当代人工智能Lab1-文本分类
环境
- python3.8
- Tensorflow-text 2.8.*
- Tf-models-offiial 2.7.0
模型选择与构建
模型选择
这里我选择的是BERT模型,它是最近几年比较流行的用来做自然语言处理的模型。BERT主要采用了双向编码器架构,因此相较于RNN,LSTM模型来说,有着更强的并发能力、能在多个不同层次提取关系特征,进而更全面地反映出句子的语义。
此外,BERT对TensorFlow的支持也很全面(都是谷歌开发的),甚至可以直接通过API来下载预训练模型。因此只要选择合适的模型与环境,就能迅速地实现数据训练,事实上我们所做的就是对预训练模型中的权重进行微调。
数据预处理
首先我们拿到的训练数据是 json格式的文档。为了能让Pandas、TensorFlow导入方便,我们需要将其转换为csv文件。因为python比较缺乏成熟的自动化转换库,因此我们采用了比较偷懒的方法——把json导入mongodb,再以csv的格式导出。
此外,测试集由于给的是txt格式的文档,这里我用了python程序将其转换为一个csv文件。
这两个文件分别为lab1_test.csv,lab1_train.csv ,在根目录下可以找到。

接下来,我们需要对label进行独热编码,因为我们不能用连续的数字来表示标签,否则会导致语义上的一些差别。可以用tf.keras.utils.to_categorical()这个函数来操作
最后,我们使用train_test_split 对数据集和标签进行 分割,变成训练集和测试集(实际上是验证集)。
模型的构建
首先,我们需要用到Bert的文本预处理层: 下载地址。这个预处理层从维基百科和BooksCorpus中提取英文单词并可以将每一行输入文字转换为一个
shape=(1,128)的向量。这个向量将被作为下一层Transformer Encoder的输入。然后,我们需要用到Bert的预训练模型:下载地址 。由于我们要处理的数据集的数据量并不是很大(8000条数据),因此我们选择的是一个小型的Bert模型——具有4个隐藏层,每个隐藏层大小为512;8个注意力头。
这一层有两个输出:
pooled_output和sequence_output,前者是句子的向量表示,大小为[batch size,512]; 后者代表句子中每个词语的向量表示,大小为[batch size,seq_length,512]. 在这里,我们选择前者作为下一层的输入。接下来的Drop out主要是用来正则化的,来让模型简化,减小冗余,我们不希望很多神经元去学习同一个特征,我们希望神经网络中的神经元有自己的“特长”,各自负责各自的特征。这样就可以减少过拟合发生的概率。我们将随机丢失神经元的概率设置为20%
最后,我们添加一个全连接层。由于这个任务要求单标签多分类,一共有10类文本,因此我们要将输出向量设为(1,10)。同时设置激活函数为softmax
1 | def build_classifier_model(): |
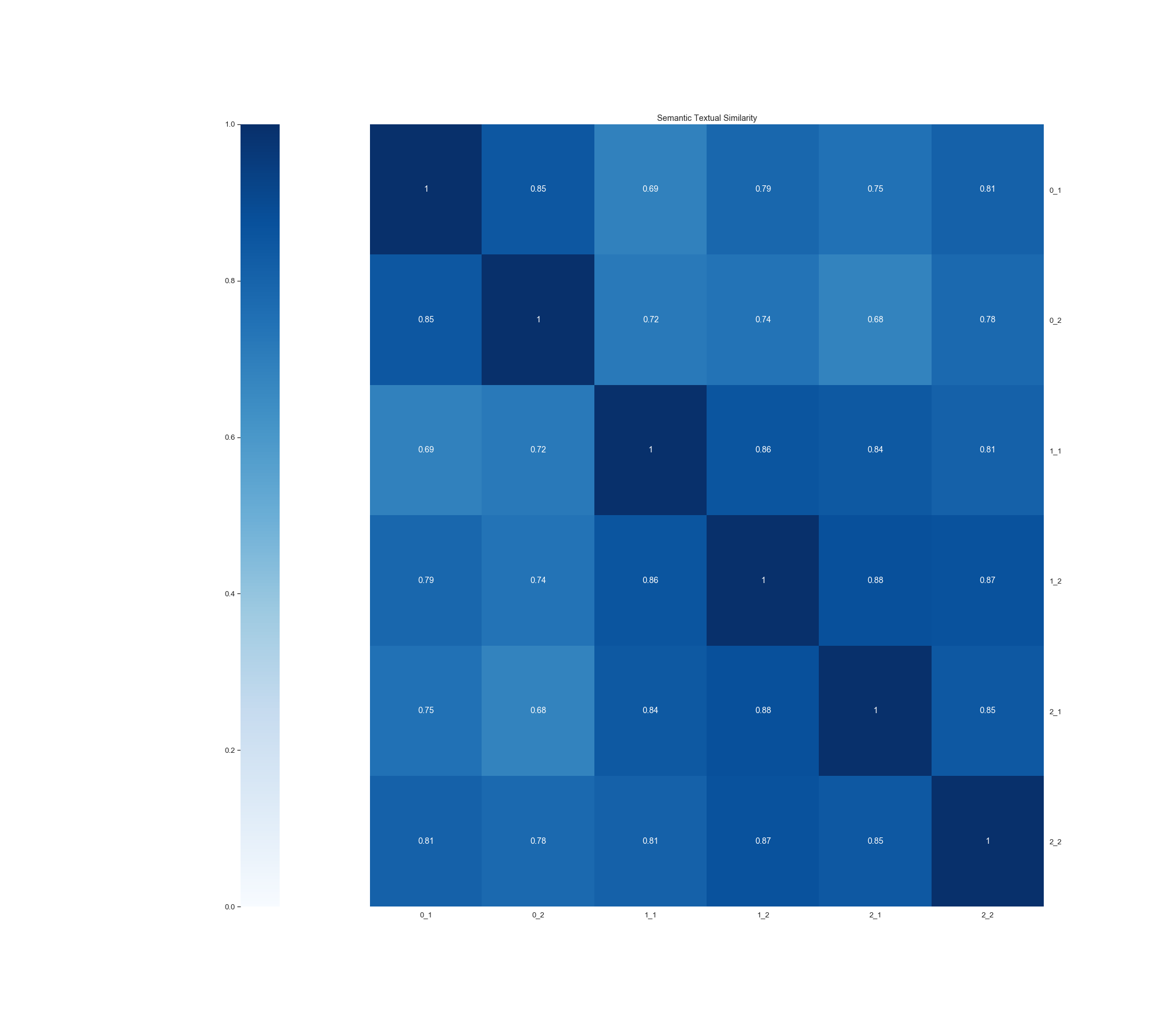
在这里我们就可以利用预处理层和编码器层来查看不同类别的文本之间的相似程度:我选择了来自0、1、2三类各两条数据绘制成热力图。我们发现,相同类之间的颜色确实会更深一些——(1,1)-(2,2)这一个正方形;(3,3)-(4,4)这一个正方形,都比周围的色块要深。因此可以定性得说明经过bert模型编码之后,可以有效地反映出文本之间的相似程度。
模型的训练
Optimizer选择与策略
现在表现较好、较为流行的梯度下降策略就是adam算法了,在这里我没有使用Tensorflow.train.AdamOptimizer 。而使用的是official.nlp中的optimization模块。相比前者,这个模块创建的优化器可以提供更多的功能,而且对Bert模型有良好的支持。
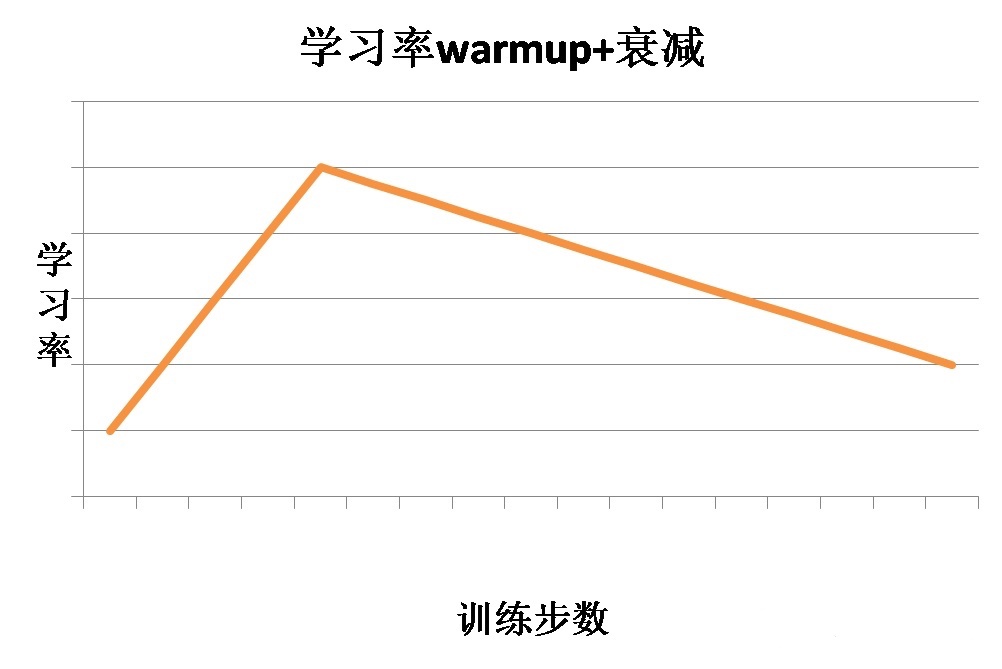
在这个模块中,我们除了需要设置最基本的初始学习率之外,还要输入总的训练步长num_train_steps,以及预热步数num_warmup_steps。学习率预热是指在训练初期选择一个较小的学习率,然后在训练一定步数之后使用预先设置好的学习率。因为刚开始的时候模型是随机初始化权重,如果使用较大的学习率,会让模型不稳定,所以可以在一定训练步数内,使用较小的学习率,模型可以慢慢稳定,然后使用之前设定的学习率。
把学习率预热和adam算法结合起来,学习率走势如下所示:
1 | epochs = 10 |
引入早停机制
为了避免模型过拟合,这里我设置了早停。对val_loss进行观测,如果连续三轮没有降低0.01、或者连续三轮没有降低到0.25以下的话,训练就会自动停止,并将val_loss最低(表现最好)的那轮的结果保存下来。
1 | # 设置早停 |
评价函数的设置
此外,在训练过程中我们还需要记录一些实时观测的值。也就是设置metrics。首先,我们要看的一个指标就是预测的准确率,即tf.keras.metrics.CategoricalAccuracy
此外,我们还要保留召回率(recall)、精确率(precision)、以及 f1值
召回率计算公式:$R = \frac{TP}{TP+FN}$, TP+FN: 也就是全体完全满足文本标注的文本的条数 ; TP:被预测正确的文本个数
精确率计算公式:$P = \frac{TP}{TP+FP}$ ,TP+FP: 也就是全体被预测为正确的文本个数,TP: 被预测正确的文本个数
F1 值是precision和recall调和平均值:$F_1 = \frac{2TP}{2TP+FP+FN}$
模型的编译
这里我们要用model.compile()方法, 其作用就是在训练之前告知模型训练时用的优化器、损失函数、准确率评测标准(metrics)。在这里,我们使用多分类的交叉熵作为损失函数。
1 | METRICS = [ |
模型的训练
在训练阶段,我们需要用到model.fit ,除了传入训练集、测试集之外,还需要设置训练集和测试集batch的大小、训练的代数、每一代训练的步数、以及是否开启多核处理。
1 | history = classifier_model.fit(x_train, |
预测
模型训练完之后,我们可以对测试集进行预测,
1 | # 预测函数 |
最后,为了模型能继续使用,我们可以把模型保存下来:
1 | classifier_model.save("./models/text_classifier_v1") |
如果我们想继续预测别的测试集,可以这样来导入模型,并做训练:
1 | new_model = tf.keras.models.load_model("./models/text_classifier_v1", |
问题与困境
- 环境的安装
首先是TensorFlow那数不清的版本,因为现在TensorFlow1.x已经没啥人用了,但是我原来的python3.7里面装的是TensorFlow1.x的版本。重装以后又发现TensorFlow2.8所依赖的库python3.7并不支持。因此干脆直接新建了一个python3.8的环境专门用来跑项目。
其实性价比更高的方法是创建虚拟环境,管理卸载起来也并不麻烦。但由于我选择在jupyter下跑,因此在anaconda中新建环境更加方便。
- 预处理
在一开始我选择的是用tf.data.experimental.make_csv_dataset将csv文件直接转换为OrderedDict,但是我却怎么也不能将其放到模型中进行训练,会报奇奇怪怪的错误。
在调试了两天无果之后,作罢,采用最原始的方式——导入为dataframe之后进行切割,并放到fit函数当中。虽然代码更长了些,但少了很多调试的煎熬。
超参数选择
由于我一开始就采用了官方文档中的初始学习率3e-5,发现效果就非常好,训练几代以后再验证集上的正确率都能达到90%以上,此外,囿于电脑算力的限制,训练一个模型的时间普遍长达2小时,因此我只是对初始学习率和batch大小进行了微调。
由于调试对模型最终的预测准确率影响不大,我把选择合适超参的重心放在正确率增长速度、正确率达到平稳值所需的时间上。我发现,当调大batch的值以后,每一轮所需要的步数变少了,虽然每步所需的时间有所增长,但总体而言,在内存能负担的情况下,调高batch的值可以有效地加快模型的训练时间。
epoch=10 batch=32 lr = 1e-5 每轮训练时间15-16分钟

Epoch=6 batch=32 lr = 3e-5 每轮训练时间 10-12分钟

Epoch=6 batch = 50 lr = 3e-5 每轮训练9-10分钟
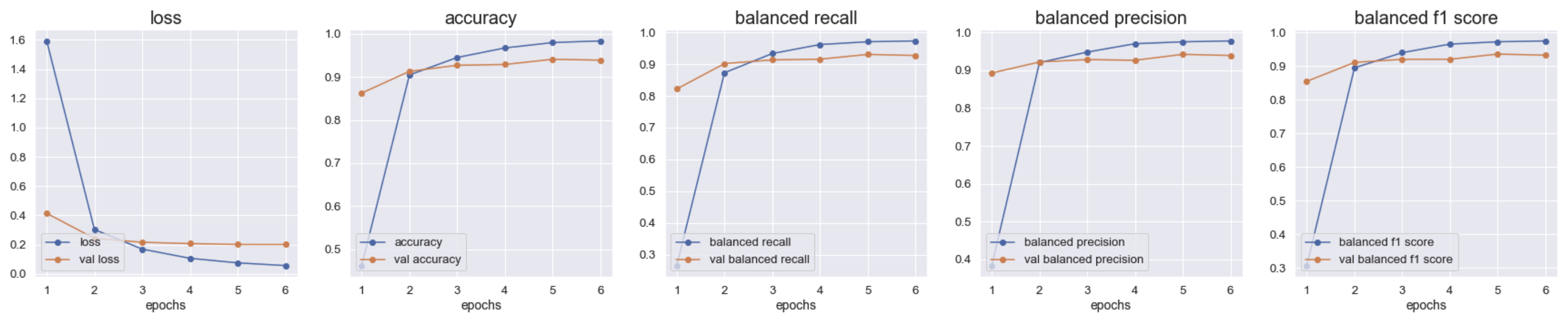
epoch=8 batch = 100 lr = 3e-5每轮训练时间 8-9 分钟
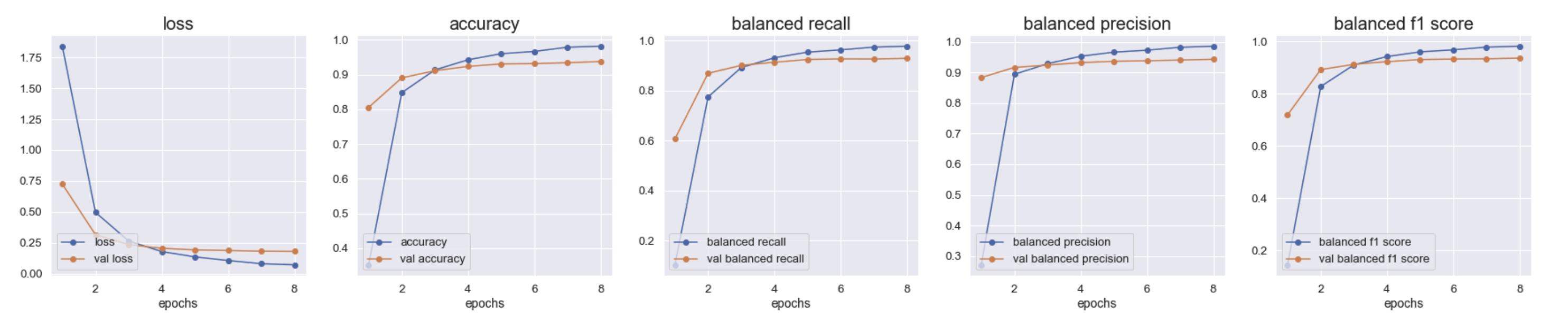
结果
根据图片和一些保存的数据,最后我们选择的是将batch设置为100,初始学习率设置为 3e-5, 训练10轮。模型在训练8轮后由于早停机制停止训练,结果如下图所示。
