了解Spark
Spark 最初是基于内存计算的批处理系统,逐步发展成为内外存同时使用的批处理系统,并增加了Spark Streaming支持实时流计算,以及Structured Streaming 支持批流融合。
设计思想
MapReduce
首先我们必须意识到,MapReduce虽然底层透明,部署简单,但是基础算子太少。比如,没有Join算子,需要自己实现。而且,Map段的结果需要先写入到本地磁盘,才能由Reduce来拉取。那么如果有多个MapReduce作业串行执行的话,就会使得数据不断在HDFS中写入读出,严重影响性能。
因此我们可以总结一下MapReduce的局限性:
- 编程框架的表达能力有限,无法直接用Join操作
- 单个作业中需要Shuffle的数据以阻塞方式传输,磁盘IO开销大、延迟高。因为Shuffle数据需要先写磁盘
- 多个作业之间衔接设计IO开销,应用程序的延迟高
- 特别是迭代计算,因为会导致迭代中间结果反复读写,使得整个应用程序的延迟非常高。
数据模型
在学MapReduce的时候,其数据结构是简单的键值对。而在Spark里面,数据模型是RDD(Resilient Distributed Dataset)
RDD 是一个数据集(Dataset): 与MapReduce不同,Spark操作对象是抽象的数据集,而不是文件
RDD是分布式的(Distributed):每个RDD可分成多个分区,每个分区就是一个数据集片段,一个RDD的不同分区可以存到集群中的不同的节点上。
RDD具有弹性(Resilient): 具有可恢复的容错特性,就好比一个弹力球,变形了以后还能恢复。
RDD性质
RDD是只读的记录分区的集合
- 其本质上就是一个只读的对象集合
- RDD经创建后,不能进行修改
RDD不可变(Immutable)
- 只能通过在其他RDD上执行确定的转换操作(如map、join、group by) 来得到新的RDD, 而不是改变原有的RDD
遵循了函数式编程的特性
- 变量的值是不可变的
计算模型
在MapReduce里面其实只有两个算子:Map和Reduce。也就是一个非常简单的有向无环图。 但是在Spark中,算子比较多,大致上可以分成三大类:创建类、转换类、行动类
创建类算子
创建(create)类算子可以从本地内存或外部数据源创建RDD,提供了数据输入的功能
| 创建操作 | 含义 |
|---|---|
parallelize(seq,[numSlices]) |
从内存集合创建RDD |
textFile(path, [minPartitions]) |
读取HDFS兼容的文件系统下的文件来创建RDD |
wholeTextFile(path, [minPartitions]) |
读取HDFS兼容文件系统下的文件夹中的所有文件创建RDD |
hadoopFile(path,inputFormatClass,keyClass,valueClass,[minPartitions]) |
读取HDFS兼容的文件系统下拥有任意inputFormat的文件来创建RDD |
转换类算子
转换(Transformation)类算子描述了RDD的转换逻辑,提供对RDD进行变换的功能。现在我们列举一部分:
| 转换操作 | 含义 |
|---|---|
map(func) |
和MapReduce类似,每个记录都是用func进行转换,返回一个新的RDD |
filter(func) |
对滤除对RDD中的每个记录都是用func后返回值为true的记录,类似于数据库中的过滤 |
flatMap(func) |
与map相似,但是对于RDD中的每个记录可以映射0个或多个新的参数,而map是1个 |
mapPartitions(func) |
与map类似,但是是对每个分区进行操作 |
union(otherRDD) |
两个RDD取并集得到一个新的RDD |
intersect(otherRDD) |
两个RDD取交集得到一个新的RDD |
groupByKey([numPartitions]) |
类似于Shuffle,将键值对按键分组,返回一个[K,Iterable<V>] 组成的新RDD |
reducedByKey(func,[numPartitions]) |
将键值对按键聚合在一起,对每一个键的所有值使用func,类似于Reduce操作 |
sortByKey([ascending],[numPartitions]) |
将键值对按键进行排序,返回一个新的RDD |
join(otherRDD,[numPartitions]) |
join操作 |
cogroup(otherRDD,[numPartitions]) |
类似于笛卡尔积的操作 |
行动算子Action
行动算子标志着转换结束,出发DAG生成。有点类似于输出的操作。
| 行动操作 | 含义 |
|---|---|
reduce(func) |
对RDD中的记录按func聚合,这个func必须满足交换律和结合律 |
collect() |
收集RDD中的所有记录到driver中,返回一个Array |
count() |
返回RDD中记录的个数 |
take(n) |
返回RDD中的前n个记录 |
saveAsTextFile(path) |
将RDD中的记录以文本文件的额形式写入本地文件系统,HDFS等兼容的文件系统 |
countByKey() |
按key统计计数,返回一个由[K,long]组成的Map |
foreach(func) |
对RDD中的每个记录都使用func |
Operator DAG
在一个实际操作中,算子肯定不能像MapReduce那样组成一个非常简单的有向无环图,而是一个比较复杂的图,可能如下所示:
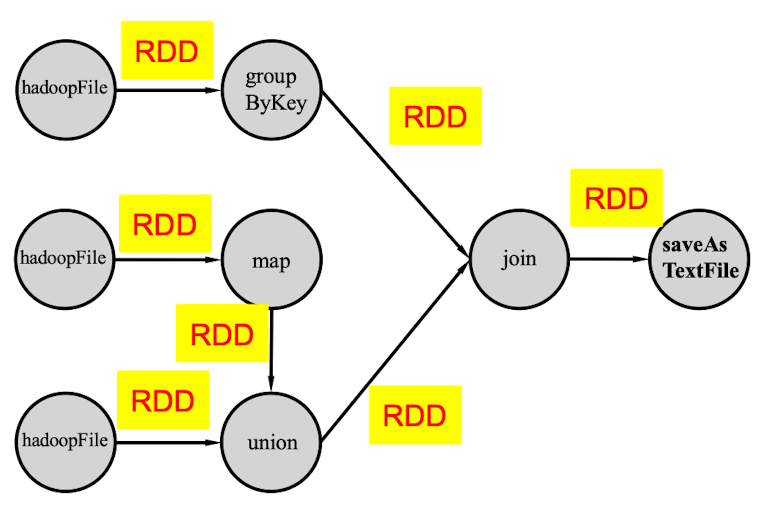
DAG主要以算子的角度来描述整个操作的过程,每一个节点都是一个算子。因此DAG的核心主要是以操作算子为描述对象
物理计算模型
在分布式架构中,DAG中的操作算子实际上是由若干个实例任务(Task)来实现。
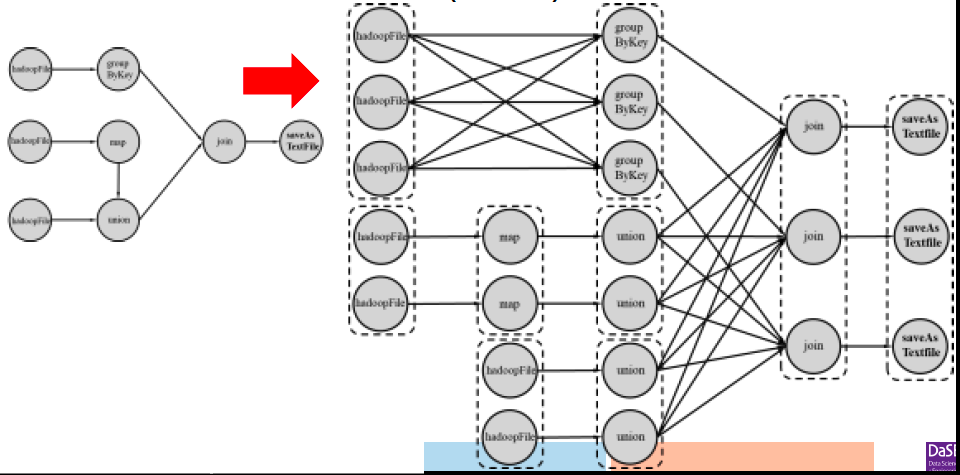
如上图,每个全都是一个task,一共有22个task
RDD Lineage
上面的DAG是以Operator为顶点、RDD为边的;现在我们可以将RDD作为顶点,Operator作为边,进行一个图的转换,这就是RDD Lineage,如下图所示:
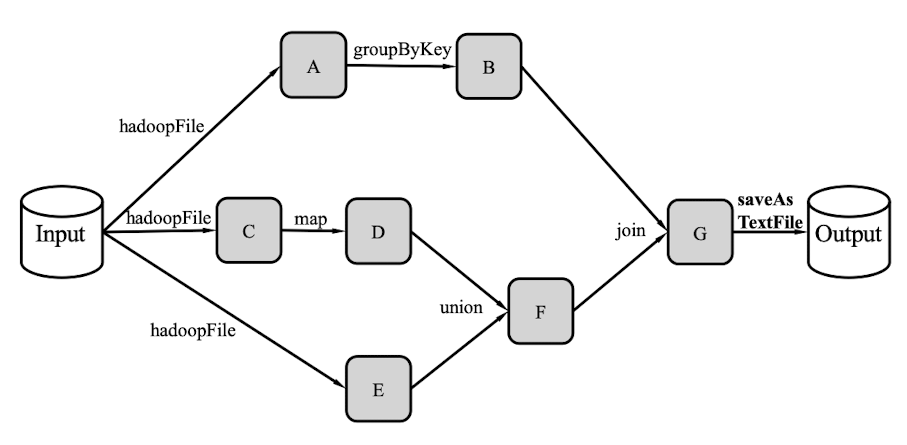
首先,RDD读取外部数据源进行创建
然后,RDD经过了一系列转换操作,每次都会产生不同的RDD,供给下一个转换操作使用。
最后一个RDD经过行动操作进行转换,并输出到外部数据源
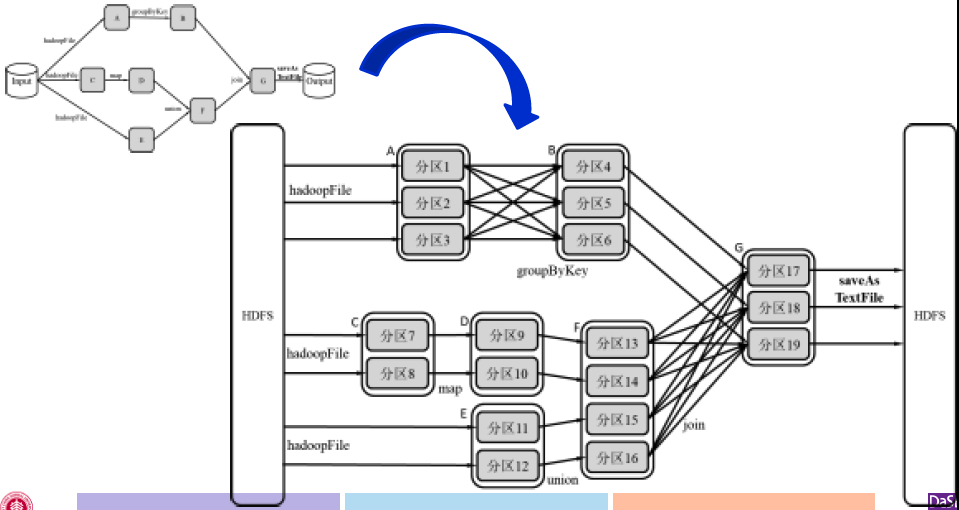
物理计算模型
用RDD Lineage的角度来看更加清楚,每个Task通常负责处理RDD的一个分区,但事实上对于一个流水线的过程(如分区7-分区9-分区13),我们可以将其简化为一个task
体系架构
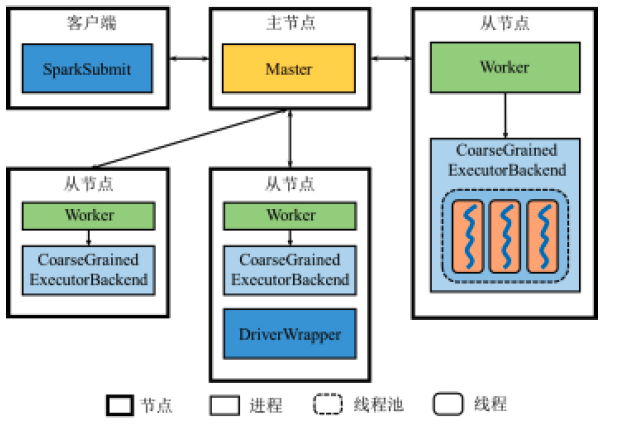
抽象架构图
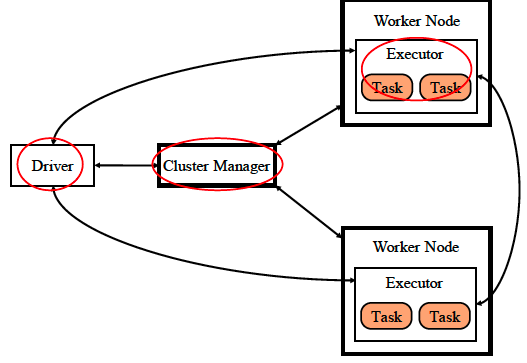
上图是Spark的抽象架构图。我们看到里面有三种节点
Cluster Manager
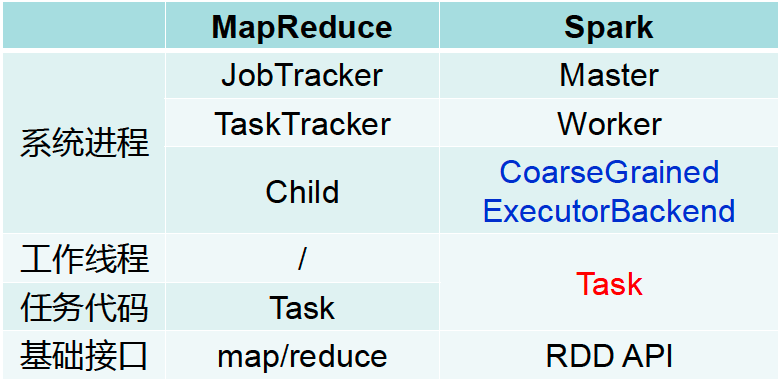
cluster manager是集群管理器,负责管理整个系统的资源、监控工作节点。就是说和MapReduce中的Job Tracker本质上是一样的。
Cluster Manager是一个抽象的概念,在部署完成后并没有一个进程叫做cluster manager。而且根据Spark的部署方式的不同,Cluster Manager也不一样
- 在Standalone方式(即不适用Yarn或Mesos等其他资源管理系统)中,集群管理器包含 Master和Worker
- 注:这个和MapReduce中的Standalone模式是不一样的,在MR中Standalone代表单机集中式部署
- 在Yarn方式中集群管理器包括:Resource Manager和Node Manager
Executor
Executor是执行器,负责任务的执行
Executor是运行在工作节点上的一个进程,它启动若干个线程Task或者线程组TaskSet来进行执行任务。
在Standalone部署方式下,Executor进程的名称为:CoarseGrainedExecutorBackend
这和MapReduce不一样,MapReduce中的Task是进程,因此其对资源的消耗往往要高于Spark
Driver
Driver是驱动器,负责启动应用程序的主方法并管理作业运行
Spark的架构实现了资源管理和作业管理两大功能的分离
- Cluster Manager负责集群资源管理
- Driver负责作业管理
在MapReduce中,JobTracker既负责资源管理,又负责作业管理
Standalone架构图
Standalone是不包含Yarn和Mesos的,其架构如下:
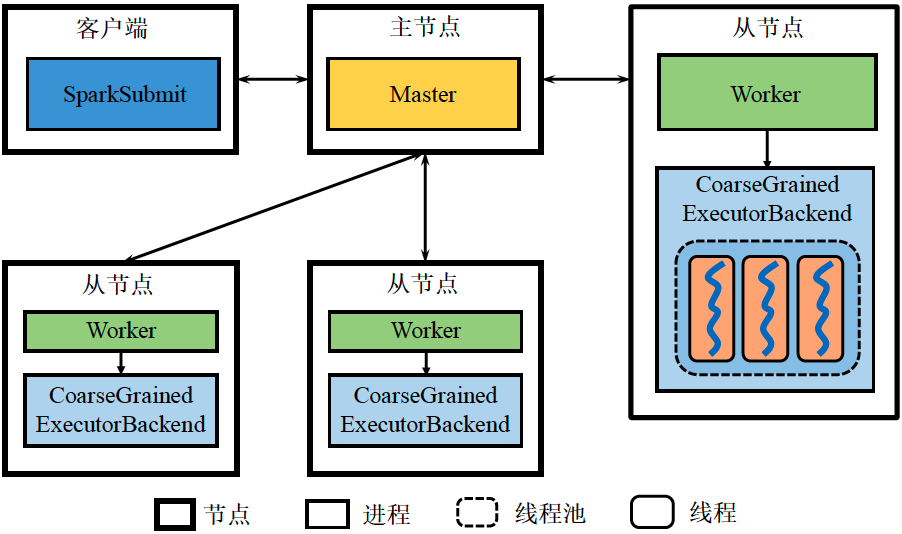
我们将其和抽象架构图作一个比较
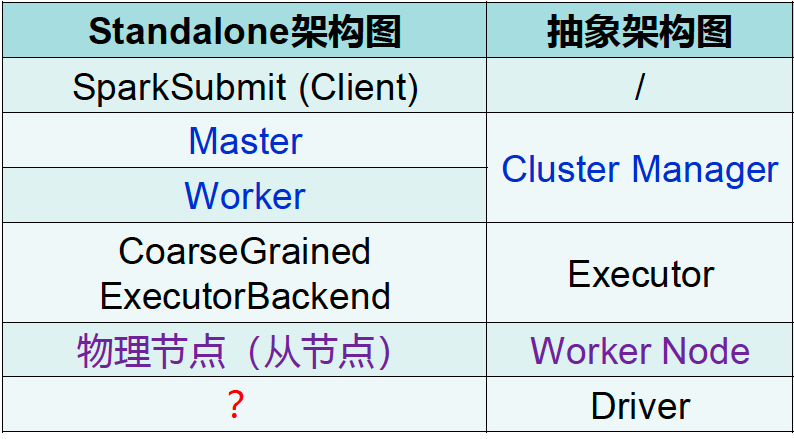
Standalone中的Driver
从图中我们看出,Standalone架构图中并没有出现Driver,那么Driver在哪里?
从逻辑上来说,Driver是独立于主节点、从节点以及客户端的
但是根据应用程序的Client或Cluster运行方式,Driver会以不同的形式存在
- Client方式:Driver和客户端以同一个进程存在
- Cluster方式:系统将由某一Worker启动一个进程作为Driver
客户端提交应用程序时可以选择Client或Cluster方式
- Standalone Client模式(默认)
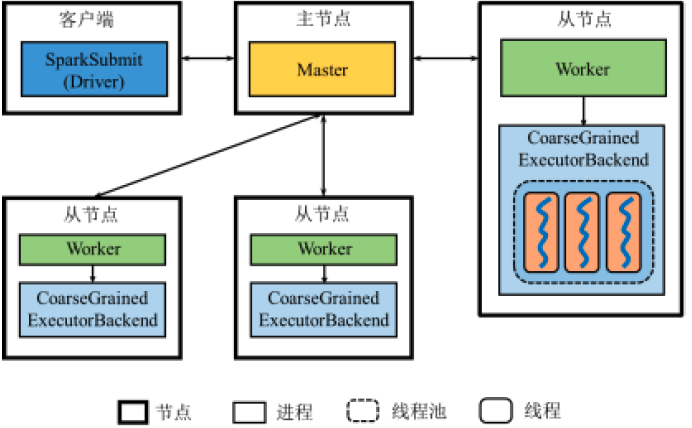
- Standalone Cluster 模式
那么这两者有什么差别呢?
由于我们申请的四台虚拟机都是在同一个云平台中的, 这时候Cluster模式和Client没有什么太大的区别。
只有当客户端和Spark集群的物理距离非常远的时候,那么就应该使用Cluster模式,因为这样内网通信更快。如果使用Client模式,Driver管理不同设备的时候,就需要通过远程网络传输,这时候开销就很大了。
Spark vs MapReduce
工作原理
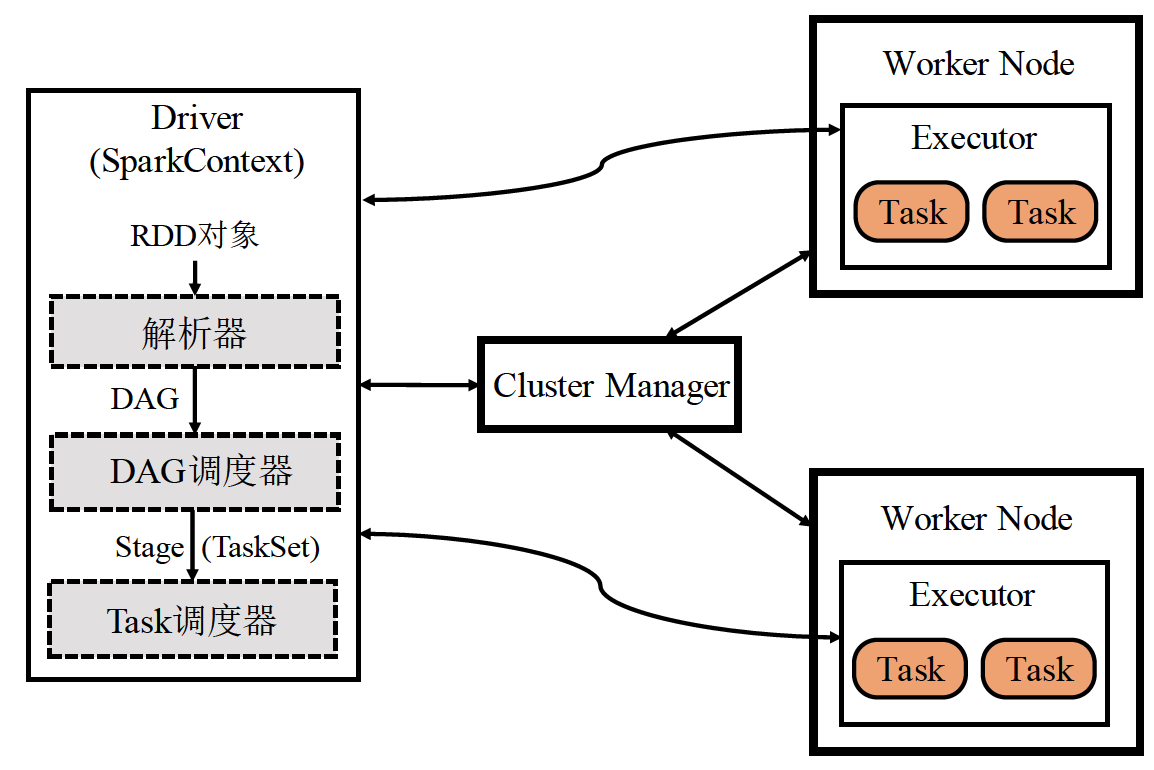
之前我们画的抽象结构图中,在driver部分并没有详细说。其实driver里面存在如上图的结构
首先RDD对象会经过解析器,然后得到一个有向无环图,然后DAG会被拆分成Stage,并交给task调度器去执行。我们可以将其和数据库查询引擎做一个对比,SQL语言经过解析器之后会变成语法树。我们可以把DAG看做是逻辑方面的模型,而Stage则是物理方面的模型
Stage划分
按依赖关系划分
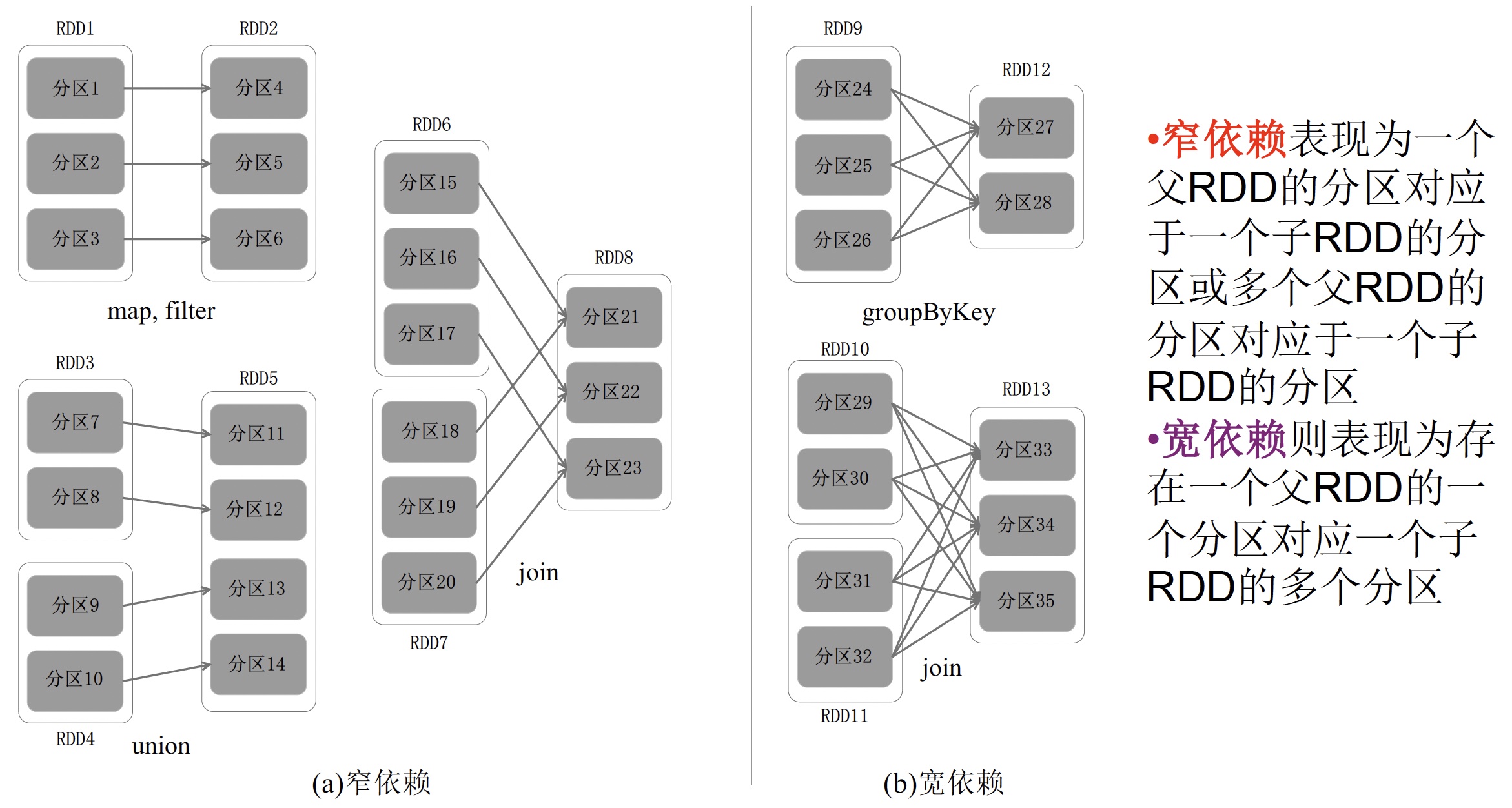
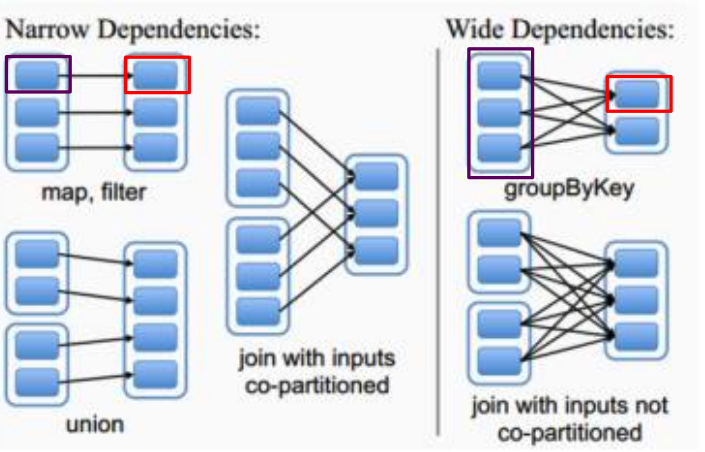
首先我们要搞清楚两种不同的依赖有何区别。宽依赖可以理解为多对多,类似于map reduce中的shuffle过程,窄依赖可以理解为子分区一对一、子分区一对多。
因此,我们可以通过分析各个RDD的偏序关系来生成DAG,再通过分析各个RDD中的分区之间的依赖关系来决定如何划分Stage。
具体划分方法如下:
- 在DAG中进行反向解析,遇到宽依赖就断开
- 遇到窄依赖就把当前的RDD加入到Stage中
比如:还是以展开后的DAG为例,我们看到有明显的两处宽依赖的部分,A与B之间、F与G之间。我们就根据这个将算子划分为三个stage
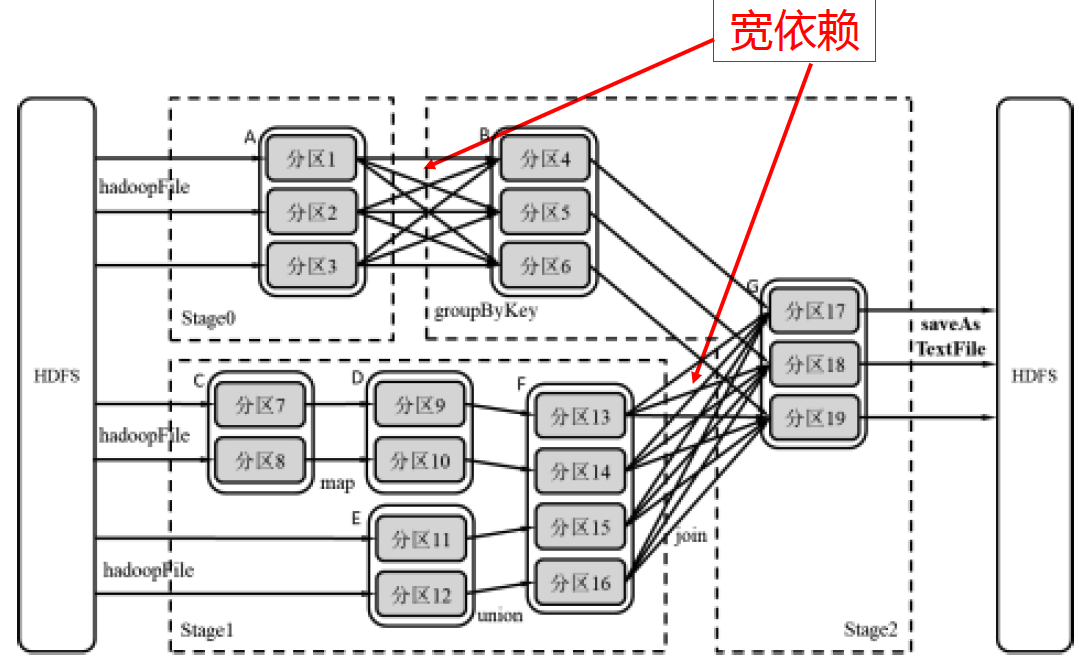
我们把每个stage抽象出来,得到下面这张拓扑图,通过这张图可以还原出原来的DAG。
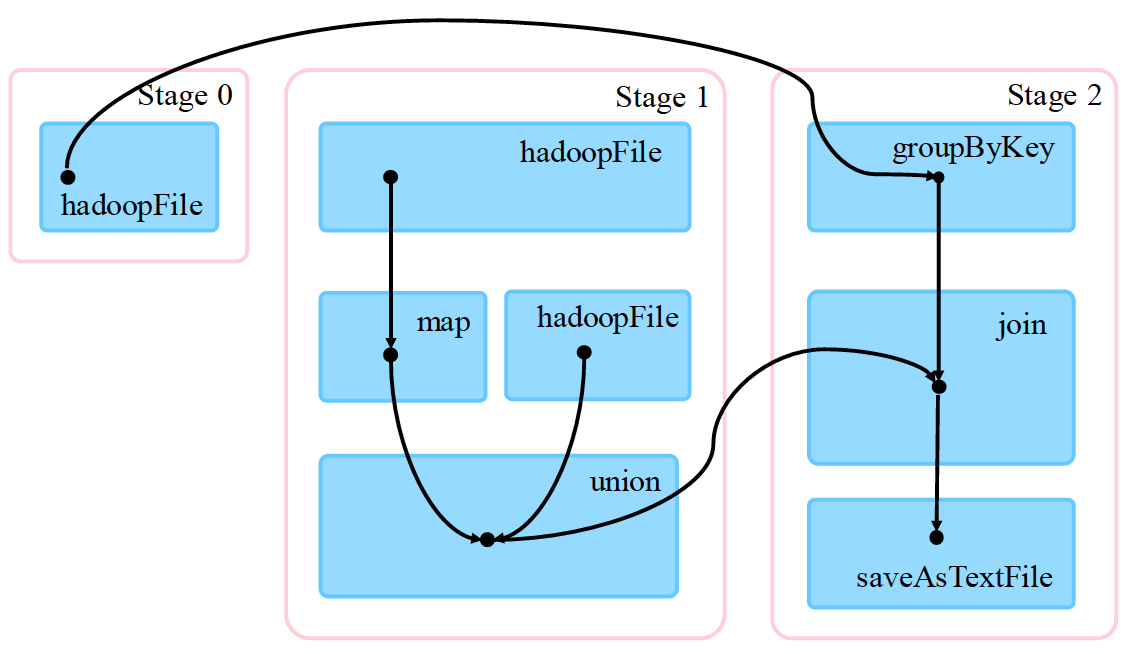
Stage类型
ShuffleMapStage
输入/输出
输入可以是从外部获取数据,也可以是另一个ShuffleMapStage的输出
以Shuffle为输出,作为另一个Stage开始
特点
不是最终的Stage,在它之后还有其他Stage
它的输出一定需要经过Shuffle过程,并作为后续Stage的输入
在一个DAG里可能有该类型的Stage,也可能没有该类型Stage
ResultStage
输入/输出
其输入可以是从外部获取数据,也可以是另一个ShuffleMapStage的输出
输出直接产生结果或存储
特点
最终的Stage
在一个DAG里必定有该类型Stage
判断方式也很容易,只要有输出结果的算子如saveAsTextFile,那么这个stage就是ResultStage。 因此,一个DAG含有一个或多个Stage,其中至少含有一个ResultStage
Stage 内部数据传输
问题是,为什么要将窄依赖尽可能划分在同一个stage里,而在宽依赖的时候将DAG断开?接下来两节我们就来解决这个问题。
首先Spark和MapReduce是不一样的,他算子很多,自然不可能想MR一样每经过一个算子就将其压入文件系统,让下一个算子读取。因此Spark采用了流水线的方式,而不是阻塞方式:
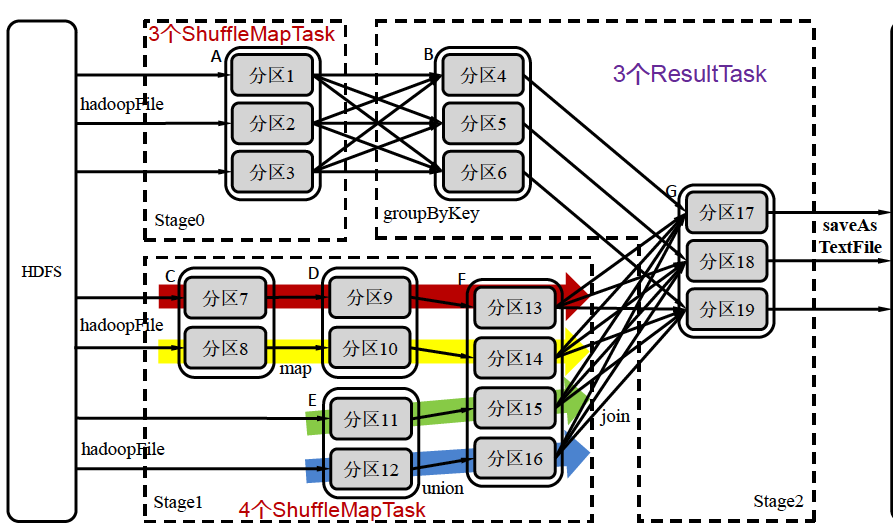
如上图,我们把目光聚焦到Stage1,这里有10个分区,如果按照最笨的方法,就需要开启10个task。但事实上,我们可以采用流水线的方式,这样只用开启4个ShuffleMapTask就可以了
那么流水线的过程是不是类似于MapReduce中的Shuffle过程呢?不同!,流水线方式不要求物化前序算子的所有计算结果
分区7通过map操作生成的分区9,并不需要物化分区9,而且可以不用等待分区8到分区10这个map操作的计算结束,而是继续进行union操作,得到分区13
如果采用MapReduce中的Shuffle方式,那么意味着分区7、8经map计算得到分区9、10并将这两个分区进行物化之后,才可以进行union
Stage之间数据传输
这时候我们再来看stage之间的划分依据,发现窄依赖的stage之间用流水线方式很方便,但在宽依赖的stage之间,采用流水线方式就不适用了。因此我们就需要在宽依赖的时候断开DAG。
Stage之间的数据传输需要进行Shuffle,该过程与MapReduce中的Shuffle类。
从Stage层面来看,Shuffle过程可能发生在两个ShuffleMapStage之间,或者ShuffleMapStage与ResultStage之间。
从Task层面来看,该过程表现为两组ShuffleMapTask之间,或一组ShuffleMapTask与一组ResultTask之间的数据传输
下面是两个宽依赖的stage之间的数据传输过程,也就是spark shuffle
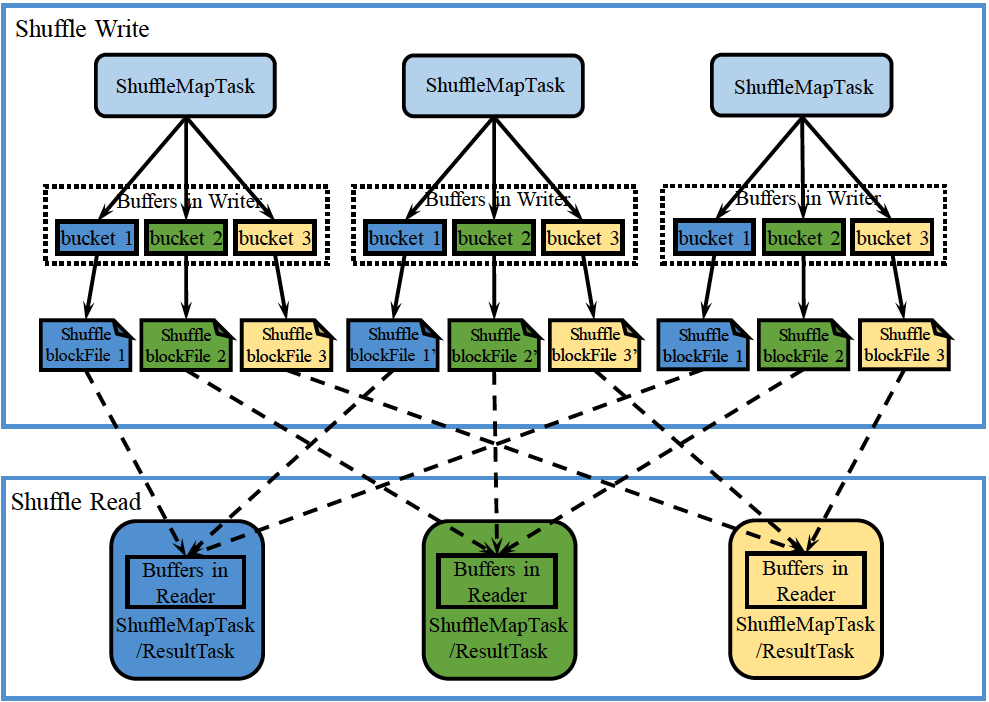
其过程如下:
在Shuffle Write阶段,会将数据进行Partition操作,ShuffleMapTask需要将输出RDD的记录按照partition函数划分到相应的bucket当中并物化到本地磁盘形成ShuffleblockFile,之后才可以在Shuffle Read阶段被拉取
在Shuffle Read阶段,ShuffleMapTask或ResultTask根据partiton函数读取相应的ShuffleblockFile,存入buffer并进行继续后续的计算
因此
- 在stage内部的信息传递不需要物化,采用pipeline 的形式
- 在stage之间的信息传递是需要物化的,且是阻塞的,采用shuffle形式
因此Spark相比于MapReduce,其改进也是有限的,特别是在Shuffle过程上,基本没有发生变化。因此从这一点来说,限制了Spark只能是一个批处理系统,而不能成为一个流处理系统
应用与作业
现在我们对Spark中的应用和作业做一个梳理
Application: 用户编写的Spark应用程序
Job: 一个Job包含多个RDD及作用于响应RDD转换操作,其中最后一个为action
MapReduce VS Spark
- 在MapReduce中,一个应用就是一个作业
- Spark中,一个应用可以由多个作业来构成

那么在Spark中,应用、作业和任务的关系又是什么?
- 从逻辑执行角度
- 一个Application = 一个或者多个DAG
- 一个DAG = 一个或多个Stage
- 一个Stage = 若干窄依赖的RDD操作
- 从物理执行角度
- 一个Application = 一个或者多个Job(Job = DAG)
- 一个Job = 一个或者多个TaskSet
- 一个Job会分为多组Task,每组Task被称为Stage,或者也被称为TaskSet
- 一个TaskSet = 多个没有Shuffle关系的Task
- 一个Task:运行在Executor上的单元。
可总结为:
容错机制
故障类型
首先,Spark里面每个部分都有可能出现故障。
- Master故障:可以利用ZooKeeper配置多个Master,但这不再讨论范围之内。
- Worker故障
- Executor故障
- Driver故障: 这个无解,只能重启,因此不在讨论范围之内
因此我们主要来解决Worker、Executor出现问题怎么办?主要有三种方式:RDD持久化、故障恢复、检查点
RDD持久化
由于计算过程中会不断地产生新的RDD, 所以系统不能将所有的RDD都存在内存 。因此, 一旦达到相应存储空间的阈值,Spark会使 用置换算法(例如,LRU)将部分RDD的 内存空间腾出 。如果不做任何声明,这些RDD会被直接丢弃。但是,某些RDD在后续很可能会被再次使用,那么这时候就需要让RDD持久化
在Spark里面提供了RDD持久化的接口
persist(StorageLevel)
- 接受StorageLevel类型参数,可配置各种级别
- 持久化后的RDD将会保留在工作节点的中,可重复使用
cache(): 缓存
- 相当于
persist(MEMORY_ONLY)
这边提供几个StorageLevel参数及其含义:
- MEMORY_ONLY: 在JVM中缓存Java的对象。如果内存不足,直接丢弃某些partition
- MEMORY_AND_DISK: 在JVM中缓存Java的对象。如果内存不足,则 将某些partitions写入到磁盘中
MEMORY_ONLY_SER: 在内存为每个partition存储一个byte数组,数组 内容为当前partition中Java对象的序列化结果
- 序列化可以理解为对存储空间进行一个压缩
MEMORY_AND_DISK_SER: 与MEMORY_AND_DISK类似,但每个分区存 储的是Java对象序列化后组成的byte数组
- DISK_ONLY: 将每个分区的数据序列化到磁盘中
- MEMORY_ONLY_2: 与MEMORY_ONLY相同,但是每个分区备份 到两台机器上
- MEMORY_AND_DISK_2: 与MEMORY_AND_DISK相同,但是每个分区备份到两台机器上
故障恢复
通常,一个Worker/Executor出了问题,常常是RDD出了问题,因此我们回到RDD Lineage,来看看出了问题后该怎么办?
根据Lineage的机制, 如果是红色部分丢失,那么就需要重新计算紫色部分。这里宽依赖和窄依赖就有所不同了,对于窄依赖,只要能拿到其对应的一两个父RDD,就可以还原出来了。但是对于宽依赖,其涉及到的父RDD就很多了。
因此宽依赖的恢复代价高、窄依赖的恢复代价低。
因此,基于RDD Lineage的恢复可被总结如下:
- 利用RDD Lineage的故障恢复
- 重新计算丢失分区
- 重算过程在不同节点之间可以并行
- Lineage 状态存放在哪里?
- Lineage是存放在Driver里面的,Driver里面可以解析DAG得到Lineage。因此如果Driver出故障的话,那真的只能重启了
- 与数据库恢复的比较
- RDD Lineage:记录粗粒度的操作 ,并没有记录RDD那里做了修改,只是对RDD变化的过程做了记录
- 数据复制或者日志:记录细粒度的操作
检查点机制
- 前述机制的不足之处
- Lineage可能非常长
- RDD持久化机制保存到集群内机器的磁盘,并 不完全可靠
- 检查点机制将RDD写入外部可靠的(本身 具有容错机制)分布式文件系统,例如 HDFS,这样更加可靠
- 在实现层面,写检查点的过程是一个独立的作业,在用户作业结束后运行