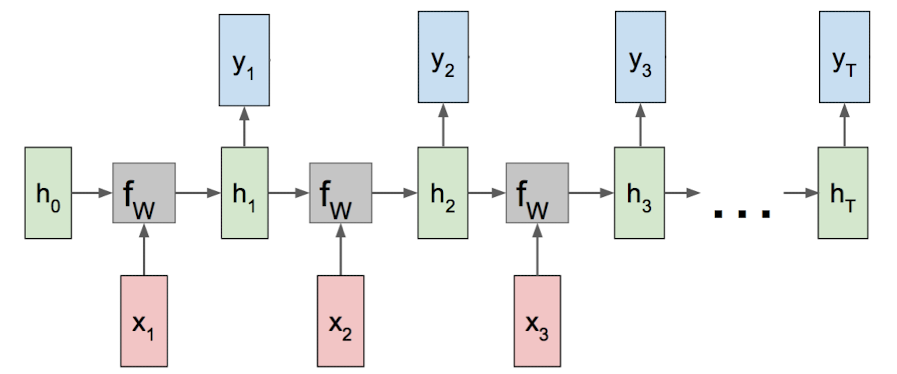
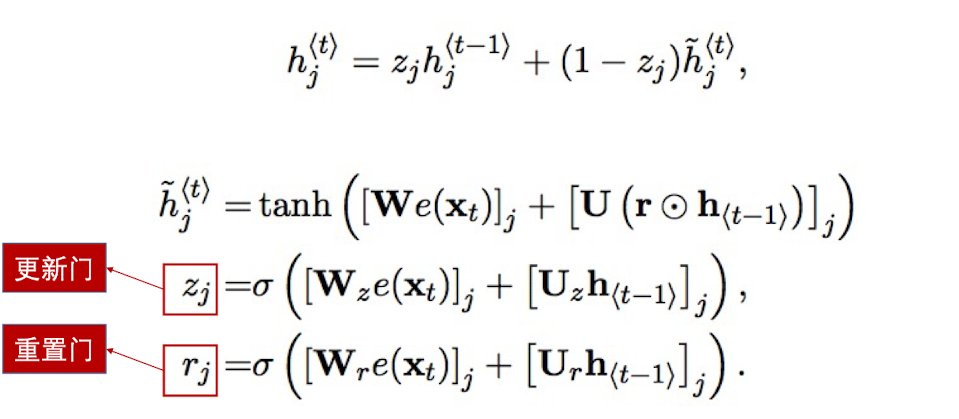循环神经网络
循环神经网络和卷积神经网络处理的数据类型是不一样的。卷积神经网络可是用来处理矩阵类型的数据,而生活中有很多数据是序列型的,且没有固定的长度、大小。因此CNN并不是非常适合用来处理这些数据。
因此我们提出了 RNN (Recurrent Neural Networks),其想法就是,采用重复的结构单元,每次输入序列里的一个数据,后面的结构单元能够记忆前面的输入信息。
RNN的结构
一对一
现在我们来看看一个简单的循环神经网络,它由输入层、隐藏层和输出层组成
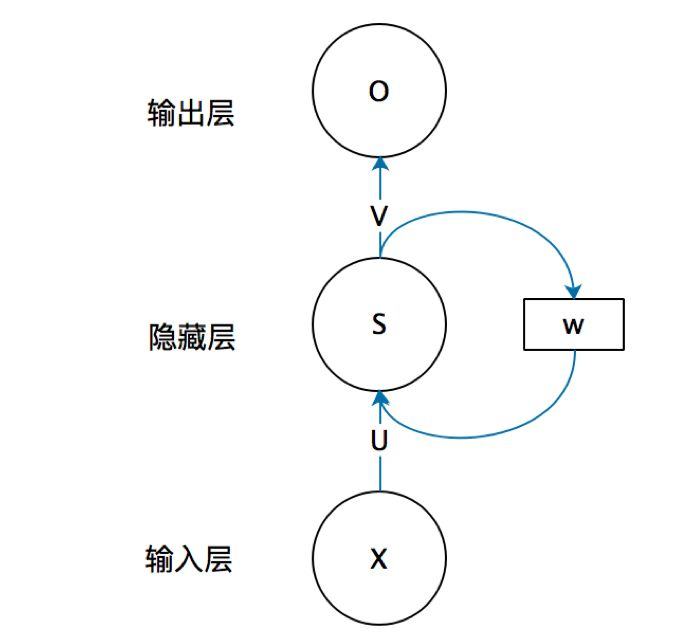
我们现在这样来理解,如果把上面有W的那个带箭头的圈去掉,它就变成了最普通的全连接神经网络。x是一个向量,它表示输入层的值(这里面没有画出来表示神经元节点的圆圈);s是一个向量,它表示隐藏层的值(这里隐藏层面画了一个节点,你也可以想象这一层其实是多个节点,节点数与向量s的维度相同);
U是输入层到隐藏层的权重矩阵,o也是一个向量,它表示输出层的值;V是隐藏层到输出层的权重矩阵。
那么,现在我们来看看W是什么。循环神经网络的隐藏层的值s不仅仅取决于当前这次的输入x,还取决于上一次隐藏层的值s。权重矩阵 W就是隐藏层上一次的值作为这一次的输入的权重。
如果我们把上面的图展开,循环神经网络也可以画成下面这个样子:
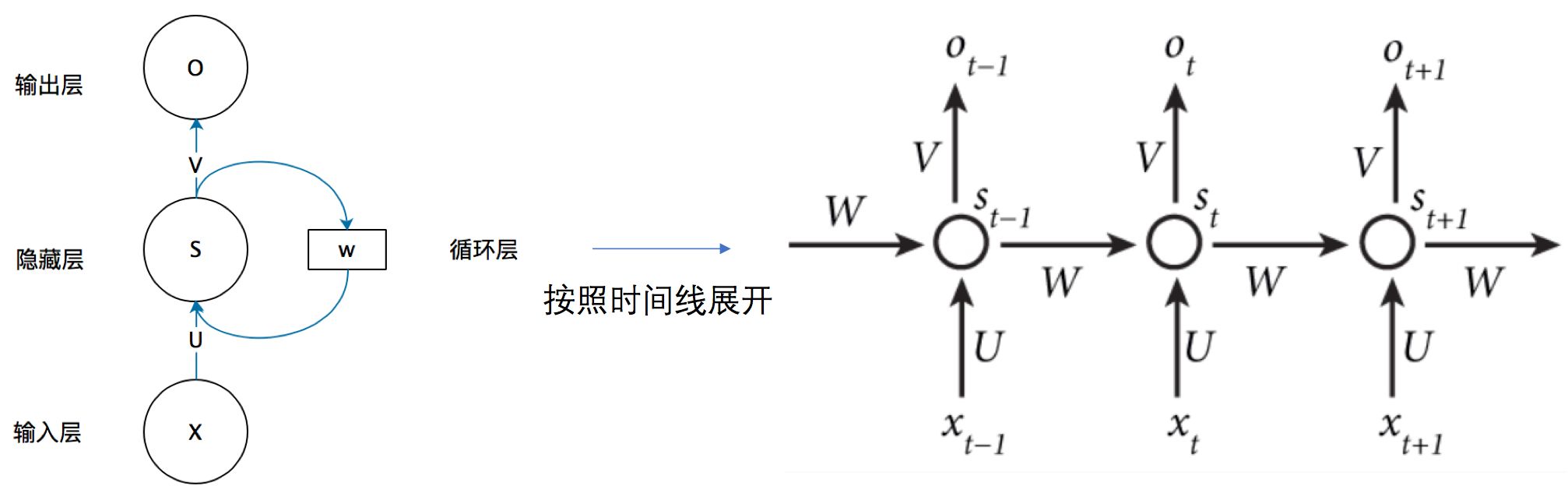
现在看上去就比较清楚了,这个网络在t时刻接收到输入 $xt$ 之后,隐藏层的值是 $s_t $,输出值是$o_t$。关键一点是,$s_t $的值不仅仅取决于$x_t$,还取决于$s{t-1}$。我们可以用下面的公式来表示循环神经网络的计算方法:
如果我们把式2反复带入式1,可得到:
其中,最简单的$f(x)$是线性变换加激活,比如说 $f(x) = \tanh(U\cdot Xt+W\cdot S{t-1})$
因此我们说,隐藏层包含了过去的历史信息,用来预测下一时刻的目标
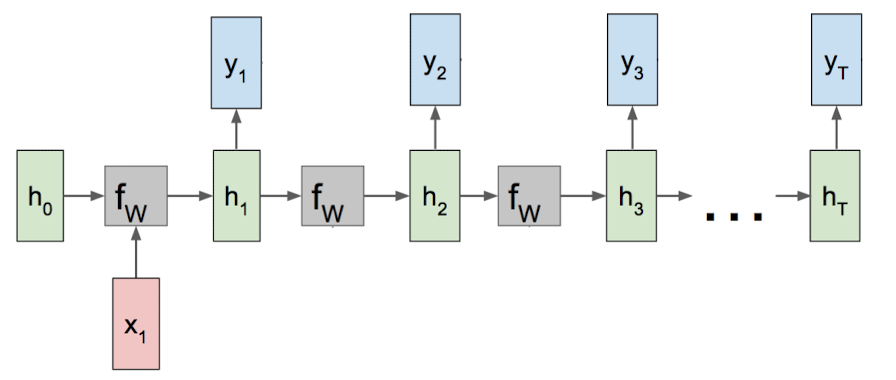
多对多
在进行文本改写等情况下,可能会用到
多对一
比如说,在情感分类的时候,输入可能是一个句子,输出代表这个情感的类型或者情感的等级。那么这就是多对一的情况
又比如说,在输入一连串文本的时候,通过神经网络生成一张图像的场景
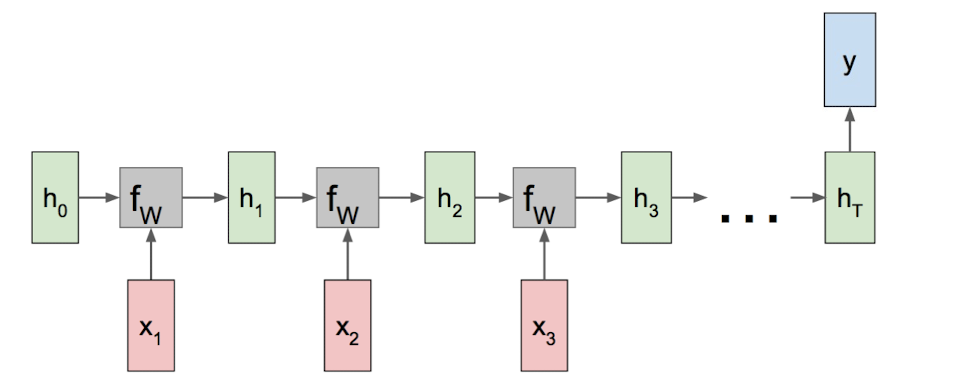
一对多
在看图说话这个应用场景中,输入一张图片,可能会有多个单词的输出。
特殊多对多
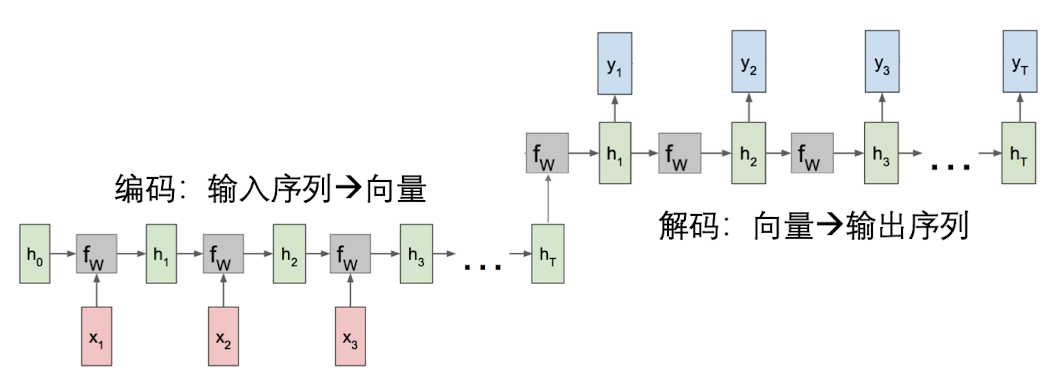
还有一种特殊的多对多循环神经网络,常常用来做机器翻译。比如输入的是红色框框代表的英语,经过循环神经网络处理,输出一个向量$h_T$,里面包含了这句话中所有的语义信息。然后,$h_T$ 作为下面一个循环神经网络序列的输入,解码器将这个向量输出成一个德语序列
这样设计的原因是,因为不同语言之间的语法结构是不同的,因此如果采用一边输入、一边输出的方式,会造成翻译不准确、语义丢失等情况
多层RNN
上面说的RNN例子,都属于一层神经网络,只是在不断堆叠时间步。那么,要训练深层神经网络的话,仅靠一层RNN是不够的,因此提出了多层RNN结构
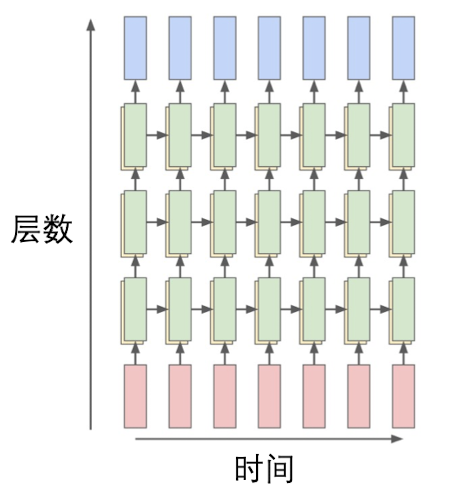
从第二层开始,隐藏层的生成是通过本层上一时刻的权重矩阵和上层本时刻的权重矩阵共同生成的。即:
反向传播
BPTT
学习博客:https://blog.csdn.net/lzw66666/article/details/113132149?utm_source=app&app_version=4.20.0
BPTT(back-propagation through time)算法是常用的训练RNN的方法,其实本质还是BP算法,只不过RNN处理时间序列数据,所以要基于时间反向传播,故叫随时间反向传播。BPTT的中心思想和BP算法相同,沿着需要优化的参数的负梯度方向不断寻找更优的点直至收敛。综上所述,BPTT算法本质还是BP算法,BP算法本质还是梯度下降法,那么求各个参数的梯度便成了此算法的核心。
首先,我们还是要看这张图:
一共有三个权重矩阵: $\boldsymbol {U,V,W}$ 需要在反向传播中更新
反向传播的计算说到底分三部分:1. 定义损失函数 2. 求出损失函数对参数的偏导数 3. 更新参数
定义损失函数
假设在时刻 $t$ 的损失函数为:
损失函数可以用均方误差、Softmax,这里用的是前者
因为有多个时刻,所以总损失函数为所有时刻的损失函数之和:$L = \sum_{t=0}^T{L_t}$
求损失函数对参数的偏导
- 我们来看最主要的权重(参数)矩阵:$\boldsymbol W$, 在RNN中的每一时刻都出现了,因此 $\boldsymbol W$ 在时刻t的梯度 等于时刻t的损失函数对所有时刻的 $\boldsymbol W$ 的梯度和
将 $\frac{\partial L_t}{\partial \boldsymbol W}$ 带入损失函数,可得$\boldsymbol W$ 的总梯度 $\frac{\partial L}{\partial \boldsymbol W}$ 等于$\boldsymbol W$ 在所有时刻的梯度和
有了梯度,我们就可以用来更新参数了
以上三步就是针对参数$\boldsymbol W$ 的反向传播
truncated BPTT
但是BPTT有个问题,当输入序列边长的时候,BPTT非常容易出现梯度爆炸和梯度消失的问题。因此,为了缓解这个问题,有人突出了 TBPTT,也就是前向传播 $k_1$ 步,然后反向传播$k_2$步,通过这个方式使得传播序列变短。通常$k_1=k_2 < n$
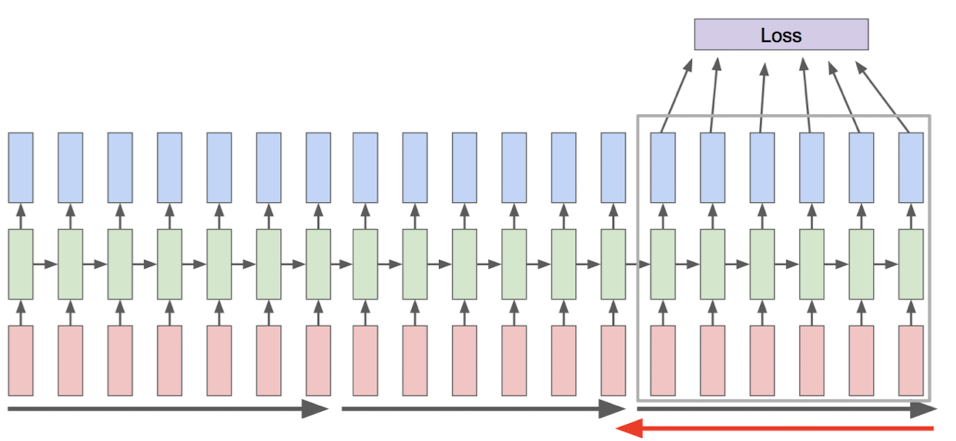
RNN的应用
训练语言模型
RNN的一大应用就是来构建语言模型. 它捕捉了一些人类语言的语法结构和语义信息,能够进行生成文字、自动回复等功能。现在我们用最简单的例子(character-level )来看一下模型是怎么被训练的.
我们用的语料库就是一个单词: hello; 词汇表为 [h,e,l,o];
我们用 独热编码来编写词汇,输入到循环神经网络中,通过权重计算、激活,得到隐藏层如下:
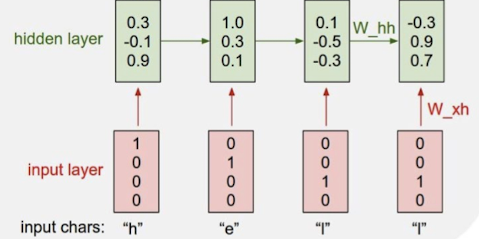
现在,隐藏层需要输出一个值,这个值就代表当前时刻输入值的下一个预测值。输出值和输入值的维度需要保持一致。在这个例子中,输出一个长度为4的向量,每个值代表词汇表中对应词出现的概率。
推理过程如下图所示:
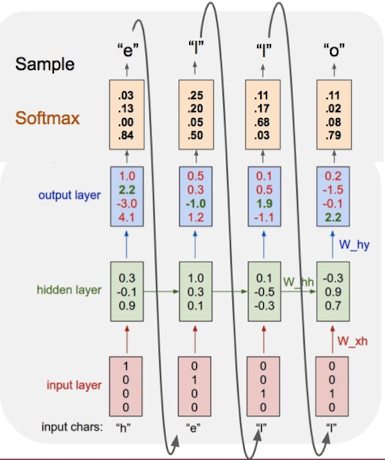
如果我们使用莎士比亚的著作当做语料库,基于character-level 训练,那么只要给神经网络输入一个字母,他就会自己写一部莎士比亚风格的著作了
其他例子
- 此外,RNN还可以用来写诗,比如说:
- 用来写代码,用整个 linux 内核来训练,虽然肯定有语法错误。更多的是像 tabline 一样给出代码提示,或者是代码的克隆检测、代码分类等。
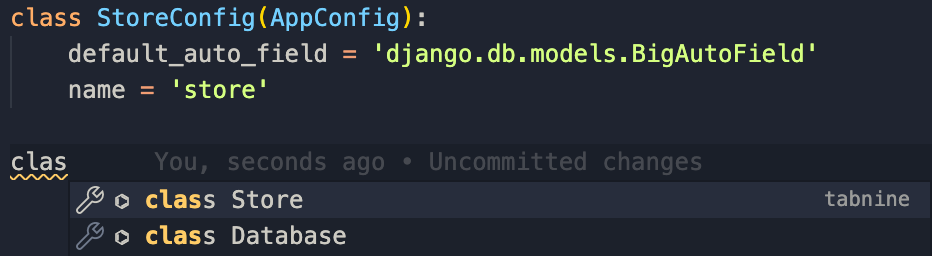
- 使用多对多神经网络,也常常被IDE用来进行代码纠错:
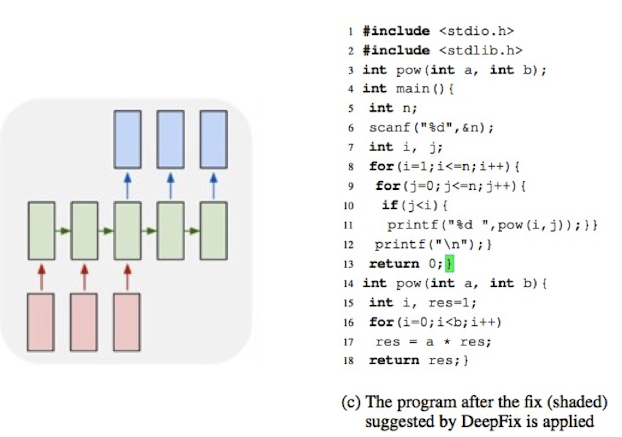
前面讲的都是自然与语言处理相关的内容,其实RNN在cv里面的应用也十分广泛。比如说看图说话:

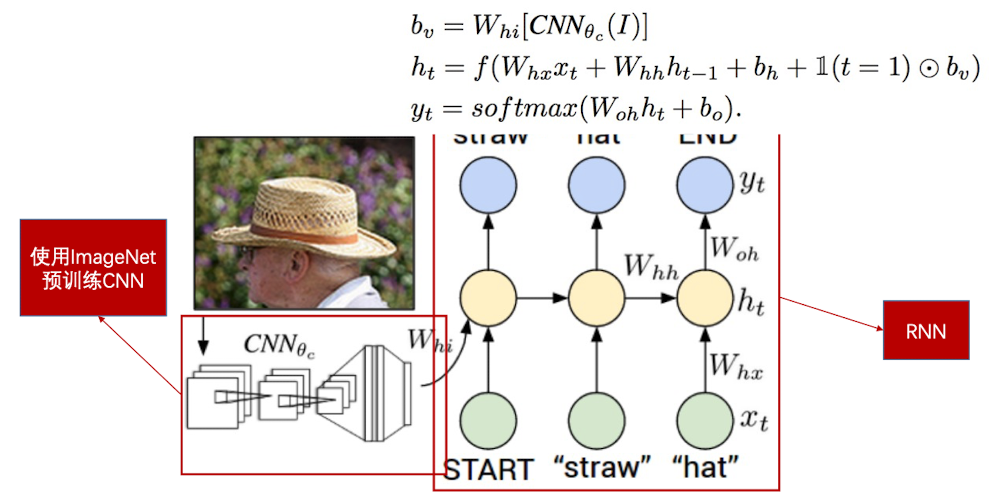
其原理如下图所示,首先输入图像,由CNN处理后,提取特征,然后变成RNN的输入向量:
但这个模型并不是百分百正确的,会出现很多识别错误的例子。
因此,我们可以引入注意力机制,提高RNN的识别率:
在没有引入注意力机制的时候,读入的是一个长度为D的特征 。那么现在,我们让CNN训练一张图片,得到一个 $L\times D$ 的矩阵(即feature map),一共L行,每行代表图片里的L个区域,如下所示:
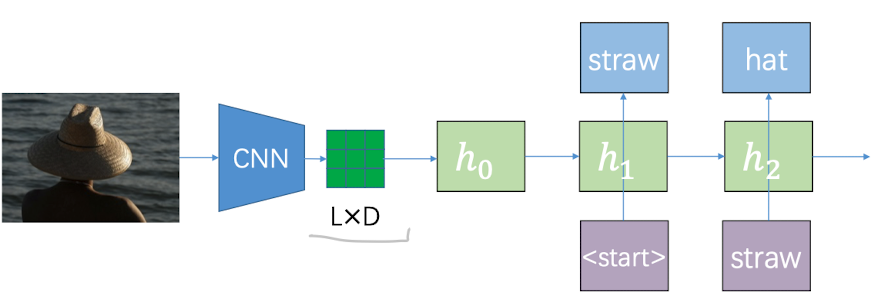
作为输入$h_0$,一般是一个向量,我们可以通过平均池化的方式获得。这样D列就会变成一个长度为D的向量,作为整个图片的特征向量
然后,通过 $L\times D$ 和 $h_0$ (长度为D)相乘,可以得到一个长度为 $L$ 的向量。
- 将$L$里面的元素进行一个softmax求出加权特征向量$Z_1$——里面的每一个元素就是对这一个区域的注意力分数。
- 将这个$Z_1$ 向量作为$h_1$ 的输入,为其指明观察的方向。
- 在$h_1$ 输出了预测值straw以后,由 $h_1$和feature map相乘,softmax后得到$Z_2$。并将$Z_2$和$h_1$得到的输出值straw 共同输入到 $h_2$ 。 $h_2$ 预测值又将和$Z_3$ 共同输入给 $h_3$ 预测,以此类推
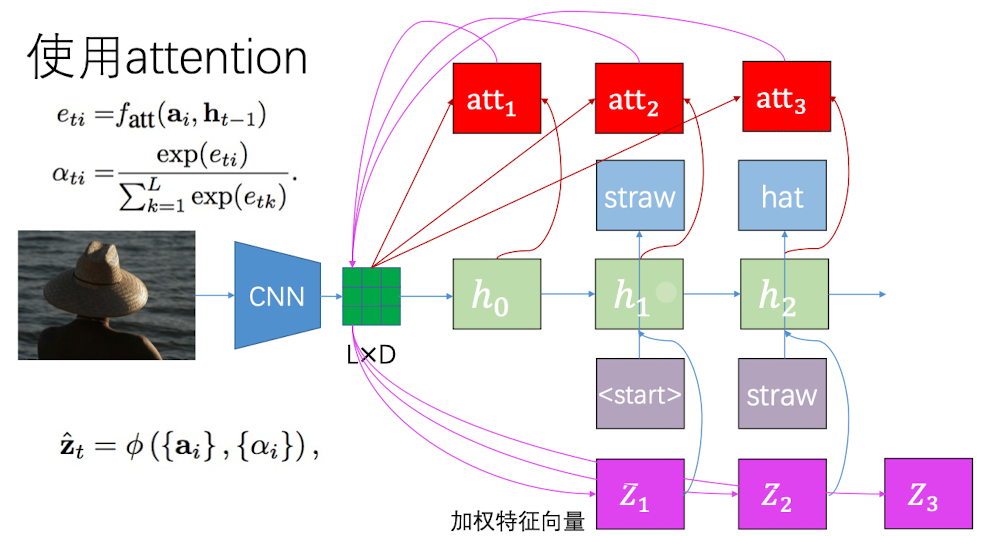
$a_i$ 代表 feature map 里面的第i行特征
$\alpha_{ti}$ 代表t时刻的这个注意力向量的第i个注意力分数
在没有引入注意力机制的时候,每次输入的特征是一样的;但是引入了注意力机制的话,相当于,每一个时间节点,都会要求RNN去观察图片中的一个重点的区域。如下图所示:

此外,这里还提到了 soft attention 和 hard attention,前者是说,直接保留输出的注意力分数,而后者是确立一个阈值,将超过阈值的注意力分数置为1,否则设为0。
RNN的缺点及解决办法
RNN 是有一个非常明显的缺点的——训练长数据的时候容易出现梯度爆炸和梯度消失的问题。为了搞明白这个问题。在前面,我们已经学习了前向传播和BPTT,现在我们再来复习一下:
前向传播公式:
这里我们为了简化,就不添加偏置项了
我们用三次循环为例,示意图如下:
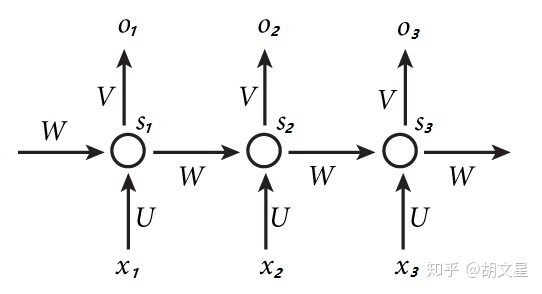
现在来计算前向传播的 $s_1,s_2,s_3,o_1,o_2,o_3$
现在来计算 $t=3$ 时刻,损失函数$L_3$ 对 $\boldsymbol {U、V、W}$ 的偏导
根据上述推导,我们可以得出在任意时刻 $t$, $L$ 对 $\boldsymbol {U,V,W}$ 的偏导公式,以$W$为例:
我 $Sj = \tanh(\boldsymbol Ux_i+\boldsymbol WS{j-1})$ ,那么 $\frac{\partial Sj}{\partial S{j-1}} = \tanh’ \boldsymbol W$ ,而$\prod{j=k+1}^t\frac{\partial S_j}{\partial S{j-1}}=\boldsymbol W^t\cdot\prod_{j=k+1}^t \tanh’$
从上式可知,在回传梯度的时候,我们需要连续不断地乘以 $\boldsymbol W$
因此,当特征值大于1的时候,只要循环次数过多,就会造成梯度爆炸
同理,当特征值小于1的时候,只要循环次数过多,会造成梯度消失
梯度裁剪
为了解决这个问题,我们们可以用梯度裁剪的方法。当特征值>1,造成梯度爆炸、或者梯度的L2范数过大的时候,我们需要对梯度进行缩小
1 | grad_norm = np.sum(grad*grad) |
LSTM
学习博客: https://www.jianshu.com/p/9dc9f41f0b29
但是梯度裁剪对于梯度消失的情况效果并不好,因此我们需要使用更高级的结构,也就是长短期记忆(Long short-Term Memory, LSTM)
因为在RNN中主要是 $h_i$会出现梯度爆炸和梯度消失,在LSTM中就主要做了一项中间步骤,使得回传以后$h$不再是永远为$W^T$,从而避免了梯度爆炸、和消失的问题
核心思想
所有 RNN 都具有一种重复神经网络模块的链式的形式。在标准的 RNN 中,这个重复的模块只有一个非常简单的结构,例如一个 tanh 层。 LSTM 同样是这样的结构,但是重复的模块拥有一个不同的结构。不同于 单一神经网络层,这里是有四个,以一种非常特殊的方式进行交互。
LSTM 的关键就是细胞状态 $C_t$,水平线在图上方贯穿运行。
细胞状态类似于传送带。直接在整个链上运行,只有一些少量的线性交互。信息在上面流传保持不变会很容易。
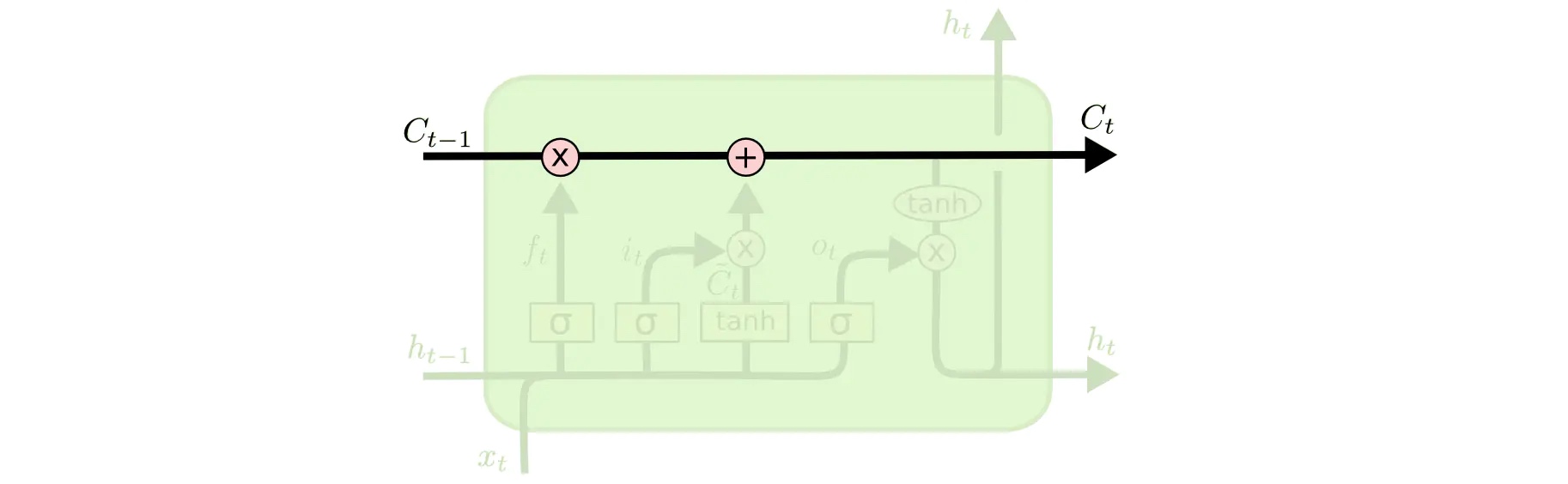
LSTM 有通过精心设计的称作为“门”的结构来去除或者增加信息到细胞状态的能力。门是一种让信息选择式通过的方法。他们包含一个 sigmoid 神经网络层和一个按位的乘法操作。
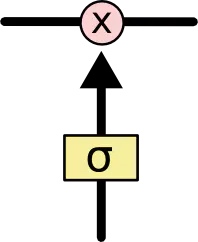
Sigmoid 层输出0到1之间的数值,描述每个部分有多少量可以通过。 0代表“不许任何量通过”,1 就指“允许任意量通过”
LSTM 拥有三个门,来保护和控制细胞状态。
逐步理解 LSTM
LSTM一开始需要计算4个向量:
- i : input gate , 控制在 $c_t$ 中写入哪些信息
- f : forget gate , 控制从$c_{t-1}$ 中擦除哪些信息
- o : output gate ,控制从$c_t$输出哪些信息
- g:激活输入
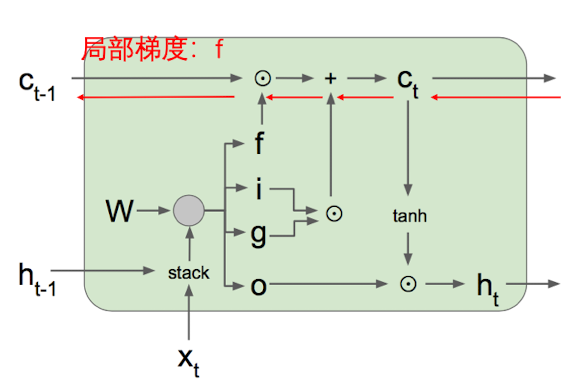
决定丢弃信息
在LSTM中的第一步是决定我们会从细胞状态中丢弃什么信息。这个决定通过上面所说的 forget gate 完成。该门会读取$h{t-1}$ 和$x_t$ ,并输出一个在0到1之间的数值给每个在细胞状态$C{t-1}$中的数字。1表示完全保留而0代表完全舍弃。
计算公式如下:
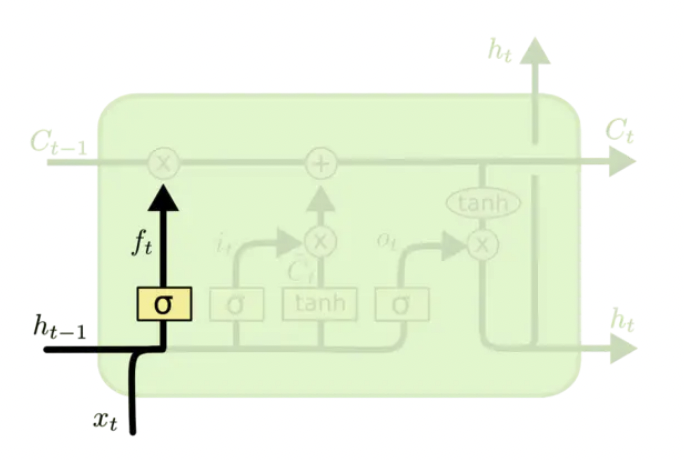
确定更新信息
下一步,是确定什么样的新信息会被存放在细胞状态中。这里包含两个部分。第一,一个sigmoid 层(即input gate) 决定我们将要更新什么值。然后一个 tanh层(gate)创建一个新的候选值向量 $\widetilde C_t$. 这个向量将会被加入到细胞状态中。
计算公式如下:
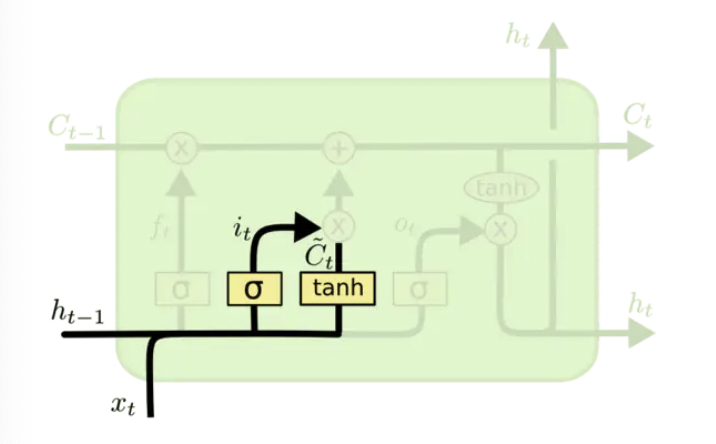
更新细胞状态
现在是更新旧细胞状态的时间了,$C_{t-1}$ 更新为 $C_t$ 。
我们把旧状态 与 $f_t$ 相乘,来丢弃掉我们确定需要丢弃的信息。接着加上 $i_t*\widetilde C_t$,即新的候选值。
公式如下:
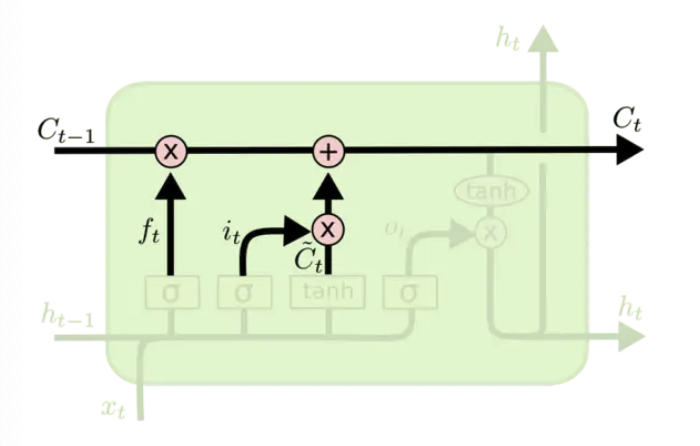
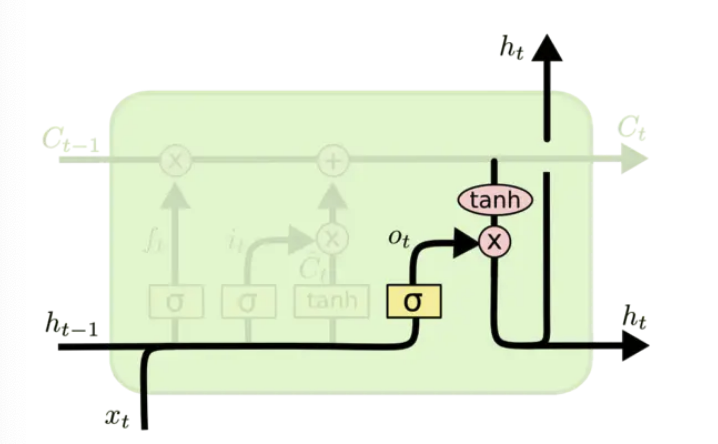
输出信息
最终,我们需要确定输出什么值。这个输出将会基于我们的细胞状态。
- 首先,我们运行一个
sigmoid来确定细胞状态的哪个部分将输出出去。得到输出门 output gate - 接着,我们把细胞状态通过
tanh进行处理,得到一个 -1~1 之间的值,并将它和sigmoid的输出相乘。最终我们仅仅会输出我们确定输出的那部分。
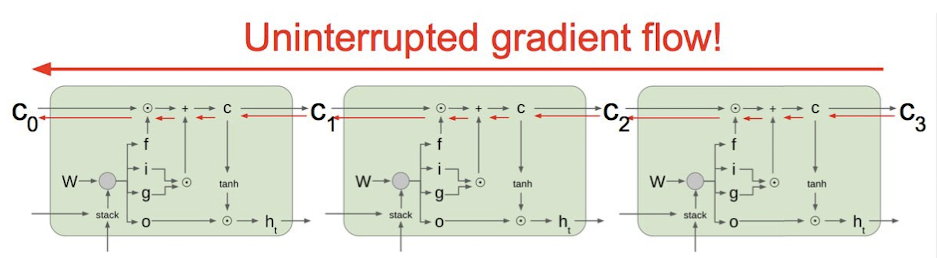
梯度回传
LSTM 中梯度的传播有很多条路径,$c{t-1}\rightarrow c_t = f_t\odot c{t-1}+i_t\odot \hat c_t$ 这条路径上只有逐元素相乘和相加的操作,梯度流最稳定;
但是在其他路径上,LSTM 的梯度流和普通 RNN 没有太大区别,照样会发生相同的权重矩阵反复连乘的情况,依然会爆炸或者消失。由于总的远距离梯度 = 各条路径的远距离梯度之和,即便其他远距离路径梯度消失了,只要保证有一条远距离路径(就是上面说的那条高速公路)梯度不消失,总的远距离梯度就不会消失(正常梯度 + 消失梯度= 正常梯度)。因此 LSTM 通过改善一条路径上的梯度问题拯救了总体的远距离梯度
同样,因为总的远距离梯度 = 各条路径的远距离梯度之和,高速公路上梯度流比较稳定,但其他路径上梯度有可能爆炸,此时总的远距离梯度 = 正常梯度 + 爆炸梯度 = 爆炸梯度,因此 LSTM 仍然有可能发生梯度爆炸。不过,由于 LSTM 的其他路径非常崎岖,和普通 RNN 相比多经过了很多次激活函数(导数都小于 1),因此 LSTM 发生梯度爆炸的频率要低得多。实践中仍然可以通过梯度裁剪来解决。
GRU
GRU是对 LSTM的进一步简化