OLAP
参考 :https://www.zhihu.com/question/24110442/answer/851671343
OLTP(on-line transaction processing)翻译为联机事务处理, OLAP(On-Line Analytical Processing)翻译为联机分析处理,从字面上来看OLTP是做事务处理,OLAP是做分析处理。从对数据库操作来看,OLTP主要是对数据的增删改,OLAP是对数据的查询。
这里我们在多介绍一下OLAP
数据仓库系统
OLAP分析的分类:ROLAP与MOLAP
OLAP分析 分为关系型联机分析处理(ROLAP)、多维联机分析处理(MOLAP)两种,他们的设计理念以及解决场景不一样,各有优劣。
ROLAP
以ROLAP为代表的有传统关系型数据库、MPP分布式数据库以及基于Hadoop的Spark/Impala,它们是将数据块存储在关系型数据库当中的。
- 优点
- 是能同时连接明细数据和汇总数据,实时根据用户提出的需求对数据进行计算后返回给用户,所以用户使用相对比较灵活,可以随意选择维度组合来进行实时计算。
- 对高维数据、超大数据集有很好的扩展性
- 技术成熟
- 正因为采用的实时计算技术,所以ROLAP的缺点也比较明显
- 当计算的数据量达到一定级别或并发数达到一定级别的时候,一定会出现性能问题(就好比如果领导一次性给你安排非常多的工作,你一个人是无法马上将所有事情做完答复领导的)。
- 需要构建明确的索引
以传统关系型数据库为代表的如Teradata、Oracle等,由于传统架构可扩展性较差,所以对硬件的要求非常高,当计算的数据量达到千万,亿级别时,数据库的计算就会出现延时,使得用户不能及时得到响应,更别提高并发了。
MPP 分布式数据库则解决了一部分可扩展性问题,对硬件设备的要求也稍稍下降了(还是有一定的硬件要求),在支持的数据体量(GB,TB级别)上有了很大的提升。当集群有几百、上千节点时,会出现性能瓶颈(增加再多节点,性能提升也不会很明显),扩容成本同样不菲。
基于Hadoop的Spark/Impala,则对部署硬件的要求很低(常见服务器即可,只是其主要依靠内存计算来缩短响应时间,所以对内存要求较高),在节点扩容上成本上相对较低,但当计算量达到一定级别或并发达到一定级别后,无法秒级响应,且容易出现内存溢出等问题。
MOLAP
以MOLAP分析为代表的有Cognos,SSAS,Kylin等,设计理念是预先将客户的需求计算好以结果的形式存下来(比如一张表分为10个维度,5个度量,那客户提出的需求会有2的10次方种可能,然后将这么多种可能提前计算好存储下来),当客户提出需求后,找到对应结果返回即可(好比你提前一天将领导明天会布置的任务先做好,明天领导布置对应任务后你直接告知他已做好)
- 优点是当命中需求后返回非常快(所以MOLAP非常适合常见固定的分析场景),同等资源下支持的数据体量更大,支持的并发更多
- 缺点则是当表的维度越多,越复杂,其所需的磁盘存储空间则越大,构建cube也需要一定的时间。
Cognos和SSAS是早期比较传统的产品,Cognos限制了Cube的大小(即限制了表的复杂度大小),而SSAS的cube则受限于单机的容量,即需要专用的服务器来进行存储。
Apache Kylin则是目前技术较为先进的一款成熟产品,也是第一个由中国人贡献给Apache社区的顶级开源项目,它基于hadoop框架,Cube以分片的形式存储在不同节点上,Cube大小不受服务器配置限制,所以具备很好的可扩展性和对服务器要求很低,在扩容成本上就非常低廉。另外为了控制整体Cube的大小,Kylin给客户提供了建模的能力,即用户可以根据自身需要,对模型种的维度以及维度组合进行预先的构建,把一些不需要的维度和组合筛选掉,从而达到降低维度的目的,减少磁盘空间的占用。
Kylin的企业版产品,即Kyligence的产品,除了在性能、功能上做了很多优化之外,稳定性上也做了很大提升,还提供了智能建模功能,在满足用户需求的前提下,很大程度上减小了磁盘空间的浪费。
综上而言
从可扩展性上看:Kylin=Impala/Spark>MPP数据库>传统数据库
从对硬件要求上看,传统数据库>MPP数据库>Impala/Spark>=Kylin;
- 从响应效率上来看,不同的数据量、并发数,响应效率差别不一,但可以确定的是,要计算的数据量越大,并发的用户数越多,同等资源情况下预计算的响应效率会越发明显。
数据仓库模型
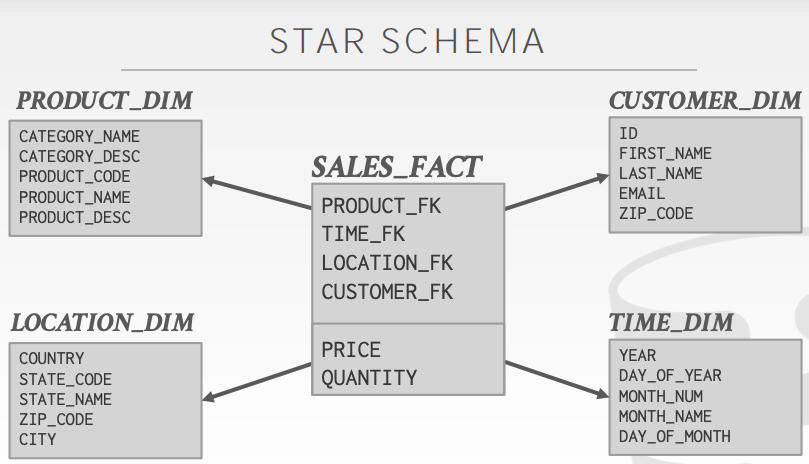
Star schema
在星型模型当中,一张事实表被若干张维度表所包围。每一个维度代表了一张表,有主键关联事实表当中的外键。
- 所有的事实都必须保持同一个粒度
- 不同的维度之间没有任何关联
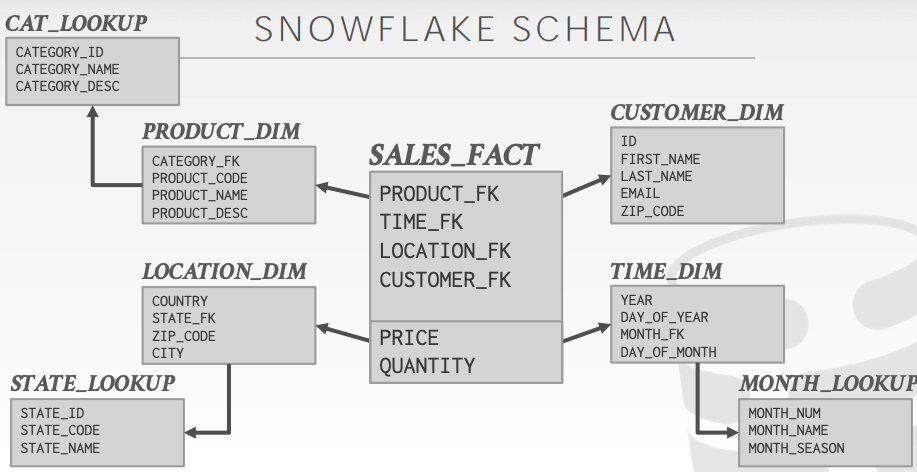
雪花模型
雪花模型是在基于星型模型之上拓展来的,每一个维度可以再扩散出更多的维度,根据维度的层级拆分成颗粒度不同的多张表。
- 优点是减少维度表的数据量,在进行join查询时有效提升查询速度
- 缺点是需要额外维护维度表的数量
总结
在规范化方面:
- 雪花模型比较符合数据库范式的理念设计方式比较正规,数据冗余少
- 非规范化的数据模型可能会违反完整性和一致性
在查询复杂度方面:
- 雪花模型在查询的时候可能需要join多张表从而导致查询效率下降,此外规范化操作在后期维护比较复杂。
- 星型模型能够提升查询效率,因为生成的事实表已经经过预处理,主要的数据都在事实表里面,所以只要扫描实时表就能够进行大量的查询,而不必进行大量的join。而且维表数据一般比较少,可直接放入内存进行join以提升效率,
在可读性方面:
- 星型模型的事实表可读性比较好,不用关联多个表就能获取大部分核心信息,设计维护相对比较简答。
数据仓库大多数时候是比较适合使用星型模型构建底层数据Hive表,通过大量的冗余来提升查询效率,星型模型对OLAP的分析引擎支持比较友好,这一点在Kylin中比较能体现。
而雪花模型在关系型数据库中如MySQL,Oracle中非常常见,尤其像电商的数据库表。在数据仓库中雪花模型的应用场景比较少,但也不是没有,所以在具体设计的时候,可以考虑是不是能结合两者的优点参与设计,以此达到设计的最优化目的。
| 属性 | 星型模型 | 雪花模型 |
|---|---|---|
| 数据总量 | 多 | 少 |
| 可读性 | 容易 | 差 |
| 表个数 | 少 | 多 |
| 查询速度 | 快 | 慢 |
| 冗余度 | 高 | 低 |
| 对实时表的情况 | 增加宽度 | 字段比较少,冗余低 |
| 扩展性 | 差 | 好 |