数据管理系统1-2章
预备知识
什么是系统
系统要拥有的性能:
- 通用性
- 隔离性
- 精巧性
什么是数据管理系统
首先,数据管理系统要有数据存放功能,这是最基本的要求。其次,要有数据组织的功能,因为一个系统里面有很多结构复杂的数据,该系统要能够在需要时迅速找到这些数据。再来,要有数据正确的功能,比如说银行的数据系统,或者是淘宝的数据系统,数据的安全非常重要。最后,要提供一个数据处理的平台,大量的数据并不会拿到云上的服务器去处理,而是在数据管理系统处理完之后再输出
课程内容
- 如何使用数据管理系统
- 构建思想
- 数据管理系统的实现原理
- RDBMS-PostgreSQL
- NoSQL-Mongodb
如何模块化
现在有一个程序,我们要他实现这样一个功能:
输入:一张表,每行为一个单词序列
输出:对每一行实施”位移“,并按照字母顺序输出所有”位移”
比如说:“A good day” ->”good day A”和”day A good”
为了解决这个问题我们可以设计如下套方案:
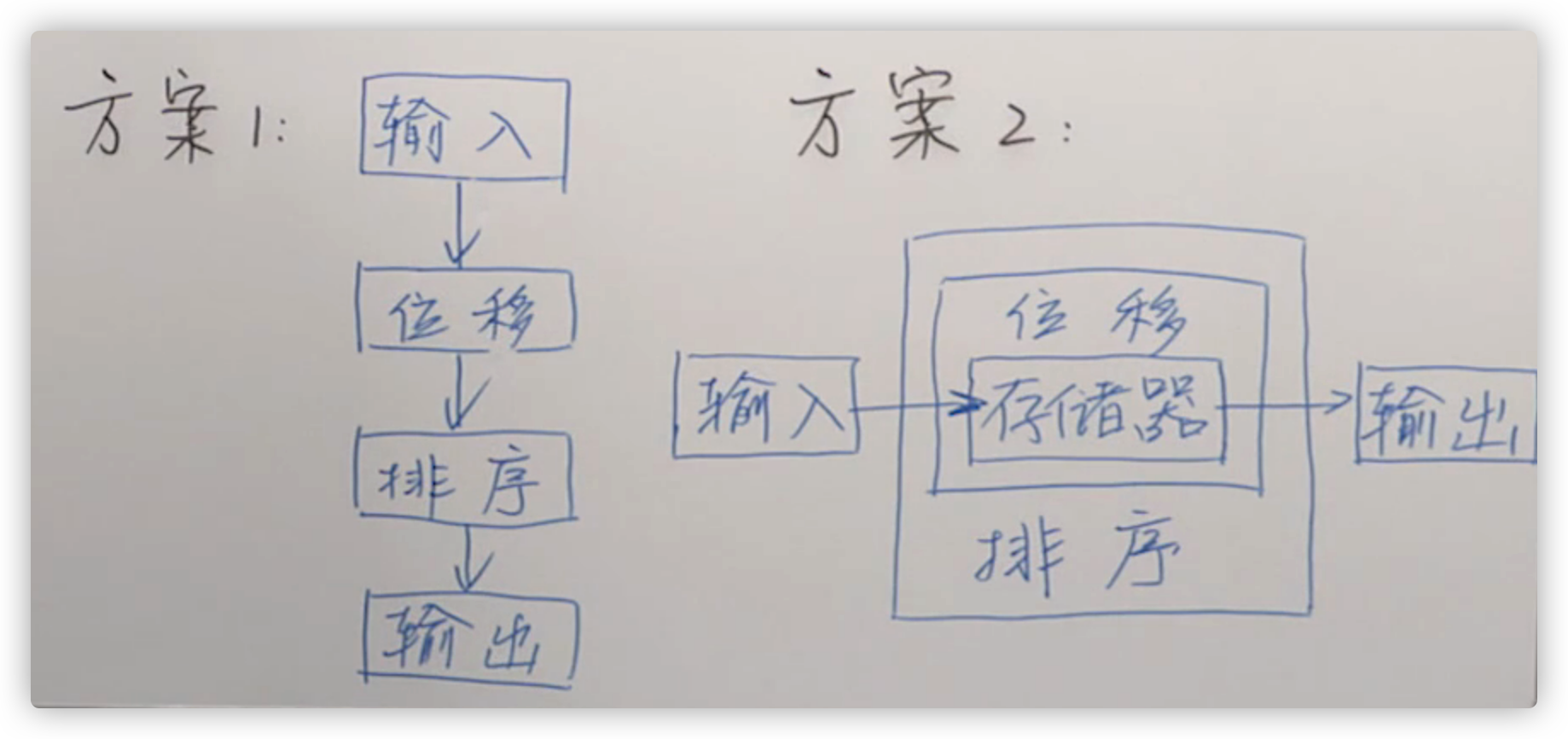
第一套方案是:设计5个模块,一个是总控模块;然后每个模块各自负责输入、位移、排序和输出操作,前一个模块处理完后,后一个模块接着处理,它们都访问的是同一片地址上的数据。
方案1 是一套非常自然的想法,是比较朴素的。
第二套方案是:设计6个模块,一个是总控模块,输入模块将数据存放到存储器中,存储器向上给出一个接口,供位移模块进行操作,位移操作完成后,由向上伸出一个接口,供排序模块操作,最后输出调用排序模块的接口输出数据。
直观来看,第一种更能让人理解,但是第二种更好。方案一中的四个模块有一个共同的接口,就是内存中的数据,那么当出现数据量过大导致存储器结构发生改变的时候,方案1中的四个模块都需要进行代码结构上的修改。而对于方案2,内存中的数据只需要排序模块来负责,其他模块只要调用更为底层的接口即可,因此出了问题可以只对存储器进行修改。
这就牵扯到模块化的一个重要原则:信息隐藏, 它可以用来衡量一个系统的模块化是否合理
思考题
请为以下程序做模块设计
输入:若干文件,每个文件是一篇文章,由若干英文单词组成。
例如:file1.txt, file2.txt, file5.txt,….输出:一个单词文件列表,记录了出现在文件中的每一个单词以及包含这个单词的所有文件的文件名。
例如: apple 出现于 file1.txt, file5.txt, ….
fish 出现于 file2.txt, file5.txt, ….
computer 出现于 file1.txt, file8.txt, …
… …
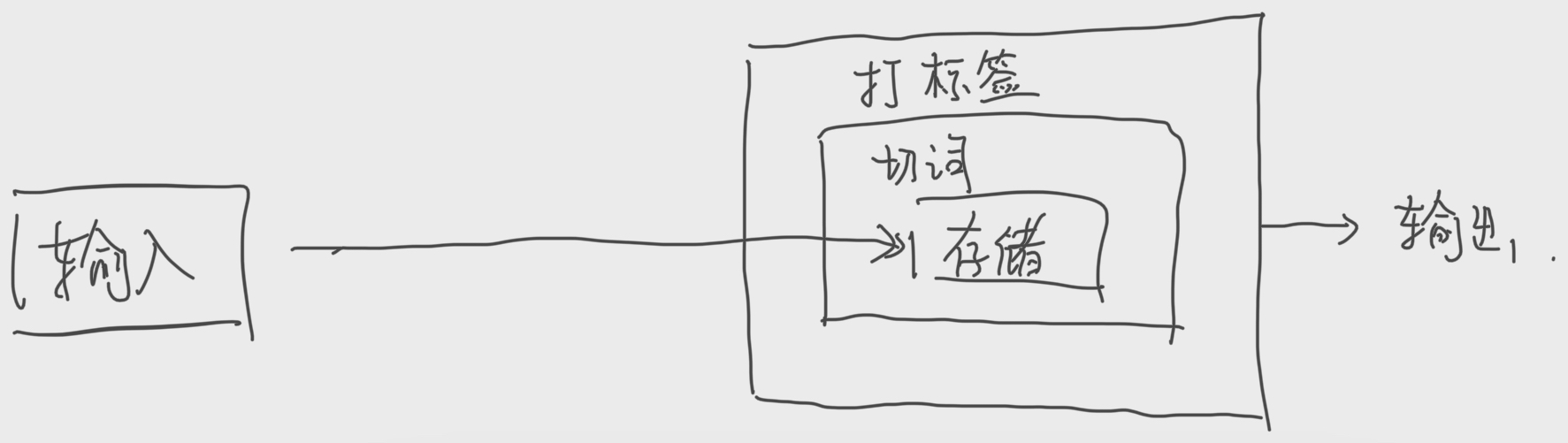
- 首先还是输入模块读入数据,放到存储器当中
- 然后,切词模块会把文章的单词一一提取,成为一个字符串数组。
- 接着打标签模块调用切词给出的接口,得到了字符串数组并为其打上了属于哪一篇文章的标签
- 最后交给输出模块输出。
文档数据库
数据库系统的基本理念
首先,基本所有数据库系统都有CRUD四种操作,分别代表:Create,Read,Update,Delete。
然后,我们要来介绍OOP(Object Oriented Programming) 也就是面向对象的程序设计,通常对于数据库中的一张数据表,我们要对其进行操作,就要设计一个于其相对应的数据模型。里面包含了个字段的名称、类型、限制以及字段之间的关系。
我们在Django教程中,对Mysql创建数据模型有着详细的介绍:Build a Data Model
在NodeJs教程中,对Mongodb数据库创建数据模型也有介绍:models目录 以及 CRUD Operations Using Mongoose
在数据库中,每一张表其实也是一个数据模型。数据模型不同,数据库的使用功能也有不同。比如说关系数据库、文档数据库. 数据库里存档的数据可以看成是一个个对象。
文档模型
对于文档数据库而言,对象就是一个个文档。数据最终是存放在文档里面的。其结构如下:
database:数据库
Collection:文档集
document:文档
文档的组织结构是什么呢?在Mongodb中我们看到过这种形式:以一件淘宝商品为例:
1 | { |
这是一个 key-value 的集合。key代表属性而value则代表取值。
文档里面也可以嵌套文档,这叫做子文档,比如:
1 | { |
从几何的角度来看,这是一个树状的结构
文档数据库的基本功能
对于文档数据库,增删改查的指令是怎么实现的呢?
以mongodb为例:
插入操作(Create):db.myCollection.insertOne({...})
db是数据库的名字
myCollection是文档集的名字
insertOne是方法
查找操作(Read): db.myCollection.find({...})
find里面是该信息的描述信息。比如说
find({"gender":"male","birthday.year":"2001"})的查找条件就是:找到文档中包含gender、birthday.year属性的信息,并且要满足gender的值为male,bithday.year的值为2001
其实在查询语句中的信息也是一个小文档,可以形象为一棵小树。观察小文档和大树的信息,可以发现小树是大树的一部分。因此说大树和小树是匹配的,大树是小数的查询结果。数据库系统所做的就是返回所有和小树匹配的大树。
修改操作(update): db.myCollection.updateOne({"name":"Jason"},{$set:{"birthday.year":"2002"}})
这条语句中包含了两个小文档,一个小文档是目标,即要查询的信息;第二个小文档是要修改的内容。
$set是修改操作符,格式如下:{ $set: { <field1>: <value1>, ... } }
删除操作(delete):db.myCollection.deleteOne({"name":"Jason})
关于查找,我们可以使用_id 来查找某一个特定的文档
文档是如何存储的
现在我们知道了文档是放在数据库里面的,但这只是软件层面的,怎么从硬件层面来了解文档的存储、组织与管理呢?
文档数据是存放在硬盘(SSD/HDD)里面的。但是对于内存可以用来当做缓存,经常被使用的数据会存放在内存里,以便于CPU去使用。
那么文档是怎么放在硬盘里面的?要知道硬盘是一块连续的空间。连续紧挨着肯定不行,因为如果我要更新文档的时候,需要整体移动,导致空间管理很混乱。更合理的方式是将空间划分称一页一页的,页与页之间互相独立,每一页是固定的大小(4MB),我们可以将文档放在页里,当需要修改文档的时候,只需要调整页即可。
当要访问文档时,首先会将页提出并存放到内存里面,当使用完毕之后,会写回到硬盘里面。
文档集的物理知识
我们上面讲了,文档 是存放在页里面的,那么文档的集合是怎么将这些页组织、打包的呢?
在操作系统中我们学过,在文件系统中我们使用inode,结构如下:
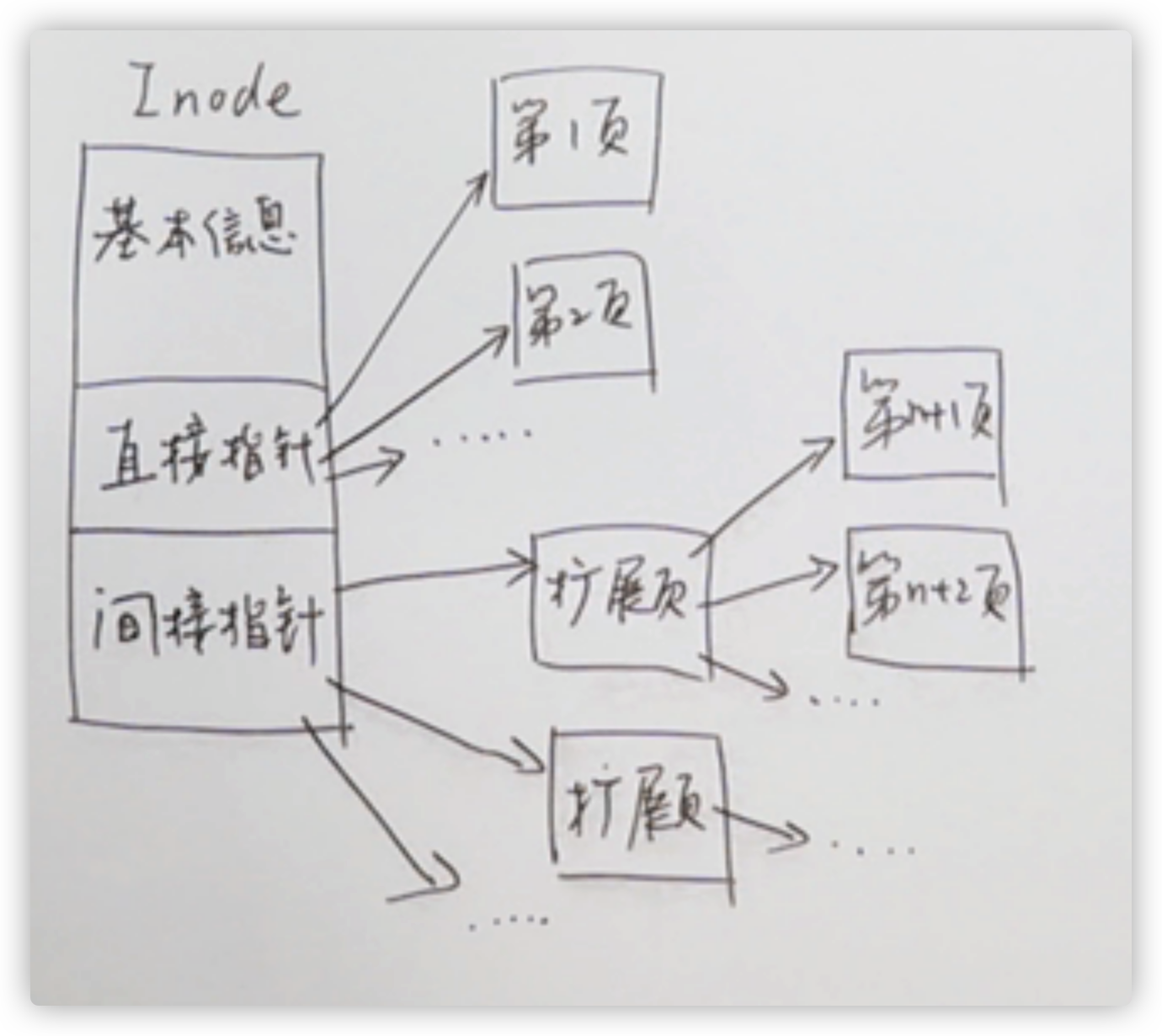
同样的,在数据库系统中也可以这样来组织。这里直接指针会直接指向数据存放的页,而间接指针指向的是存放有指针的扩展页。
当我们想要插入文档时,可以找到最后一页,然后再里面插入。
对于读取、更新、删除文档的操作,首先要找到文档在哪。首先要根据文档集合的名字,找到对应的inode,然后将文档集合中的页面存放到内存里面。然后要扫描整个文档集合来找到匹配项。显然,这种方法是不太理想的,因为要扫描整个文档会浪费大量的时间。
因此,还需要有一个索引函数,当我给其一个查询的条件之后,索隐函数会返回满足条件的文档所在的地址(页),然后我们直接去页里读取、修改。这样的效率就会大大提高。
这种索引函数怎么实现? 我们需要用到B树这个数据结构
B树索引
关于B树,我写了一篇博客,详细讲述了查找、插入以及删除的操作:B树