文档数据库-索引
文档数据库的索引采用的数据结构是B树。关于B树的创建、删除在这里就不说了,仅说说索引的创建与使用。
索引一般不会自动创建,需要我们手动为一个属性创建索引。创建了索引之后,查询的速度会快很多
mongodb创建索引的方式是:db.myCollection.createIndex({"name":1})
但是我们没有必要给所有的属性都加上索引,因为索引的每一个节点都是一个页,非常占用空间。此外,我们要保持索引和表中的数据一致。因此,更新索引的时候会增加不小的开销
我们适合在什么样的属性上添加索引呢?有几种原则:
- 常用属性
- 不常被修改(稳定的属性)
- 索引要保证有效性。对一个有着名字、生日、性别属性的文档来说,把索引加在名字上式比较有效的。但是我们在性别上添加索引的话,不但不能提速,反而会变慢。因为性别的区分度很低,我们要找的数据是分散在各个地方的,每次对性别进行索引查找的代价甚至是不如直接扫描一遍文档来得快
有些时候我们会在不止一个属性上添加索引,这一部分我们放在关系数据库中去讨论

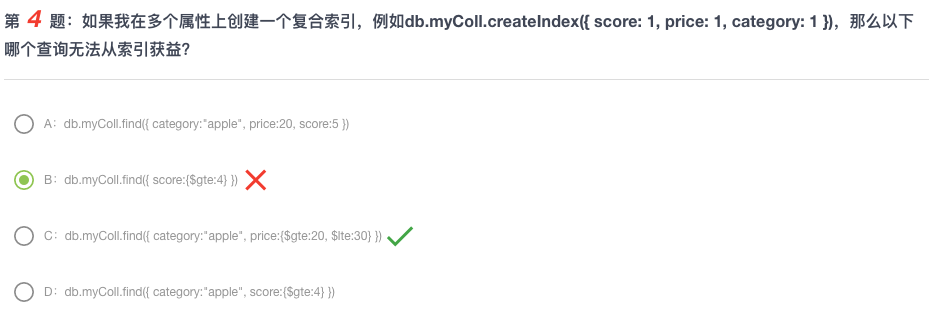
在这一题中,我们对 price进行了一个大于20而小于30的筛选,这使得筛选得到的数据是离散的分列的。效率并没有比不加索引的查询更快
例题
假设某文档数据库中有N个文档,被存放在硬盘的K个页中(N>K)。 我们要对这N个文档添加一个新的属性,导致K个页无法再容纳这K个文档。假设属性添加完毕后,需要J个页来容纳文档(N>J>K)。那么,相对高效的处理方式是:
A. 在硬盘上分配J个新页,然后对文档逐个进行修改,完成一个文档的修改就将它写到硬盘上的新页中,最后将K个旧页挥手
B. 在硬盘上分配 J 个新页,然后对文档逐个进行修改,修改后的文档先放入内存中的缓冲区,每当缓冲区满一页后将它写到硬盘上的新页中,最后将K个旧页回收
C. 对文档逐个进行修改,修改后的文档先全部放入内存中的缓冲区,修改完成后,将缓冲区的文档写入到 J 个新页中,最后将K个旧页回收
D.直接在 K 个旧页上进行修改,将溢出的文档放入内存中的缓冲区,修改完成后再将缓冲区的文档写入到 J-K 个新页中
答案是 : B
数据管理系统-文档数据库设计
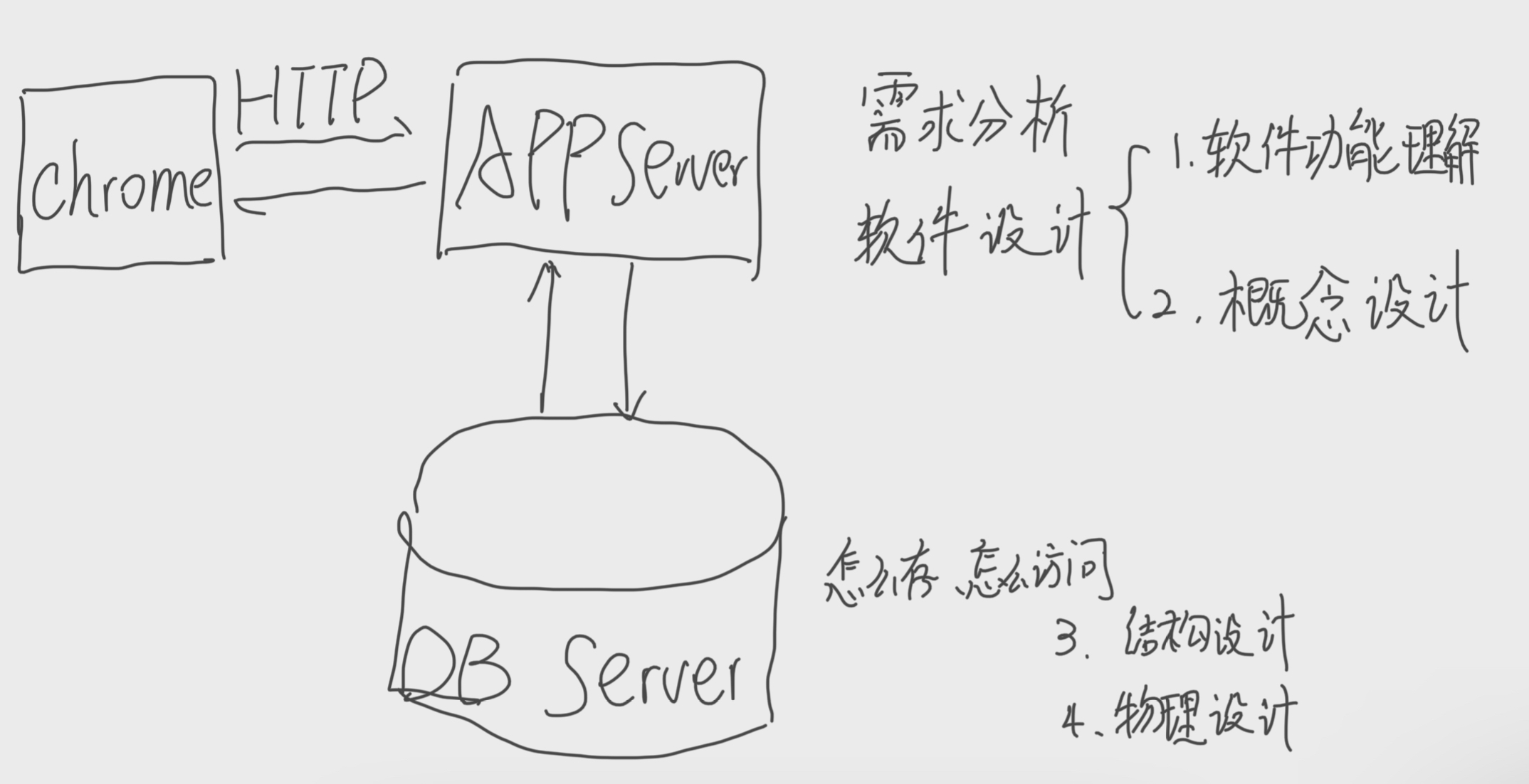
上面是设计一个数据库的基本流程
需求分析
我们用一个例子来考虑文档数据库的设计流程。首先,应该梳理出应用需要满足的功能。比如说博客应用
- 所有人都可以成为博客网站的博主
- 所有人都可以写文章发表
- 所有人都可以看我发布的文章
- 博主和博主之间有粉丝的概念
首先要设置一个界面,界面清晰了,功能就清晰了
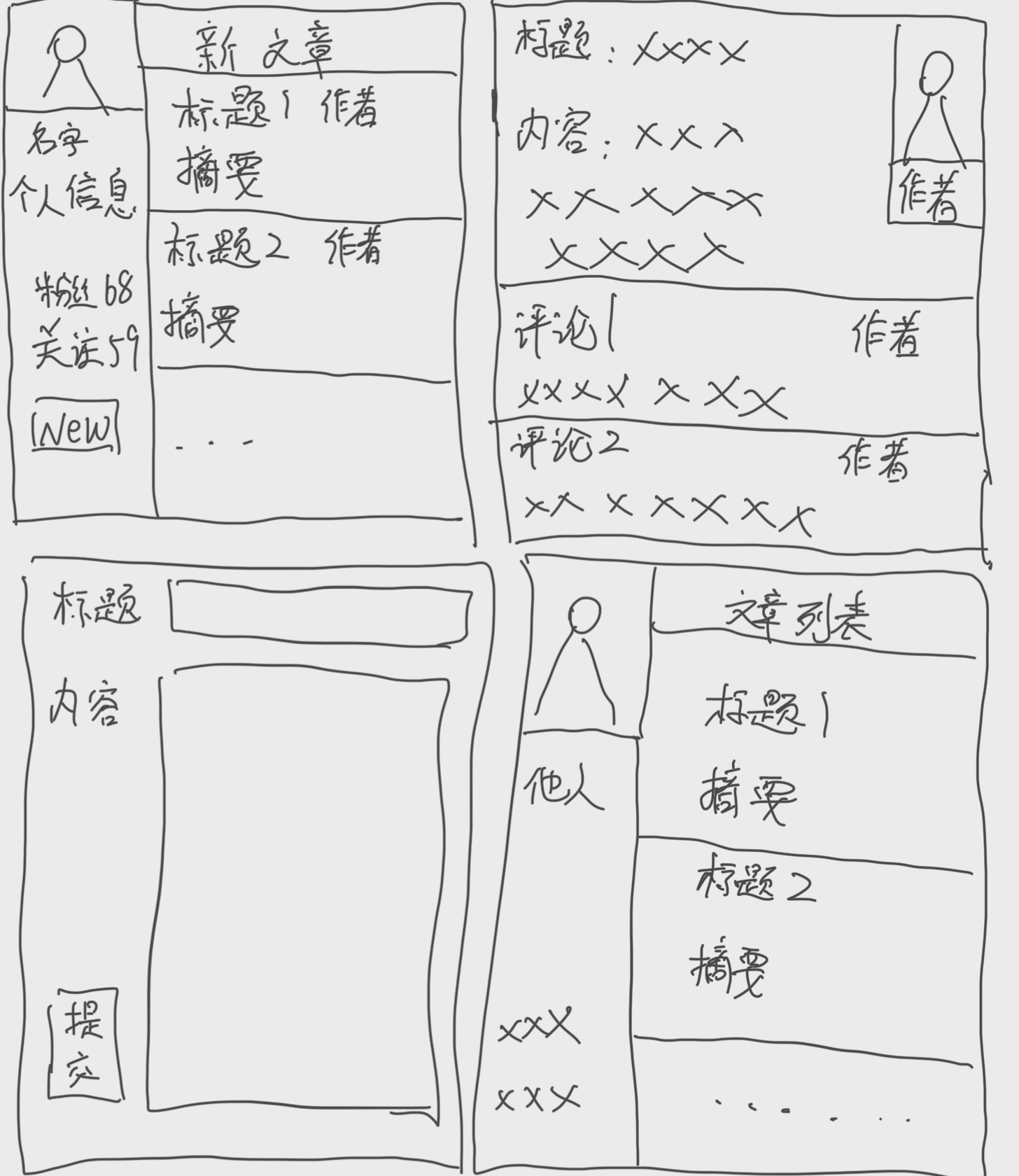
第一个界面是登陆后的个人信息,右侧是博主关注的人的新文章
第二个界面是点击某一篇文章后显示的信息,包括文章的评论
第三个界面是点击第一个界面中的 NEW 按钮显示的,是创建一篇新的博客文章
第四个界面是点击作者信息后显示出来的其他人的信息
概念设计
对于这个应用我们的需求已经比较清晰了。现在我们开始概念设计
首先要解决的问题是:存什么, 也就是要保存几类对象的信息。很显然,有用户、文章、评论。 其关系如下:
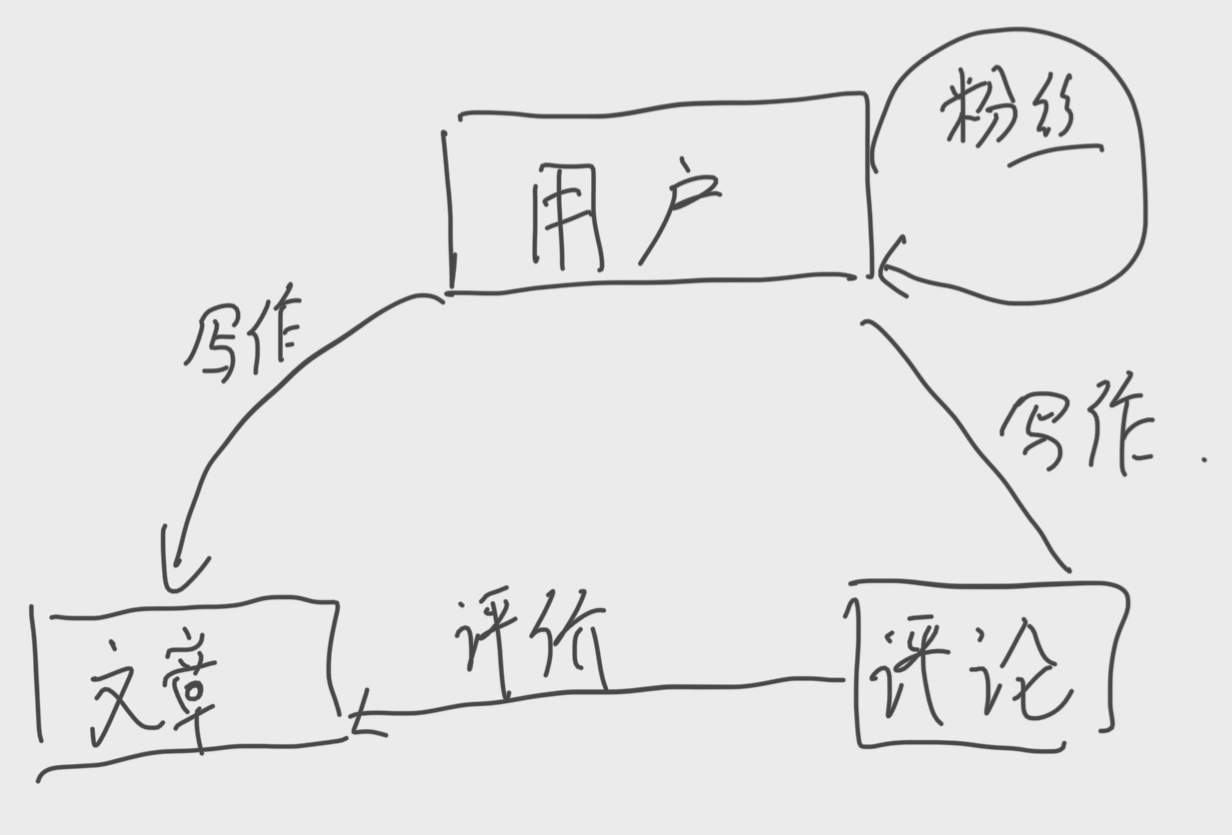
理清关系之后,我们来解决怎么存的问题, 我们有两种典型的方式。
方式1:将所有信息存放到一个文档集合

这个文档是关于用户的,包含了用户本身的信息、粉丝的信息、文章的信息
方式2:对于每个对象,用一个文档集合来存放:

不同文档结构设计的比较
上面我们用了两种方式来存放我们所需要的数据,那么那种方式更好呢?判断的标准是我们的应用如何访问数据库
首先,博主登录后看到的第一个页面,虽然可以很简单的获得个人信息,但是我们如果要获得用户关注的人所发的文章信息,会变得非常麻烦。因为我要扫描所有人的信息,找到其fans中ID与该用户相等的人的ID,并拿去找他发布的文章,其最终的结果是需要将整个文档集合扫描一遍,这个效率是很低的
如果是第二种方式,那么我们可以通过User文档来获得个人信息,我们可以扫描用户的fans的ID,去找到他们发布的文章。这样的代价低了很多
在这样一一比较之后,我们需要权衡利弊 来判断哪种方式是适合这个应用的。结果就是都不是太适合。下面我们给出一个较为适合的结构设计
结构设计

最终我们设计出来的文档数据结构如上图所示,我们发现我们在存储了基础必要的信息之后又加了不少冗余信息,包括在文档里面添加了作者的各种信息、在评论中也增加了作者的名字和ID等。这是一种用空间换时间的方法,我们通过存入冗余信息,让应用的每个页面能更快的获取到其所需要的信息
文档数据库设计方法
- 概念设计:对象以及对象之前的联系
- 结构设计:对象 <-> 文档;多个对象<——>文档(嵌入式)