隐马尔可夫模型
基本概念
首先,我们要了解,什么是隐马尔科夫模型?
隐马尔科夫模型,是关于时序的概率模型
它描述一个隐藏的马尔科夫链随机生成不可观测的状态随机序列(state sequence),再由各个状态随机生成一个观测而产生观测随机序列的过程,序列的每一个位置又可以看做是一个时刻
三要素
隐马尔科夫模型由初始概率分布,状态转移概率分布,以及观测概率分布确定,隐马尔科夫模型的形式定义如下:
$Q$ 所有可能的状态的集合 ,记为 $Q = {q_1, q_2\cdots,q_N}$, $N$ 是可能的状态数
$V$ 所有可能观测的集合,记为 $V= {v_1,v_2\cdots,v_m}$ , $M$ 是可能的观测数
$I$ 长度为$T$ 的状态序列 ,记为 $I = (i_1,i_2\cdots,i_T)$
$O$ 对应的观测序列,记为 $O= (o_1,o_2,\cdots,o_T)$
$A$ 是状态转移概率矩阵,记为 $A = [a{ij}]{N\times N}$
其中, $a{ij} = P(i{i+1}=q_j|i_i=q_i),i=1,2\cdots,N;j=1,2\cdots,N$ 。这代表着,在时刻t,处于状态$q_i$ 的条件下,在时刻 $t+1$ 转移到状态 $q_j$ 的概率
$B$ 是观测概率矩阵,记为 $B = [bj(k)]{N\times M}$
其中,$b_{j}(k) = P(o_t=v_k|i_t=q_j),k=1,2\cdots M;j=1,2\cdots,N$
这代表着,在时刻 t, 处于状态$q_j$ 的条件下,生成观测 $v_k$ 的概率
$\pi$ 是初始状态概率向量,记为 $\pi = (\pi_i)$
其中,$\pi_i = P(i_i=q_i),i=1,2\cdots,N$ ,这代表着,时刻$t=1$ 时,处于状态$q_i$ 的概率
它们的关系是:
$\pi,A$ 确定了隐藏的马尔科夫链,生成不可观测的状态序列,$B$确定了如何从状态生成观测,与状态序列总和确定了如何产生观测序列。因此,隐马尔科夫模型$\lambda$可以由三元符号来表示:$\lambda = (A,B,\pi)$
$A,B,\pi$ 也被称为是马尔科夫模型三要素。
两个基本假设
从定义可知,隐马尔科夫模型做出了两个基本假设
齐次马尔科夫性假设。即设 隐藏的马尔科夫链在任意时刻 t 的状态只依赖于前一时刻的状态,与其他时刻的状态及观测无关,也与时刻t 是无关的。(可以理解为无记忆性)
观测独立性假设。即假设任意时刻的观测只依赖于该时刻的马尔科夫链的状态,与其他观测及状态无关
隐马尔科夫模型可以用于标注,这时状态对应着标记。标注问题是给定观测序列预测期对应的标记序列. 我们可以假设,标注问题的数据是由隐马尔科夫模型生成的,这样,我们可以利用隐马尔科夫的学习与预测算法进行标注
盒球模型
假设有四个盒子,每个盒子都有红白两种颜色共10颗球,如下

转移的规则是:
- 盒子1 那么下一个一定是盒子2
- 盒子2或者盒子3,那么下一个0.4 是左边那个盒子,0.6是右边那个盒子
- 盒子4 下一个0.5是自己,0.5是盒子3
我们可以通过观测每次去除球的颜色来得到观测序列,但是观测不到球是从哪个盒子取出来的,也就是说,我们观测不到盒子的序列。
在这个例子中,盒子的序列就是状态序列 I,球颜色的观测序列就是观测序列O
已知:
状态集合 $Q =$ {盒子1,盒子2,盒子3,盒子4},$N=4$
观测集合 $V =$ {红,白} $M=2$
观测序列和状态序列的长度 $T=5$
现在抽取五次,得到观测序列$O = ${红,红,白,白,红}
我们的初始概率分布为: $\pi = (0.25,0.25,0.25,0.25)$ 也就是抽到每个盒子的概率都是相同的
状态概率转移矩阵 $A$:
我们看到,这个矩阵记录的,就是上面说的三条转移规则
观测概率举证$B$:
我们看到,这个矩阵记录的,就是每个状态下,观测到红球或者是白球的概率
观测序列如何生成
从盒球模型中,观测序列时直接给我们的,那么,它是怎么生成的呢?
通过 给定隐马尔科夫模型三要素 $\lambda = {A,B,\pi}$,以及观测序列长度 T(理解为要观测几次),我们输出观测序列$O$
- 安装初始状态分布$\pi$ 来产生 状态i
- 令$t = 1$
- 按照状态 $it$ 的观测概率分布 $b{i_t}(k)$ 来生成$o_t$
- 按照状态 $it$ 的状态转移概率分布 ${a{iti{t+1}}}$ 来产生状态 $i_{t+1}$
- 令 $t=t+1$ ,若 $t<T$ ,跳转至(3), 否则终止
三个基本问题
概率计算问题。给定模型 $\lambda = (A,B,\pi)$ 和观测序列 $O=(o_1,\cdots,o_T)$ ,计算在模型$\lambda$ 下,观测序列$O$ 出现的概率$P(O|\lambda)$
学习问题。已知观测序列$O=(o_1,\cdots,o_T)$, 估计模型 $\lambda = (A,B,\pi)$ 参数,使得在该模型下观测序列概率$P(O|\lambda)$ 最大. 即用极大似然估计的方法估计参数
- 预测问题.已知模型$\lambda = (A,B,\pi)$ 和观测序列$O=(o_1,o_2,\cdots,o_T)$,求对给定观测序列条件概率$P(I|O)$ 最大的状态序列$I=(i_1,\cdots,i_T)$。 维特比算法应用动态规划高效地求解最优路径,即概率最大的状态序列
概率计算算法
概率计算问题。给定模型 $\lambda = (A,B,\pi)$ 和观测序列 $O=(o_1,\cdots,o_T)$ ,计算在模型$\lambda$ 下,观测序列$O$ 出现的概率$P(O|\lambda)$
前向算法
首先,我们给出前向概率的定义:
给定隐马尔科夫模型$\lambda$ , 定义到时刻 t 部分观测序列为 $o_1,\cdots,o_t$ 且状态为$q_i$ 的概率为前向概率 $\alpha_t(i)$。记作:
由此,我们可以递推地求得前向概率$\alpha_t(i)$ 以及观测序列概率$P(O|\lambda)$
算法步骤
输入:隐马尔科夫模型 $\lambda$, 观测序列 $O$:
输出 :观测序列概率 $P(O|\lambda)$
- 初值
这个步骤是初始化前向概率,是初始时刻的状态$i_t = q_i$ 和观测 $o_1$ 的联合概率
- 递推,对于$t=1,2\cdots,T-1$
- 终止
例题

- 步骤1,计算初值
- 步骤2,递推
我们要递推得到$\alpha_2$ 这一层的N个值(N=3)
因为 $T=3$,所以我们还要再推一层 $\alpha_3(i)$
- 步骤3,终止
后向算法
首先我们来定义后向概率:
给定隐马尔科夫模型$\lambda$ , 定义在时刻t,状态为$qi$ 的条件下,从$t+1$到$T$ 的部分观测序列为 $o{t+1},\cdots,o_T$ 的概率为后向概率,记作
由此,我们可以递推地求得后向概率$\beta_t(i)$ 以及观测序列概率$P(O|\lambda)$
算法步骤
- 初值
- 递推
对于 $t=T-1,T-2,\cdots,1$, 有:
一些概率与期望值的计算
利用前向和后向概率,我们可以得到关于单个状态和两个状态概率的计算公式
单个状态
给定模型$\lambda$和观测$O$, 我们可以通过前向后向概率计算求得 在时刻t 处于状态 $q_i$ 的概率:
由前向概率 $\alpha_t(i)$和 后向概率 $\beta_t(i)$ 的定义可知:
于是,我们得到
例题

这就是上面所说的,求单个状态的概率值
- 第一步,列出 $P(i_4 = q_3 |O,\lambda)$ 的式子:
- 第二步,我们要求那些?
首先,我们前向概率要从 $\alpha_1(i)$ 求到 $\alpha_4(i)$ 递推4次 ; 后向概率要从 $\beta_8(i)$求到 $\beta_4(i)$ ,递推5次
第三步,前向计算
初值: $\alpha_1(i) = \pi_ib_i(o_1)$
递推: $\alpha{t+1}(i) = \bigg[\sum{j =1}^N a{ji}\cdot \alpha_t(i)\bigg]\cdot b_i(o{t+1})$
第四步,后向计算
初值: $\beta_8(1)=\beta_8(2)=\beta_8(3) = 1$
递推 : $\betat(i) = \sum{j=1}^N a{ij}\cdot b_j(o{t+1})\cdot\beta_{t+1}(j) $

预测算法
预测问题.已知模型$\lambda = (A,B,\pi)$ 和观测序列$O=(o_1,o_2,\cdots,o_T)$,求对给定观测序列条件概率$P(I|O)$ 最大的状态序列$I=(i_1,\cdots,i_T)$。 维特比算法应用动态规划高效地求解最优路径,即概率最大的状态序列
维特比算法
维特比算法,是用动态规划来解决隐马尔科夫模型预测问题,即用动态规划求概率最大路径(最优路径),这时一条路劲对应着一个状态序列。
根据动态规划原理,最优路径具有这样的特性:如果最优路径在时刻 $t$ 通过结点 $i_t^$,那么这一路径从结点$i_t^$ 到终点$i_T^$ 的部分路径,对于从结点$i_t^$ 到终点$i_T^*$ 的所有可能的部分路径来说,必须是最优的。
根据这一原理,我们只需要
- 从时刻 $t=1$ 开始,递推地计算在时刻t、状态为i的各条部分路径的最大概率,直至得到时刻$t=T$ 、状态为i 的各条路径的最大概率。
- 时刻 $t=T$ 的最大概率即为最优路径的概率 $P^$ ,最优路径的终结点 $i^_T$ 也会同时得到。
- 之后,为了找到最优路径的各个结点,从终结点 $i^T$ 开始,右后向前逐步求得点 $i{T-1}^,\cdots,i{1}^$ , 得到最优路径 $I^ = (i_1^*,\cdots,i{T}^*)$
输入:模型 $\lambda = (A,B,\pi)$ 和观测 $O=(o_1,o_2\cdots,o_T)$
输出:最优路径 $I^ = (i_1^ ,i^_2\cdots,i_T^)$
- 初始化
- 递推
- 终止
- 最优路径回溯:对于 $t=T-1,T-2,\cdots ,1$ 求得最优路径 $I^ = (i_1^,i_2^,\cdots,i_T^)$
例题

- 初始化 , 在 $t = 1$ 时,对每一个状态$i\in{1,2,3}$ ,求 状态为 i , 观测$o_1$为红 的概率,记此概率为 $\delta_1(i)$.则
代入实际数据
递推
在t = 2时
- 对于每个状态$i\in{1,2,3}$, 记最大概率为 $\delta2(i) = \max{1\leq j\leq 3}[\delta1(j)a{ji}]b_i(o_2) $
同时,对于每个状态 $i\in {1,2,3}$ ,我们记录它的最大概率的前一个状态 $j$. $\varPsi2(i) = \arg\max{1\leq j\leq 3}[\delta1(j)a{ji}]~~~i=1,2,3$
在t = 3时
$\delta3(i) = \max{1\leq j\leq3}[\delta2(j)a{ji}]\cdot b_i(o_3)$
$\varPsi3(i) = \arg\max{1\leq j\leq 3}[\delta2(j)a{ji}]~~~i=1,2,3$
在 t = 4 时
$\delta4(i) = \max{1\leq j\leq3}[\delta3(j)a{ji}]\cdot b_i(o_4)$
$\varPsi4(i) = \arg\max{1\leq j\leq 3}[\delta3(j)a{ji}]~~~i=1,2,3$
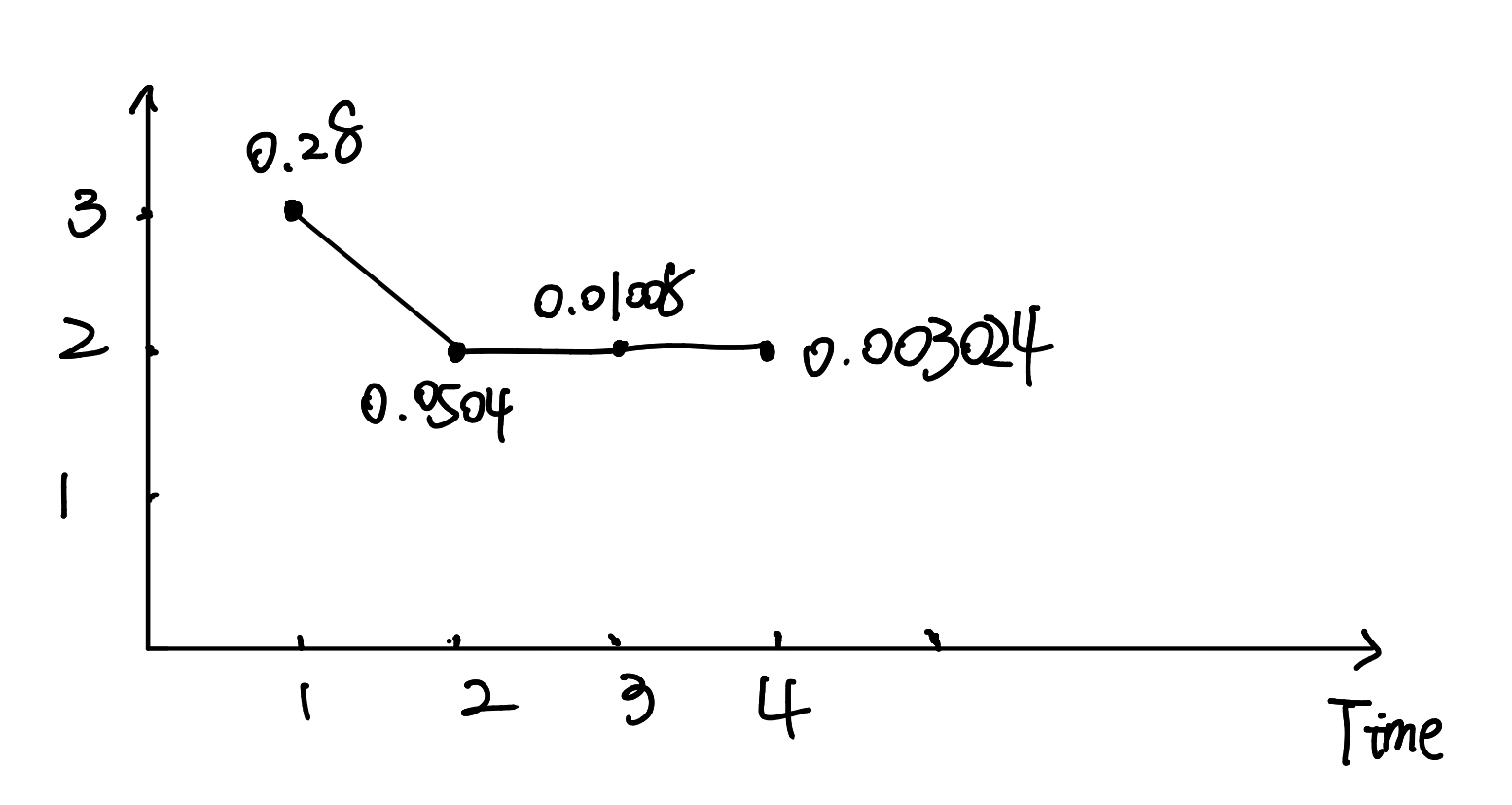
- 用 $P^*$ 来表示最优路径的概率,则:
终点即 $i_4^*= \arg\max_i[\delta_4(i)] = 2$
- 由最优路径的终点 $i^_4$ ,可以逆向找到 $i_3^,i_2^,i_1^$
于是求得最优路径,即最优状态序列 $I^ = (i^_1,i_2^,i_3^)= (3,2,2,2)$