zookeeper学习
ZooKeeper 概述
a. Znode(节点)
- Znode 是 ZooKeeper 中的数据单元,类似于文件系统中的文件或目录。
- 层级结构:ZooKeeper 使用类似于 UNIX 文件系统的层级结构来组织 Znode。每个 Znode 都有一个唯一的路径,例如
/app/config/database。 - 节点类型:
- PERSISTENT(持久节点):永久存在,除非被手动删除。
- EPHEMERAL(临时节点):与客户端会话绑定,客户端断开连接后自动删除。
- PERSISTENT_SEQUENTIAL(持久有序节点):持久节点,Znode 名称后自动添加递增序号。
- EPHEMERAL_SEQUENTIAL(临时有序节点):临时节点,Znode 名称后自动添加递增序号。
数据存储:
- 单一数据块:每个 Znode 可以存储一块数据,数据的大小在 Zookeeper 中有限制(默认最大为 1 MB,可以通过配置调整,但不建议存储大量数据)。
- 元数据:每个 Znode 除了存储数据外,还包含一些元数据,如版本号、ACL(访问控制列表)、创建时间等。
b. Watcher(观察者)
- 功能:允许客户端为特定 Znode 注册 Watcher,当 Znode 的数据或子节点发生变化时,Watcher 会被触发,客户端可以即时感知到这些变化。
- 一次性:Watcher 是一次性的,触发后需要重新注册以持续监听。
c. 会话与节点生命周期
- 会话:客户端与 Zookeeper 之间的连接会话,有超时机制。如果客户端在会话超时时间内未能与 Zookeeper 通信,Zookeeper 会认为客户端失效,删除其所有 EPHEMERAL 节点。
- 节点生命周期:PERSISTENT 节点在创建后一直存在,除非被删除;EPHEMERAL 节点与会话绑定,随会话结束而自动删除。
d. ACL权限控制
Zookeeper 采⽤ ACL(Access Control Lists)策略来进⾏权限控制。定义了 五种权限:
- CREATE : 创建子节点的权限。
- READ : 获取节点数据和子节点列表的权限
- WRITE : 更新节点数据的权限
- DELETE : 删除子节点的权限
- ADMIN : 设置节点的 ACL 权限
Zookeeper 树形结构的设计原因
a. 组织与管理
- 层级化管理:树形结构使得数据能够以逻辑和有序的方式组织。例如,可以将所有配置相关的 Znode 放在
/app/config下,将所有服务注册信息放在/app/services下。 - 模块化:不同模块或功能可以有各自的子树,便于模块化管理和维护。
- 命名空间隔离:通过层级路径,可以轻松实现不同应用或模块之间的数据隔离,避免命名冲突。
b. 简化访问与导航
- 路径导航:类似于文件系统,使用路径可以快速定位到特定的 Znode,简化了数据的访问和操作。
- 递归操作:树形结构支持递归创建、删除和遍历操作,使得批量操作更加方便。例如,
creatingParentsIfNeeded()方法可以自动创建所有必要的父节点。
c. 支持 Watcher 机制
- 灵活的监听:客户端可以选择监听特定节点或整个子树的变化,提供了灵活的事件监听机制
- 事件传播:树形结构使得事件的传播和管理更加高效。例如,当父节点发生变化时,子节点的 Watcher 也可以相应地接收到通知,便于实现动态配置和服务发现。
- 事件隔离:通过层级路径,可以隔离不同模块或功能的事件,避免不必要的事件触发。
d. 继承与权限管理
- 继承机制:在树形结构中,子节点可以继承父节点的属性,如访问控制列表(ACL),简化了权限管理。
- 权限分层:通过层级路径,可以对不同层级的节点设置不同的权限,实现细粒度的访问控制。
实际应用中的树形结构优势
a. 分布式配置管理
在微服务架构中,每个服务可能有不同的配置需求。通过树形路径,可以为每个服务或模块创建独立的配置节点。
示例路径:
/config/serviceA/database:服务 A 的数据库配置。/config/serviceB/cache:服务 B 的缓存配置。
b. 服务发现与注册
将每个服务实例注册到特定的路径下,便于服务的发现和负载均衡。
示例路径:
/services/serviceA/instance1:服务 A 的第一个实例。/services/serviceA/instance2:服务 A 的第二个实例。
c. 分布式锁
通过创建有序临时节点,实现公平的分布式锁机制。
示例路径:
/locks/resource1:资源 1 的锁节点。
d. Leader 选举
在多实例应用中,通过有序临时节点选出一个 Leader 实例,负责协调任务或管理全局状态。
示例路径:
/leader-election/serviceA:服务 A 的 Leader 选举路径。
Zookeeper选主过程
1.1 选主的必要性
在 Zookeeper 集群中,Leader 节点负责处理所有的写请求(如数据变更),并负责将这些变更同步到所有的 Follower 节点。为了确保系统的一致性和高可用性,当 Leader 节点出现故障或宕机时,集群需要迅速选举出新的 Leader,以维持服务的连续性。
1.2 选主的算法
Zookeeper 使用 ZAB(Zookeeper Atomic Broadcast) 协议来实现 Leader 选举和消息广播。ZAB 主要分为两个阶段:
- 选举阶段(Leader Election Phase)
- 广播阶段(Broadcast Phase)
1.2.1 选举阶段
选举过程遵循以下步骤:
- 初始化:
- 当 Zookeeper 集群启动时,所有节点都会尝试通过投票来选举 Leader。
- 每个节点都会生成一个唯一的投票编号(zxid),用于区分不同的提议。
- 投票流程:
- 每个节点首先向集群中的所有节点发送其自己的提议(包括自己的投票编号和当前状态)。
- 每个节点接收到提议后,会根据以下规则决定是否接受该提议:
- 如果提议的 zxid 大于当前已接受的 zxid,则接受该提议,并向提议者发送赞成票。
- 如果提议的 zxid 小于当前已接受的 zxid,则拒绝该提议。
- 如果提议的 zxid 等于当前已接受的 zxid,则根据节点的唯一标识符(如 IP 地址或端口号)决定接受或拒绝。
- 达成共识:
- 一旦某个提议获得了超过半数节点的赞成票(即多数同意),该提议就被接受,并成为新的 Leader。
- 故障恢复:
- 如果在一定时间内没有节点达成共识(例如网络分区或节点故障),集群会重新启动选举过程,直到新的 Leader 被选出。
1.2.2 广播阶段
一旦 Leader 被选出,ZAB 进入广播阶段,负责在 Leader 和 Followers 之间同步数据变更。
- 数据同步:
- Leader 负责将所有的写请求(如数据更新)广播给所有 Followers。
- Followers 接收到数据变更后,依次确认并应用这些变更。
- 故障处理:
- 如果 Leader 在广播过程中发生故障,集群会重新进入选举阶段,选举出新的 Leader。
1.3 选主过程中的一致性保证
Zookeeper 通过以下机制保证选主过程中的一致性:
- 顺序性:所有的投票和提议都是按顺序进行的,确保不会出现冲突。
- 多数原则:只有当提议获得了超过半数节点的赞成票时,才能被接受,防止脑裂(split-brain)问题。
- Zxid(Zookeeper Transaction Id):每个提议和数据变更都有唯一的 zxid,用于保证操作的顺序性和一致性。
一致性协议对比(ZAB,Raft,PBFT)
| 特性 | ZAB | Raft | PBFT |
|---|---|---|---|
| 应用场景 | 专为 Zookeeper 设计 | 通用分布式系统 | 需要拜占庭容错的系统 |
| 选主机制 | 基于 ZAB,多数原则快速选举 | 基于任期和投票,多轮投票过程 | 基于轮询,多轮消息交换 |
| 一致性模型 | 原子广播,强一致性 | 强一致性,线性一致性 | 强一致性,拜占庭容错一致性 |
| 容错能力 | Crash Fault Tolerance | Crash Fault Tolerance | Byzantine Fault Tolerance |
| 通信复杂度 | 较低,针对性优化 | 中等,日志复制需要 | 高,通信复杂度 O(n²) |
| 可理解性 | 中等,针对 Zookeeper 的专用设计 | 高,设计理念清晰易懂 | 低,协议复杂性高 |
| 性能与扩展性 | 优化小规模集群,高效同步 | 可扩展至中等规模,Leader 瓶颈存在 | 低,难以扩展到大规模集群 |
| 实现复杂性 | 中等,专用实现 | 高,通用实现 | 高,复杂实现 |
| 适用性 | 仅适用于 Zookeeper (读多写少、低延迟需求) | 适用于多种通用分布式系统 | 适用于需要高安全性和容错性的场景(区块链等) |
Zookeeper Leader的职责
Leader 节点在 Zookeeper 集群中承担以下主要职责:
- 处理所有的写请求:
- 所有客户端的写请求(如创建节点、删除节点、更新数据)都由 Leader 处理。
- Leader 接收到写请求后,会将这些请求转化为事务(Transaction),并通过ZAB 协议将事务日志同步到所有 Followers。
- 事务日志管理:
- Leader 维护事务日志(Transaction Log),记录所有的数据变更操作。
- 事务日志用于在节点重启或故障恢复时,确保数据的一致性和持久性。
- 数据同步:
- Leader 负责将数据变更同步到所有 Followers,确保集群内的数据一致性。
- Leader 通过心跳机制(Heartbeat)定期向 Followers 发送心跳包,维持与 Followers 的连接。
- 监控集群状态:
- Leader 监控整个集群的健康状态,检测节点故障或网络问题。
- Leader 在检测到故障时,会触发相应的故障恢复机制,如重新选举 Leader 或调整数据同步策略。
Zookeeper 的负载均衡机制
Zookeeper 集群的负载均衡主要体现在以下几个方面:
3.1 客户端连接的均衡
每个 Zookeeper 客户端(如应用服务器上的 Zookeeper 客户端库)会连接到集群中的一个特定 Zookeeper 节点。为了实现负载均衡,通常采取以下策略:
- 多节点连接配置:
- 在客户端配置中指定多个 Zookeeper 节点的地址(如
zk1.example.com:2181, zk2.example.com:2181, zk3.example.com:2181)。 - 客户端库会自动选择一个可用的 Zookeeper 节点进行连接,通常是按顺序尝试,或者根据负载情况动态选择。
- 在客户端配置中指定多个 Zookeeper 节点的地址(如
- 随机连接策略:
- 客户端可以随机选择一个 Zookeeper 节点进行连接,避免所有客户端集中连接到同一个节点,均衡负载分布。
- 智能连接管理:
- 客户端库会监控连接的节点状态,当当前连接的节点不可用时,自动切换到其他可用节点,确保高可用性和负载均衡。
3.2 读写负载的分离
Zookeeper 的架构设计旨在将读操作和写操作分离,从而实现有效的负载均衡:
- 读操作由 Followers 处理:
- 大多数读请求(如获取节点数据、列出子节点等)可以由 Followers 直接处理,减少 Leader 的负载。
- Followers 可以独立处理读请求,不需要通过 Leader 转发,提高系统的整体吞吐量。
- 写操作由 Leader 处理:
- 所有写请求必须由 Leader 处理,以保证数据的一致性和顺序性。
- 虽然 Leader 负责写操作,但由于 Zookeeper 的高效设计,Leader 的负载通常不会成为瓶颈。
3.3 数据同步和压缩优化
为了优化负载和性能,Zookeeper 采用了一些数据同步和压缩的策略:
- 数据压缩(Data Compression):
- Zookeeper 支持对事务日志进行压缩,减少存储空间和网络传输负载。
- 压缩后的事务日志可以更高效地同步到 Followers,减轻网络负担。
- 快照机制(Snapshotting):
- 定期对整个数据树进行快照(Snapshot),减少事务日志的数量和大小。
- 在集群恢复或新节点加入时,可以通过快照快速恢复数据,提升系统的整体性能。
3.4 集群规模和节点数量的优化
为了实现负载均衡和高可用性,Zookeeper 集群的规模和节点数量需要合理配置:
- 奇数节点数:
- 集群通常配置为奇数个节点(如 3、5、7 个),以确保在部分节点故障时,仍能维持多数节点,保证 Leader 的选举和集群的可用性。
- 合理的节点分布:
- 将 Zookeeper 节点分布在不同的物理或虚拟机上,避免单点故障和资源竞争。
- 确保网络连接稳定,减少节点之间的通信延迟,提升数据同步效率。
- 监控和调整:
- 通过监控工具(如 Prometheus、Grafana)实时监控集群的负载情况和性能指标。
- 根据实际负载情况,动态调整集群规模,添加或移除节点,以优化负载均衡和性能。
2.2 Leader 的高可用性
为了保证系统的高可用性,Zookeeper 集群通常部署为奇数个节点(如 3、5、7 个),以确保在半数以上节点正常工作时,Leader 能够被选举出来。这样,即使部分节点发生故障,集群仍能维持多数节点的可用性,继续提供服务。
2.3 Leader 的负载
尽管 Leader 主要负责写请求和数据同步,但它在正常运行时的负载相对可控。Zookeeper 的设计旨在使 Leader 节点不成为性能瓶颈:
- 高效的通信协议:ZAB 协议和 Zookeeper 的内部优化使得数据同步和事务处理高效快速。
- 轻量级操作:大多数读操作由 Followers 处理,Leader 只负责写操作和数据同步,减少了负载压力。
- 集群扩展:通过增加 Followers 节点,可以分担读请求的压力,间接减轻 Leader 的负载。
ZooKeeper 部署方案
部署一个集中式的 Zookeeper 集群
步骤如下:
部署 Zookeeper 集群:
- 节点数量:建议使用 3 个或 5 个 Zookeeper 服务器节点,具体数量根据系统规模和高可用性需求决定。
- 独立服务器:将 Zookeeper 集群部署在专门的服务器或节点上,而不是应用服务器上,以避免资源竞争。
- 网络配置:确保所有 Zookeeper 节点之间以及应用服务器与 Zookeeper 集群之间的网络连接稳定且低延迟。
配置应用服务器连接到 Zookeeper 集群:
客户端配置:在每台应用服务器上配置 Zookeeper 客户端,使其连接到整个 Zookeeper 集群,而不是单个节点。通常在配置中指定所有 Zookeeper 节点的地址,客户端会自动选择一个可用的节点进行连接。
连接字符串示例:
1
zookeeper.connect=zk1.example.com:2181,zk2.example.com:2181,zk3.example.com:2181
故障切换:如果一个 Zookeeper 节点不可用,客户端会自动连接到其他可用节点,确保高可用性。
Zookeeper 集群中的配置变化通知机制
在实际部署中,所有应用实例将通过 Zookeeper 客户端连接到同一个 Zookeeper 集群。当某个配置节点发生变化时,Zookeeper 会通过其集群机制确保所有客户端(即所有应用实例)都能及时接收到配置变化的通知。这就是Zookeeper的Watcher机制,用于监听节点的变化。
具体流程如下:
- 配置节点变化:
- 当某个配置节点(如
/big-market-dcc/config/degradeSwitch)在 Zookeeper 集群中发生变化时,所有连接到集群的客户端会收到相应的通知。
- 当某个配置节点(如
- 通知分发:
- Zookeeper 集群内部通过一致性协议确保所有节点上的数据一致,并通过网络将变化通知给所有订阅了该节点的客户端。
- 每个应用服务器上其 连接到集群的 Zookeeper 客户端接收到通知,并根据监听器逻辑更新相应属性。
示意图
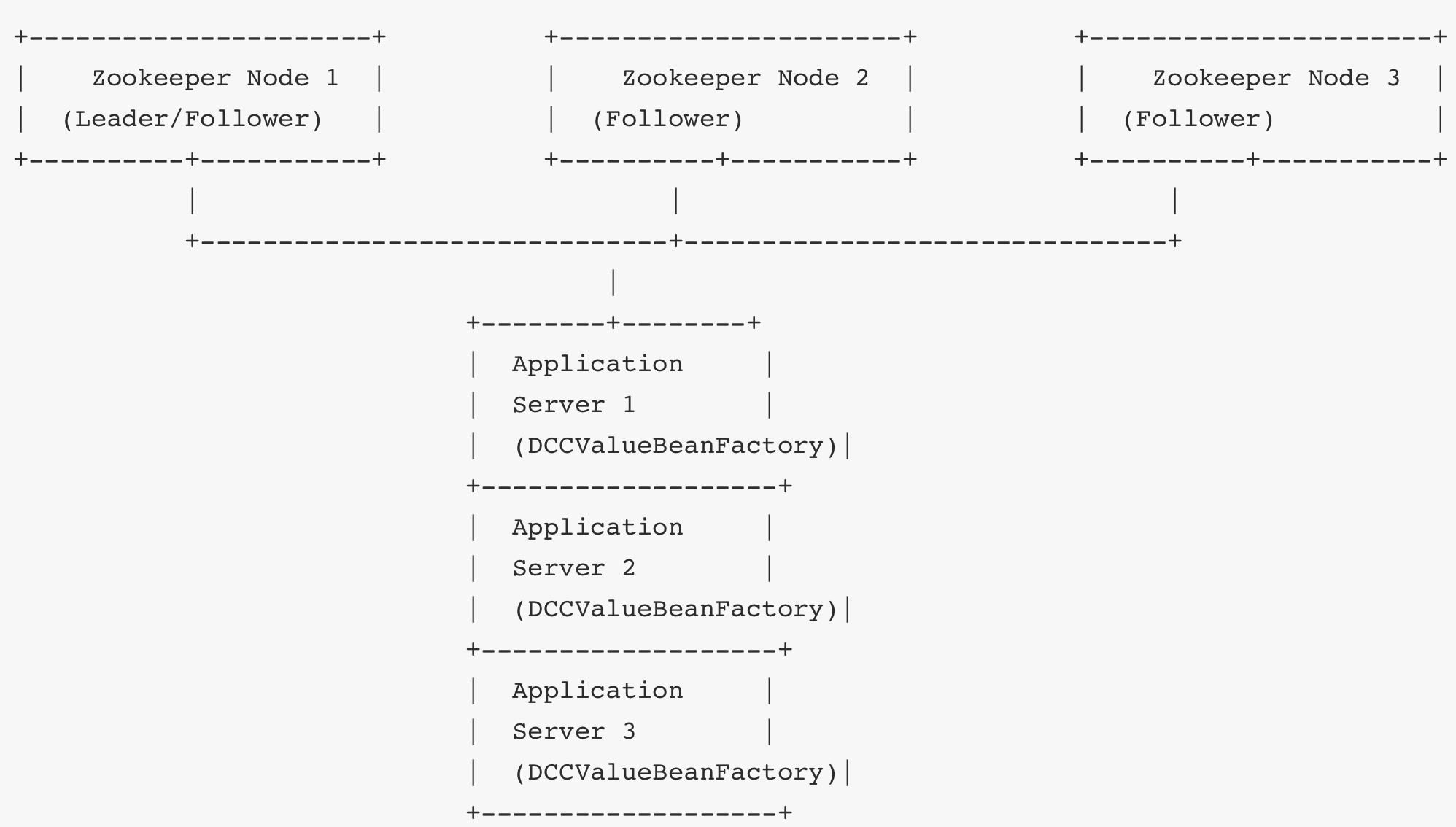
- Zookeeper 集群:3 个 Zookeeper 节点组成一个集群,确保高可用性和数据一致性。
- 应用服务器:多个应用服务器通过 Zookeeper 客户端连接到 Zookeeper 集群,监听配置节点的变化。
实现步骤总结
- 部署 Zookeeper 集群:
- 在独立的服务器上部署多个 Zookeeper 实例,形成一个集群(ensemble)。
- 配置
zoo.cfg文件,确保集群中各节点的正确通信和选举。
- 配置应用服务器连接:
- 在每台应用服务器上,配置 Zookeeper 客户端连接到整个 Zookeeper 集群。
- 确保应用服务器能够访问所有 Zookeeper 节点的地址和端口。
- 实现动态配置监听:
- 您现有的
DCCValueBeanFactory类通过 Zookeeper 客户端监听配置节点的变化。 - 当配置节点变化时,所有应用服务器上的监听器都会收到通知,并相应地更新 Bean 的属性值。
- 您现有的
- 确保配置同步:
- 使用集中式 Zookeeper 集群,确保所有应用服务器共享相同的配置数据源,保证配置的一致性和同步性。
在项目中使用Zookeeper
引入zookeeper
根pom文件,引入zookeeper包
1 | <dependency> |
单实例部署
docker-compose文件,拉取zookeeper镜像
1 | zookeeper: |
application-dev.yml中引入zookeeper配置
1 | zookeeper: |
多实例部署
Docker-compose.yml
1 | # 多实例 |
application-dev.yml中引入zookeeper配置
1 | zookeeper: |
启动之后,通过echo srvr | nc localhost 2182 命令,可以查看zoo2的信息: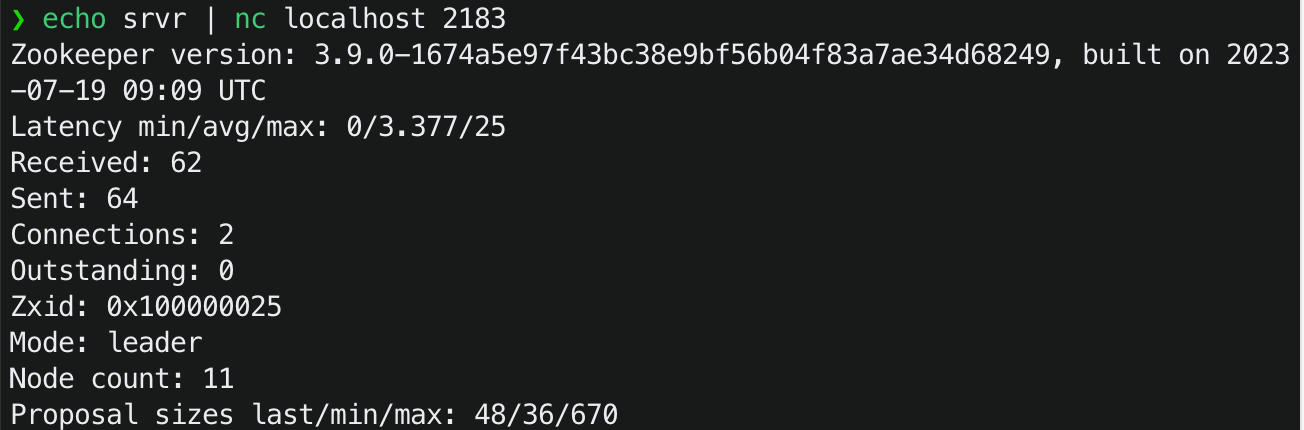
ZookeeperClientConfigProperties 类
1 | package io.github.jasonxqh.config; |
@ConfigurationProperties(prefix = "zookeeper.sdk.config", ignoreInvalidFields = true):- 这是 Spring Boot 的注解,用于将配置文件中的属性映射到这个类的字段。
prefix:指定前缀为zookeeper.sdk.config,意味着配置文件中所有以这个前缀开头的属性都会映射到这个类中。ignoreInvalidFields = true:如果配置文件中有无法映射的字段,Spring 会忽略它们,不会抛出异常。
connectString:- 描述:Zookeeper 集群的连接字符串,格式通常为
host1:port1,host2:port2,host3:port3。 - 示例:
localhost:2181或192.168.1.100:2181,192.168.1.101:2181
- 描述:Zookeeper 集群的连接字符串,格式通常为
baseSleepTimeMs:- 描述:重试连接时初始的等待时间,单位为毫秒。
- 作用:在连接失败后,Curator 会按照指数退避算法重试连接,
baseSleepTimeMs是初始等待时间。
maxRetries:- 描述:最大重试次数。
- 作用:在连接失败后,Curator 会尝试重试,
maxRetries限制了重试的次数。
sessionTimeoutMs:- 描述:Zookeeper 会话超时时间,单位为毫秒。
- 作用:如果客户端在这个时间内没有与 Zookeeper 服务器通信,服务器会认为客户端失效,并关闭会话。
connectionTimeoutMs:- 描述:连接超时时间,单位为毫秒。
- 作用:客户端在建立与 Zookeeper 服务器的连接时,如果超过这个时间还未连接成功,则会抛出异常。
ZooKeeperClientConfig 类
1 | package io.github.jasonxqh.config; |
功能与作用
@EnableConfigurationProperties(ZookeeperClientConfigProperties.class):- 启用
ZookeeperClientConfigProperties类的配置属性绑定,确保 Spring 能够将配置文件中的属性正确映射到这个类中。
- 启用
@Bean(name = "zookeeperClient"):- 定义一个 Spring Bean,名字为
zookeeperClient。标识createWithOptions方法,告诉 Spring 该方法会返回一个对象,这个对象需要被注册为 Spring 容器中的 Bean。 - 返回类型:
CuratorFramework,是 Zookeeper 的一个高级客户端框架,提供了比原生 Zookeeper 客户端更丰富、更易用的 API,简化了 Zookeeper 的操作,如服务发现、分布式锁等。
- 定义一个 Spring Bean,名字为
方法详解
createWithOptions:- 参数:
ZookeeperClientConfigProperties properties,自动注入配置属性。 - 步骤:
- 创建重试策略:
- 使用 ExponentialBackoffRetry,基于指数退避算法的重试策略,在每次重试失败后,等待时间逐渐增加,避免频繁重试导致的资源浪费。。
- 参数为
baseSleepTimeMs(初始等待时间)和maxRetries(最大重试次数)。
- 构建 CuratorFramework 客户端:
connectString:Zookeeper 连接字符串。retryPolicy:前面定义的重试策略。sessionTimeoutMs:会话超时时间。connectionTimeoutMs:连接超时时间。
- 启动客户端:
- 调用
client.start()启动 CuratorFramework 客户端。
- 调用
- 返回客户端:
- 将启动的
CuratorFramework实例作为 Bean 返回,供其他组件使用。
- 将启动的
- 创建重试策略:
- 参数:
测试类
1 |
|
先引入CuratorFramework ,也就是刚才注册为Bean的那个对象
1.test_all 方法
1 |
|
功能:
- 创建一个 临时节点(
EPHEMERAL),路径为/big-market-dcc/config/downgradeSwitch,初始数据为"0"。 - 修改该节点的数据两次,分别设置为
"0"和"1"。
背后原理:
- 临时节点在客户端与 Zookeeper 的连接断开时自动删除。这对于需要自动清理的节点非常有用,如会话信息、临时锁等。
- 数据修改:通过
setData方法更新节点的数据,操作顺序展示了 Zookeeper 对节点数据的顺序一致性。
2.createNode 方法
1 |
|
功能:
- 创建一个 永久节点(默认模式,
PERSISTENT),路径为/big-market-dcc/config/downgradeSwitch/test/a,数据为"0"(尽管未设置数据)。 - 如果该路径不存在,则创建,包括必要的父节点。
背后原理:
- 永久节点在客户端与 Zookeeper 的连接断开后仍然存在,适用于需要长期存在的数据,如配置信息、服务注册等。
creatingParentsIfNeeded():确保在创建目标节点之前,所有必要的父节点都已存在。如果父节点不存在,则自动创建。
3.createEphemeralNode 方法
1 |
|
功能:
- 创建一个 临时节点,路径为
/big-market-dcc/config/epnode,数据为"0"。
背后原理:
- 临时节点在客户端会话结束时自动删除,适用于需要临时存在的数据,如临时锁、会话信息等。
4.crateEphemeralSequentialNode 方法
1 |
|
功能:
- 创建一个 临时有序节点,路径为
/big-market-dcc/config/epsnode,数据为"0"。 - 节点名将被自动加上一个递增的序号,如
/big-market-dcc/config/epsnode0000000001。
背后原理:
- 临时有序节点结合了 临时节点和 有序节点的特性,适用于需要按顺序创建临时节点的场景,如任务队列、排名系统等。
5.setData 方法
1 |
|
功能:
- 更新两个节点的数据:
/big-market-dcc/config/downgradeSwitch设置为"111"。/big-market-dcc/config/userWhiteList设置为"222"。
背后原理:
- 数据更新:通过
setData方法修改节点的数据,Zookeeper 确保数据的一致性和顺序性。
6.getData 方法
1 |
|
功能:
- 获取两个节点的数据:
/big-market-dcc/config/downgradeSwitch。/big-market-dcc/config/userWhiteList。
- 记录日志输出获取的数据。
背后原理:
- 数据读取:通过
getData方法获取节点的数据,Zookeeper 保证数据的线性一致性,即所有客户端看到的操作都是按照顺序执行的。
7.setDataAsync 方法
1 |
|
功能:
- 异步设置数据:在后台线程中更新
/big-market-dcc/config/downgradeSwitch节点的数据为"0"。 - 监听器:注册一个
CuratorListener,监听数据更新事件,记录相关信息。
背后原理:
- 异步操作:通过
inBackground()方法,数据设置操作在后台执行,主线程不会阻塞。 - 事件监听:
CuratorListener用于监听 CuratorFramework 事件,捕捉并处理各种 Zookeeper 事件,如数据更改、节点创建等。
8.deleteData 方法
1 |
|
功能:
- 删除
/big-market-dcc/config/downgradeSwitch节点及其所有子节点。
背后原理:
- 节点删除:通过
delete方法删除指定路径的节点。 deletingChildrenIfNeeded():如果目标节点有子节点,则递归删除所有子节点。这对于删除非叶子节点非常有用。
9.guaranteedDeleteData 方法
1 |
|
功能:
- 安全删除:删除
/big-market-dcc/config/downgradeSwitch节点,即使第一次删除失败,也会在后台继续尝试删除,直到成功为止。
背后原理:
guaranteed():确保删除操作最终成功,即使发生中间失败,Curator 会在后台持续重试,直到节点被成功删除。
10.watchedGetChildren 方法
1 |
|
功能:
- 获取
/big-market-dcc节点的所有子节点,并为该路径注册一个 Watcher。
背后原理:
watched():在读取子节点列表的同时,为该路径注册一个 Watcher,当子节点发生变化时(如新增、删除),Watcher 会被触发。- 数据变化监听:通过 Watcher 机制,客户端可以实时感知 Zookeeper 节点的变化,适用于动态配置、服务发现等场景。
11. getDataByPath 方法
1 |
|
功能:
- 从指定路径
/big-market-dcc/config/downgradeSwitch获取数据,并将其反序列化为指定的类实例。
背后原理:
- 数据读取与反序列化:通过
getData方法获取节点数据后,使用 FastJSON 将 JSON 字符串转换为相应的类对象。 - 动态类型加载:使用
Class.forName(fullClassName)动态加载类,这里fullClassName需要替换为实际的类名。
可视化页面
我们可以在docker-compose中配置zoonavigator来管理zookeeper
1 | zoonavigator: |
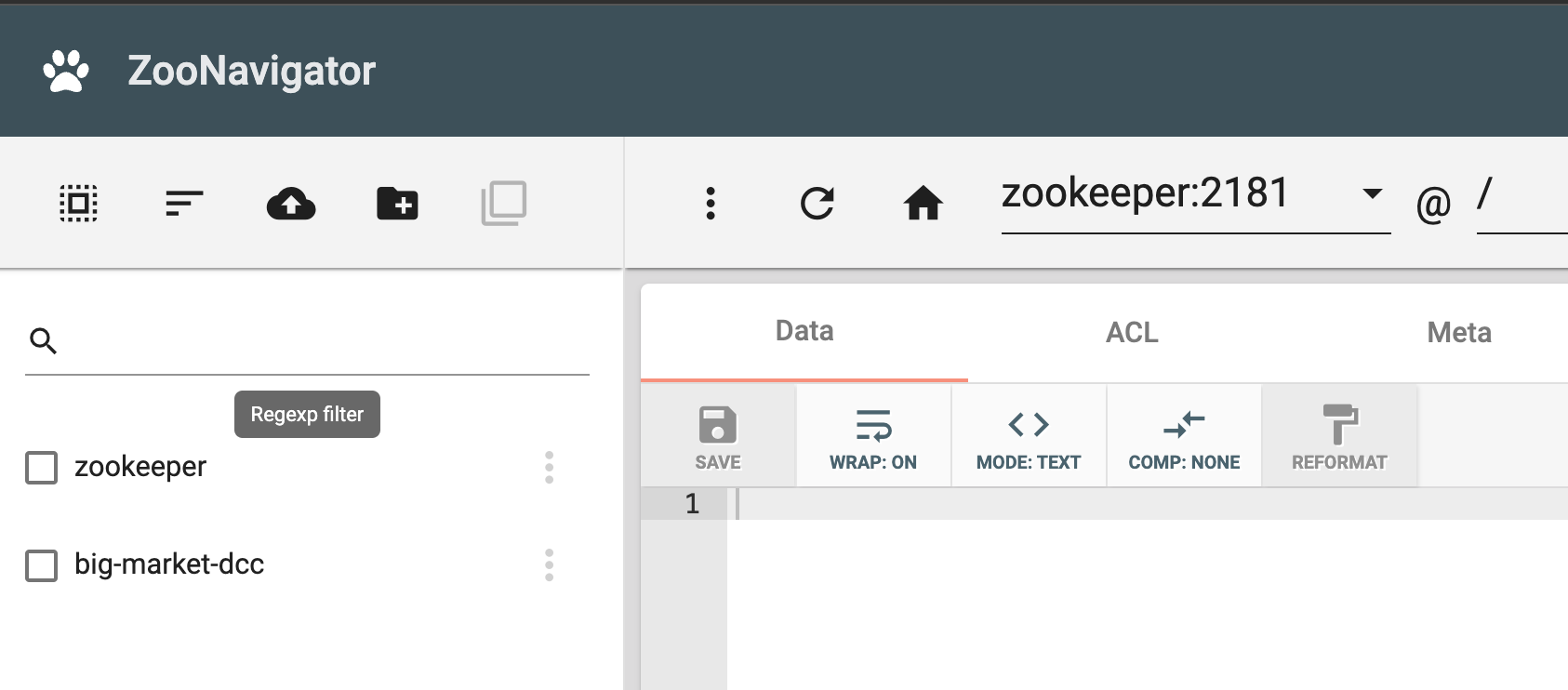
访问界面: 打开浏览器,访问
http://localhost:9000。连接 ZooKeeper: 在界面中输入 ZooKeeper 的服务地址(如
zookeeper:2181),即可查看和管理节点数据。
基于注解的动态配置管理机制
DCCValueBeanFactory 和 DCCValue 构成了一个基于注解的动态配置管理机制,主要用于将 Zookeeper(通过 Apache Curator 客户端)中的配置动态注入到 Spring 管理的 Bean 中,并在配置变化时实时更新这些 Bean 的属性值。以下是对这两个类的详细解析及其实现效果的说明:
@DCCValue注解
1 | (RetentionPolicy.RUNTIME) |
@Retention(RetentionPolicy.RUNTIME): 该注解在运行时保留,允许反射访问。@Target(ElementType.FIELD): 该注解只能应用于类的字段(成员变量)。@Documented: 该注解包含在 Javadoc 中
功能
@DCCValue 注解用于标注需要从配置中心(Zookeeper)中动态注入值的 Bean 字段。注解的 value 属性用于指定配置的键值,格式为 "key:defaultValue",其中 key 是在 Zookeeper 中的配置路径,defaultValue 是当 Zookeeper 中没有对应配置时的默认值。
1 | public class SomeService { |
在上述示例中,isSwitch 字段将从 Zookeeper 的路径 /big-market-dcc/conig/isSwitch 中获取配置值。如果该路径下没有配置值,则 isSwitch 将被赋予默认值 "1"。
DCCValueBeanFactory 类
DCCValueBeanFactory 函数
1 | 4j |
- 初始化 Zookeeper 配置路径:
- 确保 Zookeeper 中的基础配置路径
/big-market-dcc/conig存在,如果不存在则创建。
- 确保 Zookeeper 中的基础配置路径
- 监听配置变化(
NODE_CHANGED)时:- 使用
CuratorCache监听/big-market-dcc/conig路径下的节点变化。 - 当监听到节点变化(如
NODE_CHANGED)时,找到对应的 Bean 和字段,动态更新字段的值。
- 使用
postProcessAfterInitialization函数
为什么要重写 postProcessAfterInitialization?
postProcessAfterInitialization 是 Spring BeanPostProcessor 接口的方法之一,允许我们在 Spring 容器初始化 Bean 后对其进行额外的处理。通过重写该方法,可以实现对所有 Bean 的统一扫描和处理。
在这里,重写 postProcessAfterInitialization 的目的是 对 Spring 容器中所有 Bean 的字段进行扫描和注入动态配置,实现与 ZooKeeper 配置中心的集成。
函数介绍
这个函数的核心作用是 扫描 Spring Bean 中标注了 @DCCValue 注解的字段,将其与 ZooKeeper 中的节点绑定,完成以下功能:
- 根据注解配置值从 ZooKeeper 中获取数据,并注入到字段中。
- 如果 ZooKeeper 节点不存在,则自动创建,并设置默认值(如果有默认值)。
- 将字段与 ZooKeeper 节点动态绑定,当节点数据发生变化时能够更新字段的值
1 | 4j |
实现效果
- 动态配置注入:
- 通过在 Bean 的字段上使用
@DCCValue注解,开发者可以轻松地将 Zookeeper 中的配置值注入到 Spring Bean 中,无需手动编写配置加载逻辑。
- 通过在 Bean 的字段上使用
- 实时配置更新:
- 由于
DCCValueBeanFactory使用CuratorCache监听配置路径下的节点变化,当 Zookeeper 中的配置发生变化时,相关 Bean 的字段值会被实时更新,保证应用程序始终使用最新的配置。
- 由于
- 默认值支持:
- 如果 Zookeeper 中没有对应的配置值,可以在注解中指定默认值,确保应用程序在缺失配置时仍能正常运行。
示例流程
- 启动时:
- Spring 容器初始化
DCCValueBeanFactory。 DCCValueBeanFactory检查并创建基础配置路径/big-market-dcc/conig。- 遍历所有 Bean,查找被
@DCCValue注解标注的字段,加载对应的配置值到字段中。如果配置不存在,则使用默认值。
- Spring 容器初始化
- 运行时:
- 当 Zookeeper 中某个配置节点(如
/big-market-dcc/conig/isSwitch)的值发生变化时,CuratorCache监听到NODE_CHANGED事件。 DCCValueBeanFactory根据变化的节点路径找到对应的 Bean 和字段,动态更新字段的值。
- 当 Zookeeper 中某个配置节点(如
使用场景
- 动态配置管理:
- 在分布式系统中,配置管理往往需要集中化和动态化。通过这种方式,可以在不重启应用的情况下,实时更新配置,提高系统的灵活性和可维护性。
- 特性开关(Feature Toggle):
- 可以通过动态配置来控制应用程序的特性开关,快速启用或禁用某些功能,便于灰度发布和 A/B 测试。
- 环境配置隔离:
- 在不同的运行环境(如开发、测试、生产)中,通过 Zookeeper 管理不同的配置,简化配置管理和部署流程。
答疑1
修改zookeeper的节点值时,是否必须连接到Leader节点?
应用节点无需直接连接到 Leader 节点,可以连接到 Zookeeper 集群中的任意一个节点(Leader 或 Followers)。当应用节点连接到 Followers 并尝试执行写操作时,Zookeeper 的客户端库(如 Curator)会自动将写请求重定向到当前的 Leader。具体过程如下:
- 连接到任意节点:应用程序通过 CuratorFramework 客户端连接到 Zookeeper 集群中的任意一个节点。
- 执行写操作:
- 如果客户端连接的是 Leader 节点,写请求将直接由 Leader 处理。Leader会更新事务日志,并通过 ZAB 协议将变更同步到 Followers。
- 如果客户端连接的是 Followers 节点,Followers 会将写请求转发给 Leader 节点。
- 自动重定向:CuratorFramework 客户端会自动处理重定向,无需应用程序显式管理。这确保了写操作总是由 Leader 处理,保持数据一致性。
优势
- 透明性:应用程序无需关心当前 Leader 是哪个节点,简化了客户端实现。
- 高可用性:即使 Leader 发生故障,客户端可以自动切换到新的 Leader,保持写操作的连续性。
- 负载均衡:读请求可以由任意节点处理,分散了负载压力。
大营销项目中使用动态配置管理
在这里,我们用DCCValue注解标识了degradSwitch,并将其默认值设置成了open
1 | public class RaffleActivityController implements IRaffleActivityService { |
项目运行启动之后,会自动扫描带有@DCCValue注解的Bean,并在zookeeper中注册一个节点,存储其默认的值。如下所示: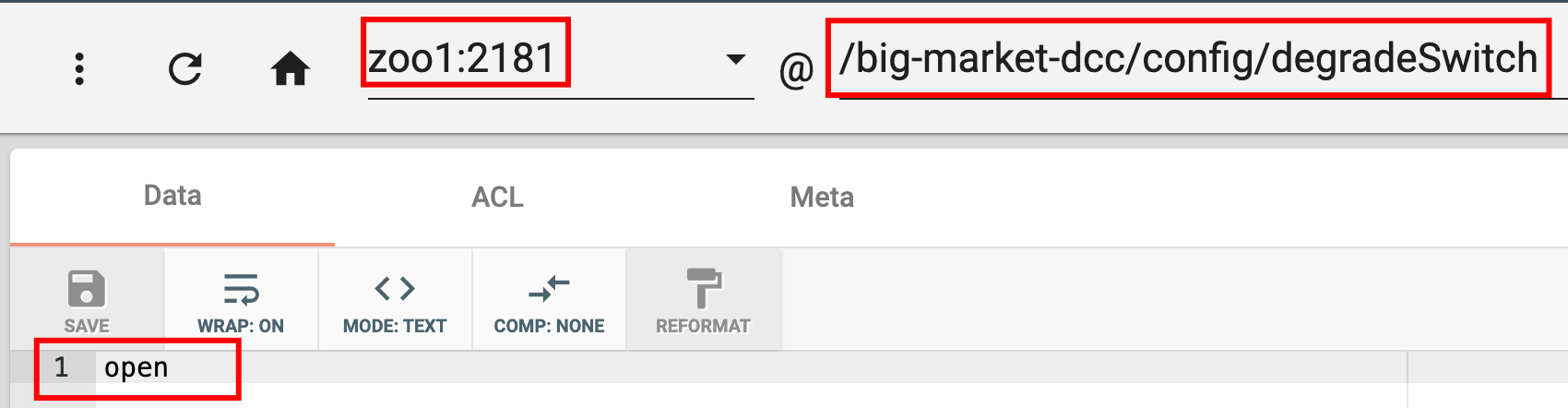
而且,我们发现切换zookeeper实例的时候,发现每个实例中都有这个degradeSwitch节点,并且节点的值都是open。
如果我们通过一些方法改变zookeeper上的degradeSwitch节点值,那么这个变化就会被监听到,从而对应的Bean对象的值就会被修改。
如果活动降级、熔断了,那么就会进入这个if判断,返回一个null值。
结合 Zookeeper 与 Redis 的最佳实践
鉴于 Zookeeper 和 Redis 各自的优势和局限性,在某些场景下,结合使用这两者可以更好地满足分布式系统的需求。以下是一些最佳实践:
- 配置管理:继续使用 Zookeeper 进行集中式配置管理,确保强一致性。使用 Redis 作为配置的缓存层,提高读取性能。
- 分布式锁:在需要高性能和快速锁定的场景下,使用 Redis 实现分布式锁;在需要强一致性和复杂锁定机制的场景下,使用 Zookeeper。
- 服务发现:使用 Zookeeper/Nacos 进行服务发现和注册,确保服务实例的动态变化能够被客户端实时感知。
- 消息传递和通知:使用 Redis 的 Pub/Sub 或 Keyspace Notifications 进行实时消息传递和事件通知。