,则称T为统计量。因此,统计量是一类函数,而统计量的分布称为抽样分布。
按照这一定义,若$x1,x_2\cdots,x_n$ 为样本,则 $\sum{i=1}^n xi,\sum{i=1}^n x_i^2$ 都是统计量,但是当$\mu,\sigma^2$ 未知时,$x_1-\mu,x_1/\sigma$ 这类的函数就不能称之为统计量。 注意了,尽管统计量不依赖于未知参数,但是它的分布是依赖于未知参数的。
下面我么来介绍一些常见的统计量及其抽样分布
样本均值及其抽样分布
首先我们给出样本均值的定义:
设 $x_1,x_2\cdots,x_n$ 为取自某总体的样本,其算数平均值称为样本均值,一般用$\overline x$ 表示,即:
在分组样本场合,样本的近似公式为:
其中,k为组数,$x_i$ 为第i组的组中值, $f_i$ 为第i组的频数
关于样本均值,有以下几个性质:
若把样本中的数据与样本均值之差称为偏差,则样本所有偏差之和为0,即 $\sum_{i=1}^n(x_i-\overline n) = 0$ 这是显然的。
数据观测值与样本均值的偏差平方和最小,即 :
用文字描述的话,就是对任意给定的常数 c, 对于形如 $\sum(x_i-c)^2$ 的函数,$\sum(x_i-\overline x)^2$ 最小
设 $x_1,x_2\cdots,x_n$ 是来自某个总体的样本,$\overline x$ 为样本均值
- 若总体分布为 $N(\mu,\sigma^2)$ , 则$\overline x$ 的精确分布为 $N(\mu,\sigma^2/n)$
- 若总体分布未知或者不是正态分布,且 $E(x)=\mu,Var(x) = \sigma^2$ 存在,则n较大时$\overline x$ 的渐进分布为$N(\mu,\sigma^2/n)$ 。这里渐近分布是指n较大的时候的近似分布
样本方差与样本标准差
首先给出定义:
设 $x_1,x_2\cdots,x_n$ 为取自某总体的样本,则它关于样本均值 $\overline x$ 的平均偏差平方和就被称为样本方差:
其算术根 $s_n=\sqrt{s_n^2}$ 称为 样本标准差。相对样本方差而言,样本标准差通常更有实际意义,因为它与样本均值具有相同的度量单位。
在n 不大时,常用下式作为样本方差(s没有n):
其算数根 $s=\sqrt{s^2}$ 也被称为样本标准差。
在实际中,$s^2$ 比 $s^2_n$ 更常用,以后我们都是用 $s^2$
样本方差是度量样本散布大小的统计量, 在这个定义中,n 为 样本量,n-1 称为偏差平方和的自由度。其含义是: 在 $\overline x$ 确定后,n个偏差 $x_1-\overline x,x_2-\overline x,\cdots,x_n-\overline x$ 中只有 $n-1$个偏差可以自由变动(因为其和为0)
样本偏差平方和有三个常用的表达式, 它们都可以用来计算样本方差:
在分组样本场合,样本方差的近似计算公式为:
其中 $x_i,f_i$ 分别为第i个区间的组中值和频数,$\overline x = \frac{x_1f_1+x_2f_2+\cdots+x_kf_k}{n}$ 给出的均值近似值
样本矩及其函数
样本矩和矩一样,是样本均值和样本方差更一般的推广,是一类常见的统计量。
设 $x_1,x_2\cdots,x_n$ 是样本,k为正整数,则下面这个统计量被称为k阶原点矩
样本一阶原点矩就是样本均值
类似的,我们给出样本的k阶 中心矩:
样本二阶中心距就是样本方差
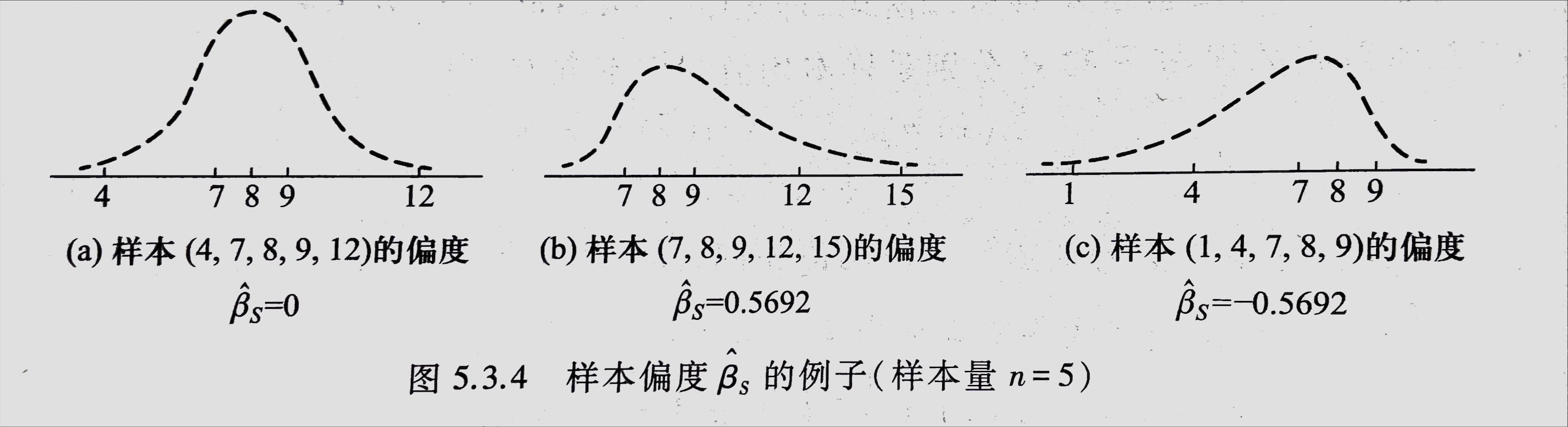
现在再介绍样本偏度和样本峰度,它们都是中心矩的函数
设 $x_1,x_2\cdots,x_n$是样本,则称统计量
为样本偏度
如果数据完全对称,那么$b_3=0$ 样本偏度就等于0;
如果 $\hat\beta_s$ 明显大于0,表示样本的右尾长,即样本中有几个特大的数,我们称其为正偏的右偏
如果 $\hat\beta_s$ 明显小于0,表示分布的左尾长,即样本中有几个特小的数,这反映了总体分布是负偏的或左偏的。
设 $x_1,\cdots,x_n$ 是样本,则称统计量:
为样本峰度
当 $\hat\beta_k$ 明显大于0 时,分布密度曲线在其峰值附近比正态分布来的更陡,尾部更细——称为尖顶型
当$\hat\beta_s$ 明显小于0时,分布密度曲线在其峰值附近比正态分布来得平坦,尾部更粗,称为平顶型
次序统计量及其分布
设 $x1\cdots,x_n$ 是取自总体X的样本,$x{(i)}$ 称为该样本的第 i 个次序统计量,它的取值是将样本观测值由小到大排列后得到的第i个观测值。其中 $x{(1)}$ 为该样本的最小次序统计量,$x{(n)}$ 称为该样本的最大次序统计量。
$(x{(1)},x{(2)},\cdots,x_{(n)})$ 称为该样本的次序统计量
在一个样本中, $x1,x_2\cdots x_n$ 是独立同分布的,而次序统计量 $x{(1)},x{(2)}\cdots,x{(n)}$ 即不独立,分布也不相同。
接下来我们讨论次序统计量的抽样分布。
单个次序统计量的分布
设总体X的密度函数为 $p(x)$ 分布函数为$F(x)$ ,$x1,x_2\cdots,x_n$为样本,则第k个次序统计量 $x{(k)}$ 的密度函数为:
特别的,当总体分布为 $U(0,1)$时,$x_1,\cdots,x_n$ 为样本,则其第k个次序统计量的密度函数为:
这就是贝塔分布 $Be(k,n-k+1)$ 从而有 $E(x_{(k)})=\frac{k}{n+1}$
例题
设总体目睹函数为:
现从该总体抽得一个容量为5的样本,试计算 $p(x_{2}<\frac{1}{2})$
第一步:求出总体分布函数
第二步:求出$x_{(2 )}$ 的密度函数
第三步:计算概率
多个次序统计量及其函数分布
次序统计量$(x{(i)},x{(j)})(i<j)$ 的联合分布密度函数为:
样本分位数与样本中位数
样本中位数 $m_{0.5}$ 也是一个常见的统计量,它也是次序统计量的函数,当n为奇数时,取中间那个数;当n为偶数时,取中间两个数的平均数。
更一般的,样本p分位数$m_p$ 可如下定义:
分位数的渐进分布
设总体密度函数为$p(x)$,$x_p$ 为其p分位数,$p(x)$ 在$x_p$处连续且 $p(x_p)>0$ ,那么当$n\rightarrow \infty$时,样本p分位数$m_p$ 的渐进分布为:
特别的,对于样本中位数,当$n\rightarrow \infty$时,近似地有
例题:
在下列密度函数下分别寻求容量为n的样本中位数$m_{0.5}$的渐近分布:
我们从这个密度函数就可以判断该分布为贝塔分布$Be(2,2)$ , 可以看出$p(x)$ 关于 0.5 对称,所以$x_{0.5}=0.5$
于是可以带入公式,得到渐进分布为 $N(0.5,\frac{1}{9n})$
显然,正态分布的中位数是 $\mu$ ,所以,$m_{0.5}$ 的渐近分布为$N(\mu,\frac{1}{4n\cdot\frac{1}{2\pi \sigma^2}}) =N(\mu,\frac{\pi\sigma^2}{2n})$
该分布的分布函数为 $F(x) = \begin{cases}0,x<0\~\x^2,0\leq x<1\~\1 ,x\geq 1\end{cases}$ 所以相应的中位数为$\frac{\sqrt2}{2}$ ,所以$m_{0.5}$ 的渐进分布为
三大抽样分布
很多统计推断是基于正态分布的假设,以标准正态变量为基石而构造的三个著名的统计量在十几种有广泛的应用。

下面我们逐个进行推导和证明
$\mathcal X^2$ 分布
设 $X_1,X_2\cdots,X_N$ 独立同分布于标准正态分布 $N(0,1)$ ,则 $\mathcal X^2 = \mathcal X_1^2+\cdots+\mathcal X_n^2$ 的分布被称为自由度为n的$\mathcal X^2$ 分布,记为 $\mathcal X^2\sim \mathcal X^2(n)$
在第三章中我们还给出了 卡方分布和伽马分布的关系,也就是$X^2(n) = Ga(\frac{n}2,\frac12)$ , 期望为 n, 方差为2n
$\mathcal X^2$ 分布有用的一个重要原因是下面这个定理:
重要定理
设 $x_1,x_2\cdots,x_n$ 是来自正态总体$N(\mu,\sigma^2)$ 的样本,其样本均值和样本方差分别为:
则有:
- $\overline x$ 与 $s^2$ 相互独立
- $\overline x\sim N(\mu,\sigma^2/n)$
- $\frac{(n-1)s^2}{\sigma^2}\sim \mathcal X^2(n-1)$
F分布
设随机变量 $X_1\sim \mathcal X^2(m),X_2\sim\mathcal X^2(n)$,$X_1$ 与 $X_2$ 独立,则称 $F=\frac{X_1/m}{X_2/n}$ 的分布是自由度为m和n的F分布。记为 $F\sim F(m,n)$ ,其中m称为分子自由度,n称为分母自由度。
推论:
设$x_1,x_2,\cdots,x_m$ 是来自 $N(\mu_1,\sigma_1^2)$的样本,$y_1\cdots,y_n$是来自$N(\mu_2,\sigma_2^2)$的样本,且此两样本相互独立。记:
其中:
则有“
特别的,若 $\sigma_1^2=\sigma_2^2$ 则 $F=s_x^2/s_y^2\sim F(m-1,n-1)$
例题: 构造F分布
设$x_1,x_2$是来自 $N(0,\sigma^2)$ 的样本,试求 $Y=(\frac{x_1+x_2}{x_1-x_2})^2$ 的分布。
第一步:根据形态判断应该凑成哪个分布
首先可以排除 t 分布的形式,因为没有根号出现。其次,这是一个分数的形式,因此最大的可能就是F分布。因此我们要想方设法配成F分布。
配成F分布的条件是:$F=\frac{X_1/m}{X_2/n}$ 其中$X_1$和$X_2$是两个卡方分布。而这里,$m=n=2$, 消去。 因此只要证明 $(x_1+x_2)^2$ 和 $(x_1-x_2)^2$ 都属于卡方分布即可。
第二步:卡方分布怎么凑?
凑卡方分布第一可以从 $Ga(n/2,1/2)$ 入手,或者从卡方分布:$x_1,x_2\cdots,x_n$ 独立同分布于标准正态分布, $\mathcal X^2 = x_1^2+\cdots+ x_n^2$ 的定义入手。
因为 $x_1,x_2$ 来自 $N(0,\sigma^2)$ , 二者又是独立同分布的,因此: $x_1+x_2\sim N(0,2\sigma^2),x_1-x_2\sim N(0,2\sigma^2)$ 把这两者看做是一个整体。标准化之后,可以获得:
也就是说,一个单独的 $(\frac{x_1+x_2}{\sqrt{2\sigma^2}})^2$就可以看做是一个卡方分布;同理,$(\frac{x_1-x_2}{\sqrt{2\sigma^2}})^2$ 构成了另一个卡方分布,那么:
t 分布
设随机变量 $X_1$与$X_2$ 独立且$X_1\sim N(0,1),X_2\sim \mathcal X^2(n)$则称$t=\frac{X_1}{\sqrt{X_2/n}}$ 的分布为自由度为n的t分布,记为 $t\sim t(n)$
t分布的密度函数的图像是一个关于纵轴对称的分布,与标准正态分布的密度函数形状类似,只是峰比标准正态分布低一点尾部的概率比标准正态分布大一些
- 自由度为1的t分布就是标准柯西分布,其均值不存在
- $n>1$时,t分布的数学期望存在且为0
- $n>2$时,t分布的方差存在且为$n/(n-2)$
- 当自由度比较大时,t分布可以用$N(0,1)$分布近似
推论
设 $x_1,x_2\cdots,x_n$ 是来自正态分布$N(\mu,\sigma^2)$的一个样本,$\overline x$ 与$s^2$ 分别是该样本的样本均值和样本方差则有:
充分统计量
概念
我们之前谈了这么多的统计量,知道了统计量是关于样本的函数。对于一个总体来说,我们选取的样本是有限的,但是有限的样本会反映出总体的一些信息,进而可能帮助我们推断总体分布,那么我们希望某个统计量所包含的有用的信息和样本分布所包含的有用的信息是一样的,则这个统计量对将来的统计推断就非常有用——这就是充分统计量的直观含义
我们通过几个例子来更全面的了解充分统计量
例1
为研究某个运动员的打靶命中率$\theta$ ,我们对该运动员进行测试,观测其10次打靶结果,发现除了第3、6次未命中之外,其余8次都命中靶心。这样的观测结果告诉我们两点:
- 打靶10次命中8次
- 2次不命中分别出现在第3次和第6次打靶上
其实,第二点信息对我们了解这个运动员的命中率是没有帮助的。我们令每次射击要么命中要么不命中,命中为1,不命中为0. 那么命中率的计算和1出现的位置是没有关系的,而和出现1的次数有关系,比如第二轮打靶发现除了第1、2未命中其余都命中,虽然两轮样本观测值不一样,但是提供的关于命中率$\theta$的信息是一样的。因此在大多数实际问题中,试验编号信息常常对了解总体或者其参数是无关紧要的
现在我们要想,什么统计量能反映出该选手的命中率$\theta$呢? 很显然,令 $T = x_1+\cdots+x_n$ ,那么就可以通过T与样本数来反应命中率 $\theta$ 了。 统计上,将这种样本加工不损失信息称为充分性
接下来,我们从概率层面分析:首先我们要搞清楚什么是有用的信息? 其实,有用的信息就和分布中的参数
我们知道,样本$X=(x1,x_2\cdots,x_n)$ 有一个样本联合分布 $F\theta(X)$, 这个分布包含了样本中一切有关$\theta$的信息。 统计量$T=T(x1\cdots,x_n)$也有一个抽样分布 $F\theta^n(t)$ 。当我们期望用统计量T代替原始样本X并且不损失任何有关$\theta$的信息 时,说明 $F\theta^T(t)$ 可以像$F\theta(X)$ 一样概括了有关$ \theta$ 的一切信息。
换言之,我们考察统计量T的取值为t的情况下样本X的条件分布$F\theta(X|T=t)$ ,当 $F\theta(X|T=t)$ 不依赖于参数$\theta$ 时,说明样本所反映出来的有用的信息,都包含在统计量 T当中了。相当于我们给定了一个统计量的值之后,也就知道了样本中关于$\theta$的所有信息,剩下的其他信息就没什么价值了,这正是统计量具有充分性的含义。
例2
现在我们看看充分统计量和不充分的统计量之间的区别
设总体为二点分布 $b(1,\theta)$ ,$X1,X_2\cdots,X_n$为样本,令 $T = X_1+X_2\cdots+X_n$ ,则在给定了T的取值之后,对于任意一组 $x_1,x_2\cdots,x_n$ ,$\sum{i=1}^n x_i = t$ 都有:
化简得到:
到最后,这个条件分布已经和 $\theta$没关系了。
但是我们现在令 $S=X_1+X_2$, 显然没有包含样本中所有关于$\theta$的信息,那么,在给定的$S=s$之后,对于任意一组$x_1,x_2\cdots,x_n,(x_1+x_2=s)$ 有:
这个分布最终的化简结果依赖于未知参数$\theta$,这说明样本中有关$\theta$的信息并没有完全包含在统计量S中。
定义
经过了上面这两个例子,其实充分统计量的定义就呼之欲出了。
设$x_1,x_2,\cdots,x_n$ 是来自某个总体的样本,总体分布函数为 $F(x;\theta)$ ,统计量 $T=T(x_1\cdots,x_n)$ 称为$\theta$的充分统计量,如果在给定T的取值后$x_1\cdots,x_n$ 的条件分布与$\theta$无关
未知参数$\theta$ 可以是一维的也可以是多维的,应用中条件分布可以用条件分布列或者条件密度函数来表示。
例题
设$x_1\cdots,x_n$ 是来自$N(\mu,1)$的样本,试证明 $T=\overline x$ 是$\mu$的充分统计量
总体采用配方策略
因子分解定理
在一般场合,直接由充分统计量的定义出发来验证一个统计量是充分的是困难的,因为条件分布的计算通常不那么容易。但是,我们有一个简单的办法判断一个统计量是否充分,这就是因子分解定理。 为了简便起见,我们引入一个两种分布类型通用的概念——概率函数。$f(x)$ 称为随机变量X的概率函数:在连续场合,$f(x)$表示X的概率密度函数,在离散场合,$f(x)$表示X的概率分布列。
定理:
设总体概率函数为 $f(x;\theta)$ ,$x_1,\cdots,x_n$ 为样本,则 $T=T(x_1,x_2\cdots,x_n)$ 为充分统计量的充分必要条件是:存在两个函数 $g(t;\theta)$ 和 $h(x_1,x_2\cdots,x_n)$ 使得对任意的 $ \theta$ 和任意一组观测值 $x_1\cdots,x_n$ 有:
其中,$g(t,\theta)$ 是通过统计量T的取值而依赖于样本的。也就是 $h(x_1,\cdots,x_n)$ 中不包含 $\theta$ 参数,$\theta$ 全部都在$g(t,\theta)$中
但是有时候我们在求联合分布函数的时候需要乘以一个示信函数 I, 当 x 和我们的参数之间存在关系时,比如:
设$x_1,x_2,\cdots,x_n$ 是取自总体 $U(0,\theta)$ 的样本,即总体的密度函数为:
于是,样本的联合密度函数是:
由于所有的 $x_i$都大于0, 且都小于$\theta$ 这里x的取值范围和$\theta$是有关系的,这时在写联合密度函数时就需要乘以示信函数,如下:
注意到这里示信函数为
因为根据上面写的密度函数,最大的$x_i$ 也是小于参数$\theta$ 的
例题1
设 $x_1\cdots,x_n\sim b(1,p)$ ,对其进行因子分解
令 $T=\sum x_i$ 经过配方:
那么,我们可以得到 $g(t;p)$ 和 $h(x_1,\cdots,x_n)$
所以, $\sum x_i$ 是 $p$ 的充分统计量
例题2
设 $x_1\cdots,x_n\sim N(0,\sigma^2)$ ,对其进行因子分解
令 $T=\sum x_i^2$ ,经过配方可以得到 $g(t;\sigma^2)$和$h(x_1,x_2\cdots,x_n)$
符合因子分解,那么 $\sum x_i^2$ 是$\sigma^2$的充分统计量
例题3
设$x_1\cdots,x_n\sim N(\mu,\sigma^2)$ 对其进行因子分解
这题比较特殊,因为这里 $\theta$ 是一个二维的参数: $\theta =\begin{pmatrix} n \ \sigma ^{2} \end{pmatrix}$
令$t1=\sum{i=1}^n xi,t_2=\sum{i=i}^n x_i^2$ 我们可以根据化简的结果计算$g(t;\theta)$和$h(x_1\cdots,x_n)$
例题4

对于(a)
- 首先,观察 x的取值范围是否和参数有关系,并写出联合密度函数。
显然这里,x和参数是有关系的,每一个 x 都要大于 $\mu$, 因此,最小的x也要大于$\mu$
- 根据因式分解定理,提取$T = x{(1)}$ ,则 $g(t;\mu) = \prod{i=1}^n\exp{-(x-\mu)}I{\mu<x_{(1)}}$ ,$h(x)=1$