数据科学算法基础-尾概率
引入
我们现在抛一枚均匀的硬币,正面和反面朝上的概率都是0.5,而且每次抛币都是独立的。知觉上,抛的次数越多正面朝上的概率越接近于0.5。如下图所示:
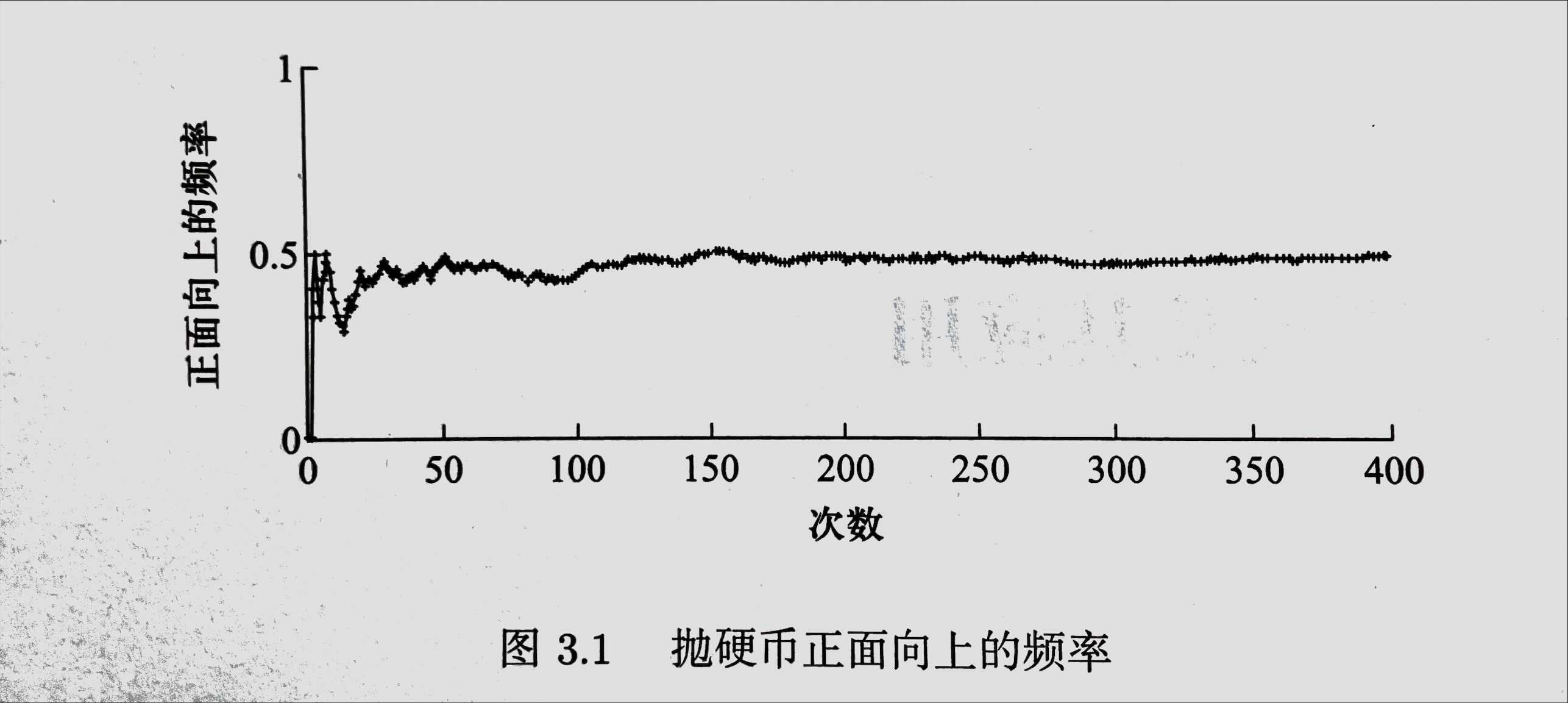
那么,如果我要计算到底抛多少次才能以$95\%$ 的概率保证正面朝上的频率和真实概率间的差距小于某个阈值(0.125)呢?
为了回答这个问题,我们要用到尾概率不等式来计算概率上界,这边有三个方法:
Markov不等式、Chebyshev不等式、和Chernoff不等式
Markov 不等式
给定样本空间$\Omega$上的非负随机变量X,对 $\forall a\geq 0$ 有:
或者
证明:
因为$X\geq 0$ ,我们得到:
所以,我们得到 $P(X>a)\leq \frac{E(X)}{a}$
但是,Markov不等式给出的尾概率上界可能非常宽松,比如说,我们要求均匀硬币抛掷n次之后,正面朝 上次数X大于$\frac{3}{4}n$的概率是:
用常识来判断,随着n的不断增大,正面朝上次数X 这个概率是很小的,但是用Markov不等式得出的结论是不管n多大,上界都是不变的。
Chebyshev 不等式
现在我们在马尔科夫不等式的基础上修改一下,令$Y = (X-\mu)^2$ ,带入Markov不等式可得:
然后,将概率中的$Y>a^2$开平方,可以得到:
因此我们可以给出Chebshev不等式的定义:令X为定义在样本空间$\Omega$ 上的随机变量,对任意的一个正实数$\epsilon$,则:
切比雪夫不等式还可以写成如下形式:
再分析一下抛硬币的例子,此时,概率P就变成了:
如果抛掷均匀1000次,这一尾概率小于 0.004
这个上界就比Markov小很多了。
Chernoff 不等式
随着实验次数的增加,Chernoff 不等式将给出比Chebyshev不等式更紧的尾概率上界。
定理:
若$Xi$ 为定义在样本空间$\Omega$上的n个独立伯努利随机变量,且 $P(X_i=1)=p_i$。 令 $X=\sum{i=1}^nXi$和$\mu=\sum{i=1}^np_i$,对任意小的$\delta \in(0,1)$ 有:
结论1:
结论2:
然而,在不等式中计算$(1-\delta)^{1-\delta}$和$(1+\delta)^{1+\delta}$这两个数是比较麻烦的,因此我们可以用Taylor展开对其进行更进一步的简化。
已知:$\ln (1-\delta) = \sum_{i=1}^\infty -\frac{\delta^i}{i}$
所以:
因此
进一步:
同理,我们可以证明另外一种情况。
简化后的Chernoff不等式
结论1:
Morris算法
定义一个数据流, $i∈[1,m],a_i∈[1,n]$,频率向量$
Morris算法
算法

将X初始化为0
循环
如果$a_ i$出现一次 就以$1/(2^X)$的概率将X增加1
返回$\hat f=(2^X−1)$
证明的目标
我们期望返回的值与N的差别尽量小,换句话说就是如果$\hat f$与N的差的绝对值大于某一个很小的值的概率很小,那么我们就可以用这种方法进行计数。说得更通俗一点就是使这个算法计算出的结果偏离N不多,或者偏离太多的概率特别小。
可以利用切比雪夫来证明这一点 $P{[|X - \mu| \geq \epsilon]} \leqslant \sigma^{2}/\epsilon^{2}$
证明
计算期望:$E[2^{X_{N} } - 1] = N$
因此 $E[2^{X_N}-1] = N$
计算方差:$var[2^{X_{N} } - 1] = \frac{1}{2}N^2-\frac{1}{2}N$
我们令切比雪夫不等式中的 $X = 2^{X_N}-1$
其中,$X_N$ 指的是$X$ 最终的值,是在这个计数器在流模型中经历了N个数字。则最终得到公式
评价
Morris算法的优点是:输出结果是真实值的无偏估计
但显而易见,模型的正确性并不好,仅当$\epsilon\geq 1$ 时,尾概率上界不大于1/2, 并且随着N的增大误差和发生误差的概率也会变得越来越大。
关于近似计数有更加高效的算法morris+算法和morris++算法
Morris+算法
为了降低Morris算法数据结果的方差,我们提出了Morris+算法

用语言来描述就是:
- 运行k次morris算法
- 记录记录结果$(X_1,\cdots,X_k)$
- 返回$\gamma = \frac{1}{k}\sum{i = 1}^{k}(2^{X{i} } - 1)$
证明
直接获取各个$X_i$对应的期望和方差,这在证明morris算法的时候已经计算过了。
于是可以直接根据期望的性质计算期望$E[γ]=N$
因为各个变量之间是相互独立的,所以可以利用独立变量之间方差的性质计算方差$D[\gamma] = \frac{N^{2} - N}{2k}$
令切比雪夫不等式中的X为$\frac{1}{k}\sum{i = 1}^{k}(2^{X{i} } - 1)$,代入计算得到:$P[|\gamma - N| \geq \epsilon] \leqslant \frac{N^{2}-N}{2k\epsilon^{2} }\approx O(\frac{1}{k\epsilon^2})$, 换一种描述就是:
以1−c的概率,$\gamma = N \pm \sqrt{\frac{N^{2}-N}{2kc} }$ 或者 $N\pm \frac{O(N)}{\sqrt k}$
评价
Morris+算法的复杂度为$O(\frac{1}{\delta\epsilon^2})$
当N确定时,如果想以0.9的概率满足近似标准,使c=0.1,则有 ,我们会发现$k = \frac{5(N^{2} - N)}{\epsilon^{2} }$,这是你需要重复morris算法的次数。然而这么看代价也是不小的,因为这个算法为了保证准确性需要的k的个数并不少。
Morris++算法

用语言来描述,就是:
- 重复morris+算法 $m = O(log(\frac{1}{\delta}))$次
- 取m个结果的中位数
为了得到$1−\delta$ 下的 $(1+\epsilon)$近似,使用morris+算法需要$k = O(\frac{1}{\epsilon^{2} \delta})$次计算,而morris++算法的工作就是将这一复杂度降低到了$O(\frac{1}{\epsilon^{2} }log(\frac{1}{\delta}))$说白了,也就是降低了计算次数。
算法分析
我们假设运行 t 个 Morris+ 实例,每一个都有 1/3 的失败概率,即:
那么,输出所有 t 个 Morris+ 实例输出值的中位数的话,t个Morris+算法都失败的期望是不会超过$t/3$的。因此,Morris++如果输出了一个糟糕的估计,就会以为t个Morris+算法至少有一半都失败了。
我们定义随机变量 $Y_i = \cases{1, \text{if} \left|{\hat n_i-n}\right
|>\epsilon n\~\0,\text{otherwise}}$ 来表示的是第i次 Morris+ 算法失败与否
注意到:
则根据Chernoff 不等式可以知道:
也就是说得到了 $\exp (-\mu/12)<\delta,\mu<12\ln (1/\delta)$
因此,需要运行 $t = O(\ln (1/\delta))$次 Morris+算法,其结果的中位数才能符合精度要求的近似估计。
例题
1
已知随机变量X的期望 $\mu = E(x)$ 和方差 $\sigma^2 = E[(X-\mu)^2]$. 如果定义随机变量 $X^* = \frac{X-\mu}{\sigma}$ ,证明
我们通过求变形后的 $X$ ,结合切比雪夫不等式,来实现
2
假设抛一枚均匀的硬币n次,随机变量X定义为正面朝上的次数
- 运用 Chebyshev 不等式给出事件 $X<\frac{n}{4}$ 的概率上界
- 运用 Chernoff 不等式给出事件 $X<\frac{n}{4}$ 的概率上界
3
设一组独立随机变量 $Xi\sim Bernoulli(p)$ ,其中$i=1,\cdots,n$ ,令 $\overline X = \frac{1}{n}\sum{i=1}^n X_i$ 试回答当$n$ 取多少时,使得
- 首先,我们要改变符号
- 同乘以n,得到:
- 展开
我们发现,式子左侧可以变成两个Chernoff 不等式
- 利用切诺夫不等式进行放缩
- 反解