Flink学习
设计思想
大数据运算主要有2个领域:1:流式计算 2:批量计算。在数据操作层面可以看做如下的两类
有限数据集:数据大小有限(固定大小,比如固定的文件),用于批处理。比如说MapReduce,Spark
无限数据集:数据持续增长(属于无限大小,比如kafka中的日志数据,总是有新数据进入,并且不知道什么时候结束或者是永远不结束),用于流式处理。
我们要学习的Flink就是一个面向流处理和批处理的分布式计算框架,既支持流处理,也支持批处理.
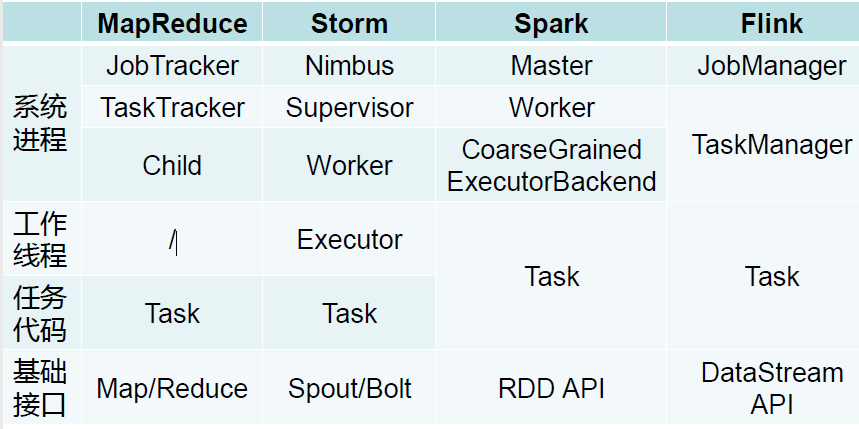
现在我们来看看三种计算框架的区别:
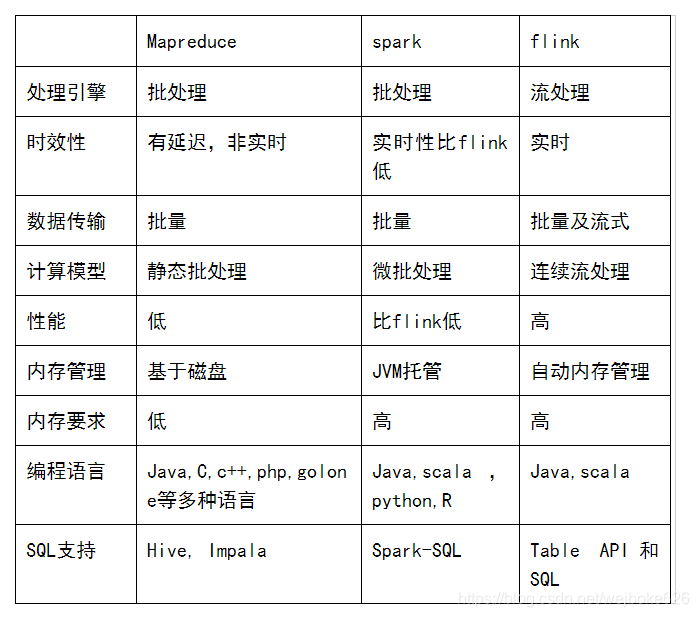
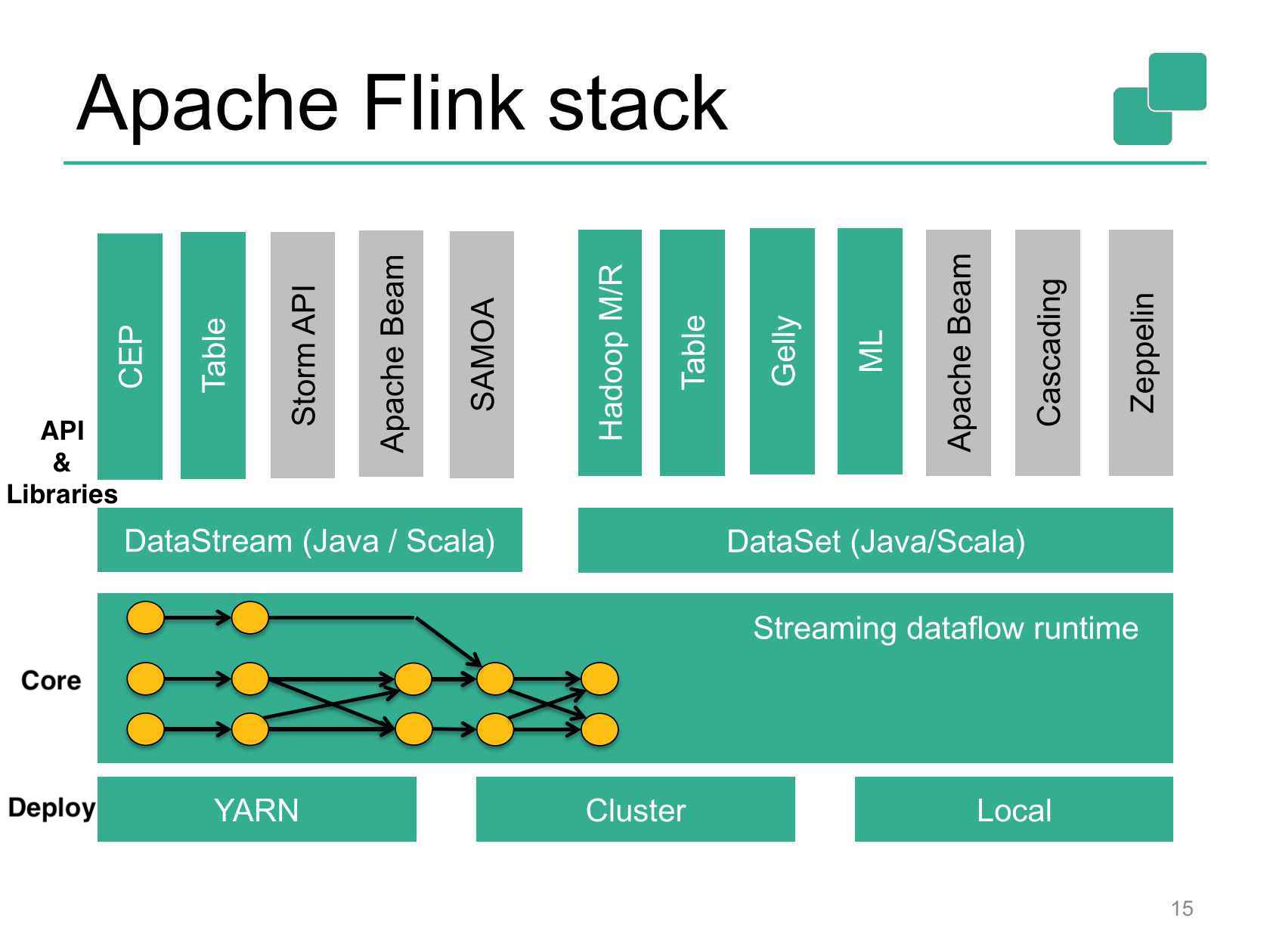
下图是Flink的技术栈,我们看到最上面一层是工具库,中间层是输入数据的类型(有流数据和固定数据),第三层是Stream Dataflow Engine,是Flink的核心部分。最下面一层是Flink的底层依赖
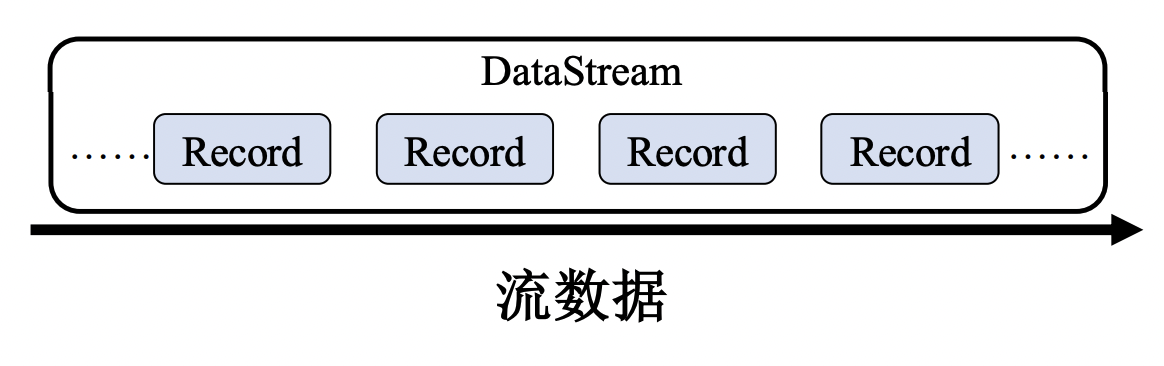
数据模型
与Storm类似,Flink将输入数据看作是一 个不间断的、无界的连续记录序列
有所不同的是,Flink将这一系列的记录抽象成DataStream 类似于RDD,DataStream是不可变的
这里的不可变,指的是unmutable, 即我们对DataSteam进行修改的话,会返回一个新的Stream,原来的Stream不会发生变化
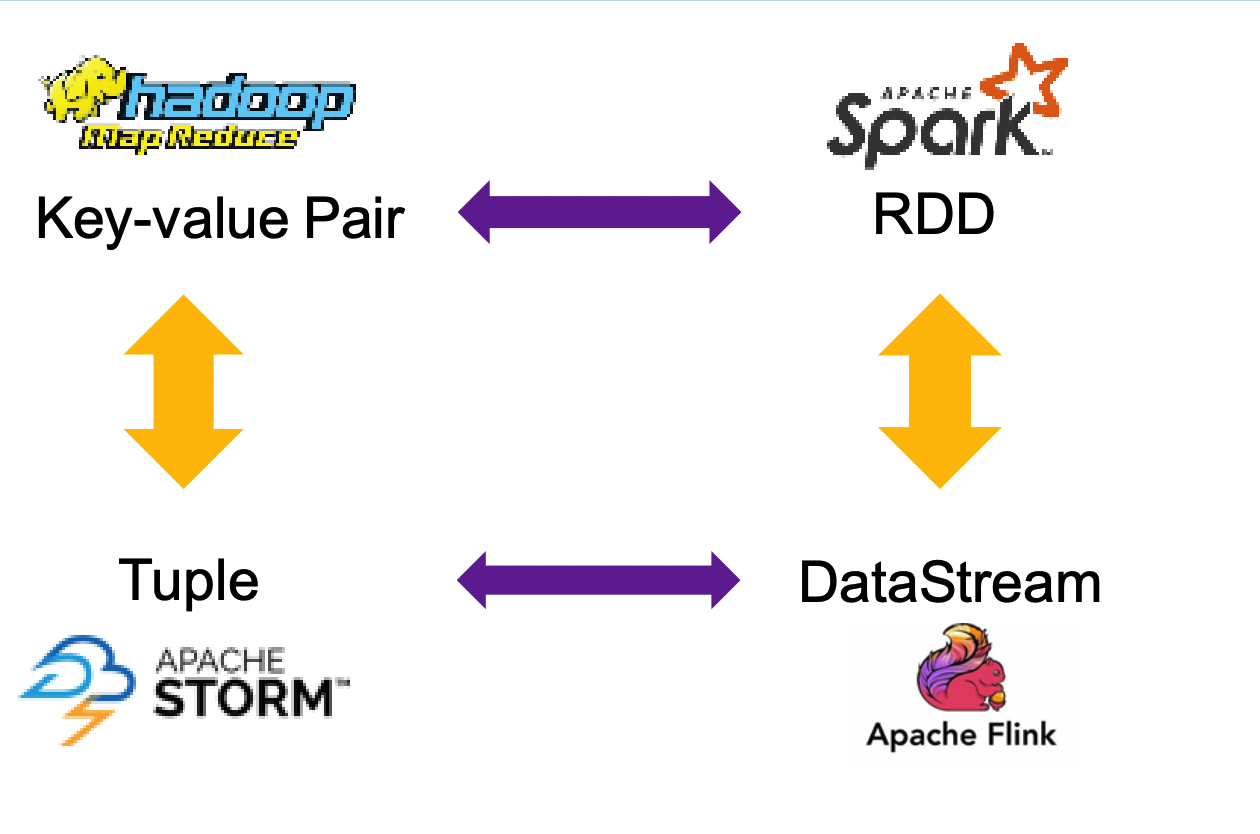
现在对之前学过的几个计算框架中的数据模型做一个总结:
- MapReduce: Key-value Pair
- Spark: RDD, 实际上就是键值对的集合
- Storm: Tuple
- Flink: DataStream 实际上是Tuple的集合
计算模型
Flink和Spark有点像,也是一系列的变换操作构成一张有向无环图, 即描述计算过程的DAG
Flink算子也分为3类:
- 数据源(DataSource)
- 转换(Transformation)
- 数据池(DataSink)
DataSource
| 操作算子 | 含义 |
|---|---|
| fromElements(elements) | 从相同类型的记录创建DataStream |
| fromCollection(collection) | 从内存集合创建DataStream |
| readTextFile(path) | 逐行读取文件内容来创建DataStream |
| socketTextSteam(hostname,port) | 接收来自套接字的内容来创建DataStream |
| addSource(customer-source-func) | 使用户自定义source func来创建DataStream |
Transformation
| 操作算子 | 含义 |
|---|---|
| map | 将DataSet中的每一个元素转换为另外一个元素,返回一个新的DataStream |
| flatMap | 与map类似,但是对DataStream中的每个记录都可以映射成0个或者多个新的记录 |
| union(otherDataStream) | 若干个数据类型相同的DataStream,取其并集得到一个新的DataStream |
| connect(otherDataStream) | 两个数据类型可能不同的DataStream,取并集得到一个新的DataStream |
| keyBy(key) | 以给定的key划分DataStream来创建KeyedStream(类似于Spark中的PairRDD) |
| window(WubdiwAssigner) | 对KeyedStream中按键按分组的记录根据WindowAssigner将其划分为多个窗口,返回一个WindowedStream |
| reduce(func) | 通过func简化DataStream中的记录,返回一个新的DataStream |
| aggregate(func) | 对DataStream中每个窗口中记录使用func聚合为结果记录,返回一个新DataStream |
| join(otherDataStream) | [K,V1]和[K,V2] 分别属于两个DataStream.返回一个[K,(V1,V2)]组成的JoinedStream |
DataSink
| 操作算子 | 含义 |
|---|---|
| print() | 将DataStream写入标准输出 |
| writeAsText(path) | 将DataStream以文本格式写入指定的文件中 |
| writeToSocket(hostname,port, schema) | 将DataStream作为字节数组写入套接字,输出格式由schema指定 |
| addSink(customer-sink-func) | 使用用户自定义sinkfunc作为数据池操作 |
逻辑计算模型
通常来说,Flink系统的一个应用对应一个DAG,而Spark中的一个应用包含一个或者多个DAG
比如说下面这个Wordcount例子:我们假定socketTextStream和print的并行度为1,其余并行度为2
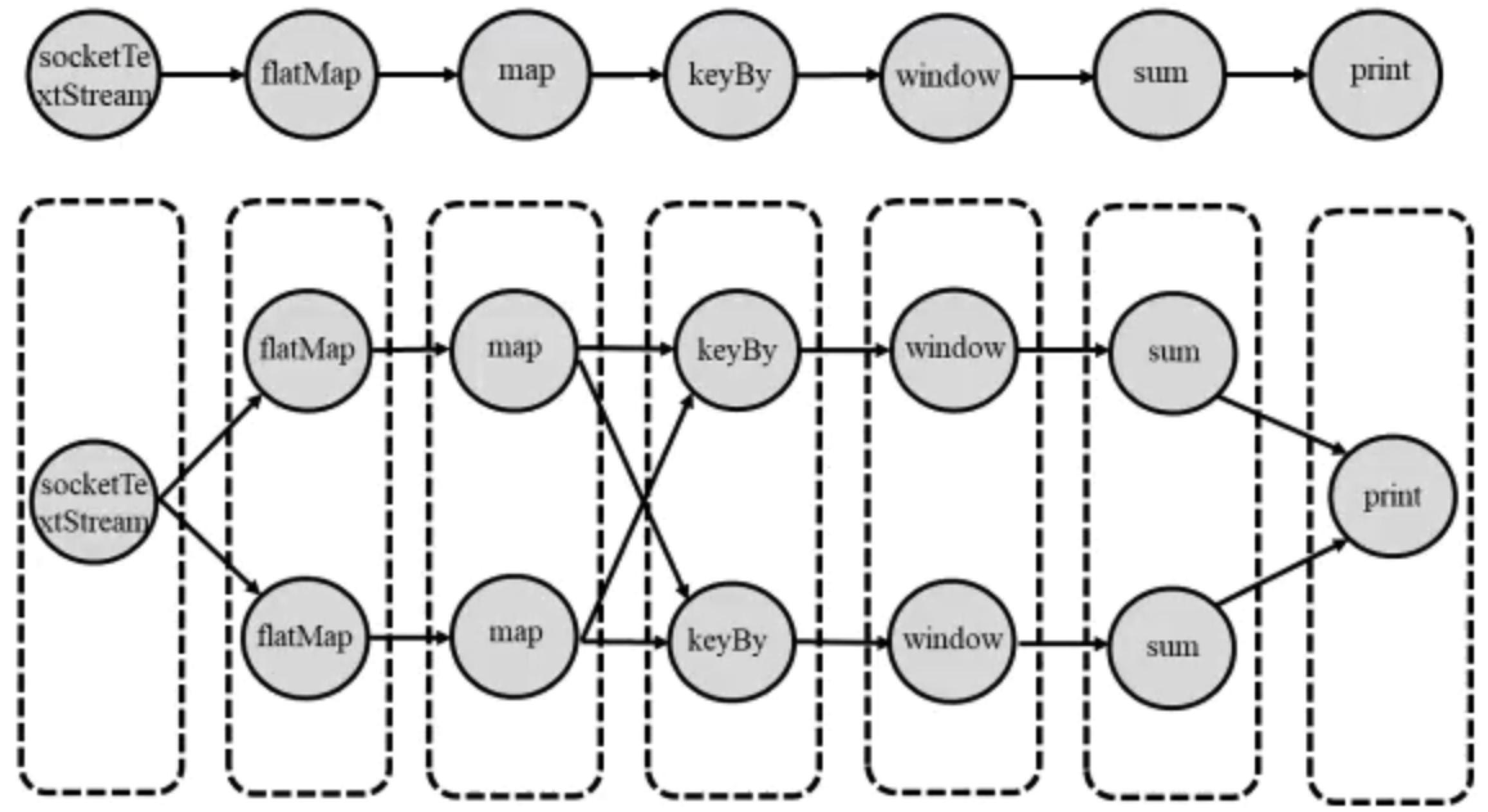
在Spark中,有两种逻辑计算模型:OperatorDAG和RDD Lineage。但是Flink只有DAG没有Datasteam Lineage
迭代模型
由于Flink和Spark相比,除了数据模型从固定的变成流动的之外,最重要的就是增加了迭代算子。因此我们要着重来介绍这个新的算子,其他部分和spark是差不多的
Flink中的迭代过程内部必定存在环路,和Spark不一样,Spark中的迭代需要我们自己设计算法,但在Flink中我们将迭代部分整体视为一个算子,计算的过程仍然是DAG, 如下:
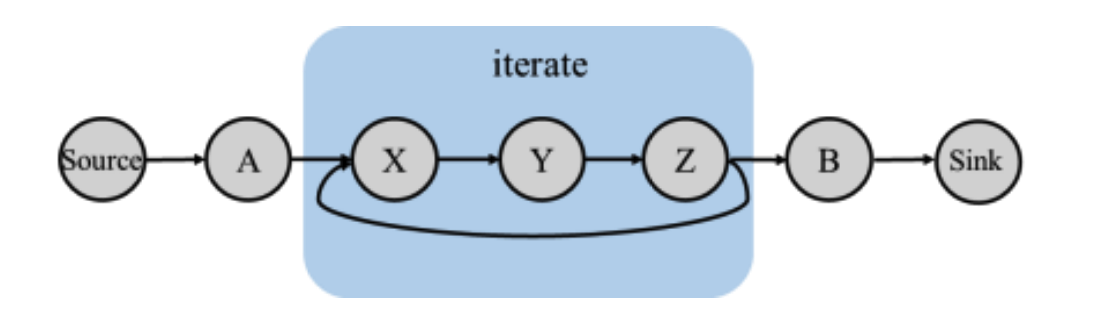
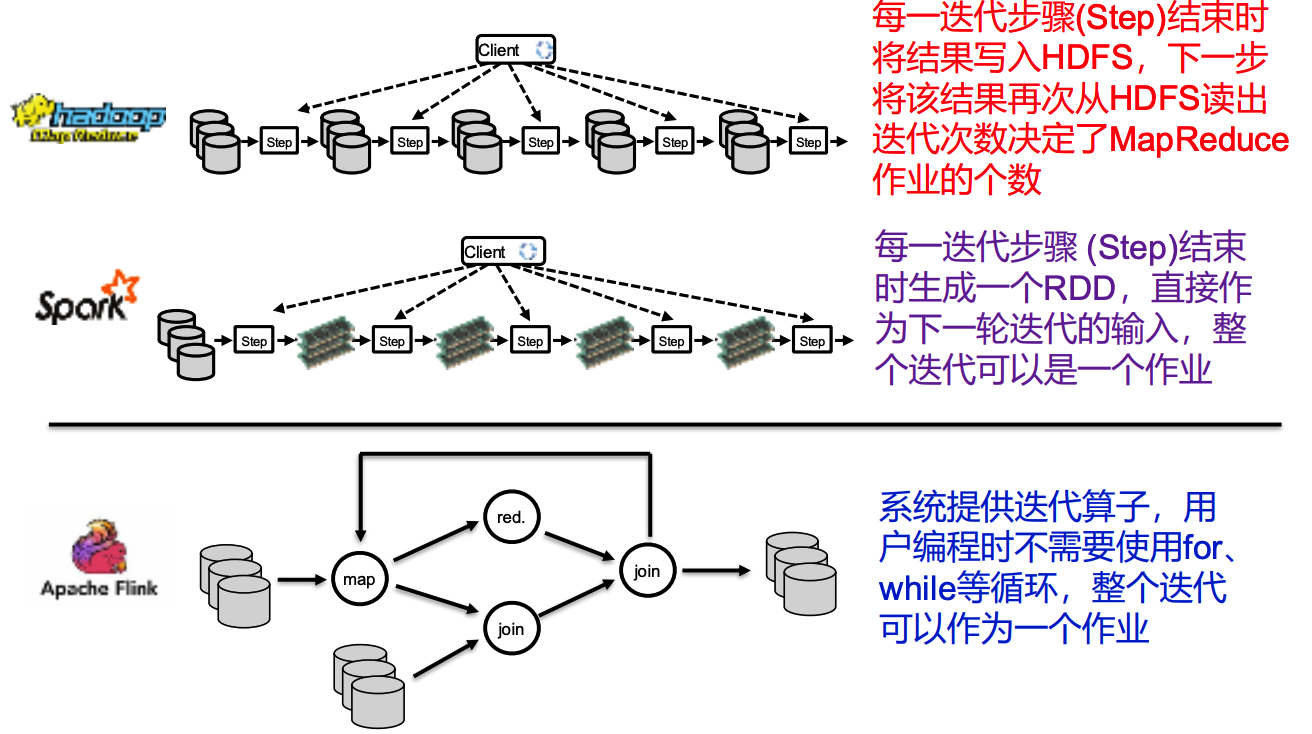
我们发现,Flink中系统提供了迭代算子,内置了一些优化,不需要我们手写for 和 while循环,因此性能更高。但是同样的,这种方法把整个系统变得更复杂了,丧失了一些编程的灵活性
还有一个问题,Spark、Flink这种计算框架中是否存在 If 算子或者 类似于Switch的算子?其实我们是需要这种算子的,因为if和switch这类的控制类的算子在逻辑中还是比较有用的。但是使用条件语句会让我们的DAG变得复杂,因为本来的DAG是静态的,数据朝着一个方向流动,一旦加了条件和控制之后,DAG会不断发生变化,这是不利于分布式系统的
所以我们把大数据处理系统也称为 Dataflow system, 而之前我们写的Java、C++都是Controlflow,这两者和计算机体系结构有关:
我们可以通过下面这个示意图来知悉两者关系:Controlflow 是指令和数据同时存储的,而Dataflow编程模型是算子级别的,把controlflow中的指令替换成算子
体系架构
架构图
Flink的架构和Spark非常类似,也是分为一个主节点和若干从节点。
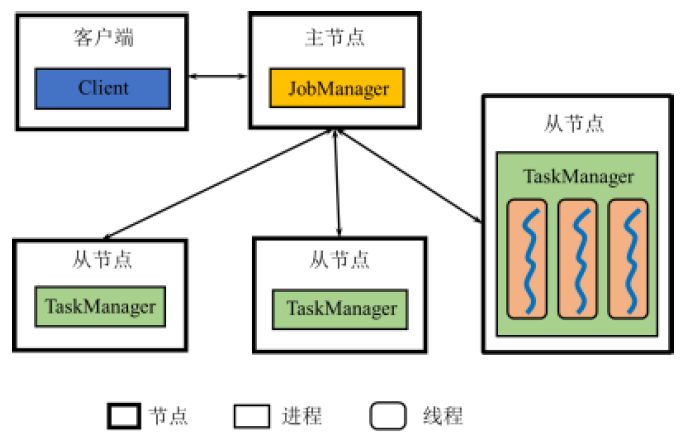
Standalone 模式架构图
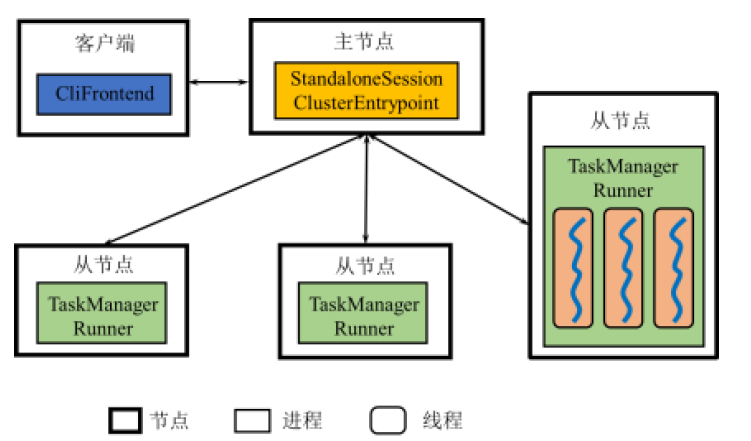
我们来逐步看一下每个部件的作用
- Client: 讲用户编写的DataStream 程序翻译为逻辑执行图病进行优化,并将优化后的逻辑执行图提交到JobManager。
- 在Standalone模式下,Client的进程名为 CliFrontend
- JobManager: 根据逻辑执行图产生物理执行图,负责协调系统的作业执行,包括任务调度,协调检查点和故障恢复等。
- 在Standalone模式下,JobManager还负责Flink系统的资源管理
- JobManager的进程名为 StandaloneSessionClusterEntryPoint
- TaskManager: 用来执行JobManager分配的任务,并且负责读取数据、缓存数据以及其他TaskManager进行数据传输
- 在Standalone模式下,TaskManager还负责所在节点的资源管理,将内存等资源抽象成若干个TaskSlot用于任务的执行
- TaskManager 的进程名为 TaskManagerRunner
Yarn模式架构
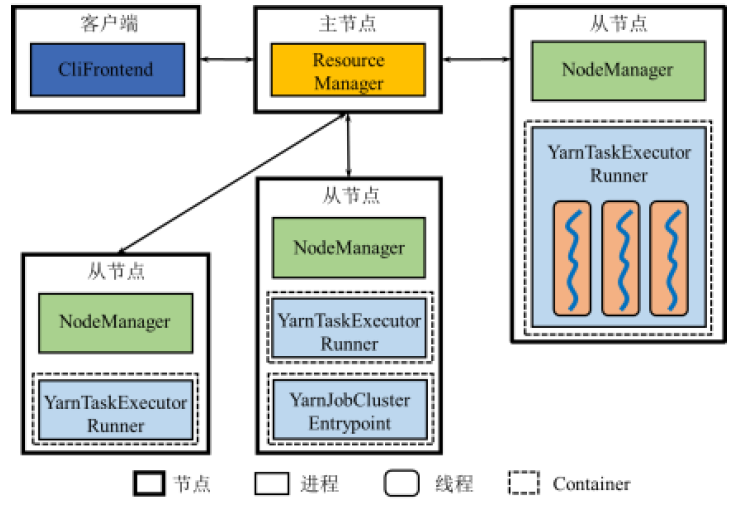
横向比较一下,从Yarn的角度来说就是让资源管理和作业管理分离
- Standalone模式中的JobManager、TaskManager对应变成了Resource Manager和NodeManager
应用程序执行流程
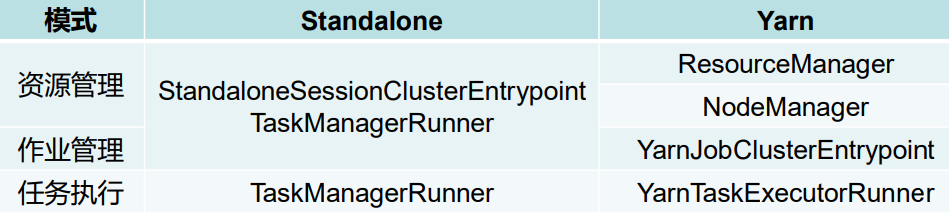
Standalone模式
- 客户端将用户编写的程序进行解析,并将 解析 后的作业描述交给StandaloneSessionClusterEntrypoint
- StandaloneSessionClusterEntrypoint根据 作业的描述进行任务分解,确定各个TaskManagerRunner所负责执行的任务
- TaskManagerRunner执行所负责的任务
提交方式
在Standalone模式下,当用户使用客户端 提交Flink应用程序时,可以选择Attached 方式或者Detached方式
- Attached提交方式:客户端与JobManager保持连接,可以获取关于应用程序执行的信息
- Detached提交方式:客户端与JobManager断开连接,无法获得关于应用程序执行的信息
这两种提交方式和Spark中的两种提交方式有点像。Attached和Client 比较类似,Detached和Cluster比较类似。
但是他们又有一些区别:
在spark 中,以cluster模式提交,其客户端还是存在的运行,只不过Driver从本地客户端跑到了远端集群当中;但是在Flink中用Detached方式提交,则是没有客户端了,没有办法获取应用程序的打印信息
Yarn 模式
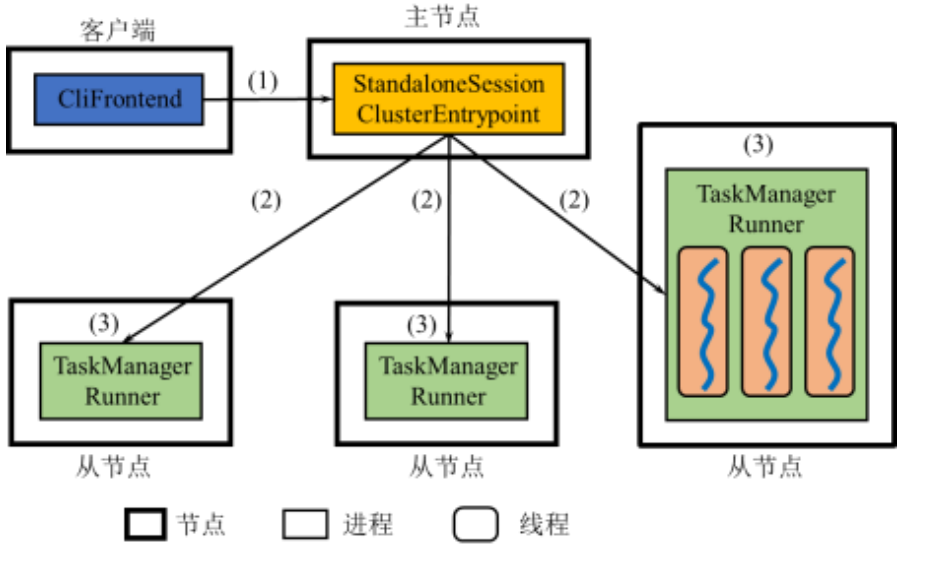
 我们看到Yarn的执行模式比Standalone要复杂得多,而且必须要用到HDFS
我们看到Yarn的执行模式比Standalone要复杂得多,而且必须要用到HDFS
客户端启动
CliFrontend进程,CliFrontend将用户编写的程序进行解 析,并将运行Flink系统的jar包以及配置文件上传至HDFSCliFrontend向ResourceManager申请启动YarnJobClusterEntrypoint (ApplicationMaster),ResourceManager确定启动YarnJobClusterEntrypoint的节点- 需启动
YarnJobClusterEntrypoint进程的节点上的NodeManager将 HDFS中的jar包与配置文件下载到该节点 NodeManager启动YarnJobClusterEntrypoint进程CliFrontend进程将解析后的作业描述交给YarnJobClusterEntrypointYarnJobClusterEntrypoint向ResourceManager注册,这样客户端可 以通过ResourceManager查看Flink应用程序的资源使用情况。YarnJobClusterEntrypoint根据作业的描述进行任务分解,并向ResourceManager申请启动这些任务的资源ResourceManager以Container形式向提出申请的YarnJobClusterEntrypoint分配资源。得到资源后,它在多个任务间 进行资源分配YarnJobClusterEntrypoint确定资源分配方案后,便与对应的NodeManager通信- 如果该
NodeManager所在节点尚未下载,则将HDFS中的jar包与配 置文件下载到本地,并在相应的Container中启动相应的YarnTaskExecutorRunner进程用于执行任务 - 各个任务向
YarnJobClusterEntrypoint汇报自己的状态和进度,以便让YarnJobClusterEntrypoint随时掌握各个任务的运行状态 - 随着部分任务执行结束,
YarnJobClusterEntrypoint逐步释放所占用 的资源,最终向ResourceManager注销并关闭自己
提交方式
- Attached提交方式:
CliFrontend将与YarnJobClusterEntrypoint保持连接,可以获取 关于应用程序执行的信息 - Detached提交方式:
CliFrontend将与YarnJobClusterEntrypoint断开连接,无法获得 关于应用程序执行的信息
我们之前说过,Yarn是应用作为粒度来管理的,Spark中的Application和MapReduce中的Job对应一个Yarn中的应用。在Flink当中,既可以以一个任务作为Yarn的一个应用,又可以拿整一个Application作为Yarn的一个应用
工作原理
现在我们来介绍Flink框架的内部工作原理,这其实和Sql的执行过程类似
- 首先生成逻辑执行计划,然后进行逻辑优化
- 接着生成物理执行计划,并执行
逻辑执行图的生成与优化
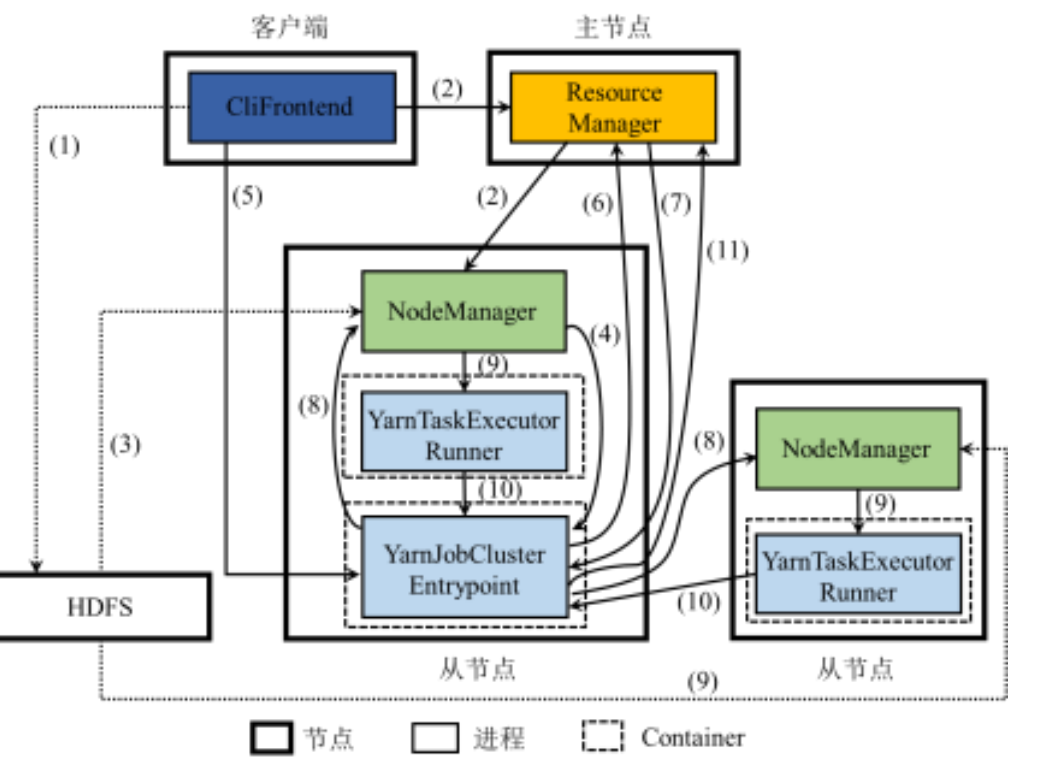
首先什么是逻辑执行图? 给定用户编写的DataStream程序,Flink的 Client将其解析产生逻辑执行图,即DAG.
那么逻辑执行图怎么优化? 有一种Chaining优化的方法:将”窄依赖“算子合并起来形成一个大的算子。如下图所示,我们将flatMap、map合并成一个 flatMap-map算子, 然后将keyBy、window、sum合并成一个keyed-window-sumAgg算子。
不能合并的情况:
- 因为 map到keyBy之间是宽依赖,有交叉的,因此不能合并。
- 并行度不同,不能合并
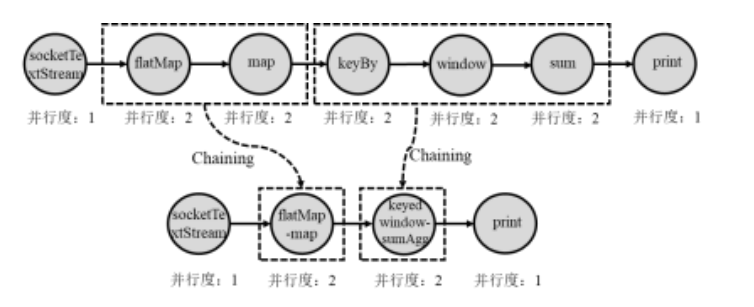
事实上,Flink的Chaining优化方法,很类似于Spark中的Pipeline,二者效果相同,只是名字有所不同
物理执行图的生成与任务分配
JobManager收到Client提交的逻辑执行图 之后,根据算子的并行度,将逻辑执行图 转换为物理执行图
物理执行图中的一个结点对应一个任务, 将分配给TaskManager来执行
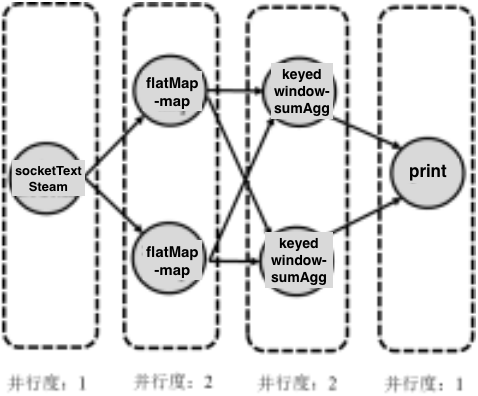
任务分配
JobManager将各算子的任务分配给 TaskManager
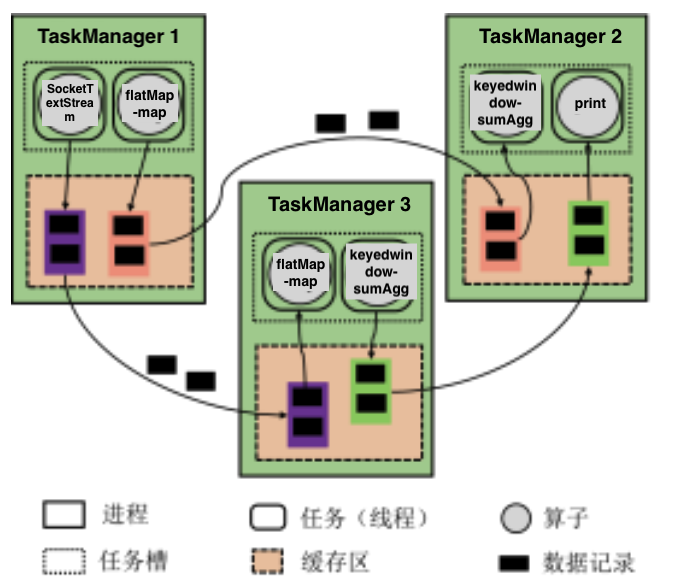
根据任务槽(TaskSlot)的容量,尽可能将存在数据传输关系的算子实例放在同一个任务槽, 保持数据传输的本地性。 和上图对照,发现上面4个算子放在一个TaskManager中,说明这一个流水线中的数据都是在内存中传递的。而对于下面一行,从socketTextStream到flatMap-map以及从keyedwindow-sumAgg到print的数据传输是在节点之间进行的
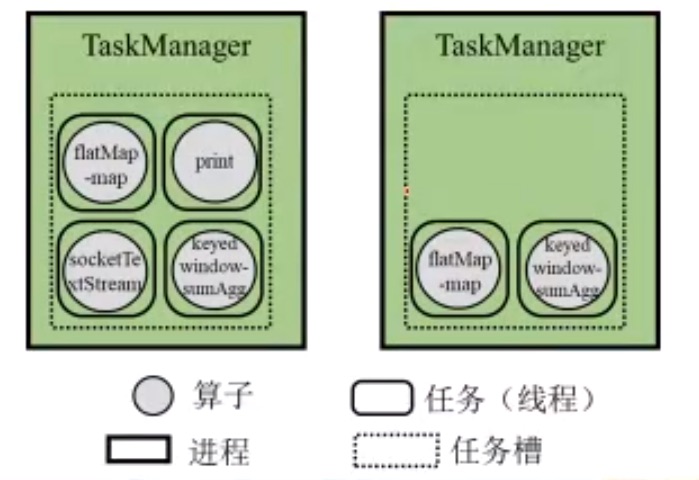
从逻辑执行图到物理执行图的整个过程如下图所示:
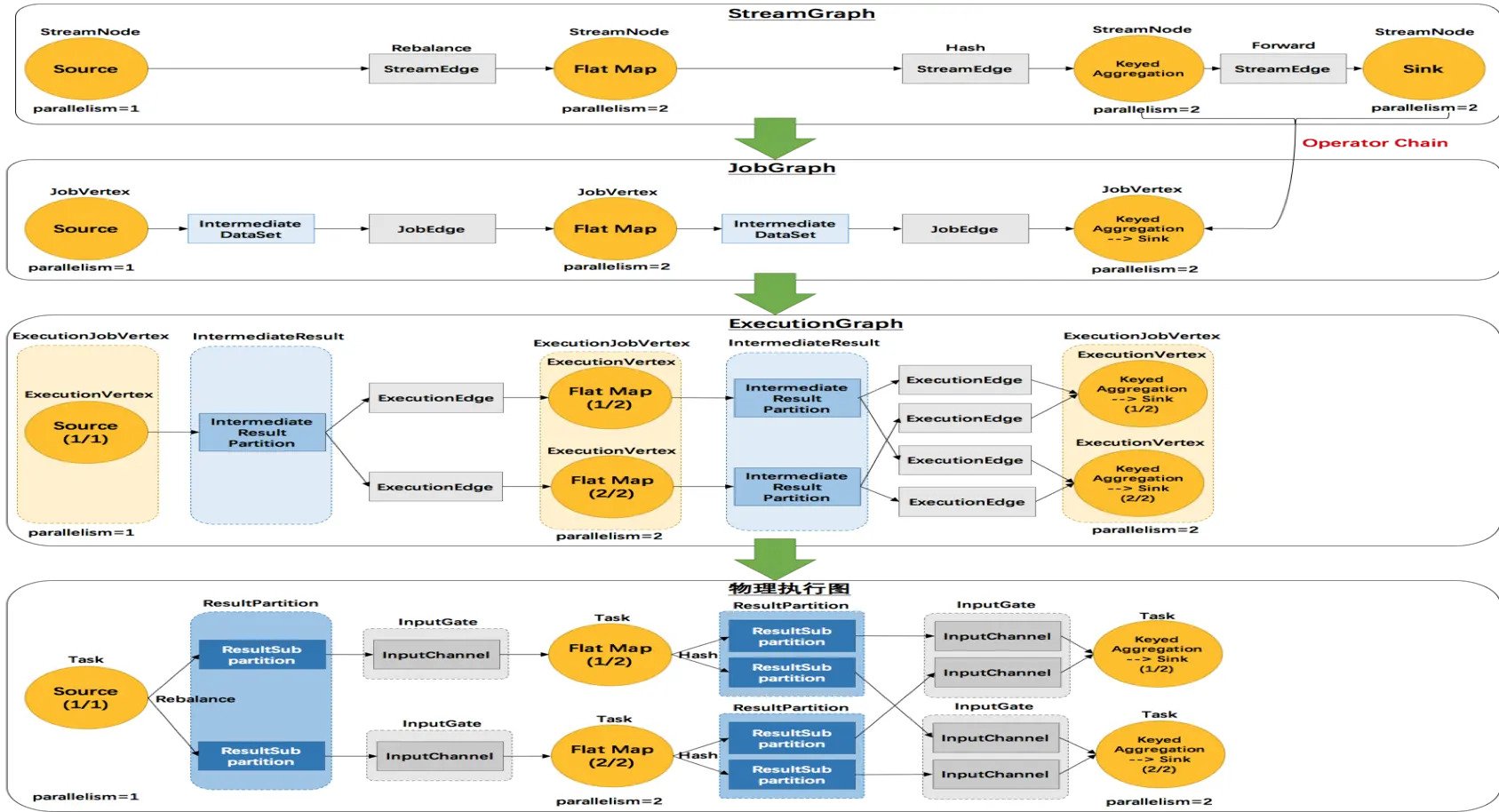
非迭代任务间的数据传输
Flink在不同Task之间的数据传输方式是:流水线机制。也就是说:上游的Task将数据存放在 buffer 中,一旦Buffer满了或者超时,就像下游Task发送
Flink并不是生成一个item传递一次,也不是像MapReduce、Spark一样,把所有item全部处理完成后下游任务才能继续运行(因此MR和Spark无法处理流数据)。
注意,Spark中的pipline和Flink中的pipeline是不同的概念
- 在Flink中,pipline表示在不同Task之间的数据传输方式,区别于MR和Spark中的Shuffle
- 在Spark中,pipline指内部同一个Task实现多个不同算子之间的数据传输方式,粒度更细
- Spark Pipline和Flink Chaining类似
Task间数据传输方式
阻塞式数据传输: 一个Task(运行某个或某些算子)将所有需要处理的数据计算完,甚至要将结果写入磁盘, 才会发送给位于下游Task或被其读取 。 比如说MapReduce、Spark
非阻塞式数据传输: 云计算天然需要非阻塞式数据传输这种特性。一个Task处理一条或一部分数据,通常将计算结果放在缓存里,就会发送给位于下游Task或被其读取。比如说Storm、Flink
| 系统 | 数据传输方式 |
|---|---|
| MapReduce | 阻塞式数据传输 |
| Spark | 阻塞式数据传输 |
| Storm | 非阻塞式数据传输 |
| Flink | 非阻塞式数据传播 |
迭代任务内部的数据传输
迭代的实现
迭代算子是Flink 特有的,它是嵌套在DAG中的一个整体。迭代算子内部存在数据反馈的环路。
那么数据反馈如何实现?
- 在同一个TaskManager当中会成对出现迭代前端(Iteration Source)和迭代末端(Iteration Sink) 两类特殊的任务。迭代末端任务的输出可以再次作为迭代前端任务的输入。
流式迭代
在流式迭代计算中,通常每一轮迭代计算的部分结果作为输出向后传递,而另一部分结果作为下一轮迭代计算的输入,并且迭代过程会一直进行下去。
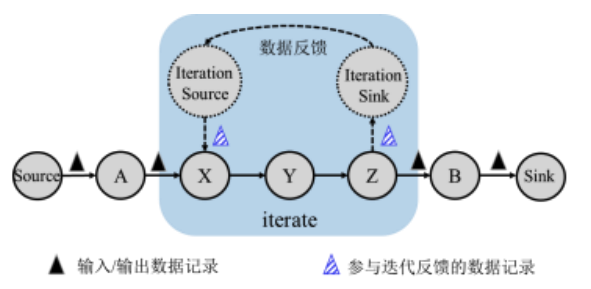
流式迭代计算中,迭代前端下一轮的计算并不依赖与迭代末端前一轮迭代得到的所有记录。同时,迭代前端收到迭代末端的反馈后,可以立即进行新一轮迭代计算。
因此,这种方式仍然是采用流水线方式进行数据传输。
批式迭代
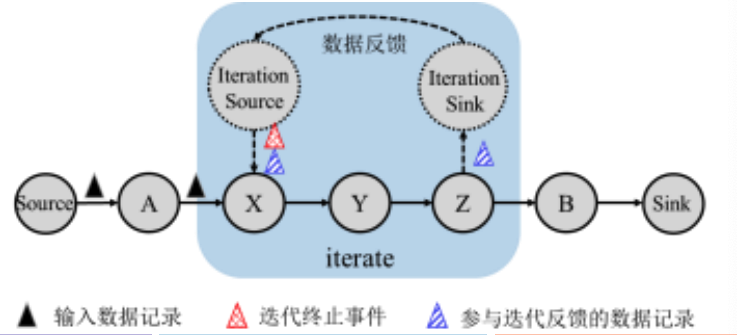
在批式迭代计算中,每一轮迭代计算的全部结果通常都是下一轮迭代计算的输入, 直到迭代过程在满足收敛条件时停止迭代。比如梯度下降,k均值.
迭代前端中发出特殊的控制事件(control event),即特殊的记录(如达到某一条件),表示迭代计算的结束
在批式迭代计算中,迭代前端必须收到迭代 末端反馈的所有记录后才可以开始新一轮迭代计算。因此这时一种阻塞的过程,无法采用流水线机制进行数据传输
容错机制
在容错机制中,我们主要需要解决当TaskManager故障了,怎么办?
- 运行了非迭代算子的容错
- 运行了迭代算子的容错
状态管理
首先,我们要了解什么是状态?
在输出数据是无界的场景中,数据会源源不断地流入Flink系统。
例如,在某一窗口中统计单词的个数:
- 窗口需要将原始的单词记录保存起来,直到窗口触发时,一并进行统计
- 或者将单词以及当前观察到的个数保存起来,并逐步累加
- 窗口这个算子所需维护的内容,就是状态
注意,我们要区分算子的状态与进程/节点的状态,前者类似于完成作业的一个进度
为什么需要系统管理状态
假设我们使用用户程序来管理状态,那么
- 用户需要编写一个HashMap来记录计数保存状态,那么一旦该算子所在的task发生了故障,内存中的HashMap就丢失了。
因此为了支持容错,需要编写程序将HashMap写入磁盘等可靠的存储设备,故障恢复后再读取。这样一来,不同数据结构都需要编写相应的保存、读取代码
因此,状态管理对用户应该是透明的,交给系统来做。
状态定义
状态是系统定义的特殊的数据结构,用于记录需要保存的算子计算结果
ValueState<T>: 状态保存的是每个Key的一个值,可以通过update(T)来更新,T.value()获取ListState<T>: 状态保存的是每个key的一个列表,通过add(T)添加数据,Iterable.get()获取ReaducingState<T>: 状态保存的是关于每个key经过聚合之后的值列表,通过add(T)添加数据,通过指定的聚合方法来获取
有状态算子/无状态算子
- 有状态算子:具备记忆能力的算子
- 可以保留已经处理记录的结果,并对后续记录的处理造成影响
- 例如:Window,Sum
- 无状态算子:不具备记忆能力的算子
- 只考虑到当前处理的记录,不会受到已处理记录的影响,也不会影响到后续待处理的记录
- 例如: Map
状态管理与容错
- 算子级别的容错
- 运行时保存其状态,在发生故障时重置状态,并继续处理尚未保存到状态中的记录
- DAG级别的容错
- 既然一个算子可以保存其状态,那么我们是不是可以对DAG中所有的算子都进行这个操作?
- 这就是DAG级别的容错,我们可以在同一时刻将所有算子的状态保存起来形成检查点,一旦出现故障,则所有算子都根据检查点来重置状态,并处理尚未保存到检查点中的记录。
- 难点是:DAG可能在分布式系统下运行,要做到同一时刻,必须要求所有节点的物理时钟绝对同步。但这是不可能的。那么怎么办?我们可以分两种情况来讨论
非迭代计算过程的容错
系统中的记录
上面我们说的DAG容错,虽然无法实现,但其Idea就是将Flink中的不同种类的记录区分开来:
在某一时刻,流计算系统所处理的记录,可以分为三种类型
- 已经处理完毕的记录,即所有算子都已经处理了这些记录
- 正在处理的记录,即部分算子处理了这些记录
- 尚未处理的记录,即没有算子处理过这些记录
因此,虽然绝对同步的时钟是不存在的,但是同一时刻保存所有算子状态到检查点的目的是区分第一种记录和后两种记录
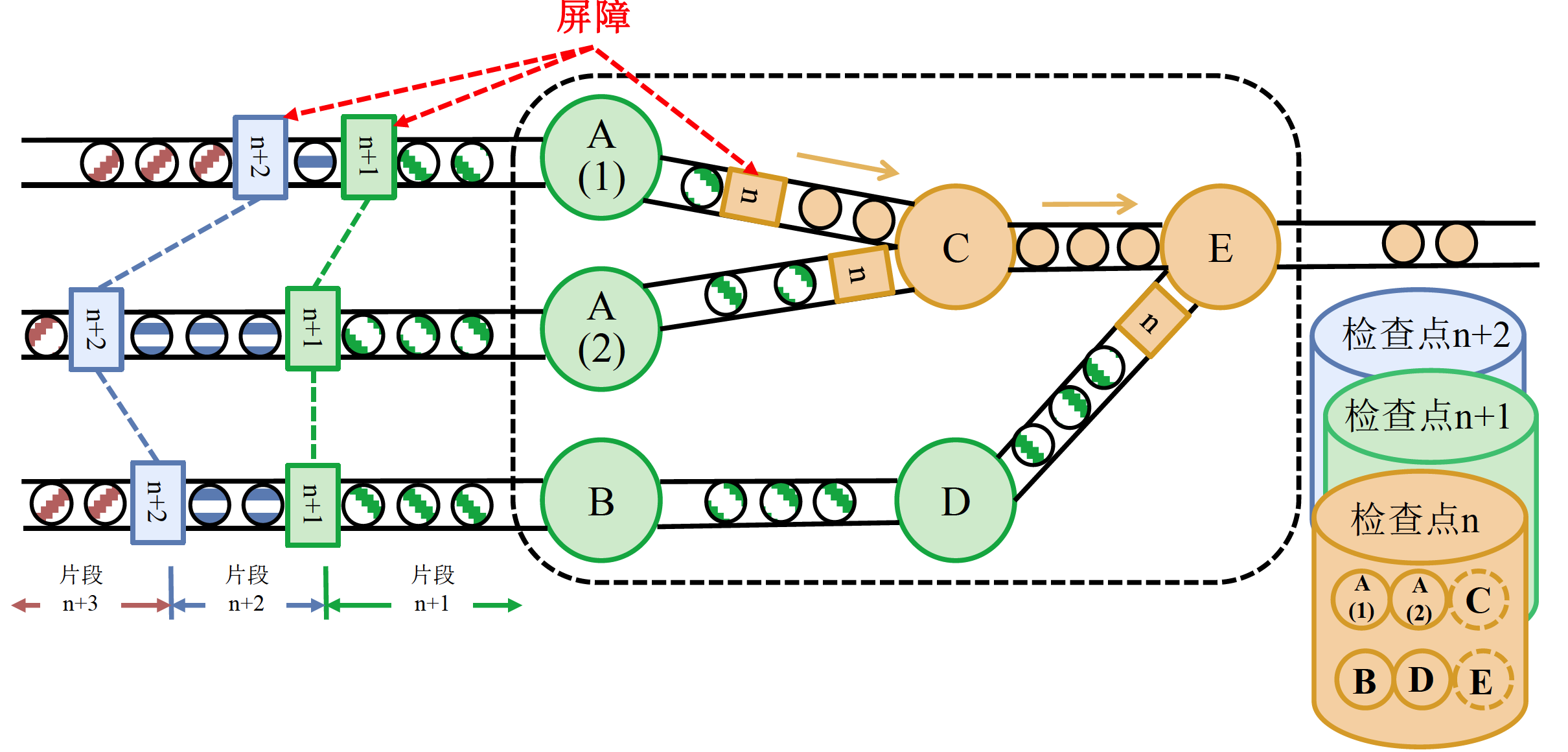
屏障
JobManager在输入记录中插入屏障,这些屏障与记录一起向下游的计算任务流动。我们可以将其理解为标记,将数据流进行一个分割。一个任务,需要收到来自上有任务中所有标识为n的屏障之后,才能将其状态保存起来,这被称为屏障对齐。每个检查点的保留结果相互独立,都保留了一份计算结果。
某一人任务将标识为n的屏障对齐之后,可以继续接收属于 检查点 n+1 的数据
 如上图:
如上图:
- 最右侧两个黄色的记录,就是已经处理完毕的记录
- 中间虚框框起来的记录则是正在处理的记录
- 最右侧是尚未处理的记录
异步屏障快照
异步屏障快照算法是由Chandy-Lamport算法(分布式系统中用于保存系统状态)扩展而来的 :
- 所保存的快照就是检查点
- 通过在输入数据中注入屏障,并异步地保存快照,达到和在同一时刻保存所有算子状态到检查点相同的目的
Flink状态存储
| 状态存储方式 | 正常运行时 | 写检查点时 |
|---|---|---|
| MemoryStateBackend | 本地内存 | JobManager内存 |
| FsStateBackend | 本地内存 | HDFS |
| RocksDBStateBackend | 本地RocksDB | HDFS |
故障恢复
当发生故障时,Flink选择最近完整的检查点n,将系统中每个算子的状态重置为检查点中保存的状态。
从数据源重新读取属于屏障n之后的记录
- 这要求数据源具备一定的记忆功能
- 例如,Flink从Kafka中重新读取屏障n对应偏移量之后的记录
Flink的容错机制能够满足准确一次的容错语义