设计模式
工厂模式
应用场景:
- 在
DefaultLogicFactory类中,实现了一个典型的工厂模式。在Spring框架下非常实用,工厂模式用于创建对象,不直接使用new操作符实例化对象,而是通过调用一个工厂方法来获取新对象的实例。在这种情况下,工厂方法(构造函数)负责从一组ILogicFilter实例中读取元数据并创建一个管理这些过滤器实例的映射。
优点:
- 工厂模式支持编程的抽象层级,并允许系统在不修改现有代码的情况下引入新的逻辑过滤器类型,符合开闭原则
示例
最近在跟大营销项目,里面的一些设计还是慢巧妙地。这边也梳理一下并加强对系统的理解.
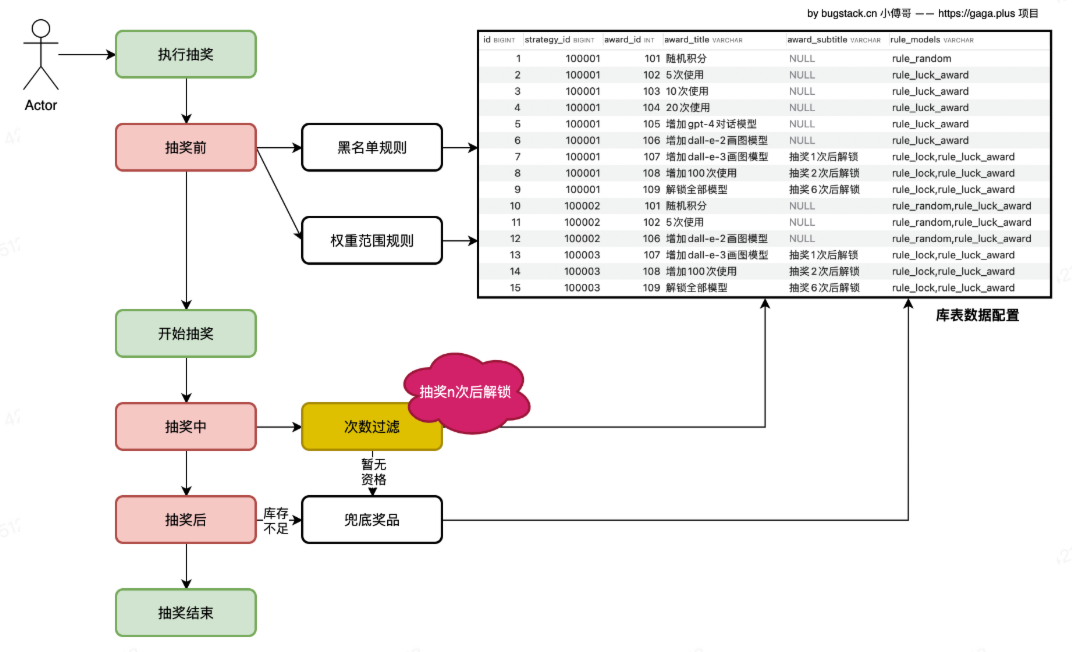
当前在strategy 领域中,结构如下:
1 | . |
整个抽奖的逻辑是这样的:
- 首先,传入一个
RaffleFactorEntity,包含用户ID和策略ID,然后调用RaffleStrategy来执行查询。 - 在执行查询前,需要根据策略ID获取规则模型,再根据规则模型前置过滤,以实现黑名单功能和权重匹配功能
- 执行查询,用户的积分不同,奖品范围也不同;如果是黑名单,那么只会返回一个最低档的积分。
在这里我们重点关注以下2部分:
1 | ├── annotation |
其中,annotation中的LogicStrategy是一个自定义的注解:
1 | ({ElementType.TYPE}) |
@Target({ElementType.TYPE}):这表明
LogicStrategy注解可以被用于类、接口或枚举声明。这意味着不能将此注解用于方法、字段等,只能标注在类等类型上。@Retention(RetentionPolicy.RUNTIME):这表明
LogicStrategy注解不仅会被编译器记录在类文件中,而且在运行时通过反射仍然可见。这是实现动态逻辑处理中关键的部分,因为它允许程序在运行时查询这些注解信息。
因此,只要在我实现的过滤器类上,应用了 LogicStrategy注解,就需要指定一个特定的策略模式。此外我还用@Component注解,Spring 容器会在应用启动时自动识别并实例化该类的对象,将其注册为 Spring 管理的 Bean。并注入到需要这个Bean的地方去。
如:
1 | 4j |
和
1 | 4j |
在 factory中的DefaultLogicFactory是一个工厂类,实现如下:
1 |
|
- 依赖注入:在
DefaultLogicFactory的构造函数中,我指定了一个List<ILogicFilter<?>>类型的参数。这告诉 Spring,这个构造函数需要注入所有匹配ILogicFilter<?>类型的 Beans。 - 集合注入:Spring 支持集合类型的依赖注入。当我在构造函数中使用如
List<ILogicFilter<?>>这样的集合类型时,Spring 会自动收集所有可用的ILogicFilter<?>实例并作为列表注入。这包括所有单独声明的实现了ILogicFilter<?>接口的类,例如RuleBlackListLogicFilter。 - 在构造函数中处理逻辑:一旦
DefaultLogicFactory获得所有逻辑过滤器的实例,它会遍历这些实例,使用AnnotationUtils.findAnnotation检查每个实例是否有@LogicStrategy注解。 - 根据注解分类存储:如果发现
@LogicStrategy注解,就会根据注解中指定的策略模式代码将对应的过滤器存储在logicFilterMap中。
工厂模式+责任链模式
未优化的代码
原来的代码如下所示:
1 | // 3. 抽奖前 - 规则过滤 |
1 |
|
现在,我们需要思考,在 doCheckRaffleBeforeLogic 方法中,所有规则的逻辑集中在一个方法内。虽然代码结构相对清晰,但它依然耦合了不同规则的判断逻辑(如黑名单和权重规则),使得方法臃肿且难以单独维护。比如,我们还要实现一个白名单规则,那么就要在这个doCheckRaffleBeforeLogic 方法中确定其位置,这会使得方法不断增大、复杂,切不容易理解各个规则的优先级。
因此,我们可以将每个规则处理器作为一个独立的类,各自实现独立的logic方法。不同规则的逻辑和判断被分离到不同的责任链节点中,代码更加模块化。比如,我们想要创建一个新的责任链节点 WhiteListLogicChain, 我们只需要在工厂中将其加入链条,而不是像原来那样修改doCheckRaffleBeforeLogic 方法。 极大地降低了代码的耦合性和维护成本。
示意图如下所示:
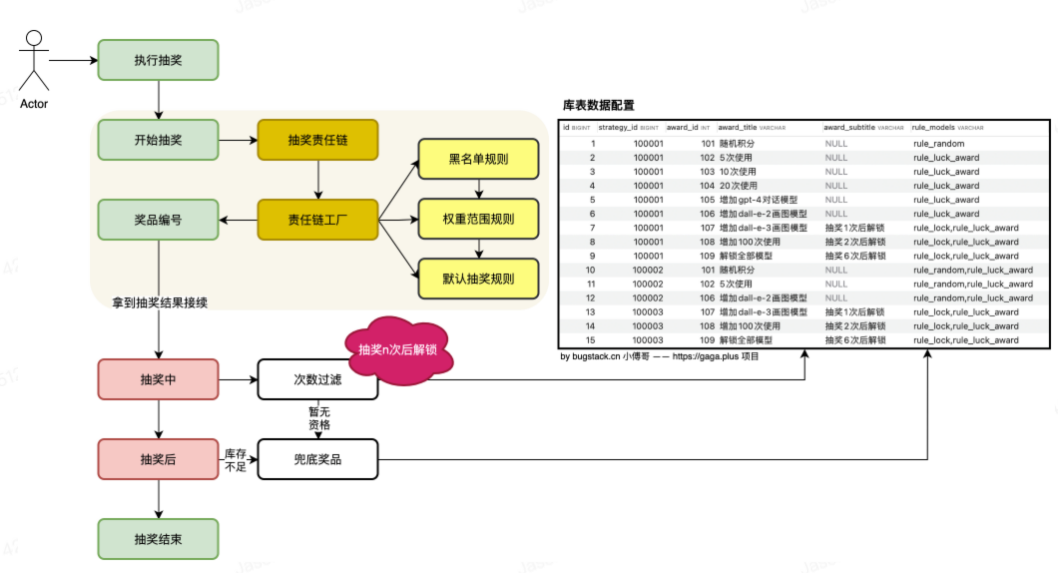
重构-链节点
对于原来的Filter,现在我们将其变成责任链上的一个节点:
1 | public interface ILogicChainArmory { |
1 | public interface ILogicChain extends ILogicChainArmory { |
1 | public abstract class AbstractLogicChain implements ILogicChain { |
这是类似于一个链表的数据结构,每个ILogicChain节点都会指向下一节点。
此外,如果一个节点继承了这个抽象节点类
AbstractLogicChain, 那么他还需要实现logic()方法,里面具体实现规则过滤逻辑。
比如,这个责任链上有一个黑名单过滤节点:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
324j
("rule_blacklist")
public class BlackListLogicChain extends AbstractLogicChain {
private IStrategyRepository strategyRepository;
public Integer logic(String userId, Long strategyId) {
log.info("抽奖责任链-黑名单开始 userId:{} strategyId:{} ruleModel:{} ", userId, strategyId,ruleModel());
String ruleValue = strategyRepository.queryStrategyRuleValue(strategyId, ruleModel());
String[] splitRuleValue = ruleValue.split(Constants.COLON);
Integer awardId = Integer.valueOf(splitRuleValue[0]);
String[] userNames = splitRuleValue[1].split(Constants.SPLIT);
// 100:user001,user002,user003 判断ruleMatterEntity.getUserId()是否在黑名单中
boolean isBlackListed = Arrays.asList(userNames).contains(userId);
if(isBlackListed){
log.info("抽奖责任链-黑名单接管 userId:{} strategyId:{} ruleModel:{} ", userId, strategyId,ruleModel());
return awardId;
}
log.info("抽奖责任链-黑名单放行 userId:{} strategyId:{} ruleModel:{} ", userId, strategyId,ruleModel());
return next().logic(userId, strategyId);
}
protected String ruleModel() {
return "rule_blacklist";
}
}
该节点根据userId和strategyId 获取ruleValue,判断当前用户是否在黑名单中。
- 如果是,那么就接管,并返回一个特定的低保奖品
- 如果否,就放行,然后调用责任链的下一个节点,交给别人去判断
此外,我们还需要一个默认节点,如果规则对这个用户都不适用,那么就返回一个默认值。在抽奖系统中,就是随便抽。
1 | 4j |
重构-链工厂
构建了节点之后,相当于我们有了很多乐高碎片,那么需要一个工厂类,将它们组装成一个链,于是需要:
1 |
|
这个工厂类基于 责任链模式 和 工厂模式 的组合,通过动态组合链条节点来生成完整的责任链,具体实现策略模式的行为选择。以下是该工厂类的关键设计思路:
- 工厂模式:
DefaultChainFactory是一个工厂类,用于构建ILogicChain的责任链。它根据输入的strategyId查询策略对应的规则,然后按顺序从logicChainGroup中取出这些规则节点,将它们组装成一条链。 - 责任链模式:工厂类生成的
ILogicChain实例是由多个链式节点组成的责任链。每个链节点都可以在链条中处理请求或将请求传递给下一个节点。这样,规则在链条中按顺序依次处理,每个规则的逻辑独立且具有优先级(顺序)。 - 基于规则的动态链式构建:
openLogicChain方法根据策略查询到的规则列表动态构建责任链。这种设计确保了链条的灵活性:可以根据不同的规则列表动态生成不同的链条,而不是依赖固定的逻辑顺序。
最后,我们需要修改一开始的抽奖操作,那一大段规则过滤的代码可以简化为:
1 | //2. 责任链抽奖 |
构造责任链:比如该策略的ruleModels为rule_blacklist,rule_weight。 那么责任链就是 rule_blacklist -> rule_weight -> default 先过滤黑名单,再过滤权重,如果都放行,那么执行默认抽奖。
规则树构建
解决了前置规则过滤,现在我们来看看抽奖中规则过滤。逻辑是这样的:
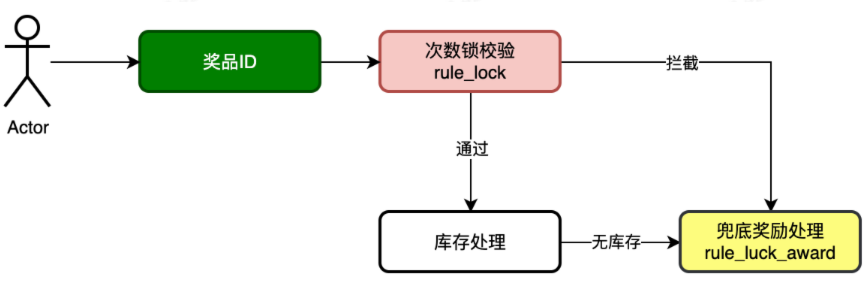
这是一个非多分支情况的规则过滤。单独的责任链是不能满足的,如果是拆分开抽奖中规则和抽奖后规则分阶段处理,中间单独写逻辑处理库存操作。那么是可以实现的。但这样的方式始终不够优雅,配置化的内容较低,后续的规则开发仍需要在代码上改造。所以这里可以使用规则树的结构,实现规则过滤。
因此,我们需要把库存处理也当做是一种规则,库存足够,说明满足规则,放行;库存不够,说明不满足规则,接管—>给兜底奖励。流程如下:
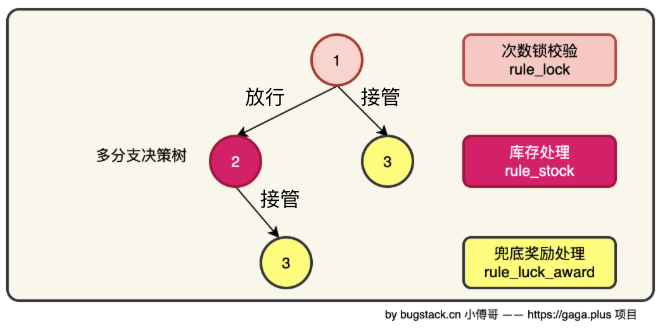
规则树结构
- 接口
ILogicTreeNode:- 定义了树节点的基础操作,即
logic方法。每个节点都有logic方法来判断当前节点是否符合条件,并返回相应的决策状态。
- 定义了树节点的基础操作,即
- 具体实现节点
RuleStockLogicTreeNode、RuleLuckAwardLogicTreeNode、RuleLockLogicTreeNode:- 每个节点实现了
ILogicTreeNode,并定义了各自的逻辑。例如,RuleStockLogicTreeNode和RuleLuckAwardLogicTreeNode返回TAKE_OVER,表示节点接管;RuleLockLogicTreeNode返回ALLOW,表示放行到下一个节点。
- 每个节点实现了
- 工厂类
DefaultTreeFactory:- 负责管理不同的
ILogicTreeNode实例。通过构造器注入Map<String, ILogicTreeNode>,在运行时动态决定使用哪种节点逻辑。 - 提供
openLogicTree方法生成决策树引擎DecisionTreeEngine,并传入节点实例映射和规则树配置(RuleTreeVO)。
- 负责管理不同的
- 规则树引擎
DecisionTreeEngine:- 核心逻辑处理类,用于遍历规则树,按顺序检查节点并作出决策。
process方法:从根节点开始,根据每个节点的决策结果决定下一步的执行节点。如果判断为接管,那么返回兜底奖励,如果判断为放行,则执行下一个节点。nextNode方法:负责判断下一节点的路径,依据RuleTreeNodeLineVO中的条件是接管还是放行,决定进入的下一个节点。
- 规则数据对象(
RuleTreeNodeVO、RuleTreeNodeLineVO、RuleTreeVO):RuleTreeVO表示整个决策树结构,包括根节点、各个节点和连线。RuleTreeNodeVO表示树中的单个节点,包含规则标识、描述、下一步连线等信息。RuleTreeNodeLineVO表示节点之间的连线条件,包括条件类型(如等于、大于等)、下一节点等信息。
- 枚举
RuleLimitTypeVO和RuleLogicCheckTypeVO:RuleLimitTypeVO:定义了节点连线的判断条件(如等于、大于、枚举等),用于nextNode判断逻辑。RuleLogicCheckTypeVO:用于标识逻辑节点的检查结果,如TAKE_OVER表示节点接管、ALLOW表示允许通过等。
测试如下:
1 | /** |
运行时的流程
- 初始化决策树引擎:
DefaultTreeFactory接收配置对象RuleTreeVO,并调用openLogicTree方法生成DecisionTreeEngine。
- 调用
process方法:- 决策树引擎的
process方法接收userId、strategyId、awardId,并从RuleTreeVO中提取根节点开始执行。
- 决策树引擎的
- 遍历节点执行逻辑:
process方法根据当前节点的ruleKey获取相应的ILogicTreeNode实现类。- 调用节点的
logic方法执行规则逻辑,返回TreeActionEntity(包含ruleLogicCheckTypeVO和strategyAwardData)。 - 通过
ruleLogicCheckTypeVO检查当前节点的执行结果:TAKE_OVER:表示当前节点已经做出决策,直接返回strategyAwardData,结束决策流程。ALLOW:表示允许继续执行,根据nextNode方法判断下一个节点。
- 判断下一节点:
nextNode方法根据RuleTreeNodeLineVO中的条件值和当前节点返回的状态判断下一步要执行的节点。- 遍历
treeNodeLineVOList,调用decisionLogic方法根据连线条件决定是否满足要求。 - 如果满足要求,返回下一个节点的标识
ruleNodeTo,并将该节点作为下一步的处理节点。
- 返回决策结果:
- 当流程到达某个
TAKE_OVER节点或遍历完所有节点时,process方法返回最终的StrategyAwardData,包含最终的决策结果,如awardId和awardRuleValue。
- 当流程到达某个
1 |
|