JPA/Hibenate CRUD App
简介
Hibernate 和 JPA 是 Java 编程语言中用于数据库操作和持久化数据管理的两个相关技术。
Hibernate: Hibernate 是一个开源的对象关系映射(ORM)框架,它提供了一个映射 Java 对象到数据库表的框架,并自动处理 Java 应用程序和数据库之间的数据查询和交换。Hibernate 旨在解决对象模型和关系数据库之间的不匹配问题,也称为”对象-关系阻抗不匹配”。通过 Hibernate,开发者可以写面向对象的代码而不必担心底层的 SQL 语句,因为 Hibernate 会负责生成和执行 SQL。Hibernate 还提供了数据查询和检索的高级优化功能,如缓存和懒加载。
JPA (Java Persistence API): JPA 是 Java EE 平台提供的一套持久化API,它定义了 ORM 系统应遵循的规范,以便开发者可以使用一致的方式访问关系数据库。JPA 设计为多个 ORM 提供者的通用接口,Hibernate 就是这些提供者之一,其他提供者还包括 EclipseLink、OpenJPA 等。JPA 允许开发者定义实体和实体之间关系,并通过 EntityManager API 管理数据库操作。
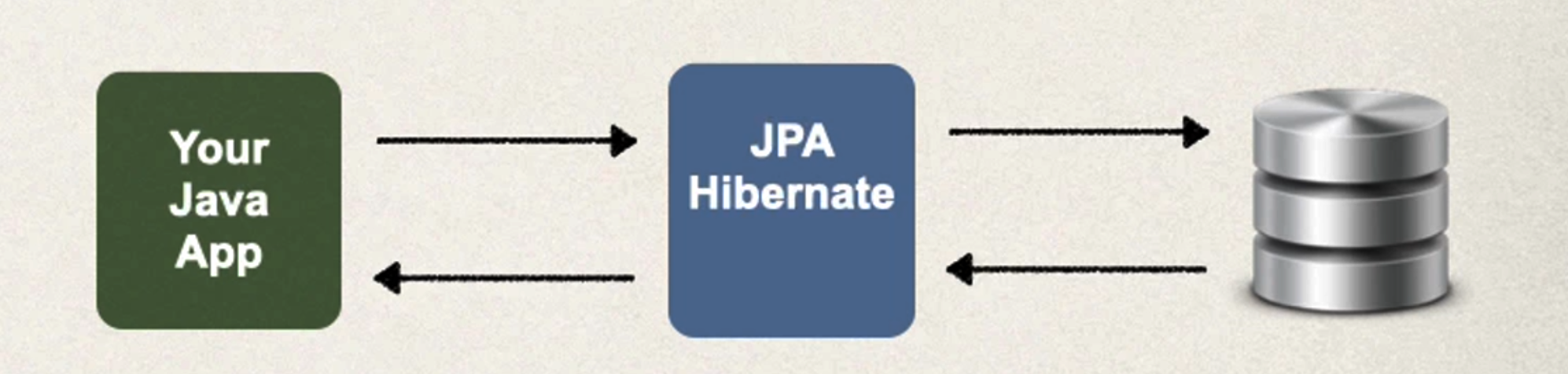
简而言之,Hibernate 是 JPA 规范的一个实现,而 JPA 是一组接口和概念的集合。使用 JPA 的好处是,你可以在不同的 ORM 提供者之间切换,而不需要改变太多代码。而 Hibernate 提供了 JPA 规范之外的一些额外特性,这些特性在 JPA 中并不是必需的,但可能在某些复杂的应用场景中很有用。
配置:
Hibernate/JPA 和 JDBC之间的关系
- JDBC (Java Database Connectivity): JDBC 是一个 Java API,它定义了客户端如何连接到数据库,如何发送 SQL 或 SQL 数据库调用,以及如何处理来自数据库的结果。它是 Java 用于与数据库交云的低级 API,提供了执行查询和更新数据的方法。
- Hibernate/JPA 作为 ORM 层: Hibernate 是 JPA 规范的一个实现,并且作为一个 ORM(对象关系映射)框架,它坐落在应用程序和 JDBC 之间。Hibernate 使用 JDBC API 与数据库通信,但它允许开发者以面向对象的方式工作,而不是直接使用 SQL 语句。开发者可以使用 Java 类和对象来表示和操作数据库中的数据。
- 抽象层: Hibernate/JPA 提供了比 JDBC 更高层次的抽象。它管理了对象到数据库表记录的映射(反之亦然),自动将对象属性转换为数据库列,提供了更复杂的事务管理和缓存机制,以及对懒加载和关联对象的支持。
- 简化数据库交互: 使用 Hibernate/JPA,开发者通常不需要写大量的 JDBC 代码和手动处理结果集。相反,他们可以专注于业务对象和逻辑。
- 性能优化: Hibernate/JPA 提供了比直接使用 JDBC 更多的性能优化选项,比如一级和二级缓存,以及延迟加载(懒加载)
自动配置
- 自动配置:
- Spring Boot 会自动配置数据源,这是基于类路径中的库和提供的配置属性完成的。
- Maven 依赖:
- 通过在 Maven 的
pom.xml文件中包含相关的依赖,比如mysql-connector-java(MySQL 的 JDBC 驱动)和spring-boot-starter-data-jpa(包含了 JPA 相关的依赖和 Hibernate),Spring Boot 能够识别需要配置哪种类型的数据源。
- 通过在 Maven 的
application.properties:- 数据库的连接信息(如 URL、用户名和密码)在
application.properties文件中提供。Spring Boot 根据这些属性来设置和配置数据源。
- 数据库的连接信息(如 URL、用户名和密码)在
例如,在 application.properties 文件中添加属性:
1 | spring.datasource.url=jdbc:mysql://localhost:3306/student_tracker |
DataSource和EntityManager的创建:- Spring Boot 将根据上述配置自动创建和配置
DataSource和EntityManagerbean。这些 bean 随后可以被注入到您的应用程序中,比如 DAO(数据访问对象)或仓库。
- Spring Boot 将根据上述配置自动创建和配置
如何连接到数据库?
Java Annotation
让 Java 类连接到数据库并映射为数据库表通常涉及到以下几个步骤,结合您提供的图片,这个过程使用 JPA (Java Persistence API)来完成:
- 定义 Entity 类:
- 在 Java 中,您需要创建一个实体类(Entity Class),这个类的实例代表数据库中表的行。实体类需要用
@Entity注解标记,这告诉 JPA 这个类是一个实体,并且它将映射到数据库的一个表。 - 实体类必须有一个无参构造函数,它可以是 public 或 protected。这是 JPA 规范的要求,以便 JPA 实现(如 Hibernate)可以实例化实体类并填充其属性。
- 实体类还可以有其他构造函数。
- 在 Java 中,您需要创建一个实体类(Entity Class),这个类的实例代表数据库中表的行。实体类需要用
- 映射类到数据库表:
- 实体类通常通过
@Table注解映射到数据库的特定表。如果省略这个注解,JPA 默认使用类名作为表名。
- 实体类通常通过
- 映射字段到数据库列:
- 实体类的每个属性通常通过
@Column注解映射到表的列。如果省略,JPA 会使用字段名作为列名。 - 特殊属性(如主键)需要使用
@Id注解来标记。
- 实体类的每个属性通常通过
Primary Key
在 JPA 中,主键(Primary Key)的设置是通过在实体类中指定一个或多个字段作为唯一标识符来完成的。以下是根据您提供的图片所描述的关于如何在 JPA 中设置和使用主键的知识点:
主键字段:
- 您需要在实体类中使用
@Id注解来标记一个字段作为实体的主键。这告诉 JPA,该字段的值将用来唯一标识实体的每个实例。
- 您需要在实体类中使用
主键生成策略:
使用
1
@GeneratedValue
注解来指定主键的生成策略。这个注解定义了如何为主键字段生成值。JPA 提供了几种不同的策略,如图所示:
GenerationType.AUTO: JPA 自动选择最适合底层数据库的策略。GenerationType.IDENTITY: 使用数据库的 identity column 特性进行主键值的自增。这意味着数据库在新行插入时自动分配下一个值。GenerationType.SEQUENCE: 使用数据库中定义的序列来生成主键值。GenerationType.TABLE: 使用特定的数据库表来模拟序列,维护主键值。
字段与数据库列的映射:
- 通过
@Column注解将实体类的字段映射到数据库表的特定列。如果您希望列名与字段名不同,可以在注解中指定。
- 通过
例子
Student 实体类中的 id 字段被标记为主键,并且使用了 GenerationType.IDENTITY 策略,它通常与 auto_increment 字段在 MySQL 或 serial 字段在 PostgreSQL 这样的数据库中使用。当插入新的 Student 实例时,数据库会自动为 id 字段分配一个唯一的值。
下面是一个 Student 实体类的示例:
1 |
|
在这个例子中,实体类 Student 映射到数据库表 student,字段 id 映射到列 id,并且它是自动生成的主键。当您通过 JPA 框架保存 Student 对象时,不需要手动设置 id 字段的值;数据库将为您自动增长。
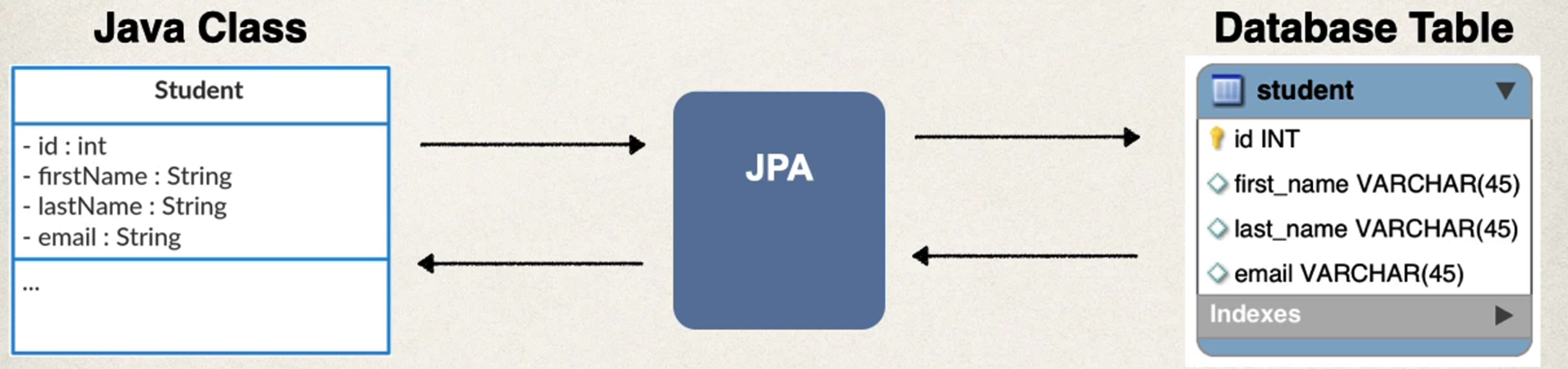
我们看到,java class中的filed和Database中的字段一一对应。这里@Column后面跟着的name即数据库中的字段名。
此外,我们还需要为字段添加Constructor、getter和setter
如何进行CRUD?
CREATE
要将一个 Student 实体保存到数据库中,通常需要以下步骤
创建实体类:
- 定义一个
Student实体类,并使用@Entity和@Table注解标注。这个类将映射到数据库中的student表。
- 定义一个
定义数据访问对象(DAO)接口:
- 创建一个数据访问对象(DAO),这是一个设计模式,用于封装对数据库的访问。
- DAO 应包含用于与数据库交互的方法,如
save()、findById()、findAll()、update()、delete()等。
1
2
3
4
5
public interface StudentDAO {
void save(Student theStudent);
// ... 其他方法
}
实现 DAO:
- 在 DAO 实现中,注入
EntityManager。EntityManager是 JPA 中用于管理实体类和数据库交互的接口。Spring Boot 会根据application.properties中的配置自动创建并配置EntityManager和数据源(DataSource)。 - 使用
EntityManager提供的方法来实现 DAO 接口中定义的操作。例如,使用entityManager.persist(student)来保存一个Student实体到数据库。 @Transactional注解提供了声明式事务管理的能力。这意味着你可以在方法或者类上添加这个注解,Spring会自动为你的JPA代码开始和结束一个事务,无需手动编写代码来控制事务的开始和提交或回滚。这样的处理通常是在幕后进行的,借助Spring框架的AOP(面向切面编程)能力。@Repository注解是一个特化的@Component注解,它用于标记数据访问对象(DAO),表明这个类是用于数据访问层的组件,具有将数据库异常转换为Spring的数据访问异常的能力。@Repository注解的类也会被组件扫描自动检测到,这意味着Spring会自动注册这些类为Spring应用上下文中的bean,并且为这些bean提供如数据源和事务管理器的依赖注入。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public class StudentDAOImpl implements StudentDAO {
private EntityManager entityManager;
//注入 Entity Manager
public StudentDAOImpl(EntityManager theEntityManager) {
entityManager = theEntityManager;
}
//实现接口
public void save(Student theStudent) {
entityManager.persist(theStudent);
}
}- 在 DAO 实现中,注入
配置 Spring Boot 应用程序:
- 确保
application.properties文件中包含正确的数据库连接信息,如 JDBC URL、用户名和密码。 - 在应用程序的启动类或配置类中声明 DAO 作为 Spring 管理的 bean。
- 确保
保存实体:
- 在应用程序的某个地方,注入
StudentDAO并调用它的save()方法来保存Student实体。
- 在应用程序的某个地方,注入

READ
要通过DAO从数据库中读取一个条目,可以遵循以下步骤:
定义DAO接口:首先需要定义一个DAO接口,这个接口包含了需要执行的数据库操作的方法,比如
findById(Integer id)1
2
3
4// StudentDAO接口
public interface StudentDAO {
Student findById(Integer id);
}
- 实现DAO接口:然后需要一个实现了DAO接口的类。这个实现类会具体定义如何使用
EntityManager来访问数据库。例如,findById方法会使用EntityManager的find方法来检索数据库中的对象。参数是:Entity class和Primary Key。这里不许要加@Transational因为并不会修改状态。
1 | // StudentDAO实现类 |
- 更新主应用程序:最后,在主应用程序中,你可以通过调用DAO实现类的方法来实现数据的读取。
1 | // 主应用程序中的使用 |
多个对象读取-JPQL
要利用Java Persistence Query Language (JPQL) 实现对多个数据的查询,你可以在DAO中定义查询方法,然后在实现类中使用EntityManager来创建和执行JPQL查询。以下是根据你提供的信息,实现findAll和findByLastName两个接口的示例代码:
首先,我们需要在DAO接口中定义这两个方法:
1
2
3
4
5
6
7public interface StudentDAO {
// ...其他方法
List<Student> findAll();
List<Student> findByLastName(String lastName);
}然后,在实现类中使用
EntityManager和JPQL来实现这些方法
1 |
|
这里findAll方法使用了一个简单的JPQL查询来检索所有Student实体,其中FROM Student 中 Student是Entity的名字,并不是表名。
而findByLastName方法则使用了一个带有参数的JPQL查询来检索所有具有特定姓氏的Student实体。我们使用:lastName来指定一个参数,然后使用theQuery.setParameter方法来绑定具体的值。
在你的Spring Boot主应用程序中,你可以注入这个DAO并调用这些方法来执行实际的查询操作。这里的@Transactional注解表明每个方法的执行都会在一个事务的上下文中运行,确保操作的原子性。
UPDATE
使用JPQL实现数据库中某条数据的更新涉及以下步骤:
- 在DAO接口中添加新方法: 这是你定义与数据库交互所需要的方法的地方。例如,你可以添加一个
update方法来更新学生信息。
1 | public interface StudentDAO { |
- 在DAO实现类中添加新方法的实现: 在这里,你将实现接口中定义的方法。你需要使用
EntityManager来访问数据库,并执行更新操作。通常,你会使用merge方法来更新现有的实体或者编写一个JPQL更新查询。
1 | public class StudentDAOImpl implements StudentDAO { |
这里的@Transactional注解确保更新操作在一个事务中执行。如果更新过程中出现异常,那么事务会被回滚,确保数据库状态的一致性。
- 在主应用程序中调用更新方法: 最后一步是在你的应用程序的逻辑中调用更新方法。通常,这会在一个服务层中完成,或者直接在
@SpringBootApplication类中
1 | private void updateStudent(StudentDAO studentDAO) { |
DELETE
要删除对象可以遵循下列开发流程:
- 添加新方法到DAO接口:在你的DAO接口中定义一个删除对象的方法。例如,如果你有一个
StudentDAO接口,你可以添加一个方法deleteById(int id)。
1 |
|
- 添加新方法到DAO实现类:在你的DAO实现类中实现这个删除方法。使用
EntityManager来完成删除操作。
1 | public class StudentDAOImpl implements StudentDAO { |
在这个方法中,我们首先使用EntityManager.find()方法检索实体。如果实体存在,我们调用EntityManager.remove()方法来删除它
- 更新主应用:最后,在你的主应用程序中,你需要调用这个新方法来执行删除操作。
1 | private void deleteStudent(StudentDAO studentDAO){ |
删除多个对象
- 添加新方法到DAO接口:定义一个方法来删除所有对象。
1 | public interface StudentDAO { |
- 添加新方法到DAO实现类:在你的DAO实现类中实现删除所有对象的方法。你可以使用
EntityManager配合JPQL来执行批量删除。
1 | public class StudentDAOImpl implements StudentDAO { |
在这个方法中,我们创建了一个JPQL查询来删除所有Student实体。注意DELETE FROM Student中的Student是实体类的名称,而不是数据库表的名称。
- 更新主应用:在主应用程序中调用新的
deleteAll方法来执行删除操作。
自动生成数据表
使用 Java 代码自动生成数据库表的过程中,可以通过配置 JPA 或 Hibernate 来实现。这里是一个基本的过程
- 编写实体类(Entity Class):首先,您需要创建一个 Java 实体类,使用 JPA 或 Hibernate 注解来定义其映射到数据库表的结构。比如,您的
Student类将包含@Entity注解,并且有诸如@Id,@Column等注解来标记实体的属性。 - 配置
application.properties文件:在 Spring Boot 应用程序中,需要在application.properties文件中设置 Hibernate 的ddl-auto属性。例如
1 | spring.jpa.hibernate.ddl-auto=create |
这个配置指示 Hibernate 在应用程序启动时创建数据库表,这些表基于您的 Java 实体类。
- 运行应用程序:当您启动 Spring Boot 应用程序时,配置为
create的ddl-auto属性将会指导 Hibernate 自动创建数据库表,如果这些表还不存在的话。这个过程是基于您的 Java 实体类的注解来执行的。
在 application.properties 文件中,ddl-auto 属性可以有几个不同的值:
none:不自动创建、更新或验证数据库表。create-only:仅创建数据库表,不进行删除操作。drop:启动时删除数据库表。create:启动时删除数据库表,然后重新创建。create-drop:在应用程序启动时创建,关闭时删除数据库表。validate:验证现有数据库表结构是否与实体类匹配。update:更新数据库表结构,以匹配实体类的变更。
例如,如果您想在每次应用程序启动时创建新的表并在关闭时删除,您可以设置:
1 | spring.jpa.hibernate.ddl-auto=create-drop |
不应该在生产环境中使用 create 或 create-drop,因为这会导致现有的数据丢失。如果您想在生产环境中创建表格并保留数据,应该使用 update 选项。但是,需要格外小心,因为这可能会根据代码的最新更改修改数据库架构。只有在基本项目中,且能够承担相关风险时,才建议使用这种方法。在生产环境中,通常推荐手动管理数据库迁移,以避免数据丢失和不可预见的更改。