神经网络和反向传播
损失函数和优化
在大多数机器学习模型中,都会有一个损失函数(lost function)。比如常见的MSE:
损失函数用来衡量机器学习模型的精确度。一般来说,损失函数的值越小,模型的精确度就越高。如果要提高机器学习模型的精确度,就需要尽可能降低损失函数的值。而降低损失函数的值,我们一般采用梯度下降这个方法。所以,梯度下降的目的,就是为了最小化损失函数。
梯度下降的原理
寻找损失函数的最低点,就像我们在山谷里行走,希望找到山谷里最低的地方。那么如何寻找损失函数的最低点呢?在这里,我们使用了微积分里导数,通过求出函数导数的值,从而找到函数下降的方向或者是最低点(极值点)。
损失函数里一般有两种参数,一种是控制输入信号量的权重(Weight, 简称 $w$ ),另一种是调整函数与真实值距离的偏差(Bias,简称 $b$ )。我们所要做的工作,就是通过梯度下降方法,不断地调整权重$w$和偏差$b$,使得损失函数的值变得越来越小。
假设某个损失函数里,模型损失值 $L$与权重 $w$ 下图这样的关系。实际模型里,可能会有多个权重$w$,这里为了简单起见,举只有一个权重$w$的例子。权重$w$目前的位置是在A点。此时如果求出A点的梯度 $\frac{dL}{dw}$ ,便可以知道如果我们向右移动,可以使损失函数的值变得更小。
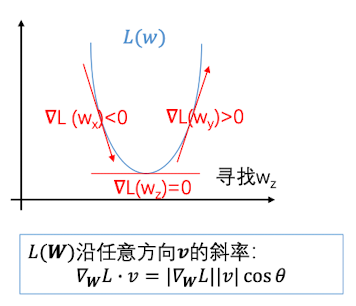
用数学语言来解释一下:假设只有一个参数w
- 那么导数$\frac{dL(w)}{dw}=\lim\limits_{h\rightarrow0}\frac{L(w+h)-L(w)}{h}$ 就代表L在w的切线斜率,即$L(w)$在该店的变化速率和方向。那么,只要导数不为0,我们往反方向微调就可以减小$L(w)$
当有多维情况下,会有多个权重,此时$\boldsymbol W$ 为向量
- 那么偏导数$[\frac{\partial L(\boldsymbol W)}{\partial w1},\frac{\partial L(\boldsymbol W)}{\partial w_2},\cdots,\frac{\partial L(\boldsymbol W)}{\partial w_n}]$ 代表L在$\boldsymbol W$ 处沿每个维度的变化速率和方向,称为梯度和(gradient),记为$\nabla{\boldsymbol W}L$ 或$grad(L(\boldsymbol W))$ 。这个时候,我们需要把各个样本数据的权重梯度加起来,并求出它们的平均值,用这个平均值来作为样本整体的权重梯度。
- $\nabla{\boldsymbol W}L$ 和方向向量$\boldsymbol v$ 的点积即为该方向的斜率(方向导数),公式为$\nabla{\boldsymbol W}L\cdot v=|\nabla{\boldsymbol W}L||v|\cos\theta$。当$cos(\theta)=1$ 的时候达到最大值。因此,负梯度 $-\nabla{\boldsymbol W}L$ 的方向即为 L 在$\boldsymbol W$处下降最快的方向, 沿$-\nabla_{\boldsymbol W}L$方向微调就可以快速减小$L(\boldsymbol W)$(即梯度下降)
- 梯度下降的公式为: $W{\text{new}} = W-\lambda\nabla{\boldsymbol W}L$ ,其中$\lambda$是超参数,其含义就是学习率(Learning Rate)或者步长(Step size)
如果学习率$\lambda$设置得过大,有可能我们会错过损失函数的最小值;如果设置得过小,可能我们要迭代式子(2)非常多次才能找到最小值,会耗费较多的时间。因此,在实际应用中,我们需要为学习率设$\lambda$置一个合适的值。
梯度下降的过程
我们把上面的内容稍微整理一下,可以得到梯度下降的整体过程:
- for i = 0 to 训练数据的个数:
(1) 计算第 i 个训练数据的权重 $w$ 和偏差 $b$ 相对于损失函数的梯度。于是我们最终会得到每一个训练数据的权重和偏差的梯度值。
(2) 计算所有训练数据权重 $w$ 的梯度的总和。
(3) 计算所有训练数据偏差 $b$ 的梯度的总和。
- 做完上面的计算之后,我们开始执行下面的计算:
(1) 使用上面第(2)、(3)步所得到的结果,计算所有样本的权重和偏差的梯度的平均值。
(2) 使用下面的式子,更新每个样本的权重值和偏差值。
1 | def train(X, y, W, B, alpha, max_iters): |
其他常见的梯度下降算法
上面介绍的梯度下降算法里,在迭代每一次梯度下降的过程中,都对所有样本数据的梯度进行计算。虽然最终得到的梯度下降的方向较为准确,但是运算会耗费过长的时间。于是人们在上面这个算法的基础上对样本梯度的运算过程进行了改进,得到了下面这两种也较为常见的算法:
小批量样本梯度下降(Mini Batch GD)
这个算法在每次梯度下降的过程中,只选取一部分的样本数据进行计算梯度,比如整体样本1/100的数据。在数据量较大的项目中,可以明显地减少梯度计算的时间。
随机梯度下降(Stochastic GD)
随机梯度下降算法只随机抽取一个样本进行梯度计算,由于每次梯度下降迭代只计算一个样本的梯度,因此运算时间比小批量样本梯度下降算法还要少很多,但由于训练的数据量太小(只有一个),因此下降路径很容易受到训练数据自身噪音的影响,看起来就像醉汉走路一样,变得歪歪斜斜的。
GD的优势:每次迭代loss下降快
GD的劣势:一次迭代需要遍历所有数据,并且容易陷入local minima(局部极小值)
SGD的优势:迭代更新速度快,并且往往因为minibatch含有噪声而避开local minima
SGD的劣势:每次迭代,loss下降较慢
由于数据量较大,训练深度神经网络基本使用SGD,以及其他性能更加的优化方法
神经网络
我们在人工神经网络 这篇博客里面感性的认识了一下神经网络的架构,现在我们回顾并从数学角度重新学习一遍。
我们学过很多线性分类器,但是有很多非线性的分类情况我们是很难用线性分类器来解决的:
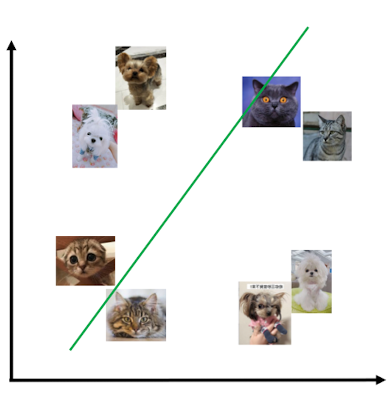
比如这种分类,我们只能够通过增加高阶多项事项来让分类器可行。那么当输入变量有n个的时候,最多会导致$O(n^n)$级别的参数,显然是不可行的。
单层神经网络
因此我们需要用到神经网络.我们从最简单的神经网络看起:
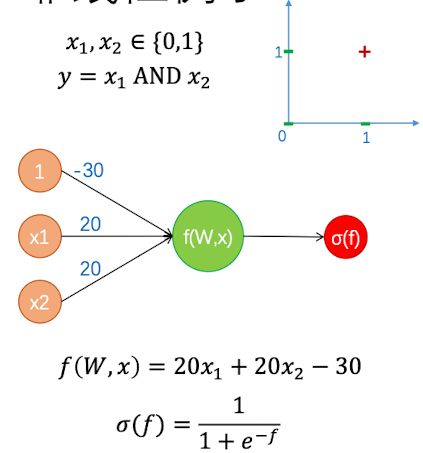
在上面这个神经网络中,每条边都有一个权重,即$w_i$, 然后让权重和输入值相乘,就得到了$f(W,x)$ .这里$\boldsymbol W =[-30,20,20]$,对应一个偏置项(神经网络都需要的一个常数)和两个输入变量。我们用一层神经网络搭配Sigmoid激活函数可以模拟出 $y=x_1 \&~x_2$的情况。
到这一步,神经网络还是线性的,那么就需要一个非线性的激活函数来打破这个线性。这里我们选择的是Sigmoid激活函数
我们可以给输入值和输出值做一个表格:
| x1 | x2 | $\sigma(f(W,x))$ |
|---|---|---|
| 0 | 0 | $\sigma(-30)\approx0$ |
| 0 | 1 | $\sigma(-10)\approx 0$ |
| 1 | 0 | $\sigma(-10)\approx 0$ |
| 1 | 1 | $\sigma(10)\approx 1$ |
同理,我们可以通过修改权重,使得这个神经网络可以模拟$y=x_1|x_2$ 的情况,如下图所示:
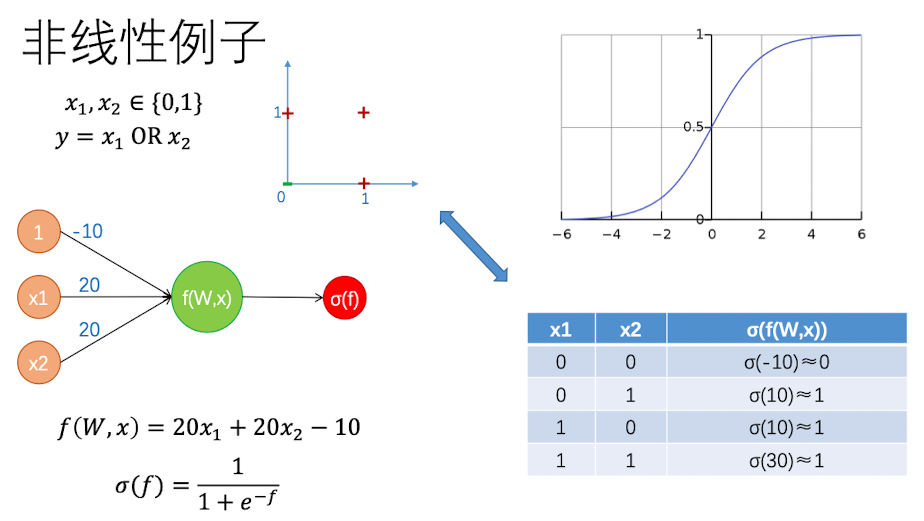
最早使用的激活函数就是 Sigmoid, 但是后来发现Sigmoid函数存在一些缺点,因此后来的神经网络大多使用tanh或者ReLU,我们在神经网络的训练那节会细讲。
进而我们可以设立多层的神经网络,将输出值当做下一层的输入值,再激活,再输入。以此来实现一个复杂的高维空间的模型。当神经网络的层数变多的时候,中间的几层就像是被“隐藏”起来了一样,因此我们称其为hidden layer(隐藏层)
hidden layer
在正常情况下,hidden layer肯定不止一个神经元,因为需要不同的神经元来捕捉不同的特征
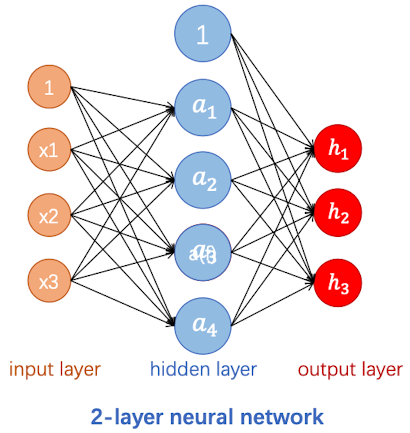
比如说上面这个两层的神经网络:输入层有三个变量,一个偏置项;隐藏层有四个神经元和一个偏置项。
那么我们可以得到hidden layer的计算公式:
用矩阵的思路来说,就是
现在,hidden layer的输出结果变成了output layer 的输入结果,此时output layer一共有3个神经元,计算公式如下:(注意,这里的上标不代表平方而代表该权重位于第二层)
矩阵思路
如果我们先不考虑偏置项,但考虑输入和输出,我们从矩阵的思路来理解一下每个层数的计算。
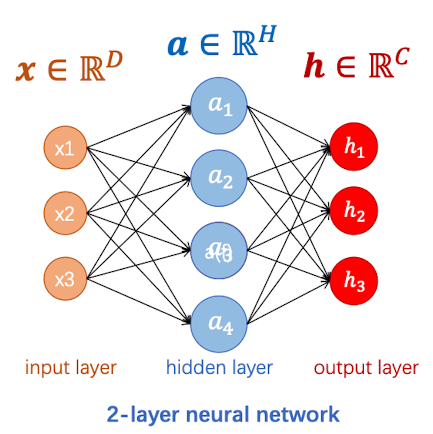
那么,对于hidden layer来说,其权重矩阵的大小就是$H$行$D$列:
对于output layer来说,其权重矩阵的大小就是$C$行$H$列:
那么,如果是三层神经网络呢?
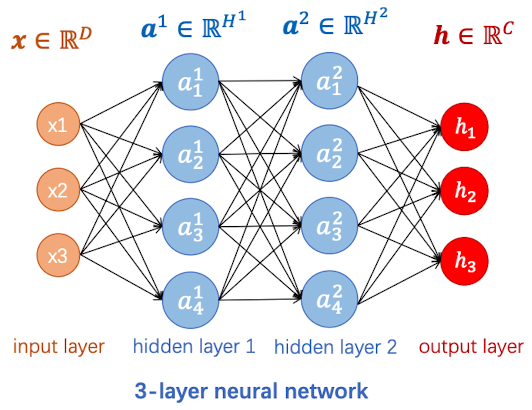
此时,对于第一层隐藏层,$\boldsymbol{W^1} \in \mathbb R^{H_1\times D}$
对于第二层隐藏层,$\boldsymbol{W^2} \in \mathbb R^{H_2\times H_1}$
对于第三层输出层,$\boldsymbol W^3\in \mathbb R^{C\times H^2}$
用代码来表示,如下:
1 | f = lambda x: 1.0/(1.0+np.exp(-x)) # activation function(use sigmoid) |
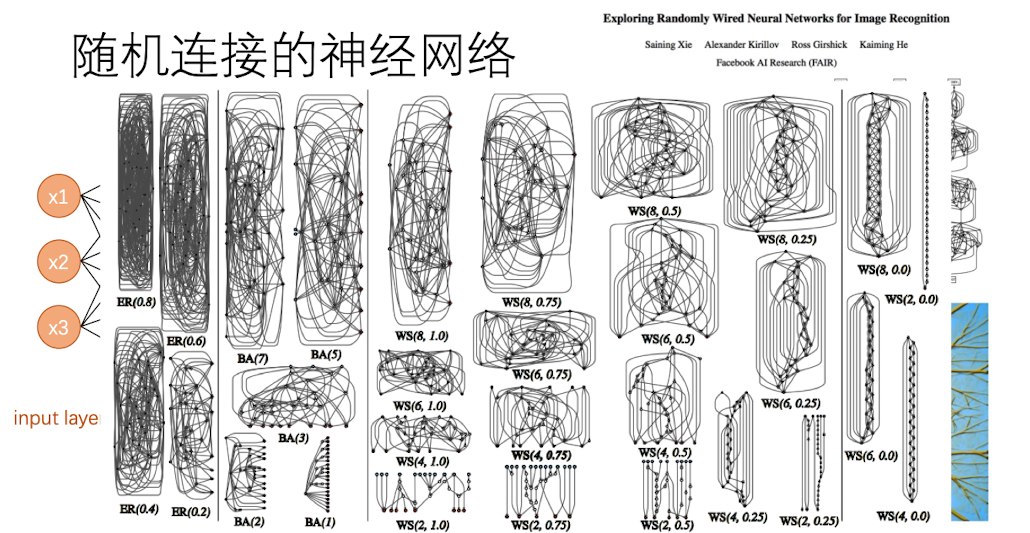
随机连接的神经网络
事实上,神经网络之间是可以随机连接的,并不需要像我们上面介绍的那样全连接,如下图所示:
两层神经网络
上面引入了多层神经网络的概念,那么用简单的两层神经网络可以解决什么问题呢?表示 异或 关系,如下图所示:
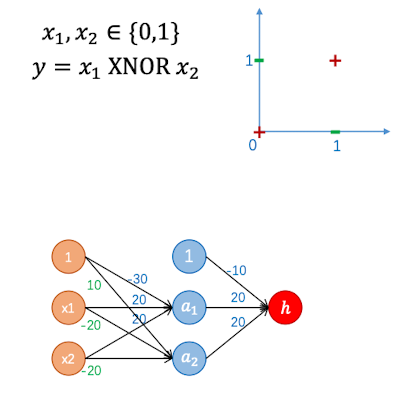
同样用Sigmoid做激活函数,可以得到如下表格:
| x1 | x2 | a1 | a2 | h |
|---|---|---|---|---|
| 0 | 0 | $\sigma(-30)\approx0$ | $\sigma(10)\approx1$ | $\sigma(10)\approx1$ |
| 0 | 1 | $\sigma(-10)\approx0$ | $\sigma(-10)\approx0$ | $\sigma(-10)\approx0$ |
| 1 | 0 | $\sigma(-10)\approx0$ | $\sigma(-10)\approx0$ | $\sigma(-10)\approx0$ |
| 1 | 1 | $\sigma(10)\approx1$ | $\sigma(-30)\approx0$ | $\sigma(10)\approx1$ |
神经网络的计算
现在我们来看看一个神经网络是如何被计算的
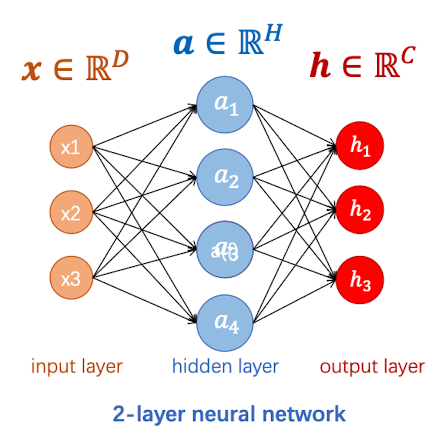
对于这个神经网络,我们训练集是:$(xi,y_i){i=1}^N$ ,其中$x_i$是向量,$y_i$是标签。激活函数式ReLU
- 第一步,我们计算 $f(x;\boldsymbol W^1)$ ,然后输入到ReLU中去激活得到 $\boldsymbol a$
- 接着我们把$\boldsymbol a$ 和 $\boldsymbol W^2$ 计算得到 $\boldsymbol s = f(\boldsymbol a,\boldsymbol W^2)$
- 用Softmax 来计算 $hk = \frac{e^{s_k}}{\sum{j}e^{s_j}}$ 得到输出值
- 计算损失函数,其组成为softmax的损失函数加上第一层、第二层权重的正则项 $L = \frac{1}{N} \sum_{i=1}^Nl(\boldsymbol h_i,y_i)+\lambda R(\boldsymbol W^1)+\lambda R(\boldsymbol W^2)$
- 优化损失函数:计算解析梯度 $\frac{\partial L}{\partial \boldsymbol W^1},\frac{\partial L}{\partial \boldsymbol W^2}$ ,可以通过数值梯度去计算,得到$\nabla{\boldsymbol W}L = \nabla{\boldsymbol W}[\frac{1}{N}\sum_{i=1}^N(l(\boldsymbol h_i,y_i)+\lambda R(\boldsymbol W^1)+\lambda R(\boldsymbol W^2))]$
这边只有两层,我们就发现解析梯度是如此的难求,那么如果神经网络的梯度再往上加的话,对计算机来说计算梯度是很复杂的一件事,因此,我们就需要反向传播这个技巧了
反向传播
我们在高数里面,已经学会了链式法则。那么,在计算梯度的时候,我们也可以用这套法则来较为方便得计算出权重的梯度。
比如说,我们得到了损失函数 $L$, 根据公式: $\frac{\partial L}{\partial \boldsymbol W^2} = \frac{\partial L}{\partial\boldsymbol h}\frac{\partial \boldsymbol h}{\partial \boldsymbol W^2}$, 我们可以先求出L关于$\boldsymbol h$的导数,然后再去求$h$关于$\boldsymbol W^2$的导数。
如果我们想计算$\frac{\partial L}{\partial \boldsymbol W^1}$ ,那么我们就在再向前推一层,根据公式:$\frac{\partial L}{\partial \boldsymbol W^1} = \frac{\partial L}{\partial\boldsymbol h}\frac{\partial \boldsymbol h}{\partial \boldsymbol a}\frac{\partial \boldsymbol a}{\partial\boldsymbol W^1}$ 。
可以看到,反向传播的原理就是每一层的输出对这一层的输入求一个梯度,也就是按照从右往左的顺序来求梯度。
具体例子
我们把某个神经网络的计算图画出来。计算图可以看做是一个可视化的神经网络,把每一步的计算都用一个结构来表示,有了计算图就可以以很清晰的思路来编写代码了
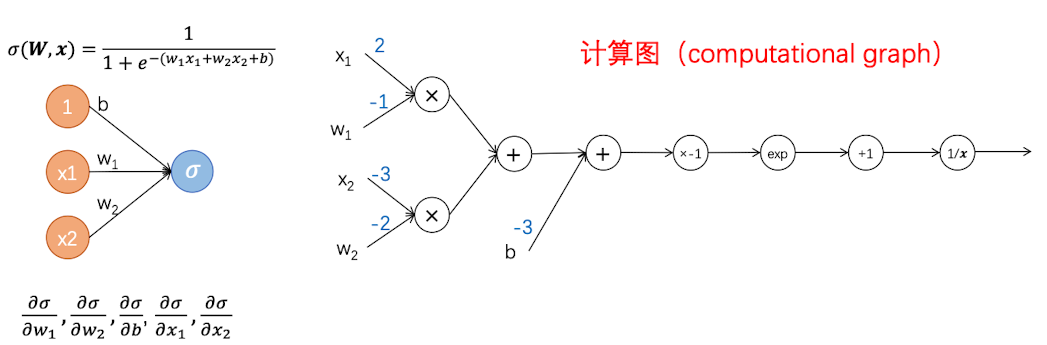
前向传播1
上面是$x_1,w_1,x_2,w_2,b$ 的初始值,根据这些初始值,我们可以前向计算来得到每个节点的输出值:
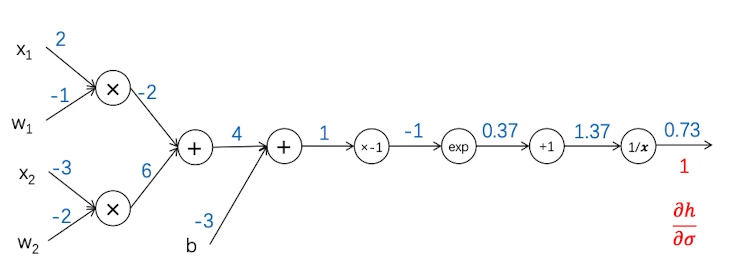
反向传播1
接下来,我们要反向传播,从最后一步向前计算,首先我们假设这已经到了最后一层,因此最后一层的梯度就定为$\frac{\partial h}{\partial \sigma}=1$。然后我们从最后一层开始计算倒数第二层的梯度
对于倒数第二层,我们要知道链式法则:$\frac{\partial h}{\partial x} = \frac{\partial h}{\partial \sigma}\frac{\partial \sigma}{\partial x}$
现在已知上游梯度 $\frac{\partial h}{\partial \sigma}=1$, 只要计算这层局部梯度,再把这层的输入值带入即可求得。因为$f(x) = \frac{1}{x}$ 所以 $\frac{df}{dx} = -\frac{1}{x^2}$ ,再把这层的输入值1.37带入,得到:$\frac{\partial h}{\partial x} = 1\times(-1/1.37^2)=-0.53$
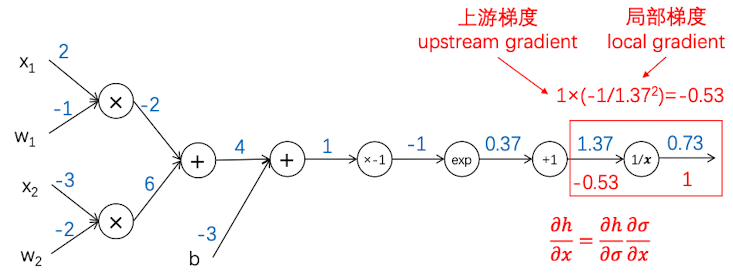
反向传播2
现在,我们已经计算得到了两层梯度,继续向前推进。现在,$f(x) = x+1$,因此局部梯度 $\frac{df}{dx} = 1$, 输入值为0.37。但是这层得到的梯度和输入值无关,因此这层反向传播得到的值为$-0.53\times 1 = -0.53$
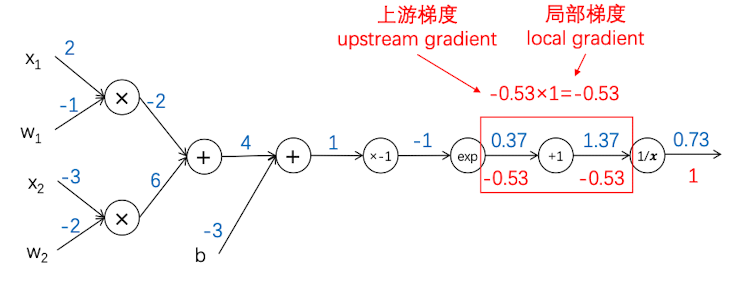
反向传播3
再向前推, 现在$f(x) = e^x$, 上游梯度为-0.53, 局部梯度为 $\frac{df}{dx} =e^x$, 输入值为-1。这层反向传播得到的值为 $-0.53\times e^{-1}=-0.2$
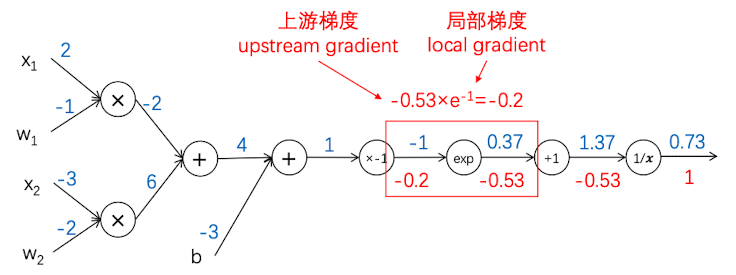
反向传播4
现在$f(x) = x-1$ ,局部梯度为 $-1$ ,和输入值无关,上游梯度为-0.2。 这层反向传播得到的值为:$-0.2\times -1=0.2$
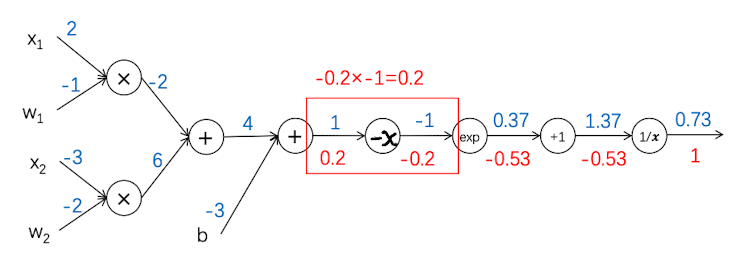
反向传播5
到这一部分,神经网络开始分叉了,在这里 $f(x)$ 为两个输入值的和。我们分别把每个输入值都当做主元,那么对于b,上游梯度为0.2, 局部梯度为$\frac{df}{dx} = 1$ ,与输入值无关,因此反向传播得到的值为0.2
对于另外一个神经元,同理,与输入值无关,反向传播得到的值为0.2
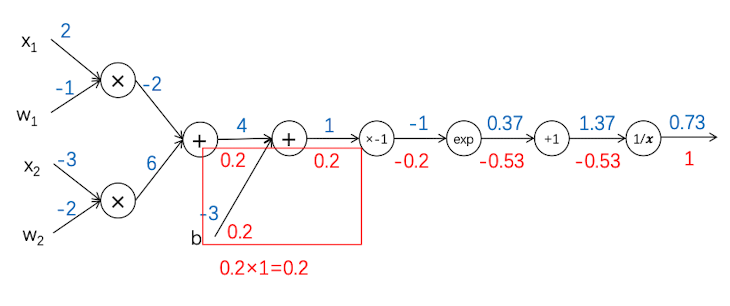
反向传播6
在这一层神经网络又分叉了,但这层还是两个输入值相加, 和上一层是一样的,因此都是0.2
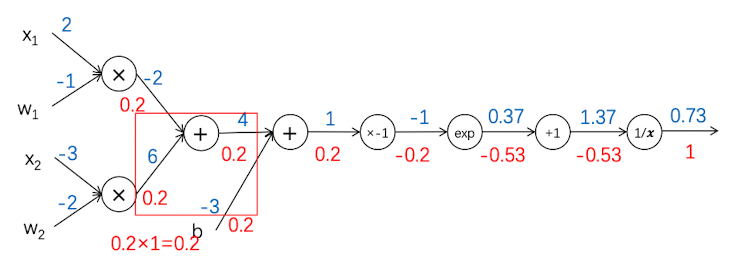
反向传播7
在这一层,我们先来看上面的分叉。$f(x)$为两个输入值的乘积,当我们把$x_1$当做主元的时候,$f(x) = -x$, 因此 $\frac{df}{dx_1}=-1$, 与输入值无关,上游梯度为0.2,因此反向传播得到的值为$0.2\times -1 =-0.2$
当把 $w_1$看做主元的时候,$f(x)= 2x,\frac{df}{dw_1} = 2$,与输入值无关,上游梯度的值为0.2. 因此反向传播得到的值为 $0.2\times 2 = 0.4$
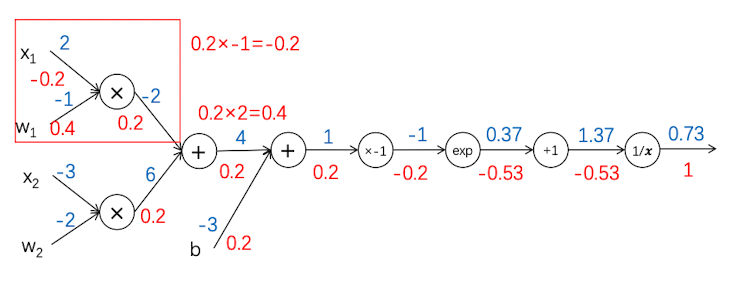
反向传播8
现在来看下层的分叉。同样是输入值的乘积。
当我们把$x_2$当做主元的时候,$f(x) = -2x$, 因此 $\frac{df}{dx_2}=-2$, 与输入值无关,上游梯度为0.2,因此反向传播得到的值为$0.2\times -2=-0.4$
当把 $w_2$看做主元的时候,$f(x)= -3x,\frac{df}{dw_2} = 3$,与输入值无关,上游梯度的值为0.2. 因此反向传播得到的值为 $0.2\times -3 = -0.6$
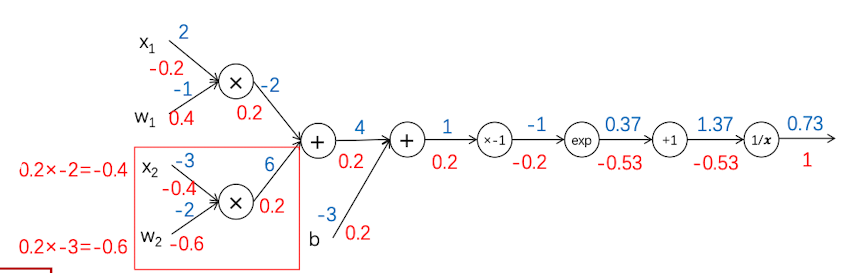
分块计算图
细心地同学可能已经发现了,在正向传播的时候, 导数第1、2、3、4步合起来刚好是一个 $\frac{1}{1+e^{-x}}$ 的函数,也就是我们选择的Sigmoid激活函数。事实上,Sigmoid有自己的梯度形式,因此可以把计算图简单化。
这样,只要求 Sigmoid的本地梯度就可以了,相当于多步并一步:
这样一来,上游梯度就是1,输入值$x=1$, $\sigma(x)=0.73$, 局部梯度如上所示,反向传播得到的结果是:
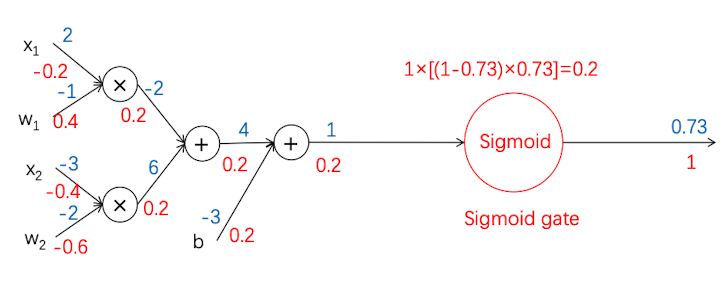
同样的,我们可以把前面的神经元也合并成一块,用线性函数$ y=w_1x_1+w_2x_2+b$ 来表示
这样,对于 $w_i,x_i$的导数,我们可以用链式法则来求得:
比如,对于$y=-x_1-2x_2-3$ ,上游梯度为0.2
如下图所示:
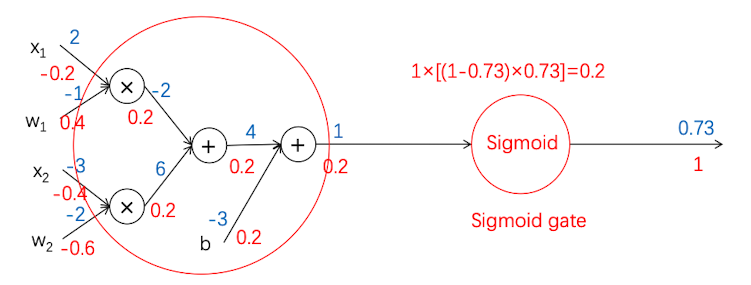
根据这个计算图,我们可以很有条理地写出代码:
1 | def f(w1,w2,w3,w4): |
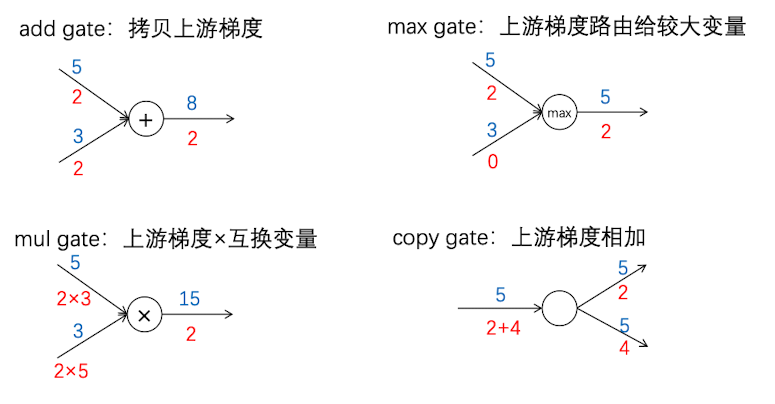
梯度流的常见模式
反向传播的矩阵运算
前面我们都是计算标量,但事实上每一层都有很多神经元,因此,在真正运算的时候,都是矩阵运算。
前向运算
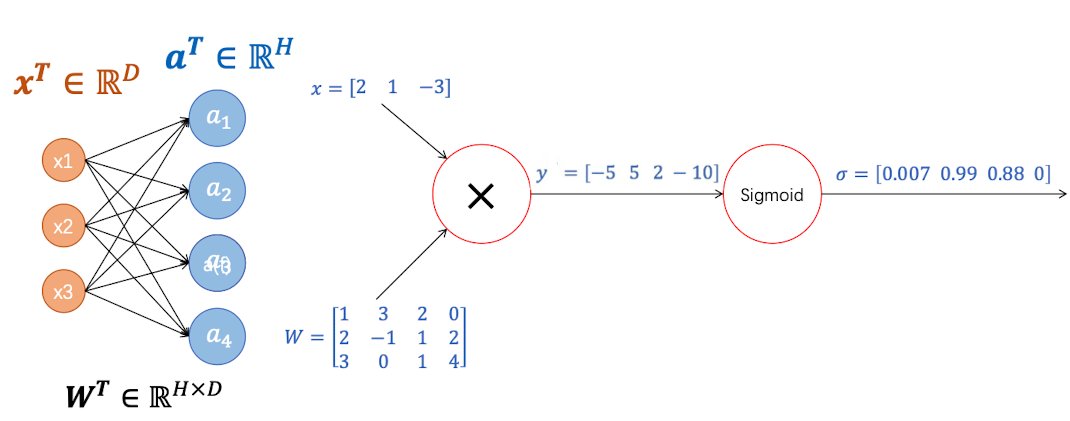
我们假设输入的x是D维的横向向量,隐藏层有H个,因此权重矩阵 $W\in\mathbb R^{D\times H}$
输入乘以权重矩阵后,矩阵的形状为 $(1,H)$ , 如下图所示
然后对每个元素进行Sigmoid激活,得到$\boldsymbol\sigma$
反向运算-输入向量
每一层计算得到的梯度矩阵的形状和这一层的输入的矩阵形状是一样的。我们首先假设在sigmoid这层反向计算得到的梯度为:$\frac{\partial h}{\partial \sigma} = [4,1,2,-1]$
反向传播1
现在,我们来计算y这层的局部梯度: $\frac{\partial\sigma}{\partial y}$
我们知道,矩阵对矩阵求导,需要$\sigma$矩阵中的每一个元素对$y$矩阵中的每一个元素求导,也就是Jacobian Matrix:
也就是说,当隐藏层矩阵的形状为$(1,H)$的时候,$\frac{\partial \sigma}{\partial y}\in \mathbb R^{H\times H}$, 显然这是很复杂的计算,当$H=4096$的时候,我们甚至需要16M的内存来储存这个Jacobian矩阵
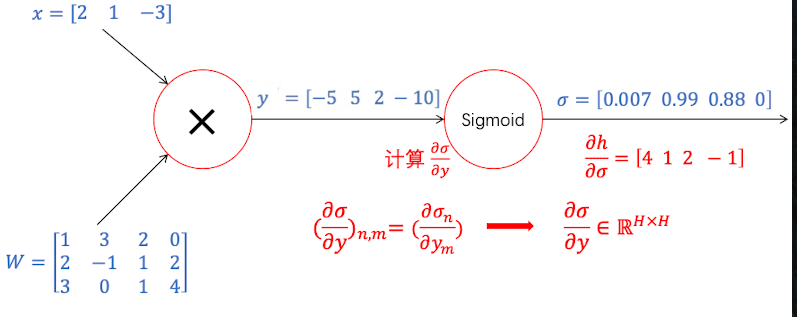
事实上,我们根本不需要实现 Jacobian Matirx。 因为我们发现
说明$y_i$只影响$\sigma_i$, 因此只需要保留对角线上的元素即可,如下图所示:
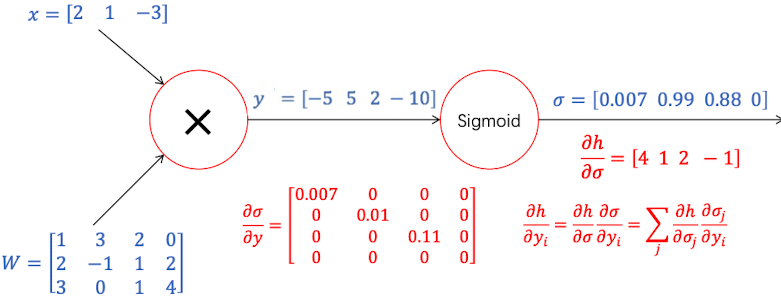
因此,我们可以求出这一层的梯度,也就是两个梯度对应元素相乘后累加:
因此,我们只要固定i,然后求一个pairwise的梯度计算,得到局部梯度;再乘以上游梯度,就可以得到这一层的梯度
反向传播2
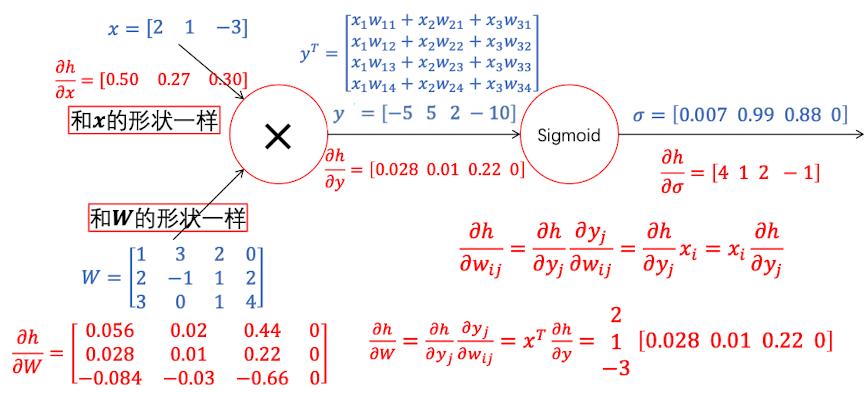
现在,我们要把y这层的梯度往前传,求出$(\frac{\partial y}{\partial x})_{n,m}=(\frac{\partial y_n}{\partial x_m})\Rightarrow\frac{\partial y}{\partial x}\in\mathbb R^{H\times D}$
我们发现,$R^{H\times D}$其实和 $\boldsymbol W^T$ 的形状是一样的. 为什么呢?我们看一下 $y^T$是如何被计算得到的就豁然明了了
那么,如果y对x求偏导的话,得到的雅克比矩阵就是:
也就是说:
$\frac{\partial h}{\partial x}$ 的形状和$\boldsymbol x$ 的形状是一样的
反向传播3
现在来看$\boldsymbol W$这层的梯度,我们首先列出公式
虽然$\boldsymbol W$是矩阵,按照雅克比行列式来计算的话,需要每个$yj$对这行中每一个元素$w{ij}$求偏导,这太麻烦了。我们还是一对一对求就好,因为$w_{ij}$只影响 $y_j$ ,因此,上式可以简化为:
那么,因为 $\boldsymbol W$ 有三行,对每一行进行如上计算,就会得到一个 $3\times 4$ 的矩阵,即
发现这和$\boldsymbol W$的形状也是一样的
反向传播4
上面因为简化,我们没有加入偏置项b,现在我们加上试试:
此时,要求偏置项的梯度,我们可以列出公示:
因为这里y关于b的导数始终是1,最后得到的关于b的梯度也是一个数
反向运算-minibatch
上面,我们输入的只是个向量,即输入一个样本,因此计算起来还是效率不够高。因此我们可以采用minibatch的方法,输入一个矩阵来计算
反向传播1
当输入变成一个矩阵的时候,发现$y{ij}$仍然只会影响$\sigma{ij}$,因此我们可以一对一计算,如下

反向传播2
和只输入向量一样,$x_{ij}$只会影响y的第i行,因此

反向传播3
$w_{ij}$只会影响y的第j列,因此:

反向传播4
在输入为向量的情况下,b只是个数,但当输入为一个矩阵的时候,偏置项b就变成了N维的向量。$b\in\mathbb R^N$
此时,要求偏置项的梯度,就是
令b原式的形状是 $(M,)$ 上游梯度的形状为$(N\times M)$ ,那么相当于是对上游梯度每一列求和,最后得到形状为$(M,)$的梯度
多层神经网络反向传播
从上面的神经网络,我们可以推广到当神经网络有很多层的时候,可以这样来求各层的权重:
注意,不要忘记每一层的偏执权重b,以及正则项