计算机视觉-检测和分割
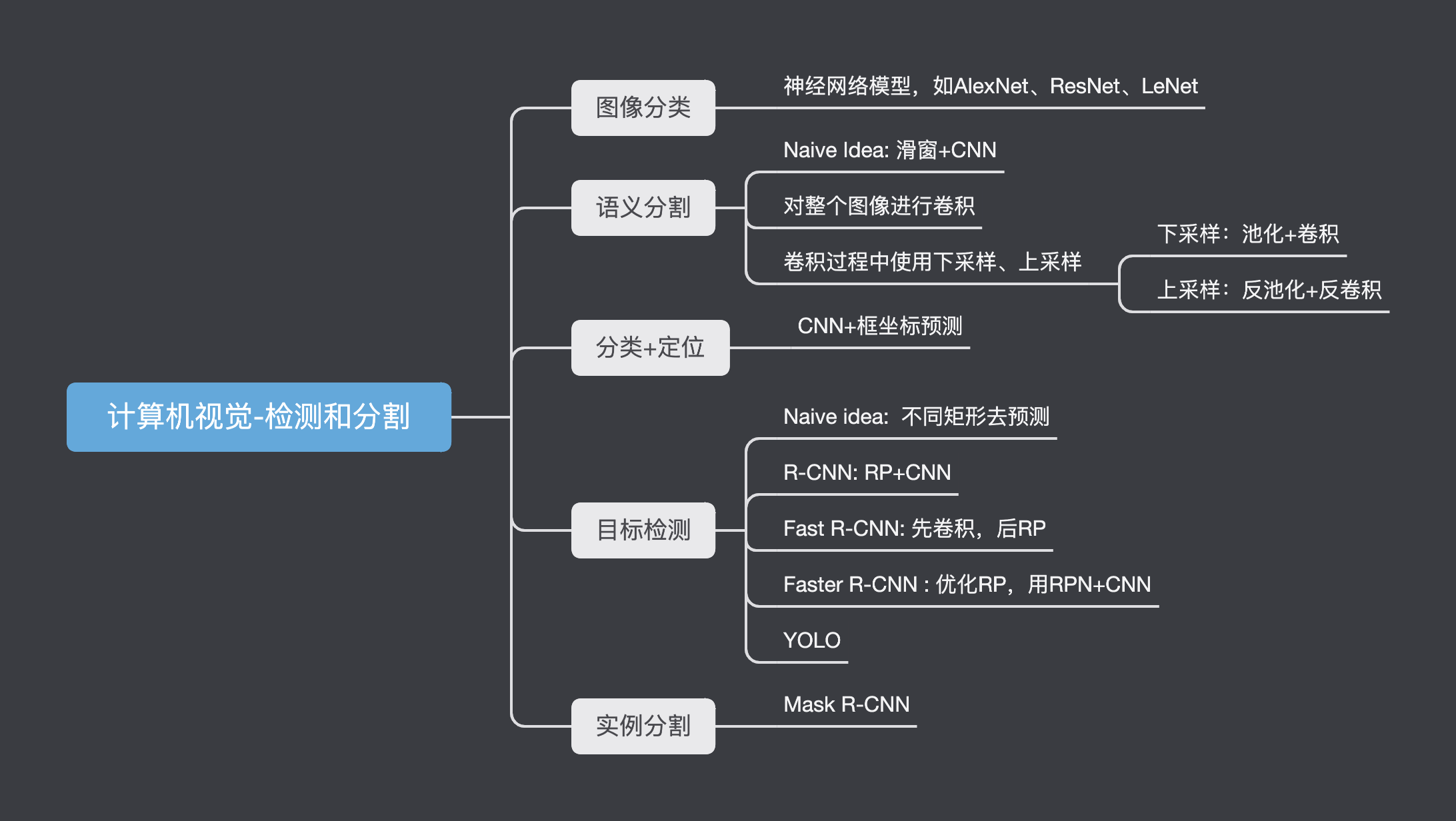
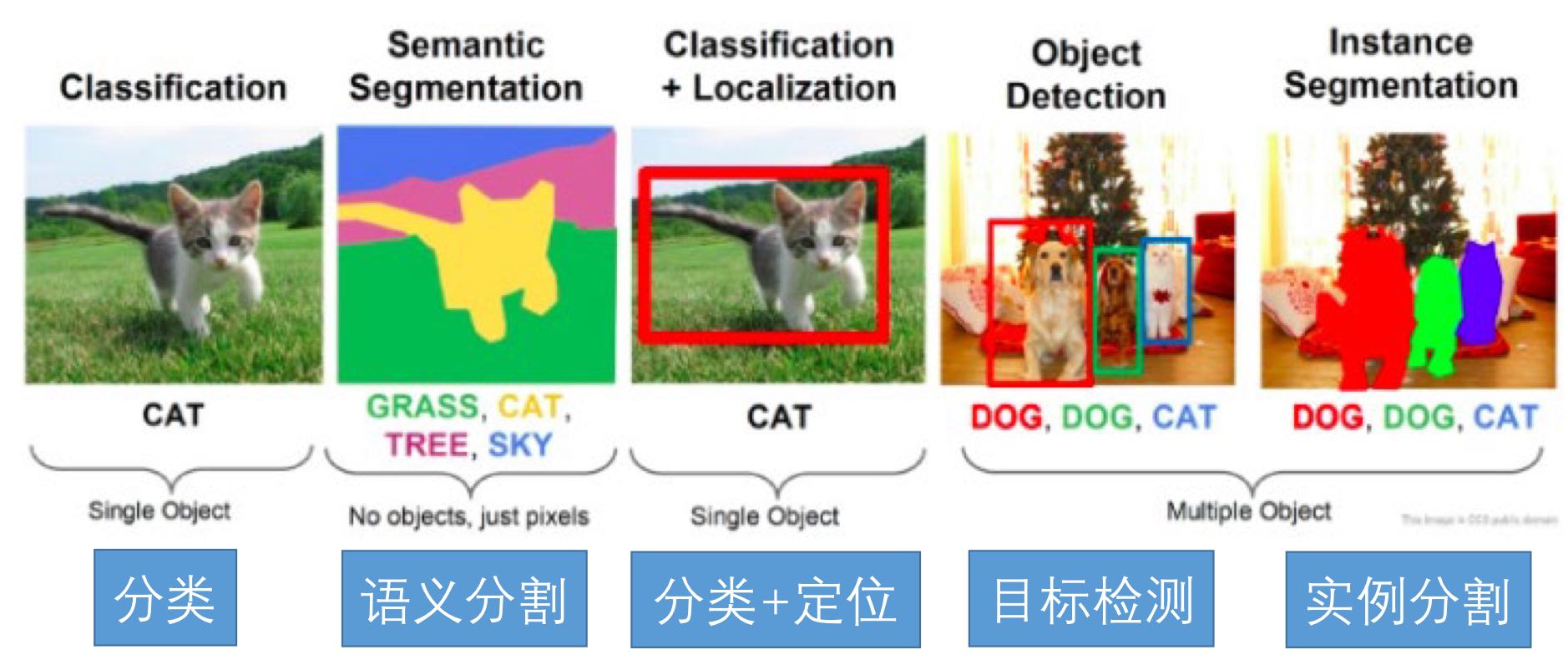
在第一章我们了解过常见的CV任务,主要有:图像分类、语义分割、分类+定位、目标检测、实例分割
图像分类
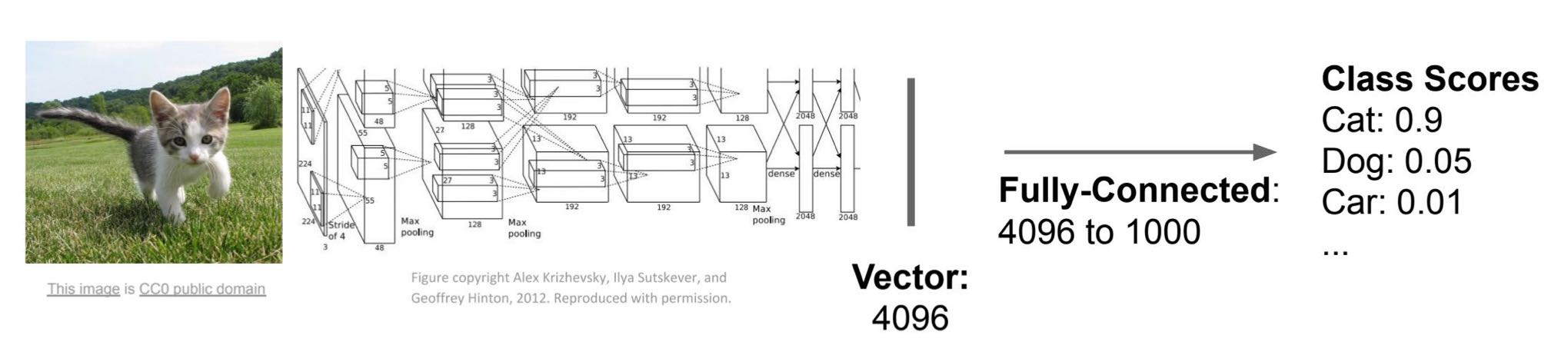
CV最常见的就是图像分类了,比如说利用AlexNet对图像进行分类,最后输出对图像的预测分数
在图像分类的基础上,延伸出来几个其他作用,下面一一介绍
语义分割
语义分割就是对于输入的图片,将每一个像素划分成一个类别。如下:

方法
那么语义分割怎么做呢?
对于图像分类,是对图像整体进行类别预测,而对于语义分割,是对每一个像素进行分类。同时,不区分相同类别的个体。
Naive Idea: 滑窗

我们可以拿一个窗口再图像上滑动,每次滑动一个像素点,然后用CNN去判断这个滑窗属于什么类别,然后将滑窗的中心点划为这个类。
虽然利用滑窗可以达到比较好的效果,但是这个方法的计算代价及其昂贵
对所有像素点同时进行预测
我们可以对整个图像进行卷积
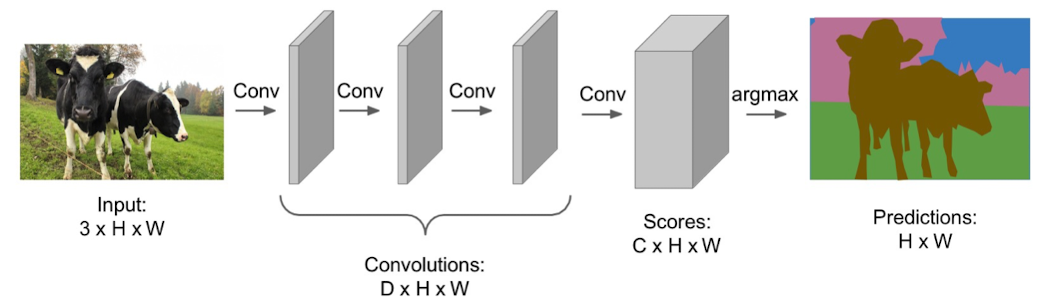
将损失函数定义为 对所有像素点进行分类的交叉熵之和,然后最小化损失函数得到预测结果。这个方法相比于滑窗效率有所提升,但是对内存的要求很大,卷积计算依然昂贵。
因此我们要在中间过程中对feature map 进行下采样,得到隐层向量,然后再进行上采样复原图片,进行损失函数的计算。
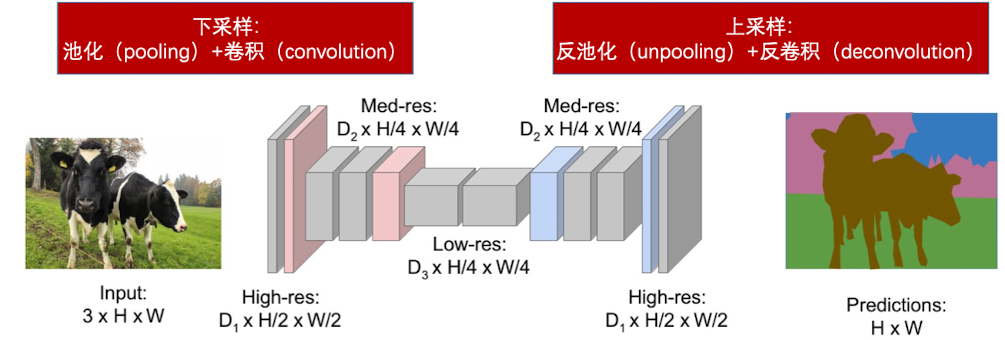
上采样
下采样是池化和卷积,上采样就是下采样的逆转方法——反池化和反卷积。
比如说,反池化有几种选择:我们可以将一个元素的邻居都赋相同的值,也可以将只赋值给区域中的固定位置,其他位置设为0
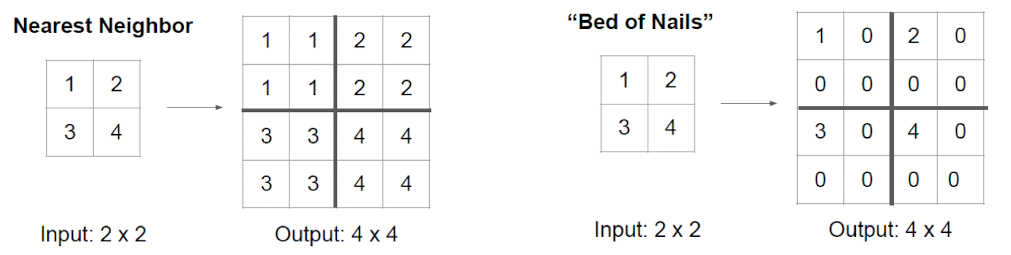
当然,还有一种就是借鉴池化反向传播的方法,将值赋给池化时的对应位置

不管是max unpooling, nearest neigbor 还是Bed of Nails,都和池化一样是没有参数的。 还有一种上采样方法:deconvolution,则需要用参数,而且是可学习的。
如下图, 我们将输入值乘以一个 $3\times 3$的”反卷积核” ,就相当于”扩张”了。如下图所示:
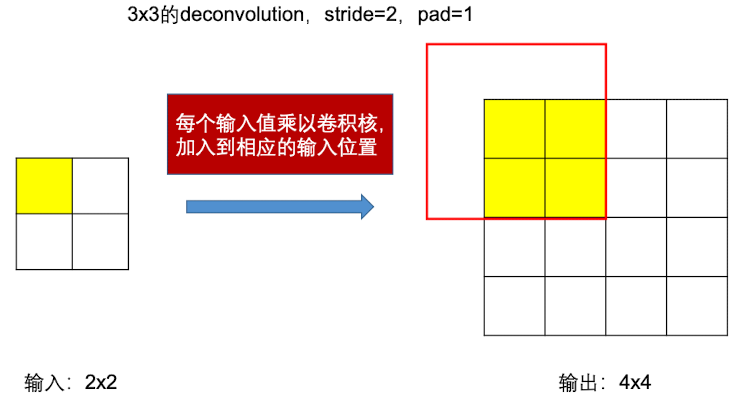
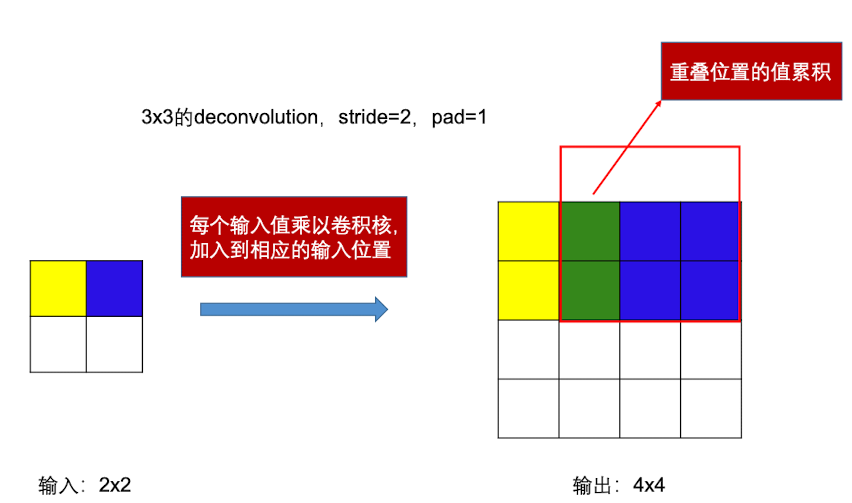
然后,对每个输入值乘以卷积核,并对重叠的位置进行累积(当然平均也可以),得到上采样后的结果,可以得到如下图所示:
分类+定位
分类加定位(单目标检测),就是识别出一张图片最主要的对象,然后框起来。如下

方法

和图像分类的区别就在于,经过卷积之后,需要做两个全连接层,一个全连接层做的工作是分类,另一个则是输出一个长度为4向量,代表了这个框的四个坐标。这样就完成了分类的预测和定位的预测。
分类的预测用softmax 损失函数,定位的预测用L2损失函数(回归),将这两个损失函数相加,共同优化,得到最终的结果。
因此,理论上只要有固定数量的点位,我们都可以对其进行预测。这项技术可以用于姿态估计
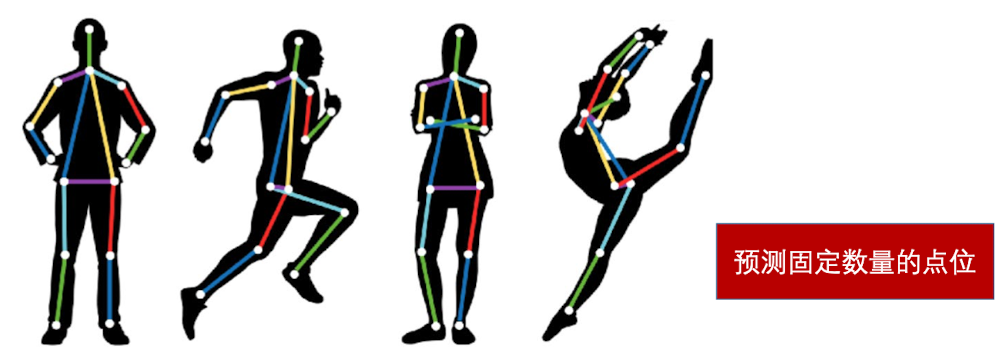
目标检测
将分类+定位中的单个物体拓展为多个物体,就变成了目标检测任务

方法
在进行分类+定位任务的时候,我们可以将问题简化为预测5个值(类别以及框的定位);但是对于目标检测任务,由于一张图片中存在多个目标,我事先是不知道有多少物体的,因此需要预测很多数值以及很多类别。
Naive idea
一个朴素的额方法就是,用不同的大小、位置、长宽比的矩形区域对图片进行卷积计算,用来预测类别以及框框位置。但很显然这种方法的代价极其昂贵。
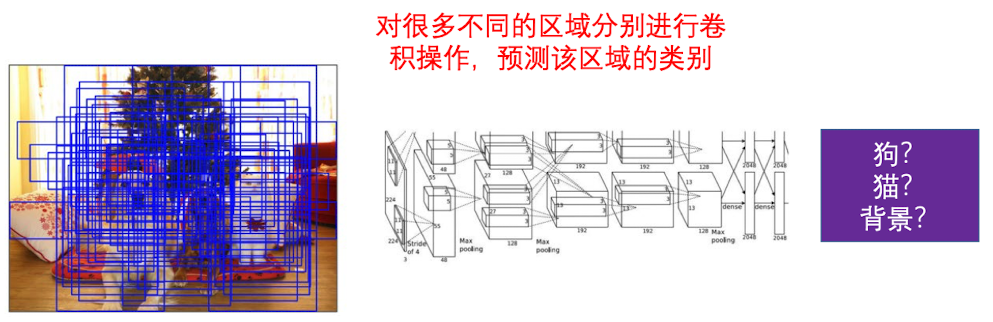
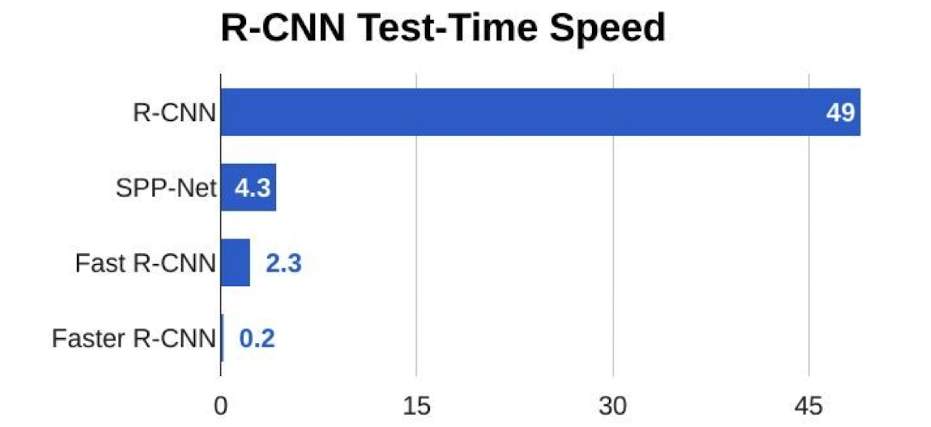
R-CNN
因此我们设想,可不可以预先寻找一些可能存在物体的区域? 这就是 Region Proposals(RP)
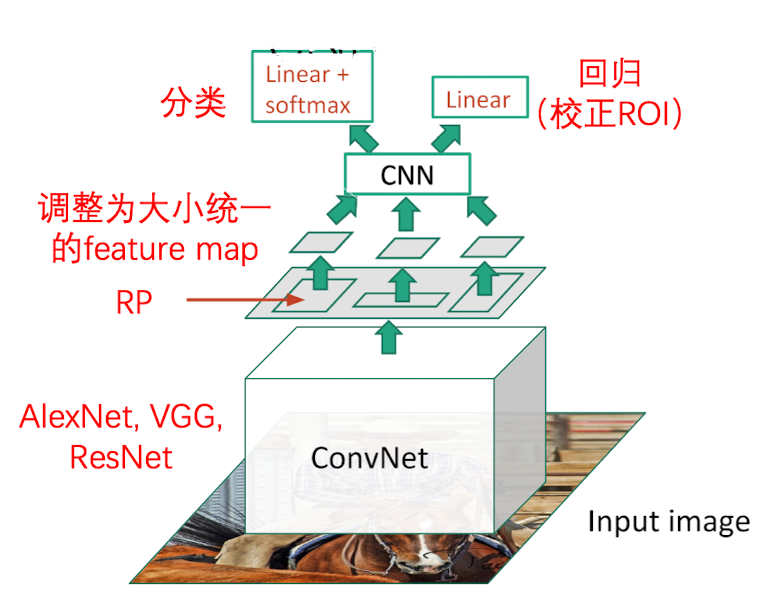
我们可以用 Selective Search 这种传统的图形学算法,来找到几个很可能存在物体的区域。通常速度为 2000区域/秒

在一张图片中经过RP之后,会在图片上标记出一些区域,我们称其为(Regions of Interest,ROI) 由于区域大小存在差异,因此会先转换成大小统一的feature map
然后经过CNN 对每一个区域进行分类以及利用回归来校正 ROI 的坐标

虽然这个算法效果非常好,肯定包含了我们需要检测的目标,但是,这种方法也很慢,需要对至少好几千个ROI分别做卷积。
Fast R-CNN
为了优化上面这个算法,我们可以先卷积,后RP,这就是所谓的 Fast R-CNN . 示意图如下:
Faster R-CNN
比 Fast R-CNN更快的,是Faster R-CNN。 这种方法优化了RP方法,使用RPN来进行物体检测。其示意图如下:
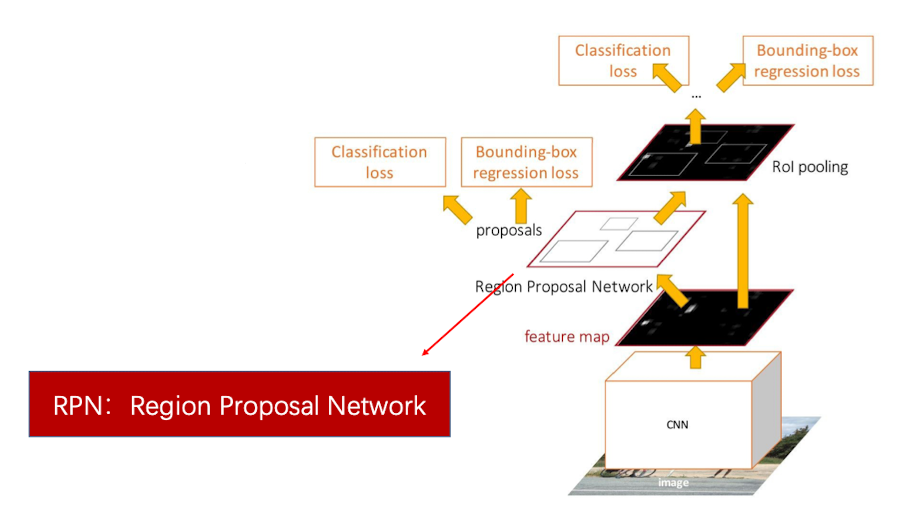
该方法使用了4个损失函数:
- RPN 是否包含物体
- RPN 边框坐标
- 物体的最终类别
- 边框的额最终目标
RPN 不同于传统的图像算法,是基于数据驱动、会不断优化自己的。训练完成以后,当RPN得到了feature map,它会去预测到底哪些区域是存在目标物体的,而不是使用selective search的方法去检索。
因此,到最后PR会被优化成一个线性计算,效率会非常高。
那么,RPN 是怎么被训练的呢?
首先,得到了一个 20x15 的feature map,我们就将其划分为20x15个block.
接着,我们把每一个block 为中心,构建一个 anchor box. 如下图所示
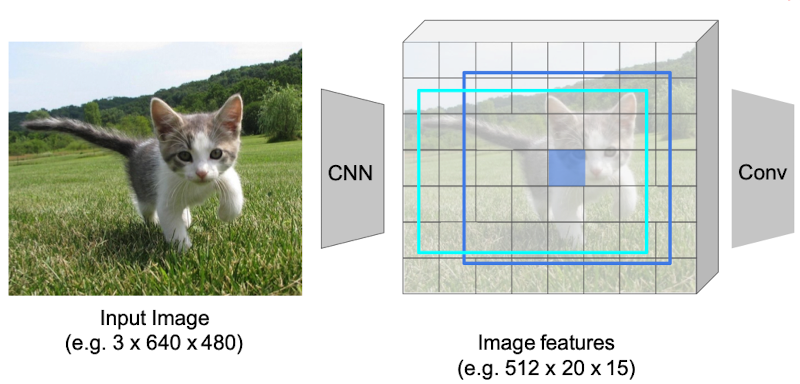
然后,我们去预测每个anchor box 里面是否包含物体。也就是输出 $1\times20\times15$ 个预测数据
在预测是否包含物体的时候,还需要预测每一个anchor box的真是坐标,因此又要输出$4\times20\times15$个数据
通常,每一个像素点,有k 个大小不同的anchor box 需要我们去预测,因此,还要在原来的基础上乘以 $K$
最后,我们会选取含物体概率最高的100个区域作为 Region Proposal
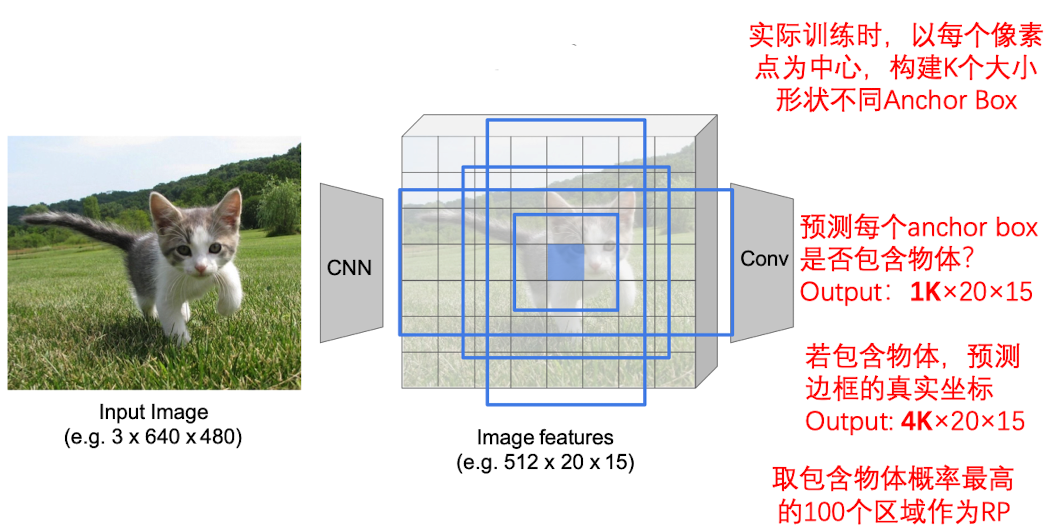
整个训练一共分为两个阶段
- 第一阶段
- CNN 提取 feature
- RPN
- 第二阶段
- ROI Pooling
- 分类
- 回归(校正 ROI)
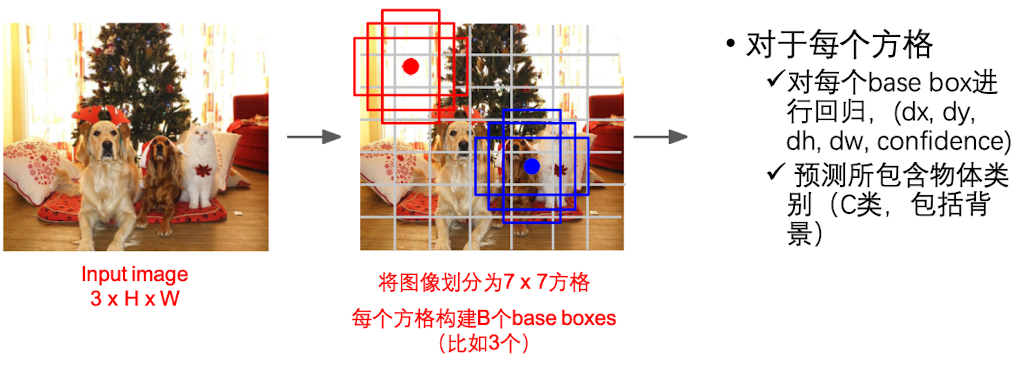
YOLO
YOLO 是 You Only Look Once 的缩写。
YOLO 是直接在图片上划分出base boxes(类似于anchor boxes),对每个base box进行回归,并预测这个框有多大概率真的包含目标物体(背景)。
YOLO在实际项目中的效果是很好的,比faster R-CNN更快。但是由于没有提取feature map,所以精度会差一点
SSD: Single-Shot MultiBox Detector
总结
Feature 提取网络
- VGG 16
- ResNet-101
- Inception V2
- Inception V3
- Mobile Net
主体结构
- 两阶段: Faster R-CNN
- 一阶段: YOLO/SSD
- 混合:R-FCN
经验总结
Faster R-CNN 相对较慢但精度较高
YOLO/SSD 速度更快,但精度较低
Feature 提取可以使用更深更大的模型
实例分割
在实例分割任务中,需要将检测到的目标用不同的颜色标注出来。但在语义分割里面,可能这些目标都是一个颜色的。

方法
实例分割就是将前面的一些方法整合起来。其中最经典的一个模型就是Mask R-CNN
Mask R-CNN
Mask R-CNN前面的结构和Faster R-CNN 非常像
先利用目标检测的方法,检测图片中那些区域可能存在物体
再利用语义分割的方法,将这个区域里面的像素点进行分类

https://openaccess.thecvf.com/content_ICCV_2017/papers/He_Mask_R-CNN_ICCV_2017_paper.pdf
总结