redis实现防超卖策略
在高并发的场景下,尤其是电商等需要控制库存的系统,超卖是一个常见的问题。超卖指的是用户在高并发情况下能够购买已经售完的商品。通过 Redis 实现防止超卖的策略,通常包括以下几个关键部分:
1. 库存控制的基本思路
- 使用 Redis 存储商品的库存信息。Redis 提供的高并发支持和高性能,可以帮助快速响应并发请求。
- 通过 Redis 的原子性操作(如
DECR)来实现库存的扣减,并利用非独占锁机制来避免并发请求导致的库存超卖。
2. 非独占锁与消息队列的协同作用
2.1 非独占锁的作用:扣减标识(流水)
- 防止超卖:在高并发场景中,库存扣减操作需要确保每个扣减请求是唯一的,这样才能避免库存被误扣。通过
setNx实现的非独占锁,可以确保每个扣减操作是独立的,并且通过锁的存在来标识每个扣减请求。 - 库存扣减的标识作用:每次库存扣减都会创建一个与当前库存数(例如
cacheKey_99或cacheKey_98)相关联的锁。这个锁并不是用来控制其他请求对资源的访问,而是作为一个 操作标识,确保每个操作在进行时被唯一标识,从而确保库存的唯一性。 - 与库存数绑定:锁的粒度是与库存数紧密绑定的,而不是共享一个通用的库存锁。例如,当线程1将库存从100扣减到99时,生成的锁是
cacheKey_99,而当线程2将库存从99扣减到98时,生成的锁是cacheKey_98。虽然它们的操作是并行的,但每个操作都会确保 独立性,因此不会产生竞争。
2.2 为什么需要非独占锁?
- 处理网络异常与集群抖动:在高并发的情况下,尤其是像秒杀这样的场景中,网络延迟或 Redis 集群的主从切换可能导致请求失败或者网络超时,从而导致一些错误。比如说:库存扣减10w次,可能不一定真的扣减了10w次,那么我们就需要每次扣减的时候,保存一个扣减的证明,这个证明就是锁。通过
setNx锁的机制,即使出现网络异常或 Redis 重试,仍然能够保证一个库存对应一把锁,不会超卖。 - 认为调整库存后的拦截: 另外就是出现问题时候,运营可能会调整库存。比如说:原来只有200个库存,抽奖的过程中添加锁,已经将库存减少到了100,这个时候人为添加100的库存的话,如果装配了的话,需要重新开始减,300-200范围内的锁还能获取,但是200-100范围内的锁已经都有了,就会被已经存在的锁拦截。防止一个商品多次被抽奖或者购买。
2.4 消息队列的作用: 削峰保护数据库
- 削峰填谷:在秒杀、抢购等高并发场景中,直接操作数据库会造成极大的压力,特别是对库存的持久化操作。因此,使用消息队列来异步处理库存扣减操作,能够有效减轻数据库的瞬时压力,避免系统因并发访问而崩溃。
- 延迟消费与批处理:消息队列能够将库存扣减的任务延迟消费并批量处理。这种设计使得数据库更新操作不再直接依赖于每个扣减请求的实时响应,而是通过异步的方式集中更新,避免数据库因并发请求造成瓶颈。
- 确保最终一致性:消息队列的使用不仅有助于减轻数据库压力,还确保了库存扣减的 最终一致性。尽管存在异步处理,但通过消息队列的消费机制,最终会确保数据库中的库存数会正确更新,而不会出现超卖。
- 异步执行与顺序执行:通过消息队列,库存更新的操作可以按照队列中的顺序进行,这样即使有多个扣减请求,也能保证最终库存的一致性。队列消费时,会按顺序进行库存更新,避免并发处理中的错误和数据不一致。
扣减库存的执行流程
0. 装配策略时一并装配库存信息
当在装配抽奖策略的时候,我们可以将奖品信息一并存放到Redis中,其键为strategyId和awardId,值为awardCount
1 |
|
1. 扣减库存请求的触发
用户发起购买请求或参与活动时,后台系统会接收到一个请求,需要检查和扣减库存。这时,可能会出现大量并发请求。我们需要通过 Redis 控制库存的扣减,防止超卖。
1 | //在规则树的库存规则节点上,需要执行库存扣减操作 |
2. 库存扣减(Redis DECR)
- 每次请求都会尝试通过 Redis 扣减库存,Redis 提供的
DECR命令是原子性的,这意味着它可以确保库存减少的操作是线程安全的。 - 比如,如果库存为 100,当第一次请求到来时,库存会通过
DECR命令减到 99;第二次请求到来时,库存再减到 98,依此类推。 - 通过
DECR执行库存减少操作,确保每次库存减少时,只有一个线程能操作该库存。
注意:
- 如果
DECR返回负数,说明库存已经为 0 或不足。这时需要采取补偿措施,如返回库存不足的错误信息。
1 | //Repository层的操作,先decr扣减redis中的库存,再返回锁 |
注意,这里必须使用原子性设置,否则可能会出现对应的库存为空的错误。因为如果多个线程几乎同时判断 surplus < 0,多个线程可能依次执行 setValue(cacheKey, 0),而 Redis 键的值可能会被覆盖或被其他逻辑清空。在这种情况下,某些线程在 setValue 操作完成后,其他并发线程可能又对该键进行了操作,导致值被意外清空。
3. 加锁机制(SETNX)
- 对于库存的每个减少操作,我们需要设置一个锁来确保在库存减少后,其他线程不能立即进行修改操作。
SETNX是 Redis 的一种原子操作,它确保只有在锁不存在的情况下,才能成功创建锁。- 每次库存减少后,我们创建一个基于库存数(
surplus)的锁,如cacheKey:98,确保每个库存值有唯一的锁。
4. 库存扣减成功后的消息队列
- 为了延迟执行库存更新(比如数据库操作),我们通过将库存更新任务加入到消息队列中,由消费者异步处理。
- 这样,库存的扣减和数据库更新分离开,避免了在高并发下直接修改数据库的压力。
- 消息队列可以用如 Kafka 或 RabbitMQ 等工具来实现。但这里使用的是redis中的阻塞队列和延迟队列,每个扣减成功的请求都会把相关的信息(如策略ID、奖品ID、剩余库存)发送到队列中,消费者会异步消费消息并执行数据库更新。
1 |
|
awardStockConsumeSendQueue() 方法:
- 该方法的作用是将一个
StrategyAwardStockKeyVO对象推送到 Redis 的延迟队列RDelayedQueue中。 RDelayedQueue是基于RBlockingQueue实现的,可以在指定的延迟时间后异步消费队列中的元素。在这里,元素将在 3 秒后被消费。- 延迟队列主要用于解耦和异步处理某些操作,比如更新库存数据库时,减少对数据库的瞬时压力。
- 通过
delayedQueue.offer()方法将strategyAwardStockKeyVO放入延迟队列,3 秒后,队列中的元素会被消费。
1 |
|
8. 定时任务的消费
- 消费者从消息队列中获取库存扣减的任务后,执行延迟更新数据库的操作。例如,可以使用定时任务每隔一段时间从队列中取出消息,处理库存更新。
- 延迟消费 可以帮助平衡系统负载,避免直接在请求时进行库存的数据库更新。
1 | 4j |
takeQueueValue() 方法:
- 从 Redis 阻塞队列中获取一个
StrategyAwardStockKeyVO类型的对象。 - 如果队列为空,调用
poll()方法会使当前线程阻塞,直到有新数据可供消费。 poll()会在有数据时返回一个元素,如果队列为空,则返回null。
updateStrategyAwardStock() 方法:
- 根据
strategyId和awardId参数,创建一个StrategyAward实体,并设置这两个属性。 - 调用 DAO 层的方法
updateStrategyAwardStock()来更新数据库中的库存数据。
1 |
|
1 | <update id="updateStrategyAwardStock" > |
Redis底层原理
非独占锁的实现
getBucket(key).trySet("lock")
在这个项目中我们实际上是这样来实现setNx的:
1 | //在redissonService中包装了一层 |
底层实现:getBucket(key).trySet("lock") 其实是对 Redis 中 SETNX 命令的封装。在 Redis 中,SETNX 的作用是:如果指定的 key 不存在,则设置它的值为指定的内容,并返回 true;如果 key 已经存在,则返回 false,表示锁已经被占用。
特点:
- 非可重入:一旦一个线程获得了锁,其他线程不能重复获取。
- 没有自动释放:
trySet本身没有为锁设置过期时间,必须由客户端来手动管理锁的释放,否则可能会导致死锁。 - 简洁性:这是一个比较简单、轻量的分布式锁实现,适用于对锁的功能要求不高的场景。
然而,使用 trySet 只能确保锁的 唯一性,但并没有处理锁的 过期时间、可重入性、锁的安全性、自动续期 等功能,这些功能是分布式锁中非常关键的部分,尤其是在高并发的分布式场景中。
getLock 锁(RLock)
1 | RLock lock = redissonClient.getLock(key); |
getLock 是 Redisson 提供的分布式锁 API,它背后是基于 Redis 实现的一个 可重入、可过期、高可用 的分布式锁。通过 getLock(key) 获取的锁会被封装为 RLock 对象,该锁提供了更多的功能和控制,尤其在复杂的分布式环境中,能够有效避免死锁和保证锁的释放。
- 底层实现:
getLock(key)返回的是一个RLock对象,它是基于 Redis 的原子命令(如SETNX、EXPIRE等)实现的分布式锁。RLock提供了许多高级功能,如 可重入性、锁超时、自动释放、重试机制 等。 - 特点:
- 重入性:同一线程可以多次获取同一把锁,而不会导致死锁。
- 锁过期:可以指定锁的过期时间,确保锁不会因为线程崩溃或异常释放导致死锁。
- 高并发安全性:通过
lock()、tryLock()等方法,确保锁的可靠性。 - 操作简便性:通过
RLock对象,可以使用锁的操作方法来直接控制锁的行为,如lock(),unlock(),tryLock()等。
RDelayedQueue
在 Redisson 中,RDelayedQueue 是基于 Redis 的 延迟队列 实现的,它允许你将任务延迟一段时间后再执行。在你的代码中:
1 | delayedQueue.offer(strategyAwardStockKeyVO, 3, TimeUnit.SECONDS); |
这行代码的意思是将 strategyAwardStockKeyVO 对象放入一个延迟队列中,并设置延迟时间为 3 秒。底层实现的核心原理如下:
1. RDelayedQueue 的工作原理

- redisson_delay_queue_timeout:xxx,sorted set数据类型,存放所有延迟任务,按照延迟任务的到期时间戳(提交任务时的时间戳 + 延迟时间)来排序的,所以列表的最前面的第一个元素就是整个延迟队列中最早要被执行的任务,这个概念很重要
- redisson_delay_queue:xxx,list数据类型,暂时没发现什么用,只是在提交任务时会写入这里面,队列转移时又会删除里面的元素。如果直接对 DelayedQueue执行poll()操作,不管有没有过期,都会删除list和sorted set中的元素。
- xxx:list数据类型,被称为目标队列,这个里面存放的任务都是已经到了延迟时间的,可以被消费者获取的任务,所以上面demo中的RBlockingQueue的take方法是从这个目标队列中获取到任务的
- redisson_delay_queue_channel:xxx,是一个channel,用来通知客户端开启一个延迟任务
2. 底层流程
- 设置延迟时间:
- 当你调用
offer(strategyAwardStockKeyVO, 3, TimeUnit.SECONDS)时,Redisson 会计算出当前时间加上 3 秒钟的时间戳(例如,假设当前时间是T,那么延迟时间戳为T + 3秒)。 - 然后,Redisson 会将
strategyAwardStockKeyVO对象存储到 Redis 的 Sorted Set 中,score为T + 3秒,并且value为strategyAwardStockKeyVO。
- 当你调用
- 等待时间到达:
RDelayedQueue并不会阻塞执行线程,而是会周期性地检查 Redis 中的元素的score(即延迟时间)。- 直到当前时间大于或等于元素的延迟时间,Redisson 才会将该元素从 Sorted Set 中移除,并放入到
RBlockingQueue中。 - 由于
RBlockingQueue是一个阻塞队列,一旦元素被添加到该队列中,消费者就可以从中获取到元素。
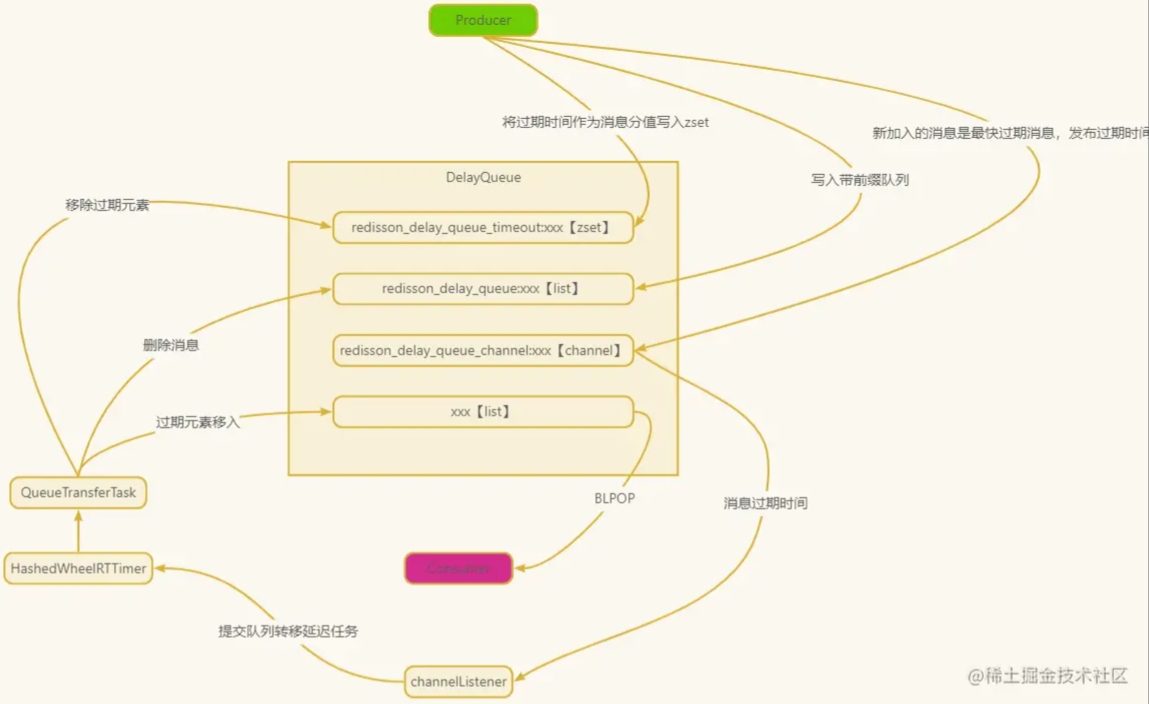
RBlockingQueue 和 RDelayedQueue 的协作
协作流程:RDelayedQueue 的底层实现依赖于 RBlockingQueue,因此在使用 RDelayedQueue 时,需要传入一个 RBlockingQueue 作为参数。这是因为 RDelayedQueue 的设计目的在于实现带延迟的队列,它的核心功能是允许元素被延迟消费。 而延迟的元素需要在最终消费时,依赖于 RBlockingQueue 的阻塞队列特性。
为了实现这一点,RDelayedQueue 需要借助 RBlockingQueue 的阻塞队列功能,即:
- 延迟入队:
- 当元素被放入
RDelayedQueue时,它并不会立即被消费,而是根据延迟时间来计算何时能被消费。
- 当元素被放入
- 延迟消费:
- 一旦延迟时间到了,元素会被消费,但消费过程需要阻塞等待。这个阻塞等待过程正是通过
RBlockingQueue来实现的。 RBlockingQueue提供了take()、poll()等阻塞方法,直到元素满足延迟消费条件后,才会从队列中取出并消费。
- 一旦延迟时间到了,元素会被消费,但消费过程需要阻塞等待。这个阻塞等待过程正是通过
set 和 setNX
Redis 底层是单线程的,所有命令执行都是顺序的,所以 SET 和 SETNX 命令在 Redis 的单线程环境下都会按顺序执行,不会出现并发执行的问题。但它们之间有一些重要的区别,尤其在 命令的行为 和 用法场景 上。
命令的区别
SET命令:用于设置一个键值对。如果指定的key已经存在,它会覆盖原有的值。1
SET key value
- 如果
key已经存在,SET会直接更新该key的值。 - 如果
key不存在,则会插入新的key-value对。
- 如果
SETNX命令:用于在key不存在时,设置该key的值。如果key已经存在,则 不执行任何操作。1
SETNX key value
- 如果
key已经存在,SETNX不会对该key进行任何修改,返回0。 - 如果
key不存在,则设置key的值,并返回1。
- 如果
SETNX 的用途:由于它只有在 key 不存在时才设置 key,这使得它成为实现分布式锁的一种非常有效的方式。你可以通过 SETNX 来尝试获取一个锁(设置一个 key),如果锁已存在,其他请求就无法获取到这个锁,从而避免了竞争条件。
例如,执行 SETNX 命令时,如果某个资源已经被占用(key 已存在),则其他线程或进程就无法再占用这个资源。这种特性使得它成为分布式系统中控制资源争用的一种常用手段。