了解区块链
部分内容引用自: https://www.zhihu.com/question/37290469
思考
首先我们要问自己三个问题:
一个去中心化的数字货币系统是什么样的
说到数字货币,我们首先想到的就是三个最明显的特征:防篡改、可追溯以及去中心化。那么什么是去中心化?简单来说就是P2P(peer to peer)模式,在这个模式中,没有中心式服务器,用户和用户之间是对等的。用户之间采用Gossip协议来传播消息。
这里岔开来简单介绍一下Gossip协议的执行过程:Gossip 过程是由种子节点发起,当一个种子节点有状态需要更新到网络中的其他节点时,它会随机的选择周围几个节点散播消息,收到消息的节点也会重复该过程,直至最终网络中所有的节点都收到了消息。这个过程可能需要一定的时间,由于不能保证某个时刻所有节点都收到消息,但是理论上最终所有节点都会收到消息,因此它是一个最终一致性协议。
那么,在这样一个去中心化的数字货币系统,在没有国家信用背书的情况下,应该设计什么?
- 第一个问题是开户,在这样一个数字货币系统中开户,需要什么?
这就要我们了解公钥和私钥的概念:我们可以把公钥理解为我们的身份证,把私钥理解为要支取货币、进行交易时候需要输入的密码。
- 第二个问题是当没有了一个中心化的服务器,各个结点应该如何存储数据?
答案是,每一份节点都需要存储全量的数据。因为当没有中心服务器的时候,如果每个人只存放了部分数据,一些人可能会篡改交易记录,导致违背了防篡改的原则。
一个永不停机的世界计算机系统是什么样的
既然说,这个系统要永不停机,而且还要是P2P的。就要求这个系统有高可用、高可靠的特性。因此,这个问题的答案和上一个问题有一定的重合——要求每一个节点要有全量的数据。
为了解释清楚为什么要这样做,我们可以说一个故事:
【1:一个公共账本】
假如你现在在上大学,你们寝室是标准的四人寝,除了你之外还有小王,小黄和小白三个室友。平时你们亲是内部的活动很多,于是经常会有人垫付饭钱,车费,还有水电费。你们大家发现,如果每次消费后,都要一一计算交结非常麻烦,于是你们决定采用记账的方案。
于是乎,你们买了一个公共的账本,本次产生消费后,就由付钱的人在账本上记清楚,谁应付给自己相应的金额。如此一来,只要每月月末统一结算即可,大大节省了时间精力。
时间一长,你们发现在纸上记账还是麻烦。于是你们决定”升级“这个账本,改成在电脑种建立一个excel表格,比如这个样子:

但问题是,如果你们寝室里有个人不厚道,偷偷修改账本怎么办呢?
例如小王把自己要付钱记在了小白头上。如果这个问题不能得以解决,那这个账本的信用就将会大大折扣。
【2:每个人都有账本】
他们采用的解决方案就是,给四个人每人都配备一个账本。需要记录时,就由对应的操作人高喊交易内容,广播给寝室里的所有人。
例如,小王高喊,”小王需要支付给小白30元 “。然后寝室里其他人听到了,就在各自的小本本上记下,”小王需要支付给小白30元 “。
如此一来,就算小王故意使坏,把自己要付的钱记在别人身上,那也只能是篡改自己的账本。这样到月底时,小王的账本和其余三个人对应不上,便能知道小王的账本有问题。
从上面这个故事可以很清楚的了解,为什么每一个节点都需要保存全量的数据。但是我们还有一个很重要的问题没有解决:我们知道,在分布式数据库中,为了解决宕机、故障时,需要使用Paxos、raft协议来保证各个分布式数据库的数据不发生错误。但是,在这种区块链系统中,Paxos是否还能达到这种效果呢?
答案是不行的,因为在这个系统里面存在背叛者。也就是经典的拜占庭将军问题——如果小王恶作剧,不负责任的乱喊“小白需要支付给小王100元”,如此一来,很可能会有不明真相的舍友记录下来;或者说,付了钱而不喊出来。那么这个账本就乱套了。
因此,可以解决拜占庭容错的方案需要被提出,也就是数字签名
【3:在交易记录后签名】
这个问题在纸质帐本里很好解决,那就是在每一条记录后,由需付款的一方加上自己的手写签名,以示自己认可这笔记录。这个思路换到计算机中就是数字签名,所以我们要求每一笔记录后面,都要由需付款的一方加上自己的数字签名。
元宇宙中支撑虚拟资产交易的基础设施是什么
在中心化系统中,DBA具有至高无上的权利,但是在去中心化的场景下,是一个无政府主义情况,没有一个绝对的权威。那么,它的基础设施就是我们今天要学习的——区块链。
比特币
上面这个账本还存在一些问题,使得只适合小范围使用,如果扩大到更大的范围,比如整个学校使用,这个时候交易量和用户数剧增,记录就会变得非常麻烦。
比特币的正是为了解决这个问题而对前面介绍的账本系统的改进。
改进一:交易单位为比特币BTC
我们之前用的账本里面的交易单位是人民币,但在比特币系统中,我们的交易单位变为比特币。
改进二:将记账改为事实交易支付
之前的账本是在月底结账,而现在我们把交易单位改成了虚拟的比特币,交易也由月底统一交割改为事实交割。而比特币就像是账本上的数字,随时都可以视大家的意见进行”套现“,即在现实中交割。
那么要完成比特币交易,就必须要求用户的账本里的比特币余额是足够多的。在传统的银行系统中(中心化系统),银行会记录储户的账余额,判断能否进行交易。但是在比特币系统中我们并没有这样一个中心,所以不能像银行这样来进行操作。
因此比特币提出的解决方案是:每笔交易不余额为基础,而是以以前的交易为基础。在这里我们就要介绍比特币的记账模型:UTXO(Unspent Transaction Out),字面意思就是尚未被花出去的交易额
UTXO
概念
这个记账模型的理念就是:一切的交易,都是可追溯的, 交易与交易之间组成了网状关系,一个交易的输出,成为了下一个交易的输入;下一个交易的输出,又成了下下一个交易的输入。
如下图:
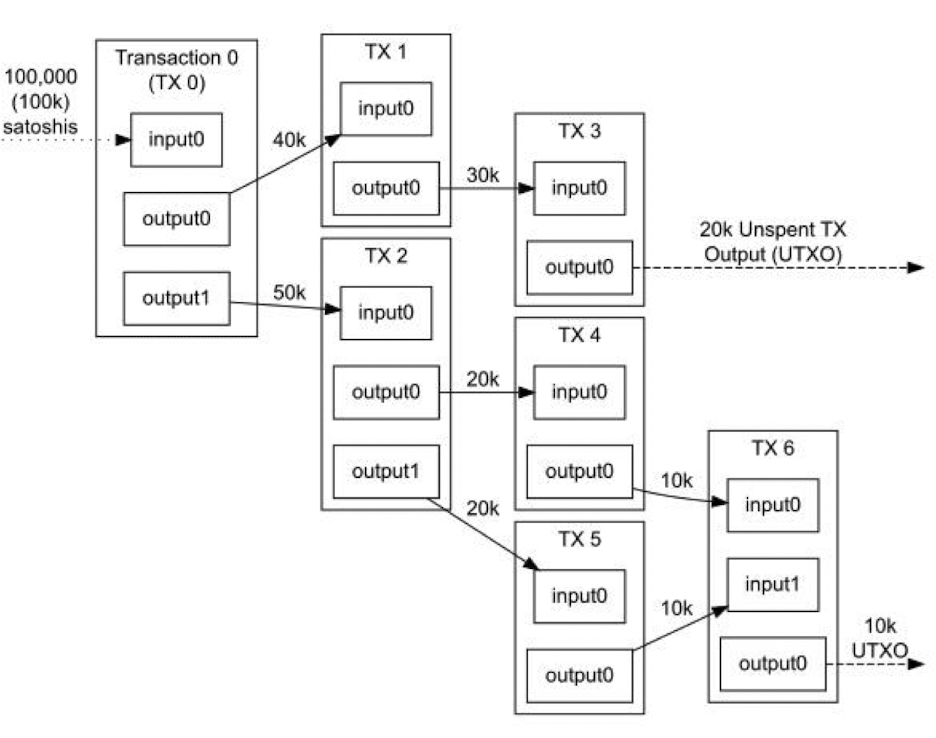
我们可以举一个例子:现在user1和user2达成了一笔交易,user1需要支付给user2 一共37个BTC,那么首先user1的账户余额里面的BTC个数是要大于37个的。
- 问题1:怎么计算user1账户中的余额?
- 因为在比特币系统中,并不像银行一样直接存储账号里有多少钱。而存储的是一笔笔的交易,也就是一笔笔的UTXO。然后,某个人的钱包的余额就等于他的UTXO的总和。比如说在这个user1的账户中,一共有3笔UTXO,金额分别是5,15和20,加起来一共是40BTC。余额是大于37BTC的,因此这笔交易可以进行
- 问题2:为什么不直接支付37元,而是要用更复杂的先支付40BTC,再让user2找user1 钱呢?
- 因为在UTXO中,每笔交易的金额是不能够被拆分的。对user1来说,他将T2、T3转给user2之后,是不能将T1交易额中的5BTC拆出2BTC转给user2的,要给就一起给。
- 打个比方,就好比你拿了一堆纸币去买东西,你必须从这堆纸币中选出几张,是的纸币的面值之和大于这笔交易的金额。你只能要求商家将多余的钱找给你,而不能说把纸币撕成两半花
- 问题3:在真实的比特币交易中,这种方法难道不会徒增麻烦吗?
- 这只是比特币交易的底层实现逻辑。事实上在上层有比特币钱包这种软件可以帮你计算UTXO、选择哪几个UTXO进行支付等。对用户来说这是完全透明的
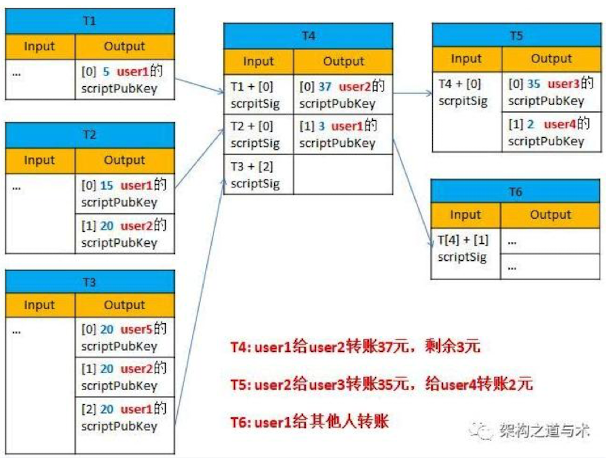
总结:
- 任何一笔Transaction ,汇划费多个UTXO(Input), 同时也会产生多个新的 UTXO(Output), 属于多个不同的收款人
- 1个UTXO = 1个Transaction ID + Output Index
- 旧的UTXO不断消亡新的UTXO不断产生,所有的UTXO组成了UTXO Set的数据库,存在于每个节点。
- 任何一笔UTXO,有且尽可能被一个交易花费1次,也就是说具有不可拆分性。(以纸币类比)
模型
UTXO(Unspent TX Output)译名为未花费的交易输出,UTXO模型的设计基于一种思路:除了铸币(Coinbase)交易生成的比特币,任意一笔钱不会凭空产生,也不会凭空消失。UTXO由四部分组成;
address: 拥有此UTXO的地址;
amount: 此UTXO的金额;
- Signature Script: UTXO解锁脚本,使用交易发送私钥加密交易内容得到的签名;
- Pubkey Script: UTXO锁定脚本,包含交易获得方的公钥哈希。
上面提及了比特币中的解锁脚本(Signature Script)与锁定脚本(PubKey Script)。比特币脚本是一种基于栈结构的无状态脚本语言,只能进行有限的操作,图灵不完备。虽然简单,但在数字货币领域,也意味着更少的金融风险。
在UTXO 模型中,交易只是代表了 UTXO 集合的变更。而账户和余额的概念是在 UTXO 集合上更高的抽象,账号和余额的概念只存在于钱包中。以比特币钱包为例,钱包管理的是一组私钥,对应的是一组公钥和地址。要查看钱包余额,必须从创世区块开始扫描每一笔交易,如果:
遇到某笔交易的某个Output是钱包管理的地址之一,则钱包余额增加;
遇到某笔交易的某个Input是钱包管理的地址之一,则钱包余额减少。
所以从狭义上来说,比特币钱包中并没有比特币,只有钱包地址关联的所有UTXO之和,代表着钱包地址拥有这些比特币的所有权。
现在我们举一个实际情况中转账交易的例子:假设Alice有amount个比特币
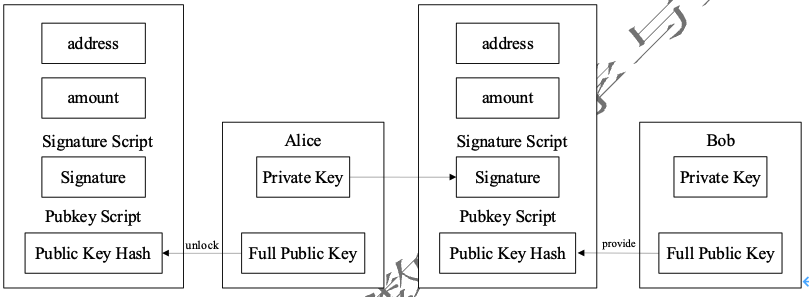
- Alice使用公钥解锁自己的UTXO,构造新的UTXO和一笔转账交易。
- Alice使用私钥对UTXO的交易内容进行签名:将UTXO的输出地址为Bob的钱包地址,并把Bob的公钥Hash作为解锁此UTXO的凭据
- 经过6个区块确认(证明该笔交易极大概率合法)之后,这amount个比特币就属于Bob了。实际上,Bob拥有的是这笔转账交易的UTXO
从比特币的记账模式来看,所有的交易记录都是可以被追踪的。因此,在一些灰色产业(如洗钱)中,用户为了抹去自己的交易记录,会采用洋葱路由的方式,将交易洗牌以后重新组合来规避法律风险。
改进三:不留证明,改留比特币账号
如上图,用户A并不用留下自己的名字,而是用一个字符串来代表自己进行交易:
- 1H6ZZpRmMnrw8ytepV3BYwMjYYnEkWDqVP
同理,用户B和C也是如此,只留下了一个字符串。所以你们室友在帐本里都不写名字,而是写下跟各自对应的字符串,即比特币账户。虽然对于你们四个人的寝室这纯属脱裤子放屁,但如果对于规模更大的系统,比如前文提到的整个学校而言,这种操作可以极大提升隐私性。
我们只能知道每个账户,而无法知道谁拥有这个账户,这就保证了隐私性。
区块链
区块链简介
前面我们提到了这个账本是分布式存储的,每个人都有一个自己独立管理的账本。
当这个账本系统变得很大时,一致性问题就必须要考虑。比如,如果你有室友在交易记录发布时不在寝室,那么他就错了这次消息,使得这次消息不会出现在他的帐本里。
换回比特币系统,也就是部分电脑可能处于关机或者未联网状态,会错过部分交易。此外,还可能会有黑客入侵部分电脑,篡改交易记录。
此外,还有一个更严重的问题就是,实际网络拓扑非常复杂,链路质量的随机性很大。因此,如果用户A(假设账户里有10BTC)连续广播两条相互矛盾的消息,比如:
- 交易信息1:用户A支付10BTC给B;
- 交易信息2:用户A支付10BTC给C;
有的读者应该会觉得,那我们就采信先收到的交易信息1,忽略与之矛盾的脚印信息2不就行了。
但问题是,因为网络链路的复杂性,所以很可能存在部分用户先收到交易信息1,又有部分用户先收到交易信息2。如果依靠先后顺序辨别有效性,那么就会存在不同用户记录的交易信息不一致。
为了解决这个问题,中本聪提出了区块链的概念。
每个用户如果愿意,都可以整理自己从网络中接收到的交易信息,然后检查其是否合理(每笔交易是否由足够余额?数字签名是否正确?)后,再将交易记录打包成一个区块。每个区块有多笔交易(两三千笔)。
因此每个交易记录都是以区块的形式存储,然后再广播到系统中的其他用户中。而区块之间相互连接,形成一条由系统内全体用户共同维护的区块链。

因此其他用户收到广播的区块时,就会把这个区块加到自己维护的账本,也就是区块链的尾部。
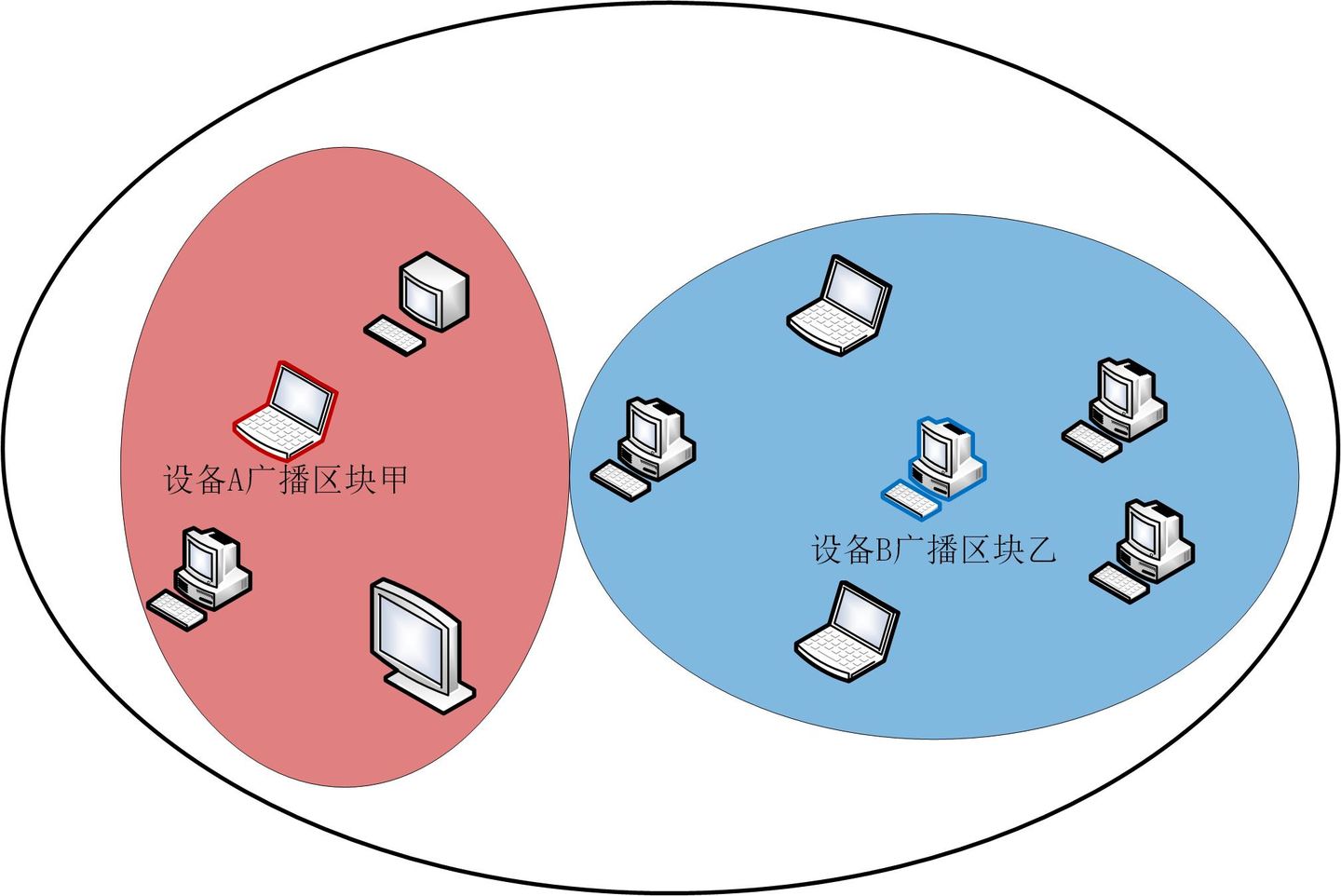
但如果只是这样,并没有解决任何问题。互联网节点遍布全球,广播过程也需要时间,因此肯定会存在不同节点收到不同区块存储的问题。
以此图为例,设备A和设备B几乎同时发布了自己的区块,两者的区块并不相同。很好理解:
- 红色区域中的用户离设备A近,会先收到设备A发的区块甲;
- 蓝色区域中的用户离设备B近,会先收到设备B发的区块乙;
然后,不同的用户会将不同的区块加入到自己维护的区块链尾部,生产不同的区块链。
如此一来这个网络就乱套了。为了降低传播时间的影响,一个简单粗暴的方式就是从系统设计中就限制区块生成的速度。比特币系统的核心思想采就是用算力限制区块的生成速度。
比特币系统要求,每个用户在发布新区块前,必须先完成一个任务。这个任务就是:
- 根据前一区块的一些信息加上新区块的一些信息,生成一个字符串S;
- 选择一个字符串B,与S合并成“BC”,且要求“BC”的哈希映射满足某个条件,比如映射结果的前72位为0(概率:2^(-72));
上面的第2步,除了一个个试以外是没有捷径的,而且结果是否满足要求可以快速试出。举个例子就相当于给你一个银行卡,让你挨个试密码。那你没有任何办法,只能000000-999999挨个试验,最后虽然能试出来,但也会花费大量时间。而且你把试出来的结果告诉别人后,别人可以很快验证你的结果是否正确
时间恰好是我们宇宙中最稀缺的资源。因此我们可以调节这个难度,比如使得系统中所有平均每20分钟才会有一台设备完成要求的任务,猜出符合要求的字符串B。如此一来,撞车的概率就会大大降低。补充一句,这个难度是不断调节的,以适应硬件算力的提升。
区块链分类
我们可以大致把联盟链分为三类:公有链、私有链、联盟链
- 公有链:Public blockchains
- 公有链没有官方组织及管理机构,没有中心服务器,参与的节点按照系统规则自由接入网络、不受控制,节点间基于共识机制开展工作
比特币就是一个典型的公有链
- 私有链:Private blockchains
- 建立在某个企业内部,系统的运作规则根据企业要求进行设定,仅有少数节点拥有修改、读取的权限,同时仍保留着区块链的真实性和部分去中心化的特性。
- 联盟链
- 联盟链由若干机构联合发起,介于公有链和私有链之间,兼具部分去中心化的特性。联盟管理员可以根据业务要求限制某些用户的读取权限。并限制某些节点参与共识计算
- 可以理解为一个特殊的分布式数据库
私有链和联盟链可以被统称为许可链,公有链又可以被称为非许可链。要进入许可链,需要一个身份证。
挖矿(POW)
比特币机制
系统为了鼓励大家生成新的区块,于是在开始时就定下规则:
- 每当一个新区块加入主链,这个区块的发行者就会被赠与50个BTC;
- 每21万个区块后,奖励额度缩水一半;
这也就解释了,为什么BTC的发行上限是:
也就是2100万个。
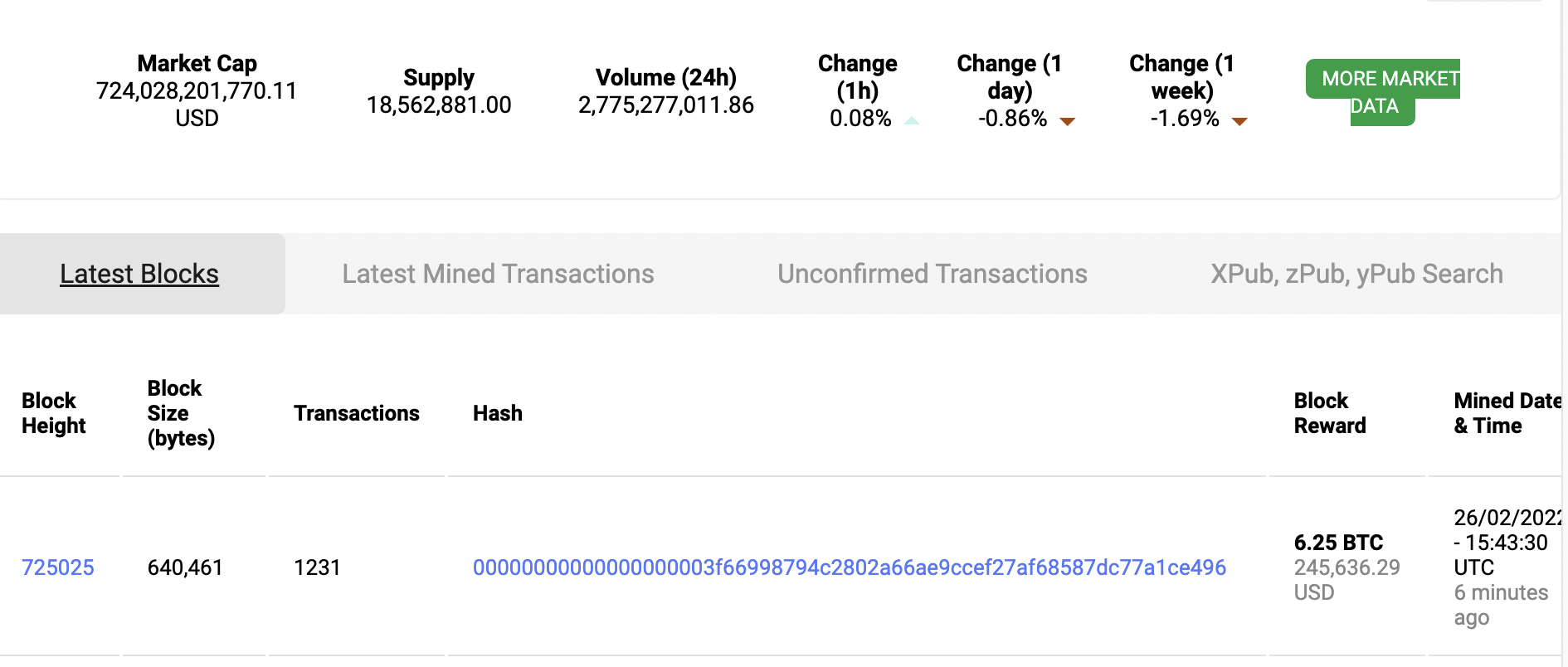
区块链的结构
区块链的内部结构如下:
Header 中包含的信息主要是下面几项:
- Version 。区块的版本号。
- 之前一个区块的 header 哈希。
- Merkle根哈希。这个哈希是由区块中包含的所有交易的哈希值运算得出的,如果有人篡改了任何交易,这个哈希值就会变。header 中保留了这个值意味着只要 header 安全了,整个区块就安全了,这解释了为何计算 nouce 的时候,只需要计算 header 的哈希,而忽略区块主体数据。
- 时间。矿工开始运算 header 哈希的那个时间点。
- nBits 。压缩格式的 target 值。这一项是跟 nonce 紧密相关的,后面我们还会详细介绍。
- Nonce 。简单来说 nonce 就是每个区块 header 之中都会保存的一个数,下面详细介绍。
计算 nonce 值的过程就是对区块 header 不断的运算哈希,直至找到能使区块哈希小于 target 的 nonce。
Target 就是一个 256-bit 的数。因为计算 header 哈希使用的哈希算法是 Sha256 ,运算得到的哈希值是 256-bit 的一个数,所以恰好可以用来和 target 对比。所有比特币客户端在计算 nonce 的时候都使用相同的 target ,并且这个 target 值会被记录到 header 中,保存到了 nbits 这一项。nBits 是一个 32-bit 的数,所以保存的是 target 的压缩形式,具体换算关系可以参考这篇文档。Target 要小于这个数 0x00000000FFFF0000000000000000000000000000000000000000000000000000 。
每次计算 header 哈希就让 nonce 值加1。具体 nonce 的运算过程就是不断的修改 nonce 值,然后对这个 header 重新运算哈希的过程。每得到一个哈希值就去跟 target 对比,如果哈希小于或者等于 target ,那么运算过程就结束了,当前 nonce 值会被最终记录到 header 中。否则,就把 nonce 值加1,再次计算 header 哈希。
显然,各个比特币客户端开始了一场寻找 nonce 的比赛,谁的硬件速度快,就有更大的概率率先找到 nonce 值,也就是宏观意义上抢到的记账权,当然,哈希的运算过程非常随机,所以这场比赛也跟抓彩票一样有很强的运气成分。
以上就是 nonce 的生成步骤了
Merkle树
从上面的结构可知,比特币的区块体就是由Merkle树组成的。那么,为什么我们需要Merkle树呢?
首先,我们要了解Merkle树的生成过程。由区块链的结构可知,每个区块由前一个区块的一些信息和新区块的一些信息组成的。其中我们要计算的这个Merkle根就属于新区块的一些信息
如何计算Merkle根?
- 首先,对于每一个区块,节点收到了一批交易以后,它们会组成Merkle树的叶子节点。
- 然后,我们要给每一项交易都生成一个哈希值。
- 接着,将树根中的哈希值两两哈希,生成倒数第二层节点。
- 重复对每一层节点进行两两哈希,生成它们的父亲节点。
- 直到生成Merkle树的树根,这个最后的哈希值就是默克尔树的根哈希。
SPV验证
SPV的目标是验证某个支付是否真实存在,并得到了多少个确认。
首先我们要来了解三种节点:
- 轻节点指的是:节点本地只保存与其自身相关的交易数据(尤其是可支配交易数据),但并不保存完整区块链信息的技术。轻节点的目标不仅是支付验证,而且是用于管理节点自身的资产收入、支付等信息。因此,轻节点仍需下载每个新区块的全部数据并进行解析,获取并在本地存储与自身相关的交易数据,只是无须在本地保存全部数据而已。
- 全节点是指:维持包含全部交易信息的完整区块链的节点。更加准确地说,这样的节点应当被称为完整区块链节点。
- SPV节点是指:和轻节点不同,SPV节点不需要下载新区块的全部数据,只需保存区块的头部信息即可。虽然轻节点部分借鉴了SPV的理念,但和SPV是完全不同的。
Merkle树结构,可以用来验证或确保一个数字货币交易已经在对应区块链的一个区块中。这就是SPV验证。
在验证某一个交易的真实性的时候,SPV节点只需要把该交易哈希值向网络中连接的全节点发起询问。网络里面的全节点只需要回复最小量必要数据给SPV节点,即可验证交易的真实性。如果SPV节点不信任提供交易验证数据的全节点,还可以同时发起多个全节点的询问,来确保交易验证的最大可靠性。
以下是SPV节点的验证过程
- 从网络上获取并保存最长链的所有block header到本地
- 计算 该交易的hash值 :tx_hash
定位到包含该tx_hash所在的区块,验证block header是否包含在已知的最长链中
- 怎么定位?最简单的方法是顺序查找。
从区块中获取构建merkle tree所需的hash值
- 根据这些hash值计算merkle_root_hash
- 若计算结果与block header中的merkle_root_hash相等,则交易真实存在
- 根据该block header所处的位置,确定该交易已经得到多少个确认。
Target
通过调整 target 值,可以来调整挖矿难度,挖矿难度每两周会调整一次。
Target 的值越小,挖矿难度就越大。POW 算法下的挖矿难度就体现在找到 nonce 值的难度,挖矿难度越大找到 nonce 值所需要的时间就越长。寻找 nonce 意味着找到一个满足特定范围的区块哈希,这个范围越大找到满足条件的 nonce 就越容易,反之则越难。而这个范围就是大于零小于 target ,所以 target 越小,找到合适的 nonce 就越难。
挖矿难度每两周会调整一次。首先说,为什么要调整呢?由于寻找 nonce 的过程带有一定的随机性,每次找到 nonce 的时间都不一定是网络所期待的十分钟,所以如果时间大于十分钟,说明挖矿难度有可能设置的太高了,那么下一次我们就需要把挖矿难度降低,从而尽量保持平均找到 nonce 的时间是十分钟。而实际中,并不是每次出块后都会调整挖矿难度,比特币网络规定挖矿难度每2016个区块调整一次,2016个十分钟恰好是两周,所以每次难度调整的时间间隔是大约两周。
总之,伴随 target 的调整,挖矿难度也随着调整,可以保证平均的每次找到 nonce 的时间尽量趋近十分钟。
安全性
采用了挖矿机制之后,虽然概率大大降低,但仍然无法排除存在撞车的概率。因此,区块链验证中最核心的思想就是——相信最长的区块链
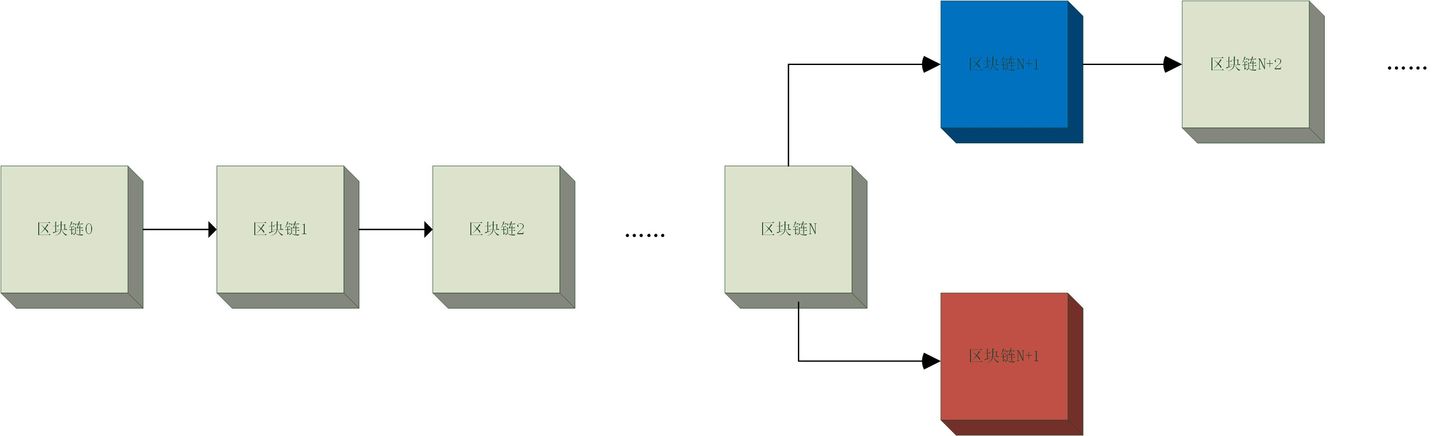
我们拿上图举例,在原有的到区块链N的情况后,短时间内出现了两个不同的区块,分别用蓝色和红色表示。
如此一来,就会有:
- 部分用户的区块链:原区块链+蓝色区块
- 部分用户的区块链:原区块链+红色区块
这个时候,我们需要做的只有一件事情,那就是『等待』。因为同时产生区块的小概率事件,总不可能连续发生。这样我们只需要等下一个区块产生,看这个新区块是连在蓝色后还是红色后。
图例里是有个新区块连在了蓝色区块后面,这个时候:
- 链长度(原区块链+蓝色区块+新区块)>链长度(原区块链+红色区块)
因此,我们选择长度更长的“原区块链+蓝色区块+新区块”作为大家共同维护的主链。
双花攻击
双花攻击(Double Spend attach),就是说攻击者几乎同时将同一笔钱(UTXO)用作不同交易。那么如何避免双花攻击?
- 虽然确实可以几乎同时发起两笔交易,这些交易单可以任意顺序进行广播,但是它们被加入区块时必定呈现一定的顺序。我们只要认定第一笔交易合法,剩余的交易非法即可。
那么,如果这个黑客向两个不同的网络,用一个UTXO发起两笔交易,分别加入两个区块。会怎么样呢?
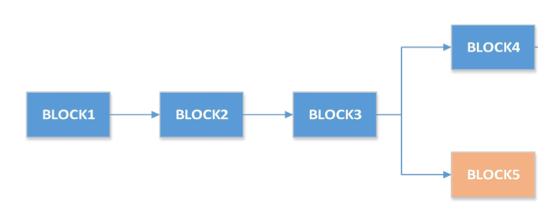
- 这也是不影响的。因为在比特币中我们最终认的是最长链。即使通过双花生成了两个分叉,但这些交易也是暂时的,最后只有在最长链的那笔交易会被保留下来。
女巫攻击
女巫攻击(Sybil attach)也是很常见的攻击手段,如果投票机制存在,那么就可能出现一个人分饰多角给某一个人投票,出现作弊的现象。
但是在区块链中,几乎不可能出现女巫攻击的情况
如果有人想对区块链造假,那么他就需要一直抢先生成假的新区块,并广播出去。
这就要求造假者生产新区块的速度,要快于系统中的其他所有用户的生成能力之和。换句话说,造假者需要用户有和其他用户算力之和匹敌的算力。
假设这个造假者拥有系统总算力的80%,而剩下用户拥有20%(注:这个假设显然不可能)。如此一来,在造假者广播了一个假的区块后,就有80%的概率先于其他用户生成新区块,然后连在自己之前生成的假区块后。此时造假才有可能成功。
但实际是,每个用户用的算力相比系统总算力都是微不足道的。而且随着比特币网络的逐渐壮大,系统就会越来越鲁棒。这就使得造假变得不可能,也使得造假的成本变得无法接受。
可锻性攻击
首先,我们需要知道密码学中的一个常识:在椭圆曲线数字签名算法中,会生成两个大整数$r$和$s$并组合起来作为签名。同时 ,$r$ 和 $BN-s$ 也同样可以作为签名来验证交易,(BN是一个很大的数)。
因此出现了这样一个状况:同样的输入和输出,可以修改签名,使得交易ID出现不同。同时可以通过验签。
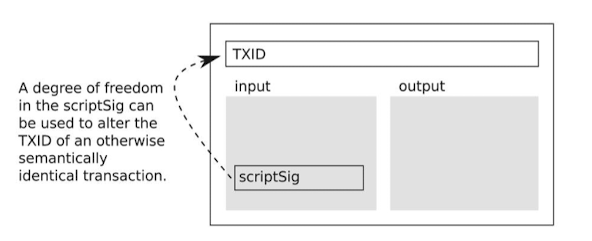
那么这时候,攻击者就可以侦听比特币网络中的交易,利用交易签名算法的特征修改原交易中的input签名,生成拥有一样input和output的新交易,然后广播导网络中形成双花
攻击过程如下:
- 首先需要有足够多的比特币矿机接入网络,以增加伪造的请求被优先处理的可能性
- 攻击者在第三方交易平台提交一个提款请求,并获得一个交易ID。第三方交易平台只根据TransactionID来判断交易是否成功。根据交易信息伪造一个签名,同时生成一个完全不同的交易ID,并将伪造的请求发出
- 若伪造的交易被优先处理,则原始交易失败
- 攻击者可以再次提交现请求,第三方交易平台确认之前的交易失败后会再次发送提现交易,至此,攻击成功
也就是说,我可以给自己转一笔钱,成功了,但是我可以伪装成自己失败了并从交易所获得退款。所以真正受到攻击的是交易所。
- 如何防范?
- 当使用TXID查找不到对应的交易时,需要用TXIN_OUTPOINT再查一下;
- 如果确实需要重发,引用的UTXO一定要与原来保持一致,把这种麻烦事儿交给比特币网络来处,系统规则确保了最终只会确认其中的一个(不会出现双花)。
挖矿的意义
挖矿的意义是什么?有些人会对挖矿机制产生质疑——这不是在浪费电力资源吗?
其实,在比特币这样的公有链中,挖矿是一个绝顶聪明的发明。通过挖矿其实是实现了一个共识机制,也就是一个选主的过程。因为在区块链中,每一个节点都会收到一批交易,那么到底认谁收到的那批交易是”正统“的呢?
答案很简单,谁的算力强,先算出来nonce的值,谁就被认可。而且通过挖矿和认可最长链的机制,使得比特币系统可以抵御很多种类的攻击
区块链的应用场景
当某一个场景符合以下几点特征的时候,运用区块链技术可以很好的解决这些困境。
- 多方参与
- 互不信任
上面两点我们很熟悉,正式因为互不信任我们才会使用P2P网络。否则相信中心化就好了
链下数据可信的保证——Oracle 预言机
这两点就比较难以理解了,链上数据的安全性能够保证,但是涉及到链下数据的时候,我们怎么能保证其上链之前没有被篡改过呢?有一种好方法就是 Oracle预言机。
比如说我和同学A打赌,明天是否下雨,并每人给100元作为赌注。如果下雨我赢,如果不下雨则他赢。那么怎么判断明天到底是否下雨呢?——存在一个公证人C会将明天的天气情况输入到系统中。但是这样存在一个问题,即我可以收买公证人C,使其输入到系统中的天气始终为下雨。这就存在链下数据遭篡改的可能。这时,就需要Oracle预言机了。我们可以在以太坊官网学习Oracle的相关知识 https://ethereum.org/zh/developers/docs/oracles/
自治
自治就相当于在一个无政府主义的社会,每个人都回去遵循大家一起定下来的规则去行事。
我们可以来看一个例子:航空公司要做一个延误险,保险双方分别为保险公司和乘客。如果航班延误,那么保险公司就会赔付相应的钱给顾客,如果航班准点到达,那么乘客投保的钱就给了保险公司。
问题就是,我们是怎么知道航班延误了?很自然的想法是,到航空公司的网站上去查找飞机到达时间,但这显示是从外部获取的信息,属于链下数据。既然是链下数据就存在一定的不安全性,因此需要Oracle预言机来保证输入数据的正确性,但是引入Oracle预言机会使得镇各系统变得复杂。因此有没有内部的方法,不引用外部的信息源,仅通过共识来保证数据的安全性、正确性呢?
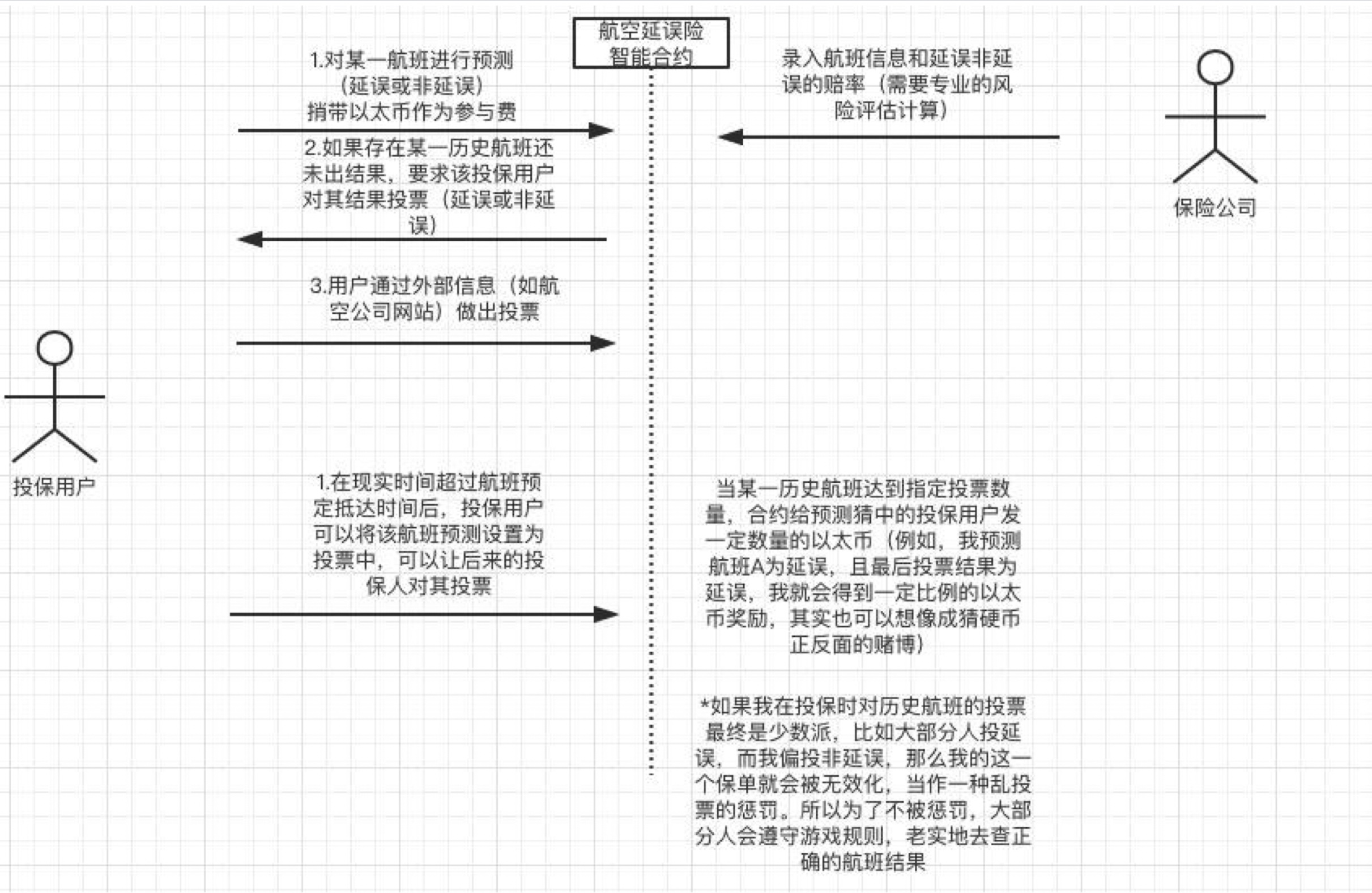
我们要了解区块链中的一个原则:一个不信任,永远在验证 。在这种情况下,仅用”1个“外部见证人肯定是不行的。因此我们可以这样——我让下一个航班买了延误险的顾客来对这个航班的晚点情况进行投票(人数够多,对这些人来说航班是否晚点是客观事实)。
- 如果一个顾客投了延误,实际上真的延误了,那么他就会获得一定的以太币奖励;
- 如果顾客投了没有延误,实际上确实没有延误,那么也会获得一定的以太币奖励;
- 如果一个顾客投了延误,但实际上并没有延误,就说明他说谎,因此我们可以取消他延误险的有效性, 即使延误了他也无法获得赔付 ,以此作为惩罚。
在这个系统中,就使用了自治的方法,对于个人来说,他说假话并不会得到任何的好处,而说实话则会得到奖励。因此大家都会倾向于说真话。基于此,就相当于通过人肉筛选来避免了直接从外部源获得信息,从而使整个系统运行起来。
区块链2.0
区块链2.0最重大的特征:支持智能合约(smart contract)
那么智能合约是什么?在比特币系统中,它支持的脚本是非常有限的,主要以转账为主。但是到了2.0,我们就可以在这个平台上编程了,我可以在上面开发应用。我们把这些应用统称为智能合约
智能合约可以对接收到的信息进行回应,可以接收和存储价值,还可以对外发送信息和价值。
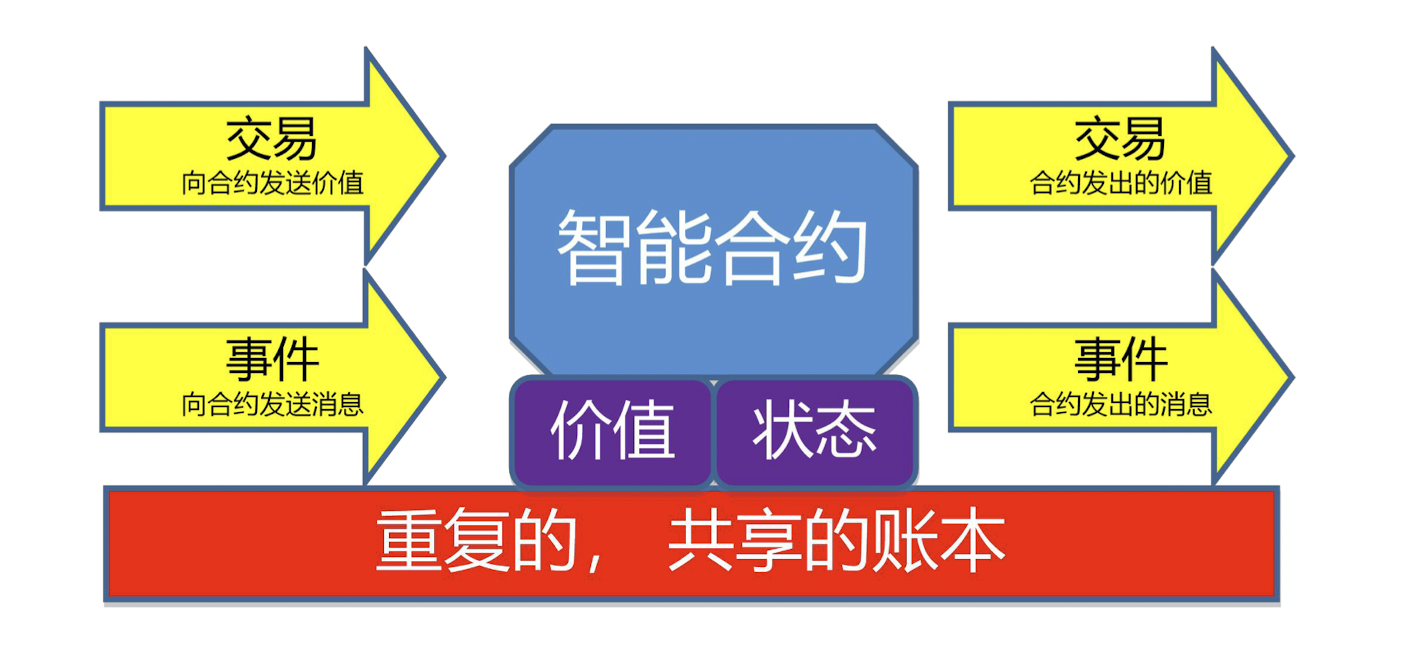
注意:智能合约程序不只是一个可以自动执行的计算机程序,其自己就是一个系统参与者。这意味着智能合约可以调用另一个智能合约
软件架构
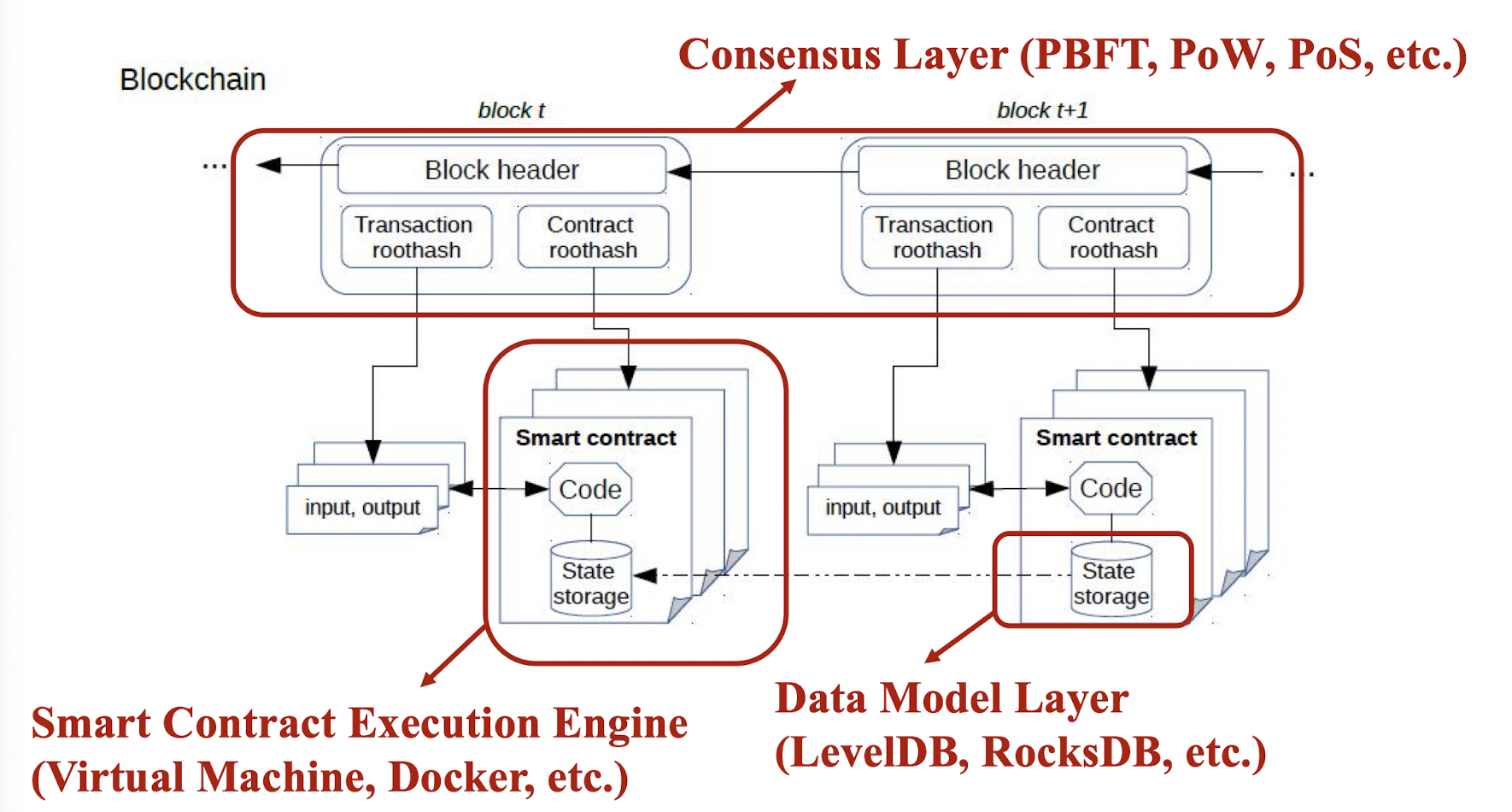
下面是区块链2.0的软件架构
- 在共识层,需要用到挖矿算法以及拜占庭容错的方法
- 在智能合约引擎中,包括智能合约的代码以及其存储的数据。
业务流程
开发人员可以写一个自己的智能合约,然后我们调用系统提供的SDK,并将数据存储在数据库当中。如下图所示:
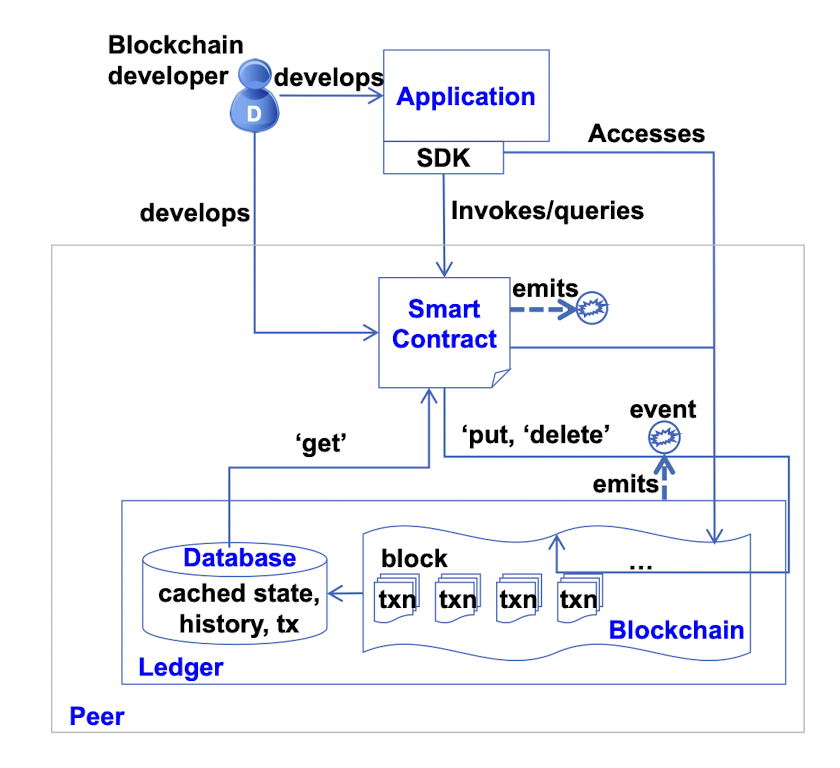
区块链小结
- 区块链是一个分布式的账本,一种通过去中心化、去信任的方式由参与各方维护一个可靠的、不可篡改交易记录的技术方案。
- 从数据库角度,可以将区块链比作一种分布式数据库技术,通过维护数据块的链式结构,可以维持持续增长的、不可篡改的数据库记录。
特征
- 匿名:交易参与方与网络中的相关节点都是匿名的
- 不可信:开放的环境需要通过数字签名技术进行验证,按照系统既定的规则运行。
去中心化:基于P2P,不存在中心化的设备和管理机构
- 任何能都可以参与到区块链网络,每一台设备都能作为一个节点,每个节点都允许获得一份完整的数据库拷贝
- 节点间基于一套共识机制,通过竞争计算共同维护整个区块链
- 任一节点失效,其余节点仍能正常工作
不可篡改性
- 批量交易一旦达成共识,就会作为一个区块添加到区块链中,会被永久地存储起来
- 单个甚至多个节点对交易数据的修改是无效的,除非能控制整个网络中超过51%的节点同时修改,但这几乎是不可能发生的。
可追溯
- 区块链中每一笔交易都通过密码学方法与相邻两个区块串联(UTXO),因此可以追溯到任何一笔交易的前世今生.
共识
- 采用协商一致的规范和协议(POW) 来保证数据质量,越多人在这个系统中,这个区块链系统就会越鲁棒。
应用情况
金融服务
金融服务是区块链最早的应用领域之一,也是区块链应用数量最多、普及程度最高的领域之-
- 防金融欺诈、资产托管交易、金融审计、跨境支付、对账与清结算、供应链金融以及保险理赔等;
- 典型案例:基于区块链的机构间对账平台、差异账检查系统,以及通过区块链技术改造的跨境直联清算业务系统等。
供应链管理
供应链核心企业、商业银行、电商平台等相关力量不断加强区块链在供应链管理领域的应用探索。
- 防伪溯源:京东、蚂蚁金服、众安科技等科技企业;
- 供应链金融:央行数宇货币研究所、央行深圳市中心支行推动“粤港澳大湾区贸易金融区块链平合”,万向区块链、乎安壹账通、京东、腾讯等众多企业;
- 防伪溯源和物流等领域:更注重与物联网、人工智能等技术的融合发展。
智能城市
区块链在建设智慧城市中的应用涵盖智薏园区、智薏物联网、智慧资产、智慧交通、能源电力、电子政务、法律应用等广阔领域。
- 采用分布式点对点的网络结构,可以使设备之问保持共识,实现,点对点传输数据,減少甚至无需与中心服务器的数据库进行验证,避免对中心化设施的依赖;
- 利用区块链数据防篡改、可追溯的特性可以帮助打通政府各部门数据孤岛,为公众提供更加可信和有价值的服务。
公共服务
部分地方政府大力推进“区块链+政务”服务,以满足公共服务在信息共享、权限控制和隐私保护等方面的高要求。
- 鉴证确权:将公民财产、数宇版权相关的所有权证明存储在区块链账本中,大大优化权益登记和转让流程,减少产权交易过程中的欺诈行为;
- 身份验证:将身份证、护照、驾照、出生证明等存储在区块链账本中,实现无需任何物理签名即可在线处理繁琐的流程,并能实时控制文件的使用权限:
- 信息共享:区块链技术用于机构内部以及机枸之问的信息共享和实时同步,能有效解决各行政部门间协同工作中流程繁琐、信息孤立等问题。
技术发展
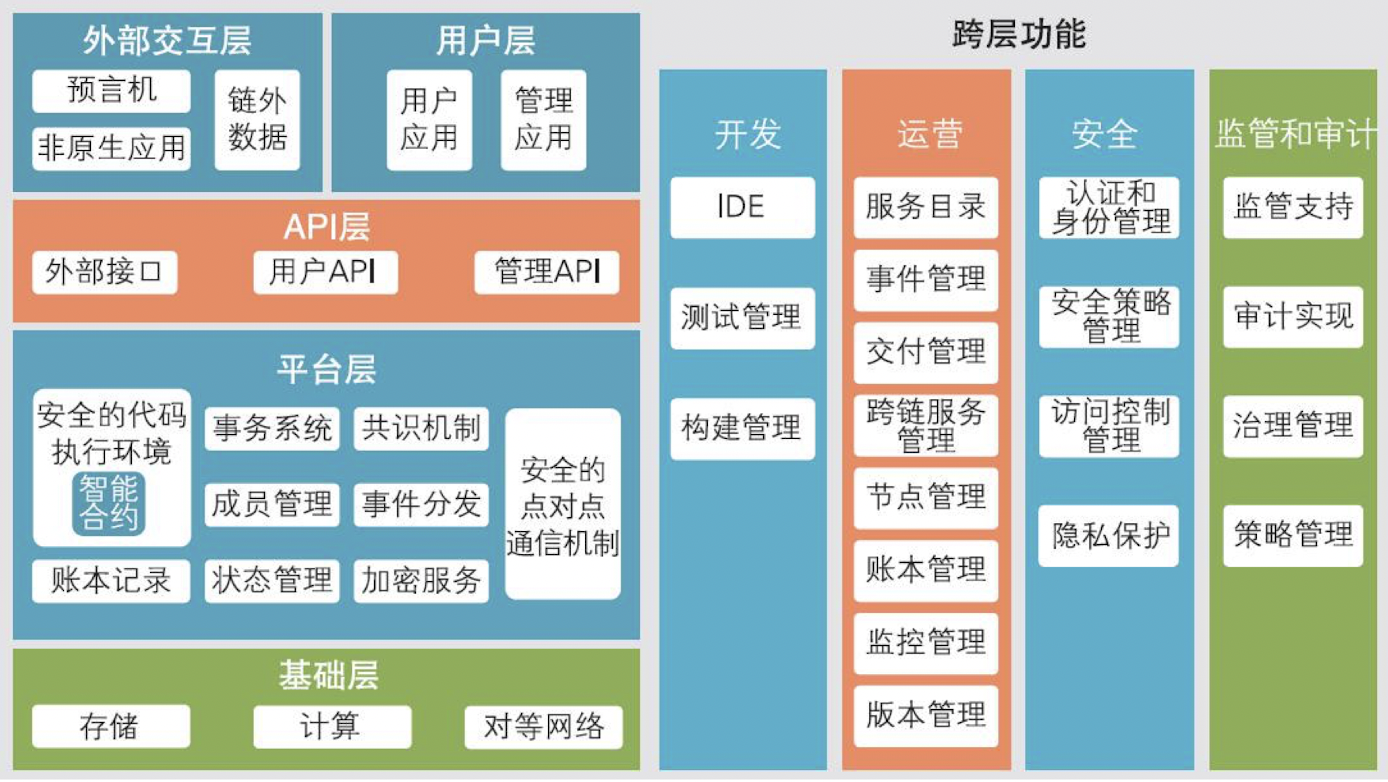
区块链系统架构
安全技术
主要包括:数宇摘要算法、数字签名和加密算法。
经典算法:
- SHA256、SM3等主流的数宇摘要算法
- RSA、 ECDSA、SM2等常用的数宇签名算法
- AES、SM4等对称加密箅法
- RSA、 SM2等非对称加密算法。
隐私保护技术
挑战
- 量子计算的技术演进对现有的密码学安全机制的巨大影响;
- 根据Shor算法,经典非对称算法(基于大数分解、离散对数等算法,如RSA、 ECDSA和SM2等)可以被稳定、可用的量子计算机攻破;
- 密码学家正积极探索能够抵抗量子计算机攻击的密码机制,如基于格的密码机制、基于纠错码的密码机制、多变量密码机制等。
目标:
- “身份的隐私性”和“数据的机密性”
- 身份的隐私性”主要是对区块链参与者身份的保护;
- “数据的机密性”主要是对记录内容、合约逻辑等数据的保护。
相关技术:环签名、同态加密、零知识证明和安全多方计算等。
- 环签名允许一个成员代表一个群组进行签名而不泄漏签名者信息,可以实现签名者完全匿名。
- 同态加密除了具有一般的加密操作之外,还能实现直接对密文的计算操作,通常分为加法同态、乘法同态、全同态等类型。
- 零知识证明是指一方(证明者)向另一方(验证者)证明某个事实的论断,同时不透露该事实的其他信息的方法。
- 安全多方计算能够在保证输入数据隐私的前提下,为缺之信任的参与方提供协同计算功能。
跨链技术
分片技术
分片技术本身是一种传统数据库技术,此前主要用于将大型数据库分成更小、更快、更容易管理的数据碎片。在区块链中,可将区块链网络分成很多更小的部分,即进行“分片”处理。
分片技术主要有网络分片、交易分片和状态分片三类
- 网络分片是利用随机函数随机抽取节点形成分片,支持更海量的共识节点。
- 交易分片分为同账本分片和跨账本分片,主要思想是确保双花交易在相同的分片中或在跨分片通信后得到验证。
- 状态分片关键是将整个存储区分开,让不同的碎片存储不同的部分,每个节点只负责托管自身的分片数据,而不是存储完整的区块链状态。
数据存储
区块的存储由链式结构发展为有向无环图 (DAG),DAG 区块链在并行性、可扩展性上有较大改善。
链外数据的存储,除了传统集中的数据中心存储、云存储以外,产生了新的互联网点对点文件系统
- 如融合Git、自证明文件系统(SFS)、BitTorrent 和DHT 等技术的星际 文件系统(IPFS)
共识机制
主要集中在:提高系统吞吐量及降低网络带宽
CFT (崩溃容错)
- Paxos, Raft
BFT (拜占庭容错)
- POW系列:POW、POS、DPOS
- PBFT, DBFT
- DAG
智能合约
主要方面:形式化验证框架与通用型合约编程语言安全性是智能合约的关键性问题
- 智能合约编程语言逐渐从脚本型语言向通用型语言演变
- 智能合约的执行逐渐从显式调用执行向由链上触发器(如预言机机制)自动触发执行的方向发展