了解Hadoop
Hadoop 可以理解为一个开源的软件平台,它的作用是在计算机集群上分布式存储和分布式处理非常大的数据集。
Hadoop的框架最核心的设计就是:HDFS和 MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算
那么我们为什么要用Hadoop来处理大量数据呢?当数据以 TB为单位产生的时候,使用单个数据库显然是不现实的,因此我们需要使用分布式数据库。
历史
Hadoop最早起源于Yahoo! 的”Nutch”。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。
2003年、2004年谷歌发表的两篇论文为该问题提供了可行的解决方案。
——分布式文件系统(GFS),可用于处理海量网页的存储
——分布式计算框架MapReduce,可用于处理海量网页的索引计算问题。- Nutch的开发人员完成了相应的开源实现HDFS和MapReduce,并从Nutch中剥离成为独立项目Hadoop,到2008年1月,Hadoop成为Apache顶级项目(同年,cloudera公司成立),迎来了它的快速发展期。
- 狭义上来说,hadoop就是单独指代hadoop这个软件;
- 广义上来说,hadoop指代大数据的一个生态圈,包括很多其他的软件
Hadoop的核心架构
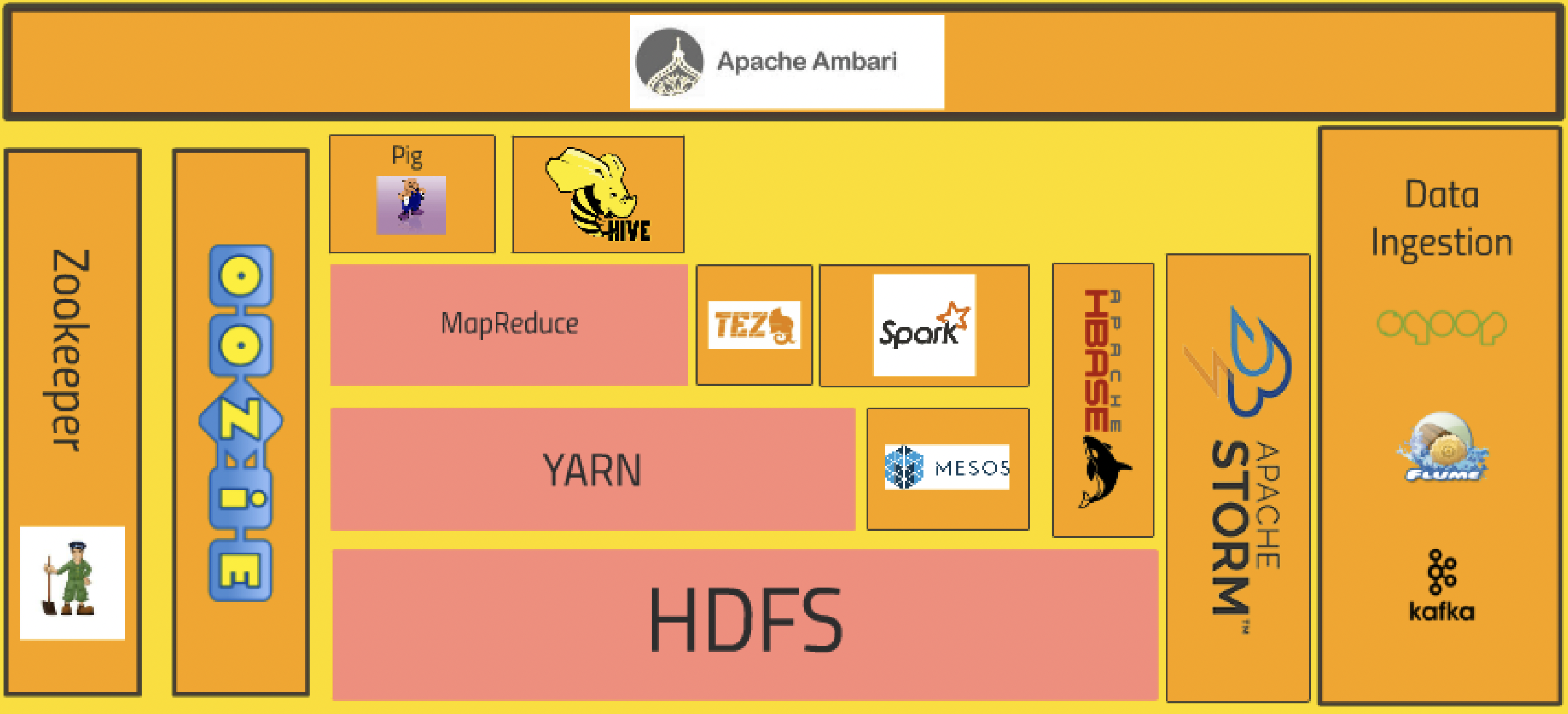
HDFS
HDFS是Hadoop项目的一部分,项目发起者是Doug Cutting,最初Hadoop只是Hadoop Lucene的子项目Nutch(文本搜索库)的一部分。2003年和2004年,Google先后发表了GFS和MapReduce两篇论文,Doug Cutting认为GFS和MapReduce不仅可以解决超大规模的网页存储和分析处理问题,而且是一个通用处理技术。因此Doug Cutting根据GFS和MapReduce的思想创建了Hadoop项目,并从Lucene项目中独立出来。
YARN
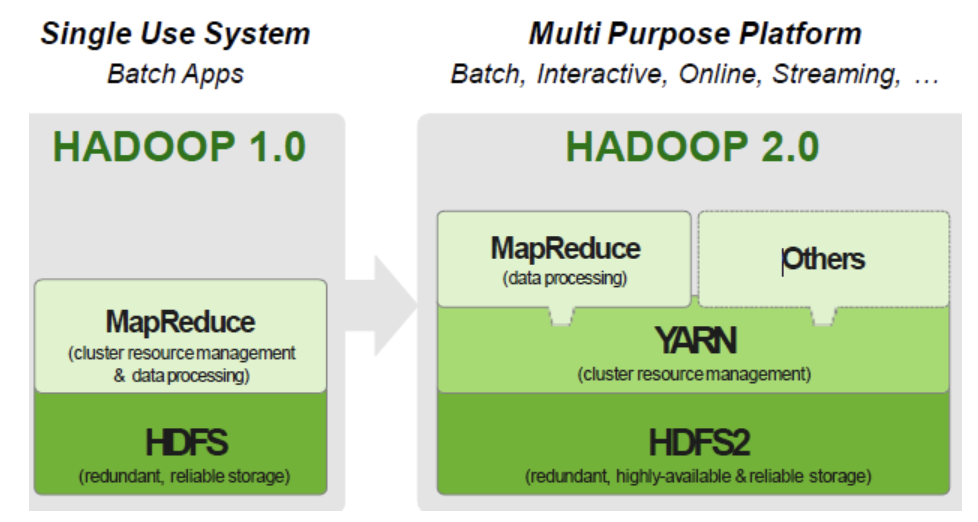
Yarn最初是为MapReduce设计的一种资源管理器,后成为通用的资源管理系统,为上层应用提供统一的资源管理和调度。Yarn的引入为集群在利用率、资源统一管理和数据共享方面带来了好处。2012年8月,Yarn成为了Apache Hadoop的一个子项目。
我们认为:引入Yarn之前的MapReduce为第一代MapReduce,引入Yarn之后的MapReduce为第二代MapReduce,第一代MapReduce存在局限性,其中最为显著的是资源管理和作业紧密耦合。Yarn的出现使得资源管理模块从第一代MapReduce中独立出来,成为一个通用资源管理平台,而MapReduce和Spark等则作为运行于该平台之上的框架。
MapReduce
通常所说的MapReduce一般是指Hadoop项目中的MapReduce,它是Google发表学术论文的一种开源实现,而Google公司内部使用的MapReduce系统并不是开源Hadoop项目中的MapReduce。
MapReduce用于处理大批量静态数据,MapReduce被纳入批处理系统范畴。

Pig
Pig是Hadoop数据操作的客户端是一个数据分析引擎,采用了一定的语法操作HDFS中的数据(Pig应该说是一种语言,有人说Pig是类SQL的语言我这里只能说它的功能类似Sql语言和数据库的关系,而且这里的Sql更像是PLSQL而不是标准SQL,Hadoop中更像标准Sql的应该是Hive或者叫HiveQL),它的语言比较像Shell脚本,可以嵌入Hadoop的JAVA程序中,从而达到简化代码的功能,Pig的脚本叫Pig Latin,之所以说Pig是一个数据分析引擎,是因为Pig相当于一个翻译器,将Pig Latin语句翻译成MapReduce程序,而Pig Latin语句是一种用于处理大规模数据的脚本语言。Pig Latin可完成排序(Order By)、过滤(Where)、求和(Sum)、分组(Group By)、关联(Join)等操作,支持自定义函数;Pig Latin是把类似Sql的语句转换成MapReduce过程进行处理,减少Java 代码的书写,Pig的运行方式有Grunt Shell方式,脚本方式和嵌入式方式。
因此,运用pig 脚本我们可以避免用Java或者Python编写MapReduce程序
Hive
https://www.cnblogs.com/jinb/p/6627521.html
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
Ambari
Ambari是Apache推出的一个集中管理Hadoop的集群的一个平台,可以快速帮助搭建Hadoop及相关组件的平台,管理集群方便。在 HDP中,就是用Ambari来对各类组件进行管理,大部分Hadoop组件都可以通过Ambari安装部署管理,包括HDFS、MapReduce、Hive、Pig、HBase、Zookeeper、Sqoop等。它提供一个可视的仪表盘来查看集群的状态,诊断其性能特征。
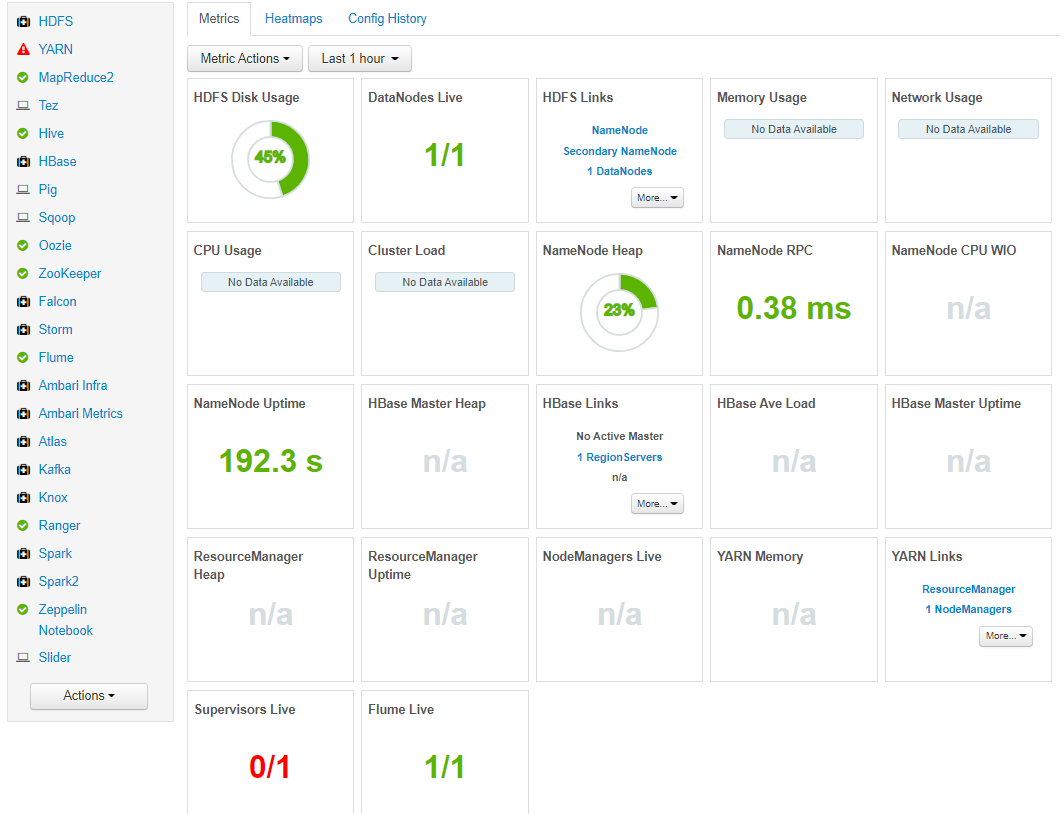
对于Ambari的功能介绍,可以看这篇博客: https://blog.csdn.net/zhangxiongcolin/article/details/83585666
MESOS
Mesos是一个集群管理平台,和YARN是类似的。 可以理解为是一种分布式系统的kernel, 负责集群资源的分配, 这里的资源指的是CPU资源, 内存资源, 存储资源, 网络资源等。 在Mesos可以运行Spark, Storm, Hadoop, Marathon等多种Framework(框架)。
Mesos的架构主要有Masters(主节点), Slaves(从节点), 和 及在Mesos上运行的Framework(框架)组成。 各个部分的分工如下:
Master: 负责处理Slave节点和Framework间的资源通讯, 根据指定的策略来决定分配多少资源给framework。
Slave: 启动本地进程, 同时向Master报告有哪些资源可用。
Framework: 接收来自Master提供的Slave节点的资源(如CPU和内存), Framework由调度器(负责监控和管理Slave的状态)和执行器(负责在服务器执行应用程序代码)组成。
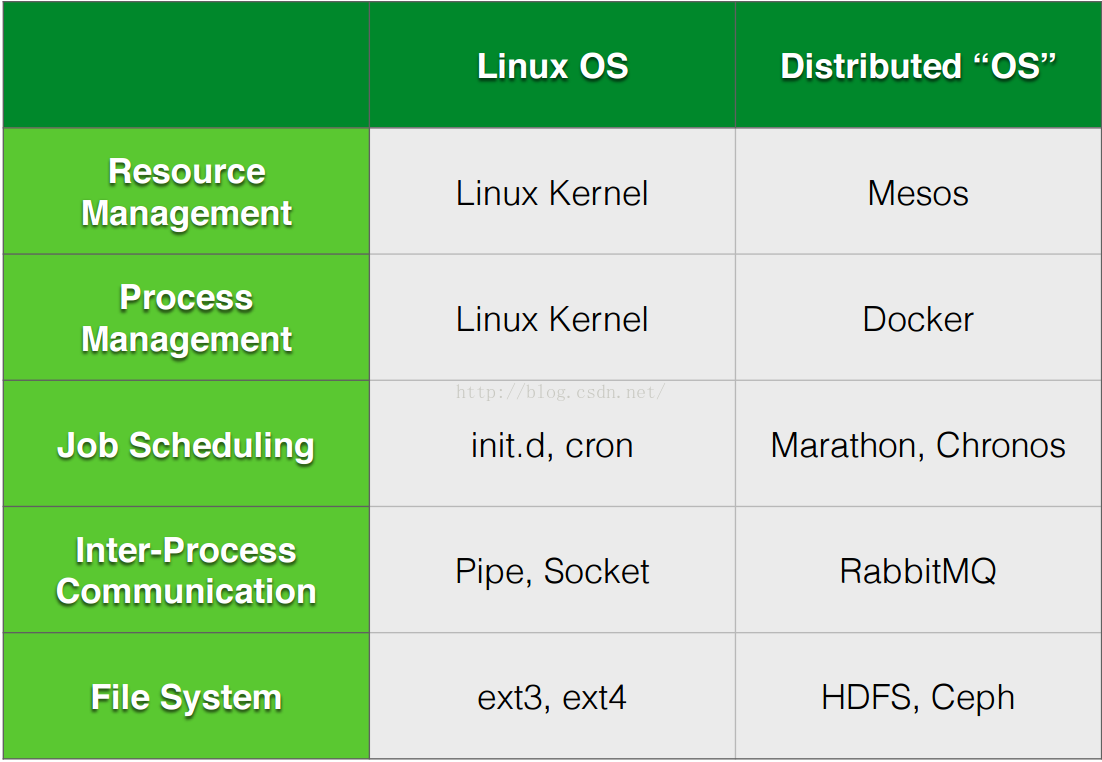
Mesos本身只提供资源的分配, 并不涉及存储, 任务调度等功能, 所以它要和其它软件或者系统搭配使用才能构成完整的分布式系统。 Mesos, Docker, Marathon/Chronos, RabbitMQ, HDFS/Ceph构成了一个完整的分布式系统, 分别负责资源分配, 进程管理,任务调度, 进程间通信和文件系统的功能。 这里可以和Linux做一个横向的比较。 如图1所示:
TEZ
MapReduce模型虽然很厉害,但是它不够的灵活,一个简单的join都需要很多骚操作才能完成,又是加标签又是笛卡尔积。那有人就说我就是不想这么干那怎么办呢?Tez是一种新的解决方法
Tez采用了DAG(有向无环图)来组织MR任务(DAG中一个节点就是一个RDD,边表示对RDD的操作)。它的核心思想是把将Map任务和Reduce任务进一步拆分,Map任务拆分为Input-Processor-Sort-Merge-Output,Reduce任务拆分为Input-Shuffer-Sort-Merge-Process-output,Tez将若干小任务灵活重组,形成一个大的DAG作业。
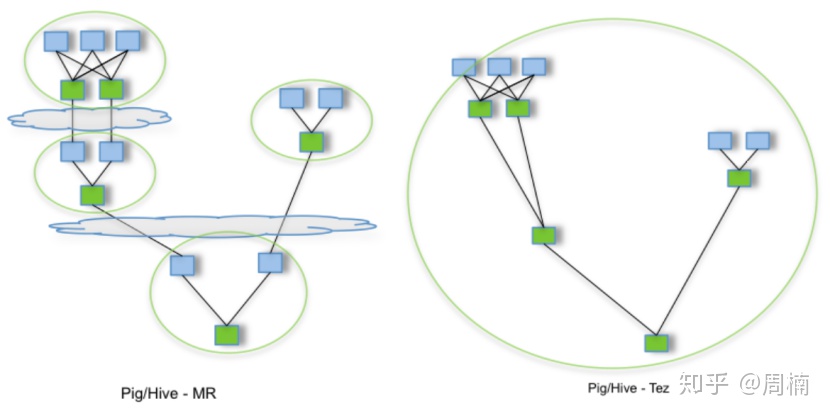
上图中蓝色框表示Map任务,绿色框表示Reduce任务,云图表示写动作,可以看出,Tez去除了MR中不必要的写过程和Map,形成一张大的DAG图,在数据处理过程中没有往hdfs写数据,直接向后继节点输出,从而提升了效率。
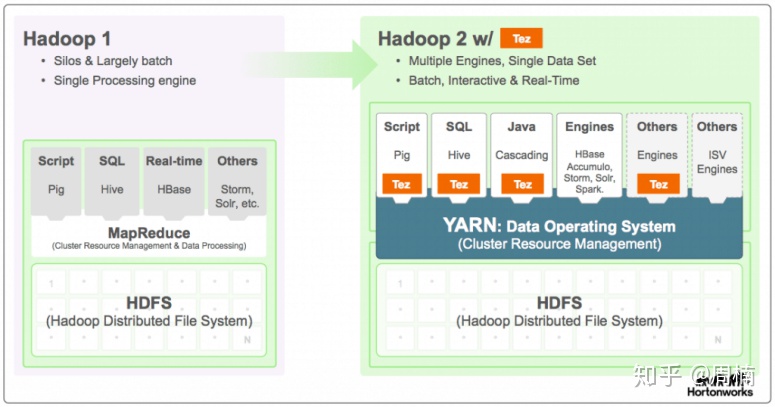
上图是Hadoop1到Hadoop2所做的改变,Hadoop1主要使用MapReduce引擎,到了Hadoop2,基于yarn,可以部署spark,tez等计算引擎,这里MapReduce作为一种引擎实现用的越来越少了,但是作为框架思路,tez本身也是MapReduce的改进。
Spark
Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发的通用内存并行计算框架
Spark是在借鉴了MapReduce之上发展而来的,继承了其分布式并行计算的优点并改进了MapReduce明显的缺陷,具体如下:
首先,Spark把中间数据放到内存中,迭代运算效率高。MapReduce中计算结果需要落地,保存到磁盘上,这样势必会影响整体速度,而Spark支持DAG图的分布式并行计算的编程框架,减少了迭代过程中数据的落地,提高了处理效率。
其次,Spark容错性高。Spark引进了弹性分布式数据集RDD (Resilient Distributed Dataset) 的抽象,它是分布在一组节点中的只读对象集合,这些集合是弹性的,如果数据集一部分丢失,则可以根据“血统”(即充许基于数据衍生过程)对它们进行重建。另外在RDD计算时可以通过CheckPoint来实现容错,而CheckPoint有两种方式:CheckPoint Data,和Logging The Updates,用户可以控制采用哪种方式来实现容错。
最后,Spark更加通用。不像Hadoop只提供了Map和Reduce两种操作,Spark提供的数据集操作类型有很多种,大致分为:Transformations和Actions两大类。Transformations包括Map、Filter、FlatMap、Sample、GroupByKey、ReduceByKey、Union、Join、Cogroup、MapValues、Sort和PartionBy等多种操作类型,同时还提供Count, Actions包括Collect、Reduce、Lookup和Save等操作。另外各个处理节点之间的通信模型不再像Hadoop只有Shuffle一种模式,用户可以命名、物化,控制中间结果的存储、分区等。
HBase
Apache HBase 是 Hadoop 数据库,一个分布式、可伸缩的大数据存储。
HBase是依赖Hadoop的。为什么HBase能存储海量的数据?因为HBase是在HDFS的基础之上构建的,HDFS是分布式文件系统。
HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。
此外,Pig和Hive还为HBase提供了高层语言支持,使得在HBase上进行数据统计处理变的非常简单。 Sqoop则为HBase提供了方便的RDBMS数据导入功能,使得传统数据库数据向HBase中迁移变的非常方便。
ZooKeeper
ZooKeeper 顾名思义 动物园管理员,他是拿来管大象(Hadoop) 、 蜜蜂(Hive) 、 小猪(Pig) 的管理员, Apache Hbase和 Apache Solr 以及LinkedIn sensei 等项目中都采用到了 Zookeeper。ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,ZooKeeper是以Fast Paxos算法为基础,实现同步服务,配置维护和命名服务等分布式应用。
ZooKeeper可以用来跟踪各个节点的状态
Oozie
Oozie是一个工作流调度系统。 最初是由Cloudear公司开发,后来贡献给Apache。 它能够提供对Hadoop MapReduce和Pig Jobs的任务调度与协调。Oozie需要部署到Java Servlet容器中运行。’
Oozie定义了控制流节点(Control Flow Nodes)和动作节点(Action Nodes),其中控制流节点定义了流程的开始和结束,以及控制流程的执行路径(Execution Path),如decision、fork、join等;而动作节点包括Hadoop map-reduce、Hadoop文件系统、Pig、SSH、HTTP、eMail和Oozie子流程。
Apache Storm
Apache Storm是一个免费开源、分布式、高容错的实时计算系统。Storm令持续不断的流计算变得容易,弥补了Hadoop批处理所不能满足的实时要求。Storm经常用于在实时分析、在线机器学习、持续计算、分布式远程调用和ETL等领域。
Storm主要分为两种组件Nimbus和Supervisor。这两种组件都是快速失败的,没有状态。任务状态和心跳信息等都保存在Zookeeper上的,提交的代码资源都在本地机器的硬盘上。
- Nimbus 负责在集群里面发送代码,分配工作给机器,并且监控状态。全局只有一个。
- Supervisor 会监听分配给它那台机器的工作,根据需要启动/关闭工作进程Worker。每一个要运行Storm的机器上都要部署一个,并且,按照机器的配置设定上面分配的槽位数。
- Zookeeper是Storm重点依赖的外部资源。Nimbus和Supervisor甚至实际运行的Worker都是把心跳保存在Zookeeper上的。Nimbus也是根据Zookeerper上的心跳和任务运行状况,进行调度和任务分配的。
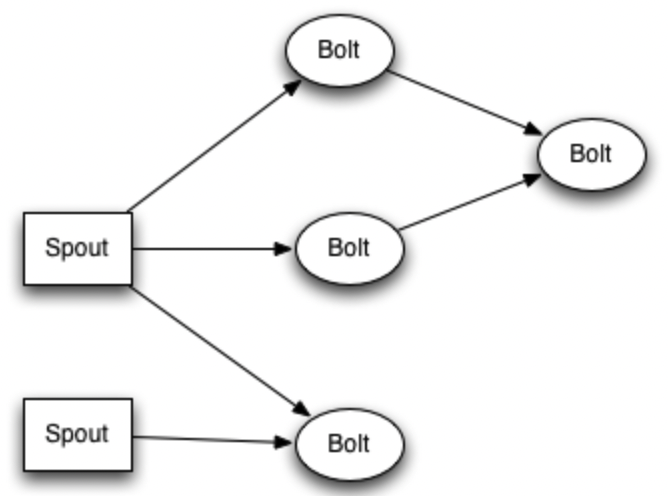
- Topology 处理的最小的消息单位是一个Tuple,也就是一个任意对象的数组。Storm提交运行的程序称为Topology。
- Topology 由Spout和Bolt构成。Spout是发出Tuple的结点。Bolt可以随意订阅某个Spout或者Bolt发出的Tuple。Spout和Bolt都统称为component。
Data Ingestion
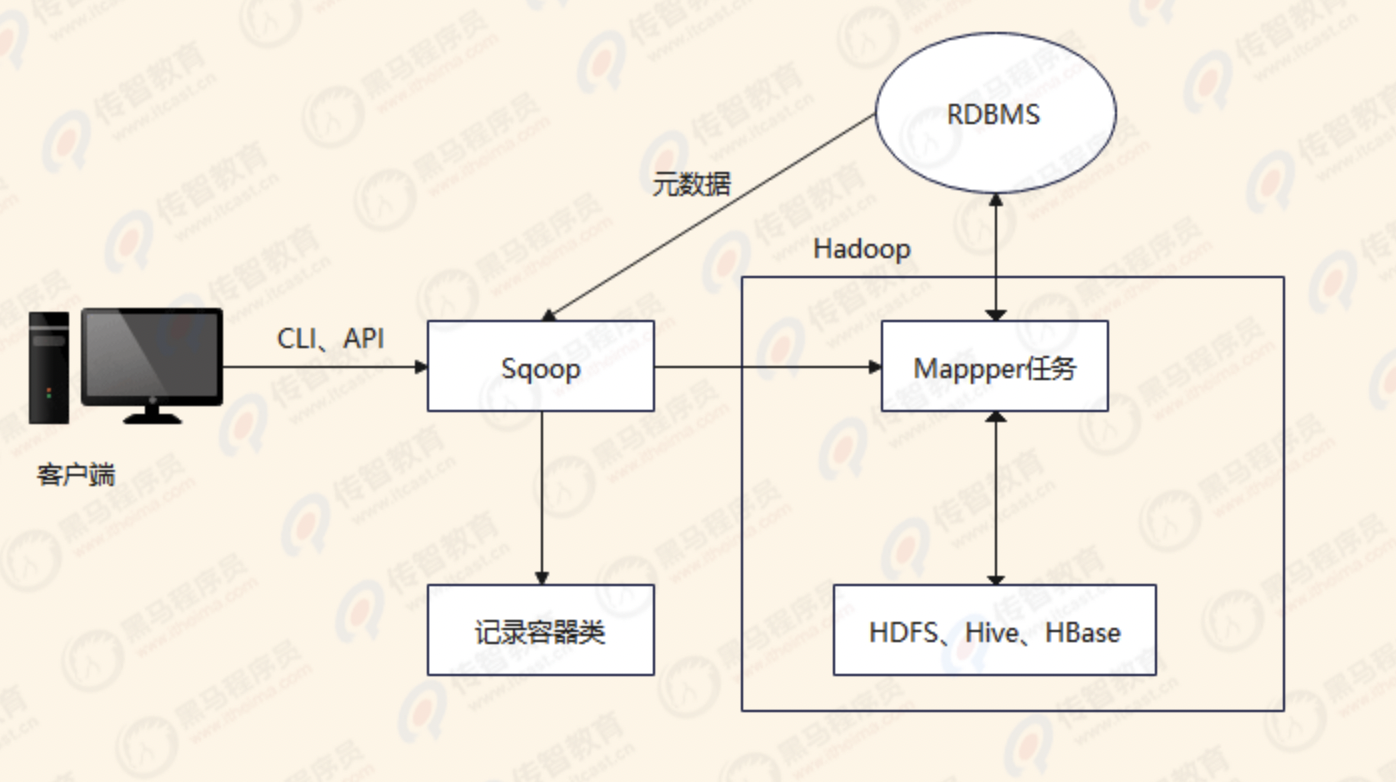
Sqoop
Sqoop是Apache旗下的一款开源工具,该项目开始于2009年,最早是作为Hadoop的一个第三方模块存在,后来为了让使用者能够快速部署,也为了让开发人员能够更快速的迭代开发,并在2013年,独立成为Apache的一个顶级开源项目。
Sqoop主要用于在Hadoop和关系数据库或大型机之间传输数据,可以使用Sqoop工具将数据从关系数据库管理系统导入(import)到Hadoop分布式文件系统中,或者将Hadoop中的数据转换导出(export)到关系数据库管理系统,其功能如下图所示。
Flume
Flume是一种分布式,可靠且可用的服务,用于有效地收集,聚合和移动大量日志数据。Flume构建在日志流之上一个简单灵活的架构。它具有可靠的可靠性机制和许多故障转移和恢复机制,具有强大的容错性。使用Flume这套架构实现对日志流数据的实时在线分析。Flume支持在日志系统中定制各类数据发送方,用于收集数据
Kafka
Apache Kafka是一个分布式发布 - 订阅消息系统和一个强大的队列,可以处理大量的数据,并使你能够将消息从一个端点传递到另一个端点。 Kafka适合离线和在线消息消费。 Kafka消息保留在磁盘上,并在群集内复制以防止数据丢失。 Kafka构建在ZooKeeper同步服务之上。 它与Apache Storm和Spark非常好地集成,用于实时流式数据分析。
Kafka 是一个分布式消息队列,具有高性能、持久化、多副本备份、横向扩展能力。生产者往队列里写消息,消费者从队列里取消息进行业务逻辑。一般在架构设计中起到解耦、削峰、异步处理的作用。
外部数据存储工具
MySQL
mongoDB
cassandra
cassandra是一套开源分布式NoSQL数据库系统
cassandra的特点:
1、弹性可扩展。
2、始终基于架构,没有单点故障。
3、快速线性性能。
4、灵活的数据存储,支持结构化,半结构化和非结构化。
5、便捷数据分发,多数据中心间复制数据。
6、支持事务。
7、快速写入。
搜索引擎
Apache Drill
在大数据时代,对于Hadoop中的信息,越来越多的用户需要能够获得快速且互动的分析方法。大数据面临的一个很大的问题是大多数分析查询都很缓慢且非交互式。目前来看,MapReduce通常用于执行Hadoop数据上的批处理分析,但并不适合于你想快速得到结果或者重新定义查询参数。Google的Dremel能以极快的速度处理网络规模的海量数据。据谷歌的研究报告显示,Dremel能以拍字节(petabyte,PB,1PB等于1024TB)的数量级来进行查询,而且只需几秒钟时间就能完成。而其对应的开源版本就是Drill。(ps:drill其实就是一个分布式实时数据分析查询的引擎。Drill,一个专为互动分析大型数据集的分布式系统。)
Hue
HUE=Hadoop User Experience
Hue是一个开源的Apache Hadoop UI系统,由Cloudera Desktop演化而来,最后Cloudera公司将其贡献给Apache基金会的Hadoop社区,它是基于Python Web框架Django实现的。
通过使用Hue,可以在浏览器端的Web控制台上与Hadoop集群进行交互,来分析处理数据,例如操作HDFS上的数据,运行MapReduce Job,执行Hive的SQL语句,浏览HBase数据库等等。
- Hue能做什么
- 访问HDFS和文件浏览
- 通过web调试和开发hive以及数据结果展示
- 查询solr和结果展示,报表生成
- 通过web调试和开发impala交互式SQL Query
- spark调试和开发
- Pig开发和调试
- oozie任务的开发,监控,和工作流协调调度
- Hbase数据查询和修改,数据展示
- Hive的元数据(metastore)查询
- MapReduce任务进度查看,日志追踪
- 创建和提交MapReduce,Streaming,Java job任务
- Sqoop2的开发和调试
- Zookeeper的浏览和编辑
Presto
presto是Facebook开源的,完全基于内存的并⾏计算的,分布式SQL交互式查询引擎
是一种Massively parallel processing (MPP)架构,多个节点管道式执⾏⽀持任意数据源(通过扩展式Connector组件),数据规模GB~PB级
使用的技术,如向量计算,动态编译执⾏计划,优化的ORC和Parquet Reader等
presto不太支持存储过程,支持部分标准sql
presto的查询速度比hive快5-10倍
和hive的对比:
hive是一个数据仓库,是一个交互式比较弱一点的查询引擎,交互式没有presto那么强,而且只能访问hdfs的数据
presto是一个交互式查询引擎,可以在很短的时间内返回查询结果,秒级,分钟级,能访问很多数据源
hive在查询100Gb级别的数据时,消耗时间已经是分钟级了
但是presto是取代不了hive的,因为p全部的数据都是在内存中,限制了在内存中的数据集大小,比如多个大表的join,这些大表是不能完全放进内存的,实际应用中,对于在presto的查询是有一定规定条件的,比比如说一个查询在presto查询超过30分钟,那就kill掉吧,说明不适合在presto上使用,主要原因是,查询过大的话,会占用整个集群的资源,这会导致你后续的查询是没有资源进行查询的,这跟presto的设计理念是冲突的,就像是你进行一个查询,但是要等个5分钟才有资源继续查询,这是很不合理的,交互式就变得弱了很多
Phoenix
phoenix:构建在hbase上的一个SQL层,让我们可以用标准的JDBC APIs来创建表,插入数据和对HBase数据进程查询。
Apache Zeppelin
Apache Zeppelin提供了web版的类似ipython的notebook,用于做数据分析和可视化。背后可以接入不同的数据处理引擎,包括spark, hive, tajo等,原生支持scala, java, shell, markdown等。它的整体展现和使用形式和Databricks Cloud是一样的,就是来自于当时的demo。
Zeppelin 提供了内置的 Apache Spark 集成。你不需要单独构建一个模块、插件或者库。
Zeppelin的Spark集成提供了:
- 自动引入SparkContext 和 SQLContext
- 从本地文件系统或maven库载入运行时依赖的jar包。
- 可取消job 和 展示job进度