Django学习1
Fundamentals
Django 是一个用来做Web开发的、基于python的开源框架。YouTube、Instergram等网页就是用Django制作的。
Django的好处有很多,比如说它直接提供了一个 admin site,也就是后台帮我们监控流量、处理用户信息等,帮我们减少了很多编程的时间。以及 Object-related mapper(ORM),这可以让我们少些很多SQL语句。此外还有Authentication以及提供了Cache 等优点。
我们之前已经学过了一些前端和后端,前端有 React 后端有 Express。那其实Django是一个Web后端,当浏览器向后端发送HTTP请求的时候,后端就会通过查询、计算等步骤返回给前端一些数据(不返回网页是因为效率太低),然后前段负责渲染这些数据。
我们使用的环境
python3.9
pip3 install pipenv
vscode
现在我们在文件夹中新建一个Django项目:
1 | mkdir storefront |
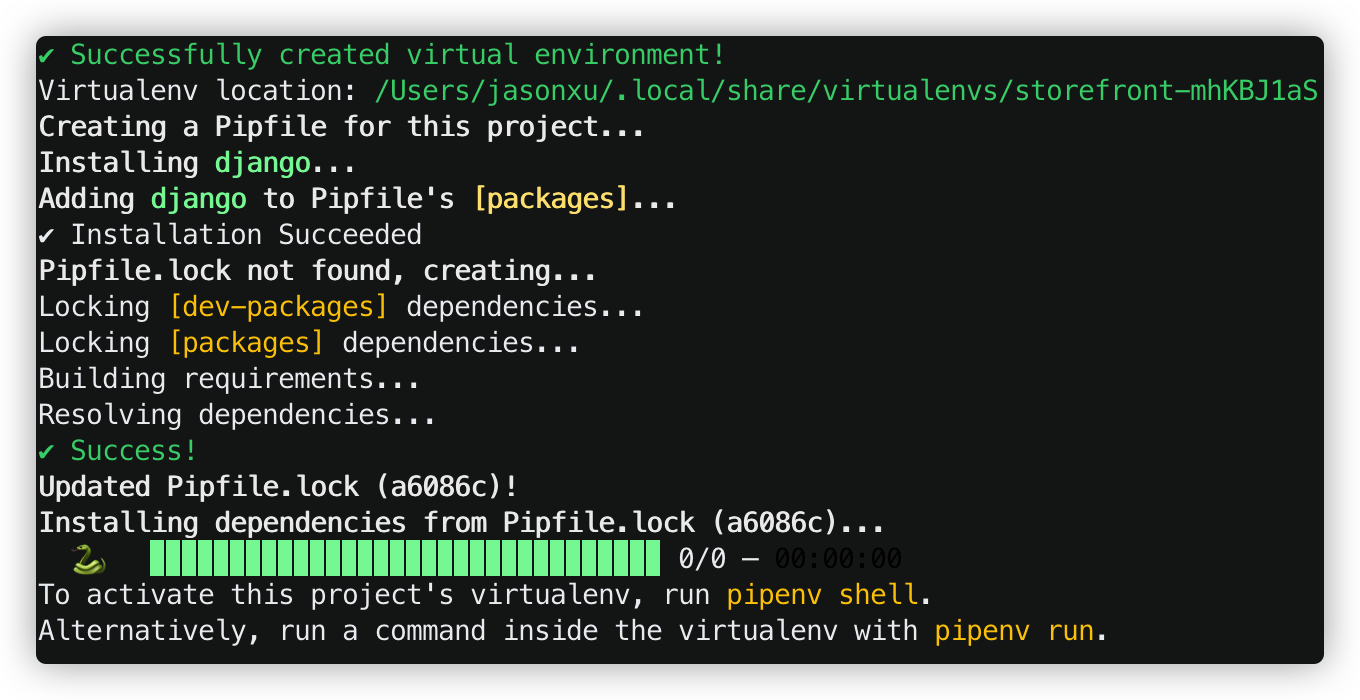
输入pipenv install django 之后,会给这个Django项目新建一个虚拟的python环境。然后,python会在这个虚拟环境中下载Django。与此同时,python还为我们生成了两个文件: Pipfile 和 Pipfile.lock, 这两个文件存放着一些关于虚拟环境的信息:Pipfile如下,我们可以看到虚拟环境的python版本以及已经安装的package,这里暂且只有django 。其中django = "*" 代表可以兼容Django之前的版本。
1 | [[source]] |
接下来用pipenv shell来启动虚拟环境,并用django-admin startproject storefront . 来新建一个名叫storefront 的Django项目(之所以这里要加一个 . 是因为要把当前文件夹作为根目录,否则目录层级太多了,管理起来不方便)。创建好后如下图所示
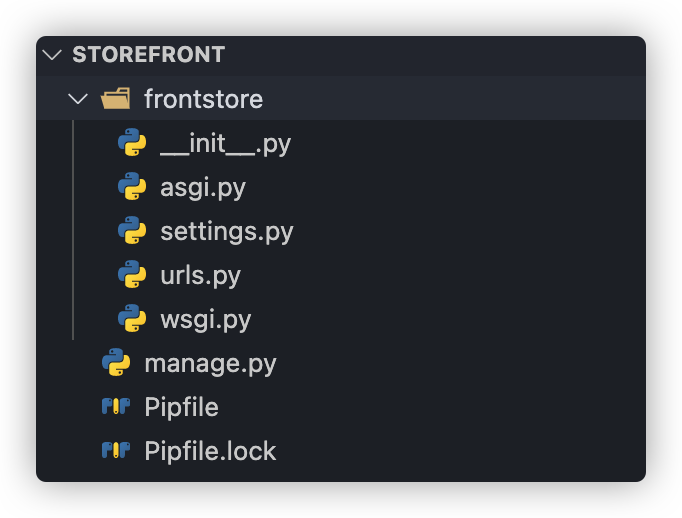
在
frontstore子文件夹中有这些文件:
__init__.py是用来定义的
asgi.py,wsgi.py是用来发布项目的
setting.py是Django 项目的配置文件。如果你想知道这个文件是如何工作的,请查看https://docs.djangoproject.com/zh-hans/2.1/topics/settings/
urls.py是用来保存路由网址的在根目录下还有
manage.py,是一个让你用各种方式管理 Django 项目的命令行工具。
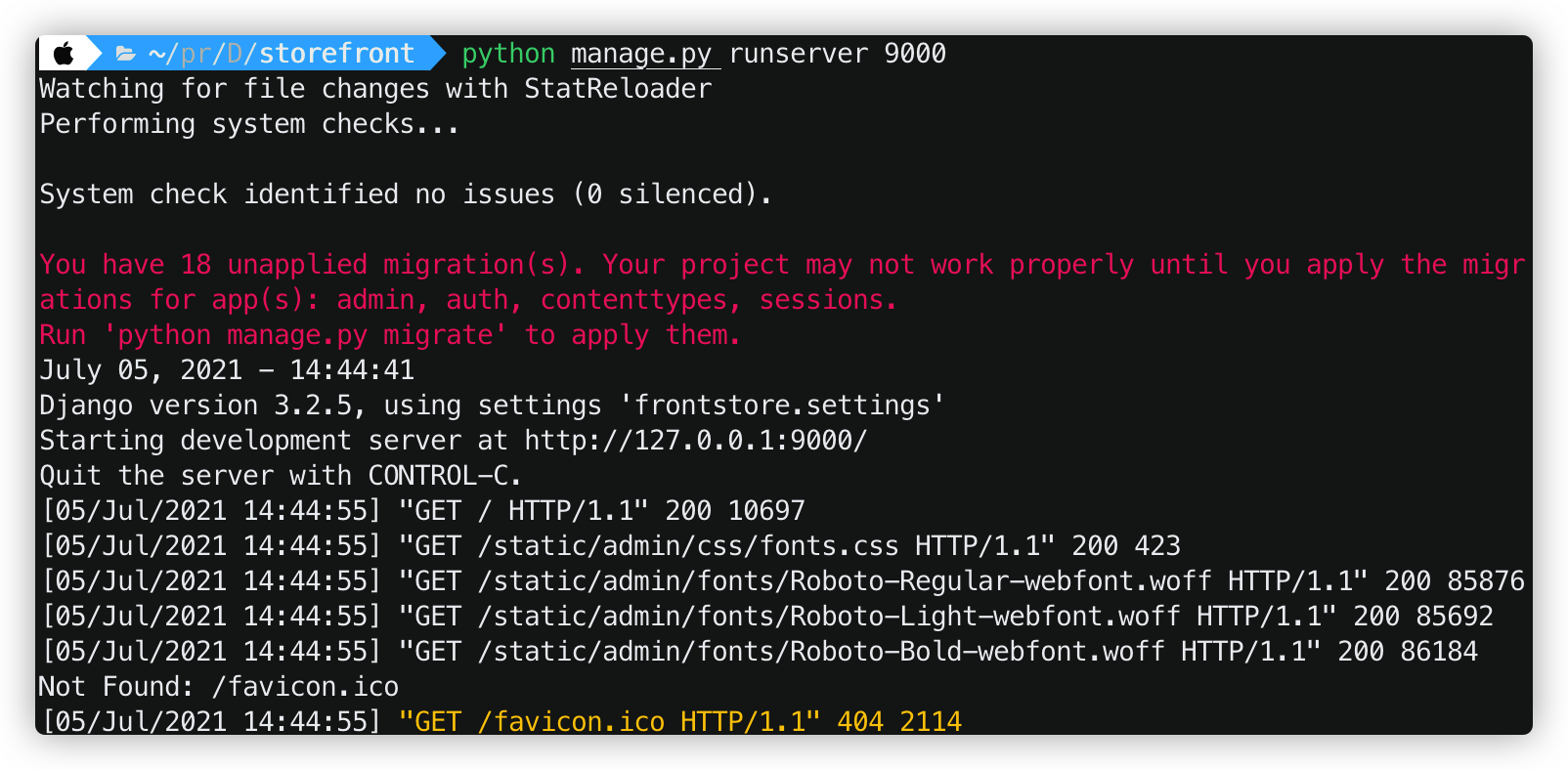
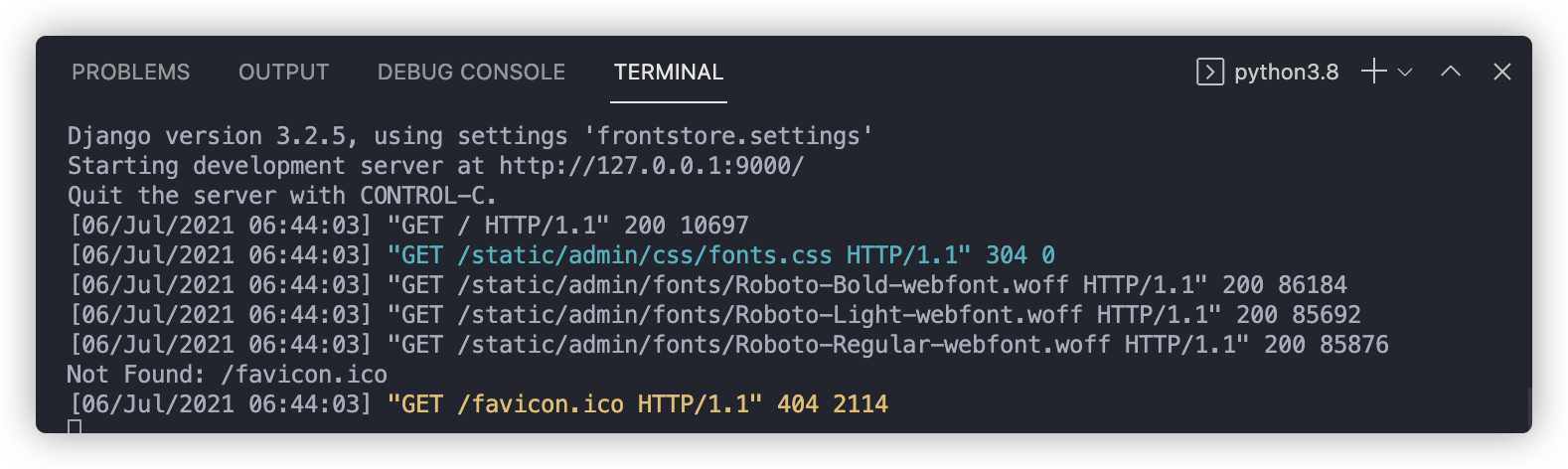
现在如果我们直接运行 django-admin runserver 是不能启动这个Django项目的,会告诉我们还没有配置好。因此我们需要先运行:python manage.py runserver 9000
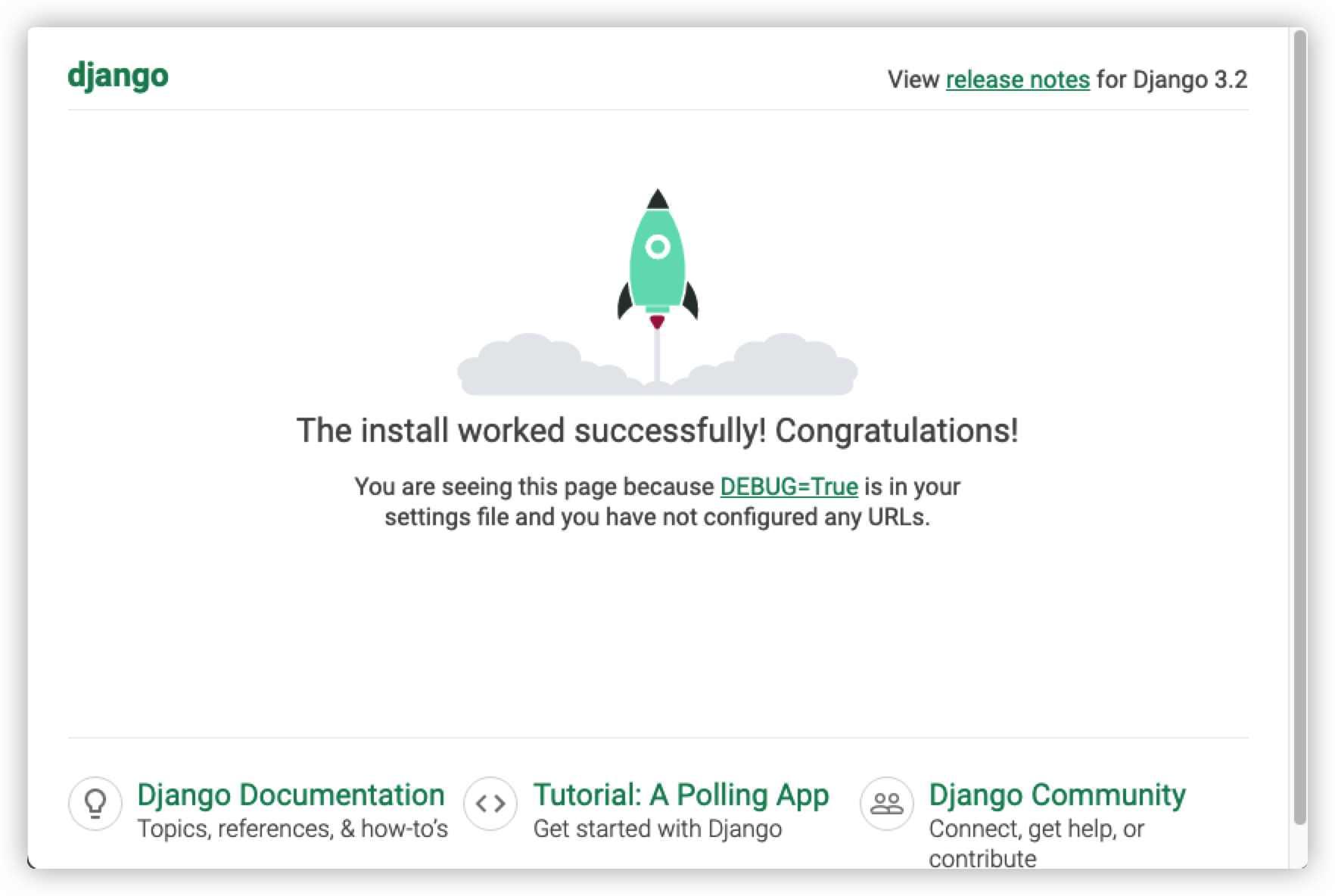
打开http://127.0.0.1:9000/ 可以看到如下页面:
要在vscode中打开Terminal并使用python环境,首先可以通过快捷键shift+command+p打开配置栏并修改python interpreter为我们刚刚创建的虚拟环境。然后再通过 ctrl+` 或者 view>terminal打开终端。
Creating Your First App
Django可以看成是一些组件的集合,其中每个组件负责不同的功能。在 settings.py 中,我们可以看到Django中已经默认安装的APP,我们也可以写自己的APP
1 | # Application definition |
创建的语句如下:
1 | python manage.py startapp playground |
也就是创建一个名为 playground 的APP,结构如下
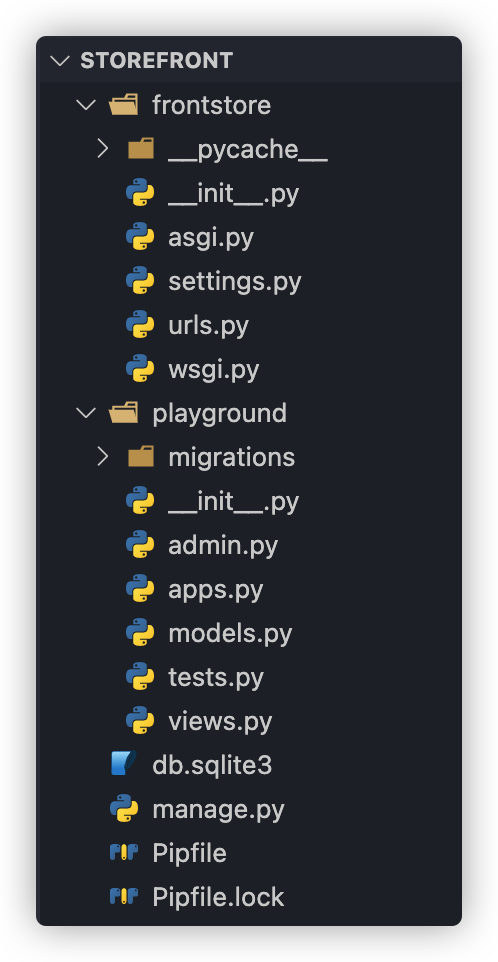
migration 文件夹是用来生成数据表的
admin.py 是用来写这个app的用户界面的
apps.py 是用来配置这个app的
models.py 是用来和“接收”数据库的信息的
tests.py 是用来单元测试的
views.py 视图,用来接受 Web 请求并且返回 Web 响应。
创建完之后,我们需要在 setting.py 中加入这个APP
Writing Views
View相当于一个句柄,收到了来自web前端发来的请求之后就返回一个Response。我们可以在里面写视图函数,视图函数的名字是任意的,比如下面这个 say_hello函数。
1 | from django.shortcuts import render |
因此Django中的view用视图去理解是非常抽象的,我们将其理解为句柄即可。
这个意思是说,当解析得到了playground/ 之后,交给playground.urls这个文件去处理/后面的内容。
写好了 视图,现在就要通过网页来访问后台了,于是我们要把urls注册进去。我们的目标是希望请求 http://localhost:9000/playground/hello/ 时在前端显示 Hello World。
Django中的url是可以分层级注册的。比如说我在frontstore这个主应用文件夹下的urls.py中注册第一层的url :
1 | urlpatterns = [ |
现在我们编写playground中的urls.py
1 | from django.urls import path |
这是第二层的url了,由于一开始playground交给上层解析掉了,现在我们只需要负责解析hello/即可。
注意要点:
- url的每一部分必须以
/为结尾- 注意path的用法,调用函数的时候(如say_hello)不需要加双引号
- 注意include的用法,在调用文件的时候需要用双引号。
Using Templates
Template字面意义是模板,在Django系统中,后端生成的数据会套用在模板中,然后发给前端。比如说:
views.py
1 | def say_hello(request): |
hello.html
1 | <h1>Hello World</h1> |
在这个很简单的例子中,当handler收到request之后,会调用渲染器render()将这个HttpRequest 放到hello.html这个模板中去处理。这里无论收到什么请求都会返回 Hello World
传入dictionary
在使用 render函数时,还可像函数一样传入想要的参数,也可以写一些简单的逻辑,比如:
1 | def say_hello(request): |
这里我传入了一个 name参数,name的值为Jason,那么在 hello.html中我就可以这样修改:
1 | {% if name %} |
这段代码的逻辑是,如果传入的参数中有 name,那么就做一个渲染,否则直接传回Hello World
小细节
- 结尾要写 endif 注意是连起来的
- 引用参数的时候要注意使用两对大括号
其实,现在Template的应用场景已经比较少了,现在流行的模式都是后端返回数据,前端渲染网页,而使用template的话就等于在后端就渲染好网页然后传给前端了。
Debugging Django Applications in VSCode
现在我们来讲讲如何调试Django项目,这里介绍两种方法:在VSCode中调试和使用Debug Toolbar进行调试。首先讲讲VSCode。
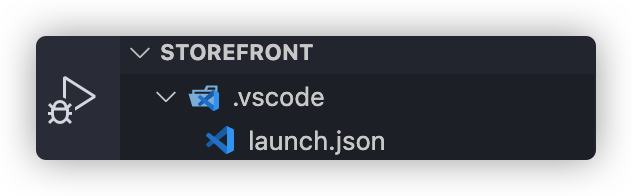
首先点击右边的debug按钮,然后新建一个针对python>Django的 launch.json文件,内容如下:
1 | { |
然后我们就在调试界面点击 Run 即可正常调试, 设间断点然后一步一步运行
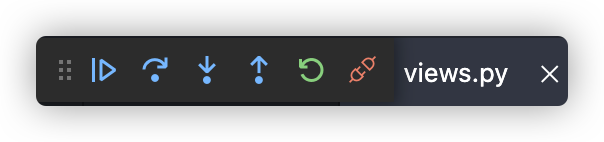
这边有几个符号,从左到右依次是:
- continue 2.Step over 3. Step into 4. Step out 5. Disconnect
注意点
调试端口要和运行着程序的端口错开
每次调试结束后,要删除间断点
Using Django Debug Toolbar
Django Debug Toolbar 是一个package,我们需要下载一下:教程在这里
https://django-debug-toolbar.readthedocs.io/en/latest/installation.html
注意了,因为我们用的是虚拟环境,因此下载的时候需要用
pipenv install django-debug-toolbar其余步骤和教程一致
和VSCode不同,使用 toolbar 作为调试工具,需要传回一个HTML页面,因此我们需要对hello.html进行修改。
1 | <html> |
结果如下,还是比较炫酷的。
Build a Data Model
在Django这种后端框架中,是通过Model类来操作数据库的,程序员不需要关注SQL语句和数据库的类型(无论数据库是MySql、Sqlite,还是其它类型),Django自动生成相应数据库类型的SQL语句,来完成对数据库数据的操作。
Introduction to Data Modeling
进行Django开发的第一步是弄明白,我们要存储那些数据,这些数据之间有什么关系。比如说,商城中最重要的就是产品(Product)的信息:一个产品可以有名称、描述、价格、库存等信息。此外,不同的商品会分为不同的类型,因此我们还需要一个 类别(Collection),这个类别也有自己的名称。
那么产品和类别之间是否有联系呢? 肯定是有的。我们希望点击一个类别可以获取到其下面所有的产品,那么这是一个 1对多 的关系。如下图所示:
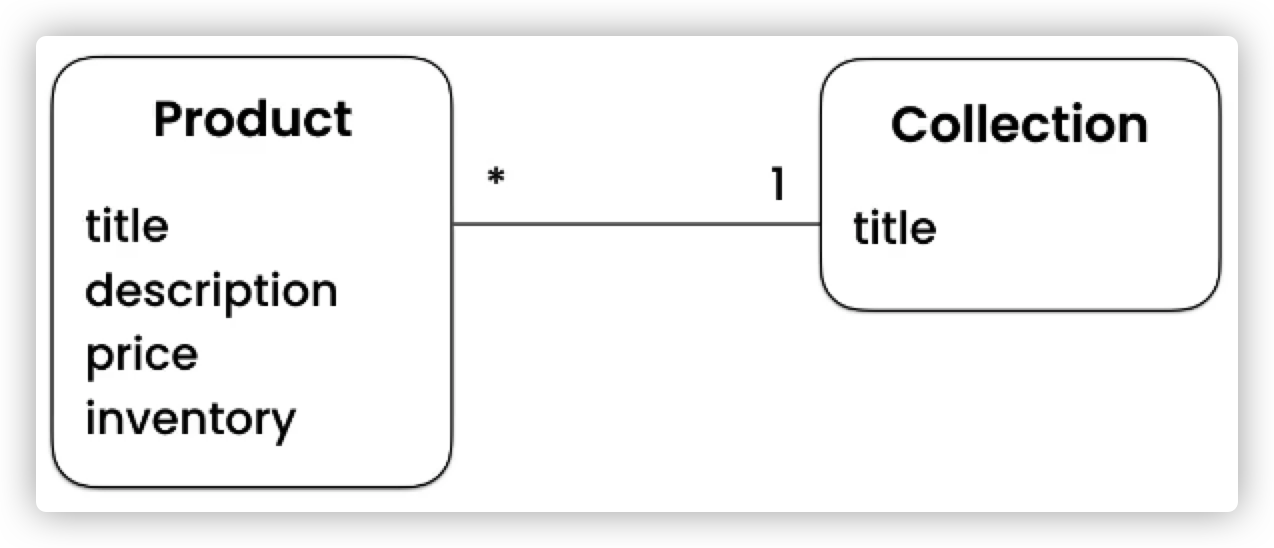
数据与数据的关系还有1对1、多对多
注意点:
我们不需要考虑ID信息,Django会自动为我们生成。
要根据需求出发确定关系,不要天马行空
Building an E-commerce Data Model
现在我们再来说几个数据模型:
比如说商品和购物车之间的关系
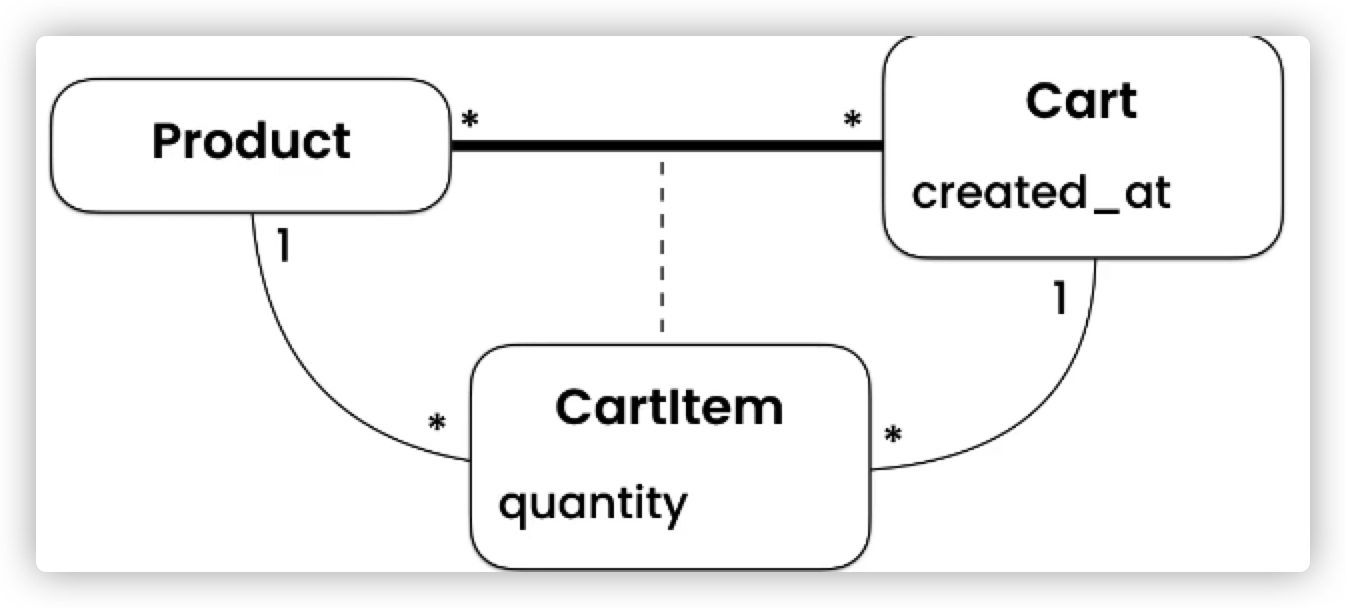
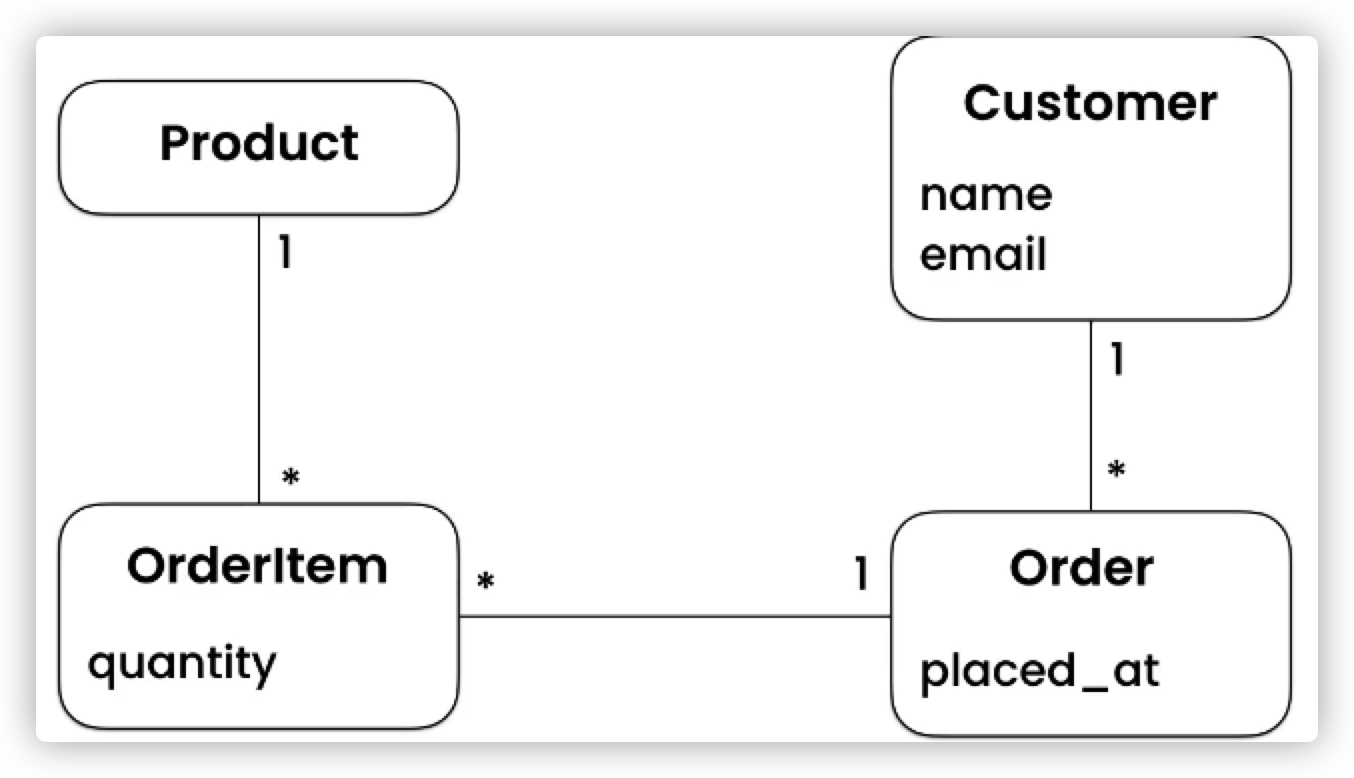
还要客户、订单和商品之间的关系
商品和标签之间的关系

此外还有这样的关系:
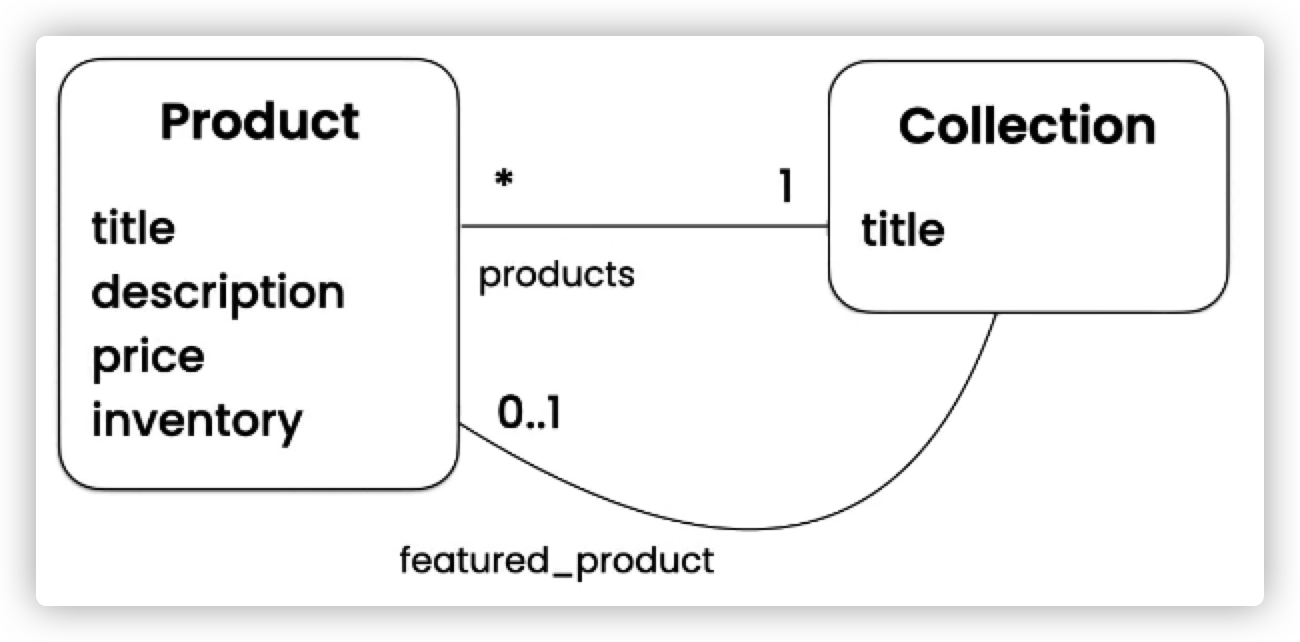
0..1 表示一个集合中一个对象可以对应另一个集合中的0个或者1个对象
此外,还有:
0..*表示一个集合中的一个对象对应另一个集合中的0个或多个对象。( 可以不对应)1..*表示一个集合中的一个对象对应另一个集合中的一个或多个对象。( 至少对应一个)
Organizing Models in Apps
之前我们说了Django是多个APP的合集,每个APP有属于自己的Data Model. 因此我们现在来看看怎么在APP中管理Data Model。
这里提供了三种模式,我们一次分析其利弊:
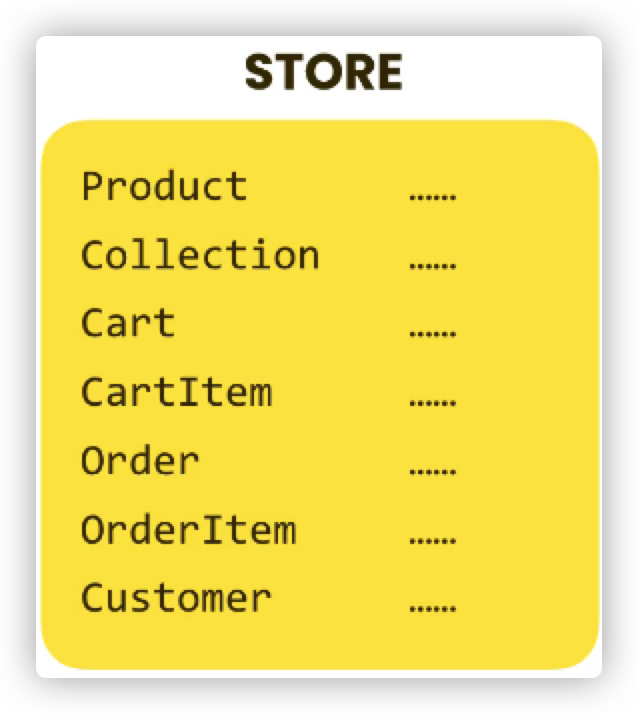
第一种就是把所有的字段都集成在一个 Model中,这样能让model迁移时更加方便,但是随着项目的扩大,会难以管理,如下图所示:
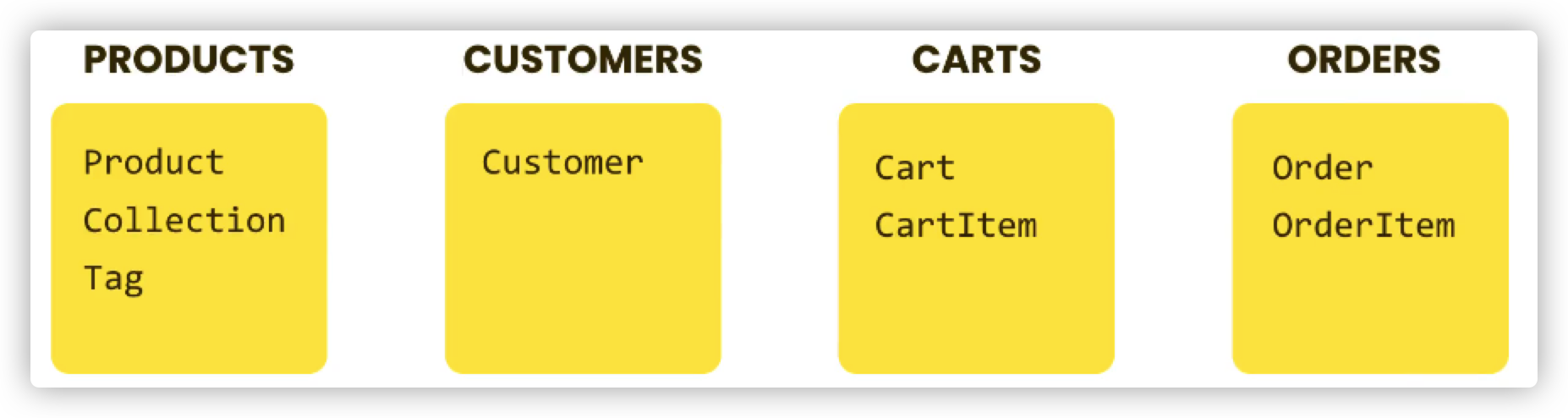
另一种就是交给不同的Model来管理,这种做法更加不可取,你可能认为这样很方便,但事实上这些字段之间是相互联系的,这样分开反而会导致耦合度、代码量大大提升:
最后一种是最优解,也就是让不同的Model “各司其职”,只管好自己的事情。比如说Store中就没必要把Tag,TaggedItem加进来,因为这两个字段在其他场景下也可以使用,比如说社交网站上,朋友圈上都可以用;因此可以将其分开。
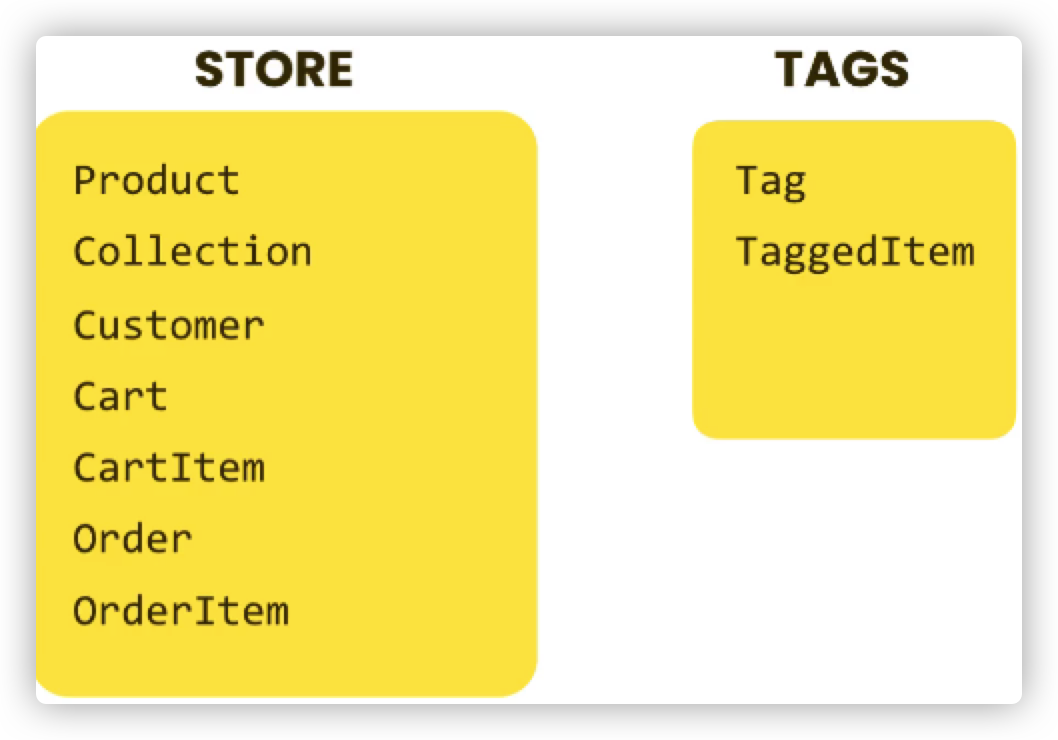
归化数据模型的两个准则
- 使得model之间的耦合度最小
- 使得每个model的内部凝聚性尽可能高
上面规划了两个Data Model,那么我们就创建两个APP来装下它们。
1 | python manage.py startapp store |
创建完之后,别忘了在settings.py中添加这两个app
Creating Models
理清楚各个App之间的关系之后,现在我们开始编写 APP 文件夹中的 models.py
对于 store文件夹下的models.py ,之前我们说一个Store需包含商品、顾客、购物车、订单等元素,现在我们来一一实现。
首先我们创建一个 Product类,用来存放关于产品的相关信息,我们需要Model Field来Cover住这些信息,关于每个field都有这些通用的options参数可以写。
更多的Field我们可以参考Django的文档:
https://docs.djangoproject.com/en/3.2/ref/models/fields/
Class 格式如下:
1 | from django.db import models |
首先最重要的是商品的名称,我们用
CharField来cover它,选择用CharField 的好处是可以限定最长的字符串,这里我设置为255其次是商品的描述,因为可能会很长,因此我们用
TextField()来Cover,这是不限字数的再来是商品的价格,因为价格包含整数和小数,这里使用
DecimalField来Cover,需要设定最大长度和小数点后几位,比如说这个商场里最高价格只能标注为9999.99,那么就要设置max_digits=6,decimal_places=2在后面是商品的库存,因为不可能有半件商品,所以这里用
IntegerField()来Cover就可以了。最后是最后更新时间了,Django中提供了专门适用的时间格式
DateTimeField(auto_now=True)
同样的我们依葫芦画瓢可以写出 Customer Class:
1 | class Customer(models.Model): |
这里要注意的是,每个客户的email都必须是独一无二的,因此在填写EmailField的时候要写
unique=True此外,在一开始创建客户的birth_date 的时候,是空白的(可以理解为客户可以自己完善信息),因此要写
null=True
Choice Fields
设想有一个字段,他代表了你会员的等级,有金银铜三个等级,那么我们该如何创建字段,这时候就可以用 choice Fields来实现:
在Django文档中,给了我们这样一个示例
1 | YEAR_IN_SCHOOL_CHOICES = [ |
这是一个 Choice Field, 表现形式是一个元组列表,每个元组中,前者是存放在数据库当中的信息,后者是易于用户理解的信息。按照这个形式,我们可以写出会员等级,如下:
1 | class Customer(models.Model): |
那么这里我们为什么又要将 存放在数据库当中的字段单独赋值呢?
这是为了降低耦合度,如果未来’B’ 替换成别的字,按照之前的方法,就需要修改两个地方,不方便管理,现在就变得很清楚明了了。
同样的,我们可以对 Order类中的 payment_status字段设置为 Choice Field
1 | class Order(models.Model): |
Defining One-to-one Relationships
现在我们将两个class之间建立一对一的联系。首先要明白哪个是Parent,哪个是Child,比如说我要在Customer和Address 之间建立联系,那么显然Customer是Parent,Address 是Child.
需要在child model 中联系 parent model,如下:
1 | class Address(models.Model): |
OneToOneField 的第一个参数是 parent model 的类型,这里是Customer , 第二个参数比较有意思,是说当 parent model 中的一条信息删除时,对应的child model的操作。
CASCADE 代表这条对应的信息也一并删除
SET_NULL 代表这条对应的信息中的字段(这里是street和city)将被置为 NULL
SET_DEFAULT 顾名思义就是当信息删除时,字段恢复默认值
PROTECT 是一种保护机制,即必须先删除 child 再删除 parent
此外我们还需要设置 primary_key = True,也就是将Address设置为主键,也就是客户必须要设置这个参数,且具有唯一性,我们可以用主键来定位一条信息。
为什么要在这里设其为主键,因为只有这样才能保证 One to One 关系,否则django会默认生成一个ID字段并设其为主键,这样会导致多个Address 对应一个 Customer
Defining a One-to-many Relationship
刚才说的一个用户对应一个地址显然是不符合现实的,因此现在我们在它们之间定义 一对多关系。
语法: bid = models.ForeignKey("要关联的模型类名称") ,子关联父
方法很简单,如下所示:
1 | class Address(models.Model): |
这里我们就要引入主键和外键的关系和区别了。
| 主键 | 外键 | 索引 | |
|---|---|---|---|
| 定义: | 唯一标识一条记录,不能有重复的,不允许为空 | 表的外键是另一表的主键, 外键可以有重复的, 可以是空值 | 该字段没有重复值,但可以有一个空值 |
| 作用: | 用来保证数据完整性 | 用来和其他表建立联系用的 | 是提高查询排序的速度 |
| 个数: | 主键只能有一个 | 一个表可以有多个外键 | 一个表可以有多个唯一索引 |
Address是Customer的外键,说明一个Customer可以有多个Address. 定义了一个外键字段,那么在该字段生成数据表之后会变为这样的形式: 外键字段名_id, 比如这里就会变成 customer_id, 如果多个Address关联到一个Customer,那么它们的customer_id 是一样的。
新加入的如下:
1 | class Collection(models.Model): |
这里要注意,有些
on_delete属性我们选择的是PROTECT,为什么呢?比如说 Order和Customer 之间的关系,我们希望Customer被删除后,还能保留其之前下的订单(完以数据分析有用)
而有些关系比如说 Cart 和CartItem 之间,删除了购物车之后,想必不需要留下购物车中的物品了。
Defining Many-to-many Relationships
现在我们来定义多对多关系, 比如说商场里面商品和促销活动之间的关系。一个商品可以同时参加多个促销活动,同时一个促销活动也可以涵盖多个商品
1 | class Promotion(models.Model): |
这里我们在 Product 类中建立与 promotion 的多对多关系
Resolving Circular Relationships
在 Store 中我们还会碰到这种问题:两个 model 是互相依赖的, 构建出了一个环形的关系(Circular Relationships) 如下所示:
- 一个 Collection 中可以有多个 Product,这代表 Product 依赖于 Collection
- 同时,特定的Product可以作为Collection的封面、代表 之类的,这说明Collection 反过来在依赖Product
在 python 中,我若把 Collection 放在 Product 之前,会识别不出 Product,如下:

为了解决这个问题,需要用引号将 Product 引起来,但这也是不够的,会报这样的错误:
1 | Reverse query name for 'store.Collection.featured_product' clashes with field name 'store.Product.collection'. |
这是因为在 Collection 中有一个字段叫 featured_product ,Django 会自动生成 Reverse Relationship ,也就是反向查找在 models.py 中是否有 Product 的类,如果有就会和其建立反向联系。但是现在的情况是 ,Product 中已经有一个名叫collection 的字段了,因此出现了名字上的冲突。
因此需要用到 ForeignKey.related_name 这个属性。
我不想让Django创建一个反向关联,因此我将其设为+ 即可。这样一来, Collection可以找到Product,但又不会和Product创建反向关联,因此可以实现环形关系。
1 | class Collection(models.Model): |
Generic Relationships
之前我们说了对于 Tag、Likes 这样的 model,我们是希望其能在不同的情况下使用的, 比如说对于Like,允许用户在文章评论视频下方点赞,Tag可以再不同的场所打上标签。
那么对于这么多要点赞的类型,都需要创建1对多的关系,很显然代码量以及管理起来都比较繁琐。虽然Likes这个类是一对多关系里的“多”这一侧,但实际上他的模型字段也是广义上的“一”,因为他的外键字段和所连接的模型都是“一对一”建立连接的。
Django里面的ContentType其实就是起到一个自动一对多的作用,和任何模型都能连接起来,保证了代码的干净。
现在我们再来了解一下 GenericForeignKey, 普通的Foreignkey,只能“指向”单一的模型,而ContentType则可以允许和任意的模型进行连接,非常灵活。设立这种外键,你需要3个字段
1:设定一个普通外键,连接于ContentType,一般名字叫“content_type”。
这个字段实际上是代码你在Likes这个点赞里面,是给哪个对应的模型在点赞,是文章/评论/视频,或是其他。2:设立一个PostiveIntegerField的字段,一般名字叫做“object_id”。
以记录所对应的模型的实例的id号,比如我们给一篇文章点赞,这篇文章是Post类里的id为10的文章,那么这个object_id就是这个10。
其实看到这里,应该清楚了,当你有了模型的名字,也告诉了你这个模型的实例的id号,你就可以找出这个实例了。3:第三个也是最后一个,就是设定这个GenericForeignkey外键了,这个外键需要传入两个参数,就是上面的1和2,如果你为上面2个字段取的名字就是content_type和object_id的话,你可以不需要输入,因为这个字段默认会读取这2个名字。如果你自定义过了,那就需要你手动添加。
实例
回头我们所需要的应用场景上来,我创建了一个 tags 模型,里面设计两个 Class, Tag 和 TaggedItem ,前者可以看做是标签的实例,后者则是一个广泛的标签概念,可以打在不同的物品类型上面
1 | # Create your models here. |
同样的,我们可以创建 LikedItem 类,用来给不同类型的物品点赞:其中,user就是用来定义是谁点的赞。
1 | from django.db import models |
Setting Up the Database
我们首先来了解一下 SQLite,然后会使用Mysql数据库
Creating Migrations
在Django项目中,我们并不会手动来创建数据库,Django会自动帮我们生成。
运行:python manage.py makemigrations 可以生成很多迁移文件:
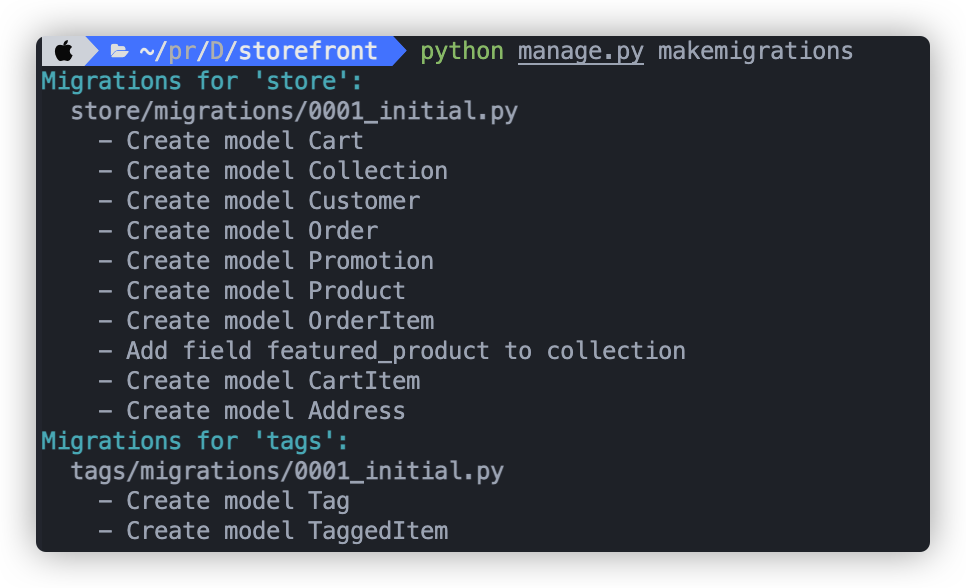
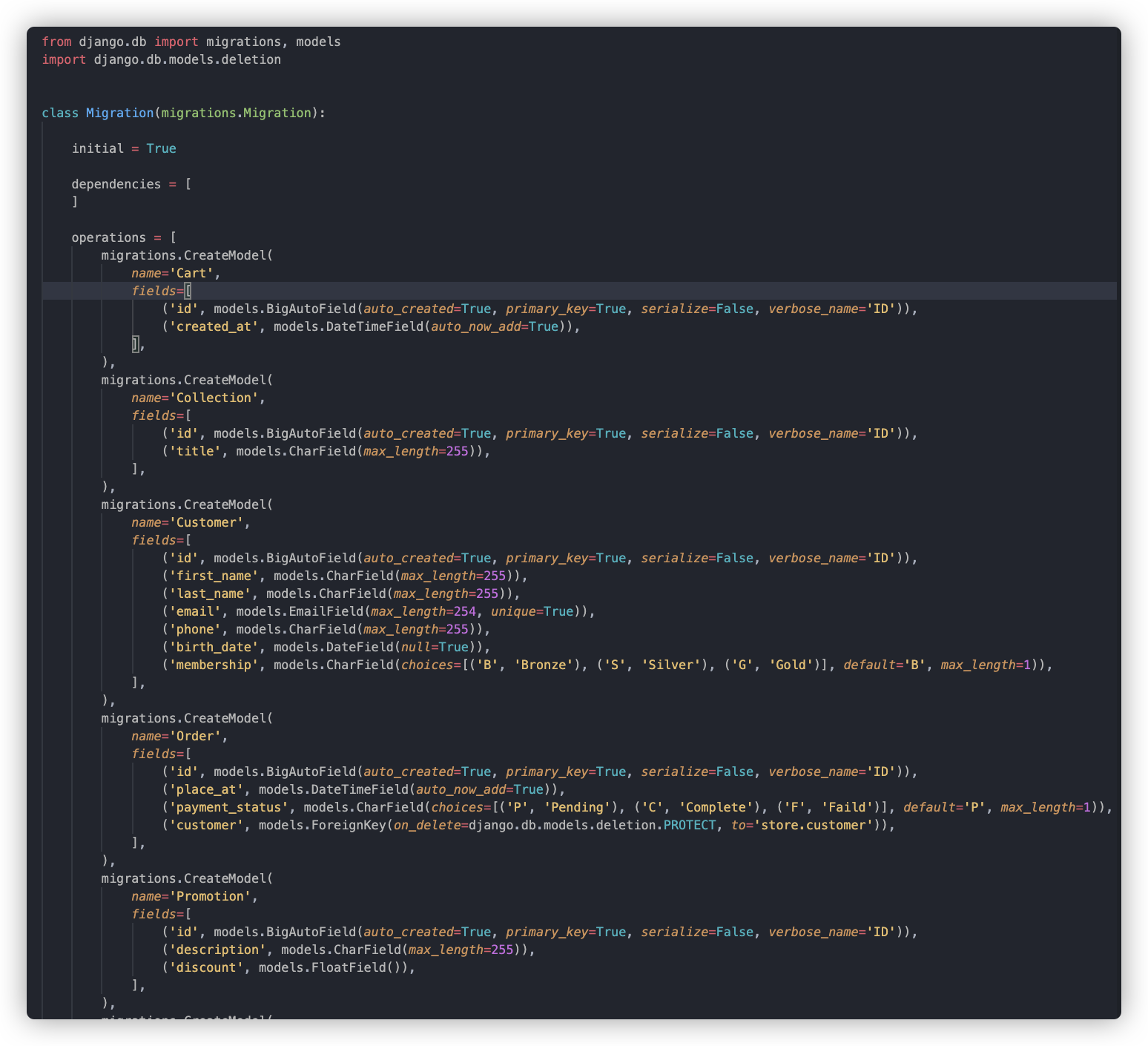
更新与修改
如果我们要更新 migration文件,只需要修改完model 然后重新运行python manage.py makemigrations即可.比如说我要修改 class Product中的price字段,将其改名为unit_price, 然后运行。

1 | # Generated by Django 3.2.5 on 2021-07-25 05:56 |
需要注意的是,我们在修改model的时候,之前一定要先将该app添加到
settings.py当中去,否则Django是检测不出是否修改的。
比如说现在我要给Product再添加一条字段:slug, slug可以帮助数据库更快的找到商品信息,比如说:https://stackoverflow.com/questions/12099315/design-1-or-2-tables-for-a-1-to-0-1-relationship-with-sql-server中的 design-1-or-2-tables-for-a-1-to-0-1-relationship-with-sql-server 就是这个页面的slug
1 | slug = models.SlugField(default='-') |
注意到,在0002号migration文件中,有一个dependencies列表,里面是0001号migration文件,说明后者是在前者的基础上进行修改的。因此,如果我们要重命名前面的 文件,就需要修改对应的dependeny
Running Migrations
现在我们来运行上面创建的migration文件,用他们来生成数据表
运行: python manage.py migrate 即可
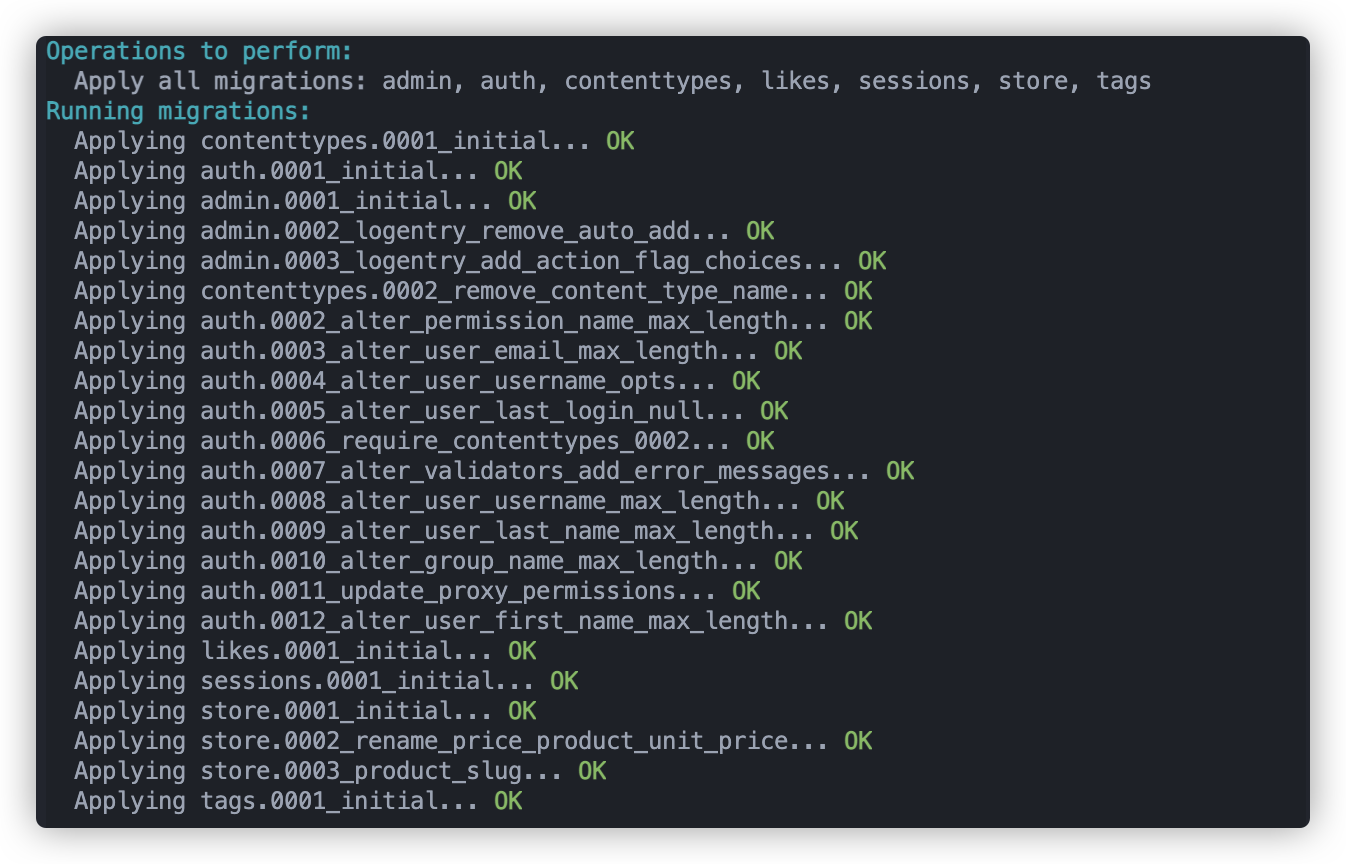
我们发现Django是对所有的app中的migration文件进行迁移。
那么这些生成的数据表存放到哪里了呢?是存放到Django项目自带的sqllite数据库当中了。我们可以下载VSCode中的SQLite插件然后用这个插件打开数据库

可以再导航栏的最下面发现SQLITE EXPLORER,里面就是生成的数据库。其中django_migrations数据表中就存放着每个app于其对应的migration的信息。
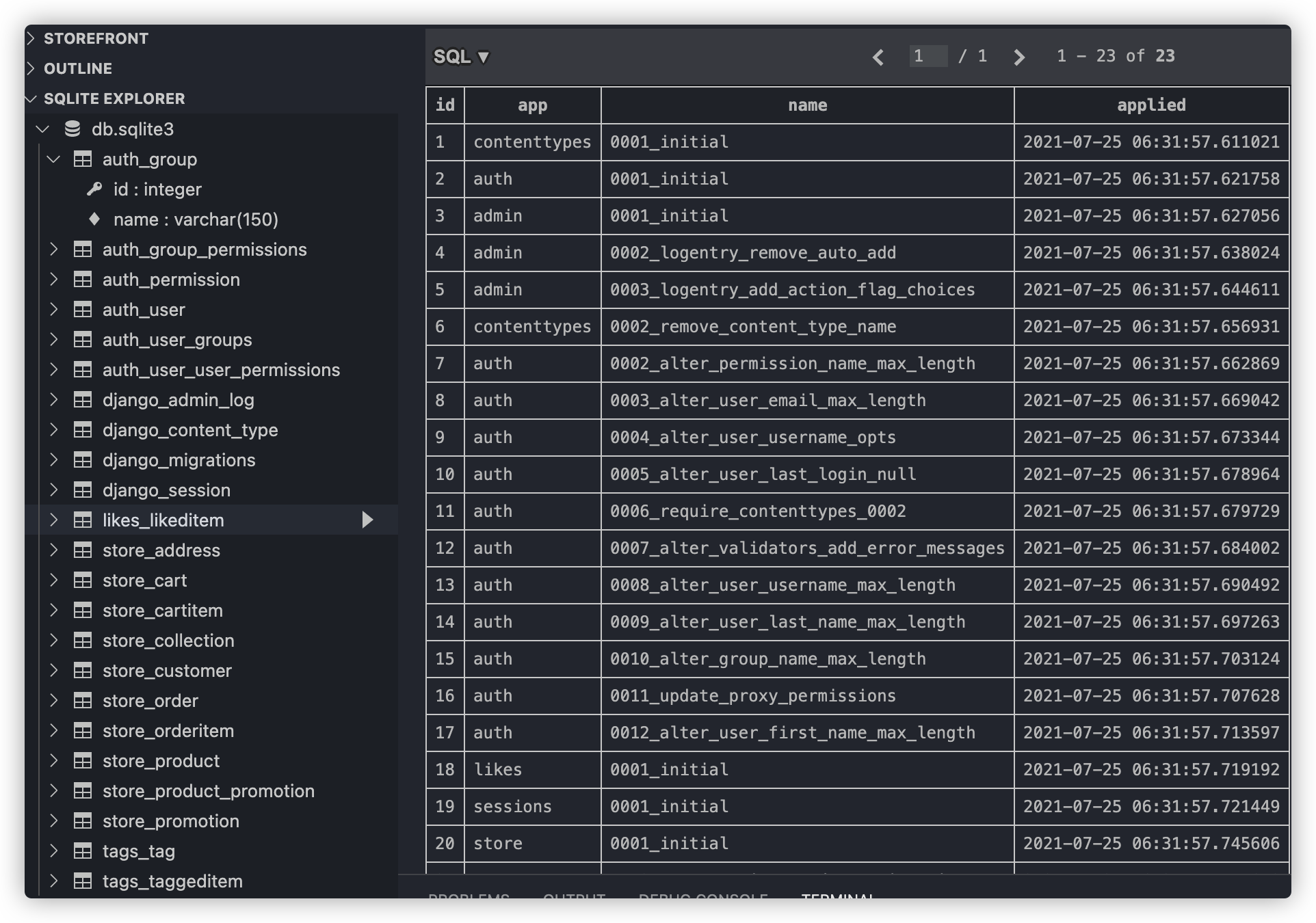
如果我们要运行一个特定的migration文件,可以这样来写:
python manage.py sqlmigrate store 0003 Django就会运行至store app中的0003号文件,后面的文件不运行下去了
小测试
- Add zip to Address
- Create a migration
- Run it
- Inspect the migrations table
Customizing Database Schema
有些时候我们希望对数据标进行定制化,比如说修改索引,或者修改表名等. 为了实现这个效果,我们可以使用 元数据(Metadata)。
元数据可以用来描述一类事务,比如说对于人,我们可以从年龄、身高、相貌、性格来描述;对于数码图片,我们有作者、型号、光圈、曝光时间等。这都是元数据。
Django中我们也可以对Model 设置元数据:
https://docs.djangoproject.com/en/3.2/ref/models/options/
1 | class Customer(models.Model): |
这边我设置了两个元数据,一个是数据表的名字,另一个是数据表的索引,我改成了两个。
运行python manage.py makemigration 之后,因为修改了两个点,新生成的 migration文件命名为 auto

Django能帮助我们快速创建一个APP因此对每个model都设置元数据是没有必要的
生成migration文件的时候,最好一次只修改一个地方,这样自动命名会比较直观
Reverting Migrations
假设我现在发现运行的Migration文件有错误,怎么回滚呢?
如果我们只想回退一步,那么只要在model中修改然后重新生成一个migration文件即可。 但假如一个migration里面有很多步骤,我想将其全部删除,又该怎么做呢?
上面我们讲到,用python manage.py migrate XXXX 可以精确运行到某一migration文件,因此我们如果要抹除0005,可以这么写:python manage.py migrate store 0004, 结果如下:
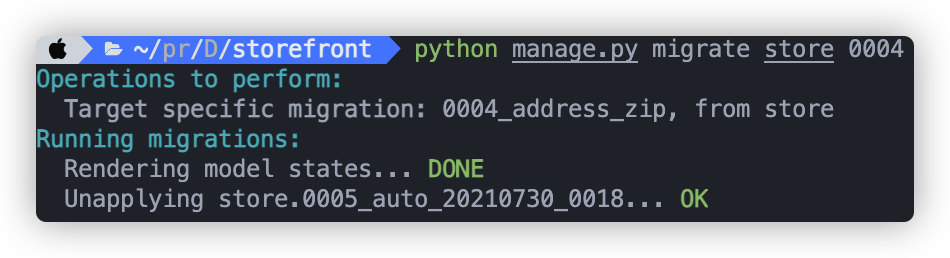
但现在还是不行,因为0005文件仍然存在,若我再次运行python manage.py migrate ,还是会回到之前的版本,因此要删去这个文件以及在model中对应的代码。
虽然说这样也可行,但是最好的办法还是使用版本控制软件如 git,但是每次migrate之后注意commit
Using MySQL in Django
要在Django框架下连接mysql,首先需要安装pymysql 和 mysqlclient
然后在 settings.py 中修改 DATABASES 一项:
1 | DATABASES = { |
一开始我发现仅仅安装mysqlclient 的话,启动程序时会出错:NameError: name ‘_mysql‘ is not defined
这是因为django一开始调用MYSQLdb,与python3.x起了冲突。解决办法是在配置文件目录下的__init__.py文件下加入以下代码来用pymysql替代MySQLdb:
1 | import pymysql |
Django现在已经成功连接Mysql了,现在在Mysql中创建frontstore的DATABASE,然后调用python manage.py migrate ,就可以将数据全部载入mysql了:
Running Custom SQL
有时我们想要自己运行一些SQL语句来修改数据库,怎么实现?
首先,运行 python manage.py makemigrations store --empty 创建一个属于store app的空的migration文件。
我们要写的就是operation里面的SQL 语句,格式是:migration.RunSQL() 我们需要写两段SQL语句,第一段是修改的,第二段则是删除修改的,如下
1 | from django.db import migrations |
如果不写第二段SQL语句的话,当我们想回滚时会发生报错: ... is not reversible ,因此为了便于维护,还是需要写一下的
1 | django.db.migrations.exceptions.IrreversibleError: |
Generating Dummy Data
创建一些无意义的数据,便于我们接下来的程序开发
https://mockaroo.com/ 我们需要用这个网站帮我们生成数据
详见我的一篇博客:
1.0.11. Generate 1000 Rows with Mockaroo
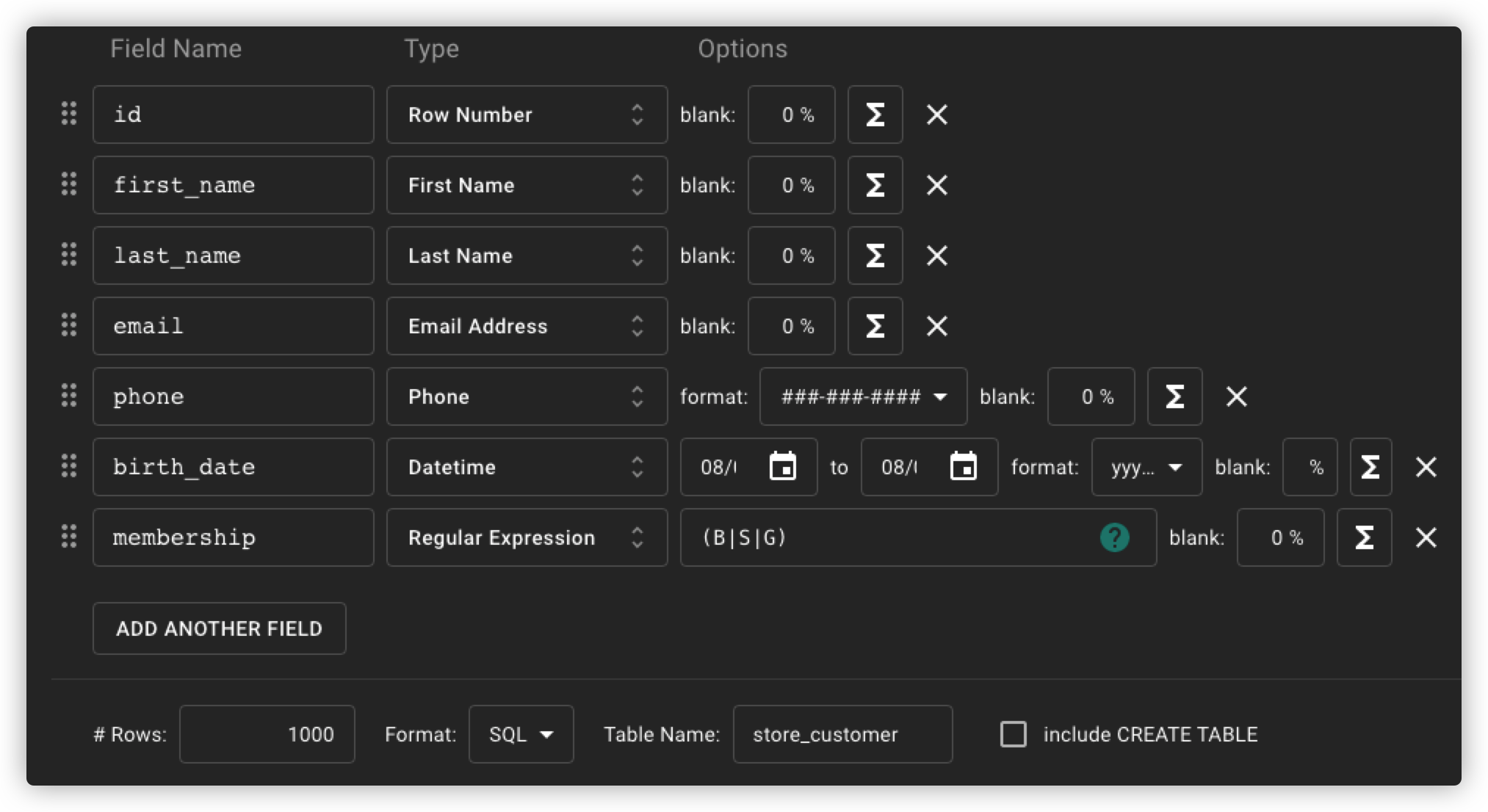
下载好SQL语句文件之后,拖到Datagrip中运行即可。
Django ORM
Django ORM
ORM (Object Relational Mapping) 也就是对相关系映射,用于实现面向对象编程语言里不同类型系统的数据之间的转换。通俗得说,就是当我们要用程序将数据库中的表格拉出进行操作室,需要用一个对象去接收它
使用Python的Django模型的话,一般都会用它自带的ORM(Object-relational mapping)模型。这个ORM模型的设计比较简单,学起来不会特别花时间。不过,Django的ORM模型有自己的一套语法,有时候会觉得别扭。
其实,之前我们写的migration以及model文件,也是通过ORM来转换成sql语句的。但这也并不意味着我们不再需要了解SQL语句,当处理一些复杂问题时,还是需要我们自己写sql的.
Managers and QuerySets
关于Django ORM首先我们要明白 manager和queryset的概念。
manager 可以理解为一个数据库的接口,它可以管理、调用数据库中的信息。比如说下面这段代码,首先从models 中引入Product类, Product.objects 就是一个manager,它可以实现很多功能。比如说all() 可以获取数据表中的所有行,get()可以获得一个单一的对象
1 | from django.shortcuts import render |
manager 返回的数据叫做 quertset,类似于 list,里面放的是一个个模型类的对象,可用索引下标取出模型类的对象。比如下面,可以通过切片来打印对象。
1 | def say_hello(request): |

在 Django Toolbar中,我们也可以看到Django向数据库发送的SQL语句:
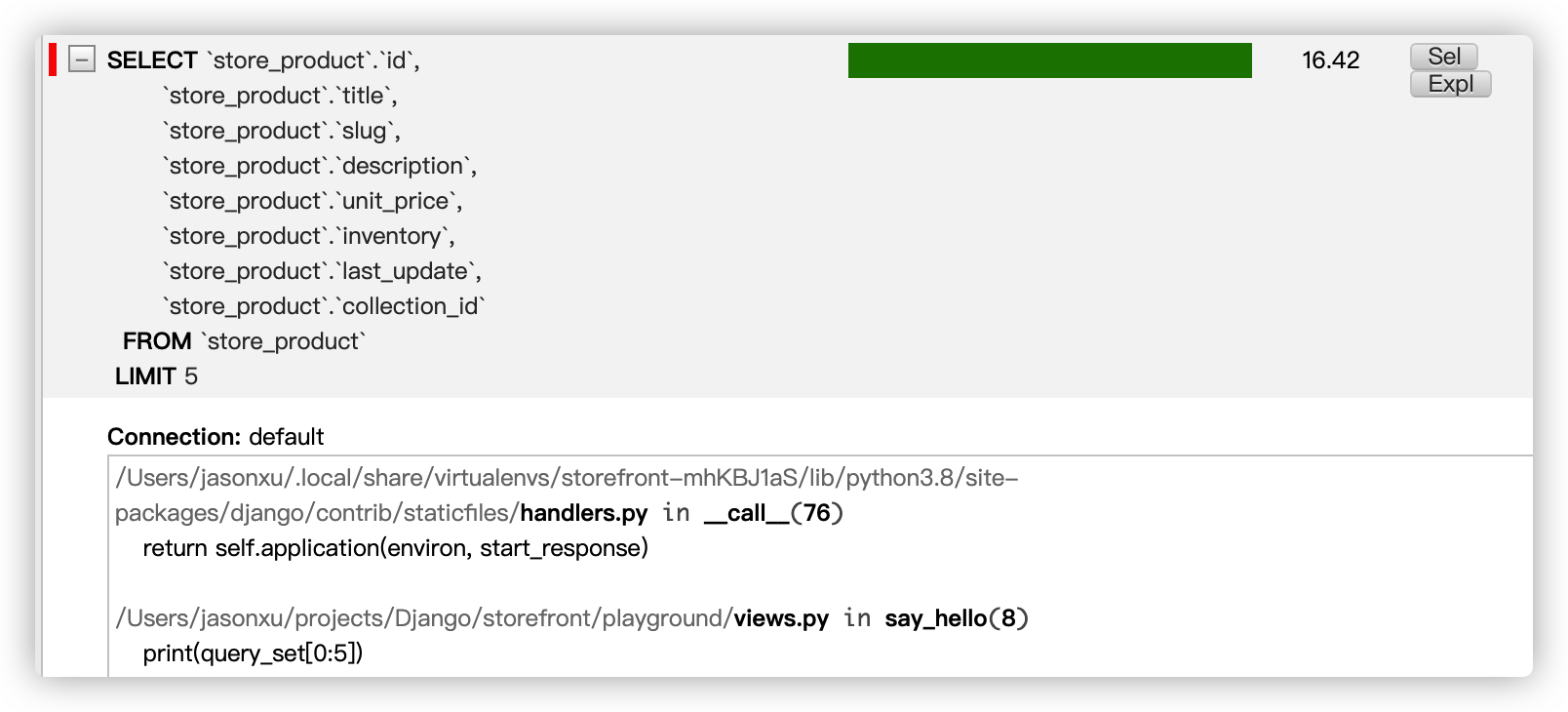
此外还有filter() 用于查询符合条件的数据,order_by()用于对查询结果进行排序,reverse()用于对查询结果进行反转,count()用于对查询结果计数等操作,
详见:https://www.runoob.com/django/django-orm-1.html
Retrieving Objects
现在要说怎么检索对象。
- all
all方法是获得所有对象的方法,queryset = Product.objects.all()
- get
get 方法则是获得特定的一个对象的方法,里面的参数 pk=?便是对象的位置。比如:product = Product.objects.get(pk=1)
注意,序号时从1开始算起的,所以如果写了 pk=0,Django会报错。为了解决这个问题,我们可以使用 try-catch
1 | try: |
但是在这么简单的语句中使用try-catch 有点不太美观,因此我们还可以这样写:
Product.objects.filter(pk=0).first()
首先filter 会进行筛选,如果条件是 pk = 0,那么筛选结果就是空,然后再返回first(), 结果就是 null,用这种方法也不会报错
- exists()
如果想单纯判断某一个对象是否存在,可以使用exists()
比如:Product.objects.filter(pk=0).exists()
Filtering Objects
在使用 filter() 时,需要传入一个 key-value值,因此如果我们想筛选单价大于20元的商品时,是不能输入 filter(unit_price>20) 的
为了解决这个问题,Django有自己的一套语言:https://docs.djangoproject.com/en/3.2/ref/models/querysets/
要表达 unit_price>20 ,可以用unit_price__gt=20 ,同样的,大于等于可以用__gte, 此外还有lt,lte等
要表达一个范围,可以用__range() 比如:
1 | def say_hello(request): |
再通过html的修改,我们可以将筛选出的结果显示在网页上
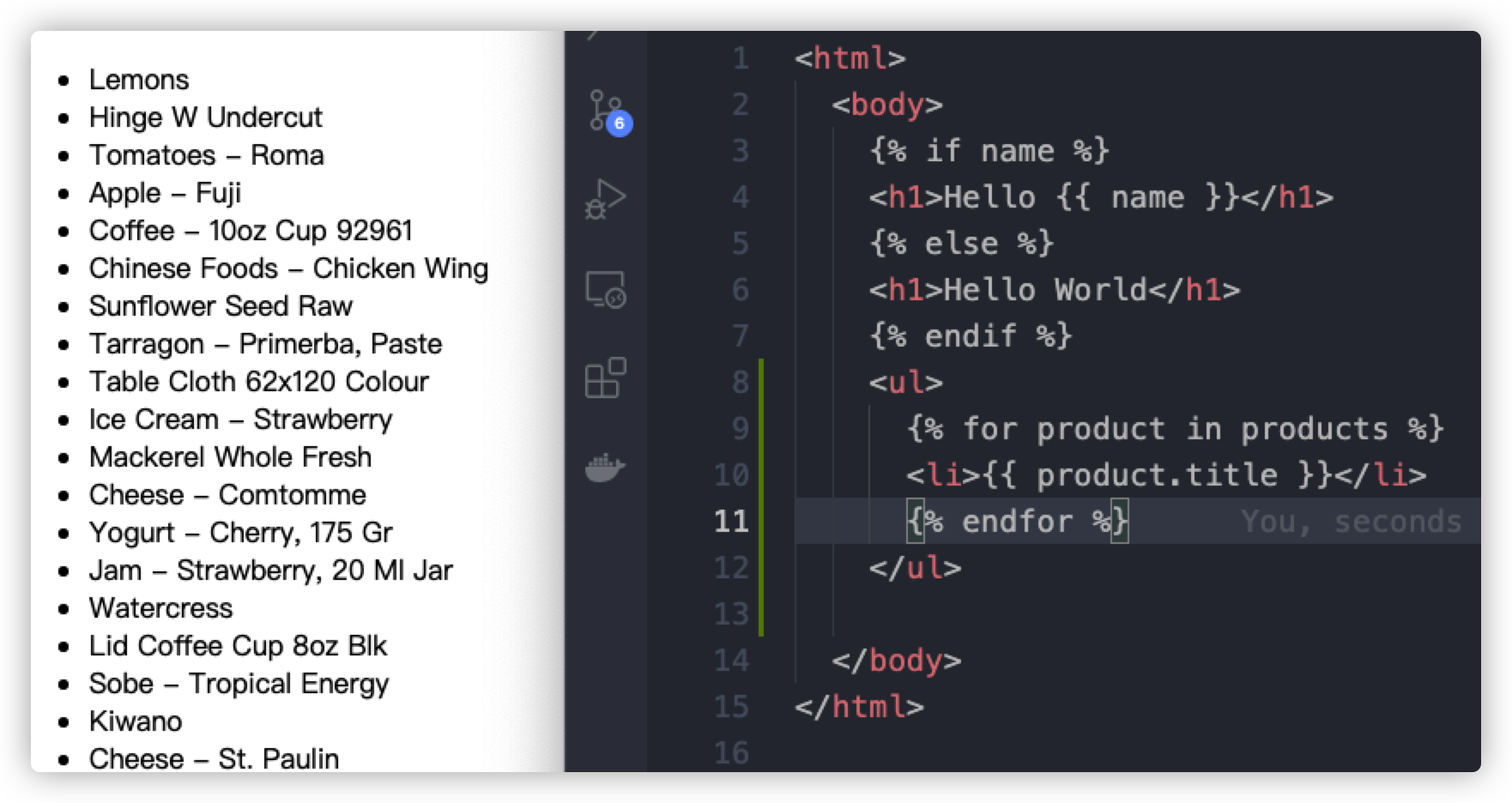
- 找出包含某些特定字符的信息
可以使用 contains, 比如:title__icontains = 'coffee' 注意,默认是区分大小写的,如果要求不区分大小写,可以在contains前面加 i.
类似的还有 __startswith,__endswith
- 筛选日期
有一个字段是 last_update,类型是日期,可以用__year来筛选特定的年份,同样还有__month,__day
比如说`Product.objects.filter(last_update__year = 2021)
- 判断是否为空
__isnull 是用来判断是否为空的,比如Products.objects.filter(description__isnull = True) 就会筛选处description字段为空的信息
query_set = Customer.objects.filter(email__icontains = '.com')
- Collections that don’t have a featured product
query_set = Collection.objects.filter(featured_product__isnull = True)
- Products with low inventory (less than 10)
query_set = Product.objects.filter(inventory__lt= 10)
- Orders placed by customer with id = 1
这道题要我们选择id=1的顾客下的订单,首先要明白customer和order是由一对多关系的. 注意,这里需要使用两个下划线:__
query_set = Order.objects.filter(customer__id= 1)
- Order items for products in collection 3
这道题还是比较难的,转了两个弯,要门选择出orderitem这张表中,属于 collection 3的商品。首先,product是orderitem的外键,而collection又是product的外键所以要product__collection__3
query_set = OrderItem.objects.filter(product__collection__id =3)
Complex Lookups Using Q Objects
如果我想多条件查询,又该怎么办?
- 实现 AND
其中一种是用逗号分割查询条件:
queryset = Product.objects.filter(inventory__lt = 10,unit_price__lt = 20)
此外还有一种链式的filter写法,比如说:
queryset = Product.objects.filter(inventory__lt = 10).filter(unit_price__lt = 20)
- 实现 OR
要实现或查询(Q也可以用于与查询),那么需要使用Q object,首先要引入 from django.db.models import Q
Q()对象就是为了将这些条件组合起来。当我们在查询的条件中需要组合条件时(例如两个条件“且”或者“或”)时。我们可以使用Q()查询对象。 比如说:
query_set = Product.objects.filter(Q(inventory__lt=10)| Q(unit_price__lt=20))
这时候,我们可以用&、|、~ 这些符号来筛选符合条件的数据了。

Referencing Fields using F Objects
F对象主要用于模型类的 A 字段属性与 B 字段属性两者的比较,即操作数据库中某一列的值。通常是对数据库中的字段值在不获取的情况下进行操作。F 对象内置在数据包django.db.models中,所以使用时需要提前导入。如下所示:from django.db.models import F
在使用F对象进行查询的时候需要注意:一个 F() 对象代表了一个 Model 的字段的值;F 对象可以在没有实际访问数据库获取数据值的情况下对字段的值进行引用。
比如说我要对单列的所有制进行操作,统统加上20,可以这么写:
1 | from django.db.models import F |
此外F对象还可以实现两个字段值(两列)之间的比较,比如:
1 | #对数据库中两个字段的值进行比较,列出哪儿些书的零售价高于定价 |
Sorting
- 要对筛选出的结果进行排序,需要用到
order_by,比如说:
queryset = Product.objects.order_by('title') 就会按照字母表顺序进行排列。来看看Django自动生成的SQL语句:

如果要倒排的话,只要在参数前面加一个 负号即可
-,如:queryset = Product.objects.order_by('-title')- 还有一种倒排的方法,就是在正常排序后加上
.reverse()即可
- 还有一种倒排的方法,就是在正常排序后加上
也可以设置多个排列参数,按照优先级在括号内依次传入多个参数即可。如:
queryset = Product.objects.order_by('unit_price','-title')
需要注意,
order_by()和filter()一样,返回的是一个 queryset,是可以被索引被迭代的因此,我们可以用
Product.objects.order_by('unit_price')[0]来获得第一个对象。其实,有一种更简单的方法,即Product.objects.earliest('unit_price')也会返回单价最低的一个对象;当然,也有latest()来获取单价最高的对象。
Limiting Results
比如一个页面中最多显示5条信息,那么我们怎么对其进行限制呢?其实在python语法中这很简单:
queryset = Products.objects.all()[:5] 是返回表中前五条信息
queryset = Products.objects.all()[5:10] 是返回表中第6-10条信息

Selecting Fields to Query
对于Product表格,我们想返回其title和description,那么用什么来选中特定的字段呢?value() ,这个方法会以字典的形式返回字段名和值。如下所示:
query_set = Product.objects.values('title','description')

此外,还可以显示关联表的字段,比如 collection是product 的外键,要筛选collection中的title字段可以这样写
query_set = Product.objects.values('title','collection__title')
sql语句如下:

将html修改成打印整个product对象后,如下图所示

如果我将value()换成value_list(),则会返回元组形式的对象,如下:

注意,value或者value list,会返回字段的值,只是表现的形式不同;
filter,order_by 则是对所有字段进行筛选并返回对象实例
小测验:
- Select products that have been ordered and sort them by title
首先,订单中订购的产品都在 OrderItem表格中,里面的product_id就是订购的商品的编号。我们要将其筛选出来。订单可能有重复的商品,因此要用 .distinct
OrderItem.objects.values('product__id').distinct()
然后,我们要用这些id找到product的名字:
1 | Product.objects.filter( |
Only() And Defer()
那么有没有办法即返回对象,有能够对特定的列进行筛选呢? 这种方法就是only()
比如: query_set = Product.objects.only('id','title')
特别要注意的是, 如果用到only在循环取值是最好是选择only中的列,否则将会再执行一次查询,效率很差
比如我在 html中这么渲染:
1 | <ul> |
unit_price 并没有在only中出现过,因此当要渲染时,django会再次去mysql中查询,导致渲染一条信息就要多查一次,非常非常慢。

所以在渲染时一定要选中only中出现的列!
和only()恰恰相反的是defer(), defer()中的字段名在sql查询时会被排除,只选择剩下的列。所以当我们在渲染时出现defer中的字段时,效率也会非常的差。
Selecting Related Objects
有些时候我们不仅仅只引入一张表的内容,我们想要搜寻出与其相关的表的内容。
比如说:
1 | # view.py |
但如果这么写,会导致对于每一条数据,django都会去数据库中搜寻信息,效率会非常慢。怎么解决呢?
对于1对多的关系,比如说product只能属于一个collection,我们可以用select_related,它帮你直接连表操作、查询数据,括号内只能放外键字段。比如上面这个例子中要引用相关的collection数据表,则可以写如下代码:
1 | queryset = Product.objects.selected_related('collection').all() |
等于说现在这行代码就把两张表都预载了。
那么对于多对多字段,你不能使用select_related方法,这样做是为了避免对多对多字段执行JOIN操作从而造成最后的表非常大。Django提供了prefect_related方法来解决这个问题。prefect_related可用于多对多关系字段,也可用于反向外键关系(related_name)。
比如说 product 和 promotion之间的关系是多对多的,在定义model时,对promotions使用的是ManyToManyField()
prefetch_related使用方法如下:
1 | query_set = Product.objects.prefetch_related('promotions').all() |
sql执行结果如下:
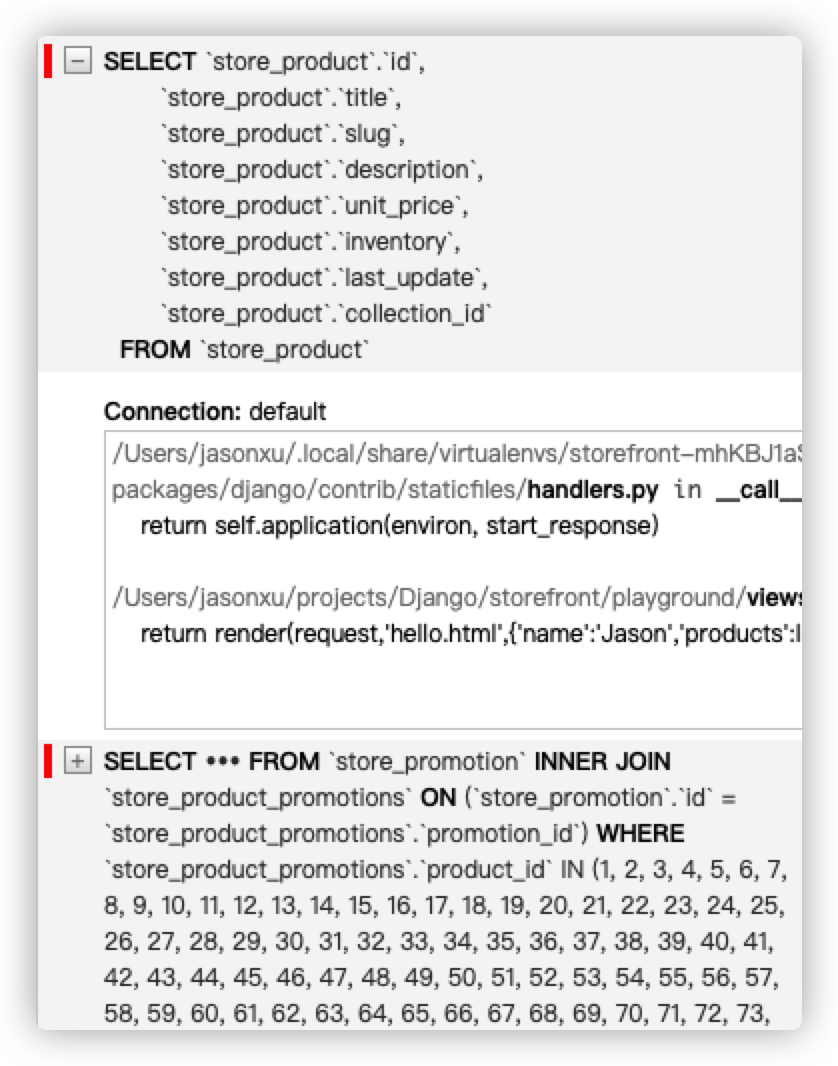
此外,select_related 和 prefetch_related 可以连用,用来连接多张表格。比如:
1 | query_set = Product.objects |
小练习
Get the last 5 orders with their customer and items(including product)
列出最后下单的5个订单以及对应的客户和商品
首先,我们要了解model,customer是Order中的外键,而order又是OrderItem的外键,要筛选出订单对应的顾客很简单,如下:
1 | query_set = Order.objects.select_related('customer').order_by('-placed_at')[:5] |
但是要“反向使用外键”就比较困难,我们要知道,当我们设order为OrderItem的外键时,同时也设置了一个反向外键名为orderitem_set ,如果我们觉得这个名字不好,可以再定外键的时候额外使用related_name属性修改。然后使用prefetch_related()如下:
1 | query_set = Order.objects |
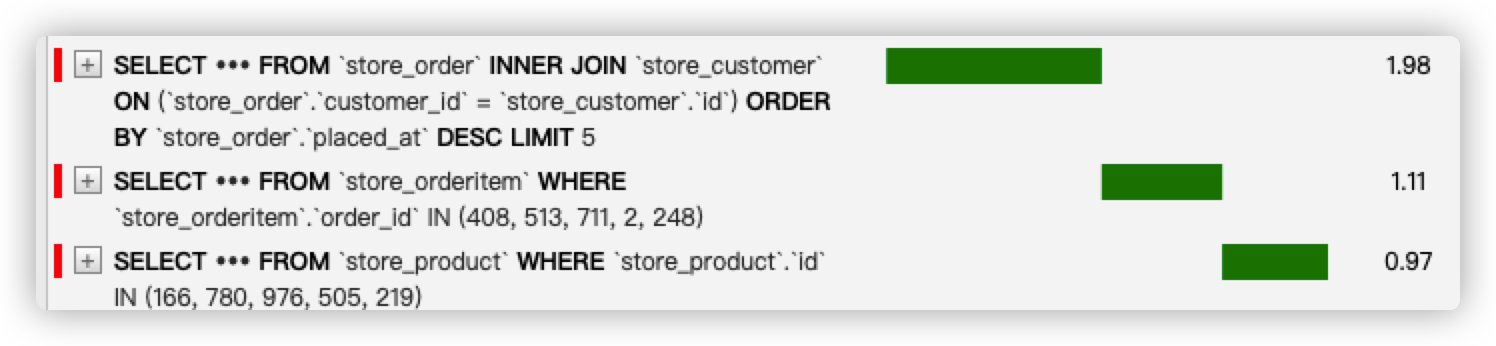
小结
当你查询单个主对象或主对象列表并需要在模板或其它地方中使用到每个对象的关联对象信息时,请一定记住使用select_related和prefetch_related一次性获取所有对象信息,从而提升数据库查询效率,避免重复查询。如果不确定是否有重复查询,可使用django-debug-toolbar查看。
对与单对单或单对多外键ForeignKey字段,使用select_related方法
对于多对多字段和反向外键关系,使用prefetch_related方法
两种方法均支持双下划线指定需要查询的关联对象的字段名
使用Prefetch方法可以给prefetch_related方法额外添加额外条件和属性。
Aggregating Objects
现在我们想要计算一列值中的最大值或者平均值,就需要用到聚合函数了
aggregate()中有很多“子函数”
首先可以导入:
from django.db.models.aggregates import *
- Count()
1 | result = Product.objects.aggregate(Count('id')) |
如果要命名计算得到的列,可以这么写:
1 | result = Product.objects.aggregate(count = Count('id')) |
- Min()
1 | result = Product.objects.aggregate(min_price = Min('unit_price')) |
此外还可以与filter()联合使用,能聚合某一范围的信息。
练习
Write code to answer the following questions:
- How many orders do we have?
1 | result = Order.objects.aggregate(Count('id')) |
- How many units of product 1 have we sold?
1 | result = OrderItem.objects.filter(product__id=1).aggregate(units_sold = Sum('quantity')) |
How many orders has customer 1 placed?
1
result = Order.objects.filter(customer__id=1).aggregate(total_order = Count('id'))
What is the min, max and average price of the products in collection 3?
1 | result = Product.objects |
Annotating Objects
我们之前学了Java中的 annotation,其实在Django中我们也可以用某种方法给对象打标签,如:
- ```python
from django.db.models import Value
queryset = Customer.objects.annotate(is_new = Value(True))from django.db.models import F1
2
3
4
5
6
7
8
9
10
> 我们不能直接传入布尔值,而要传入一个表达式, 因此要用`Value(True)`
我们看到数据库中已经有新的列(is_new)了
<img src="./Django学习1/43.png" style="zoom:67%;" />
需要注意的是,这只是”暂时”的修改,数据库中并没有改动。
+
queryset = Customer.objects.annotate(is_new = F(‘id’))1
2
3
4
5
同样的,可以用 F object 来创造一个与现有列一模一样的新列
+ ```python
queryset = Customer.objects.annotate(is_new = F('id')+1)
还可以对新列进行数值上的运算之类的操作。
Calling Database Functions
现在我们来介绍一下怎么在Django里面调用 mysql 提供的一些数据库函数,比如 Concat(字段连接),Trunc(字段截取)等
我们在view中可以这样写,一共两种方法:
- 第一种方法是导入Func类,然后在函数内部定义要调用的数据库函数类型,这里使用的是Concat(拼接函数)。要注意,两类拼接如果中间需要用空格隔开的话,需要使用
Value(' '),不能直接用(' ')
1 | from django.db.models import Value, F, Func |

- 第二种方法更加简单,在导入时就导入Concat函数,不需要在函数使用时确定函数类型
1 | from django.db.models.functions import Concat |
更多Database Funtion可以参考Django官方文档:
https://docs.djangoproject.com/en/3.2/ref/models/database-functions/
Grouping Data
现在我们要计算一下每个人下的订单数量,该怎么办?
我们知道 Customer和Order是一对多的关系,customer是order的外键。这时候虽然数据库里Customer表格没有Order这个字段,但是Django models已经为我们创建了一个反向关系,我们使用Count函数就可以直接计算Order的数量:
1 | def say_hello(request): |
通过Django生成的SQL语句,发现可以自动将customer和order两张表做连接

Working with Expression Wrappers
现在我们已经学习了Django中的 Value(表达布尔值、字符串等)、F(多列操作)、Func(数据库函数),Aggregate(聚合函数),它们都属于Expression类
现在我们来介绍另一种函数:ExpressionWrappers
当我们使用到一些复杂的表达式的时候,可能会涉及到数据格式的问题.比如说,我要新建一列:
queryset = Customer.objects.annotate(discount_price= F('unit_price')*0.8)
这在Django系统中是会报错的,因为这个表达式中包含了多种类型的数据:unit_price是DecimalField而0.8是FloatField,这时候就需要用ExpressionWrappers来规定一下output_field来让输出结果统一了,一般我们要表示小数的时候都会选择DecimalField(),因其更准确
1 | def say_hello(request): |
生成的URL如下:

Annotating Exercises
Write code to get:
- Customers with their last order ID
1 | result = Customer.objects.annotate(last_order_ID = Max('order__id')) |
- Collections and count of their products
1 | result = Collection.objects.annotate( |
- Customers with more than 5 orders
1 | result = Customer.objects\ |
- Customers and the total amount they’ve spent
1 | result = Customer.objects.annotate( |
- Top 5 best-selling products and their total sales Solutions are on the next page.
1 | result = Customer.objects\ |
Querying Generic Relationships
Custom Managers
Understanding QuerySet Cache
我们要善用 QuertSet Cache,这可以大大节省去数据库访问的时间。比如说:
1 | def say_hello(request): |
就相当于我们把数据库的数据都放在queryset这个缓存中了,之后用就不需要再去数据库查询了。
但是我们也要注意在某些情况下并不会访问缓存:
- 重复获取queryset中一个特定的索引,将每次都查询数据库
1 | queryset = Entry.objects.all() |
- 简单地打印查询集不会填充缓存
1 | queryResult=models.Article.objects.all() |
Creating Objects
上面所说的都是对数据库的查询操作,现在我们来学习如何向数据库插入(增)数据
首先我们新创建一个 Collection对象,然后依次设定其字段
1 | def say_hello(request): |
还有另外一种方法:
1 | collection = Collection.objects.create(title = 'a',featured_product_id=1) |
但是这样的方法虽然简单但并不推荐,因为可以用.来轻易获得一个model对象中的属性,而用create是无法实现的,不太方便
执行效果如下:

Updating Objects
对数数据库中一行的更新,我们一个很朴素的想法就是先筛选出来,再修改想要的字段值
但是我们不能这么写:
1 | def say_hello(request): |
因为这样Django会误认为你是对所有的字段都要进行修改。我们这里不想修改title,但是Django会认为我们是想将其置为空字符串。
因此,我们要用get函数先获取到目标对象:
1 | def say_hello(request): |
还可以使用这种方法:
1 | collection.objects |

Deleting Objects
删除数据是比较简单的,也有两种方法:
第一种:
1 | def say_hello(request): |
第二种:
1 | Collection.objects.filter(id__gt=5).delete() |
Transactions
现在我们来用Django来创建事务。也就是如果不能执行成功,就需要回滚到未执行的状态。
要让一段代码称为一个事务,我们可以用with transaction.atomic()来包裹:
1 |
|
当然如果我们要对整个view function进行事务级别的包裹,我们可以使用:
1 |
|
Executing Raw SQL Queries
最后,我们来学习如何在Django中执行原生SQL查询
一种是使用raw函数
1 | def say_hello(request): |
还有一种是使用cursor对象来执行任意sql语句
因为在使用cursor之后,需要手动用close()函数关闭连接,因此我们可以用with connection.cursor()来包裹住要执行的代码
1 | from django.db import connection |
此外,还可以用cursor.callproc()来执行mysql中已经存在的procedure
但是我们没有必要使用原生SQL进行查询,只有当原生查询比ORM中的函数更加简单的时候,才建议使用。
The Admin Site
Setting Up the Admin Site
首先我们要在 settings中的 INSTALLED_APPS中添加sessions 应用:
1 | INSTALLED_APPS = [ |
添加以后,需要进行migrate
然后我们要在终端设置管理员信息,用python manage.py createsuperuser来创建:
保存后,我们可以通过http://localhost:9000/admin/ 进入管理后台
如果要修改密码,可以使用python manage.py changepassword admin修改
此外,我们还可以修改Django administration和Site administration这两个字段值
1 | admin.site.site_header = 'Storefront Admin' |
Registering Models
我们可以在admin后台直接查看 model 的相关信息。
在每一个 app 中有一个admin.py
1 | from django.contrib import admin |
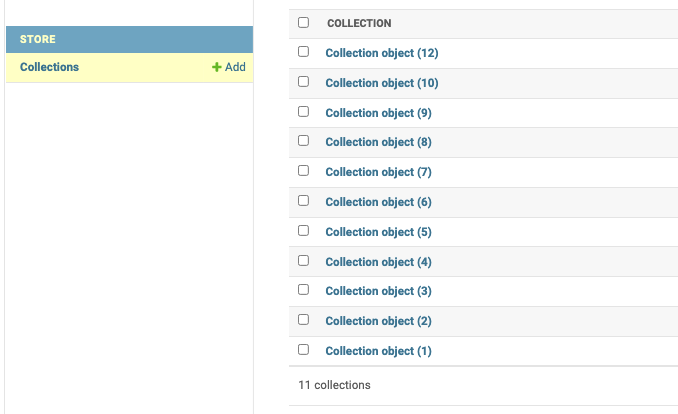
但是,我们只能看到每个collection的编号,一个理想的状态是我们可以直接看到每个collection的title是什么,否则不太直观,我们需要做如下改动
我们要对__str__这个函数进行一个重写,起作用就是一个对象到字符串的映射,默认的是 return super().__str__() 也就是上面看到的Collection object(i),现在我让其返回self.title
1 | class Collection(models.Model): |
结果如下:
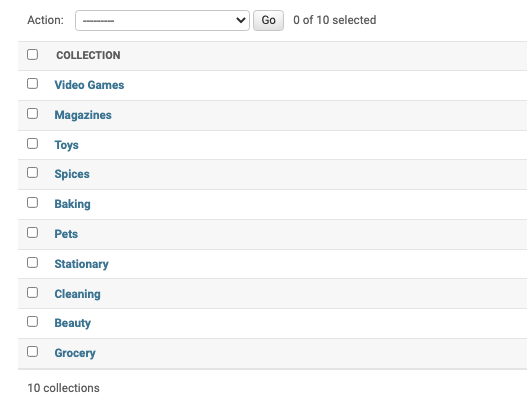
还有,我们发现这10个Collection是杂乱无章的排序的,我们可以用Meta类来排序
1 | class Collection(models.Model): |
Customizing the List Page
现在我们想给上面显示出来的表格多添加几列。
一种简单的方法就是创建一个ProductAdmin类,并在里面确定list_display属性
1 | class ProductAdmin(admin.ModelAdmin): |
当然,我们也可以使用 @ 来修饰:
1 |
|
这种方式更简单,还不需要我们再注册,因为已经在@中注册了
此外,我们还可以对列开启修改功能, 也就是定义list_editable属性
1 |
|
规定每页的行数:
1 |
|
也可以在这里定义排序字段:
1 |
|
Adding Computed Columns
现在我们要在products中添加一列Inventory,即库存。但是我们又不想直接显示库存的多少,而希望用low,ok来表示。怎么办?
我们可以自己创建一列,然后用一个mapper渲染上去,如下:
1 |
|
在这里,我新建了一个inventory_status 的列,然后在下面我们创建一个函数来对该列进行一个映射:
因为这不是数据库内原生的列,因此如果我们设定排序字段的话Django是不会提供排序接口的。因此我们要在这个函数前面加上修饰@admin.display(ordering='inventory'),也就是说这列是根据inventory的大小排序的
Selecting Related Objects
如果我要把该表的外键字段加进来,又该怎么解决呢?
比如说我想在Product表格中把它属于的Collection加进来,我们可以新建一列collection_title然后为其创建mapper,如下:
1 | class ProductAdmin(admin.ModelAdmin): |
但是这样会导致查询性能低的情况:
因为Django会为表中每行数据创建一条SQL查询语句
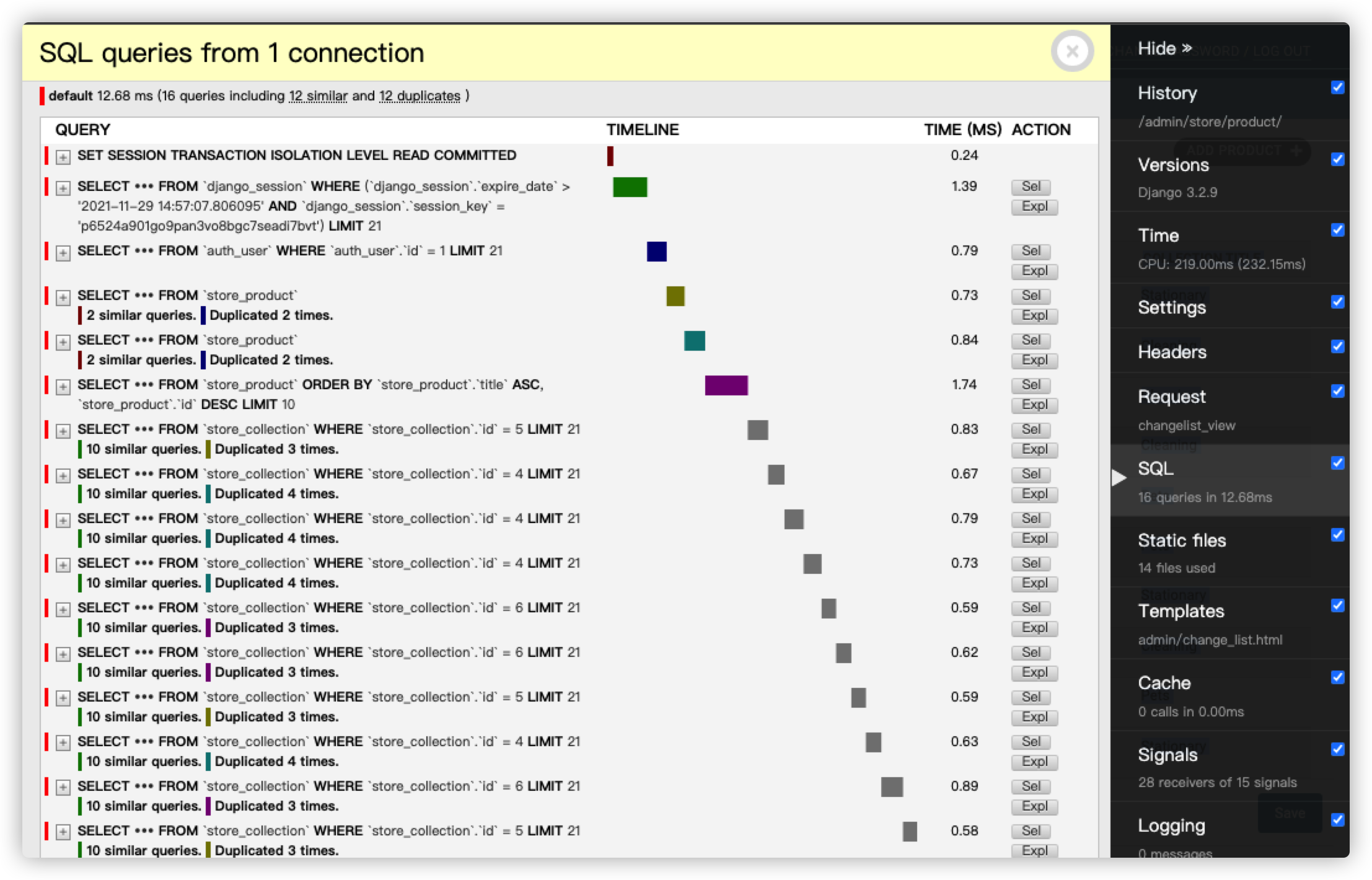
我们可以用这样一行代码来规避这些冗余的查询:
1 | class ProductAdmin(admin.ModelAdmin): |

这样,只需要执行一条SQL查询即可
当然,我们也可以直接在list_display中直接写外键相关的表的名字,比如:
1 |
|
但是,我们还是要重写__str__ 函数,让其返回客户的全名:
1 | def __str__(self): |
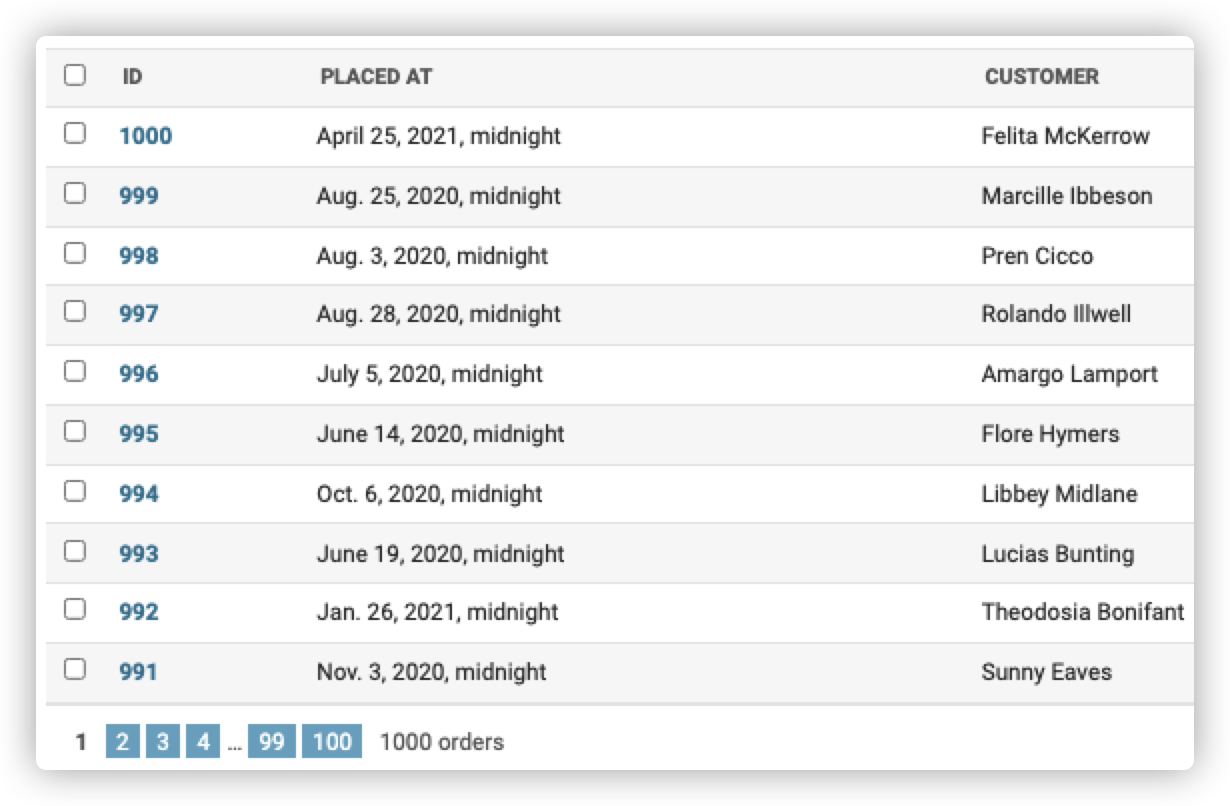
Overriding the Base QuerySet
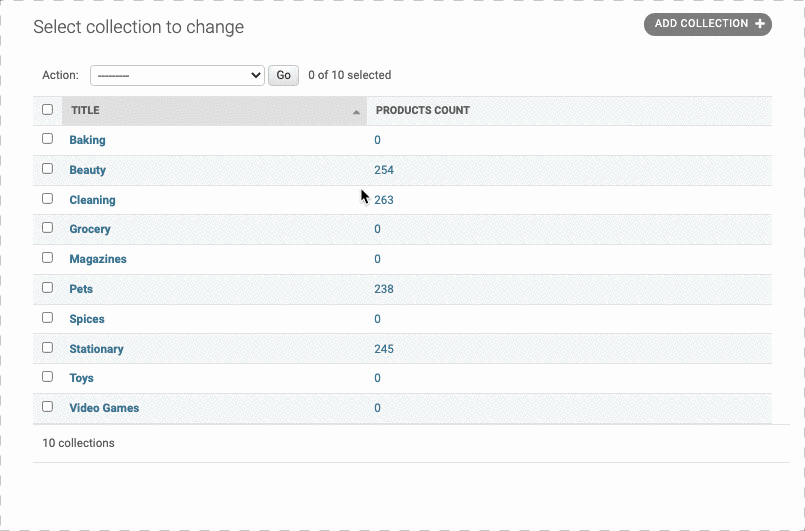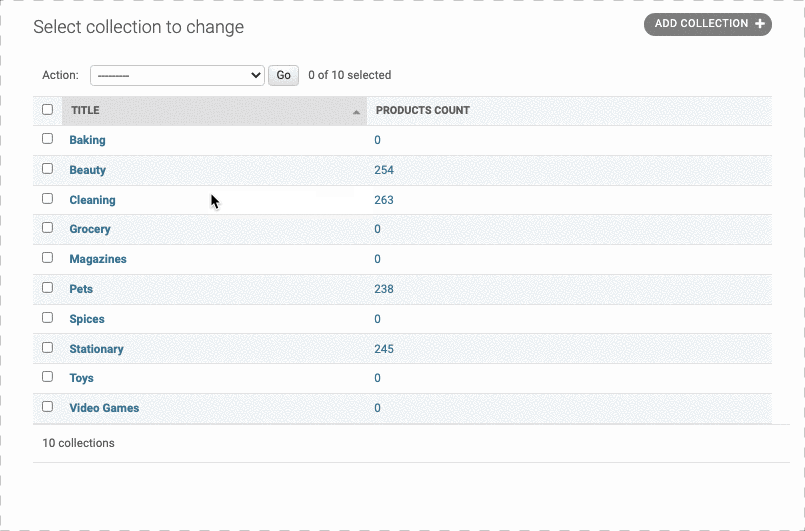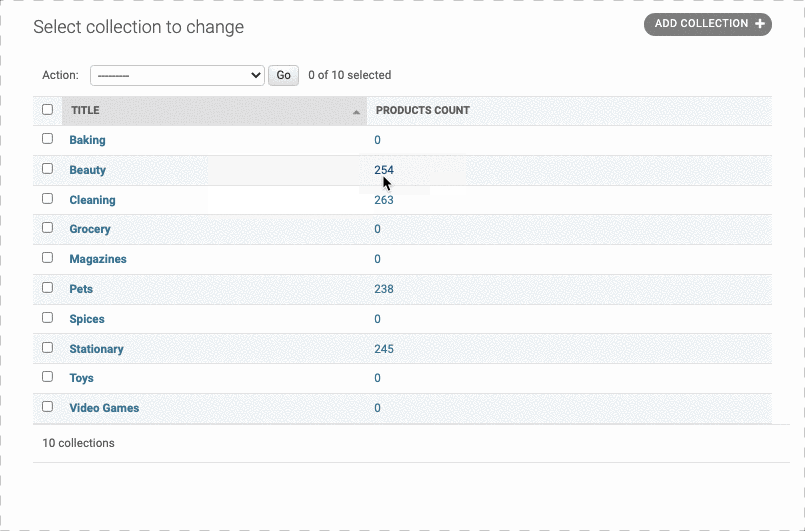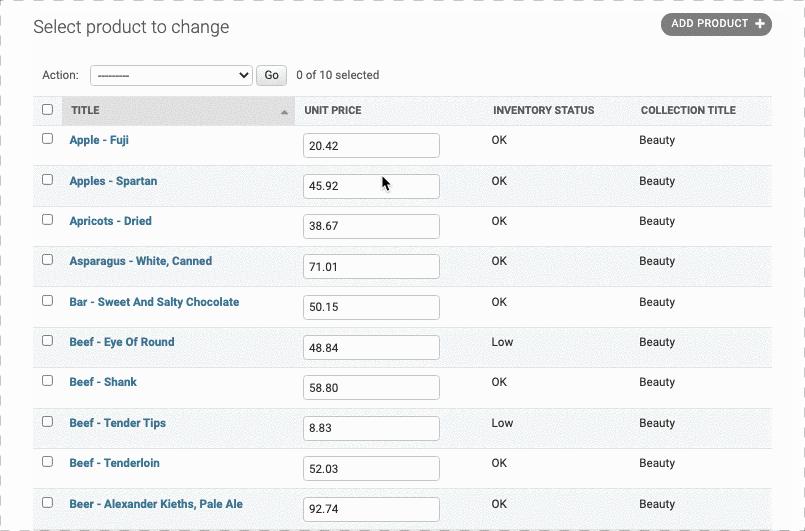
现在我们要在Collection表格中新建一列,用来查询每个Collection一共有多少件Products
Collection和Products相当于一对多的关系, 有外键相连,因此可以通过Count来计算各个类别中的产品数量
首先新建一列products_count,然后创建一个函数让其返回collection.products_count
但是我们知道Collection表格中并没有这一列,因此用默认的sql是查询不到结果的,因此我们要重写默认查询。使用到的工具就是get_queryset函数。在这个函数中,我们首先继承默认的get_queryset函数,然后将其返回的products_count改为对product数量的查询,也就是Count(product)
最后,还要定义一下排序索引,即@admin.display(ordering='products_count')
1 |
|
注意,这个@admin.display(ordering='') 一定要修饰和列名一样的哪个函数,否则会不起作用。这里,要修饰products_count
Providing Links to Other Pages
现在我想点击 Collection中的products_count列,就跳到Product页面,并筛选出这个Collection中的产品信息。
我们一步一步来,首先要将products_count 中的字符串信息转换为链接,如下:
我们需要用到format_html函数,其中,占位符中的数字就是每个collection中的产品数
1 | from django.utils.html import format_html |
然后,我们要把这边的google.com换成Products页面,如下:
我们需要用到 reverse函数,来帮助我们找到product页面的url,格式如下:admin:app_model_page。这里,app是store,model是product,page是changelist .
1 | from django.utils.html import format_html |
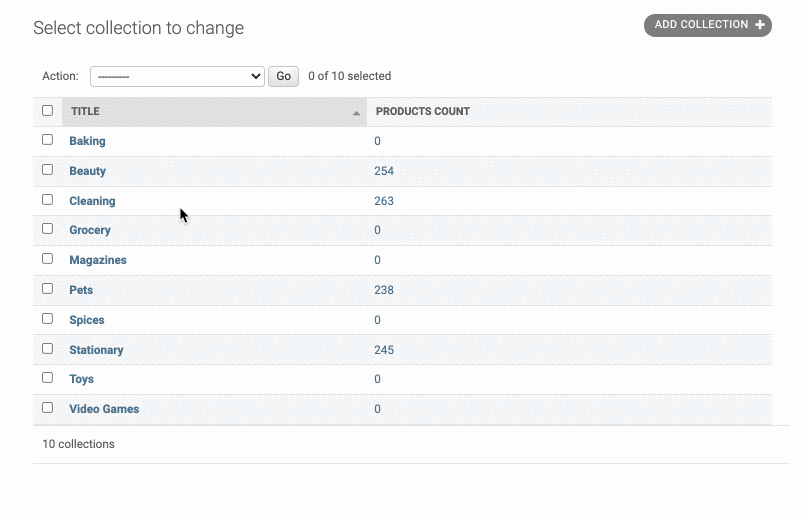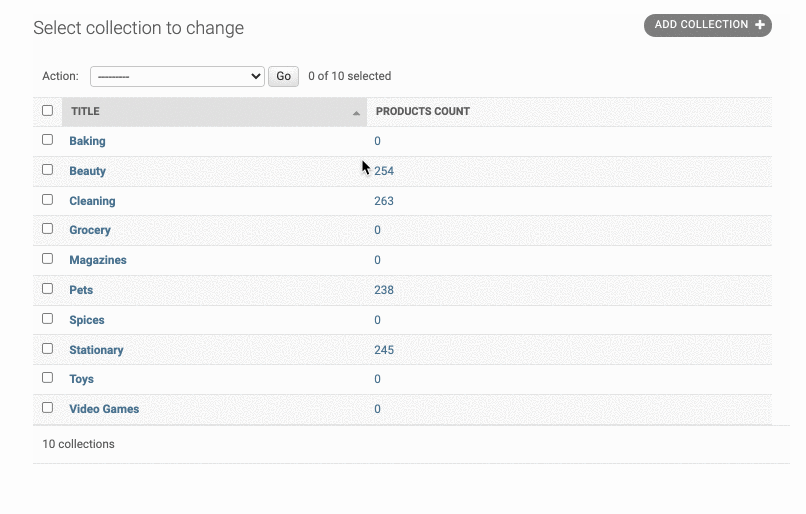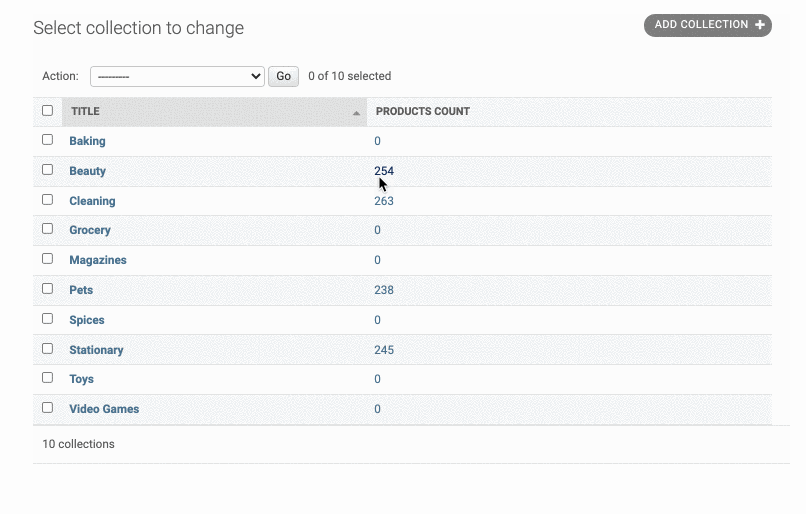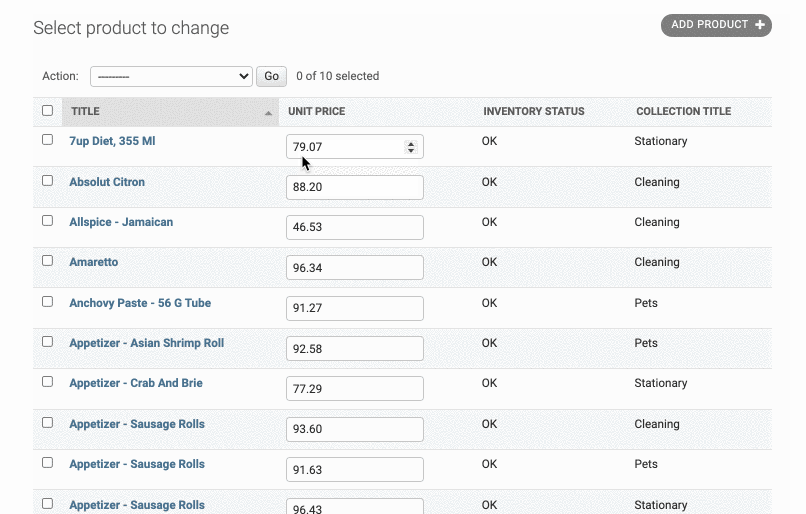
但这样只是跳转到了product页面,并没有筛选出对应collection的产品,因此我们需要对url进行完善。也就是在url中带上对collection的查询。比如说:http://localhost:9000/admin/store/product/?collection__id=3
因此我们要对url后面加上 ?collection__id=* 这样的格式
为了实现这个功能,我们需要引入一个urlencode函数,在里面可以做参数的映射,如下:
1 | from django.utils.html import format_html,urlencode |
最终效果如下:
Adding Search to the List Page
如果我们要对某一字段查询,可以在类中添加search_fields字段:
1 |
|
但这样是搜索名字里有m的顾客,和我们想要搜索以m开头的顾客名不太一样,因此我们可以这么写:
search_fields = ['first_name__startswith','last_name__startswith']
结果如下,

但是这个搜索条件是大小写敏感的,如果我搜索的是g,是搜不到任何东西的。要让Django对搜索不敏感,可以这么写:
search_fields = ['first_name__istartswith','last_name__istartswith']
Adding Filtering to the List Page
如果我们想在页面中加入筛选栏,只需要定义list_filter属性即可:
1 |
|
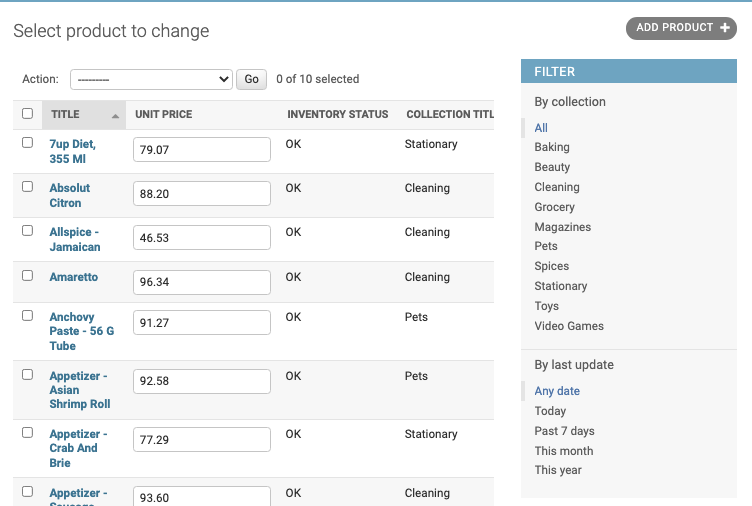
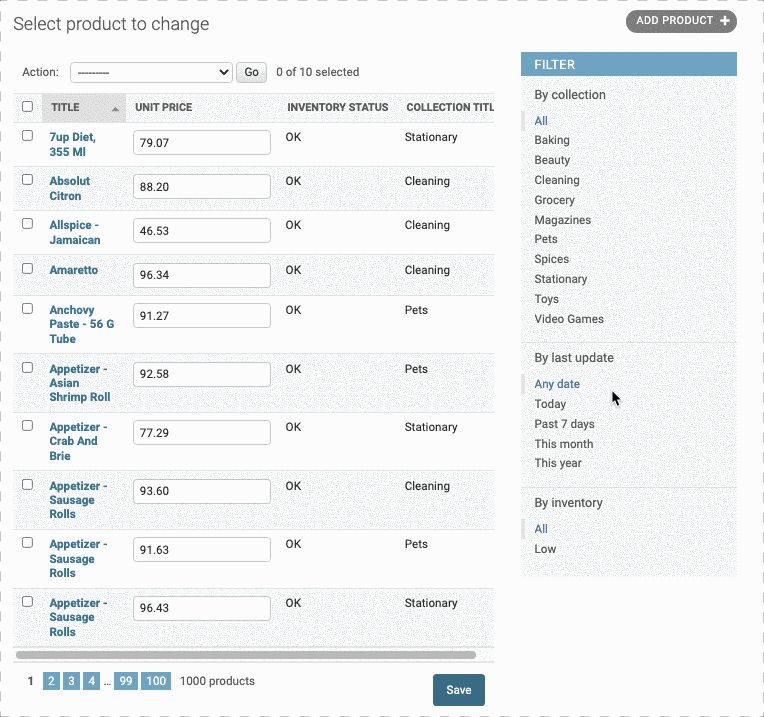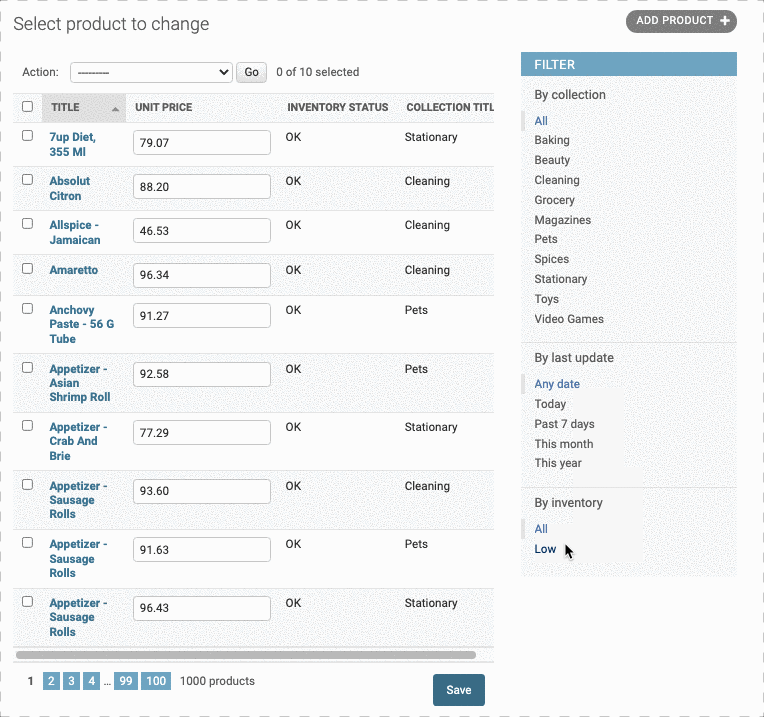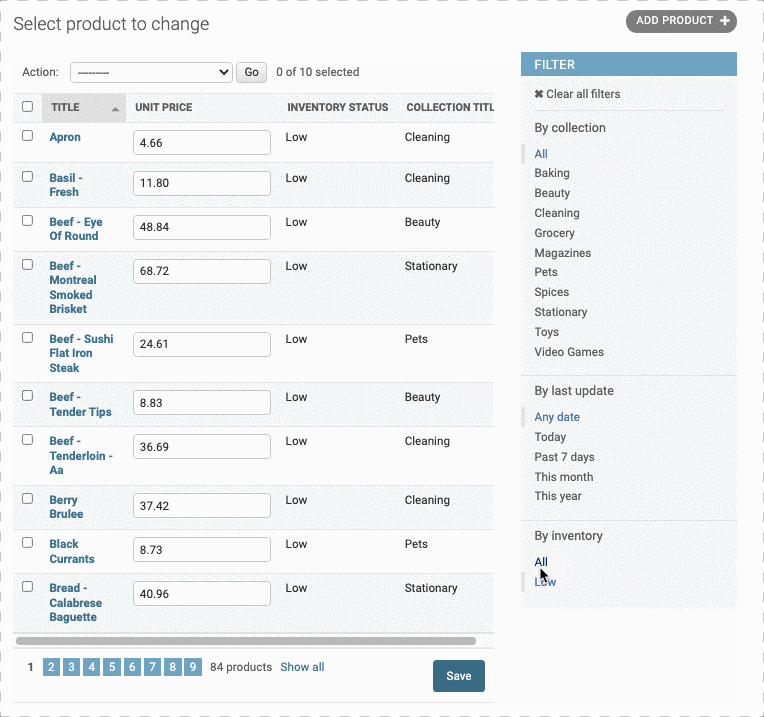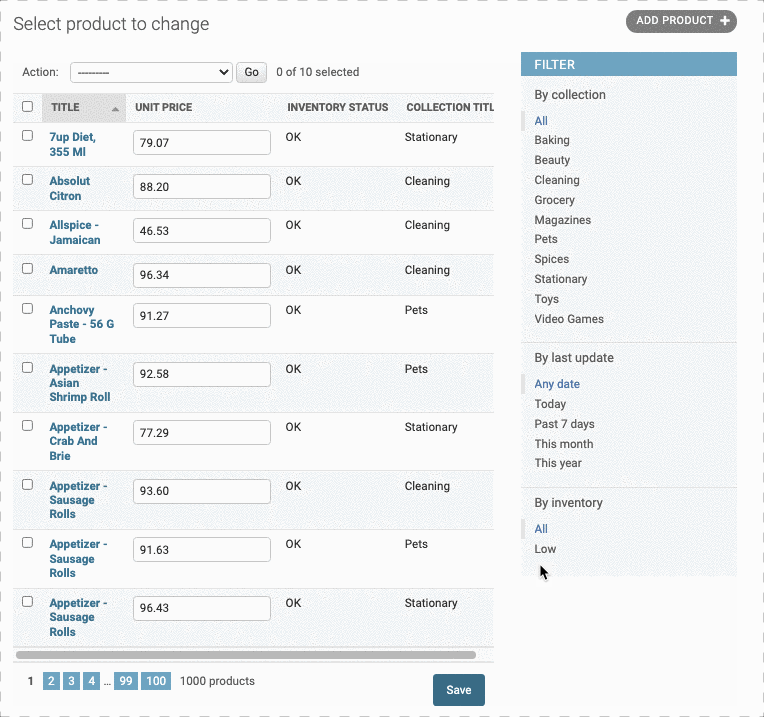
那么我们可以不可以自己创建一个筛选器呢?比如说对库存进行一个分类筛选,比如筛选出状态为Low的产品。
首先,我们要创建一个筛选器类,继承自admin.SimpleListFilter, 就叫其InventoryFilter就好
然后,我们要确认两个必要的参数:title和parameter_name,其中 title就是这个分类器的名字,也就是筛选栏顶部By后面的字符串;而parameter_name则用于url中作为查询的参数,也就是http://localhost:9000/admin/store/product/?inventory=<10中?后面的字符串inventory。
接着我们重写lookups函数.用来确定filter中的类别。这个函数要返回一个元组列表,每一个元组就代表filter中的一类元组第一个值代表url中的筛选条件,(也就是上面url最后的<10),第二个值就是这类的名字。这里我们只要选出low的库存,因此我们只要写一个元组(<10,low)即可:
但这样只是做了一个 <10和low的映射,我们还需要写一下如果小于10的内部逻辑——也就是queryset函数:告诉它,如果url中的参数是<10,应该做什么样的查询。
最后,我们要把这个类添加到list_filter中去
1 | class InventoryFilter(admin.SimpleListFilter): |
Creating Custom Actions
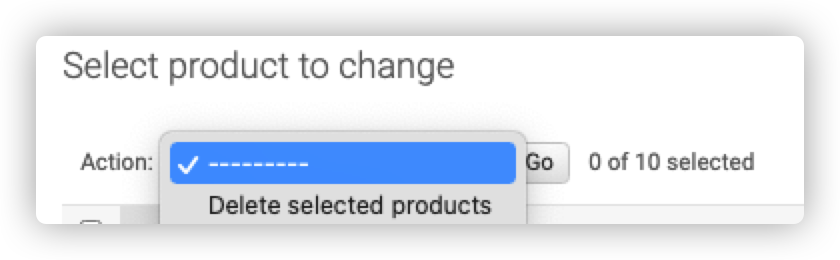
我们知道在admin中,有Action表单,在里面可以删除选中的对象。那么我们可不可以自定义Action呢?
比如说,我想自定义一个操作,每次点击会让选中的对象的库存清零。
首先,我们要新建一个函数,叫什么都行,尽量能表达出action的作用。注意,函数需要有三个参数:self,request和queryset
在这个函数中要写我们自定义操作的逻辑,这里我们就是把选中的对象的inventory属性清零。
此外我们还要定义self.message_user属性,用来确定返回给用户的信息,里面有必写的两个参数:
- 第一个参数是request,直接写就好
- 第二个参数是信息的具体内种,这里用了一个带参数的字符串,
updated_count即被更新的条目数量
message_user中的第三个参数是可选的,也就是确定信息的类型,这里选择的是message.ERROR,因此成功后的信息为红色警示
最后把这个函数加入到actions中去,注意要用字符串的形式。(函数用字符串的形式,类则不用)
1 |
|
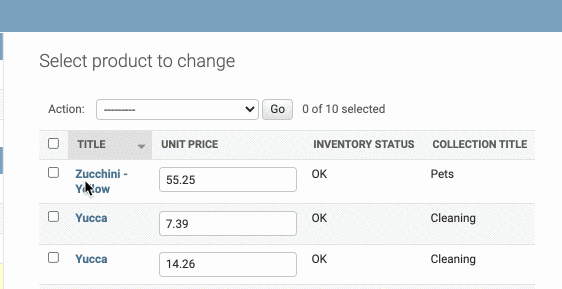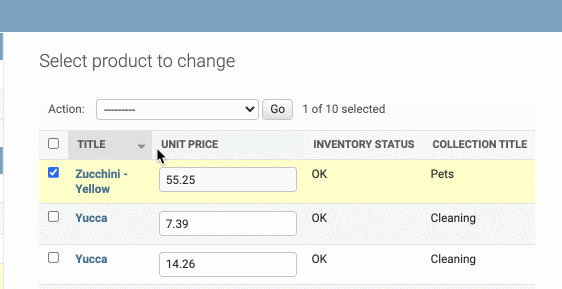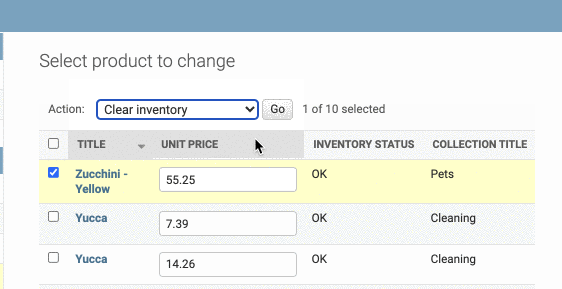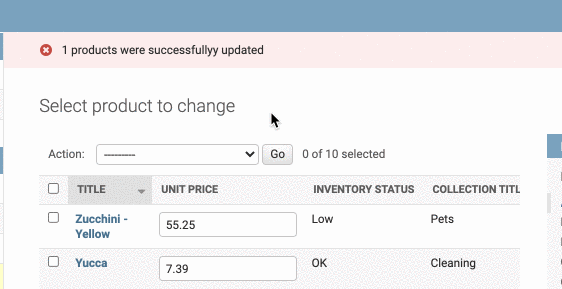
Customizing Forms
我们在products界面的右上角的ADD PRODUCT, 就会有一张现成的表单,现在我们想自定义这张表单。
限制字段
比如说我对于一个新的product,我只想开放title和slug这两个属性,其他属性都是默认值,那么可以这么写:
1 |
|
字段同步更新
因为slug的内容和Title一样,是出现在url中的一个参数,因此,可以用定义prepopulated_fields 属性来让slug和Title保持一致,如下:
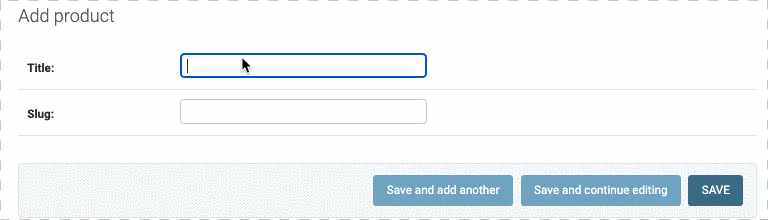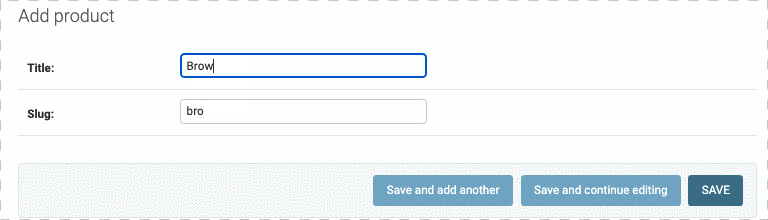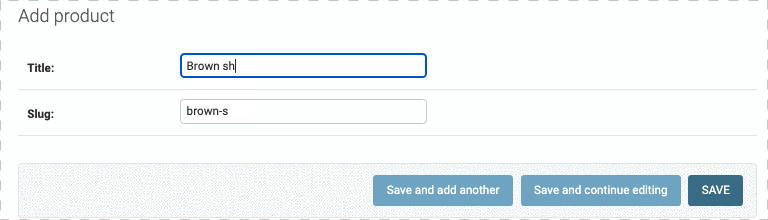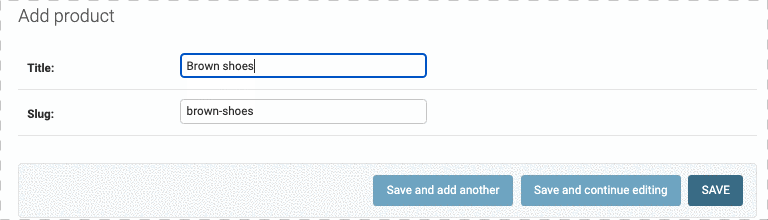
但是注意了,我们修改Title,slug会跟着一起变,但是我们如果在slug写了点东西,是不会和Title中的内容同步的,并且再回到Title中修改,slug也不会同步
下拉表单优化
对于离散的数据,Django会提供一个下拉表单供我们选择,但是如果离散值很多(比如选择省市),那么下拉表单太长会很不方便,因此我们可以在下拉表单中添加一个搜索框。
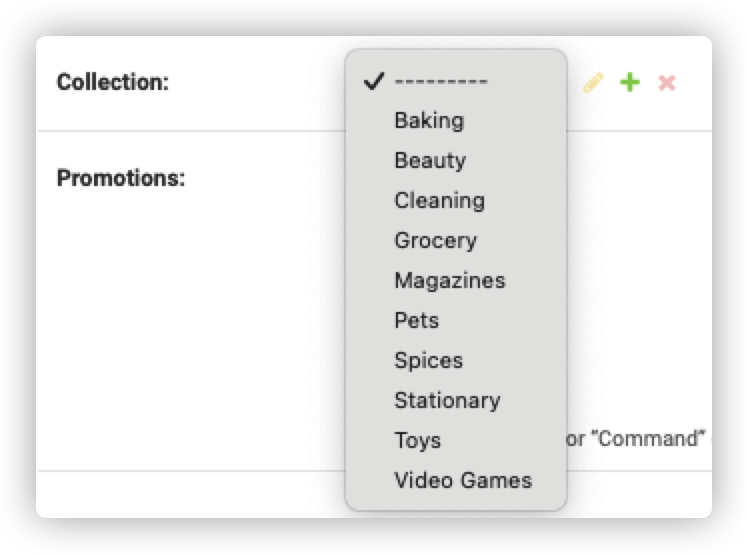
我们要修改两个地方,第一个地方是在ProductAdmin类中定义autocomplete_fields
1 |
|
此外我们还要在 CollectionAdmin中定义search_fields属性,否则相当于没开权限,没报错
1 |
|
结果如下:
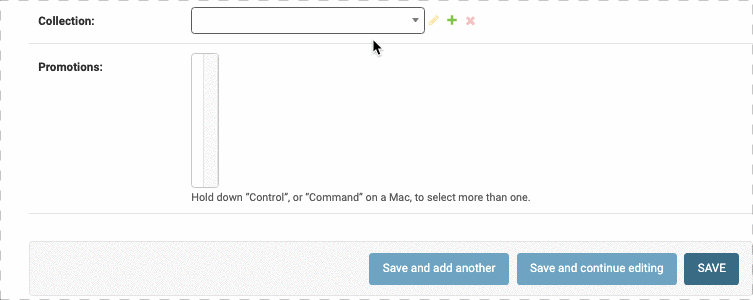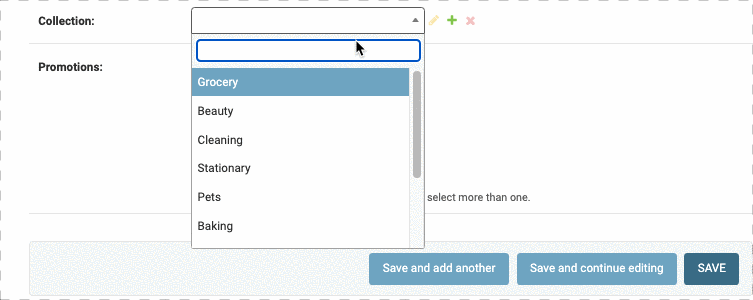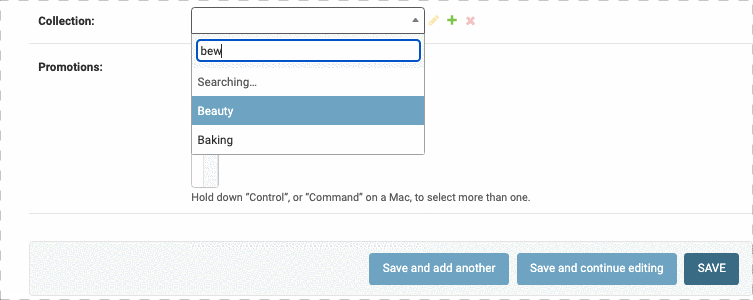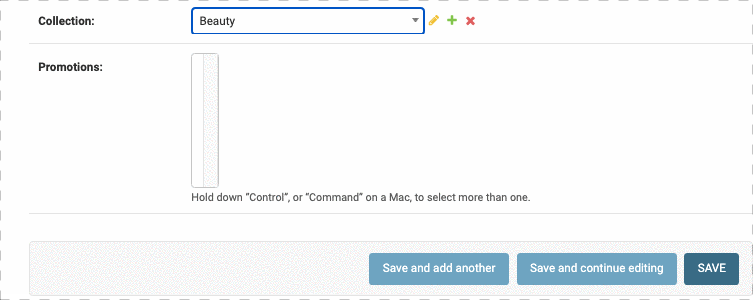
同样的,我们可以给order表单中的Customer字段添加搜索框
auto_now_add=True对表单的影响
如果在定义model的时候设立placed_at 为 auto_now_add=True,那么新建Order表单中是不会有placed_at的,因为系统会自动生成,此时如果删去auto_now_add=True就会出现Placed at字段,如下:
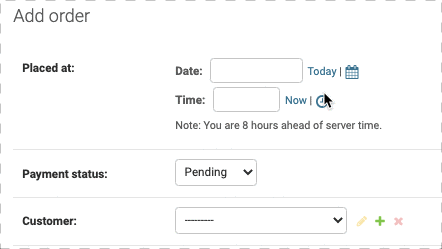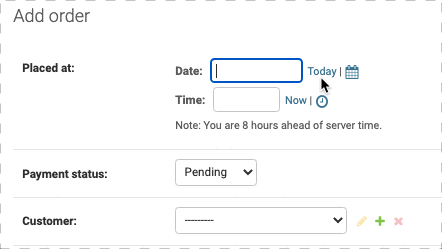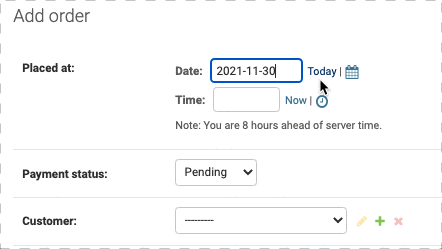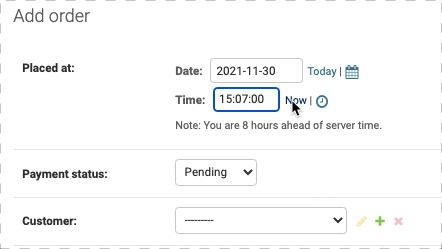
更多的自定义操作,可以看Django官方文档:
https://docs.djangoproject.com/en/3.2/ref/contrib/admin/#modeladmin-options
Adding Data Validation
我们新建一个Product,如果什么都不写就提交,Django会告诉你必写的字段还未填写内容。
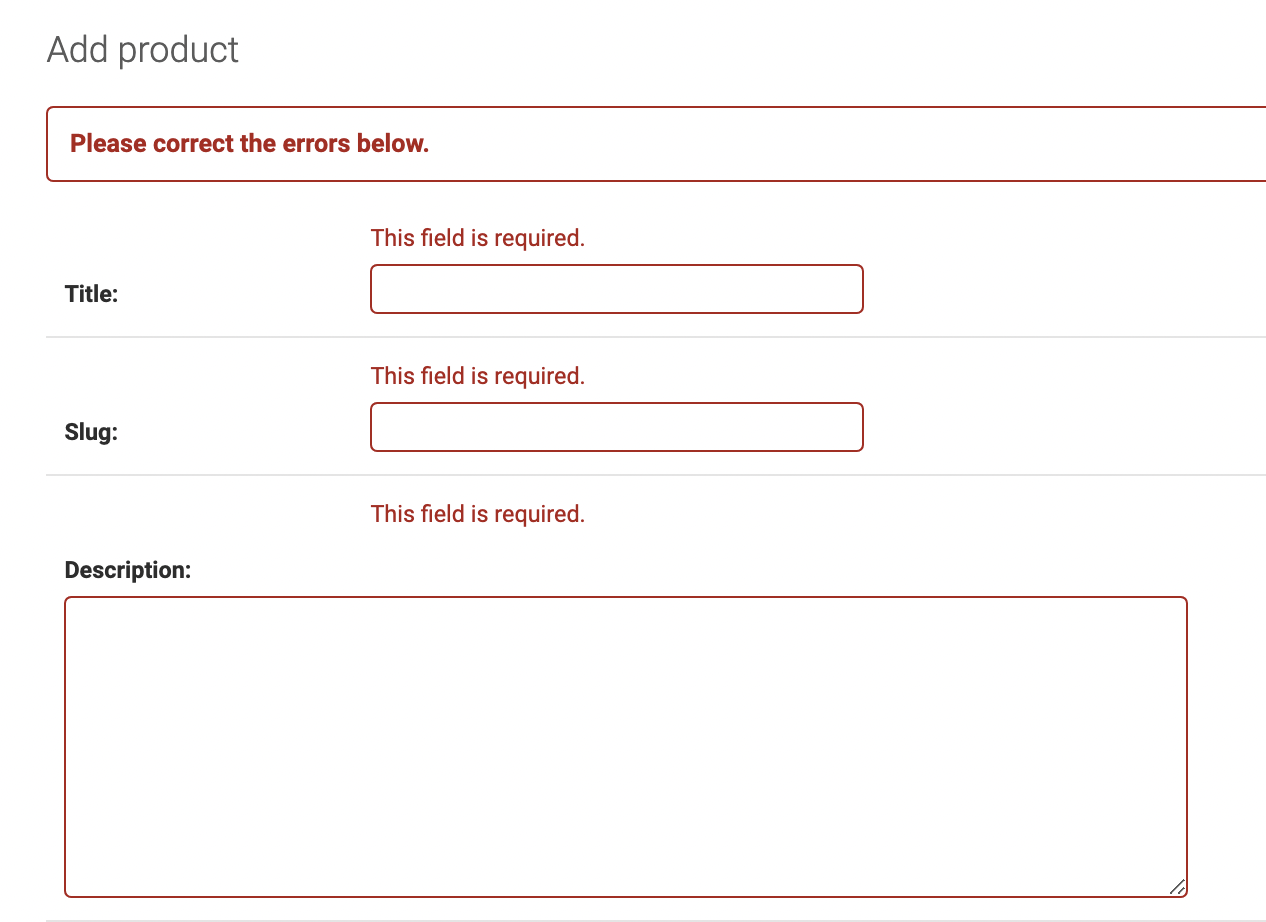
但是,在创建model的时候,如果我们设置属性是null=True的话,Django就不会给我们这种提示
此外,比如说对于unit price字段,我们知道需要填一个正数,但是现在Django只要求你填写数字,不要求正负。因此我们要通过代码把这个验证功能加上:
我们需要用到 django.core.validators 这个类。这里我们要规定价格的最小值,因此要用到MinValueValidator这个类,传入的1就代表最小值。第二个参数是可选的,即可以自定义不满足要求所返回的信息比如:validators = [MinValueValidator(1,message="No No No")]
1 | from django.core.validators import * |

https://docs.djangoproject.com/en/3.2/ref/validators/
Editing Children Using Inlines
我们现在可以新创建一个订单,但是没有办法在创建订单的时候确定订单中的产品。这时候就需要把子对象OrderItem添加进来,可以使用inlines属性:
首先我们要创建一个类,叫OrderItemInline, 它可以继承自admin.TabularInline也可以继承自admin.StackedInline
我们想添加的是 OrderItem类型,因此要确定model属性
其中有字段product,我们要为其添加搜索框。
我们希望订单最少订购一件商品,最多10件,因此规定min_num和max_num
如果我们不设定min_num和max_num,那么默认是3个,上不封顶。如果我们希望默认是0个,可以用extra=0 ;否则,当我们设定min_num=1的时,默认就有4个Products了
最后,我们要在父类OrderAdmin中定义inline属性,把OrderItemInline传入
1 | class OrderItemInline(admin.TabularInline): |
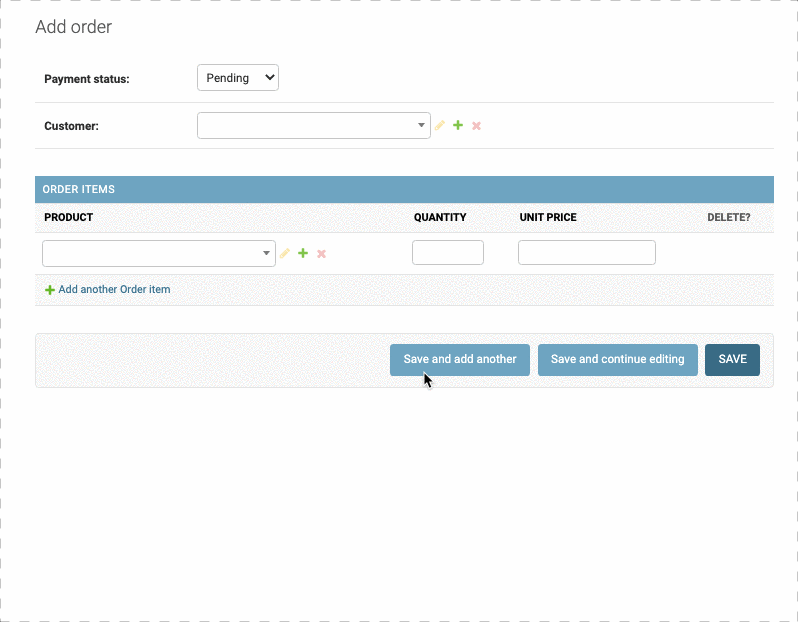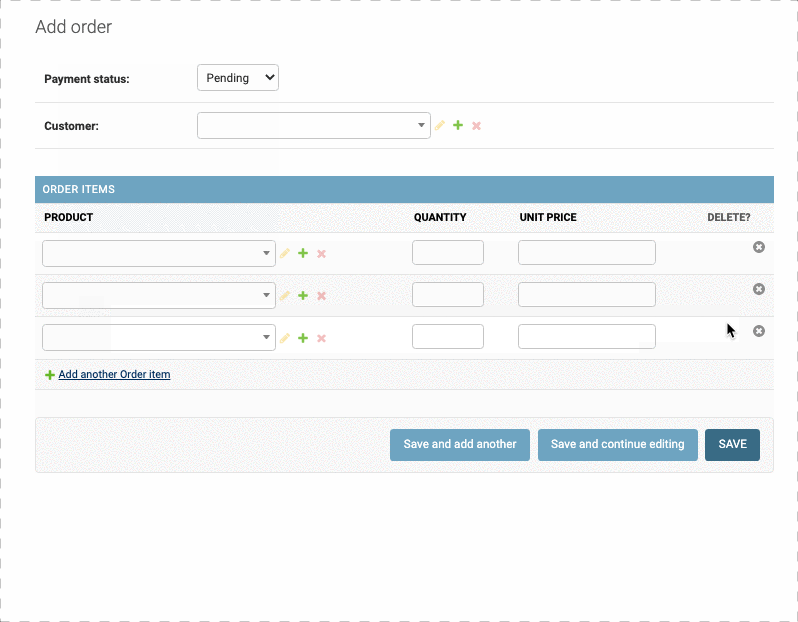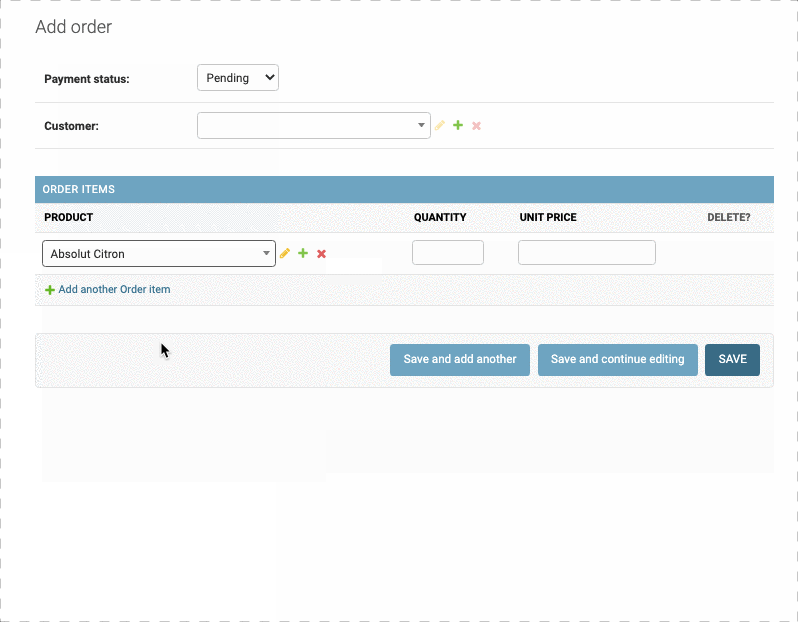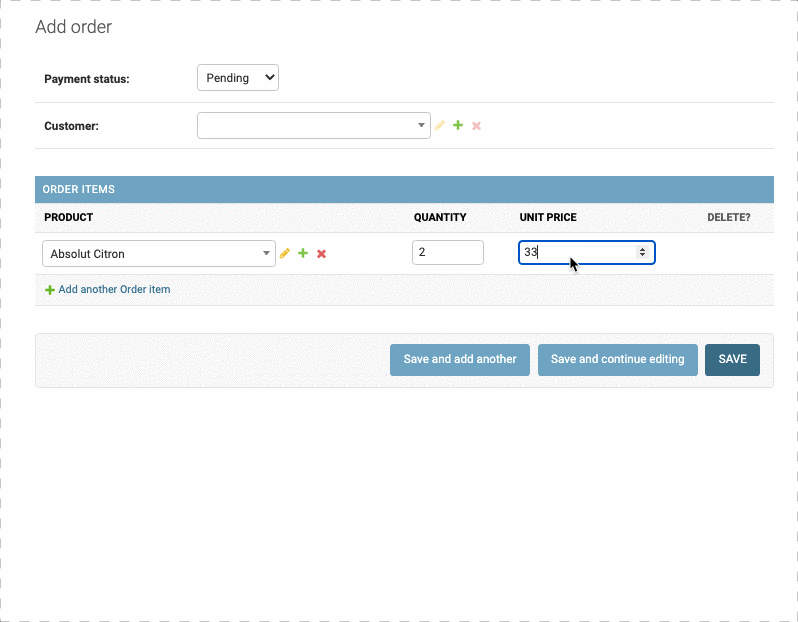
TabularInline和StackedInline 的差别就在于排版方式,StackedInline是按列排版的,如下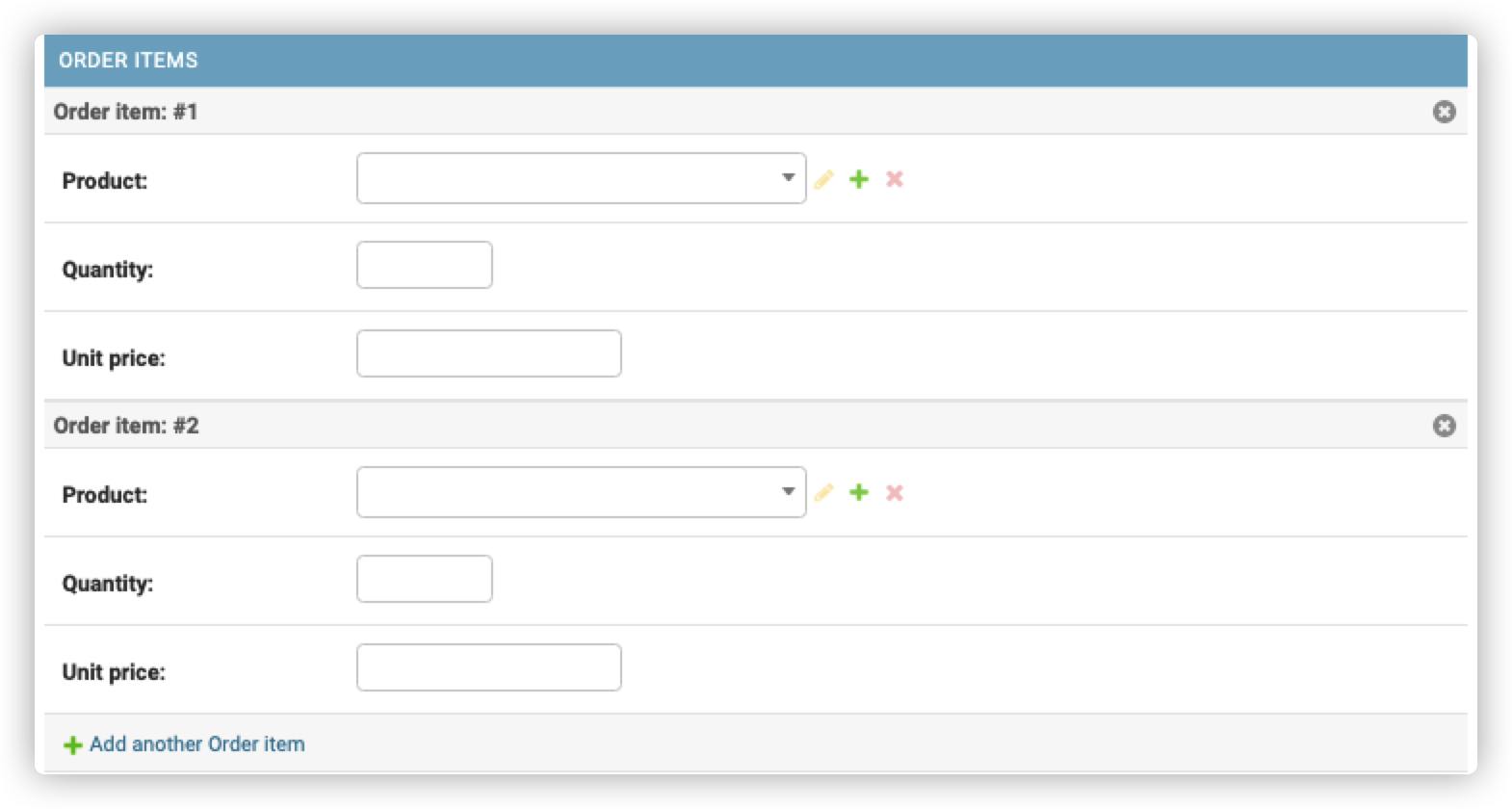
Using Generic Relations
现在,我们要把Tag以inline的形式加入到新建Product表单里面
首先,我们要把Tag界面加到Admin主页中去:
1 | from django.contrib import admin |
1 | from django.contrib.contenttypes.admin import GenericTabularInline |