大营销项目中遇到的bug与心得
营销服务第11节: API实现
这一节先自己实现了API,然后和视频中的对了一下,感觉还可以,就开始测试。
bug1: 404 Not Found
首先遇到的问题就是怎么也找不到Endpoint,curl,apiPost等工具都是404 Not Found。其实我是没写错的,有时候真是玄学问题,maven重新载入一下项目就可以了。
bug2: redis DelayedQueue
我们要用redisson中的RBlockQueue和RDelayedQueue的话,存入和取出的逻辑是这样的:
1 |
|
可以看到,在存入的时候,要先获取RBlockingQueue根据这个阻塞队列再构建RDelayedQueue,最后把对象存入延时队列。等到过期以后,延时队列中的对象会被存到RBlockingQueue中去,因此在取对象的时候,只需要根据key获得RBlockingQueue即可,不需要再获取RDelayedQueue了
bug3: redis setValue 和 setAtomicLong
在扣减库存的时候有如下代码:
1 |
|
我一开始写的是 setValue(cacheKey,0) 但是在压测的时候:如果多个线程几乎同时判断 surplus < 0,多个线程可能依次执行 setValue(cacheKey, 0),而 Redis 键的值可能会被覆盖或被其他逻辑清空。在这种情况下,某些线程在 setValue 操作完成后,其他并发线程可能又对该键进行了操作,导致值被意外清空。
因此我们要使用原子性操作setAtomicLong
前端第3节:对接抽奖页面
bug1
我想在页面中加一个<div> 里面包装了抽奖逻辑:
1 |
|
结果遇到报错:1
2
3
4Unhandled Runtime Error
[ Server ] Error: Event handlers cannot be passed to Client Component props.
<div className=... onClick={function strategyArmoryHandle} children=...>
这个错误是因为 Next.js 15 的新架构中,onClick 等事件处理器不能直接传递给 Server Components,而你定义的组件 Home 默认是 Server Component。解决方案是将需要交互的部分(如按钮和 onClick 逻辑)改为 Client Component。
新建一个 StrategyArmoryButton 组件:
1 | 'use client'; |
修改 Home 组件,使用 StrategyArmoryButton:1
2
3
4
5
6
7
8
9
10
11
export default function Home() {
return (
<div className="flex flex-col items-center justify-center min-h-screen bg-gray-100">
<header className="text-3xl font-bold text-center text-gray-800 my-8">
大营销平台 - 抽奖展示
</header>
<StrategyArmoryButton />
//....
</div>
营销服务 第13节:引入分库分表路由组件
bug1
因为mybatis中的mapper文件比较多,所以我将其按照domain分类成了两个子文件夹,但是做测试的时候一直找不到对应的mapper,这是因为配置问题:
之前在application-dev中关于mapper-locations 的配置是这样的:
1 | mybatis: |
这样就导致子文件夹中的mapper不能被扫描到,改成这样即可:
1 | mybatis: |
营销服务第16节:引入mq
心德1:流程中为什么要引入MQ
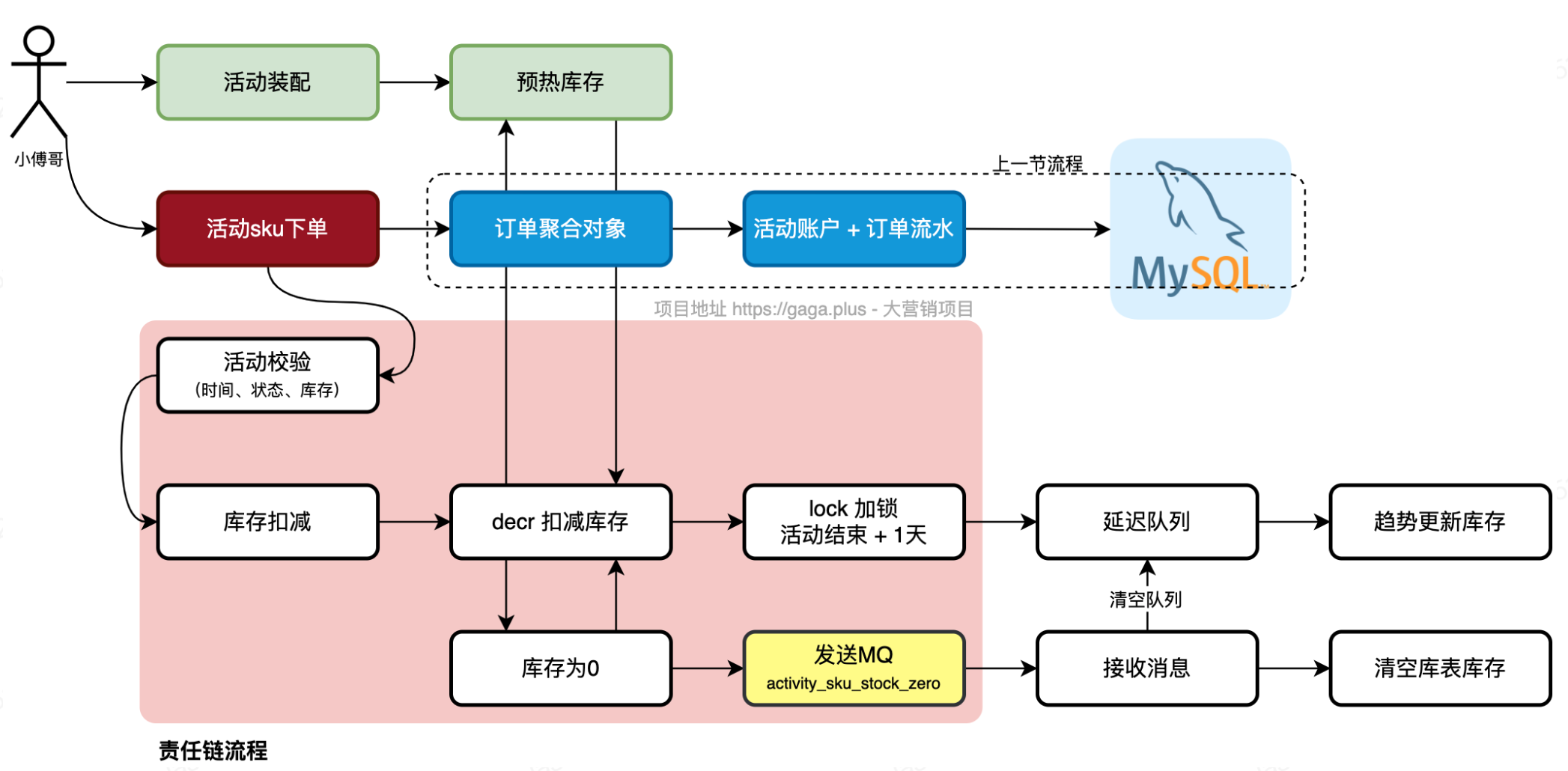
这是营销活动中,下抽奖单的逻辑:
- 第一步;完成责任链的活动校验,时间、状态、库存。
- 第二步;对库存的扣减,使用 decr + lock 锁的方式(兜底)进行处理。(和策略部分抽奖扣减库存的逻辑一样)
- 第三步;做完库存扣减后,发送延迟队列,由任务调度更新趋势库存,满足最终一致。
- 第四步;库存消耗为0后,发送MQ消息,驱动变更数据库库存为0
这里为什么要引入MQ?为什么只在sku库存扣减到0的时候引入MQ?
答:如果扣减完库存,直接发送mq去更新库,和直接操作库扣减库存不用缓存是一样的了。数据库是扛不住大量的数据同时更新一条记录的,所有的请求会进入等待前面的处理释放行级锁。那么其他查询的操作,也没法获取到数据库连接,直至拖垮数据库。 所以要做异步的,延迟的,缓慢的更新,降低集中操作数据库的处理。
因此redis缓存扣减策略是必要的,那么为什么还要引入MQ呢?因为可能一瞬间有几千条抽奖单将库存消耗为0,如果一条一条去更新数据库,确实比较慢,造成开销浪费。因此,用MQ一步到位,将库存变为0,同时清空延迟队列,减少数据库更新次数。
营销服务第19节:中奖记录写入MQ和任务扫描补偿
这里我遇到了一个很坑的bug:
在我查询数据库中的Task表的时候,我的xml是这么定义的:1
2
3
4
5
6<select id="queryNoSendMessageTaskList" resultMap="BaseResultMap">
select user_id,topic,message_id,message,state
from task
where state = 'fail' or (state = 'create' and now() - update_time > 6)
limit 10
</select>
但是,运行的时候却和我报如下错:
1 | org.mybatis.spring.MyBatisSystemException: nested exception is org.apache.ibatis.executor.result.ResultMapException: Error attempting to get column 'user_id' from result set. Cause: java.lang.NumberFormatException: For input string: "xiaofuge" |
也就是说,在表中读取user_id这列,却没有办法将其转换成数字类型。
这就很奇怪,因为我TaskPO对象和xml中,从来就没有定义过user_id是数字类型的。为什么会自动转换并报错?
答案出于一个偷懒的想法:
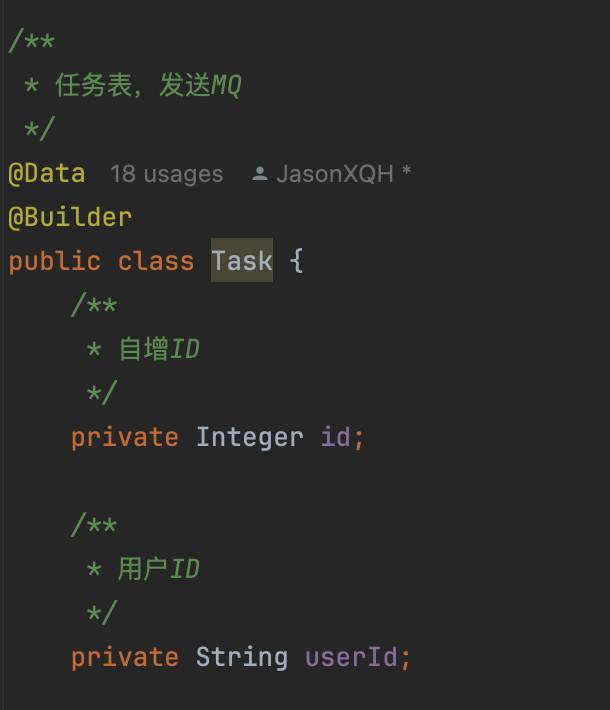
就是我在定义Task持久化对象的时候,使用了@Builder注释,但没有加上@AllArgsConstructor 和@NoArgsConstructor,这就导致了这导致了构造器的缺失,进而影响了 MyBatis 的工作方式。
@Builder 只生成了一个带有所有字段的构造器,并没有自动生成无参构造器和全参构造器。
@AllArgsConstructor注解会自动生成一个包含所有字段的构造器(包含Task类中的所有字段)。@NoArgsConstructor注解会自动生成一个无参构造器。
而MyBatis 在进行字段映射时,通常会使用无参构造器来实例化对象,然后通过 setter 方法来设置字段的值。而这里Task没有一个无参构造器,因此 MyBatis 就无法使用反射实例化对象,也就无法正确填充属性值。
所以,我们对于一个对象来说,要么老老实实用@Data修饰,然后用setXXX来填入参数,如果要用@Builder构造,就一定要再加上@AllArgsConstructor 和 @NoArgsConstructor
营销服务第20节
写API controller的时候,如何定义API?
当请求方法是GET的时候,传入参数是放在url里面的,此时需要使用@RequestParam注解
当请求方法是POST的时候,传入参数是放在请求体里面的,此时需要用@RequestBody注解获取参数
1 | (value = "armory", method = RequestMethod.GET) |
营销服务第26节:积分领域调额服务
在这一部分中,我们除了实现逻辑之外,还增加了查询判断和 redis lock 加锁增强代码健壮性。另外完善工程日志。
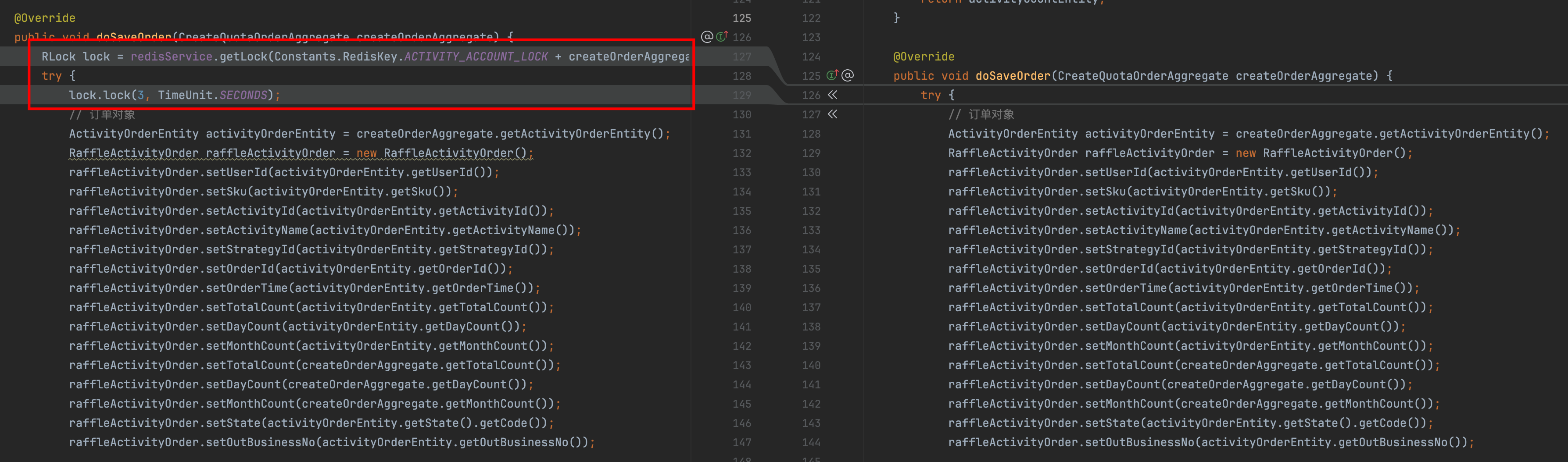
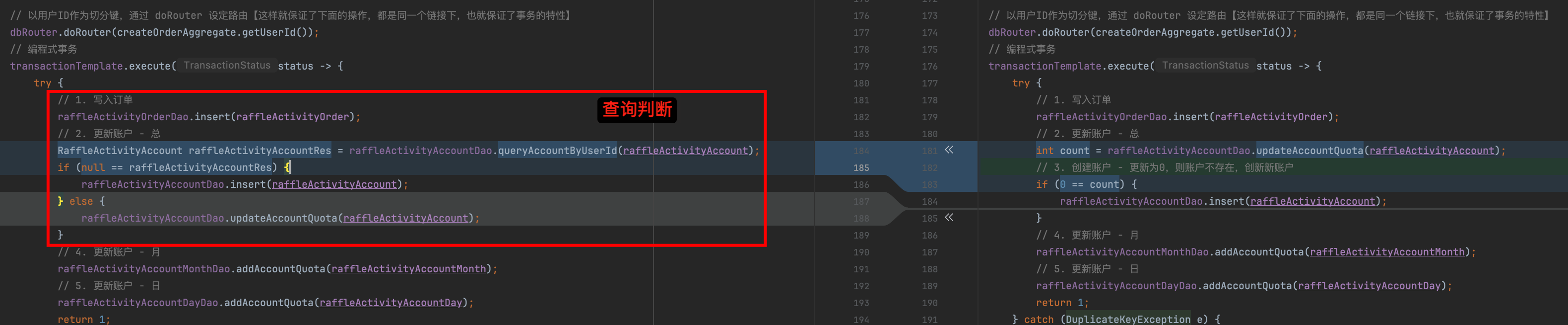
这样做的目的是什么?
确保并发安全
- 优势: 通过在方法开始时获取基于 Redis 的分布式锁,确保同一用户在同一活动下的订单保存操作不会被多个线程或进程同时执行。这有效防止了并发导致的数据不一致或重复插入的问题。
- 应用场景: 特别适用于高并发环境下,多个请求可能同时尝试为同一用户和活动创建订单的情况。
减少竞争条件
- 优势: 分布式锁确保了“查询再操作”逻辑中的一致性。由于锁的存在,多个线程不会同时执行
queryAccountByUserId和后续的插入或更新操作,从而避免了第一版本中可能出现的重复键异常 (DuplicateKeyException)。
- 优势: 分布式锁确保了“查询再操作”逻辑中的一致性。由于锁的存在,多个线程不会同时执行
锁的超时机制
- 优势:
lock.lock(3, TimeUnit.SECONDS);设置了锁的持有时间为3秒,防止因异常或错误导致的死锁。这确保了系统的健壮性,即使某个线程未能正常释放锁,锁也会在超时后自动释放,避免资源被永久占用。
原来的做法,是仅依赖于数据库级别的并发控制和事务管理来处理并发操作。
Redis 锁的特点
1. 分布式锁
- 目的: 确保在分布式系统中,某一关键代码段在任何给定时间内只能被一个实例执行。
- 使用场景: 防止竞争条件、管理资源访问、确保数据一致性。
2. 实现细节
- 原子性: Redis 提供原子操作(如
SETNX),确保锁的获取是原子的,避免竞争条件。 - 超时机制(TTL): 锁通常设置有过期时间,以防止持有锁的进程在失败或未能释放锁时导致死锁。
- 锁键的唯一性: 锁的键通常基于特定的标识符(如用户ID和活动ID)构建,以确保锁的范围和粒度。
3. 优势
- 性能高效: Redis 作为内存数据库,提供快速的锁获取和释放操作。
- 实现简单: 通过 Redis 命令和诸如 Redisson 等库,可以轻松实现分布式锁。
- 可扩展性强: 适用于大规模分布式系统,能够在多个实例间同步访问共享资源。
4. 潜在缺点
- 单点故障风险: 如果 Redis 服务不可用,锁机制将失效。可以通过 Redis 集群或哨兵机制来提高可用性。
- 复杂的失败场景处理: 需要处理进程在获取锁后崩溃但未释放锁的情况,通常需要结合唯一锁值和合理的超时设置。
- 额外的开销: 引入分布式锁会增加网络开销,如果滥用可能成为性能瓶颈。
5. 最佳实践
- 使用成熟的库: 采用经过验证的库(如 Redisson)来处理边界情况,并提供高级功能,如锁租约和可重入性。
- 设置合理的超时: 确保锁的超时时间足够完成关键代码段的执行,但不至于过长导致不必要的阻塞。
- 优雅地处理锁获取失败: 实现重试机制和回退策略,以应对锁获取失败的情况。
- 避免长时间持有锁: 将关键代码段保持尽可能短,减少锁的持有时间,降低竞争和阻塞的风险。
营销服务第27节:串联case
@RequestBody注解问题
在这一节我们新暴露了几个API,直到此时我才发现原来在controller里面,根据客户端发送的消息格式的不同,也需要匹配不同的写法。
第一个方法:creditPayExchangeSku
1 |
|
- 参数类型:
SkuProductShopCartRequestDTO是一个复杂的对象,通常包含多个字段,可能对应于前端发送的 JSON 结构。 - 注解使用:
@RequestBody注解用于将整个 HTTP 请求体中的内容(例如 JSON、XML)反序列化为SkuProductShopCartRequestDTO对象。
第二个方法:queryUserCreditAccount
1 |
|
- 参数类型:
userId是一个简单的字符串类型参数。 - 注解使用: 没有使用
@RequestBody注解,而是直接将userId作为方法参数。
为什么一个方法使用 @RequestBody,另一个不使用
a. 参数的复杂度和结构
- 复杂对象 vs 简单类型:
- 复杂对象(如
SkuProductShopCartRequestDTO): 通常包含多个字段和嵌套结构,适合通过@RequestBody将整个请求体映射为一个 Java 对象。这种方式适用于客户端以 JSON 或 XML 等格式发送复杂数据的情况。 - 简单类型(如
String userId): 仅包含单一值,通常通过 URL 参数、表单参数或查询参数传递。这种情况下,不需要@RequestBody,因为数据不在请求体的复杂结构中。
- 复杂对象(如
b. 客户端发送数据的方式
使用
@RequestBody的场景:- 客户端通过 HTTP 请求体(如 POST 请求的 JSON 数据)发送复杂的对象。
- 需要将整个请求体内容反序列化为一个 Java 对象进行处理。
如:客户端发送一个 POST 请求,内容类型为
application/json,请求体包含一个 JSON 对象:```
{"userId": "user123", "sku": 456789, "其他字段": "值"}
1
2
3
4
5
6
7
8
9
10
11+ Spring 使用 @RequestBody 将整个 JSON 对象反序列化为 `SkuProductShopCartRequestDTO` 实例,并传递给 `creditPayExchangeSku` 方法。
- 不使用 `@RequestBody` 的场景:
- 客户端通过 URL 参数或表单数据发送简单的键值对。
- 参数可以直接作为方法的参数进行绑定,无需反序列化整个请求体。
- 如:表单数据
-POST /query_user_credit
Content-Type: application/x-www-form-urlencodeduserId=user123
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
- URL 参数:
- `POST /query_user_credit?userId=user123`
- Spring 将 `userId` 参数直接绑定到 `queryUserCreditAccount` 方法的 `userId` 参数上,无需 `@RequestBody`。
#### **c. 注解的具体作用**
- `@RequestBody`:
- 告诉 Spring MVC 将 HTTP 请求体中的数据绑定到方法参数上。
- 适用于需要从请求体中读取和解析数据的情况,尤其是复杂对象。
- 无注解或使用其他注解(如 `@RequestParam`):
- 适用于从 URL 参数、查询参数或表单数据中获取简单值。
- 默认情况下,如果没有使用特定注解,Spring 会根据参数名称和请求中的参数进行匹配和绑定。
- 虽然在功能上,对于简单参数,省略 `@RequestParam` 可能不会引发问题,但为了代码的清晰性、可维护性以及更好的配置灵活性,**建议显式地使用 `@RequestParam` 注解**。这样不仅有助于代码的自解释性,还能在需要时轻松进行参数的详细配置
## Dubbo配置流程以及踩坑情况
### 引入dubbo和nacos
1. 在项目根pom文件中引入nacos:
```xml
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo</artifactId>
<version>3.0.9</version>
</dependency>
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo-spring-boot-starter</artifactId>
<version>3.0.9</version>
</dependency>
<dependency>
<groupId>com.alibaba.nacos</groupId>
<artifactId>nacos-client</artifactId>
<version>2.1.0</version>
</dependency>
- 配置
application-dev.xml
1 | dubbo: |
dubbo.application
name:
- 作用:定义 Dubbo 应用的名称。这个名称在服务注册中心(如 Nacos)中用于标识该应用。
- 意义:便于在注册中心中区分不同的 Dubbo 应用,尤其在微服务架构中有多个应用时。
version:
- 作用:指定应用的版本号。
- 意义:用于服务版本管理,可以在同一个接口的不同版本之间进行区分和兼容。例如,不同版本的服务可以同时存在,消费者可以选择调用特定版本的服务。
dubbo.registry
id:
- 作用:给注册中心实例指定一个唯一标识符。
- 意义:在配置多个注册中心时,通过
id区分不同的注册中心实例。
address:
- 作用:指定注册中心的地址和协议。
- 值:
nacos://127.0.0.1:8848nacos:表示使用 Nacos 作为注册中心。127.0.0.1:8848:Nacos 注册中心的地址和端口。
- 意义:Dubbo 服务提供者和消费者通过这个地址与 Nacos 进行通信,实现服务的注册与发现。
dubbo.protocol
name:- 作用:指定使用的通信协议。
- 值:
dubbo,表示使用 Dubbo 协议。 - 意义:Dubbo 支持多种协议(如
dubbo、rmi、http等),选择合适的协议以满足不同的性能和兼容性需求。
port:- 作用:指定服务提供者监听的端口号。
- 值:
-1表示自动分配端口。 - 意义:
- 自动分配:在开发或测试环境中,使用自动分配端口可以避免端口冲突,简化配置。
- 固定端口:在生产环境中,建议指定固定端口,便于服务的管理和监控。
dubbo.scan
base-packages:
- 作用:指定 Dubbo 扫描注解的基础包路径。
- 值:
io.github.jasonxqh.api - 意义:
- 自动扫描:Dubbo 会自动扫描指定包及其子包下的类,查找并注册带有 Dubbo 注解(如
@DubboService、@DubboReference)的服务提供者和消费者。 - 简化配置:无需在每个类上单独配置注册信息,提升开发效率。
- 自动扫描:Dubbo 会自动扫描指定包及其子包下的类,查找并注册带有 Dubbo 注解(如
启动nacos
首先,要在
在docker-compose-environment中配置nacos信息,运行后 拉取镜像,即可启动
1 | # http://127.0.0.1:8848/nacos 【账号:nacos 密码:nacos】 |
MYSQL_SERVICE_HOST=mysql:
- 含义:指定 MySQL 服务的主机名为
mysql。在 Docker Compose 中,服务之间可以通过服务名互相通信。因此,mysql指的是同一 Docker Compose 文件中定义的名为mysql的服务。
networks: - my-network:
- 含义:将 Nacos 容器加入到名为
my-network的 Docker 网络中。
depends_on: mysql:
- 含义:Nacos 服务依赖于名为
mysql的服务,并且在 MySQL 服务健康(service_healthy)后才启动。
MYSQL_SERVICE_PORT=3306:
- 含义:指定 MySQL 服务的端口为
3306,这是 MySQL 的默认端口。
Dubbo 服务提供者(@DubboService)
@DubboService 是 Dubbo 提供的注解,用于标识一个类为 Dubbo 服务提供者。它相当于 Spring 中的 @Service 注解,但专门用于 Dubbo 服务的发布和注册。
主要功能
- 服务发布:将标注的类作为 Dubbo 服务提供者,自动将其注册到注册中心(如 Nacos、Zookeeper)。
- 配置服务属性:通过注解属性配置服务的版本、分组、超时、重试次数等参数。
- 支持多协议和多注册中心:允许在不同的协议和注册中心下发布服务实例。
常用属性
version:指定服务的版本号,用于区分不同版本的服务。group:指定服务的分组,便于在同一个注册中心中管理不同组的服务。interfaceName:指定服务接口的全限定名(不常用,通常通过接口类自动推断)。timeout:调用超时时间,单位毫秒。retries:失败重试次数。protocol:指定服务使用的协议
比如:
1 | 4j |
- 自动注册:
@DubboService注解会自动将RaffleActivityController类注册为 Dubbo 服务,Dubbo 会根据配置将其信息发布到注册中心。 - 版本与分组:通过
version和group属性,可以在同一注册中心中管理不同版本和不同组的服务,避免冲突和提高灵活性。 - 超时与重试:通过
timeout和retries属性,控制服务调用的容错行为,提升系统的鲁棒性。
bug1
在我正确在application-dev.yml 中配置dubbo时,一开始出现了这个问题,spring无法扫描到我的配置信息。

解决:这种问题很坑,一般不是我们的代码问题,单纯是idea没有刷新配置文件。我们清理缓存并重启即可。
Dubbo 服务消费者(@DubboReference)
@DubboReference 是 Dubbo 提供的注解,用于注入 Dubbo 服务消费者,即引用远程的 Dubbo 服务。它相当于 Spring 中的 @Autowired 注解,但专门用于引用远程服务。
- 在 测试项目中,引入注册到nacos中的包,然后编写测试类:
1 | 4j |
@DubboReference:- 作用:这是 Dubbo 提供的注解,用于注入远程服务的引用(即消费者)。
- 属性说明:
interfaceClass:指定要引用的远程服务接口类。version:指定服务的版本,用于区分不同版本的服务实例。
- 优势:
- 简化配置:通过注解方式注入远程服务,无需手动配置服务地址。
- 动态代理:Dubbo 自动生成代理对象,简化服务调用。
注意:确保 Dubbo 已正确配置,且
IRaffleActivityService接口在服务提供者和消费者中版本一致,且接口类在两端保持同步。
bug2
在大营销项目中,需要先 mvn clean install重新构建项目所有的包,这样测试项目中才能引入最新版本的包。否则会出现引用到过去没有serialize的DTO的报错
运营上踩得坑
本地构建docker 镜像的时候,消耗过多本地空间
可以通过❯docker system df查看docker占用了那些资源,一般来说,build cache可能会占用大量空间
TYPE TOTAL ACTIVE SIZE RECLAIMABLE
Images 4 2 771.4MB 287.5MB (37%)
Containers 2 2 0B 0B
Local Volumes 4 2 197.1MB 196.8MB (99%)
Build Cache 80 0 15.25GB 15.25GB
可以使用 docker system prune -a 来删除缓存内容
构建不同平台的镜像
我们写完Dockerfile之后,可以运行一个脚本来构建,比如:1
2普通镜像构建,随系统版本构建 amd/arm
docker build -t jasonxqh/big-market-xqh-app:1.0 -f ./Dockerfile .
如果要部署到云服务器,那么就要构建云服务器段的版本,我因为本地是mac,云端是amd64, 导致不兼容。
1 | 只构建linux/amd64 |
1. 运行dockerfile前的构建准备
流程1:使用dockerhub
我们第一阶段的部署策略,是在我们的本地部署,然后利用docker把构建好的images推送到dockerhub上,然后在云主机上,运行docker compose文件将images拉取下来。这样做的缺点就是每次要迭代版本的时候,需要在本地构建、推送、云端拉取,时间会很长,而且有时候网络不好。
流程2:云主机端构建
现在我们可以先用git把前后端项目都拉取到云主机,直接在云主机端构建images,可以方便得制定版本号,自由度更高,构建速度更快。
前端后端调用情况
在云服务器上,前端调用后端时,不能再用localhost:8091了,而是要用公网IP
前端DockerFile模版
1 | docker build --platform linux/amd64 -t jasonxqh/big-market-frontend-xqh-app:1.0 . |
1 | FROM node:18-alpine AS base |
Dockerfile 解析
1. 第一阶段:base(基础镜像)
1 | FROM node:18-alpine AS base |
- 使用轻量级的 Node.js 18 Alpine 镜像作为基础镜像。
- 该镜像体积小,适合生产环境使用。
2. 第二阶段:deps(依赖安装阶段)
1 |
|
- 继承基础镜像:
- 在
base基础上创建一个新的构建阶段deps,用于安装依赖。
- 在
- 安装兼容库:
apk add --no-cache libc6-compat:安装glibc兼容库,用于运行某些需要特定依赖的 Node.js 程序。
- 设置工作目录:
WORKDIR /app:设置工作目录为/app,之后的所有操作都在此目录下执行。
- 复制依赖文件:
COPY package.json yarn.lock* package-lock.json* pnpm-lock.yaml* ./:将依赖文件复制到容器中。如果某些文件不存在,这一命令不会报错。
- 设置 npm 镜像源:
- 使用
https://registry.npmmirror.com/镜像源,加快依赖安装速度。
- 使用
- 安装依赖:
yarn install:安装依赖。
3. 第三阶段:builder(构建阶段)
1 |
|
- 继承基础镜像:
- 在
base基础上创建一个新的构建阶段builder,用于构建应用程序。
- 在
- 复制依赖:
COPY --from=deps /app/node_modules ./node_modules:从deps阶段复制node_modules目录到当前工作目录,避免重复安装依赖。
- 复制应用代码:
COPY . .:将当前目录的所有文件复制到容器中。
- 构建应用:
RUN yarn build:no-lint:运行构建命令(假设build:no-lint是package.json中定义的一个构建脚本)。
4. 第四阶段:runner(运行阶段)
1 | FROM base AS runner |
- 继承基础镜像:
- 在
base基础上创建一个运行阶段runner,只包含运行所需的内容,确保最终镜像尽量小。
- 在
- 设置工作目录:
WORKDIR /app:设置工作目录为/app。
- 复制构建输出:
COPY --from=builder /app/public ./public:复制public文件夹。COPY --from=builder /app/.next/standalone ./:复制standalone文件夹(Next.js 独立运行模式的输出)。COPY --from=builder /app/.next/static ./.next/static:复制静态文件。COPY --from=builder /app/.next/server ./.next/server:复制服务器端文件。
- 开放端口:
EXPOSE 3000:声明服务运行在容器的 3000 端口。
- 环境变量:
ENV PORT 3000:设置服务的运行端口为 3000。ENV HOSTNAME "0.0.0.0":服务监听所有网络接口。
- 启动命令:
CMD ["node", "server.js"]:运行应用服务器,启动 Next.js 应用。
需注意
此外,还需要配置next.config.ts:
1 | import type { NextConfig } from "next"; |
以及.eslintrc.json来忽略一些typescript的报错信息:
1 | { |
重构MyBatis时遇到错误
首先,如果在resource/mybatis文件夹下,如果我们的Mapper放在多个子文件夹中,我们需要再yml中冲顶定义mybatis的扫描路径:
1 | mybatis: |
否则会出现找不到mapper的错误
当我移动了某个mybatis中的某个mapper到新文件夹的时候(原本在其他子文件夹中),此时运行项目汇报如下错误:1
Cause: java.lang.IllegalArgumentException: Result Maps collection already contains value for io.github.jasonxqh.infrastructure.dao.IUserAwardRecordDao.BaseResultMap
这是因为我们之前构建的时候,在已经把这个mapper放在了target/classes/mybatis/mapper 中的某个子文件夹中了,现在我们将其移动到新的文件夹的话,再次构建就会导致重复构建的错误。
遇到这种情况我们可以用mvn clean install 来重新构建项目。