Scala初识
The Absolute Scala Basics
Values, Variables and Types
学习一门新的语言,自然要先从数值类型入手。在scala中,常量用val定义,变量用var定义。
- 定义常量Int
一个量有两种定义方式,一种是显式的定义x. 指明其为类型;另外一种则是隐式的声明,让编译器来判断的类型。推荐使用显式的定义,可读性更强一些。
1 | val x : Int = 62 |
- 定义常量String,同样分显式和隐式两种。
1 | val aString : String = "hello" |
- 定义布尔值Boolean
1 | val aBoolean: Boolean = false |
- 定义字符类型 Char
1 | val aChar: Char = 'a' |
- 定义Short类型整数
1 | val aShort : Short = 3456 |
- 定义Long 整数, 需要在数值尾部加上L
1 | val aLong : Long =5273985273895237L |
- 定义浮点数Float, 需要在尾部加上f
1 | val aFloat: Float = 2.0f |
- 定义双精度浮点数Double
1 | val aDouble: Double = 3.14 |
scala中还有一个特殊的类型:Unit类型,它表示无值,和其他语言中的void等同。用作不返回任何结果的方法的结果类型。Unit只有一个实例值,写成 ()
比如说:
1 | val aWeirdValue = (aVariable = 3)// Unit == void |
Expressions
- 操作符
1 | val x = 3+5 |
scala中的操作符和Java中的操作符是一样的,包括||, && , >>,<<, ^ ,+= , 但是注意,没有++,—
- if 表达式,if在scala中是以表达式的形式存在,而不是以指令的形式存在的,如下
1 | val cond: Boolean = true |
当然也可以写正常的 If-else 指令
1 | if(aVariable==4){ |
- while表达式,在Scala中请不要写while表达式,因为scala有更方便的方法进行遍历。 while表达式也是可以返回值的,只不过返回一个unit。
在scala中,所有的代码都是以表达式的形式呈现的,因此我们在写scala的时候要尽量减少如 println()、 while、以及变量再赋值这类的命令式语言的代码。虽然他们有效,但本质上还是表达式,返回的值是Unit,且会干扰我们代码的工整
- code block, 此外scala还有一种特殊的表达式 : CodeBlocks .这种表达式返回的值是代码块的最后一行得到的值,在这里
aCodeBlock = "goodbye". 此外要记住,在CodeBlocks中定义的val定量,在块外是无法被访问到的
1 | val aCodeBlock = { |
Exercise
1 | val somValue = { |
请问someOtherValue的结果是什么? 因为CodeBlock的值等于最后一行代码的值,在这里someOtherValue = 42
Functions
在Scala中,一个函数的定义如下:
aFunction是函数的名字,a和b是函数的两个需要被输入的参数,String是该函数的返回值类型
1 | def aFunction (a: String,b: Int) String = { |
如果函数只有一行,那么可以不需要用{}
1 | // 比如这个函数只需要返回42 |
我们可以写一个递归函数:会连续打印n遍 aString。 在scala中,当我们需要写一个for/while循环的时候,我们需要写一个等价的递归函数。
1 | def aRepeatedFunction(aString: String, n: Int): String = { |
我们也可以在一个函数里面写另外一个函数
1 | def aBigFunction(n: Int): Int = { |
Exercise
写一个函数,用来判断一个数是否为素数?
在其他语言中,我们可能会用一个for循环,每次循环都让n除以一个不大于其自身$\frac{1}{2}$ 的数(1除外),如果都不能整除,就说明这个数是素数。
在Scala中,由于我们要用递归去代替循环,那么就只能这么写:
1 | def isPrime(n: Int): Boolean = { |
Type Inference
Scala有隐式的类型转换,比如说:
1 | val x = 2 |
此时,编译器认为一个Int+一个String还是String,因此y的类型就是一个String类型的常量。
但是,也存在编译器推测失灵的情况,主要发生在递归函数里面。我们看到,如果n<=0,会返回1,此时编译器会认为函数的返回类型为诶Int,但是第二行,返回的值类型是Int乘以一个函数调用,这就把便一起搞混了,到底是不是返回Int呢?
因此,在创建函数的时候最好点名函数的返回类型,如果返回类型为空,那么就将类型置为Unit
1 | def factorial(n: Int): Int = |
Recursion
使用递归函数的时候,很容易出现一种情况:栈溢出。就拿连乘函数来说,factorial(10) 还可以跑,但是factorial(5000) 就会报错。
那么怎么避免这个问题?
要解决问题就需要找到问题为什么会发生,if (n <= 0) 1 else n * factorial(n-1) 这句代码中,每调用一次factorial,就会占用一行栈空间。
如果n=5,那么这个递归的调用过程大致如下:
1 | factorial(5) |
为了解决这个问题,需要学习“尾递归”的概念。什么是尾递归?尾递归是指递归调用是函数的最后一个语句,而且其结果被直接返回,这是一类特殊的递归调用。 由于递归结果总是直接返回,尾递归比较方便转换为循环,因此编译器容易对它进行优化。
以上阶乘函数不是尾递归,因为递归调用的结果有一次额外的乘法计算,这导致每一次递归调用留在堆栈中的数据都必须保留。我们可以将它修改为尾递归的方式。
1 | def anotherFactorial(n: Int): BigInt = { |
以上的调用,由于调用结果都是直接返回,所以之前的递归调用留在堆栈中的数据可以丢弃,只需要保留最后一次的数据,这就是尾递归容易优化的原因所在, 而它的秘密武器就是上面的acc,它是一个累加器(accumulator,习惯上翻译为累加器,其实不一定非是“加”,任何形式的积聚都可以),用来积累之前调用的结果,这样之前调用的数据就可以被丢弃了。
因此,当我们需要用循环的时候,就可以用到 Tail Recursion
比如说我要用tail recursion来写一个判断是否为素数的函数,在这里我们的accumulator是一个布尔值的变量,用来记录在当前情况下,n是否还为素数。如果布尔值为否,那么就返回false,如果t<=1了,说除到2还是素数,说明n是真的素数,因此返回true。如果t还没到1,那么就递归调用IsPrimeUntil函数,将布尔值设定为 n%t != 0
1 | def IsPrime(n: Int): Boolean ={ |
比如我要写一个Fibonacci的递归函数,这个比较难一些。和一般的Fibonacci思维不同,如果使用tail recursion,是从底部想上去加,而且要有两个accumulator来记录$f(n-1),f(n-2)$的值
1 | def fibonacci(n: Int): Int = { |
Call-by-Name and Call-by-Value
scala的call by name 和call by value最大的区别就是:
call-by-name在调用的时候会重新根据name做计算,而call-by-value预先计算,然后保留计算值后一直使用这个value。
比如说:
1 | def calledByValue(x: Long): Unit = { |
结果如下图所示,我们看到,call by name的话,每次都会计算x的值;而call by value的话,会预计算x的值

同时call by name传入的表达式是lazy 的,也就是说,只有要用到这个参数的时候,才回去计算这个参数的值。
比如说:
1 | def infinite(): Int = 1 + infinite() |
如上面这几行代码,我们定义了一个无限递归的函数infinite,如果调用infinite()必会导致stackoverflow
然后我们有定义了一个printFirst函数,第一个参数是call by value的,第二个是call by name的。
如果我们调用printFirst(infinite(), 34),会报错,因为x是call by value的,需要预计算,那么丢会调用infinite().导致栈溢出
但是如果我们调用printFirst(34,infinite()),就不会报错,因为y是call by name的,是lazy 的,若函数体内没有关于y的调用,就不会去计算y的值。因此不会报错。
当然,如果输入的都是数字的话,那么call by name和call by value就是一样的了
Default and Named Arguments
在写下尾递归的时候,我们常常会选择两个函数嵌套的写法,这是因为我们不想让用户手动输入accumulator的值,函数嵌套可以实现对用户的透明机制。
那么可不可以既实现透明,又只写一层函数的方法呢?显然,我们可以用默认参数
1 | def trFact(n: Int, acc: Int = 1): Int = |
如果一个函数有多个默认参数的话,编译器会默认输入的第一个参数对应函数中第一个place holder,因此如果我们想让第一个参数默认,其他两个参数自己设置的话,就需要我们显式得设置参数的名字。
1 | def savePicture(format: String = "jpg", width: Int = 1920, height: Int = 1080): Unit = println("saving picture") |
Smart Operations on Strings
现在我们来介绍一些对于字符串的操作
1 | val str: String = "Hello, I am learning Scala" |
- 输出指定位置的字符
1 | println(str.charAt(2)) // l |
- 节选字符串
1 | println(str.substring(7,11)) //I am |
- 切分字符串
1 | println(str.split(" ").toList) //List(Hello,, I, am, learning, Scala) |
- 判断字符串是否从某字符串开始
1 | println(str.startsWith("Hello")) //True |
- 字符串替换
1 | println(str.replace(" ", "-")) //Hello,-I-am-learning-Scala |
- 小写化
1 | println(str.toLowerCase()) //hello, i am learning scala |
- 字符串长度
1 | println(str.length) // 26 |
- 字符串反转
1 | println(str.reverse) // alacS gninrael ma I ,olleH |
- 字符串转为数字
1 | val aNumberString = "2" |
字符串和数字拼接,需要用到特殊的拼接符号。
- +: 用于在list的头部添加元素
- :+ 用于在list尾部追加元素;
1
println('a' +: aNumberString :+ 'z')
S-插值器
S-插值器的语法有点类似于CSS、PHP中的变量。也就是说,利用S-插值器可以往字符串中插入变量,比如说”
1 | val name = "David" |
- F-插值器
F-插值器的作用是用来格式化的
1 | val speed = 1.2f |
- raw-插值器
raw插值器则是让字符串中的转义符失效 。
1 | val str2 = "a\nb" |
但是我如果把string当做一个插入的参数打印,那么转义符就不会失效,比如:
1 | val escaped = "This is a \n newline" |
Object Oriented Programming in Scala
Object-Oriented Basics
现在我们来创建一个最简单的类
我们首先从构造类的参数说起。这个Person类需要两个构造参数:name和age,其中,age用val来修饰,说明age变成了类中的一个成员,我们可以用person.age来访问;但是name只是一个参数,我们无法用person.name 来获取这个参数。
然后我们来看类中的body部分,这一部分类似于CodeBlock,一些逻辑会直接运行。如果在里面定义了常量或者定量,他们都会变成fields我们都可以通过点运算符对其进行访问
接着我们来看两个函数,函数名都是greet,因此会发生函数重载。第一个greet函数接收一个String类型的参数,并打印字符串,这个字符串里面如果需要引用这个传参,需要用${this.name} ,而不能单纯的用$name
第二个函数没有任何输入参数,直接打印字符串,这里调用的参数是 $name ,是类里面的成员变量
和C++一样,scala也支持在类里面写多个构造函数,可以是没有参数的构造函数,也可以是有参数的
1 | class Person(name: String, val age: Int = 0) { |
Exercise
1
2
3
4
5
6
7
8
9
10
11/*
Novel and a Writer
Writer: first name, surname, year(出生年)
- method fullname 返回全名
Novel: name, year of release, author
- authorAge 返回作者的年龄
- isWrittenBy(author) 返回作者对象
- copy (new year of release) = new instance of Novel 返回一个新实例
*/
如下:
1 | class Writer(firstName: String, surname: String, val year: Int) { |
1
2
3
4
5
6
7
8
9/*
Counter class
- receives an int value
- method current count
// 需要实现两个方法,一个增1,一个减1
- method to increment/decrement => new Counter
// 还要实现函数重载,输入一个n,要增加n次
- overload inc/dec to receive an amount
*/
1 | class Counter(val count: Int = 0) { |
由于函数返回一个Counter,所以可以在调用inc之后继续调用inc,如果调用了三次,那么会让count+3 = 3
但是如果重新调用inc,那么之前的inc并不会累加,对于counter来说,其count值始终为零。
1 | 调用: counter.inc.print |
Syntactic Sugar: Method Notations
现在来介绍一些语法糖。scala是一个很”自然语言化”的语言,里面有很多特殊的语法,我觉得很像是C++中的运算符重载。
- infix notation/ operator notation ,这种语法只适用于只有一个参数的函数中 。 在scala中,我们要理解一个概念:所有的操作符,同时也是一个函数。
1 | class Person(val name: String, favoriteMovie: String,val age: Int = 0){ |
我们要调用Person中的likes函数,正常的写法如下:mary.likes("Inception")
但我们可以直接这样写: mary likes "Inception", 也就是将其他特殊符号全部略去,只留下最重要的三个部分。又比如说,可以直接写 mary hangOutWith tom
甚至我可以重命名hangOutWith函数为 def +(person: Person): String = s"${this.name} is hanging out with ${person.name}", 那么就可以这么写: mary + tom
而+ 和.+ 是相等的,所以我们还可以这么写: mary.+(tom)
- prefix notation,主要是
unary_前缀,它只适用于单目运算符-,+,~,!
1 | val x = -1 // equivalent with 1.unary_- |
同样的,我们也可以在Person类中定义 名为unary_!的函数
1 | class Person(val name: String, favoriteMovie: String,val age: Int = 0){ |
1 | //下面两个表达式是等价的 打印值: Hi, my name is Mary and I like Inception |
- Postfix notation 适用于没有任何参数的函数
1 | class Person(val name: String, favoriteMovie: String, val age: Int = 0) { |
1 | import scala.language.postfixOps |
- apply () 函数
当我们直接在一个对象后面加上(),编译器就会自动调用该类中的apply函数
1 | class Person(val name: String, favoriteMovie: String, val age: Int = 0) { |
Method Notations (Exercises)
1 | /* |
Scala Objects
Scala既然可以当做面向对象的语言来写,那么就必须具备面向对象语言的特征。那么其中一个特征就是:类内静态方法、静态成员变量。静态方法我们在Java中学过,就是只能被类调用,而不能被实例调用。比如说:
1 | class Person { |
那么在scala中,如何实现类内静态成员呢? 答案就是Object
比如我创建一个名为Person的Object,里面的所有成员都是静态的,如果要调用,只能这样来写Person.N_EYES,Person.canFlay, Person.apply
此外,Object只有唯一一个实例,就是他自己,如果我令 mary = Person("Mary") ,又令 john = Person("John") 。那么事实上,mary和john是相等的,它们都是同一个实例。 专业一点叫做singleton instance
1 | object Person { // type + its only instance |
那么如果要创建一个实例的的话,就需要另外创建一个class Person, 这里object 和 class后面的名字必须相同。可以这么说,Scala中的Object和Class共同构成了Java中的类。
如下:
1 | object Person { // type + its only instance |
如果我想调用类内静态方法:
1 | val bobbie = Person(mary,john) |
最后,我们来说为什么我们现在都用object xxx extends App 来运行scala文件:
在Java中,要使程序能够运行,需要有一个main函数,如下所示:
1 | public class Main { |
由于scala到最后也是需要放到JVM上去运行的,因此也需要有一个main函数。scala中的main函数如下:
1 | def main(args: Array[String]): Unit |
但是如果我们用 object xxx extends App ,那么就会继承 App中的main函数,我们就不用每次都写了。
Inheritance
既然上面提到了 继承,现在我们就来说说scala中的继承是怎么回事。
scala的继承以及一些关键字基本和Java中的类似。
单类继承
一个基本的单类继承如下:我创建了一个Animal类,然后有创建了一个Cat类去继承Animal,此时在Cat类中就可以继承Animal中的成员了。
成员默认是public,子类和外部都可以调用
如果成员被private修饰,那么其子类就无法调用和外部就无法调用
如果成员被protected修饰,那么其子类内部可以调用,但外部无法调用(实例调用)
1 | sealed class Animal { |
那么如果父类和子类的参数不同,该如何写继承语法?
比如说,Person有两个参数,Adult有三个参数,如果我们还是直接 extends Person ,编译器会报错。因此这样如果新建一个Adult实例的话,Adult事实上会调用Person中的构造函数,而Person中的构造函数只接受两个参数。因此,对于子类和父类参数不同的情况下,在继承时就要调用父类的构造函数,如下
1 | class Person(name: String, age: Int) { |
函数重写
在子类 可以重写父类中的函数和成员变量,需要使用override关键词。
当然,如果重写的是父类中的成员变量,可以放在子类的构造函数中,比如:Dog(override val creatureType: String)
1 | class Dog(override val creatureType: String) extends Animal { |
super
如果想要在重写的函数中仍然运行父类中的代码,可以使用super,super就代表父类,比如:
1 | class Dog(override val creatureType: String) extends Animal { |
事实上我们要尽量避免函数继承,因为会很乱。这里提供了一些办法来避免函数的重载:
- 对成员变量、成员函数使用 final 关键词修饰,就可以避免被重写
- 对类用final关键词修饰,就可以避免该类被继承
- 新语法:使用seal关键词,如果用seal来修饰类,那么仅在此文件中可以继承该类,但是其他文件中无法继承该类
Inheritance, Continued: Abstract Classes and Traits
Abstract class
- 抽象类的一个或者多个方法没有完整的定义
- 声明抽象方法不需要加abstract关键字,只需要不写方法体,如
def eat: Unit - 子类重写父类的抽象方法时不需要加override
- 父类可以声明抽象字段(没有初始值的字段)
- 子类重写父类的抽象字段时不需要加override
1 | abstract class Animal { |
Traits
类似于Java中的接口,trait被用于通过所支持的方法特例化来定义对象。如Java 8中一样,Scala允许trait被部分实现。其有以下特征:
- Abstract class和Traits 可以同时有抽象成员和非抽象成员
- 但是和class相比,trait 没有构造函数.
- 一个类只能继承一个抽象类,但可以混合多个traits。 比如说下面的Crocodile,继承了Animal,同时继承了两个traits: Carnivore和ColdBlooded
- 一般 抽象类是描述一种物体的,而一个traits 是用来描述该物体的行为的
1 | trait Carnivore { |
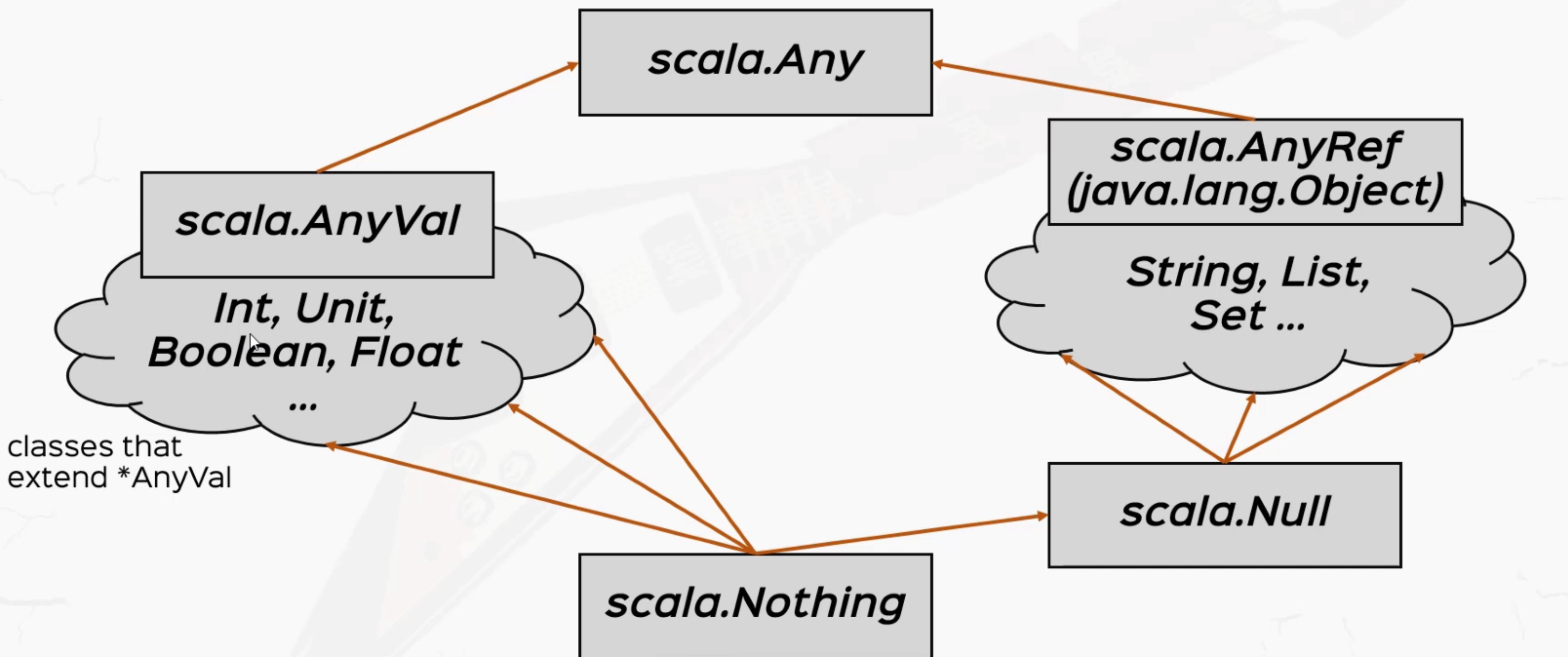
Type Hierarchy
最后提一嘴Scala中的类型结构,首先,所有类型都是继承自 scala.Any , 这就类似于JavaScript中的Object类, Any是整个Scala类型系统的超类。
scala.Any下面分为两个类: scala.AnyVal 和 scala.AnyRef 。
scala.AnyVal类中,主要是Int,Unit,Boolean,Float这几个数值类scala.AnyRef类中,主要是String,List, Set 这几个引用类型scala.Noting类是一切类的子类,包括我们自己创建的类
Inheritance Exercises Implementing Our Own Collection
现在我们要实现一个Int类型的链表,链表要实现这样几个功能:
head:返回链表头部def tail: 返回除了链表头部以外的剩余部分def isEmpty: 返回链表是否为空def add(int): 往链表中添加元素def toString: 可以打印链表中的元素
根据上述要求我们写一个抽象类如下:我们要用函数式编程的思路去设计这个列表。所以添加一各元素,需要返回一个新的对象。
1 | abstract class MyList { |
然后我们要实现这个列表:由于一开始新建链表的时候,肯定需要一个空链表,因此我们要创建一个Empty的对象。这里Object没必要用class, 因为我们没有创建一个Empty实例然后去调用其内部方法的需求和必要。
然后创建 一个Cons类,同样继承MyList,这个类需要传入两个参数,链表的头部和其他部分。
1 | object Empty extends MyList{ |
测试:
1 | val list = new Cons(1,new Cons(2, new Cons(3,Empty))) // 1,2,3 |
Generics
现在来谈谈scala中的泛型类,这一块比较难
泛型类使用中括号 [] 接收类型参数,虽然类型参数可以是任何名字,但是一个惯例是使用字母 A 作为类型参数标识符。
1 | //比如说我定义一个MyList的泛型类: |
这个MyList泛型类使用A作为类型参数。这意味着这个 MyList[A] 只能存储类型为A的元素。因此,我可以创建一个字符串类型的列表,一个整数类型的列表:1
2val listOfIntegers = new MyList[Int]
val listOfStrings = new MyList[String]
然后我们来说说泛型方法:泛型方法就是接收了泛型参数的方法,如下
1 | // generic methods |
variance problem
现在我们来讨论一下泛型中多样化的问题
1 | class Animal |
我们来看,Cat是Animal的子类,Dog也是Animal的子类,那么,MyList[Cat]是不是MyList[Animal]的子类
我们有三种推测
MyList[Cat]是MyList[Animal]的子类, 即List[Cat] extends List[Animal],二者 Covariance(协变)MyList[Cat]不是MyList[Animal]的子类,即 二者 Invariance(不可变)MyList[Cat]反而要比MyList[Animal]更高一级,是MyList[Animal]的父类,即二者 Contravariance(逆变)
在scala中,这三种方法其实都可以实现,但是需要不同的符号:用加号表示为协变,减号表示逆变,如:
Convariance : 参数类型前面需要有一个
+。如果是类型是协变的,那么我们可以用一个ConvarianceList[Cat]去替换ConvariantList[Animal],说明Cat是Animal的子集那么这时候其实出了一个大问题:我们能不能加其他类型的动物进去?
animalList.add(new Dog)合法吗?按照道理来说,Dog属于Animal,添加到animalList中是没有逻辑上的问题的,但是显然会污染一个cat类型的animallist。 如果我们要创建一个convariant的类,就必须解决这个问题——我们学完bounded types就知道了。
1 | class ConvarianceList[+A] |
- Invariance :在scala中,什么符号都不加就是Invariance。在这种情况下,
InvariantList[Animal]只能对应 Animal类型
1 | class Invariant[A] |
Contravariance: 参数类型前面需要有一个
-, 这是最难以理解的,特别是如果我们还以列表为例的话——那么只能写成InvariantList[cat] = new InvariantList[Animal],我们用Animal可以去替换Cat,说明Animal是Cat的一个子类,语法上没问题但是逻辑上有问题。为了方便理解,我们可以重新设计一个类Trainer这样的话,一个动物训练师当然可以替换一个猫咪训练师,因为动物训练师可以训练所有动物,也包括猫。从这个角度上来看 逆变关系比较好理解。但是从动物训练师是猫咪训练师的一个子类来理解,就比较奇怪了。
1 | class contravariantTrainer[-A] |
bounded types
在Scala中,类型界限是对类型参数或类型变量的限制。 通过使用类型边界,我们可以定义类型变量的限制。
- 上界:这里T是类型参数,而S是类型。 通过将“上界”声明为“ [T <:S] ”,表示此类型参数T必须与S相同或S的子类型。
1 | // 这里,我们要求Cage中的输入参数必须是Animal的子类 |
我们看到,如果是另外一个不是animal的子类,我们就没有办法将其放到Cage里面,因为Cage有类型限制

- 下界:这里T是类型参数,而S是类型。 通过将“下界”声明为“ [T>:S] ”,表示此类型参数T必须与S相同或为S的超类型。
现在我们可以解决上面那个可不可以把Dog插入 List[Cat]的难题了,解决方法就是,如果我往一个List[Cat]里面插入Dog,就会返回一个 List[Animal] ,也就是说把类型更泛化一个级别
1 | class MyList[+A] { |
最后,我们对之前写的MyList进行修改:
1 | abstract class MyList[+A] { //将MyList改为泛型抽象类 |
Anonymous Classes
匿名类:也就是没有命名的类. 对于一个类的子类,如果我们只需要实现其一次(创建一个实例), 我们就可以使用匿名类
首先我们来看不使用匿名类的写法:
1 | // 首先创建一个抽象类 |
那么如果这个类的实例只会被创建一次,我们就没必要搞这么复杂,直接使用匿名类就可以:
1 | abstract class Animal { |
匿名类不只有抽象类能使用,正常的类中也可以使用, 但是需要显式得写 override
1 | class Person(name: String) { |
Object-Oriented Exercises : Expanding Our Collection
现在我们在来扩展一下之前写的MyLIst,往里面添加三个函数: map,filter 和flatmap,示例和要求如下:
1 | /* |
Case Classes
case class是scala中的一种更强大的创建类的方式。它不仅拥有普通class的功能,又有很多内建方法,不用我们自己去实现。
比如说我创建一个case class如下:
1 | case class Person(name: String,age: Int) |
现在来一一介绍case class的一些特性
- 类的构造参数默认是类内成员
- 初始化的时候可以不用new,也可以加上,但是普通类必须加new
1 | val jim = Person("Jim",34)//初始化的时候可以不用new |
- toString的实现更漂亮
1 | println(jim)//Person(Jim,34) 我们看到直接打印case class的实例很直观的显示Person的参数 |
- 默认实现了equals 和hashCode;
1 | /*在case class中,如果两个类参数相等,那么会默认判定这两个类是相等的(内置了equals方法)*/ |
- case class 实现了 copy方法
1 | val jim3 = jim.copy()//创建一个和jim一模一样的实例 |
- Case class 在创建时同时创建了companion object(伴生对象),同时在里面给我们实现子apply方法,使得我们在使用的时候可以不直接显示地new对象;
1 | val thePerson = Person//合法,这里的Person是case class Person的伴生对象 |
Case Class 可以序列化(Serializable)
Case Class 可以用于模式匹配,这是case class最重要的特性关于模式识别是什么,我们最后一章会学
- 除了Case Class之外,还有Case Object,其主要特性和Case Class相同,但不会创建伴生对象——因为他们自己就是自己的伴生对象
Scala 3: Enums
现在我们来说说Scala中的枚举类,枚举类是Scala3中的新语法
基础定义
首先我们可以给出一个最基本的枚举类的定义,我们可以将scala中的enum理解为一中数据类型,case后面的是该类型可选的值
1 | enum Permissions { |
Enum中也可以有函数
在Enum中也可以定义函数:
1 | enum Permissions { |
constructor args
Enum也可以接收参数:
1 | enum Color(val rgb: Int){ |
companion objects
我们可以为Enum创建伴生对象:
1 | object Color{ |
Enum的一些标准接口
Enum.ordinal, 通过ordinal可以返回某个枚举值在类中的index,比如:
1 | al somePermissions: Permissions = Permissions.READ |
Enum.values可以以数组的方式返回Enums中的所有值
1 | println(Permissions.values.mkString("Array(", ", ", ")")) |
Enum.valueOf这个方法感觉有点鸡肋..
1 | println(Color.valueOf("Blue")) // Color.Blue |
有了case class,我们可以让MyList的功能变得更加强大。
- 首先有了equals方法,可以方便的比较两个List的元素是否相等
- 能序列化,使得在分布式系统中更加方便操作
Exceptions
现在来学习scala中的异常处理。首先来分辨一下Error和Exception的区别:
Error 是指在正常情况下,不大可能出现的情况,绝大部分的 Error 都会导致程序(比如 JVM 自身)处于非正常的、不可恢复状态。既然是非正常情况,所以不便于也不需要捕获,常见的比如 OutOfMemoryError , StackOverFlowError, 都是 Error 的子类。
Exception 是程序正常运行中,可以预料的意外情况,可能并且应该被捕获,进行相应处理。Exception 又分为可检查(checked)异常和不检查(unchecked)异常【即运行时异常】,可检查异常在源代码里必须显式地进行捕获处理,这是编译期检查的一部分。
- 检查性异常:最具代表的检查性异常是用户错误或问题引起的异常,这是程序员无法预见的。例如要打开一个不存在文件时,一个异常就发生了,这些异常在编译时不能被简单地忽略。
- 运行时异常: 运行时异常是可能被程序员避免的异常。与检查性异常相反,运行时异常可以在编译时被忽略,类似 NullPointerException、ArrayIndexOutOfBoundsException 之类,通常是可以编码避免的逻辑错误,具体根据需要来判断是否需要捕获,并不会在编译期强制要求。
在JVM中,Exception和Error都继承了Throwable类,在 Java 中只有 Throwable 类型的实例才可以被抛出(throw)或者捕获(catch),它是异常处理机制的基本组成类型。
throw-catch
- 首先来说怎么抛出一个异常:
要知道 throw new NullPointerException 也是一个表达式,返回一个Nothing, 所以我们可以用String类型接收它,因为Nothing是任何类的子类
1 | val aWeirdValue: String = throw new NullPointerException // also crashes |
- 然后我们来说怎么catch一个异常
1 | def getInt(withExceptions: Boolean): Int = |

自定义异常
scala中自定义异常也非常容易,只需要让其继承某一异常类即可
1 | /* |
Packaging and Imports
Functional Programming in Scala
What’s a Function, Really
我们要学习scala中的函数式编程特性,就先要弄明白函数式编程是什么。
函数式编程中的函数指的并不是编程语言中的函数(或方法),它指的是数学意义上的函数,即映射关系(如:y = f(x)),就是 y 和 x 的对应关系。
函数式编程的特性
函数是一等公民,它的意思就是函数与其他数据类型一样,可以把它们存在数组里,当做参数传递,赋值给变量,可以在任何地方定义,在函数内或函数外,可以作为函数的参数和返回值,也可以对函数进行组合。
高阶函数(Higher Order Function, HOF),在函数式编程中, 高阶函数的定义是把其它函数当做参数,或者返回一个函数作为结果的函数。
柯里化,就是把一个多参数的函数 f,转换为单参数函数 g,并且这个函数的返回值也是一个函数。
Side Effects,所谓“副作用”,指的是函数内部与外部互动(最典型的情况,就是修改全局变量的值),产生运算以外的其他结果。
在像 C++ 这样的命令式语言中,函数的意义与数学函数完全不同。例如,假设我们有一个 C++ 函数,它接受一个浮点参数并返回一个浮点结果。从表面上看它可能看起来有点像数学函数意义上的映射实数成实数,但是 C++ 函数可以做的不仅仅是返回一个取决于其参数的数字,它还可以读写其他的全局变量,也可将将输出写入屏幕并接收来自用户的输入。但是,在纯函数式语言中,函数只能读取其参数提供给它的内容,并且它对世界产生影响的唯一方式就是通过它返回的值。纯函数,纯函数编程和函数编程的区别在于:是否允许在函数内部执行一些非函数式的操作,同时这些操作是否会暴露给系统中的其他地方?也就是是否存在副作用。如果不存在副作用,或者说可以不用在意这些副作用,那么就将其称为纯粹的函数式编程。
引用透明性,函数无论在何处、何时调用,如果使用相同的输入总能持续地得到相同的结果,就具备了函数式的特征。这种不依赖外部变量或“状态”,只依赖输入的参数的特性就被称为引用透明性(referential transparency)。“没有可感知的副作用”(比如不改变对调用者可见的变量,进行I/O,不抛出异常等)的这些限制都隐含着引用透明性
- 递归和迭代,对于函数式而言,循环体有一个无法避免的副作用,就是它会修改某些对象的状态,通常这些对象又是和其他部分共享的。而且也因为变量值是不可变的,纯函数编程语言也无法实现循环。所以纯函数编程语言通常不包含像 while 和 for 这样的迭代构造器,而是采用的无需修改的递归。
function value
Scala编译后是要放到JVM上运行的,其实本质上是一个面向对象的编程语言。但是为了让他可以实现函数式编程,就需要对其方法(method)做一定的包装(变为函数)。因此,我们要理解——在scala里面,函数和方法是两个不同的概念。
- 函数接口是 FunctionN(N可以是1,2,3…代表接收的参数个数) ,将其理解为一个实体,在实体中包装了一个行为方式,写在了其apply方法里
- 方法是 Method(在实体中用def定义),将其理解为一种行为方式,这个行为方式可以通过转换来包装成一个FunctionN实体
比如说,我想创建一个函数,它可以将字符串转移成数字,那么显然它接受1个参数,并返回一个Int类型的值。那么此时我需要用到Function1接口:
1 | // stringToIntConverter 接收String类型的参数,返回 Int类型的值 |
Function1接口的源码如下:我们看到,其内部只有一个apply函数,之前我们学过,在一个对象后面加上(),编译器就会自动调用该类中的apply函数
1 | .implicitNotFound(msg = "No implicit view available from ${T1} => ${R}.") |
再比如说,我想创建一个函数,它可以实现两个Int值相加,那么此时我需要用Function2接口
1 | val adder = new Function2[Int, Int, Int] { |
语法糖
事实上,我们在创建函数的时候, Function2[A,B,R] 与 (A,B) => R是等价的,因此为了简介,我们也可以直接这样写:
1 | val adder: ((Int, Int) => Int) = new Function2[Int, Int, Int] { |
是不是感觉比原来更复杂了,我们接下来学习匿名函数的时候会对其做一个简化
练习
- write a function which takes 2 strings and concatenates them
1 | val concatenator:((String,String) => String ) = new Function2[Int,Int,Int]{ |
- transform the MyPredicate and MyTransformer into function types
要对MyList中的MyPredicate和MyTransformer做一个改造,使其成为function types. 事实上,我们可以直接删去这两个接口
1 | package exercises |
- define a function which takes an int and returns another function which takes an int and returns an int
对于这个问题我们要从两个方面来思考:
- 这个函数是什么类型的?接收一个Int,返回一个function,因此是Function1类型的
- 怎么实现?如下
1 | val superAdder: Function1[Int, Function1[Int, Int]] = new Function1[Int, Function1[Int, Int]] { |
Anonymous Functions
不知道你们有没有发现,我们利用Function type来实现函数接口,从语法上还是遵循了 定义类、重载函数的思想,实际上还没有摆脱面向对象的编程思维。
因此我们可以使用 匿名函数,也就是 JavaScript中的 Lambda函数。 Scala 中定义匿名函数的语法很简单,箭头左边是参数列表,右边是函数体。
使用匿名函数后,我们的代码变得更简洁了。比如:
1 | val doubler = (x:Int) => x*2 |
同样我们可以在匿名函数中定义多个参数:
1 | val adder = (x: Int, y: Int) => x+y |
也可以不给匿名函数传入参数:
1 | val justDoSth = () => 3 |
需要注意,println(justDoSth) 和 println(justDoSth()) 是不同的,前者是打印函数本身,后者是打印调用函数后返回的结果
语法糖
我们再来介绍一个匿名类中的语法糖:可以用下划线来代替传入的参数
1 | val niceIncrementer: Int => Int = _ + 1 // equivalant to x => x+1 |
Exercise
现在我们将MyList中的FunctionN接口都改为匿名函数
改之前:
1 | object ListTest extends App { |
改之后:
1 |
|
然后我们将之前的 super adder改成匿名函数
1 | //改之前 |
Higher-Order-Functions and Curries
我们之前说过scala中的高阶函数要么接收一个函数为参数,要么返回一个函数。
比如说,我想设计一个可以重复将某一函数执行n次的函数,那么就需要传入一个函数f、参数n、初始值x
如 nTimes(f,3,x) = nTimes(f,2,f(x)) = nTimes(f,1,f(f(x)))=nTimes(f,0,f(f(f(x))))
1 | def nTimes(f:Int => Int, n: Int, x:Int) : Int = |
但我们有没有感到一丝奇怪,就是我们说的函数式编程,是希望像数学里的那样,实现一个映射关系。每次只对一个参数x进行操作,而不是像上面的调用那样,一次要输入3个参数
因此我们可以对nTimes函数做一个改进:改进后的nTimes,每次返回的不再是Int,而是一个(Int => Int)的函数, 因此,我们可以调用返回的函数去计算
但是这种方法也有弊端,就是会出现栈溢出的问题,不是下尾递归
1 | def nTimesBetter(f: Int => Int, n: Int): (Int => Int) = |
多个参数列表
多个参数列表(multiple parameter lists)常常和柯里化常常一起用,比如说,我想创建一个函数,它可以将double类型的浮点数格式化成想要的样子。正常来说,需要输入两个参数,一个是需要被格式化的浮点数,另一个是String类型的格式本身。但是若要对其进行柯里化,就只能让函数每次只接收一个参数。
因此,我们可以使用多个参数列表的语法。也就是使用多个(), 注意,括号的顺序和参数输入的顺序是有关的。比如说下面这个curriedFormatter,需要先输入String, 然后在去处理Double,最后返回String
其本质上是一个String => Double => String 的函数
1 | def curriedFormatter(c: String)(x: Double) : String = c.format(x) |
需要注意的是,如果使用 多个参数列表的话,我们在定义子函数的时候(如上面的standardFormat和preciseFormat),需要显式得注明函数接受的参数及其返回类型。
为了把多个参数列表讲清楚,我们在来举一个三个参数列表的例子:
- 首先,我定义了triplefunc,它是一个
String => Double => Int =>String的函数 - 然后,我有定义了一个doubleFormatter, 它是triplefunc接收了一个参数后的返回值,类型为
Double => Int => String - 接着,我又定义了一个IntAdder,它是doubleFormatter接收了一个参数后的返回值,类型为
Int=>String
1 | def triplefunc(c:String)(x:Double)(y:Int):String = c.format(x+y) |
Exercises
1 | /* |
Exercise1
首先对MyList进行改进,新加入了四个高阶函数
- abstract class
1 | abstract class MyList[+A]{ |
- object Empty
1 | case object Empty extends MyList[Nothing] { |
- class Cons
1 | case class Cons[+A](h: A, t: MyList[A]) extends MyList[A] { |
map, flatMap, filter and for-comprehensions
我们之前实现了自己的List,并在其中实现了map,flatmap和filter的相关功能,现在来介绍Scala中的内置方法。
首先来创建一个List:
1 | val list = List(1,2,3) |
- map
1 | println(list.map(_ + 1)) //List(2, 3, 4) |
- filter
1 | println(list.filter(_ % 2 == 0)) //List(2) |
- flatMap
1 | val toPair = (x: Int) => List(x, x+1) |
- foreach
1 | list.foreach(println)// 1,2,3 |
我们看到这些函数和我们之前自己实现的功能是一样的。
多重循环
现在如果我想输出两个甚至更多个list的笛卡尔积,该如何操作?在面向对象的语言中,我们会使用双重循环for-loops,但是在scala中,我们需要用flatmap和map的组合来实现
- 如果是双重循环,外循环中的每个值,都会产生一个list,是一对多的映射,因此使用flatMap;内循环每个值只生成一个对应的值,是一对一映射,因此使用map
- 如果是三重循环,除了最内层循环使用map,外层循环都会产生一个list,因此使用flatMap
1 | val numbers = List(1,2,3,4) |
事实上,这种代码的可读性是比较差的,因此,scala提供了多重循环的简化版本。也就是 for循环,如下:
1 | val forCombinations = for { |
for 循环中的 yield 会把当前的元素记下来,保存在集合中,循环结束后将返回该集合。Scala中 for 循环是有返回值的。如果被循环的是 Map,返回的就是 Map,被循环的是 List,返回的就是 List,以此类推。
上面这句话的意思就是,对于numbers中的偶数、chars中的字符,colors中的颜色,都将其组合并保存在集合中
但是这只是一种语法糖,在编译器内部,还是将for语句转换成map和flatmap来执行的。
- 注意,以下两种写法都是可以的,属于语法重载。
1 | list.map { x => |
发散
试问,我们之前创建的MyList对象,是不是也可以使用for语句进行循环呢?可以的,只要我们在函数内定义了逻辑正确的map、flatMap、filter函数,就可以应用for
1 | val listOfIntegers: MyList[Int] = new Cons(1, new Cons(2, new Cons(3, Empty))) |
A Collections Overview
这一节我们来学习scala中的 集合类,这是一个比较大的类,包含了很多子类.
首先,我们要了解scala中的集合分为 mutable(可变) collection 和immutable(不可变) collection。
- 可变集合可以在适当的地方被更新或扩展。这意味着你可以修改,添加,移除一个集合的元素。
- 不可变集合类,相比之下,永远不会改变。不过,你仍然可以模拟添加,移除或更新操作。但是这些操作将在每一种情况下都返回一个新的集合,同时使原来的集合不发生改变。
之前我们自己写的MyList,List都属于immutable collection之列。
mutable collection架构图

在本篇文章中不会介绍mutable collection的相关内容
immutable collection 架构图

Traversable是所有collection的母类,然后在Iterable下面主要分三大类:Set,Map, 和Seq。 Set是不包含重复数据的集合, Maps是键值对集合,Seq是适合存有序重复数据的列表集合。
Seq下面还是有 IndexSeq 和 LinearSeq两种, 前者可以通过 索引来快速定位元素。后者的元素则是线性的,按照某种顺序排列的。
Sequences: List, Array, Vector
首先我们来看看 Seq接口提供了哪些操作:
1 | trait Seq[+A] { |
Seq接口是一个很general(不知道怎么翻译了)的接口,其中的元素是按照清晰地顺序进行排列的。而且可以通过下标index进行访问。
Seq接口提供很多操作:
在索引和迭代方面
apply: 可以直接通过Seq(1,3,2,4)这样的方法构造Seq- iterator: 详细用法可以参考文档
- length:返回seq长度
- reverse: 倒转seq
创建新的Seq方面
- concatenation: 两个seq连接
- appending: seq之后连一个元素
- prepending: seq之前连一个元素
- 其他
- grouping
- sorting
- zipping
- searching
- slicing
1 | val aSequence = Seq(1,3,2,4) |
Ranges
scala中的Range也是一种类型,其本质上是一种特殊的 Array
range有两种定义方式:
- 利用until / to 定义 . to代表前闭后闭区间;until代表前闭后开区间
1 | val aRange: Seq[Int] = 1 until 10 |
- 利用Range(A,B) by C 定义。Range(A,B)代表A和B的前闭后开区间 ,C代表自定义步长
1 | //范围需要在最大值和最小值范围内即 2 <= 元素 <= 19 |
利用 Ranges我们可以实现类似循环的效果:
1 | (1 to 10).foreach(x => println("Hello")) // 打印10遍 Hello |
List
List列表:不可变
LIst支持在头部快速添加和移除条目,意味着模式匹配很顺畅, head、tail、isEmpty操作只需要 $O(1)$的复杂度。
大多数List操作还是需要遍历整个列表的,需要O(n)的复杂度,如length,reverse。
List不支持索引直接定位,如 list(2)=10 (非法); 但是可以使用updated方法,但此方法也不是索引定位,而是线性复杂度的。
List列表跟其他语言中的数组非常像,二者都是同构的,同一个列表的所有元素必须是相同类型。
1 | val aList = List(1,2,3) |
Array
Array和List不一样,它和Java中的arrays是等价的
- 在创建的时候,可以预先其分配内存,而不对其进行赋值
- 在适当的位置可以被修改(更新),所以是部分可变的
- 可以和 Java的 T[] arrays互相操作
- 可以通过索引访问,速度很快
1 | // 这是创建一个长度为4的Array,同时赋值 |
- seq和array之间的转化
1 | // arrays and seq |
Vector
vector是另外一个独立的体系,也是 Imuutable的
- vector可以利用索引来进行读写,复杂度为$O(\log_{32}(n))$,因此vector的索引操作是非常快的
- 可以使用append和prepend
- 底层数据结构是fixed-branched Trie树(字典树),
- 当vector中数据很大时,表现很好
- 可以使用prepend和append方法,也可以调用 updated 进行更新
1 | val vector: Vector[Int] = Vector(1,2,3) |
- vectors和lists性能对比
在数据量很大的情况下,vectors的表现要远远优于list:
首先我们写一个函数,对一个长度为1,000,000的Seq(vector和list都继承自seq),随机替换seq中的某一个值,重复1,000遍。最终返回平均每次updated操作的运算时间。
1 | val maxRuns = 1000 |
我们看到,list和vector在updated 操作上,有着近三百多倍的差距,而且差距会随着规模的增大而继续拉大
Tuples and Maps
和List一样,Tuple也是不可变的,但是和list也有不同之处:元组可以包含不同类型的元素,但是list为元素为统一中类型
Tuples
声明元组的语法如下:
1 | val aTuple = new Tuple2(2,"hello scala")//最正规也最复杂的定义 |
事实上,scala会自动根据元组里面的元素类型以及个数去创建 TuplesN[],N最大为22(因为是根据FunctionN来的),所以说元组的最大容量只有22
- tuple 访问元素的方法
tuple访问里面的第一个元素用._1; 第二个元素用._2 ,以此类推
如果想要修改tuple中的元素,需要使用copy方法
1 | println(aTuple._1) // 2 |
Maps
- Maps是键值对集合,可以由如下定义:
1 | // string 是key, Int 是value |
- 判断map是否包含某个键
1 | println(phonebook.contains("Jim"))// true |
- 由于map是immutable的,因此如果要往原来的map里插入新键值对,
1 | val newPairing = "Mary" -> 678 |
- 让tuples打印得更漂亮
1 | println(tuple.toString) |
functionals on maps
- map 函数
1 | println(phonebook.map(pair => pair._1.toLowerCase -> pair._2)) |
- filter函数
1 | println(phonebook.view.filterKeys(x => x.startsWith("J")).toMap) |
- mapValues
1 | println(phonebook.view.mapValues(number => "0245-" + number).toMap) |
map与其结构之间的转换
1 | // conversions to other collections |
groupBy函数
groupBy函数比较有用,可以将List中的元素分成组。比如说
1 | val names = List("Bob", "James", "Angela", "Mary", "Daniel", "Jim") |
Exercise
1 | /* |
Options
现在来介绍一下Scala中一种特殊的类: Option
Option 可以看做一个容器要么有东西(Some),要么什么东西都没有。我们可将其看成一个长度为0或1的List。当Option里面有东西的时候,这个List的长度是1(也就是 Some),而当你的Option里没有东西的时候,它的长度是0(也就是 None)。
那么Option可以应用在哪里?我们设想一个情况:打印一个还未分配内存的字符串,显然,这会导致 Null Pointer Error并使得程序崩溃。
1 | val string: String = null |
为了解决这个问题,正常方法可以这样写,但是如果通篇都是这样的处理,就会显得很杂乱
1 | val string : String = null |
此时,Option就发挥其作用了。Option可以作为一个wrapper,被它包含的值可以使存在的,也可以是Nothing。
1 | def unsafeMethod(): String = null |
此外,在 map 中,我们可以用Option来包裹 map.get("key") 如果key不存在,那么值就是 None
又比如,在访问一个空列表的头部的时候,也可以用Option。
我的理解是,option有点像植物大战僵尸中的南瓜,南瓜里面可以有植物,也可以什么都没有,但南瓜放在那边就会起一个保护作用。
使用 getOrElse() 方法
以下是示例程序,显示了如何使用getOrElse()方法访问值或不存在值时的默认值。
比如说:
1 | def backupMethod(): String = "A valid result" |
事实上,我们可以在进行优化,在定义函数的时候,就将返回值定为 Option, 这样可读性更强,而且对用户更友好(api中已经设定了option,用户不用自己再套一层option)
1 | def betterUnsafeMethod(): Option[String] = None |
functions on Options
1 | println(myFirstOption.isEmpty) // 判断是否为空 |
Option也可以使用map、filter和flatMap函数
1 | val myFirstOption: Option[Int] = Some(4) |
for-comprehensions
在设计api的时候,如果返回值可能是None,我们需要在前面套一层Option使得api更加安全。
1 | class Connection { |
Handling Failure
Pattern Matching
Pattern Matching
pattern matching是scala中很重要的一部分,它类似于switch case,可以对一个值进行条件判断,然后针对不同的条件进行不同的处理。
但是Scala的模式匹配的功能比Java的swich case语法的功能要强大的多,Java的swich case语法只能对值进行匹配。但是Scala的模式匹配除了可以对值进行匹配之外,还可以对类型进行匹配、对Array和List的元素情况进行匹配、对case class进行匹配、甚至对有值或没值(Option)进行匹配。
一个常见的pattern match的语法如下:很容易理解,就是swich case
1 | val random = new Random |
在使用pattern matching的时候我们要注意几点:
- case 要按照一定的顺序来组织,增强可读性
- 为了防止出现 MatchError的情况,一定要设置 Wildcard,也就是默认不匹配情况下的返回值。(用
_符号)
pattern matching还有其他好用的特性
解耦合
模式匹配不单匹配值,甚至可以匹配类中的某个成员变量来进行条件筛选
1 | case class Person(name: String, age: Int) |
PM在继承类中的应用
Pattern Matching 甚至可以匹配子类类型。如下:
1 | sealed class Animal |
Exercise
给出如下要求:
1 | /* |
要我们用PM实现代码到数学公式的转换。这里最难想到的就是乘法的处理:
Prod(Number(2), Number(1)), 对2和1不需要改,直接变成2*1Prod(Sum(Number(2),Number(1)),Number3),那么前面的Sum(Number(2),Number(1))就需要额外加个括号,符合预算规则Prod(Prod(Number(2),Number(1)),Number(3)),那么不需要括号,计算出2*1之后在和3计算得到2*1*3
1 | trait Expr |
测试:
1 | println(show(Sum(Number(2), Number(3)))) |
ALL the Patterns
这一节我们来系统总结一下总共有多少Patterns可以供我们去匹配
constants
case里面可以是很多类型,数字、字符串、布尔值、对象等
1 | val x: Any = "Scala" |
variables
1 | val matchAVariable = x match { |
wildcard
1 | val matchAnything = x match { |
tuples
1 | val aTuple = (1,2) |
甚至可以匹配 嵌套元组:
1 | val nestedTuple = (1, (2, 3)) |
case classes
constructor pattern可以匹配我们自己创建的case class。比如说我创建了一个MyList[Int]类型的列表。case类型可以类似于case class的构造器,用来解构类中的成员
1 | val aList: MyList[Int] = Cons(1, Cons(2, Empty)) |
list
List patterns非常有用,它可以有很多种形式的case
case List(1, _, _, _)匹配开头为1,长度为4的Listcase List(1, _*)匹配开头为1,长度不限的Listcase 1 :: List(_)匹配开头为1的Listcase List(1,2,_) :+ 42匹配以42结束的Listcase h :: t => h + "" + processList(t)提取list的头元素和尾元素
1 | val aStandardList = List(1,2,3,42) |
type
scala还可以匹配输入对象的类型,如下:
1 | val unknown: Any = 2 |
name binding
1 | val nameBindingMatch = aList match { |
multi-patterns
multiple patterns就是将两个模式用 Pipe符号连接起来——只要符合其中一个模式,就匹配成功,如下:
1 | // 8 - multi-patterns |
if guards
可在模式后添加 if 语句
1 | val secondElementSpecial = aList match { |
注明
JVM中会存在type erase的情况,如下:
此时打印 numbersMath,会得到 a list of strings,这是因为在 Java刚开始被创建时,是没有泛型这一概念的,泛型直到Java5才被加入。因此,JVM在做类型判断的时候,为了能让Java1的程序也能运行,在判断的时候,将泛型全部抹去了
因此,在java内部,事实上不会对List究竟是哪一种类型的做匹配,而是只匹配是否为List
1 | val numbers: List[Int] = List(1, 2, 3) |
Patterns Everywhere
事实上,模式匹配的思想在 scala中随处可见:
在try-catch中
1 | try { |
在try-catch中的case 其实是简写的形式,事实上在catch里面也有一个match,如下
1 | try { |
在 for 中
1 | val list = List(1,2,3,4) |
Tuple, List
可以直接提取出tuple、list中的元素,这也包含了PM的思想。
1 | val tuple = (1,2,3) |
partial function
有时我们会遇到这样子的函数,可能会被搞得不知道是什么意思,其实这也是PM的简化形式
1 | val list = List(1,2,3,4) |
省去了对每一个list中的元素x做match的过程
1 | val mappedList2 = list.map { x => x match { |